Django连接mysql数据库浅析_django连接mysql可以 数据分析-程序员宅基地
技术标签: django
一、安装pymysql
1. 查看已安装的第三方库的列表
命令: pip list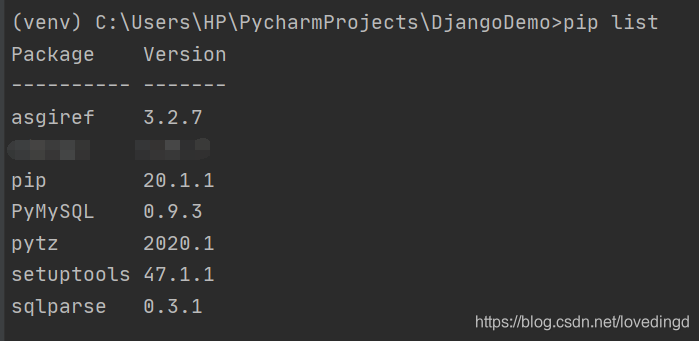
2. 如果没有pymysql这个第三方库,则安装(需要注意的是django2.2版本的暂时还不支持pymysql,所以如果使用的话,需要先降到2.1版本,不然可能会报错,如果报错,请查看我上一篇的解决办法)
命令:pip install django==2.1.0
命令:pip install pymysql
3. 安装成功后的第三方库
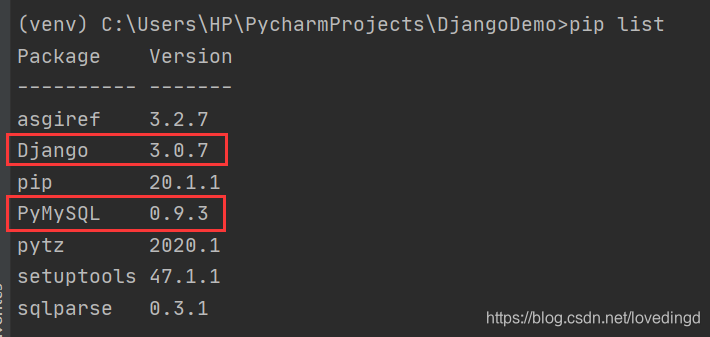
二、在主项目的文件中设置连接
1. 在项目主目录下的init文件中添加下面两句代码
import pymysql # 导入第三方模块,用来操作mysql数据库
pymysql.install_as_MySQLdb()
需要注意的是,如果你import pymysql的时候下面有红线,并且你已经在你使用的python虚拟环境中安装好了pymysql模块,那么你可以重新打开一下你的项目:点击一下 File—> close project ----> 然后再打开你使用的项目,这时import 导入pymysql就不会报错了。
2. 在settings文件中设置数据库连接
DATABASES = {
'default': {
# python自带的一个数据库,基本不会被使用
# 'ENGINE': 'django.db.backends.sqlite3',
# 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'),
# 注册我们自己使用的数据库连接
'ENGINE': 'django.db.backends.mysql', # 数据库引擎
'NAME': 'mydb', #数据库名称
'USER':'admin', # 连接数据库的用户名称
'PASSWORD':'Root110qwe', # 用户密码
'HOST':'192.168.152.154', # 访问的数据库的主机的ip地址
'PORT':'3306', # 默认mysql访问端口
}
}
需要注意的是,host需要写成你的数据库所在的主机或虚拟机的ip地址,如果是在本机上或者是virtualbox中设置了端口转发可以使用127.0.0.1即可。
三、创建数据库模型类
1. 创建模型类(找到你需要使用模型的项目中的任意app的目录下的models文件)
from django.db import models
# Create your models here.
# 创建模型类
class Meishi(models.Model):
id = models.AutoField(primary_key=True) # 该字段可以不写,它会自动补全
food_name = models.CharField(max_length=30) # 设置食物名称
food_author = models.CharField(max_length=8) # 设置食物制作人
food_money = models.FloatField() # 设置食物价格
food_star = models.CharField(max_length=10,default='普通') # 设置食物美味程度
def __str__(self): # 重写直接输出类的方法
return "<Meishi:{id=%s,food_name=%s,food_author=%s,food_money=%s,food_star=%s}>"\
%(self.id,self.food_name,self.food_author,self.food_money,self.food_star)
2. 将我们创建好的模型类映射到数据库
a:
直接在命令行执行命令 : python manage.py makemigrations 或 python manage.py makemigrations app_name
可以指定你的项目中的app的名字;也可以不指定,直接映射该项目中全部的app中的表模型
b:
在pycharm中运行 Run manage.py Task 然后输人makemigrations 或 makemigrations app_name 同上面的效果是一样的
3. 将我们映射的数据表真正在数据库中创建的对应的表
a:
直接在命令行执行命令 : python manage.py migrate 或 python manage.py migrate app_name
可以指定你的项目中的app的名字;也可以不指定,直接创建项目中所有app下映射好的表
b:
在pycharm中运行 Run manage.py Task 然后输人migrate 或 migrate app_name 同上面的效果是一样的
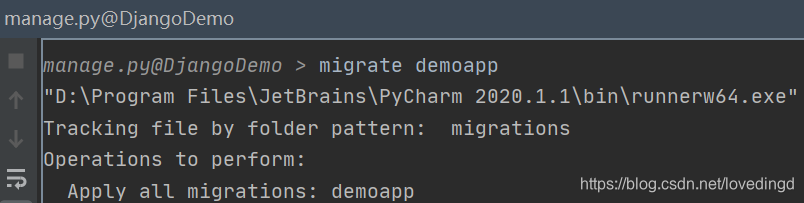
现在我们在数据库中就可以看到我们创建的表了,效果图如下:
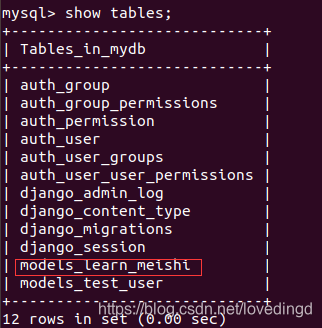
数据库中创建的表的名称是以项目中app的名称+我们自己创建的表的模型类的类名组合成的。
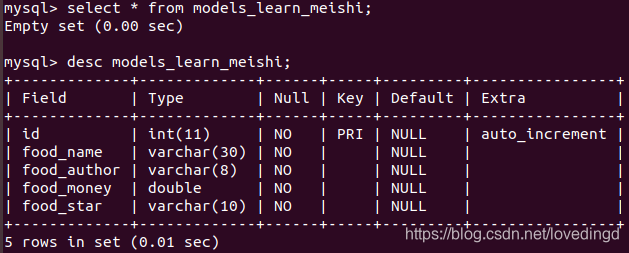
可以通过desc 表名的命令查看表结构就是我们在模型类中设置的表结构:
四、创建好对数据库增删改查的视图渲染方法
1. 在项目使用的app目录下的views.py文件中写增删改查的方法
from django.shortcuts import render # 可以用来返回我们渲染的html文件
from django.http import HttpResponse # 可以返回渲染的页面
from .models import Meishi # 导入我们的模型类
# Create your views here.
# 添加数据方法
def add_food(request):
# 第一种方式插入数据
tcpg = Meishi(food_name='糖醋排骨',food_author='一一',food_money=25,food_star='美味')
tcpg.save() # 一定要记得保存,不然数据无法插入进去
# 第二种方式插入数据
lzj = Meishi()
lzj.food_name = '辣子鸡'
lzj.food_author = '张三'
lzj.food_money = '30'
lzj.food_star = '超级美味'
lzj.save() # 一定要记得保存,不然数据无法插入进去
# 第三种方式插入数据(该方法不需要保存,会自动保存)
sltds = Meishi.objects.create(food_name='酸辣土豆丝',food_author='一一',food_money=25,food_star='美味')
# 第四种方式插入数据(该方法不需要保存,且不会插入重复数据)
clbc = Meishi.objects.get_or_create(food_name='醋溜白菜',food_author='李四',food_money=25,food_star='很美味')
return HttpResponse("添加数据成功")
# 查询数据方法
def select_food(request):
# 查询表中的所有数据
rs = Meishi.objects.all()
print(rs)
# 根据筛选条件查询出表中的单挑数据(注意如果条件查询出多条数据,使用该语句会报错)
rs1 = Meishi.objects.get(food_name='醋溜白菜')
print(rs1)
# 根据筛选条件查询出表中的数据(可查询出多条)
rs2 = Meishi.objects.filter(food_author="一一")
rs2 = list(rs2)
print(rs2)
return HttpResponse("查询数据成功")
# 更新数据方法
def update_food(request):
# 根据条件查询后再修改再保存
clbc = Meishi.objects.get(food_name='醋溜白菜')
clbc.food_star = '难吃'
clbc.save()
# 直接修改所有的数据
Meishi.objects.all().update(food_star='美味')
return HttpResponse("修改数据成功")
# 删除数据方法
def delete_food(request):
Meishi.objects.get(id=1).delete()
return HttpResponse("删除数据成功")
2. 在项目中对应app下的urls文件中配置对应的路由
from django.urls import path,include # path设置我们的路由,include可以设置我们的分路由
from . import views # 将我们写好的views文件导入
urlpatterns = [ # 我们这个app的所有路由都会写在这个文件下
path("add_food/",views.add_food),
path("select_food/",views.select_food),
path("update_food/",views.update_food),
path("delete_food/",views.delete_food),
]
五、前端显示
这个时候我们通过我们设置的路由即可对数据库中的表进行增删改查操作:
http://127.0.0.1:8000/add_food/
http://127.0.0.1:8000/select_food/
http://127.0.0.1:8000/update_food/
http://127.0.0.1:8000/delete_food/
智能推荐
stm32与Freertos入门(一)_单片机rtos系统-程序员宅基地
文章浏览阅读311次。传统的单片机开发都属于裸机开发,就是程序都在一个大循环内执行处理。但是对于一些复杂的项目,功能较多的项目,裸机开发就很吃力,这时候就需要操作系统来进行多任务执行处理。本文就是通过Freertos入门的讲解来对操作系统有个基本认识。_单片机rtos系统
android实战开发-天气预报PPT,android软件开发实例-程序员宅基地
文章浏览阅读787次,点赞15次,收藏17次。学习技术需要结合项目进行训练,在Android里面最常用的架构无外乎 MVC,MVP,MVVM,但是这些思想如果和模块化,层次化,组件化混和在一起,就不是一件这么简单的事情了,我们需要学习更多的Android开发知识才能知道其中蕴含的深理。不能一直停留在基本api的使用上,应该往更深层次的方向去研究,例如activity、view的内部运行机制、Android的内存优化、JNI等,除了能灵活运用,更应该能通过阅读源码而理解其实现原理。写日志是我们日常学习的一种记录方式,写日志其实是对知识体系的回顾与总结。
elasticsearch RangeFilter实例-实现时间范围过滤-程序员宅基地
文章浏览阅读2.1k次。2019独角兽企业重金招聘Python工程师标准>>> ..._es时间过滤
python学习笔记(四)【随机数、运算符(算术运算、比较运算、赋值运算、逻辑运算、位运算、成员运算、身份运算)】_产生随机数并进行比较 用python-程序员宅基地
文章浏览阅读305次。主要内容1.随机数2.比较运算符3.赋值运算符4.逻辑运算符5.位运算符6.成员运算符7.身份运算符一、随机数注:iter:可迭代对象,即列表、元组、range()、str、dict(返回的是值,而不是键)1.random.choice(iter):从可迭代对象中挑选一个元素2.random.randrange(start,end,step):star:从start..._产生随机数并进行比较 用python
快速解决ERROR: Exception: Traceback (most recent call last)的办法-程序员宅基地
文章浏览阅读9.5k次,点赞5次,收藏6次。在新电脑上使用cmd的pip安装python第三方库selenium时候,遇到了ERROR: Exception: Traceback (most recent call last)的问题,搞了好久,最后解决了。解决方法非常简单,就是开手机热点。原本是用的家里千兆网线,cmd下载速度非常低,而且出错之前就是进度条卡顿不动,然后报错。最后开了wifi后解决了问题,而且速度比有线网要快些。..._error: exception: traceback (most recent call last):
NSURLSession VS NSURLConnection_nsurlconnection vs nsurlsession-程序员宅基地
文章浏览阅读275次。NSURLSession VS NSURLConnection NSURLSession可以看做是NSURLConnection的进化版,其对NSURLConnection的改进点有: * 根据每个Session做配置(http header,Cache,Cookie,protocal,Credential),不再在整个App层面共享配置.* 支持网络操作的取消和断点续传* 改进了_nsurlconnection vs nsurlsession
随便推点
测试flink实时流系列(二):搭建DataGen数据生成节点服务器(Hadoop + HiBench)_在cdh datagen-程序员宅基地
文章浏览阅读500次。一、在服务器节点安装及运行Hadoop安装和运行单节点Hadoop请参考:搭建Hadoop(v2.7.1)单节点伪模式, 集群(2 节点)及 集群(5 节点)二、在服务器节点安装运行HiBench下载HiBench-7.0,解压后进入HiBench-7.0,修改conf/目录下相应的配置文件:1. 修改hadoop.conf配置文件重点关注参数hibench.hadoop.ho..._在cdh datagen
net面试问答(大汇总)-程序员宅基地
文章浏览阅读849次。用.net做B/S结构的系统,您是用几层结构来开发,每一层之间的关系以及为什么要这样分层? 答:从下至上分别为:数据访问层、业务逻辑层(又或成为领域层)、表示层 数据访问层:有时候也称为是持久层,其功能主要是负责数据库的访问 业务逻辑层:是整个系统的核心,它与这个系统的业务(领域)有关 表示层:是系统的UI部分,负责使用者与整个系统的交互。 优点: 分工明确,条理清晰,
10天学会flutter DAY4 玩转 dart 中的 运算符,android个人信息界面设计-程序员宅基地
文章浏览阅读537次,点赞22次,收藏18次。包含了腾讯、百度、小米、阿里、乐视、美团、58、猎豹、360、新浪、搜狐等一线互联网公司面试被问到的题目。只要是程序员,不管是Java还是Android,如果不去阅读源码,只看API文档,那就只是停留于皮毛,这对我们知识体系的建立和完备以及实战技术的提升都是不利的。返回对 x 调用 == 方法的结果,参数为 y。详情请查阅 操作符。仅当你确定这个对象是该类型的时候,你才可以使用 as 操作符可以把对象转换为特定的类型。真正最能锻炼能力的便是直接去阅读源码,不仅限于阅读各大系统源码,还包括各种优秀的开源库。
Debug | ‘wget‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件。_wget' 不是内部或外部命令,也不是可运行的程序-程序员宅基地
文章浏览阅读2.6w次,点赞59次,收藏82次。报错信息'wget' 不是内部或外部命令,也不是可运行的程序 或批处理文件。分析在jupyter notebook使用!wget遇到了这个问题,查到发现wget是linux系统下,windows不自带。解决方法去wget官网下载,选择32位/64位,下载ZIP/EXE,将下载下来的EXE文件放到C:\Windows\System32即可。叨下后续:由于我用的是jupyter notebook。虽然windows的cmd可以用了,但是不能直接在jupyter cell里面使用!wget首先要说_wget' 不是内部或外部命令,也不是可运行的程序
uniGUI用Grid++Report报表插件设计保存报表(For unigui ver:0.95.0.1045)_unigui gridreport-程序员宅基地
文章浏览阅读6k次。object MainForm: TMainForm Left = 0 Top = 0 ClientHeight = 369 ClientWidth = 598 Caption = 'uniGUI'#20013'Grid++Report'#35774#35745#24182#20445#23384#25253#34920#27169#26495 Color = clBtnF_unigui gridreport
海康威视Java实习面试_海康威视 面经 java-程序员宅基地
文章浏览阅读5.2k次,点赞5次,收藏41次。海康威视Java实习面试自我介绍技术问题画一下java集合图谱介绍一下spring中的AOPmybatis和hibernate的区别与优劣redis有哪些数据类型手写一个单例模式用到的技术栈非技术问题为什么要用你,你与其他竞争者比较优势是什么你有什么想问我的如果公司需要你加班你有问题吗更多文章欢迎访问个人博客 www.herobin.top面试时间:20min自我介绍技术问题画一下jav..._海康威视 面经 java