Elasticsearch介绍及如何使用_elasticsearch match_phrase_prefix-程序员宅基地
技术标签: elasticsearch
是什么
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念:
- 节点(Node):
一个节点是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群的索引和搜索功能。
一个节点可以通过配置特定的集群名称来加入特定的集群。默认情况下,每个节点被设定加入一个名称为 “elasticsearch” 的集群,这意味着如果你在你的网络中启动了一些节点,并且假设它们能相互发现,它们将会自动组织并加入一个名称是 “elasticsearch” 的集群。 - 索引(Index):
可以近似的理解SQL中的数据库,虽然官方文档上说这是不好的。可以包涵表和数据。 - 类型(Type):(警告!Type在6.0.0版本中已经不赞成使用):
可以近似的理解成是SQL中的表,里面会包涵许多数据 - 文档(Document):
可以近似的理解是SQL中的表里的每一条数据。
去哪下:
官网下载传送
官网下载window版(我的是6.6.1版本)。
双击运行bin目录下的 elasticsearch.bat
怎么玩:
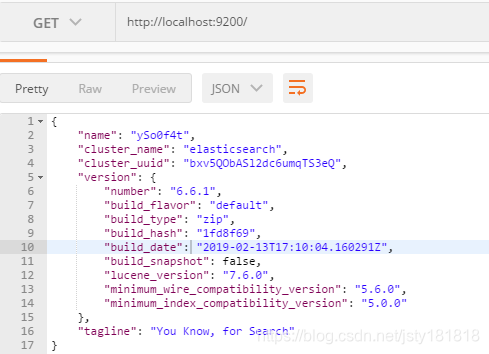
看到这个结果,说明安装,启动成功。
- 列出所有的索引:(GET)
http://localhost:9200/_cat/indices?v
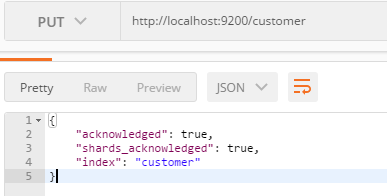
- 创建一个索引:(PUT)
http://localhost:9200/customer
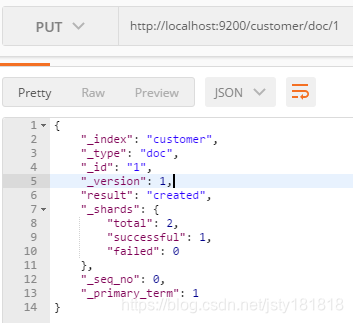
- 向索引中添加文档(PUT)
http://localhost:9200/customer/doc/1
//其中doc是类型。
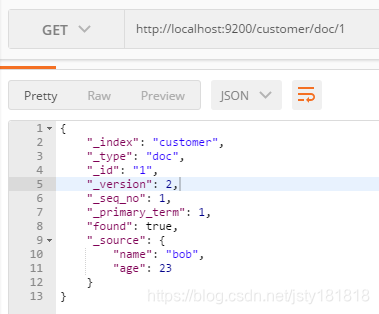
- 获取刚刚加入索引的文档:(GET)
http://localhost:9200/customer/doc/1
- 删除一个索引:(DELETE)
http://localhost:9200/customer
- 更新文档(POST)
除了能够新增和替换文档,我们也可以更新文档。注意虽然 Elasticsearch 在底层并没有真正更新文档,而是当我们更新文档时,Elasticsearch 首先去删除旧的文档,然后加入新的文档。
http://localhost:9200/customer/doc/1/_update?pretty
{
"doc": { "name": "Jane Doe" }
}
更新操作也可以使用简单的脚本来执行。如下的示例使用一个脚本将age增加了5:
http://localhost:9200/customer/doc/1/_update?pretty
{
"script" : "ctx._source.age += 5"
}
- 删除文档(DELETE):
http://localhost:9200/customer/doc/2?pretty
推荐使用Kibana进行数据查询
搜索:
- _mget(批量获取文档)
类似sql中的 id in(1,2,3)这样。
GET _mget
{
"docs":[
{
"_index": "bank",
"_type": "account",
"_id": "1",
"_source": ["balance", "city"]
},
{
"_index": "bank",
"_type": "account",
"_id": "5",
"_source": "firstname"
}
]
}
也可以简写:
GET /bank/account/_mget
{
"ids": ["1", "2", "4"]
}
-
_bulk(批量操作)
1.格式:
{action:{metadata}}
{requestbody}
其中action(行为)可以取值:
1.create:文档不存在时创建
2.update:更新文档
3.index:创建新文档或覆盖已有文档
4.delete:删除一个文档
create和index的区别:如果数据存在,使用create操作失败,会提示文档以存在,使用index可以成功执行。
如果使用create创建多个,其中有存在的,那么存在的返回失败,不存在的添加成功
其中metadata可以取值:
_index,_type,_id示例:
1.create:POST /bank/account/_bulk { "create":{ "_id":"999"}} { "account_number":999, "balance": 999} { "create":{ "_id":"1000"}} { "account_number":1000, "balance": 1000} { "create":{ "_id":"1001"}} { "account_number":1001, "balance": 1001}2.delete:
POST bank/account/_bulk { "delete":{ "_index":"bank", "_type":"account", "_id":"1000"}}3.update:
POST /bank/account/_bulk { "update":{ "_id":"1001"}} { "doc":{ "balance":"0"}} -
term:
用于查询指定字段包含某个词项的文档。这个查询不知道分词器的存在,所以搜索的值不会进行分词。只会拿搜索的值去倒排索引中找。
GET /bank/account/_search
{
"query":{
"term":{
"address":{
"value":"heath"
}
}
}
}
- match:
知道分词器的存在,所以搜索的值会被分词在去查询。
GET /bank/account/_search
{
"query":{
"match":{
"address":"511 Heath Place"
}
}
}
- multi_match:
可以指定多个字段,意思是:查找fields字段值的字段中包含query字段中对应的值
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
}
}
- match_phrase:
短语搜索,就是搜索含有指定的短语的数据。意思是搜索的值经过分词之后和es中分词保存的一致,顺序也一致,两头的可以少,中间的不可以少
GET /bank/account/_search
{
"query":{
"match_phrase":{
"address":"511 Heath Place"
}
}
}
- _source:
用来指定返回的字段:
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": ["firstname", "age"]
}
_可以写个数组来指定,也可以在 "source" 字段中加"includes"和"excludes"
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": {
"includes": ["age", "balance", "gen*"],
"excludes": ["gender"]
}
}
- sort:
用来排序,和关系型数据库的排序类似
GET /bank/account/_search
{
"query":{
"match_all":{
}
},
"sort":[
{
"balance":{
"order":"desc"
}
},
{
"age":{
"order":"asc"
}
}
]
}
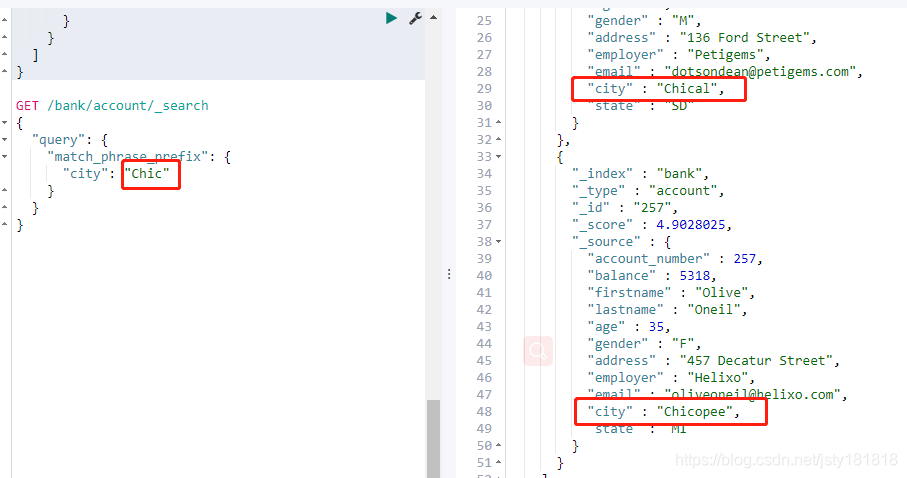
- match_phrase_prefix:
前缀匹配(查询的值不会分词,但是忽略大小写)
- range:
范围查询:
GET /bank/account/_search
{
"query":{
"range":{
"age":{
"gte": 20,
"lt": 30
}
}
}
}
- wildcard:
通配符匹配:
通配符:
* 代表任意多字符
? 代表一个字符
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
}
}
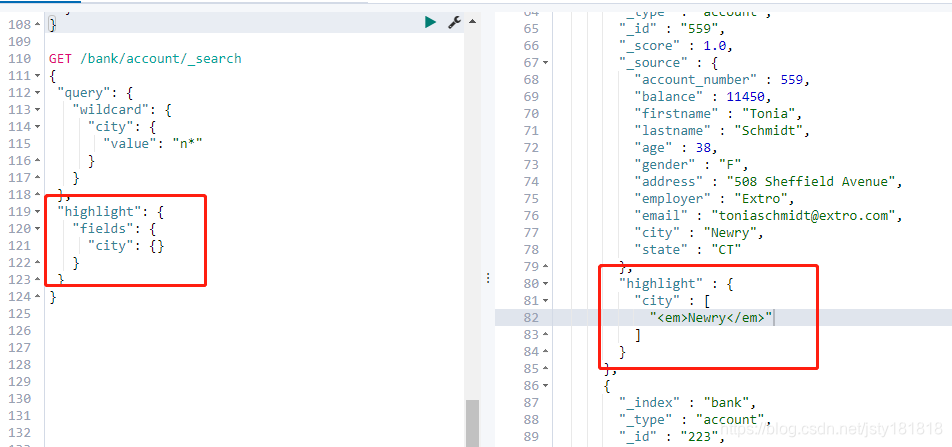
- highlight:
高亮显示:
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
},
"highlight":{
"fields":{
"city":{
}
}
}
}
- fuzzy:
模糊匹配,这个可不是mysql中的like,是可以错误的输入一些字 来进行匹配
GET /bank/account/_search
{
"query":{
"fuzzy":{
"city": "Nicho1so"
}
}
}
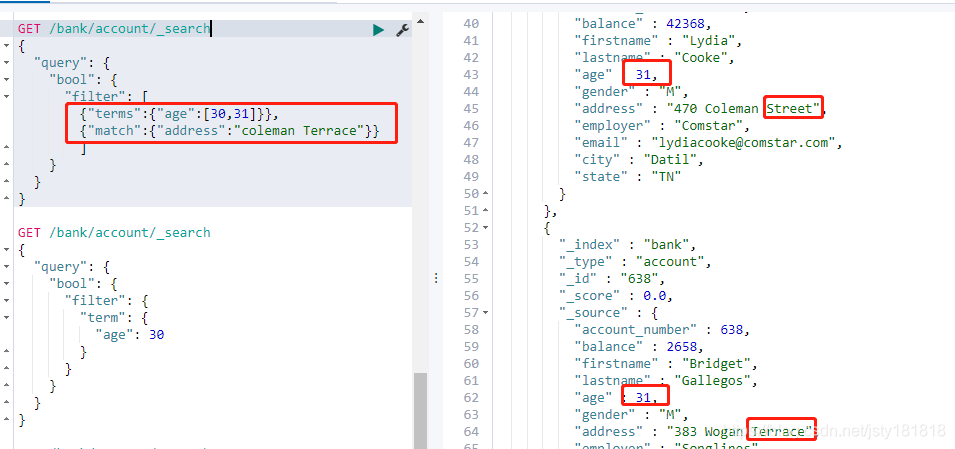
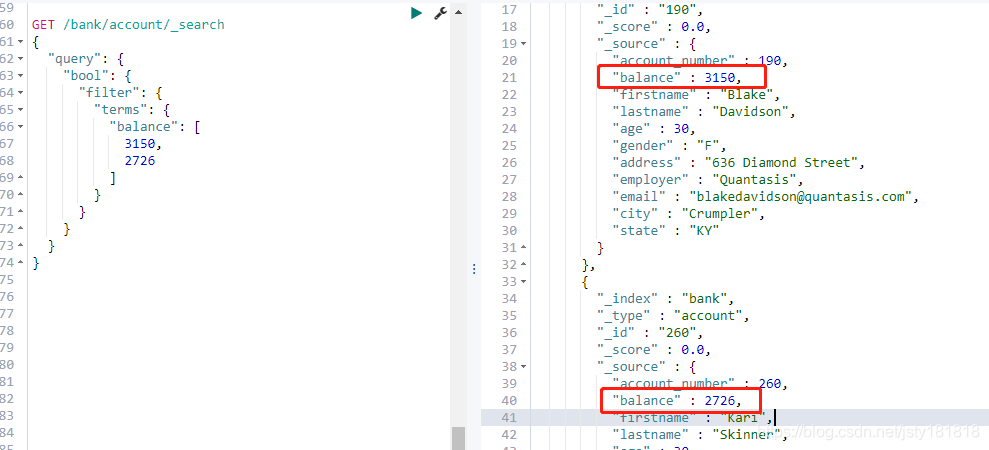
- filter查询:
过滤查询:
- must,should,must_not:
GET /bank/account/_search
{
"query":{
"bool":{
"must": [
{
"term":{
"age":{
"value" :20
}
}
}
]
}
}
}
- exists:
查询某个字段不为空
GET /bank/account/_search
{
"query":{
"bool":{
"filter": {
"exists":{
"field": "age"
}
}
}
}
}
- 聚合查询:
1.sum

智能推荐
Fine-Grained Semantically Aligned Vision-Language Pre-Training细粒度语义对齐的视觉语言预训练_语义对齐 细粒度-程序员宅基地
文章浏览阅读1.2k次,点赞16次,收藏18次。接下来,我们将 softmax-normalization 应用于一个获得一个~.对于我-th 区域,我们将其最大对齐分数计算为麦克斯�一个~我�.然后,我们使用所有区域的平均最大对齐分数作为细粒度图像与文本的相似度�1.同样,我们可以获得细粒度的文本与图像的相似度�2,并且可以定义总的细粒度相似度分数:�=(�1+�2)/2.直观地讲,假设一组补丁标记对应图像中的视觉实例,那么它们往往具有很强的交互性,形成对应实例的完整语义,这有助于更好地判断与配对文本的相似度。,我们设计了一个轻量级的区域生成模块。_语义对齐 细粒度
【愚公系列】2021年11月 攻防世界-进阶题-MISC-030(red_green)_攻防世界 red_green-程序员宅基地
文章浏览阅读4w次。red_green下载得到一张图片解法一:pytho脚本#生成脚本from PIL import Imageimport osimport bitstring#image_name = 'flag.jpg'image_name = input("请输入当前文件夹下图片的名称>>>\n")current_path = os.path.dirname(__file__)with open(os.path.join(current_path,image_name),'rb'_攻防世界 red_green
【Python】卸载完Python3 之后 Python2 无法打开IDLE-程序员宅基地
文章浏览阅读76次。安装官方的Python带Idle但是却无法打开,百度谷歌了几种解决方法,加上自己的实际境况予以解决。我的python是直接安装在C盘下的。1.首先是设置环境变量:Path=C:\Python27PYTHONPATH= C:\Python27\Lib;C:\Python27\Lib\tkinterTCL_LIBRARY=C:\Python27\tcl\tcl8.5TK_LIBRARY=C..._python 改变环境变量之后 py文件不能使用idle打开
【玩转华为云】手把手教你利用ModelArts实现垃圾自动分类_华为云人工智能 垃圾分类-程序员宅基地
文章浏览阅读1.4k次。本篇推文共计2000个字,阅读时间约3分钟。华为云—华为公司倾力打造的云战略品牌,2011年成立,致力于为全球客户提供领先的公有云服务,包含弹性云服务器、云数据库、云安全等云计算服务,软件开发服务,面向企业的大数据和人工智能服务,以及场景化的解决方案。华为云用在线的方式将华为30多年在ICT基础设施领域的技术积累和产品解决方案开放给客户,致力于提供稳定可靠、安全可信、可持续创新的云服务,做智能世界的“黑土地”,推进实现“用得起、用得好、用得放心”的普惠AI。华为云作为底座,为华为全栈全场景A.._华为云人工智能 垃圾分类
Python 开发桌面应用居然如此简单_python制作桌面端-程序员宅基地
文章浏览阅读6.4k次,点赞4次,收藏86次。我们都知道 Python 可以用来开发桌面应用,一旦功能开发完成,最后打包的可执行文件体积大,并且使用 Python 开发桌面应用周期相对较长假如想快速开发一款 PC 端的桌面应用,推荐使用 Aardio + Python 搭配的方式进行开发1. Aardio介绍Aardio 是一款专注于 Windows 桌面端的软件开发,适用于快速开发一些自用的 PC端桌面工具,并且它支持与Python、JS、Golang 等主流语言进行混合编程它是一款免费的开发工具,简单易学,支持多线程,具有轻巧..._python制作桌面端
IDEA中Spring配置错误:class path resource [.xml] cannot be opened because it does not exist_class path resource [feign/requestinterceptor.clas-程序员宅基地
文章浏览阅读10w+次,点赞71次,收藏72次。如果在运行 Spring 项目时出现了类似于:class path resource [applicationContext.xml] cannot be opened because it does not exist这样的异常 意思就是没有找到你的 .xml 配置文件原因我可以肯定你一定用的是 ApplicationContext ctx = new ClassPathXmlApplicati_class path resource [feign/requestinterceptor.class] cannot be opened becaus
随便推点
linux bash shell:最方便的字符串大小写转换(lowercase/uppercase conversion)_shell 小写变大写-程序员宅基地
文章浏览阅读1.4w次,点赞6次,收藏12次。关于字符串大小写转换,是写 linux 脚本经常干的事儿,所以总想找个方便的方法让我少打点字儿,搜索国内的中文资源,网上也能找到很多关于这个帖子,介绍的方法都差不多,用typeset是最简单的方法了,但我觉得还是不够简单,因为需要多定义一个变量。google上找到这个stackoverflow上的帖子,才知道Bash 4.0以上版本有更好的办法:《How to convert a strin..._shell 小写变大写
C++实现线性表的顺序存储结构_c++使用顺序存储表示方法创建线性表-程序员宅基地
文章浏览阅读2.5k次,点赞6次,收藏48次。C++线性表的顺序存储结构 线性表是最基本、最简单、也是最常用的一种数据结构。线性表(linear list)是数据结构的一种,一个线性表是n个具有相同特性的数据元素的有限序列。线性表的特点除第一个元素外,其他每一个元素有且仅有一个直接前驱。除最后一个元素外,其他每一个元素有且仅有一个直接后继。直接前驱和直接后继描..._c++使用顺序存储表示方法创建线性表
重装protobuf报错undefined symbol: _ZNK6google8protobuf7Message11GetTypeNameB5cxx11Ev-程序员宅基地
文章浏览阅读1.4w次,点赞2次,收藏7次。服务器将protobuf版本从2.6.1降级到2.5.0后,重新装回2.6.1,出现报错:protoc: symbol lookup error: /usr/lib/x86_64-linux-gnu/libprotoc.so.9: undefined symbol: _ZNK6google8protobuf7Message11GetTypeNameB5cxx11Ev搜索网上解决办法,发现并...__znk6google8protobuf7message11gettypenameb5cxx11ev
【校招VIP】java语言考点之synchronized和volatile-程序员宅基地
文章浏览阅读356次。synchronized和volatile两个关键字也是校招常考点之一。volatile可以禁止进行指令重排。synchronized可作用于一段代码或方法,既可以保证可见性,又能够保证原子性。_synchronized和volatile
互联网平台经济模式逐渐形成,许多新的创新型企业涌现出来,将会影响到社会的治理结构以及公共政策走向-程序员宅基地
文章浏览阅读461次。作者:禅与计算机程序设计艺术 1.简介在新冠病毒疫情期间,由于经济全面恢复、国内外大量人员返乡、工作日程调整等因素的影响,使得整个社会成为新冠病毒大流行的重灾区。为了减轻生产企业和消费者的不满情绪,提高社会福利水平,防止再次发生类似事件,各地都制定了诸多限制、规范、政策等方面的法律法规,但这些法律法规
ethereum/EIPs-161 State trie clearing-程序员宅基地
文章浏览阅读152次。EIP 161: State trie clearing- makes it possible to remove a large number of empty accounts that were put in the state at very low cost as a result of earlier DoS attacks. With this EIP, 'empty' accou..._eip161