Transfer Learning Toolkit (TLT) + DeepStream (DS)快速部署深度学习模型(以口罩检测为例)_nvidia transfer learning toolkit-程序员宅基地
技术标签: 机器学习
最近在做一个深度学习的横向,被实时性搞的很头疼,遂打算研究研究新的技术路线,做点技术储备。TLT+DS的中文资料很少,本文以官方资料为基础做了一点整理工作。
简介
TLT
如何快速训练和部署深度学习模型是工业界关注的重点问题,英伟达推出的TLT+DS工具链为训练自有数据集进而进行快速部署提供了端到端的解决方案。
其中,TLT是英伟达迁移学习工具,提供对预训练模型的迁移训练、模型剪纸、量化,的一站式解决方案。文档 指南
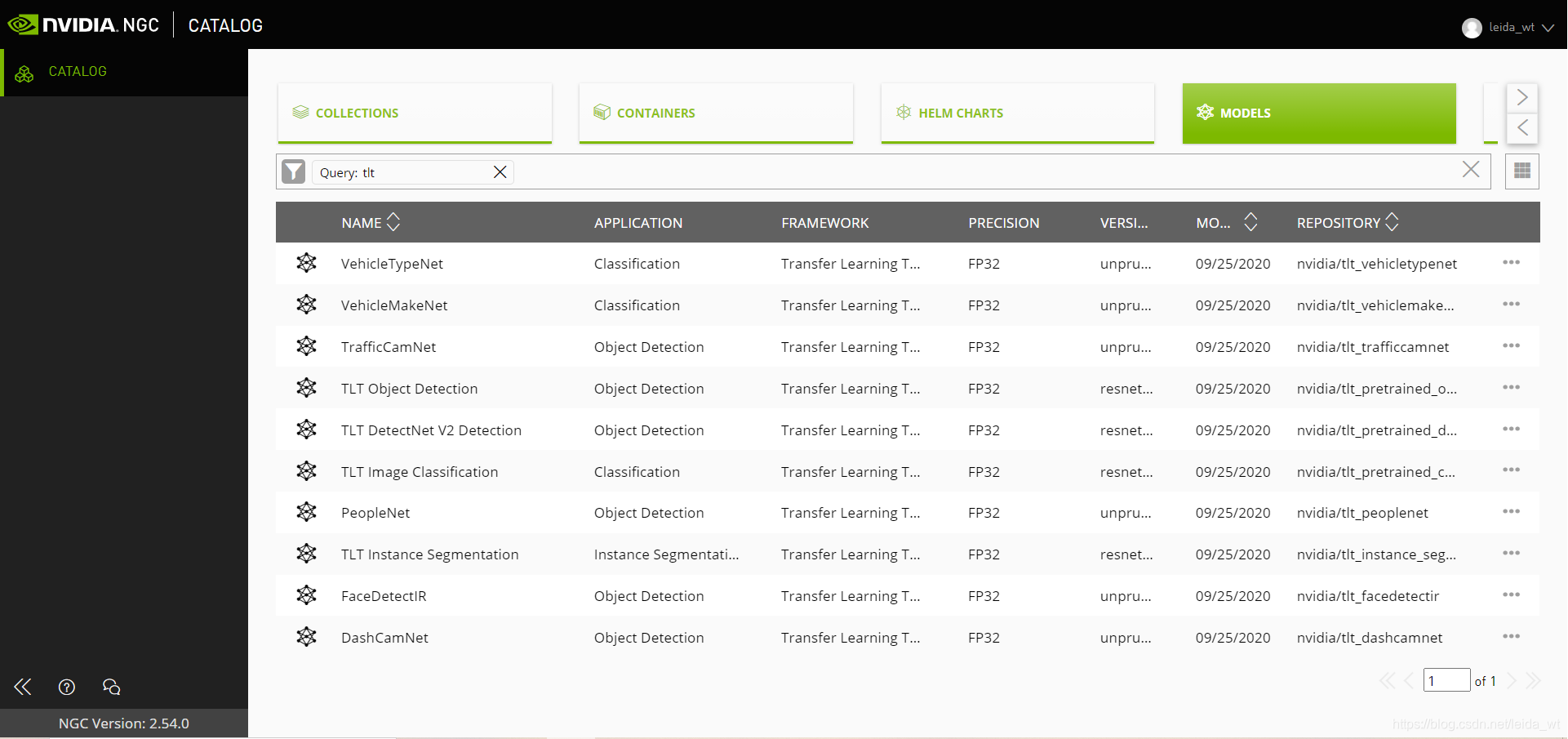
Nvidia在NGC仓库中提供了一组为TLT工具维护的预训练模型,囊括了常见CV任务的经典模型(人脸识别、目标检测、语义分割、人体姿态估计、分类等):
DS
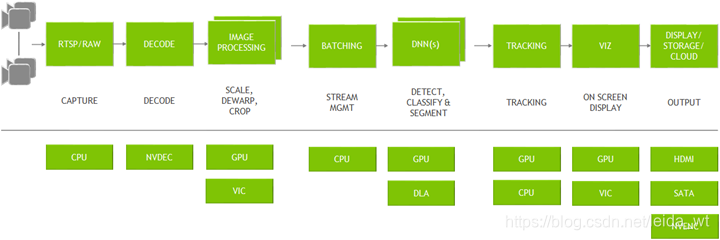
DeepStream(DS)则是一套经高度优化的推理系统,提供完整的检测流水线实现,包含高速编解码器、预处理器、模板跟踪器、TensorRT推理引擎等组件,并配套有完善的可视化、精度校验工具。
- 文档中包含了基本概念的介绍。
- 手册描述了DeepStream的配置方法及其提供的GStreamer插件的输入、输出和控制参数。
- 宣传PPT给出了DS的基本特性和DS配置文件的简要编写方法。
- GStreamer是DeepStream的底层依赖,阅读其文档可以帮助理解DeepStream的相关概念。
- 官方示例:
(1)Creating a Human Pose Estimation Application with NVIDIA DeepStream
(2) Building Intelligent Video Analytics Apps Using NVIDIA DeepStream 5.0 (Updated for GA)
本文主要参照官方提供的口罩检测demo对使用TLT+DS进行深度学习模型训练、部署的方法进行初步探索,并对demo缺少的细节进行补充,修正demo的部分bug,添加部分配置文件。

基于TLT进行迁移学习
环境准备
使用Docker镜像是获取TLT和DS工具的最佳方式。
本文使用的运行环境:
- Ubuntu 18.04
- Docker 19.04
- nvidia-docker(提供GPU的Docker虚拟化支持)
- GTX 2080Ti
首先拉取官方镜像:
# TLT
docker pull nvcr.io/nvidia/tlt-streamanalytics:v2.0_py3
# DeepStream
docker pull nvcr.io/nvidia/deepstream:5.0.1-20.09-samples
2021/3/13注:官方tlt镜像已升级到3.0:链接
注册一个NGC账户,并获取一个API Key,API key将用于访问NGC相关的服务(如预训练模型下载):
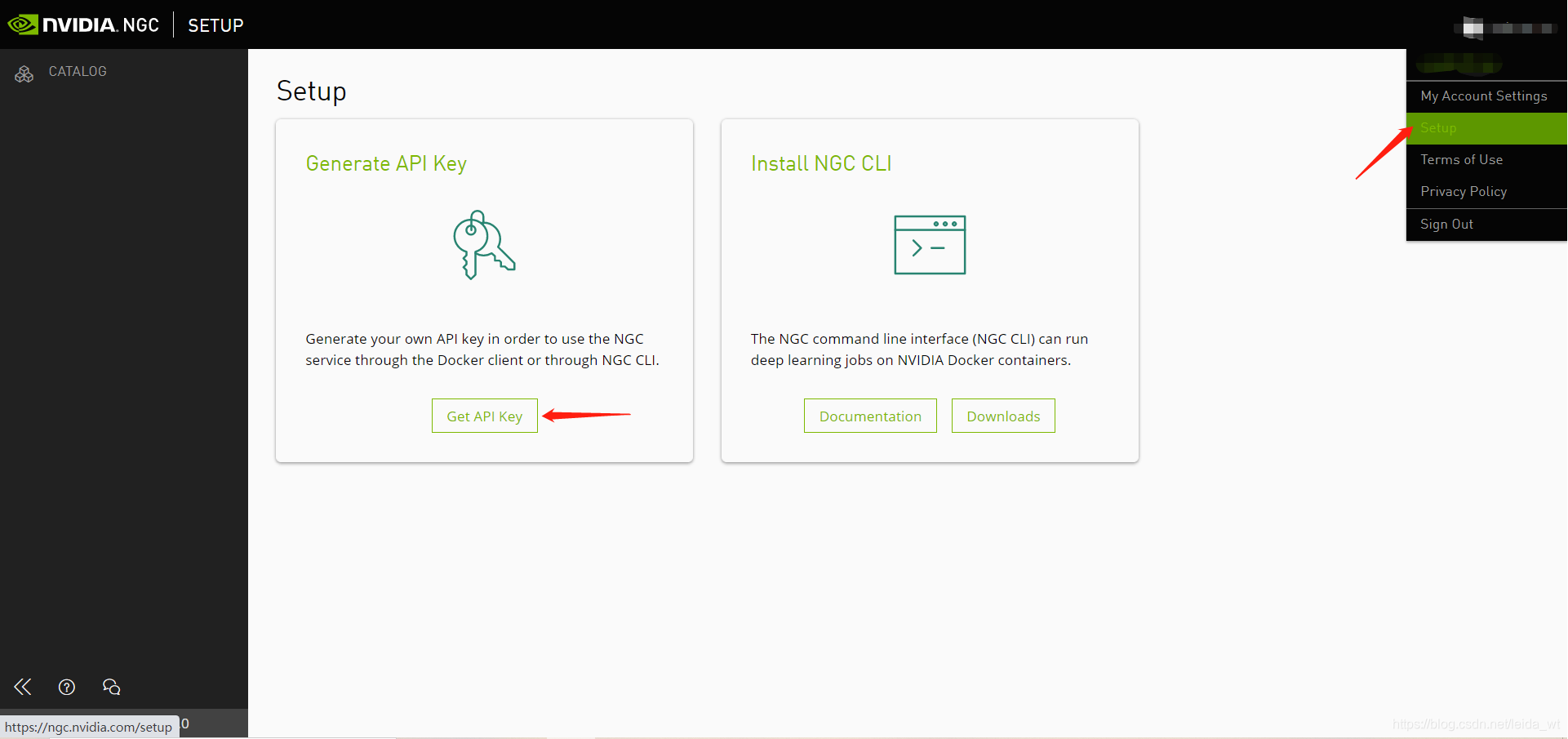
API key仅显示一次,请注意保存,如丢失可以重新生成一个。
为便于陈述,下文使用xxx/tlt-demo指代项目根路径,目录结构如下:
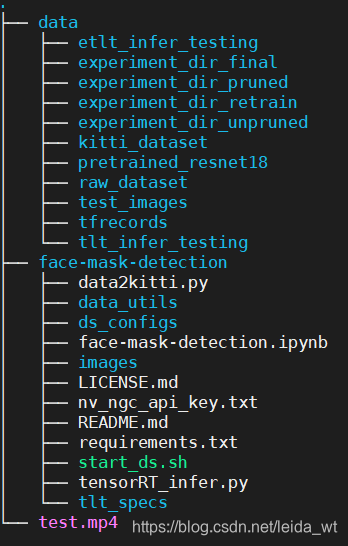
其中原始数据集data/raw_data、代码部分face-mask-detection、最终训练好的模型data/experiment_dir_final和预训练模型data/pretrained_resnet18已经打包上传到网盘,其他文件可通过代码生成。
链接:https://pan.baidu.com/s/1VCp5nPF5NHGtD00GNPmiPA
提取码:7sxb
如已下载上面的文件,则下面git clone 和数据集下载两步可跳过。
拉取demo项目(face-mask-detection)github仓库到xxx/tlt-demo路径
cd xxx/tlt-demo
git clone https://github.com/NVIDIA-AI-IOT/face-mask-detection.git
下载数据集文件,存放到xxx/tlt_demo/data路径下。
face-mask-detection同时使用了四个公共数据集作为训练数据。
模型训练
在启动容器前,先填一下API key,执行:
docker login nvcr.io
填入:
Username: $oauthtoken
Password: 【Your Key】
启动TLT训练容器:
docker run --gpus all --name tlt_train -it -v "xxx/tlt-demo":"/tlt-demo" \
-p 8888:8888 nvcr.io/nvidia/tlt-streamanalytics:v2.0_py3 /bin/bash
参数解释:
- –gpus all 指定使用的GPU
- -v “xxx/tlt-demo”:"/tlt-demo" 映射宿主机文件
- -p 8888:8888 绑定8888端口方便访问jupyter notebook
进入容器后,首先运行数据集转换脚本。
cd /tlt-demo/face-mask-detection
python data2kitti.py --kaggle-dataset-path /tlt-demo/data/raw_dataset/Kaggle-Medical-Mask-Dataset \
--mafa-dataset-path /tlt-demo/data/raw_dataset/MAFA \
--fddb-dataset-path /tlt-demo/data/raw_dataset/FDDB \
--widerface-dataset-path /tlt-demo/data/raw_dataset/WiderFace \
--kitti-base-path /tlt-demo/data/kitti_dataset \
--train
该脚本将四种数据集合并,转换为kitti数据格式,并存放在容器的/tlt-demo/data/kitti_dataset路径(即宿主机xxx/tlt-demo/data/kitti_dataset路径)下。转换中产生的警告可忽略。
对data2kitti.py的补充说明:
用于目标检测的kitti数据集格式具有如下组织结构:
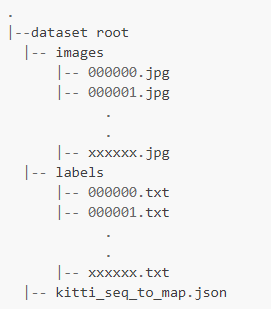
其中kitti_seq_to_map.json文件是可选的,用于描述训练集/测试集的划分。
labels文件中每一行描述一个边界框的信息,具有如下字段:
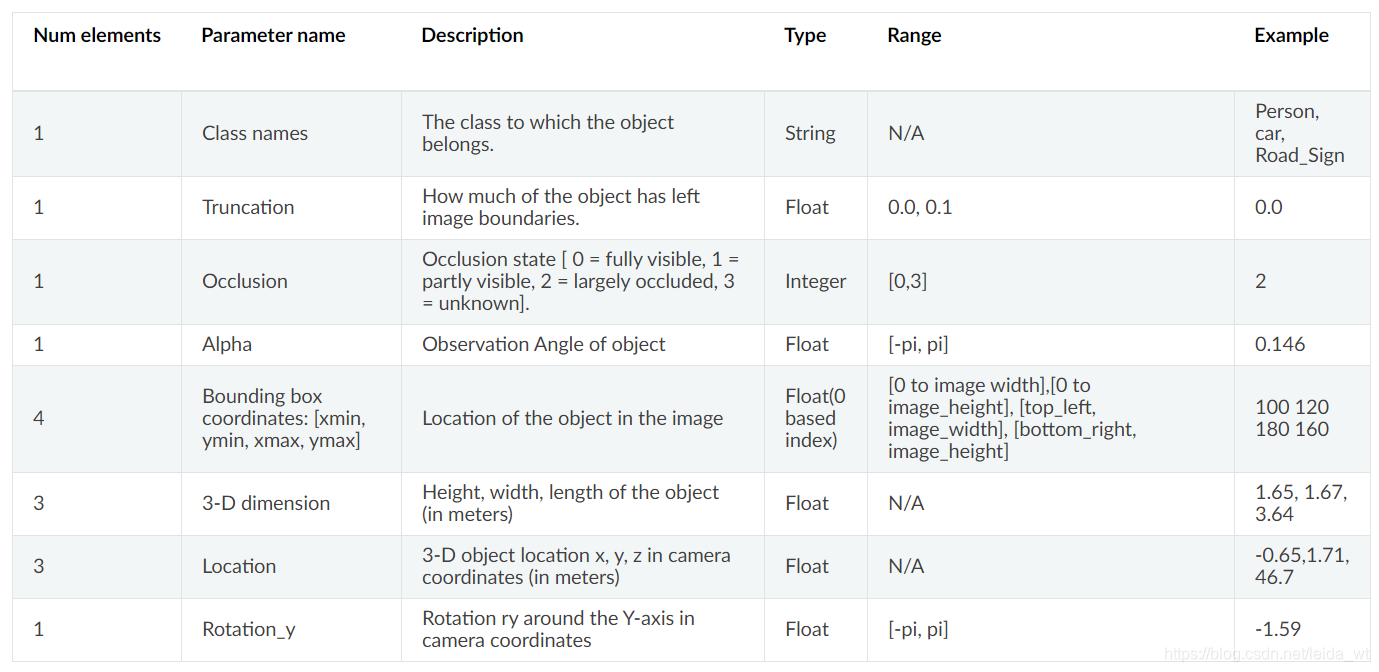
如:
Mask 0 0 0 5 299 121 465 0 0 0 0 0 0 0
No-Mask 0 0 0 386 17 425 53 0 0 0 0 0 0 0
Mask 0 0 0 280 14 336 51 0 0 0 0 0 0 0
No-Mask 0 0 0 544 94 584 132 0 0 0 0 0 0 0
No-Mask 0 0 0 499 121 557 167 0 0 0 0 0 0 0
Mask 0 0 0 633 52 687 104 0 0 0 0 0 0 0
Mask 0 0 0 443 196 508 257 0 0 0 0 0 0 0
在data2kitti.py脚本中,四个数据集的图片被统一resize到(960,544),存储为jpg格式文件。
下一步,启动jupyter-notebook并按照face-mask-detection.ipynb提供的指示进行模型训练,本文网盘中的版本已对face-mask-detection.ipynb的bug进行修正,并补充了一些内容。
jupyter-notebook --ip 0.0.0.0 --no-browser --allow-root
启动后,访问【宿主机ip】:8888即可。其中token可在jupyter-notebook的启动消息中获得。
下面对face-mask-detection.ipynb中的主要步骤进行简要说明和补充。
设置一些环境变量,注意修改路径和KEY:
执行数据集转换和切分:
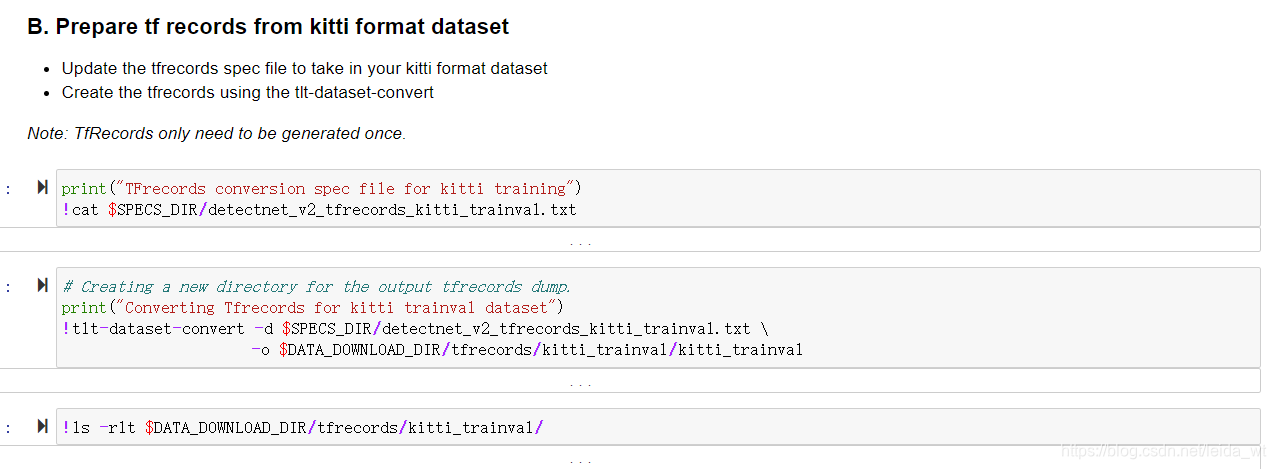
其中使用的配置文件detectnet_v2_tfrecords_kitti_trainval.txt 内容如下:
kitti_config {
root_directory_path: "/tlt-demo/data/kitti_dataset/train/"
image_dir_name: "images"
label_dir_name: "labels"
image_extension: ".jpg"
partition_mode: "random"
num_partitions: 2
val_split: 20
num_shards: 10 }
ref: https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/text/preparing_data_input.html#conversion-to-tfrecords
参数如下:
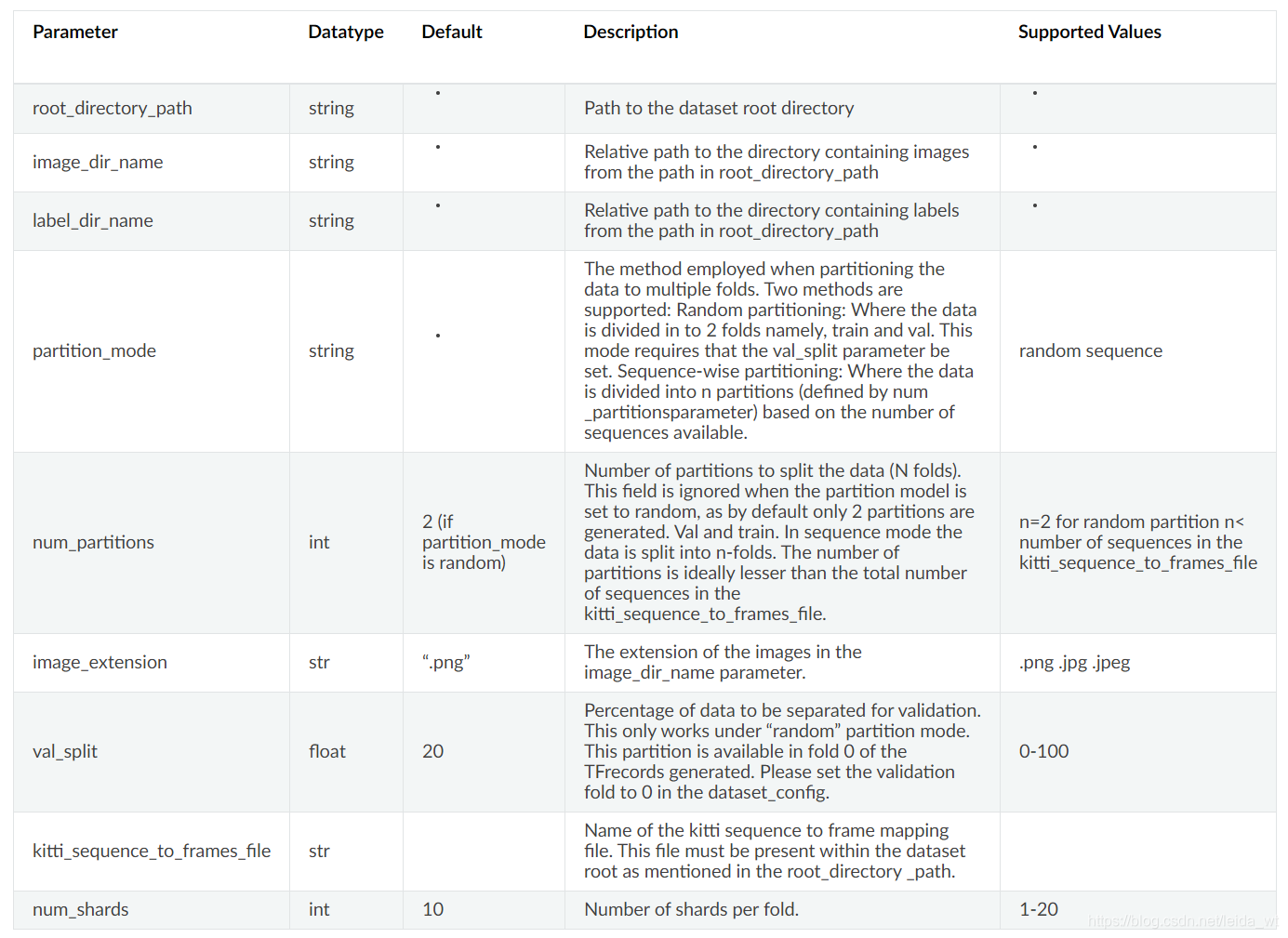
因此在detectnet_v2_tfrecords_kitti_trainval.txt 表示我们以数据集/tlt-demo/data/kitti_dataset/train/为输入,切分20%作为验证集,其余为训练集。
下载与训练模型:
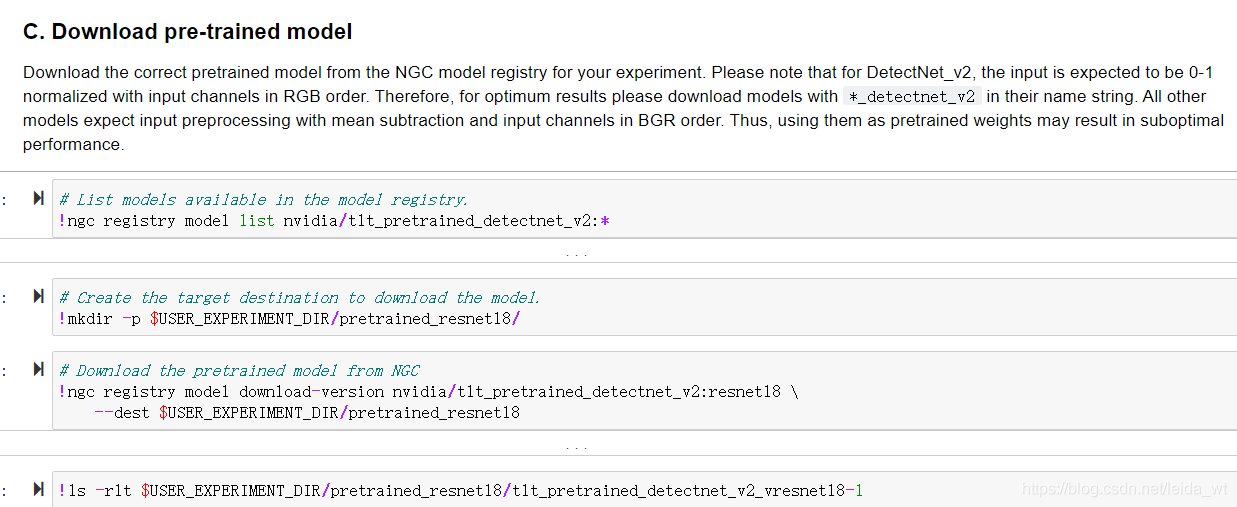
此处使用英伟达的detectnet_v2模型,鉴于数据集不大,任务也比较简单,选用较为精简的resnet18作为骨架网络。
启动训练:

这里对配置文件detectnet_v2_train_resnet18_kitti.txt的内容进行简单解释。
配置文件约定所使用的数据增强方法和训练参数,其参数说明见:
https://docs.nvidia.com/metropolis/TLT/tlt-getting-started-guide/text/creating_experiment_spec.html#specification-file-for-detectnet-v2
我仅修改了路径相关的几行:


笔者使用2块2080Ti训练的用时为1:32:42.382548.
模型剪枝:
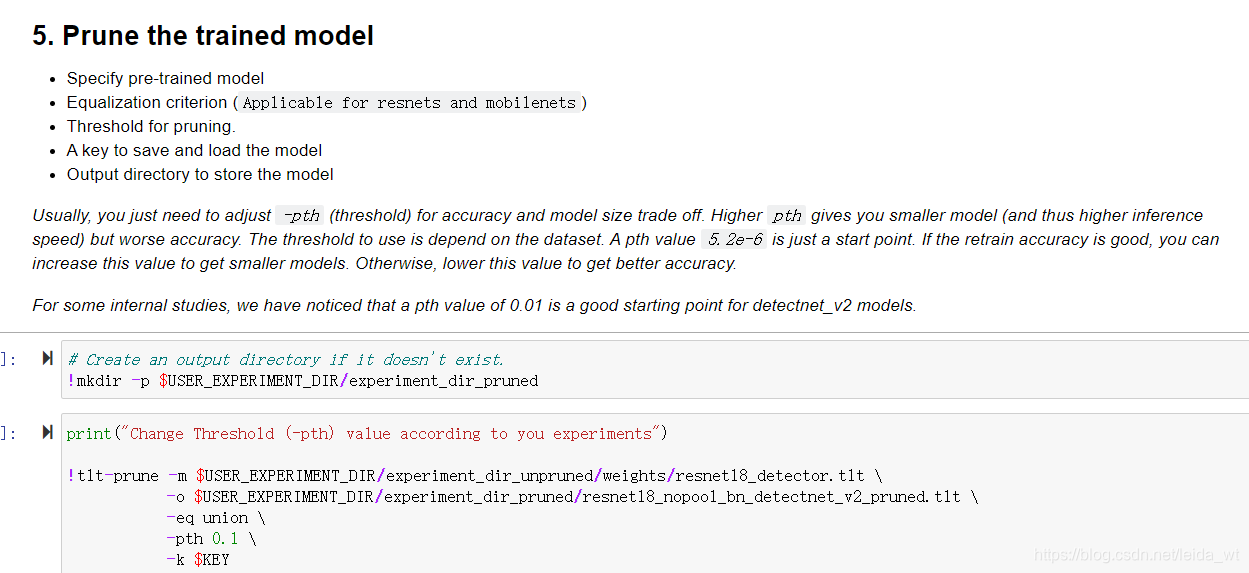
笔者此处设置剪纸阈值为0.1(参数越大,剪的越狠),效果不错,精度没有降低。
剪枝后还需要再重新训一下:
配置文件detectnet_v2_retrain_resnet18_kitti.txt的修改方法和detectnet_v2_train_resnet18_kitti.txt相似。
最终精度是

可视化检查:
在宿主机xxx/tlt-demo/data/test_images路径中放入待检图片。
对test_images中的图片执行推理:
可视化:
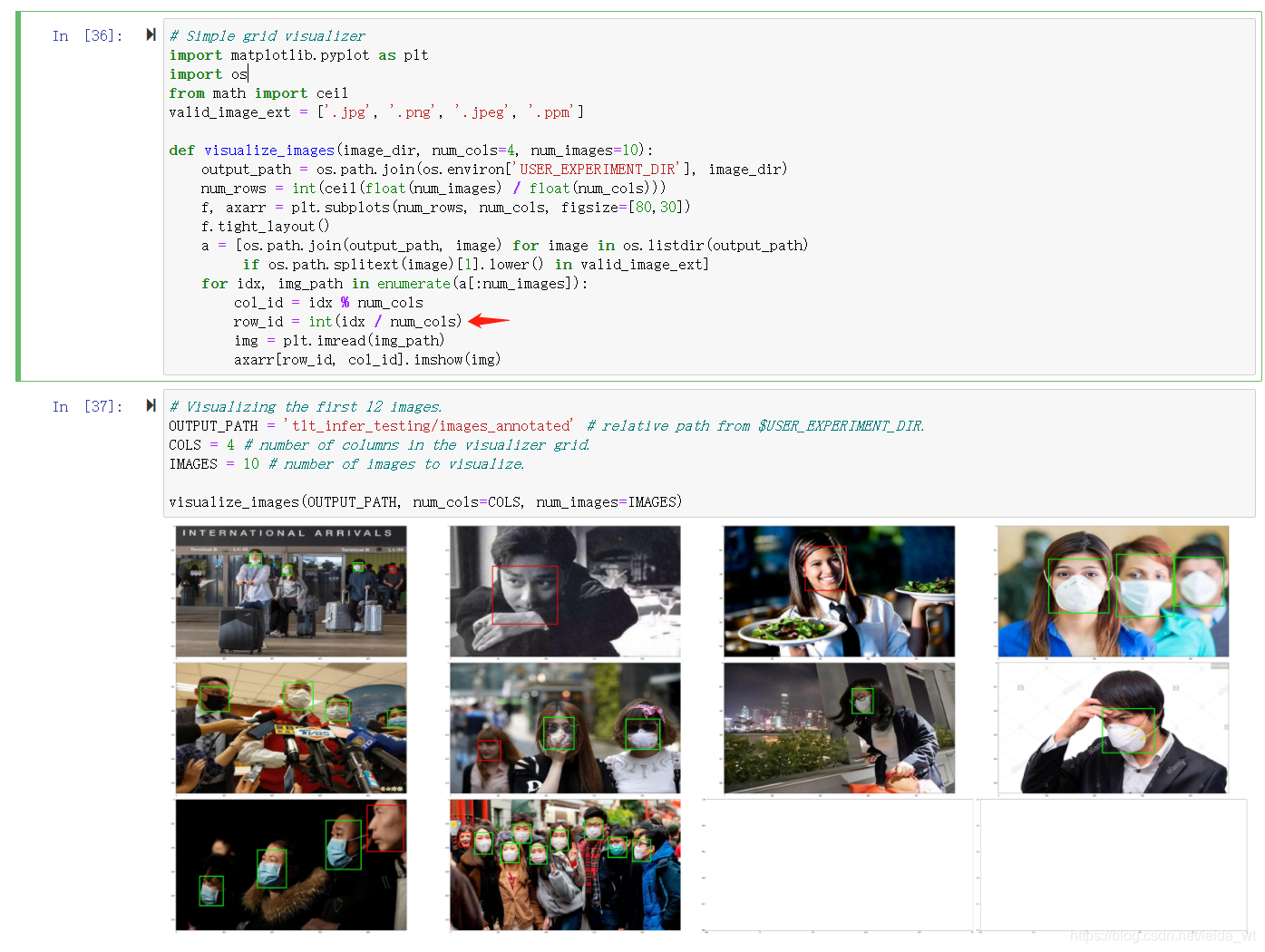
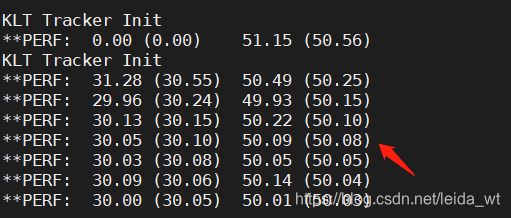
注意在箭头处需加个int修复源程序bug。
可见训练效果非常理想。
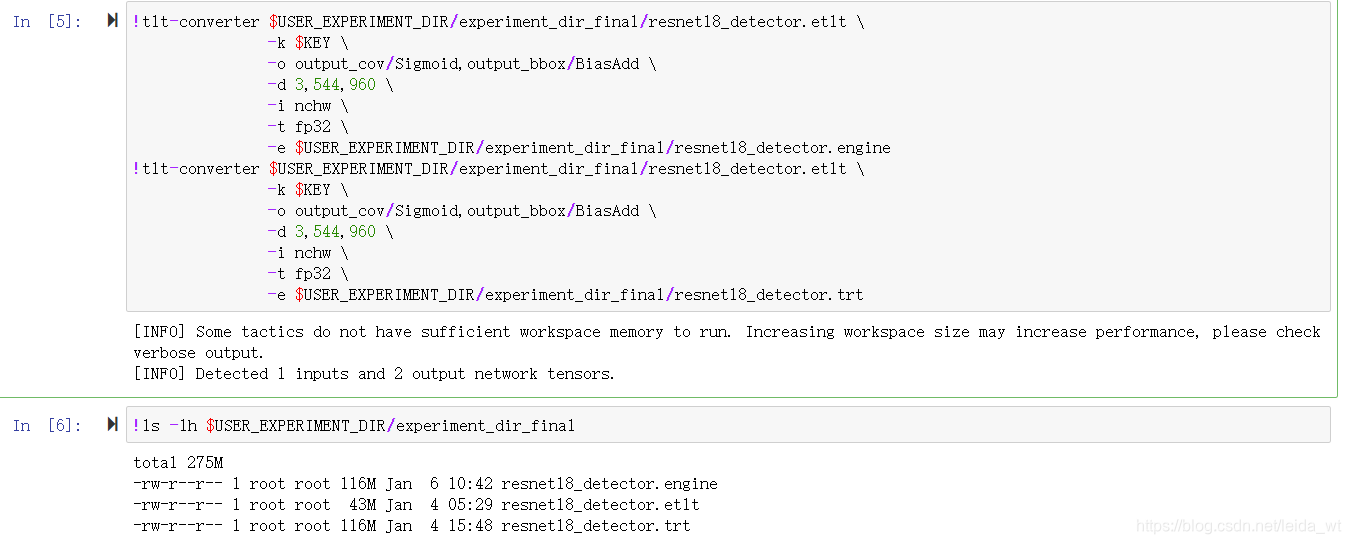
最后,导出模型,格式为etlt,etlt格式可被转换为trt或tensorRT的engine文件,亦可被DeepStream加载并自动转化为所需的trt格式模型。
我们也可进一步将其转换成TensorRT的engine文件:
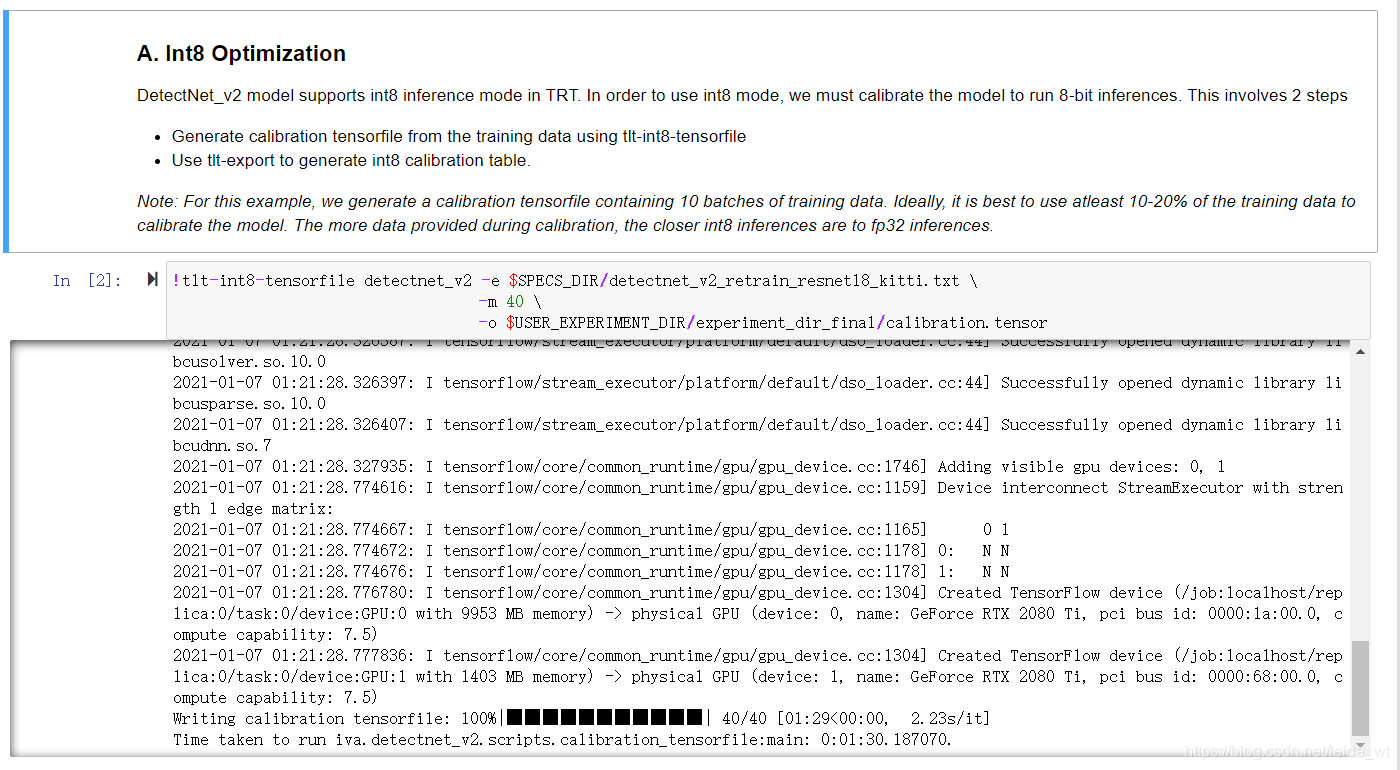
上面导出的模型是Float32类型的,为了追求更快的推理速度,可将Float32类型的模型量化int8模型。为了解决解决参数转换为int8类型后动态范围下降的问题,量化的一个关键步骤是确定float32到int8的量化映射,映射参数是根据模型对数据集的响应进行的,下面的命令抽取40个batch的数据生成calibration tensorfile。
随后我们调用tlt-convert导出int8推理engine:
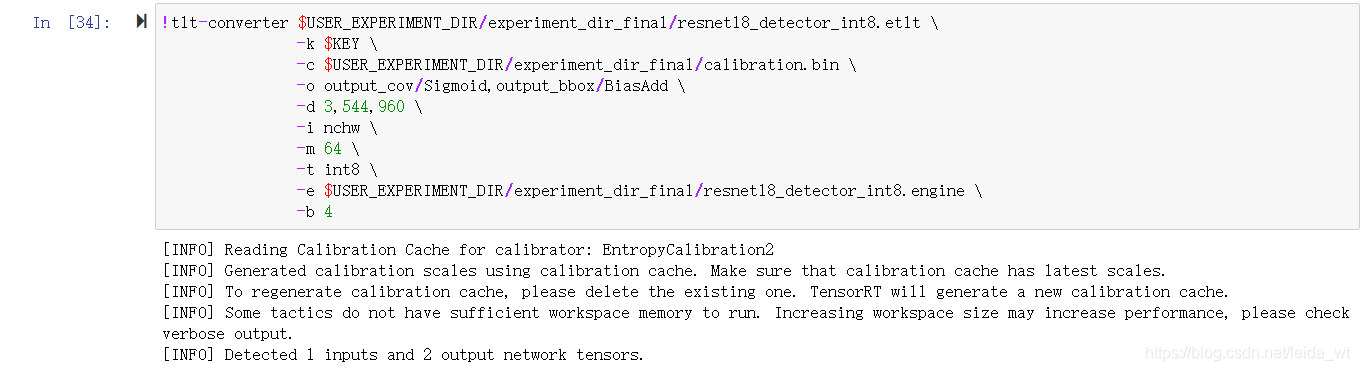
engine文件是平台相关的,比如3080系显卡上执行tlt-convert导出的engine并不能在10系显卡上运行,需注意。Nvidia也提供了不同平台的tlt-convert工具供使用。
至此我们已经得到了如下文件:
- /tlt-demo/data/experiment_dir_unpruned/下存放原始训练模型
- /tlt-demo/data/experiment_dir_pruned/存放经过剪枝的模型
- /tlt-demo/data/experiment_dir_retrain/存放经过再次训练后的剪枝模型
- /tlt-demo/data/experiment_dir_final/存放导出模型,包括原始的resnet18_detector.etlt模型文件和经过int8量化并转化为tensorRT推理引擎的resnet18_detector_int8.engine文件,未经过int8量化但转化为tensorRT推理引擎的resnet18_detector.engine文件。还有保存有int8映射信息的calibration.bin文件。
2021/1/12注:为了查看不同剪枝阈值的影响,对pth=[0.15,0.2,0.25,0.3,0.35,0.45]分别进行了实验:
| pth | mask | no-mask | mean AP |
|---|---|---|---|
| 0.15 | 84.7971 | 81.9967 | 83.3969 |
| 0.2 | 84.8928 | 81.5916 | 83.2422 |
| 0.25 | 83.9029 | 81.9541 | 82.9285 |
| 0.3 | 84.6431 | 82.0092 | 83.3262 |
| 0.35 | 84.9796 | 82.394 | 83.6868 |
| 0.45 | 83.9478 | 81.4966 | 82.7222 |
可见在本例中,对pth的裕度是很大的。但有些模型对pth很敏感,需仔细调整。
下一节将探讨如何在DS框架上部署这些模型。
基于DS的模型部署
DeepStream SDK提供了完整的流分析工具链,可用于基于AI的视频和图像理解以及多传感器处理。
如前所述,DeepStream的相关资料较少,尚未由较为详细的中文技术博客对其进行介绍,DS开发的主要的参考来源是官方文档和例子:
- 文档中包含了基本概念的介绍。
- 手册描述了DeepStream的配置方法及其提供的GStreamer插件的输入、输出和控制参数。
- 宣传PPT给出了DS的基本特性和DS配置文件的简要编写方法。
- python API
- GStreamer是DeepStream的底层依赖,阅读其文档可以帮助理解DeepStream的相关概念。
依旧通过容器运行DeepStream,摆脱繁琐的环境配置工作:
xhost +
docker run --rm --gpus all --name ds_test --device=/dev/video0 -it -p 8554:8554 -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=:0 -v "xxx/tlt-demo":"/tlt-demo" -w /tlt-demo/face-mask-detection/ds_configs nvcr.io/nvidia/deepstream:5.0.1-20.09-samples /bin/bash
其中xhost +用于开放宿主机图形界面的接入权限
参数解释:
- –gpus all 指定容器可见的GPU
- –device=/dev/video0 将摄像头1映射进入容器
- -it -p 8554:8554 映射RTSPStreaming RTSP端口(可选)
- -p 5400:5400/udp 映射RTSPStreaming UDP端口(可选)
- -v /tmp/.X11-unix:/tmp/.X11-unix -e DISPLAY=:0 连接图形界面到宿主机
- -v “xxx/tlt-demo”:"/tlt-demo" 映射宿主机文件夹
- -w /tlt-demo/face-mask-detection/ds_configs 设置进入容器后开启的路径
注意这里使用的是deepstream:5.0.1-20.09-samples版本镜像而非更精简的deepstream:5.0.1-20.09-base,该镜像包含重要的例程文件(deepstream-app)。
进入容器后,我们运行demo写好的配置文件(有改动)。
通过指定的配置文件启动deepstream-app检测程序:
deepstream-app -c deepstream_app_source1_camera_masknet_gpu_int8.txt
这个配置文件以640*480的分辨率,30fps的帧率从/dev/video0这个usb摄像头读入视频流,进行推理,跟踪,并渲染检测结果,最后推送到宿主机的图形界面,同时发送RTSP流。
RTSP是流行的流传输协议,使用VLC,potplayer等视频播放器均可访问,其地址是
rtsp://[容器所在宿主机IP]:8554/ds-test
其他配置文件说明:
- deepstream_app_source1_camera_masknet_gpu_fp32.txt 加载fp32推理模型、摄像头0为输入
- deepstream_app_source1_camera_masknet_gpu_int8.txt 加载int8推理模型、摄像头0为输入
- deepstream_app_source1_video_masknet_gpu_fp32.txt 加载fp32推理模型、/tlt-demo/test.mp4为输入
- deepstream_app_source1_video_masknet_gpu_int8.txt 加载int8推理模型、/tlt-demo/test.mp4为输入
若一切正常,则可通过GUI或视频浏览器看到标注由检测结果的输出视频流,整个检测流水线运行速度很快,显卡的占用率也很低。
下面简要分析一下demo中配置文件的编写方法。
DeepStream的底层是GStreamer,GStreamer是用于创建流媒体应用程序的极其强大且通用的框架。 GStreamer框架的核心优点来自其模块化,视频处理的各个环节均有丰富的插件进行支撑,基于GStreamer进行开发的核心内容就是合理的将各个环节的模块串接为一个处理管线。GStreamer是纯C编写的,底层基于Glib库,并使用G-object提供对C语言的面向对象支持(暗黑科技)。
DeepStream在GStreamer提供的基础模块(如编解码,文件I/O,合成器等)的基础上,又为深度学习的应用场景实现了一组插件:
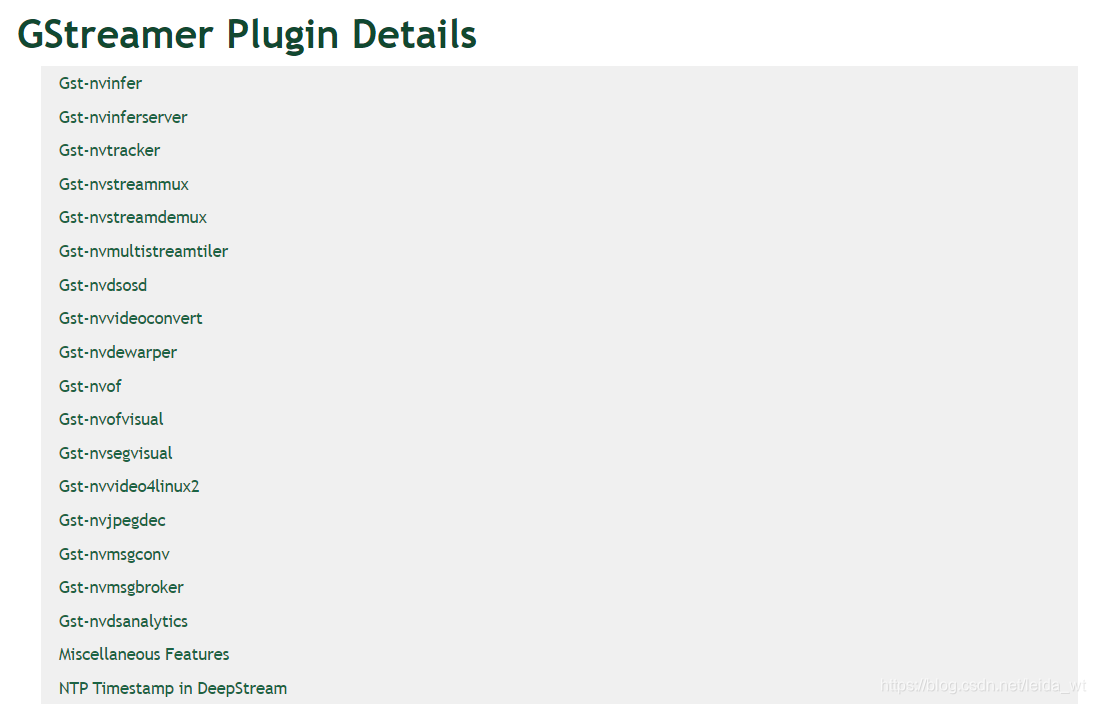
如nvinfer用于支持tensorRT推理,nvtracker用于边界框的跟踪,nvdsosd用于渲染检测结果。
看DS提供的例程是学习DS开发的最佳途径:

其中C语言版本位于容器的如下路径:
/opt/nvidia/deepstream/deepstream-5.0/sources/apps/sample_apps
python语言版本可在这里下载。
更多例程可见这里。
其中一个很重要的例程是deepstream-test5 app。
除常规推理管道外,Test5应用程序还支持以下功能:
- 将消息发送到后端服务器。
- 充当使用者以从后端服务器接收消息。
- 基于从服务器收到的消息触发基于事件的记录。
- OTA模型更新。
除此之外。鉴于通过DS的底层C接口和Python接口构建检测流水线仍有些繁琐,Nvidia针对最常见的深度学习模型处理流程提炼并设计了参考程序deepstream-app,该程序允许用户通过传入配置文件描述检测流水线,deepstream-app会根据配置文件的描述调用相应DS插件,构建流水线。因此,虽然deepstream-app是个参考程序,但常被当做DS的CLI工具使用。
如下是deepstream-app提供的流水线的结构框图,其中很多组件是可选的(如secondary classifiers):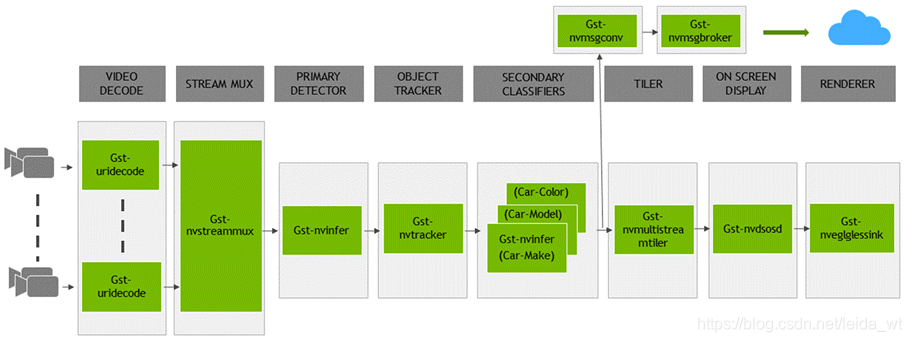
首先,前端使用decode插件读入视频流(来源可以是RTSP、文件、usb摄像头等),多个摄像头经过MUX进行合并,组成batch,送入主检测器(目标检测)获得边界框,随后送入tracker进行跟踪,每个跟踪的边界框继续送入次级检测器(一般是分类器),检测结果发送到tilter形成2D帧数组,进而用osd插件渲染检测结果。最后,要输出结果(sink),DeepStream提供了各种选项:在屏幕上用边框显示输出,将输出保存到本地磁盘,通过RTSP进行流传输或仅将元数据发送到云。为了将元数据发送到云,DeepStream使用Gst-nvmsgconv和Gst-nvmsgbroker插件。 Gst-nvmsgconv将元数据转换为架构有效负载,而Gst-nvmsgbroker建立与云的连接并发送遥测数据。 有几种内置的代理协议,例如Kafka,MQTT,AMQP和Azure IoT。 可以创建自定义代理适配器。
deepstream-app的配置文件使用freedesktop格式,是一种非常精简的键值对描述文件,形如:
# demo
[Desktop Entry]
Version=1.0
Type=Application
Name=Foo Viewer
Comment=The best viewer for Foo objects available!
TryExec=fooview
Exec=fooview %F
Icon=fooview
MimeType=image/x-foo;
Actions=Gallery;Create;
[Desktop Action Gallery]
Exec=fooview --gallery
Name=Browse Gallery
[Desktop Action Create]
Exec=fooview --create-new
Name=Create a new Foo!
Icon=fooview-new
描述文件由若干个组(Group )组成,[groupname]表示参数组的名字,每行用Key=Value的形式描述一个键值。使用“# ”表明注释行。
deepstream-app的配置文件有如下可选的配置组。
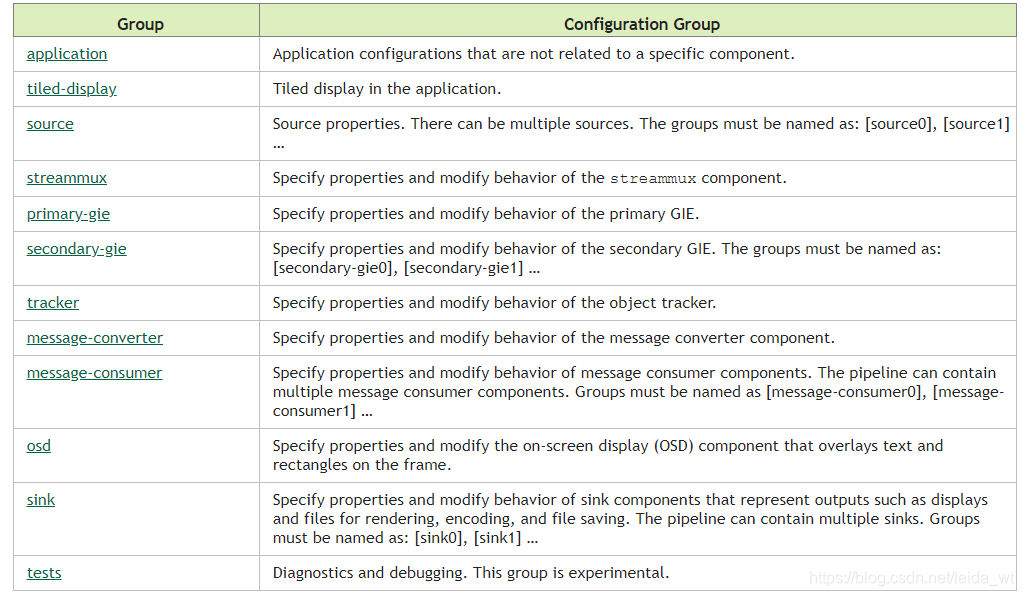
本文的口罩检测demo程序正是使用deepstream-app来构建DS流水线的。我们以调用int8推理模型的配置文件为例进行说明。
int8推理的配置包含两个文件:
- deepstream_app_source1_camera_masknet_gpu_int8.txt
- config_infer_primary_masknet_gpu_int8.txt
前者描述流水线的配置情况,后者对流水线的nvinfer推理模块进行配置(因nvinfer参数比较多,故单独拆分为一个配置文件),下面分别说明两个文件中配置项的含义。
deepstream_app_source1_camera_masknet_gpu_int8.txt:
application配置组指定是否在命令行打印性能评估信息:
[application]
enable-perf-measurement=1
perf-measurement-interval-sec=1
source组指定输入源,这里指定两个输入源同时输入:摄像头和视频文件
[source0]
enable=1
#Type - 1=CameraV4L2 2=URI 3=MultiURI
type=1
camera-width=640
camera-height=480
camera-fps-n=30
camera-fps-d=1
camera-v4l2-dev-node=0
[source1]
enable=0
#Type - 1=CameraV4L2 2=URI 3=MultiURI
type=3
num-sources=1
uri=file:/tlt-demo/test.mp4
gpu-id=0
streammux组开启mux插件,将两个输入源的图像集成打包为batch,由于先前导出int8.engine时设置batch-size=4,故这里保持一致
[streammux]
gpu-id=0
batch-size=4
batched-push-timeout=40000
## Set muxer output width and height
width=640
height=480
osd组指定检测标签的渲染颜色、字体
[osd]
enable=1
gpu-id=0
border-width=4
text-size=18
text-color=1;1;1;1;
text-bg-color=0.3;0.3;0.3;1
font=Arial
primary-gie组设置主推理引擎,注意导入了config_infer_primary_masknet_gpu_int8.txt文件
[primary-gie]
enable=1
gpu-id=0
# Modify as necessary
# GPU engine file
# model-engine-file=/tlt-demo/data/experiment_dir_final/resnet18_detector_int8.engine
# batch-size=4
# Required by the app for OSD, not a plugin property
bbox-border-color0=0;1;0;1
bbox-border-color1=1;0;0;1
#bbox-border-color2=0;0;1;1 # Blue
#bbox-border-color3=0;1;0;1
gie-unique-id=1
config-file=config_infer_primary_masknet_gpu_int8.txt
tracker组使能边界框跟踪器,此处选择klt跟踪算法
[tracker]
enable=1
tracker-width=640
tracker-height=384
#ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_mot_iou.so
#ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_nvdcf.so
ll-lib-file=/opt/nvidia/deepstream/deepstream-5.0/lib/libnvds_mot_klt.so
#ll-config-file required for DCF/IOU only
#ll-config-file=../deepstream-app/tracker_config.yml
#ll-config-file=iou_config.txt
gpu-id=0
#enable-batch-process applicable to DCF only
enable-batch-process=1
tiled-display组将两个视频源的检测结果分开,并排渲染为一个视频流,故这里设置的输出宽度为640*2=1280
[tiled-display]
enable=1
rows=1
columns=2
width=1280 #640
height=480 #480
gpu-id=0
sink组指定了两个输出源,一是在GUI显示,二是编码并推流RTSP到8554端口
[sink0]
enable=0
#Type - 1=FakeSink 2=EglSink 3=File
type=2
sync=1
source-id=0
gpu-id=0
container=2
codec=1
bitrate=2000000
output-file=/tlt-demo/out.mp4
[sink1]
enable=1
#Type - 1=FakeSink 2=EglSink 3=File 4=RTSPStreaming
type=4
#1=h264 2=h265
codec=1
sync=0
bitrate=4000000
# set below properties in case of RTSPStreaming
rtsp-port=8554
#udp-port=5400
最后,tests组的含义设置视频循环播放,方便调试时能够对短视频文件持续反复的观察
[tests]
file-loop=1
config_infer_primary_masknet_gpu_int8.txt文件则有三个配置组。
property组对推理引擎进行设置,包括engine文件路径、推理模型类型、输入大小、推理batch大小、int8映射文件路径、分类阈值等。
[property]
gpu-id=0
net-scale-factor=0.0039215697906911373
tlt-model-key=Z2doZm5wZmsyaTRqdTFpaTh2cTduNjdjbW46OWYwMzYyNDEtMWY0ZS00NmRjLTgxZDAtYjI0NjkzYTY0YjJk
#tlt-encoded-model=/tlt-demo/data/experiment_dir_final/resnet18_detector_int8.etlt
labelfile-path=labels_masknet.txt
# GPU Engine File
model-engine-file=/tlt-demo/data/experiment_dir_final/resnet18_detector_int8.engine
# DLA Engine File
# model-engine-file=/tlt-demo/data/experiment_dir_final/resnet18_detector_int8.engine
input-dims=3;544;960;0
uff-input-blob-name=input_1
batch-size=4
model-color-format=0
## 0=FP32, 1=INT8, 2=FP16 mode
network-mode=1
int8-calib-file=/tlt-demo/data/experiment_dir_final/calibration.bin
num-detected-classes=2
cluster-mode=3
interval=0
gie-unique-id=1
is-classifier=0
classifier-threshold=0.9
output-blob-names=output_bbox/BiasAdd;output_cov/Sigmoid
[class-attrs-all]组为所有类别配置检测参数,由于任务是目标检测,故设置项主要包含极大值抑制算法的相关参数。
[class-attrs-0]
pre-cluster-threshold=0.3
group-threshold=1
eps=0.5
#minBoxes=1
detected-min-w=0
detected-min-h=0
detected-max-w=0
detected-max-h=0
[class-attrs-1]
pre-cluster-threshold=0.3
group-threshold=1
eps=0.3
#minBoxes=1
detected-min-w=0
detected-min-h=0
detected-max-w=0
detected-max-h=0
关于字段的具体含义,可查询文档,这里不再赘述。
总结
总体来看,TLT和DS构成的工具链将模型的训练和部署变得极为方便,唯一需要编程的部分仅仅是一些数据集转换脚本。最关键的是,借助DS框架,算法可以达到极高的帧率,TLT+DS绝对是做工(heng)程(xiang)的利器!
当然,使用deepstream-app+配置文件仍然有很多限制,后续有机会将探索DS的python接口的使用方法。
智能推荐
获取大于等于一个整数的最小2次幂算法(HashMap#tableSizeFor)_整数 最小的2的几次方-程序员宅基地
文章浏览阅读2w次,点赞51次,收藏33次。一、需求给定一个整数,返回大于等于该整数的最小2次幂(2的乘方)。例: 输入 输出 -1 1 1 1 3 4 9 16 15 16二、分析当遇到这个需求的时候,我们可能会很容易想到一个"笨"办法:..._整数 最小的2的几次方
Linux 中 ss 命令的使用实例_ss@,,x,, 0-程序员宅基地
文章浏览阅读865次。选项,以防止命令将 IP 地址解析为主机名。如果只想在命令的输出中显示 unix套接字 连接,可以使用。不带任何选项,用来显示已建立连接的所有套接字的列表。如果只想在命令的输出中显示 tcp 连接,可以使用。如果只想在命令的输出中显示 udp 连接,可以使用。如果不想将ip地址解析为主机名称,可以使用。如果要取消命令输出中的标题行,可以使用。如果只想显示被侦听的套接字,可以使用。如果只想显示ipv4侦听的,可以使用。如果只想显示ipv6侦听的,可以使用。_ss@,,x,, 0
conda activate qiuqiu出现不存在activate_commandnotfounderror: 'activate-程序员宅基地
文章浏览阅读568次。CommandNotFoundError: 'activate'_commandnotfounderror: 'activate
Kafka 实战 - Windows10安装Kafka_win10安装部署kafka-程序员宅基地
文章浏览阅读426次,点赞10次,收藏19次。完成以上步骤后,您已在 Windows 10 上成功安装并验证了 Apache Kafka。在生产环境中,通常会将 Kafka 与外部 ZooKeeper 集群配合使用,并考虑配置安全、监控、持久化存储等高级特性。在生产者窗口中输入一些文本消息,然后按 Enter 发送。ZooKeeper 会在新窗口中运行。在另一个命令提示符窗口中,同样切换到 Kafka 的。Kafka 服务器将在新窗口中运行。在新的命令提示符窗口中,切换到 Kafka 的。,应显示已安装的 Java 版本信息。_win10安装部署kafka
【愚公系列】2023年12月 WEBGL专题-缓冲区对象_js 缓冲数据 new float32array-程序员宅基地
文章浏览阅读1.4w次。缓冲区对象(Buffer Object)是在OpenGL中用于存储和管理数据的一种机制。缓冲区对象可以存储各种类型的数据,例如顶点、纹理坐标、颜色等。在渲染过程中,缓冲区对象中存储的数据可以被复制到渲染管线的不同阶段中,例如顶点着色器、几何着色器和片段着色器等,以完成渲染操作。相比传统的CPU访问内存,缓冲区对象的数据存储和管理更加高效,能够提高OpenGL应用的性能表现。_js 缓冲数据 new float32array
四、数学建模之图与网络模型_图论与网络优化数学建模-程序员宅基地
文章浏览阅读912次。(1)图(Graph):图是数学和计算机科学中的一个抽象概念,它由一组节点(顶点)和连接这些节点的边组成。图可以是有向的(有方向的,边有箭头表示方向)或无向的(没有方向的,边没有箭头表示方向)。图用于表示各种关系,如社交网络、电路、地图、组织结构等。(2)网络(Network):网络是一个更广泛的概念,可以包括各种不同类型的连接元素,不仅仅是图中的节点和边。网络可以包括节点、边、连接线、路由器、服务器、通信协议等多种组成部分。网络的概念在各个领域都有应用,包括计算机网络、社交网络、电力网络、交通网络等。_图论与网络优化数学建模
随便推点
android 加载布局状态封装_adnroid加载数据转圈封装全屏转圈封装-程序员宅基地
文章浏览阅读1.5k次。我们经常会碰见 正在加载中,加载出错, “暂无商品”等一系列的相似的布局,因为我们有很多请求网络数据的页面,我们不可能每一个页面都写几个“正在加载中”等布局吧,这时候将这些状态的布局封装在一起就很有必要了。我们可以将这些封装为一个自定布局,然后每次操作该自定义类的方法就行了。 首先一般来说,从服务器拉去数据之前都是“正在加载”页面, 加载成功之后“正在加载”页面消失,展示数据;如果加载失败,就展示_adnroid加载数据转圈封装全屏转圈封装
阿里云服务器(Alibaba Cloud Linux 3)安装部署Mysql8-程序员宅基地
文章浏览阅读1.6k次,点赞23次,收藏29次。PS: 如果执行sudo grep 'temporary password' /var/log/mysqld.log 后没有报错,也没有任何结果显示,说明默认密码为空,可以直接进行下一步(后面设置密码时直接填写新密码就行)。3.(可选)当操作系统为Alibaba Cloud Linux 3时,执行如下命令,安装MySQL所需的库文件。下面示例中,将创建新的MySQL账号,用于远程访问MySQL。2.依次运行以下命令,创建远程登录MySQL的账号,并允许远程主机使用该账号访问MySQL。_alibaba cloud linux 3
excel离散度图表怎么算_excel离散数据表格-Excel 离散程度分析图表如何做-程序员宅基地
文章浏览阅读7.8k次。EXCEL中数据如何做离散性分析纠错。离散不是均值抄AVEDEV……=AVEDEV(A1:A100)算出来的是A1:A100的平均数。离散是指各项目间指标袭的离散均值(各数值的波动情况),数值较低表明项目间各指标波动幅百度小,数值高表明波动幅度较大。可以用excel中的离散公式为STDEV.P(即各指标平均离散)算出最终度离散度。excel表格函数求一组离散型数据,例如,几组C25的...用exc..._excel数据分析离散
学生时期学习资源同步-JavaSE理论知识-程序员宅基地
文章浏览阅读406次,点赞7次,收藏8次。i < 5){ //第3行。int count;System.out.println ("危险!System.out.println(”真”);System.out.println(”假”);System.out.print(“姓名:”);System.out.println("无匹配");System.out.println ("安全");
linux 性能测试磁盘状态监测:iostat监控学习,包含/proc/diskstats、/proc/stat简单了解-程序员宅基地
文章浏览阅读3.6k次。背景测试到性能、压力时,经常需要查看磁盘、网络、内存、cpu的性能值这里简单介绍下各个指标的含义一般磁盘比较关注的就是磁盘的iops,读写速度以及%util(看磁盘是否忙碌)CPU一般比较关注,idle 空闲,有时候也查看wait (如果wait特别大往往是io这边已经达到了瓶颈)iostatiostat uses the files below to create ..._/proc/diskstat
glReadPixels读取保存图片全黑_glreadpixels 全黑-程序员宅基地
文章浏览阅读2.4k次。问题:在Android上使用 glReadPixel 读取当前渲染数据,在若干机型(华为P9以及魅族某魅蓝手机)上读取数据失败,glGetError()没有抓到错误,但是获取到的数据有误,如果将获取到的数据保存成为图片,得到的图片为黑色。解决方法:glReadPixels实际上是从缓冲区中读取数据,如果使用了双缓冲区,则默认是从正在显示的缓冲(即前缓冲)中读取,而绘制工作是默认绘制到后缓..._glreadpixels 全黑