awstats CGI模式下动态生成页面缓慢的改进_awstats的页面如何修改-程序员宅基地
技术标签: Linux相关 awstat查看速度 awstat页面缓存 awstats改进 运维架构
本文可以看做是 多server多站点情况下awstats日志分析 这篇文章的下篇,在使用过程中发现awstats在cgi模式下动态生成分析报告慢的问题 (尤其是有些站点每天两个多G的日志,查看起来简直是在考验人的耐性),本文分享一种改造这个缺点的思路。
首先再来总结下awstats的处理过程以及查看分析结果的两种方式,来看官方版说明:
Process logs: Building/updating statistics database,建立/更新统计数据库(包含统计结果的文本文件)命令如下
perl awstats.pl -config=mysite -update
Run reports: Building and reading reports(生成并阅读报告)
- The first option is to build the main reports, in a static HTML page, from the command line, using the following syntax
第一种方式,通过命令行生成html文件,然后浏览器展示。命令如下
perl awstats.pl -config=mysite -output -staticlinks > awstats.mysite.html- The second option is to dynamically view your statistics from a browser. To do this, use the URL:
第二种方式,通过如下的url“动态”的生成该站点的分析报告
http://www.myserver.mydomain/awstats/awstats.pl?config=mysite
总体思路就是,既然“动态生成”这个过程耗时,那就在服务器上定时通过curl 请求每个站点对应的url将生成的html页面存储到特定位置,然后浏览器访问时直接读取html文件即可(可能有同学要问了,这么费事,那为啥不直接用上面的第一种方式,用awstats.pl提供的参数直接生成html文件呢?这也就回归到上篇文章中讨论过的两种方式的差别了,awstats.pl生成的静态html页面从易用性和美观性都不如通过CGI动态生成的html页面)
思路有了,接下来就是“尝试”和“分析特征”。我们直接以
curl -o /tmp/mysite.html http://www.myserver.mydomain/awstats/awstats.pl?config=mysite
得到的页面源代码如下
<html >
<head>
<meta name="generator" content="AWStats 7.4 (build 20150714) from config file awstats./usr/local/awstats/etc/www.conf.conf (http://www.awstats.org)">
<meta name="robots" content="noindex,nofollow">
<meta http-equiv="content-type" content="text/html; charset=utf-8">
<meta http-equiv="expires" content="Wed Apr 27 11:09:58 2016">
<meta http-equiv="description" content="Awstats - Advanced Web Statistics for www.dddd.com (2015-08) - main">
<title>Statistics for www.mysite.com (2015-08) - main</title>
</head>
<frameset cols="240,*">
<frame name="mainleft" src="awstats.pl?config=mysite&framename=mainleft" noresize="noresize" frameborder="0" />
<frame name="mainright" src="awstats.pl?config=mysite&framename=mainright" noresize="noresize" scrolling="yes" frameborder="0" />
<noframes><body>Your browser does not support frames.<br />
You must set AWStats UseFramesWhenCGI parameter to 0
to see your reports.<br />
</body></noframes>
</frameset>
</html>可以看到动态生成的页面实际上是一个包含了两个frame(mainleft和mainright)的html文件,也就是说,如果我们想还原一个动态生成的报告页面,需要通过如下三条命令来生成对应的三个文件
curl -s -o main.html "http://www.myserver.mydomain/awstats/awstats.pl?config=mysite" #取得主页面
curl -s -o left.html "http://www.myserver.mydomain/awstats/awstats.pl?config=mysite&framename=mainleft" #取得左frame
curl -s -o right.html "http://www.myserver.mydomain/awstats/awstats.pl?config=mysite&framename=mainright" #取得右frame然后,需要在 main.html中修改mainleft和mainright两个frame的src属性,将其指定到我们生成的left.html和right.html。如此我们就实现了将动态页面静态化(实际上是把动态生这个等待时间放到脚本里定时执行了)。
接下来,就是具体的实现过程了,涉及到对上篇文章中“cron_awstats_update.sh”脚本的改进,修改后的脚本内容如下(注释还算丰富,也能帮助理解思路)
#!/bin/sh
#by ljk
#awstats日志分析
basedir=/usr/local/awstats-7.4
date_y_m=$(date +%Y%m -d '1 day ago') #因为该脚本是第二天凌晨分析前一天的日志
year=`echo ${date_y_m:0:4}`
month=`echo ${date_y_m:4:5}`
cd $basedir
#循环更新所有站点日志统计信息
echo -e "\e[1;31m-------`date "+%F %T"` 开始处理---------\n\e[0m" >>logs/cron.log
for i in `ls result/`
do
echo -e "\e[1;32m -----`date "+%F %T"` 处理 $i 日志-----\e[0m" >>logs/cron.log
perl wwwroot/cgi-bin/awstats.pl -config=etc/$i.conf -lang=cn -update &>>logs/cron.log
#将动态页面静态化,查看展示页面结构可得:主页面基本没内容,主要靠左右两个frame来生成内容
#所以可以将每一个站点的展示页分为三部分来缓存
echo -e "\e[1;32m -----`date "+%F %T"` 分析 $i 生成静态页面-----\n\e[0m" >>logs/cron.log
cd wwwroot
if [ ! -d $i/$date_y_m ];then mkdir -p $i/$date_y_m;fi
cd $i/$date_y_m
curl -s -o main.html\ #主页面
"http://127.0.0.1/cgi-bin/awstats.pl?month=$month&year=$year&output=main&config=/usr/local/services/awstats-7.4/etc/$site.conf&framename=index"
curl -s -o left.html\ #左页面
"http://127.0.0.1/cgi-bin/awstats.pl?month=$month&year=$year&output=main&config=/usr/local/services/awstats-7.4/etc/$site.conf&framename=mainleft"
curl -s -o right.html\ #右页面
"http://127.0.0.1/cgi-bin/awstats.pl?month=$month&year=$year&output=main&config=/usr/local/services/awstats-7.4/etc/$site.conf&framename=mainright"
#修改main.html里关于左右两个frame的引用
sed -i -e 's/awstats.pl.*left/left.html/g' -e 's/awstats.pl.*right/right.html/g' main.html
#接下来修改上面三个文件中的超链接部分
sed -i -e 's#awstats.pl#http://123.123.123.123/cgi-bin/awstats.pl#g'\ #123.123.123.123为公网ip
-e 's/charset=.*/charset=utf-8">/g'\
-e 's/lang="cn"//g'\
main.html left.html right.html
#剩下的事就是去修改nginx index.html页面的超链接指向
cd $basedir
done
echo -e "\e[1;33m-------`date "+%F %T"` 处理完成---------\n\e[0m" >>logs/cron.log
#####
#原始请求样式,
#http://127.0.0.1/cgi-bin/awstats.pl?config=/usr/local/awstats-7.4/etc/heibai.conf 这个url访问该站点最新数据,会产生下面三个请求
#http://127.0.0.1/cgi-bin/awstats.pl?config=/usr/local/awstats-7.4/etc/heibai.conf
#http://127.0.0.1/cgi-bin/awstats.pl?config=/usr/local/awstats-7.4/etc/heibai.conf&framename=mainleft
#http://127.0.0.1/cgi-bin/awstats.pl?config=/usr/local/awstats-7.4/etc/heibai.conf&framename=mainright
#####
#选择年月之后,会产生如下三个请求
#http://127.0.0.1/cgi-bin/awstats.pl?month=05&year=2016&output=main&config=%2Fusr%2Flocal%2Fawstats-7.4%2Fetc%2Fheibai.conf&framename=index 经过编码的
#http://127.0.0.1/cgi-bin/awstats.pl?month=05&year=2016&output=main&config=/usr/local/awstats-7.4/etc/heibai.conf&framename=mainleft
#http://127.0.0.1/cgi-bin/awstats.pl?month=05&year=2016&output=main&config=/usr/local/awstats-7.4/etc/heibai.conf&framename=mainright
#####经过脚本处理之后,在wwwroot目录下,站点目录与html文件会是这个样子
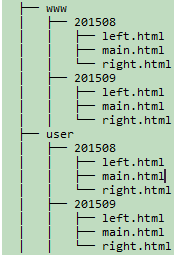
到此,我们对上篇文章中的nginx配置部分做相应修改后就可以通过如下url来访问了
http://www.myserver.mydomain/www/201605 #表示www站2016年5月的统计页面
但是,改造到这里并不算完,在动态生成的页面里,有选择年和月的下拉框,可以查看指定年月的统计页面,如下图

这个功能会产生一个如下的请求
http://www.myserver.mydomain/cgi-bin/awstats.pl?month=04&year=2016&output=main&config=www.conf&framename=index
仍然是动态请求(即仍然会慢),但按照我们的设计,每个月应该都已经生成了静态文件,所以是不需要动态生成的。如何将这个功能点修改为也按照上面静态url的格式呢,这里作者首先想到了两个方案:
- 一个是通过js获取年和月的值,然后在表单的action处拼出所需的url
- 另一个是通过nginx的rewrite来实现
经过尝试和对比,第二种方案更适合这里的场景,因为第一种涉及到对生成的html文件内容进行修改,且不止一处,实现起来啰嗦一些;而第二种方案只需要在nginx里做配置即可(这里如何从nginx获取到参数值并且引用该值算是一个小技巧吧)。
最终,修改之后的nginx配置文件如下
server {
listen 800;
root /usr/local/awstats/wwwroot;
access_log /tmp/awstats_access_log access;
error_log /tmp/awstats_nginx.error_log notice;
location / {
index index.html main.html;
}
# Static awstats files: HTML files stored in DOCUMENT_ROOT/awstats/
location /awstats/classes/ {
alias classes/;
}
location /awstats/css/ {
alias css/;
}
location /awstats/icon/ {
alias icon/;
}
location /awstats-icon/ {
alias icon/;
}
location /awstats/js/ {
alias js/;
}
# Dynamic stats.
location ~ ^/cgi-bin/(awredir|awstats)\.pl.* {
gzip off;
fastcgi_pass 127.0.0.1:9000;
fastcgi_param SCRIPT_FILENAME $document_root/cgi-bin/fcgi.php;
fastcgi_param X_SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param X_SCRIPT_NAME $fastcgi_script_name;
include fastcgi_params;
fastcgi_send_timeout 300;
#为了让顶部根据时间筛选功能也能用上之前生成的静态页面, 其中%2F部分为url编码后的/,为了取得站点名
if ($query_string ~* "^month=(\d+)&year=(\d+)&output=main&config=.+etc%2F(.+)\.conf&framename=index$") {
set $month $1;
set $year $2;
set $site $3;
rewrite ^/cgi-bin/awstats\.pl /$site/$year$month? permanent;
}
}
expires 12h;
}最后一点,不要忘了修改“入口文件”index.html哦,js自动生成的超链接要修改,增加及修改下面内容
/* ...省略... */
//一个能计算昨天明天等日期的函数
function GetDateStr(AddDayCount) {
var dd = new Date();
dd.setDate(dd.getDate()+AddDayCount);//获取AddDayCount天后的日期
var y = dd.getFullYear();
var m = dd.getMonth()+1;//获取当前月份的日期
var d = dd.getDate();
if (m<10) {
return y+"0"+m; //格式自定义
} else {
return y+''+m;
}
}
var yesterday=GetDateStr(-1); //计算昨天日期 格式 201604
//向表格填充内容
for (var tdid=0;tdid<num;tdid++) {
//依顺序获取各td元素
var tdnode=document.getElementById(tdid+1);
//取出每个域名里的主机名,服务器端配置文件命名方式为 “主机名.conf”
var hostname=vhost[tdid].split(".dmzj",1);
//向表格插入域名并且设置超链接
tdnode.innerHTML="<a href=\""+hostname+"/"+yesterday+"\">" +vhost[tdid] +"</a>";
}
/* ...省略... */ 与原文件内容差别如下
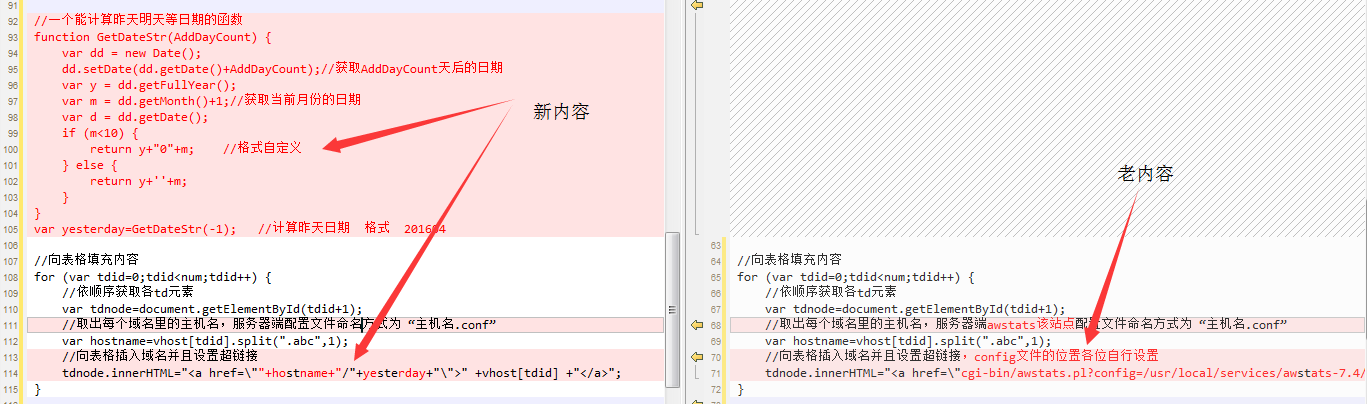
OK,到这里整个改进过程完毕。每个月份的统计结果的主页面都已经实现了静态化,查看时再也不用经历漫长的等待了!
PS:工具再好,也不见得完全适合或者满足自己的需求,大部分情况下作为“软件使用者”的运维同胞,应该有这个意识:不只会用,必要时还能改。共勉!
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象
二叉树的各种创建方法_二叉树的建立-程序员宅基地
文章浏览阅读6.9w次,点赞73次,收藏463次。1.前序创建#include<stdio.h>#include<string.h>#include<stdlib.h>#include<malloc.h>#include<iostream>#include<stack>#include<queue>using namespace std;typed_二叉树的建立