Dubbo 序列化-程序员宅基地
前言
大家好,今天开始给大家分享 — Dubbo 专题之 Dubbo 序列化。在前一个章节中我们介绍了 Dubbo 路由规则之标签路由,其实现原理为:如果消费端传递标签则和配置的动态规则和静态规则进行匹配,如果消费端未传递标签则使用服务提供端的本地配置的静态标签和动态配置标签进行匹配。同时我们也例举了常见的使用场景并且进行了源码解析来分析其实现原理。有的小伙伴可以想知道 Dubbo 中远程调用数据传输是通过哪些方式进行数据的序列化呢?那么这个章节我们一起来讨论在我们的 Dubbo 中有哪些序列化方式以及性能表现如何。下面就让我们快速开始吧!
1. 序列化简介
首先我们得明白什么是序列化和反序列化,举个简单的例子:当我们需要把一个数据对象写入到文件或者在网络中传输时,就要把数据对象进行转换为二进制格式进行数据传输这个过程就叫做序列化,反之如果一个远程数据或本地文件数据需要读取并解析为我们的对象时就叫做反序列化。在 Dubbo RPC 中,同时支持多种序列化方式:
-
Dubbo 序列化:阿里尚未开发成熟的高效 Java 序列化实现,阿里不建议在生产环境使用它
-
Hessian2 序列化:Hessian 是一种跨语言的高效二进制序列化方式。但这里实际不是原生的 Hessian2 序列化,而是阿里修改过的Hessian Lite,它是 Dubbo RPC 默认启用的序列化方式
-
Json 序列化:目前有两种实现,一种是采用的阿里的 Fastjson 库,另一种是采用 Dubbo中自己实现的简单 Json库,但其实现都不是特别成熟,而且 Json 这种文本序列化性能一般不如上面两种二进制序列化。
-
Java 序列化:主要是采用 JDK 自带的 Java 序列化实现,性能很不理想。
下图是当前2.7.x版本中支持的序列化方式:
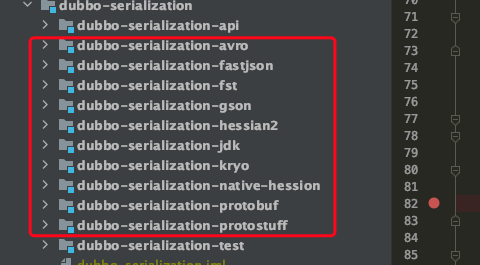
Dubbo RPC 默认采用 Hessian2 序列化。但 Hessian 是一个比较老的序列化实现了,而且它是跨语言的,所以不是单独针对 Java 进行优化的。而 Dubbo RPC实际上完全是一种 Java to Java 的远程调用,其实没有必要采用跨语言的序列化方式。最近几年,各种新的高效序列化方式层出不穷,不断刷新序列化性能的上限,最典型的包括:
-
专门针对Java语言的:Kryo、FST等等
-
跨语言的:Protostuff、ProtoBuf、Thrift、Avro、MsgPack等等
其中,Kryo 是一种非常成熟的序列化实现,已经在Twitter、Groupon、Yahoo以及多个著名开源项目(如Hive、Storm)中广泛的使用。而FST是一种较新的序列化实现,目前还缺乏足够多的成熟使用案例。
2. 配置方式
下面我们主要通过 XML 方式进行配置介绍:
XML 方式
<dubbo:protocol name="dubbo" serialization="hession2"/>
这里使用serialization来进行序列化方式配置。
3. 使用场景
根据前面的介绍我们大概理解了什么是序列化和反序列化,而序列化和反序列化在 Dubbo 中是必须的,那么 Dubbo 中提供了多种序列化方式我们应该使用哪一种序列化方式呢?我们先看一个来自官网的性能测试图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LFQBI7oR-1622043912093)(http://youngitman.tech/wp-content/uploads/2021/05/idea-9.png)]
从上图可以看出序列化方式:kyro、FST 性能最优。如果被序列化的类中不包含无参的构造函数,则在 Kryo 的序列化中,性能将会大打折扣,因为此时我们在底层将用 Java 的序列化来透明的取代 Kryo 序列化。所以,尽可能为每一个被序列化的类添加无参构造函数是一种最佳实践。另外,Kryo 和 FST 本来都不需要被序列化都类实现 Serializable 接口,但我们还是建议每个被序列化类都去实现它,因为这样可以保持和 Java 序列化以及 Dubbo 序列化的兼容性。
4. 示例演示
下面我以获取图书列表为例进行演示。项目结构如下:
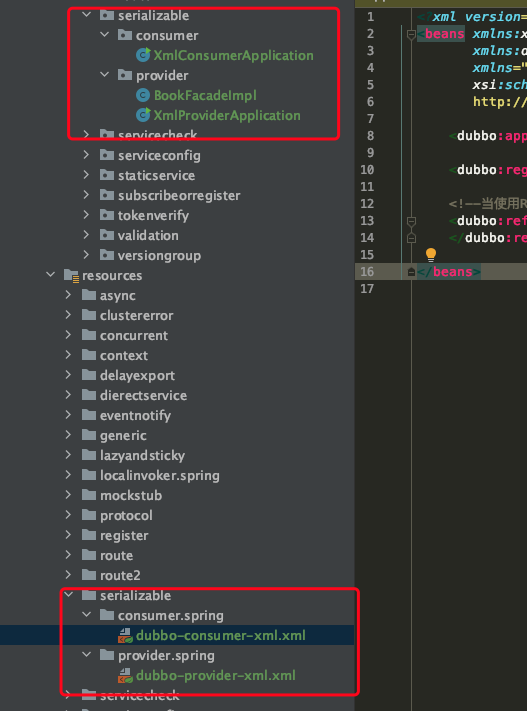
我们主要看服务提供者端的dubbo-provider-xml.xml的 XML 配置 :
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://dubbo.apache.org/schema/dubbo"
xmlns="http://www.springframework.org/schema/beans"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://dubbo.apache.org/schema/dubbo http://dubbo.apache.org/schema/dubbo/dubbo.xsd">
<!--自定序列化方式为:hession2 -->
<dubbo:protocol port="20880" serialization="hession2"/>
<dubbo:application name="demo-provider" metadata-type="remote"/>
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<bean id="bookFacade" class="com.muke.dubbocourse.serializable.provider.BookFacadeImpl"/>
<!--暴露服务为Dubbo服务-->
<dubbo:service interface="com.muke.dubbocourse.common.api.BookFacade" ref="bookFacade" />
</beans>
上面的配置文件中指定序列化方式为hession2。
5. 实现原理
下面我们通过源码的方式简单的分析它们的实现原理。下面我们直接到序列化的核心类org.apache.dubbo.remoting.transport.CodecSupport我们看其中的反序列化方法deserialize:
public static ObjectInput deserialize(URL url, InputStream is, byte proto) throws IOException {
//获取序列化对象
Serialization s = getSerialization(url, proto);
return s.deserialize(url, is);
}
我们继续看看getSerialization方法:
public static Serialization getSerialization(URL url, Byte id) throws IOException {
//通过协议查找Serialization对象
Serialization serialization = getSerializationById(id);
String serializationName = url.getParameter(Constants.SERIALIZATION_KEY, Constants.DEFAULT_REMOTING_SERIALIZATION);
//...
return serialization;
}
上面查找通过 SPI 注册的所有序列化方式。我们接着deserialize方法看,这里我们以 Java JDK 提供的序列化方式为例:
public ObjectInput deserialize(URL url, InputStream is) throws IOException {
return new JavaObjectInput(is);
}
可以看到这了通过 JDK 提供的 JavaObjectInput 对象包装数据流。 其他的序列化方式也是类似,小伙伴可以自行分析。
6. 小结
在本小节中我们主要学习了 Dubbo 序列化,同时我们也分析了 Dubbo 中序列化的实现原理。其底层的实现原理就是利用我们的序列化和反序列化框架对数据对象进行操作,同时我们也介绍了当前针对 Java 序列化性能比较高的两种方式,分别是:Kryo 和 FST。
本节课程的重点如下:
-
理解 Dubbo 序列化和反序列化
-
了解了序列化使用方式
-
了解序列化框架性能
-
了解序列化实现原理
作者
个人从事金融行业,就职过易极付、思建科技、某网约车平台等重庆一流技术团队,目前就职于某银行负责统一支付系统建设。自身对金融行业有强烈的爱好。同时也实践大数据、数据存储、自动化集成和部署、分布式微服务、响应式编程、人工智能等领域。同时也热衷于技术分享创立公众号和博客站点对知识体系进行分享。关注公众号:青年IT男 获取最新技术文章推送!
博客地址: http://youngitman.tech
微信公众号:

智能推荐
最强Android入门开发指南,帮你打通Android的任督二脉_android 开发指南-程序员宅基地
文章浏览阅读687次。Android 新手想要入门,很容易会遇到各类困难和学习瓶颈。没有一个好学的学习方向,学习规划,学习教程,这都是新手会面临的问题。 很多人会在百度上搜索,查阅相关资料。但是网上搜索的很多资料,都是断片式的学习,缺乏完整性和系统性。那么新手应该从何学起?这样学习呢?这里给大家一份最强Android入门指南:_android 开发指南
PHP程序运行流程:词法分析(Lexing,Tokenizing,Scanning)_phpscanning-程序员宅基地
文章浏览阅读1k次。在不开启 Opcache 的情况下,PHP解释器在解释PHP脚本的时候,首先会经过词法分析(Lexing),而词法分析的具体实现就是将PHP代码转换成 Tokens,此过程成为 Lexing / Tokenizing / Scanning 。那么 Tokens 是啥样的呢,Lex就是一个词法分析的依据表。 Zend/zend_language_scanner.c会根据Zend/zend_language_scanner.l (Lex文件),来输入的 PHP代码进行词法分析,从而得到一个一个的“词”,PHP_phpscanning
编程语言数值型和字符型数据的概念_数值 字符-程序员宅基地
文章浏览阅读1.7k次。在编程语言中区分变量的数据类型;最简单的是数值型和字符型;以SQL为例;新建一个表如下图;name列是字符型,age列是数值型;保存表名为pp;录入如下图的数据;看这里name列输入的‘123’、'789',这些是字符型的数据;age输入的内容是数值型;显示结果如下;因为age列是数值型,输入的 009 自动变为了 9;写查询语句时字符型数据按语法规则是用引号括起来;如果如下图写也可以运行出结果;是因为sqlserver本身具有一定的智能识别功能;写比较长的SQL语句_数值 字符
Caffe2 Tutorials[0](转)-程序员宅基地
文章浏览阅读558次。Caffe2 Tutorials[0](转)https://github.com/wizardforcel/data-science-notebook/blob/master/dl/more/caffe2-tut.md本系列教程包括9个小节,对应Caffe2官网的前9个教程,第10个教程讲的是在安卓下用SqueezeNet进行物体检测,此处不再翻译。另外由于栏主不关注RNN和LS..._writer.add_scalar [enforce fail at pybind_state.cc:221] ws->hasblob(name). c
java学习笔记day09 final、多态、抽象类、接口_} } class a { public void show() { show2(); } publ-程序员宅基地
文章浏览阅读155次。java学习笔记day09思维导图final 、 多态 、 抽象类 、 接口 (都很重要)一、final二、多态多态中的成员访问特点 【P237】多态的好处 【P239]多态的弊端向上转型、向下转型 【P241】形象案例:孔子装爹多态的问题理解: class 孔子爹 { public int age = 40; public void teach() { System.out.println("讲解JavaSE"); } _} } class a { public void show() { show2(); } public void show2() { s
Qt5通信 QByteArray中文字符 出现乱码 解决方法_qbytearray中文乱码-程序员宅基地
文章浏览阅读2.4k次,点赞3次,收藏9次。在写qt网口通信的过程中,遇到中文就乱码。解决方法如下:1.接收端处理中文乱码代码如下 QByteArray-> QString 中文乱码解决: #include <QTextCodec>QByteArray data= tcpSocket->readAll(); QTextCodec *tc = QTextCodec::codecForName("GBK"); QString str = tc->toUnicode(data);//str如果是中文则是中文字符_qbytearray中文乱码
随便推点
kettle 提交数据量_kettle——入门操作(表输出)详细-程序员宅基地
文章浏览阅读820次。表输出控件如下1)步骤名称,2)数据库连接,前面有过部分解释3)目标模式,数据库中的概念,引用:https://www.cnblogs.com/csniper/p/5509620.html(感谢)4)目标表:数据库中的表,这里有两种方式:(1) 应用数据库中已经存在的表,浏览表选中对应表即可,下图有部分sql功能。ddl可以执行ddl语句。(2) 创建新的表,填写表的名字,点击下面的sql就可以执..._kettle 步骤 提交
Sublime 多行编辑快捷键_submlite 同时操作多行 macos-程序员宅基地
文章浏览阅读4.4k次,点赞2次,收藏2次。鼠标选中多行,按下 widows 下 Ctrl Shift L( Mac下 Command Shift L)即可同时编辑这些行;鼠标选中文本,反复按widows 下CTRL D(Mac下 Command D)即可继续向下同时选中下一个相同的文本进行同时编辑;鼠标选中文本,按下Alt F3(Win)或Ctrl Command G(Mac)即可一次性选择全部的相同文本进行同时编辑;..._submlite 同时操作多行 macos
如何双启动Linux和Windows-程序员宅基地
文章浏览阅读252次。尽管Linux是具有广泛硬件和软件支持的出色操作系统,但现实是有时您必须使用Windows,这可能是由于关键应用程序无法在Linux下运行。 幸运的是,双重引导Windows和Linux非常简单-本文将向您展示如何使用Windows 10和Ubuntu 18.04进行设置。 在开始之前,请确保已备份计算机。 尽管双启动设置过程不是很复杂,但是仍然可能发生事故。 因此,请花点时间备份您的重要..._windows linux双启动
【flink番外篇】1、flink的23种常用算子介绍及详细示例(1)- map、flatmap和filter_flink 常用的分类和计算-程序员宅基地
文章浏览阅读1.6w次,点赞25次,收藏20次。本文主要介绍Flink 的3种常用的operator(map、flatmap和filter)及以具体可运行示例进行说明.将集合中的每个元素变成一个或多个元素,并返回扁平化之后的结果。按照指定的条件对集合中的元素进行过滤,过滤出返回true/符合条件的元素。本文主要介绍Flink 的3种常用的operator及以具体可运行示例进行说明。这是最简单的转换之一,其中输入是一个数据流,输出的也是一个数据流。下文中所有示例都是用该maven依赖,除非有特殊说明的情况。中了解更新系统的内容。中了解更新系统的内容。_flink 常用的分类和计算
(转)30 IMP-00019: row rejected due to ORACLE error 12899-程序员宅基地
文章浏览阅读590次。IMP-00019: row rejected due to ORACLE error 12899IMP-00003: ORACLE error 12899 encounteredORA-12899: value too large for column "CRM"."BK_ECS_ORDER_INFO_00413"."POSTSCRIPT" (actual: 895, maximum..._row rejected due to oracle
降低Nginx代理服务器的磁盘IO使用率,提高转发性能_nginx tcp转发 硬盘io-程序员宅基地
文章浏览阅读918次。目前很多Web的项目在部署的时候会采用Nginx做为前端的反向代理服务器,后端会部署很多业务处理服务器,通常情况下Nginx代理服务器部署的还是比较少,而且其以高效性能著称,几万的并发连接处理速度都不在话下。然而去年的时候,我们的线上系统也采用类似的部署结构,同时由于我们的业务需求,Nginx的部署环境在虚拟机上面,复用了其他虚拟机的整体磁盘,在高IO消耗的场景中,我们发现Nginx的磁盘_nginx tcp转发 硬盘io