docker部署Airflow(修改URL-path、更换postgres -->myslq数据库、LDAP登录)_airflow docker-程序员宅基地
技术标签: python devops mongodb docker
Airflow

什么是 Airflow?
Airflow 是一个使用 python 语言编写的 data pipeline 调度和监控工作流的平台。 Airflow 是通过 DAG(Directed acyclic graph 有向无环图)来管理任务流程的任务调度工具, 不需要知道业务数据的具体内容,设置任务的依赖关系即可实现任务调度。
这个平台拥有和 Hive、Presto、MySQL、HDFS、Postgres 等数据源之间交互的能力,并且提供了钩子(hook)使其拥有很好地扩展性。 除了一个命令行界面,该工具还提供了一个基于 Web 的用户界面可以可视化管道的依赖关系、监控进度、触发任务等。
Airflow 的架构
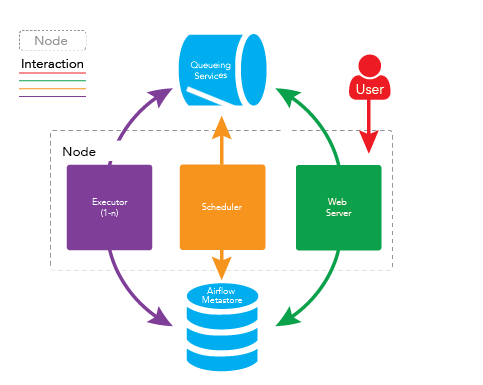
在一个可扩展的生产环境中,Airflow 含有以下组件:
- 元数据库:这个数据库存储有关任务状态的信息。
- 调度器:Scheduler 是一种使用 DAG 定义结合元数据中的任务状态来决定哪些任务需要被执行以及任务执行优先级的过程。 调度器通常作为服务运行。
- 执行器:Executor 是一个消息队列进程,它被绑定到调度器中,用于确定实际执行每个任务计划的工作进程。 有不同类型的执行器,每个执行器都使用一个指定工作进程的类来执行任务。 例如,LocalExecutor 使用与调度器进程在同一台机器上运行的并行进程执行任务。 其他像 CeleryExecutor 的执行器使用存在于独立的工作机器集群中的工作进程执行任务。
- Workers:这些是实际执行任务逻辑的进程,由正在使用的执行器确定。
Airflow 解决哪些问题
通常,在一个运维系统,数据分析系统,或测试系统等大型系统中,我们会有各种各样的依赖需求。包括但不限于: 时间依赖:任务需要等待某一个时间点触发。 外部系统依赖:任务依赖外部系统需要调用接口去访问。 任务间依赖:任务 A 需要在任务 B 完成后启动,两个任务互相间会产生影响。 资源环境依赖:任务消耗资源非常多, 或者只能在特定的机器上执行。
crontab 可以很好地处理定时执行任务的需求,但仅能管理时间上的依赖。
Airflow 的核心概念是 DAG (有向无环图)。DAG 由一个或多个 task 组成,而这个 DAG 正是解决了上文所说任务间的依赖问题。 任务执行的先后依赖顺序、多个 task 之间的依赖关系可以很好的用 DAG 表示完善。
Airflow 同样完整的支持 crontab 表达式,也支持直接使用 python 的 datatime 模块表述时间,还可以用 datatime 的 delta 表述时间差。
一、docker-compose 安装airflow(postgres)
docker-compose文件包含几个服务定义:
airflow-scheduler-调度程序监控所有任务和 DAG,然后在它们的依赖关系完成后触发任务实例。airflow-webserver- 网络服务器可在http://localhost:8080.airflow-worker- 执行调度程序给出的任务的工作人员。airflow-init- 初始化服务。flower-用于监控环境的花卉应用程序。可在http://localhost:5555.postgres- 数据库。redis- redis - 将消息从调度程序转发到工作人员的代理。
所有这些服务都允许您使用CeleryExecutor运行 Airflow 。有关详细信息,请参阅架构概述。
容器中的某些目录是挂载的,这意味着它们的内容在您的计算机和容器之间是同步的。
./dags- 你可以把你的 DAG 文件放在这里。./logs- 包含来自任务执行和调度程序的日志。./plugins- 你可以把你的自定义插件放在这里。
前要:
运行需要的文件基础结构
leojiang]# mkdir -p /var/opt/tools/airflow && cd /var/opt/tools/airflow
leojiang]# ll
-rw-rw-r-- 1 root root 44155 Mar 3 13:26 airflow.cfg
-rwxrwxrwx 1 root root 8337 Mar 3 17:00 airflow-docker-compose.yml
-rw-rw-r-- 1 root root 1626 Mar 14 16:12 webserver_config.py
leojiang]# pwd
/var/opt/tools/airflow
1、创建启动文件airflow-docker-compose.yml.
数据库连接配置为postgres,此yaml文件up运行后会自动创建postgres数据库。
---
version: '3'
x-airflow-common:
&airflow-common
image: ${
AIRFLOW_IMAGE_NAME:-apache/airflow:2.2.3}
# build: .
environment:
&airflow-common-env
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0
AIRFLOW__CORE__FERNET_KEY: ''
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true'
AIRFLOW__CORE__LOAD_EXAMPLES: 'true'
#AIRFLOW__WEBSERVER__BASE_URL: 'http://1.11.1.127:8080/airflow'
#AIRFLOW__WEBSERVER__X_FRAME_ENABLED: 'True'
AIRFLOW__API__AUTH_BACKEND: 'airflow.api.auth.backend.basic_auth'
#AUTH_ROLE_PUBLIC: 'Admin'
# AIRFLOW__CLI__ENDPOINT_URL: 'http://localhost:8080/airflow'
AIRFLOW__WEBSERVER__ENABLE_PROXY_FIX: 'True'
_PIP_ADDITIONAL_REQUIREMENTS: ${
_PIP_ADDITIONAL_REQUIREMENTS:-}
volumes:
- ./dags:/opt/airflow/dags
- ./logs:/opt/airflow/logs
- ./plugins:/opt/airflow/plugins
- ./airflow.cfg:/opt/airflow/airflow.cfg
#- ./webserver_config.py:/opt/airflow/webserver_config.py
user: "${AIRFLOW_UID:-50000}:0"
depends_on:
&airflow-common-depends-on
redis:
condition: service_healthy
postgres:
condition: service_healthy
services:
postgres:
image: postgres:13
environment:
POSTGRES_USER: airflow
POSTGRES_PASSWORD: airflow
POSTGRES_DB: airflow
volumes:
- postgres-db-volume:/var/lib/postgresql/data
healthcheck:
test: ["CMD", "pg_isready", "-U", "airflow"]
interval: 5s
retries: 5
restart: always
redis:
image: redis:latest
expose:
- 6379
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 30s
retries: 50
restart: always
airflow-webserver:
<<: *airflow-common
command: webserver
ports:
- 8080:8080
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8080/health"]
interval: 10s
timeout: 10s
retries: 5
restart: always
#volumes: #此处使用会覆盖引用的变量‘airflow-common’
# - /var/opt/tools/airflow/airflow.cfg:/opt/airflow/airflow.cfg
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-scheduler:
<<: *airflow-common
command: scheduler
healthcheck:
test: ["CMD-SHELL", 'airflow jobs check --job-type SchedulerJob --hostname "$${HOSTNAME}"']
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-worker:
<<: *airflow-common
command: celery worker
healthcheck:
test:
- "CMD-SHELL"
- 'celery --app airflow.executors.celery_executor.app inspect ping -d "celery@$${HOSTNAME}"'
interval: 10s
timeout: 10s
retries: 5
environment:
<<: *airflow-common-env
# Required to handle warm shutdown of the celery workers properly
# See https://airflow.apache.org/docs/docker-stack/entrypoint.html#signal-propagation
DUMB_INIT_SETSID: "0"
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-triggerer:
<<: *airflow-common
command: triggerer
healthcheck:
test: ["CMD-SHELL", 'airflow jobs check --job-type TriggererJob --hostname "$${HOSTNAME}"']
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-init:
<<: *airflow-common
entrypoint: /bin/bash
# yamllint disable rule:line-length
command:
- -c
- |
function ver() {
printf "%04d%04d%04d%04d" $${
1//./ }
}
airflow_version=$$(gosu airflow airflow version)
airflow_version_comparable=$$(ver $${
airflow_version})
min_airflow_version=2.2.0
min_airflow_version_comparable=$$(ver $${
min_airflow_version})
if (( airflow_version_comparable < min_airflow_version_comparable )); then
echo
echo -e "\033[1;31mERROR!!!: Too old Airflow version $${airflow_version}!\e[0m"
echo "The minimum Airflow version supported: $${min_airflow_version}. Only use this or higher!"
echo
exit 1
fi
if [[ -z "${AIRFLOW_UID}" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: AIRFLOW_UID not set!\e[0m"
echo "If you are on Linux, you SHOULD follow the instructions below to set "
echo "AIRFLOW_UID environment variable, otherwise files will be owned by root."
echo "For other operating systems you can get rid of the warning with manually created .env file:"
echo " See: https://airflow.apache.org/docs/apache-airflow/stable/start/docker.html#setting-the-right-airflow-user"
echo
fi
one_meg=1048576
mem_available=$$(($$(getconf _PHYS_PAGES) * $$(getconf PAGE_SIZE) / one_meg))
cpus_available=$$(grep -cE 'cpu[0-9]+' /proc/stat)
disk_available=$$(df / | tail -1 | awk '{print $$4}')
warning_resources="false"
if (( mem_available < 4000 )) ; then
echo
echo -e "\033[1;33mWARNING!!!: Not enough memory available for Docker.\e[0m"
echo "At least 4GB of memory required. You have $$(numfmt --to iec $$((mem_available * one_meg)))"
echo
warning_resources="true"
fi
if (( cpus_available < 2 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough CPUS available for Docker.\e[0m"
echo "At least 2 CPUs recommended. You have $${cpus_available}"
echo
warning_resources="true"
fi
if (( disk_available < one_meg * 10 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough Disk space available for Docker.\e[0m"
echo "At least 10 GBs recommended. You have $$(numfmt --to iec $$((disk_available * 1024 )))"
echo
warning_resources="true"
fi
if [[ $${
warning_resources} == "true" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: You have not enough resources to run Airflow (see above)!\e[0m"
echo "Please follow the instructions to increase amount of resources available:"
echo " https://airflow.apache.org/docs/apache-airflow/stable/start/docker.html#before-you-begin"
echo
fi
mkdir -p /sources/logs /sources/dags /sources/plugins
chown -R "${AIRFLOW_UID}:0" /sources/{
logs,dags,plugins}
exec /entrypoint airflow version
# yamllint enable rule:line-length
environment:
<<: *airflow-common-env
_AIRFLOW_DB_UPGRADE: 'true'
_AIRFLOW_WWW_USER_CREATE: 'true'
_AIRFLOW_WWW_USER_USERNAME: ${
_AIRFLOW_WWW_USER_USERNAME:-airflow}
_AIRFLOW_WWW_USER_PASSWORD: ${
_AIRFLOW_WWW_USER_PASSWORD:-airflow}
user: "0:0"
volumes:
- .:/sources
airflow-cli:
<<: *airflow-common
profiles:
- debug
environment:
<<: *airflow-common-env
CONNECTION_CHECK_MAX_COUNT: "0"
# Workaround for entrypoint issue. See: https://github.com/apache/airflow/issues/16252
command:
- bash
- -c
- airflow
flower:
<<: *airflow-common
command: celery flower
ports:
- 5555:5555
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:5555/"]
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
volumes:
postgres-db-volume:
上方配置文件中要注意的,需要修改airflow-webserver下的配置,来进行添加挂载卷。
如果不copy我的也可以直接下载官网的docker-compose进行修改
1.1、添加挂载卷,需要修改airflow-docker-compose.yml的位置
……
x-airflow-common:
&airflow-common
image: ${
AIRFLOW_IMAGE_NAME:-apache/airflow:2.2.3}
……
volumes:
- ./dags:/opt/airflow/dags
- ./logs:/opt/airflow/logs
- ./plugins:/opt/airflow/plugins
# 添加映射本地配置到集群中
- ./airflow.cfg:/opt/airflow/airflow.cfg
#- ./webserver_config.py:/opt/airflow/webserver_config.py
……
添加完成后然后创建需要映射的配置文件airflow.cfg
2、创建本地配置文件airflow.cfg
/var/opt/tools/airflow/airflow.cfg
[core]
# The folder where your airflow pipelines live, most likely a
# subfolder in a code repository. This path must be absolute.
dags_folder = /opt/airflow/dags
# Hostname by providing a path to a callable, which will resolve the hostname.
# The format is "package.function".
#
# For example, default value "socket.getfqdn" means that result from getfqdn() of "socket"
# package will be used as hostname.
#
# No argument should be required in the function specified.
# If using IP address as hostname is preferred, use value ``airflow.utils.net.get_host_ip_address``
hostname_callable = socket.getfqdn
# Default timezone in case supplied date times are naive
# can be utc (default), system, or any IANA timezone string (e.g. Europe/Amsterdam)
default_timezone = utc
# The executor class that airflow should use. Choices include
# ``SequentialExecutor``, ``LocalExecutor``, ``CeleryExecutor``, ``DaskExecutor``,
# ``KubernetesExecutor``, ``CeleryKubernetesExecutor`` or the
# full import path to the class when using a custom executor.
executor = SequentialExecutor
# The SqlAlchemy connection string to the metadata database.
# SqlAlchemy supports many different database engines.
# More information here:
# http://airflow.apache.org/docs/apache-airflow/stable/howto/set-up-database.html#database-uri
sql_alchemy_conn = sqlite:////opt/airflow/airflow.db
#sql_alchemy_conn = mysql://airflow:[email protected]:3305/airflow_db
# The encoding for the databases
sql_engine_encoding = utf-8
# Collation for ``dag_id``, ``task_id``, ``key`` columns in case they have different encoding.
# By default this collation is the same as the database collation, however for ``mysql`` and ``mariadb``
# the default is ``utf8mb3_bin`` so that the index sizes of our index keys will not exceed
# the maximum size of allowed index when collation is set to ``utf8mb4`` variant
# (see https://github.com/apache/airflow/pull/17603#issuecomment-901121618).
# sql_engine_collation_for_ids =
# If SqlAlchemy should pool database connections.
sql_alchemy_pool_enabled = True
# The SqlAlchemy pool size is the maximum number of database connections
# in the pool. 0 indicates no limit.
sql_alchemy_pool_size = 5
# The maximum overflow size of the pool.
# When the number of checked-out connections reaches the size set in pool_size,
# additional connections will be returned up to this limit.
# When those additional connections are returned to the pool, they are disconnected and discarded.
# It follows then that the total number of simultaneous connections the pool will allow
# is pool_size + max_overflow,
# and the total number of "sleeping" connections the pool will allow is pool_size.
# max_overflow can be set to ``-1`` to indicate no overflow limit;
# no limit will be placed on the total number of concurrent connections. Defaults to ``10``.
sql_alchemy_max_overflow = 10
# The SqlAlchemy pool recycle is the number of seconds a connection
# can be idle in the pool before it is invalidated. This config does
# not apply to sqlite. If the number of DB connections is ever exceeded,
# a lower config value will allow the system to recover faster.
sql_alchemy_pool_recycle = 1800
# Check connection at the start of each connection pool checkout.
# Typically, this is a simple statement like "SELECT 1".
# More information here:
# https://docs.sqlalchemy.org/en/13/core/pooling.html#disconnect-handling-pessimistic
sql_alchemy_pool_pre_ping = True
# The schema to use for the metadata database.
# SqlAlchemy supports databases with the concept of multiple schemas.
sql_alchemy_schema =
# Import path for connect args in SqlAlchemy. Defaults to an empty dict.
# This is useful when you want to configure db engine args that SqlAlchemy won't parse
# in connection string.
# See https://docs.sqlalchemy.org/en/13/core/engines.html#sqlalchemy.create_engine.params.connect_args
# sql_alchemy_connect_args =
# This defines the maximum number of task instances that can run concurrently in Airflow
# regardless of scheduler count and worker count. Generally, this value is reflective of
# the number of task instances with the running state in the metadata database.
parallelism = 32
# The maximum number of task instances allowed to run concurrently in each DAG. To calculate
# the number of tasks that is running concurrently for a DAG, add up the number of running
# tasks for all DAG runs of the DAG. This is configurable at the DAG level with ``max_active_tasks``,
# which is defaulted as ``max_active_tasks_per_dag``.
#
# An example scenario when this would be useful is when you want to stop a new dag with an early
# start date from stealing all the executor slots in a cluster.
max_active_tasks_per_dag = 16
# Are DAGs paused by default at creation
dags_are_paused_at_creation = True
# The maximum number of active DAG runs per DAG. The scheduler will not create more DAG runs
# if it reaches the limit. This is configurable at the DAG level with ``max_active_runs``,
# which is defaulted as ``max_active_runs_per_dag``.
max_active_runs_per_dag = 16
# Whether to load the DAG examples that ship with Airflow. It's good to
# get started, but you probably want to set this to ``False`` in a production
# environment
load_examples = True
# Whether to load the default connections that ship with Airflow. It's good to
# get started, but you probably want to set this to ``False`` in a production
# environment
load_default_connections = True
# Path to the folder containing Airflow plugins
plugins_folder = /opt/airflow/plugins
# Should tasks be executed via forking of the parent process ("False",
# the speedier option) or by spawning a new python process ("True" slow,
# but means plugin changes picked up by tasks straight away)
execute_tasks_new_python_interpreter = False
# Secret key to save connection passwords in the db
fernet_key =
# Whether to disable pickling dags
donot_pickle = True
# How long before timing out a python file import
dagbag_import_timeout = 30.0
# Should a traceback be shown in the UI for dagbag import errors,
# instead of just the exception message
dagbag_import_error_tracebacks = True
# If tracebacks are shown, how many entries from the traceback should be shown
dagbag_import_error_traceback_depth = 2
# How long before timing out a DagFileProcessor, which processes a dag file
dag_file_processor_timeout = 50
# The class to use for running task instances in a subprocess.
# Choices include StandardTaskRunner, CgroupTaskRunner or the full import path to the class
# when using a custom task runner.
task_runner = StandardTaskRunner
# If set, tasks without a ``run_as_user`` argument will be run with this user
# Can be used to de-elevate a sudo user running Airflow when executing tasks
default_impersonation =
# What security module to use (for example kerberos)
security =
# Turn unit test mode on (overwrites many configuration options with test
# values at runtime)
unit_test_mode = False
# Whether to enable pickling for xcom (note that this is insecure and allows for
# RCE exploits).
enable_xcom_pickling = False
# When a task is killed forcefully, this is the amount of time in seconds that
# it has to cleanup after it is sent a SIGTERM, before it is SIGKILLED
killed_task_cleanup_time = 60
# Whether to override params with dag_run.conf. If you pass some key-value pairs
# through ``airflow dags backfill -c`` or
# ``airflow dags trigger -c``, the key-value pairs will override the existing ones in params.
dag_run_conf_overrides_params = True
# When discovering DAGs, ignore any files that don't contain the strings ``DAG`` and ``airflow``.
dag_discovery_safe_mode = True
# The number of retries each task is going to have by default. Can be overridden at dag or task level.
default_task_retries = 0
# The weighting method used for the effective total priority weight of the task
default_task_weight_rule = downstream
# Updating serialized DAG can not be faster than a minimum interval to reduce database write rate.
min_serialized_dag_update_interval = 30
# Fetching serialized DAG can not be faster than a minimum interval to reduce database
# read rate. This config controls when your DAGs are updated in the Webserver
min_serialized_dag_fetch_interval = 10
# Maximum number of Rendered Task Instance Fields (Template Fields) per task to store
# in the Database.
# All the template_fields for each of Task Instance are stored in the Database.
# Keeping this number small may cause an error when you try to view ``Rendered`` tab in
# TaskInstance view for older tasks.
max_num_rendered_ti_fields_per_task = 30
# On each dagrun check against defined SLAs
check_slas = True
# Path to custom XCom class that will be used to store and resolve operators results
# Example: xcom_backend = path.to.CustomXCom
xcom_backend = airflow.models.xcom.BaseXCom
# By default Airflow plugins are lazily-loaded (only loaded when required). Set it to ``False``,
# if you want to load plugins whenever 'airflow' is invoked via cli or loaded from module.
lazy_load_plugins = True
# By default Airflow providers are lazily-discovered (discovery and imports happen only when required).
# Set it to False, if you want to discover providers whenever 'airflow' is invoked via cli or
# loaded from module.
lazy_discover_providers = True
# Number of times the code should be retried in case of DB Operational Errors.
# Not all transactions will be retried as it can cause undesired state.
# Currently it is only used in ``DagFileProcessor.process_file`` to retry ``dagbag.sync_to_db``.
max_db_retries = 3
# Hide sensitive Variables or Connection extra json keys from UI and task logs when set to True
#
# (Connection passwords are always hidden in logs)
hide_sensitive_var_conn_fields = True
# A comma-separated list of extra sensitive keywords to look for in variables names or connection's
# extra JSON.
sensitive_var_conn_names =
# Task Slot counts for ``default_pool``. This setting would not have any effect in an existing
# deployment where the ``default_pool`` is already created. For existing deployments, users can
# change the number of slots using Webserver, API or the CLI
default_pool_task_slot_count = 128
[logging]
# The folder where airflow should store its log files.
# This path must be absolute.
# There are a few existing configurations that assume this is set to the default.
# If you choose to override this you may need to update the dag_processor_manager_log_location and
# dag_processor_manager_log_location settings as well.
base_log_folder = /opt/airflow/logs
# Airflow can store logs remotely in AWS S3, Google Cloud Storage or Elastic Search.
# Set this to True if you want to enable remote logging.
remote_logging = False
# Users must supply an Airflow connection id that provides access to the storage
# location.
remote_log_conn_id =
# Path to Google Credential JSON file. If omitted, authorization based on `the Application Default
# Credentials
# <https://cloud.google.com/docs/authentication/production#finding_credentials_automatically>`__ will
# be used.
google_key_path =
# Storage bucket URL for remote logging
# S3 buckets should start with "s3://"
# Cloudwatch log groups should start with "cloudwatch://"
# GCS buckets should start with "gs://"
# WASB buckets should start with "wasb" just to help Airflow select correct handler
# Stackdriver logs should start with "stackdriver://"
remote_base_log_folder =
# Use server-side encryption for logs stored in S3
encrypt_s3_logs = False
# Logging level.
#
# Supported values: ``CRITICAL``, ``ERROR``, ``WARNING``, ``INFO``, ``DEBUG``.
logging_level = INFO
# Logging level for Flask-appbuilder UI.
#
# Supported values: ``CRITICAL``, ``ERROR``, ``WARNING``, ``INFO``, ``DEBUG``.
fab_logging_level = WARNING
# Logging class
# Specify the class that will specify the logging configuration
# This class has to be on the python classpath
# Example: logging_config_class = my.path.default_local_settings.LOGGING_CONFIG
logging_config_class =
# Flag to enable/disable Colored logs in Console
# Colour the logs when the controlling terminal is a TTY.
colored_console_log = True
# Log format for when Colored logs is enabled
colored_log_format = [%%(blue)s%%(asctime)s%%(reset)s] {%%(blue)s%%(filename)s:%%(reset)s%%(lineno)d} %%(log_color)s%%(levelname)s%%(reset)s - %%(log_color)s%%(message)s%%(reset)s
colored_formatter_class = airflow.utils.log.colored_log.CustomTTYColoredFormatter
# Format of Log line
log_format = [%%(asctime)s] {
%%(filename)s:%%(lineno)d} %%(levelname)s - %%(message)s
simple_log_format = %%(asctime)s %%(levelname)s - %%(message)s
# Specify prefix pattern like mentioned below with stream handler TaskHandlerWithCustomFormatter
# Example: task_log_prefix_template = {ti.dag_id}-{ti.task_id}-{execution_date}-{try_number}
task_log_prefix_template =
# Formatting for how airflow generates file names/paths for each task run.
log_filename_template = {
{ ti.dag_id }}/{
{ ti.task_id }}/{
{ ts }}/{
{ try_number }}.log
# Formatting for how airflow generates file names for log
log_processor_filename_template = {
{ filename }}.log
# Full path of dag_processor_manager logfile.
dag_processor_manager_log_location = /opt/airflow/logs/dag_processor_manager/dag_processor_manager.log
# Name of handler to read task instance logs.
# Defaults to use ``task`` handler.
task_log_reader = task
# A comma\-separated list of third-party logger names that will be configured to print messages to
# consoles\.
# Example: extra_logger_names = connexion,sqlalchemy
extra_logger_names =
# When you start an airflow worker, airflow starts a tiny web server
# subprocess to serve the workers local log files to the airflow main
# web server, who then builds pages and sends them to users. This defines
# the port on which the logs are served. It needs to be unused, and open
# visible from the main web server to connect into the workers.
worker_log_server_port = 8793
[metrics]
# StatsD (https://github.com/etsy/statsd) integration settings.
# Enables sending metrics to StatsD.
statsd_on = False
statsd_host = localhost
statsd_port = 8125
statsd_prefix = airflow
# If you want to avoid sending all the available metrics to StatsD,
# you can configure an allow list of prefixes (comma separated) to send only the metrics that
# start with the elements of the list (e.g: "scheduler,executor,dagrun")
statsd_allow_list =
# A function that validate the statsd stat name, apply changes to the stat name if necessary and return
# the transformed stat name.
#
# The function should have the following signature:
# def func_name(stat_name: str) -> str:
stat_name_handler =
# To enable datadog integration to send airflow metrics.
statsd_datadog_enabled = False
# List of datadog tags attached to all metrics(e.g: key1:value1,key2:value2)
statsd_datadog_tags =
# If you want to utilise your own custom Statsd client set the relevant
# module path below.
# Note: The module path must exist on your PYTHONPATH for Airflow to pick it up
# statsd_custom_client_path =
[secrets]
# Full class name of secrets backend to enable (will precede env vars and metastore in search path)
# Example: backend = airflow.providers.amazon.aws.secrets.systems_manager.SystemsManagerParameterStoreBackend
backend =
# The backend_kwargs param is loaded into a dictionary and passed to __init__ of secrets backend class.
# See documentation for the secrets backend you are using. JSON is expected.
# Example for AWS Systems Manager ParameterStore:
# ``{"connections_prefix": "/airflow/connections", "profile_name": "default"}``
backend_kwargs =
[cli]
# In what way should the cli access the API. The LocalClient will use the
# database directly, while the json_client will use the api running on the
# webserver
api_client = airflow.api.client.local_client
# If you set web_server_url_prefix, do NOT forget to append it here, ex:
# ``endpoint_url = http://localhost:8080/myroot``
# So api will look like: ``http://localhost:8080/myroot/api/experimental/...``
endpoint_url = http://localhost:8080/airflow
[debug]
# Used only with ``DebugExecutor``. If set to ``True`` DAG will fail with first
# failed task. Helpful for debugging purposes.
fail_fast = False
[api]
# Enables the deprecated experimental API. Please note that these APIs do not have access control.
# The authenticated user has full access.
#
# .. warning::
#
# This `Experimental REST API <https://airflow.readthedocs.io/en/latest/rest-api-ref.html>`__ is
# deprecated since version 2.0. Please consider using
# `the Stable REST API <https://airflow.readthedocs.io/en/latest/stable-rest-api-ref.html>`__.
# For more information on migration, see
# `UPDATING.md <https://github.com/apache/airflow/blob/main/UPDATING.md>`_
enable_experimental_api = False
# How to authenticate users of the API. See
# https://airflow.apache.org/docs/apache-airflow/stable/security.html for possible values.
# ("airflow.api.auth.backend.default" allows all requests for historic reasons)
auth_backend = airflow.api.auth.backend.deny_all
# Used to set the maximum page limit for API requests
maximum_page_limit = 100
# Used to set the default page limit when limit is zero. A default limit
# of 100 is set on OpenApi spec. However, this particular default limit
# only work when limit is set equal to zero(0) from API requests.
# If no limit is supplied, the OpenApi spec default is used.
fallback_page_limit = 100
# The intended audience for JWT token credentials used for authorization. This value must match on the client and server sides. If empty, audience will not be tested.
# Example: google_oauth2_audience = project-id-random-value.apps.googleusercontent.com
google_oauth2_audience =
# Path to Google Cloud Service Account key file (JSON). If omitted, authorization based on
# `the Application Default Credentials
# <https://cloud.google.com/docs/authentication/production#finding_credentials_automatically>`__ will
# be used.
# Example: google_key_path = /files/service-account-json
google_key_path =
# Used in response to a preflight request to indicate which HTTP
# headers can be used when making the actual request. This header is
# the server side response to the browser's
# Access-Control-Request-Headers header.
access_control_allow_headers =
# Specifies the method or methods allowed when accessing the resource.
access_control_allow_methods =
# Indicates whether the response can be shared with requesting code from the given origins.
# Separate URLs with space.
access_control_allow_origins =
[lineage]
# what lineage backend to use
backend =
[atlas]
sasl_enabled = False
host =
port = 21000
username =
password =
[operators]
# The default owner assigned to each new operator, unless
# provided explicitly or passed via ``default_args``
default_owner = airflow
default_cpus = 1
default_ram = 512
default_disk = 512
default_gpus = 0
# Default queue that tasks get assigned to and that worker listen on.
default_queue = default
# Is allowed to pass additional/unused arguments (args, kwargs) to the BaseOperator operator.
# If set to False, an exception will be thrown, otherwise only the console message will be displayed.
allow_illegal_arguments = False
[hive]
# Default mapreduce queue for HiveOperator tasks
default_hive_mapred_queue =
# Template for mapred_job_name in HiveOperator, supports the following named parameters
# hostname, dag_id, task_id, execution_date
# mapred_job_name_template =
[webserver]
# The base url of your website as airflow cannot guess what domain or
# cname you are using. This is used in automated emails that
# airflow sends to point links to the right web server
base_url = http://localhost:8080/airflow
authenticate = False
# Default timezone to display all dates in the UI, can be UTC, system, or
# any IANA timezone string (e.g. Europe/Amsterdam). If left empty the
# default value of core/default_timezone will be used
# Example: default_ui_timezone = America/New_York
default_ui_timezone = UTC
# The ip specified when starting the web server
web_server_host = 0.0.0.0
# The port on which to run the web server
web_server_port = 8080
# Paths to the SSL certificate and key for the web server. When both are
# provided SSL will be enabled. This does not change the web server port.
web_server_ssl_cert =
# Paths to the SSL certificate and key for the web server. When both are
# provided SSL will be enabled. This does not change the web server port.
web_server_ssl_key =
# Number of seconds the webserver waits before killing gunicorn master that doesn't respond
web_server_master_timeout = 120
# Number of seconds the gunicorn webserver waits before timing out on a worker
web_server_worker_timeout = 120
# Number of workers to refresh at a time. When set to 0, worker refresh is
# disabled. When nonzero, airflow periodically refreshes webserver workers by
# bringing up new ones and killing old ones.
worker_refresh_batch_size = 1
# Number of seconds to wait before refreshing a batch of workers.
worker_refresh_interval = 6000
# If set to True, Airflow will track files in plugins_folder directory. When it detects changes,
# then reload the gunicorn.
reload_on_plugin_change = False
# Secret key used to run your flask app. It should be as random as possible. However, when running
# more than 1 instances of webserver, make sure all of them use the same ``secret_key`` otherwise
# one of them will error with "CSRF session token is missing".
secret_key = UNZrpq4hSNDXVICm4Tbe8Q==
# Number of workers to run the Gunicorn web server
workers = 4
# The worker class gunicorn should use. Choices include
# sync (default), eventlet, gevent
worker_class = sync
# Log files for the gunicorn webserver. '-' means log to stderr.
access_logfile = -
# Log files for the gunicorn webserver. '-' means log to stderr.
error_logfile = -
# Access log format for gunicorn webserver.
# default format is %%(h)s %%(l)s %%(u)s %%(t)s "%%(r)s" %%(s)s %%(b)s "%%(f)s" "%%(a)s"
# documentation - https://docs.gunicorn.org/en/stable/settings.html#access-log-format
access_logformat =
# Expose the configuration file in the web server
expose_config = False
# Expose hostname in the web server
expose_hostname = True
# Expose stacktrace in the web server
expose_stacktrace = True
# Default DAG view. Valid values are: ``tree``, ``graph``, ``duration``, ``gantt``, ``landing_times``
dag_default_view = tree
# Default DAG orientation. Valid values are:
# ``LR`` (Left->Right), ``TB`` (Top->Bottom), ``RL`` (Right->Left), ``BT`` (Bottom->Top)
dag_orientation = LR
# The amount of time (in secs) webserver will wait for initial handshake
# while fetching logs from other worker machine
log_fetch_timeout_sec = 5
# Time interval (in secs) to wait before next log fetching.
log_fetch_delay_sec = 2
# Distance away from page bottom to enable auto tailing.
log_auto_tailing_offset = 30
# Animation speed for auto tailing log display.
log_animation_speed = 1000
# By default, the webserver shows paused DAGs. Flip this to hide paused
# DAGs by default
hide_paused_dags_by_default = False
# Consistent page size across all listing views in the UI
page_size = 100
# Define the color of navigation bar
navbar_color = #fff
# Default dagrun to show in UI
default_dag_run_display_number = 25
# Enable werkzeug ``ProxyFix`` middleware for reverse proxy
#enable_proxy_fix = False
enable_proxy_fix = True
# Number of values to trust for ``X-Forwarded-For``.
# More info: https://werkzeug.palletsprojects.com/en/0.16.x/middleware/proxy_fix/
proxy_fix_x_for = 1
# Number of values to trust for ``X-Forwarded-Proto``
proxy_fix_x_proto = 1
# Number of values to trust for ``X-Forwarded-Host``
proxy_fix_x_host = 1
# Number of values to trust for ``X-Forwarded-Port``
proxy_fix_x_port = 1
# Number of values to trust for ``X-Forwarded-Prefix``
proxy_fix_x_prefix = 1
# Set secure flag on session cookie
cookie_secure = False
# Set samesite policy on session cookie
cookie_samesite = Lax
# Default setting for wrap toggle on DAG code and TI log views.
default_wrap = False
# Allow the UI to be rendered in a frame
x_frame_enabled = True
# Send anonymous user activity to your analytics tool
# choose from google_analytics, segment, or metarouter
# analytics_tool =
# Unique ID of your account in the analytics tool
# analytics_id =
# 'Recent Tasks' stats will show for old DagRuns if set
show_recent_stats_for_completed_runs = True
# Update FAB permissions and sync security manager roles
# on webserver startup
update_fab_perms = True
# The UI cookie lifetime in minutes. User will be logged out from UI after
# ``session_lifetime_minutes`` of non-activity
session_lifetime_minutes = 43200
# Sets a custom page title for the DAGs overview page and site title for all pages
# instance_name =
# How frequently, in seconds, the DAG data will auto-refresh in graph or tree view
# when auto-refresh is turned on
auto_refresh_interval = 3
[email]
# Configuration email backend and whether to
# send email alerts on retry or failure
# Email backend to use
email_backend = airflow.utils.email.send_email_smtp
# Email connection to use
email_conn_id = smtp_default
# Whether email alerts should be sent when a task is retried
default_email_on_retry = True
# Whether email alerts should be sent when a task failed
default_email_on_failure = True
# File that will be used as the template for Email subject (which will be rendered using Jinja2).
# If not set, Airflow uses a base template.
# Example: subject_template = /path/to/my_subject_template_file
# subject_template =
# File that will be used as the template for Email content (which will be rendered using Jinja2).
# If not set, Airflow uses a base template.
# Example: html_content_template = /path/to/my_html_content_template_file
# html_content_template =
[smtp]
# If you want airflow to send emails on retries, failure, and you want to use
# the airflow.utils.email.send_email_smtp function, you have to configure an
# smtp server here
smtp_host = localhost
smtp_starttls = True
smtp_ssl = False
# Example: smtp_user = airflow
# smtp_user =
# Example: smtp_password = airflow
# smtp_password =
smtp_port = 25
smtp_mail_from = airflow@example.com
smtp_timeout = 30
smtp_retry_limit = 5
[sentry]
# Sentry (https://docs.sentry.io) integration. Here you can supply
# additional configuration options based on the Python platform. See:
# https://docs.sentry.io/error-reporting/configuration/?platform=python.
# Unsupported options: ``integrations``, ``in_app_include``, ``in_app_exclude``,
# ``ignore_errors``, ``before_breadcrumb``, ``transport``.
# Enable error reporting to Sentry
sentry_on = false
sentry_dsn =
# Dotted path to a before_send function that the sentry SDK should be configured to use.
# before_send =
[celery_kubernetes_executor]
# This section only applies if you are using the ``CeleryKubernetesExecutor`` in
# ``[core]`` section above
# Define when to send a task to ``KubernetesExecutor`` when using ``CeleryKubernetesExecutor``.
# When the queue of a task is the value of ``kubernetes_queue`` (default ``kubernetes``),
# the task is executed via ``KubernetesExecutor``,
# otherwise via ``CeleryExecutor``
kubernetes_queue = kubernetes
[celery]
# This section only applies if you are using the CeleryExecutor in
# ``[core]`` section above
# The app name that will be used by celery
celery_app_name = airflow.executors.celery_executor
# The concurrency that will be used when starting workers with the
# ``airflow celery worker`` command. This defines the number of task instances that
# a worker will take, so size up your workers based on the resources on
# your worker box and the nature of your tasks
worker_concurrency = 16
# The maximum and minimum concurrency that will be used when starting workers with the
# ``airflow celery worker`` command (always keep minimum processes, but grow
# to maximum if necessary). Note the value should be max_concurrency,min_concurrency
# Pick these numbers based on resources on worker box and the nature of the task.
# If autoscale option is available, worker_concurrency will be ignored.
# http://docs.celeryproject.org/en/latest/reference/celery.bin.worker.html#cmdoption-celery-worker-autoscale
# Example: worker_autoscale = 16,12
# worker_autoscale =
# Used to increase the number of tasks that a worker prefetches which can improve performance.
# The number of processes multiplied by worker_prefetch_multiplier is the number of tasks
# that are prefetched by a worker. A value greater than 1 can result in tasks being unnecessarily
# blocked if there are multiple workers and one worker prefetches tasks that sit behind long
# running tasks while another worker has unutilized processes that are unable to process the already
# claimed blocked tasks.
# https://docs.celeryproject.org/en/stable/userguide/optimizing.html#prefetch-limits
# Example: worker_prefetch_multiplier = 1
# worker_prefetch_multiplier =
# Umask that will be used when starting workers with the ``airflow celery worker``
# in daemon mode. This control the file-creation mode mask which determines the initial
# value of file permission bits for newly created files.
worker_umask = 0o077
# The Celery broker URL. Celery supports RabbitMQ, Redis and experimentally
# a sqlalchemy database. Refer to the Celery documentation for more information.
broker_url = redis://redis:6379/0
# The Celery result_backend. When a job finishes, it needs to update the
# metadata of the job. Therefore it will post a message on a message bus,
# or insert it into a database (depending of the backend)
# This status is used by the scheduler to update the state of the task
# The use of a database is highly recommended
# http://docs.celeryproject.org/en/latest/userguide/configuration.html#task-result-backend-settings
result_backend = db+postgresql://postgres:airflow@postgres/airflow
#result_backend = db+mysql://airflow_user:[email protected]:3305/airflow_db
# Celery Flower is a sweet UI for Celery. Airflow has a shortcut to start
# it ``airflow celery flower``. This defines the IP that Celery Flower runs on
flower_host = 0.0.0.0
# The root URL for Flower
# Example: flower_url_prefix = /flower
flower_url_prefix =
# This defines the port that Celery Flower runs on
flower_port = 5555
# Securing Flower with Basic Authentication
# Accepts user:password pairs separated by a comma
# Example: flower_basic_auth = user1:password1,user2:password2
flower_basic_auth =
# How many processes CeleryExecutor uses to sync task state.
# 0 means to use max(1, number of cores - 1) processes.
sync_parallelism = 0
# Import path for celery configuration options
celery_config_options = airflow.config_templates.default_celery.DEFAULT_CELERY_CONFIG
ssl_active = False
ssl_key =
ssl_cert =
ssl_cacert =
# Celery Pool implementation.
# Choices include: ``prefork`` (default), ``eventlet``, ``gevent`` or ``solo``.
# See:
# https://docs.celeryproject.org/en/latest/userguide/workers.html#concurrency
# https://docs.celeryproject.org/en/latest/userguide/concurrency/eventlet.html
pool = prefork
# The number of seconds to wait before timing out ``send_task_to_executor`` or
# ``fetch_celery_task_state`` operations.
operation_timeout = 1.0
# Celery task will report its status as 'started' when the task is executed by a worker.
# This is used in Airflow to keep track of the running tasks and if a Scheduler is restarted
# or run in HA mode, it can adopt the orphan tasks launched by previous SchedulerJob.
task_track_started = True
# Time in seconds after which Adopted tasks are cleared by CeleryExecutor. This is helpful to clear
# stalled tasks.
task_adoption_timeout = 600
# The Maximum number of retries for publishing task messages to the broker when failing
# due to ``AirflowTaskTimeout`` error before giving up and marking Task as failed.
task_publish_max_retries = 3
# Worker initialisation check to validate Metadata Database connection
worker_precheck = False
[celery_broker_transport_options]
# This section is for specifying options which can be passed to the
# underlying celery broker transport. See:
# http://docs.celeryproject.org/en/latest/userguide/configuration.html#std:setting-broker_transport_options
# The visibility timeout defines the number of seconds to wait for the worker
# to acknowledge the task before the message is redelivered to another worker.
# Make sure to increase the visibility timeout to match the time of the longest
# ETA you're planning to use.
# visibility_timeout is only supported for Redis and SQS celery brokers.
# See:
# http://docs.celeryproject.org/en/master/userguide/configuration.html#std:setting-broker_transport_options
# Example: visibility_timeout = 21600
# visibility_timeout =
[dask]
# This section only applies if you are using the DaskExecutor in
# [core] section above
# The IP address and port of the Dask cluster's scheduler.
cluster_address = 127.0.0.1:8786
# TLS/ SSL settings to access a secured Dask scheduler.
tls_ca =
tls_cert =
tls_key =
[scheduler]
# Task instances listen for external kill signal (when you clear tasks
# from the CLI or the UI), this defines the frequency at which they should
# listen (in seconds).
job_heartbeat_sec = 5
# The scheduler constantly tries to trigger new tasks (look at the
# scheduler section in the docs for more information). This defines
# how often the scheduler should run (in seconds).
scheduler_heartbeat_sec = 5
# The number of times to try to schedule each DAG file
# -1 indicates unlimited number
num_runs = -1
# Controls how long the scheduler will sleep between loops, but if there was nothing to do
# in the loop. i.e. if it scheduled something then it will start the next loop
# iteration straight away.
scheduler_idle_sleep_time = 1
# Number of seconds after which a DAG file is parsed. The DAG file is parsed every
# ``min_file_process_interval`` number of seconds. Updates to DAGs are reflected after
# this interval. Keeping this number low will increase CPU usage.
min_file_process_interval = 30
# How often (in seconds) to scan the DAGs directory for new files. Default to 5 minutes.
dag_dir_list_interval = 300
# How often should stats be printed to the logs. Setting to 0 will disable printing stats
print_stats_interval = 30
# How often (in seconds) should pool usage stats be sent to statsd (if statsd_on is enabled)
pool_metrics_interval = 5.0
# If the last scheduler heartbeat happened more than scheduler_health_check_threshold
# ago (in seconds), scheduler is considered unhealthy.
# This is used by the health check in the "/health" endpoint
scheduler_health_check_threshold = 30
# How often (in seconds) should the scheduler check for orphaned tasks and SchedulerJobs
orphaned_tasks_check_interval = 300.0
child_process_log_directory = /opt/airflow/logs/scheduler
# Local task jobs periodically heartbeat to the DB. If the job has
# not heartbeat in this many seconds, the scheduler will mark the
# associated task instance as failed and will re-schedule the task.
scheduler_zombie_task_threshold = 300
# Turn off scheduler catchup by setting this to ``False``.
# Default behavior is unchanged and
# Command Line Backfills still work, but the scheduler
# will not do scheduler catchup if this is ``False``,
# however it can be set on a per DAG basis in the
# DAG definition (catchup)
catchup_by_default = True
# This changes the batch size of queries in the scheduling main loop.
# If this is too high, SQL query performance may be impacted by
# complexity of query predicate, and/or excessive locking.
# Additionally, you may hit the maximum allowable query length for your db.
# Set this to 0 for no limit (not advised)
max_tis_per_query = 512
# Should the scheduler issue ``SELECT ... FOR UPDATE`` in relevant queries.
# If this is set to False then you should not run more than a single
# scheduler at once
use_row_level_locking = True
# Max number of DAGs to create DagRuns for per scheduler loop.
max_dagruns_to_create_per_loop = 10
# How many DagRuns should a scheduler examine (and lock) when scheduling
# and queuing tasks.
max_dagruns_per_loop_to_schedule = 20
# Should the Task supervisor process perform a "mini scheduler" to attempt to schedule more tasks of the
# same DAG. Leaving this on will mean tasks in the same DAG execute quicker, but might starve out other
# dags in some circumstances
schedule_after_task_execution = True
# The scheduler can run multiple processes in parallel to parse dags.
# This defines how many processes will run.
parsing_processes = 2
# One of ``modified_time``, ``random_seeded_by_host`` and ``alphabetical``.
# The scheduler will list and sort the dag files to decide the parsing order.
#
# * ``modified_time``: Sort by modified time of the files. This is useful on large scale to parse the
# recently modified DAGs first.
# * ``random_seeded_by_host``: Sort randomly across multiple Schedulers but with same order on the
# same host. This is useful when running with Scheduler in HA mode where each scheduler can
# parse different DAG files.
# * ``alphabetical``: Sort by filename
file_parsing_sort_mode = modified_time
# Turn off scheduler use of cron intervals by setting this to False.
# DAGs submitted manually in the web UI or with trigger_dag will still run.
use_job_schedule = True
# Allow externally triggered DagRuns for Execution Dates in the future
# Only has effect if schedule_interval is set to None in DAG
allow_trigger_in_future = False
# DAG dependency detector class to use
dependency_detector = airflow.serialization.serialized_objects.DependencyDetector
# How often to check for expired trigger requests that have not run yet.
trigger_timeout_check_interval = 15
[triggerer]
# How many triggers a single Triggerer will run at once, by default.
default_capacity = 1000
[kerberos]
ccache = /tmp/airflow_krb5_ccache
# gets augmented with fqdn
principal = airflow
reinit_frequency = 3600
kinit_path = kinit
keytab = airflow.keytab
# Allow to disable ticket forwardability.
forwardable = True
# Allow to remove source IP from token, useful when using token behind NATted Docker host.
include_ip = True
[github_enterprise]
api_rev = v3
[elasticsearch]
# Elasticsearch host
host =
# Format of the log_id, which is used to query for a given tasks logs
log_id_template = {
dag_id}-{
task_id}-{
execution_date}-{
try_number}
# Used to mark the end of a log stream for a task
end_of_log_mark = end_of_log
# Qualified URL for an elasticsearch frontend (like Kibana) with a template argument for log_id
# Code will construct log_id using the log_id template from the argument above.
# NOTE: scheme will default to https if one is not provided
# Example: frontend = http://localhost:5601/app/kibana#/discover?_a=(columns:!(message),query:(language:kuery,query:'log_id: "{log_id}"'),sort:!(log.offset,asc))
frontend =
# Write the task logs to the stdout of the worker, rather than the default files
write_stdout = False
# Instead of the default log formatter, write the log lines as JSON
json_format = False
# Log fields to also attach to the json output, if enabled
json_fields = asctime, filename, lineno, levelname, message
# The field where host name is stored (normally either `host` or `host.name`)
host_field = host
# The field where offset is stored (normally either `offset` or `log.offset`)
offset_field = offset
[elasticsearch_configs]
use_ssl = False
verify_certs = True
[kubernetes]
# Path to the YAML pod file that forms the basis for KubernetesExecutor workers.
pod_template_file =
# The repository of the Kubernetes Image for the Worker to Run
worker_container_repository =
# The tag of the Kubernetes Image for the Worker to Run
worker_container_tag =
# The Kubernetes namespace where airflow workers should be created. Defaults to ``default``
namespace = default
# If True, all worker pods will be deleted upon termination
delete_worker_pods = True
# If False (and delete_worker_pods is True),
# failed worker pods will not be deleted so users can investigate them.
# This only prevents removal of worker pods where the worker itself failed,
# not when the task it ran failed.
delete_worker_pods_on_failure = False
# Number of Kubernetes Worker Pod creation calls per scheduler loop.
# Note that the current default of "1" will only launch a single pod
# per-heartbeat. It is HIGHLY recommended that users increase this
# number to match the tolerance of their kubernetes cluster for
# better performance.
worker_pods_creation_batch_size = 1
# Allows users to launch pods in multiple namespaces.
# Will require creating a cluster-role for the scheduler
multi_namespace_mode = False
# Use the service account kubernetes gives to pods to connect to kubernetes cluster.
# It's intended for clients that expect to be running inside a pod running on kubernetes.
# It will raise an exception if called from a process not running in a kubernetes environment.
in_cluster = True
# When running with in_cluster=False change the default cluster_context or config_file
# options to Kubernetes client. Leave blank these to use default behaviour like ``kubectl`` has.
# cluster_context =
# Path to the kubernetes configfile to be used when ``in_cluster`` is set to False
# config_file =
# Keyword parameters to pass while calling a kubernetes client core_v1_api methods
# from Kubernetes Executor provided as a single line formatted JSON dictionary string.
# List of supported params are similar for all core_v1_apis, hence a single config
# variable for all apis. See:
# https://raw.githubusercontent.com/kubernetes-client/python/41f11a09995efcd0142e25946adc7591431bfb2f/kubernetes/client/api/core_v1_api.py
kube_client_request_args =
# Optional keyword arguments to pass to the ``delete_namespaced_pod`` kubernetes client
# ``core_v1_api`` method when using the Kubernetes Executor.
# This should be an object and can contain any of the options listed in the ``v1DeleteOptions``
# class defined here:
# https://github.com/kubernetes-client/python/blob/41f11a09995efcd0142e25946adc7591431bfb2f/kubernetes/client/models/v1_delete_options.py#L19
# Example: delete_option_kwargs = {"grace_period_seconds": 10}
delete_option_kwargs =
# Enables TCP keepalive mechanism. This prevents Kubernetes API requests to hang indefinitely
# when idle connection is time-outed on services like cloud load balancers or firewalls.
enable_tcp_keepalive = True
# When the `enable_tcp_keepalive` option is enabled, TCP probes a connection that has
# been idle for `tcp_keep_idle` seconds.
tcp_keep_idle = 120
# When the `enable_tcp_keepalive` option is enabled, if Kubernetes API does not respond
# to a keepalive probe, TCP retransmits the probe after `tcp_keep_intvl` seconds.
tcp_keep_intvl = 30
# When the `enable_tcp_keepalive` option is enabled, if Kubernetes API does not respond
# to a keepalive probe, TCP retransmits the probe `tcp_keep_cnt number` of times before
# a connection is considered to be broken.
tcp_keep_cnt = 6
# Set this to false to skip verifying SSL certificate of Kubernetes python client.
verify_ssl = True
# How long in seconds a worker can be in Pending before it is considered a failure
worker_pods_pending_timeout = 300
# How often in seconds to check if Pending workers have exceeded their timeouts
worker_pods_pending_timeout_check_interval = 120
# How often in seconds to check for task instances stuck in "queued" status without a pod
worker_pods_queued_check_interval = 60
# How many pending pods to check for timeout violations in each check interval.
# You may want this higher if you have a very large cluster and/or use ``multi_namespace_mode``.
worker_pods_pending_timeout_batch_size = 100
[smart_sensor]
# When `use_smart_sensor` is True, Airflow redirects multiple qualified sensor tasks to
# smart sensor task.
use_smart_sensor = False
# `shard_code_upper_limit` is the upper limit of `shard_code` value. The `shard_code` is generated
# by `hashcode % shard_code_upper_limit`.
shard_code_upper_limit = 10000
# The number of running smart sensor processes for each service.
shards = 5
# comma separated sensor classes support in smart_sensor.
sensors_enabled = NamedHivePartitionSensor
2.1、如果想修改WEB URL地址,需要修改airflow.cfg中以下两个地方
URL地址后添加path为/airflow
第一处 【cli】下
[cli]
# 如果想在访问地址后加Path可以修改成如下,默认http://localhost:8080
endpoint_url = http://localhost:8080/airflow
第二处【webserver】下
[webserver]
# 与cli下的rul修改成一致的
base_url = http://localhost:8080/airflow
3、之后up -d直接启动即可
docker-compose -f airflow-docker-compose.yml up -d
web访问地址:
webserver is http://localhost:8080
监控web is http://localhost:5555
二、存储数据库更换postgres -->myslq
注意mysql数据库需要自己安装,或是连接已存在的数据库都可以。docker安装mysql可以参考此文章,创建用户以及权限修改可以参考此文章
您需要创建一个数据库和一个数据库用户,Airflow将使用该数据库访问该数据库。在下面的例子中,将创建一个数据库airflow_db和用户名airflow_user和密码airflow_pass的用户。记住库名、用户名、密码不要自己随便更改一定 使用如下的配置
CREATE DATABASE airflow_db CHARACTER SET utf8 COLLATE utf8mb4_unicode_ci;
CREATE USER 'airflow_user' IDENTIFIED BY 'airflow_pass';
GRANT ALL PRIVILEGES ON airflow_db.* TO 'airflow_user';
1、连接mysql数据库的docker-compose.yaml配置文件如下
1、更换了环境变量中数据库的连接配置;2、删除了postres的相关配置
airflow-docker-compose.yml
---
version: '3'
x-airflow-common:
&airflow-common
image: ${
AIRFLOW_IMAGE_NAME:-apache/airflow:2.2.3}
# build: .
environment:
&airflow-common-env
AIRFLOW__CORE__EXECUTOR: CeleryExecutor
#AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
#AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CORE__SQL_ALCHEMY_CONN: mysql://airflow_user:[email protected]:3305/airflow_db
AIRFLOW__CELERY__RESULT_BACKEND: db+mysql://airflow_user:[email protected]:3305/airflow_db
AIRFLOW__CELERY__BROKER_URL: redis://:@redis:6379/0
AIRFLOW__CORE__FERNET_KEY: ''
AIRFLOW__CORE__DAGS_ARE_PAUSED_AT_CREATION: 'true'
AIRFLOW__CORE__LOAD_EXAMPLES: 'true'
#AIRFLOW__WEBSERVER__BASE_URL: 'http://146.11.56.127:8080/airflow'
#AIRFLOW__WEBSERVER__X_FRAME_ENABLED: 'True'
AIRFLOW__API__AUTH_BACKEND: 'airflow.api.auth.backend.basic_auth'
#AUTH_ROLE_PUBLIC: 'Admin'
# AIRFLOW__CLI__ENDPOINT_URL: 'http://localhost:8080/airflow'
AIRFLOW__WEBSERVER__ENABLE_PROXY_FIX: 'True'
_PIP_ADDITIONAL_REQUIREMENTS: ${
_PIP_ADDITIONAL_REQUIREMENTS:-}
volumes:
- ./dags:/opt/airflow/dags
- ./logs:/opt/airflow/logs
- ./plugins:/opt/airflow/plugins
- ./airflow.cfg:/opt/airflow/airflow.cfg
user: "${AIRFLOW_UID:-50000}:0"
depends_on:
&airflow-common-depends-on
redis:
condition: service_healthy
#postgres:
# condition: service_healthy
services:
redis:
image: redis:latest
expose:
- 6379
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 30s
retries: 50
restart: always
airflow-webserver:
<<: *airflow-common
command: webserver
ports:
- 8080:8080
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:8080/health"]
interval: 10s
timeout: 10s
retries: 5
restart: always
#volumes:
# - /var/opt/tools/airflow/airflow.cfg:/opt/airflow/airflow.cfg
#labels:
# - "traefik.frontend.rule=Host:jpyocndd127.jp.ao.ericsson.se;Path:/airflow"
#- "traefik.port=8080"
# - "traefik.backend="
# - "traefik.enable=true"
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-scheduler:
<<: *airflow-common
command: scheduler
healthcheck:
test: ["CMD-SHELL", 'airflow jobs check --job-type SchedulerJob --hostname "$${HOSTNAME}"']
interval: 10s
timeout: 10s
retries: 5
restart: always
#labels:
# - "traefik.frontend.rule=Host:jpyocndd127.jp.ao.ericsson.se; PathPrefixStrip:/airflow;"
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-worker:
<<: *airflow-common
command: celery worker
healthcheck:
test:
- "CMD-SHELL"
- 'celery --app airflow.executors.celery_executor.app inspect ping -d "celery@$${HOSTNAME}"'
interval: 10s
timeout: 10s
retries: 5
#labels:
# - "traefik.frontend.rule=Host:jpyocndd127.jp.ao.ericsson.se; PathPrefixStrip:/airflow;"
environment:
<<: *airflow-common-env
# Required to handle warm shutdown of the celery workers properly
# See https://airflow.apache.org/docs/docker-stack/entrypoint.html#signal-propagation
DUMB_INIT_SETSID: "0"
restart: always
#volumes:
# - /var/opt/tools/airflow/airflow.cfg:/opt/airflow/airflow.cfg
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-triggerer:
<<: *airflow-common
command: triggerer
healthcheck:
test: ["CMD-SHELL", 'airflow jobs check --job-type TriggererJob --hostname "$${HOSTNAME}"']
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
airflow-init:
<<: *airflow-common
entrypoint: /bin/bash
# yamllint disable rule:line-length
command:
- -c
- |
function ver() {
printf "%04d%04d%04d%04d" $${1//./ }
}
airflow_version=$$(gosu airflow airflow version)
airflow_version_comparable=$$(ver $${airflow_version})
min_airflow_version=2.2.0
min_airflow_version_comparable=$$(ver $${min_airflow_version})
if (( airflow_version_comparable < min_airflow_version_comparable )); then
echo
echo -e "\033[1;31mERROR!!!: Too old Airflow version $${airflow_version}!\e[0m"
echo "The minimum Airflow version supported: $${min_airflow_version}. Only use this or higher!"
echo
exit 1
fi
if [[ -z "${AIRFLOW_UID}" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: AIRFLOW_UID not set!\e[0m"
echo "If you are on Linux, you SHOULD follow the instructions below to set "
echo "AIRFLOW_UID environment variable, otherwise files will be owned by root."
echo "For other operating systems you can get rid of the warning with manually created .env file:"
echo " See: https://airflow.apache.org/docs/apache-airflow/stable/start/docker.html#setting-the-right-airflow-user"
echo
fi
one_meg=1048576
mem_available=$$(($$(getconf _PHYS_PAGES) * $$(getconf PAGE_SIZE) / one_meg))
cpus_available=$$(grep -cE 'cpu[0-9]+' /proc/stat)
disk_available=$$(df / | tail -1 | awk '{print $$4}')
warning_resources="false"
if (( mem_available < 4000 )) ; then
echo
echo -e "\033[1;33mWARNING!!!: Not enough memory available for Docker.\e[0m"
echo "At least 4GB of memory required. You have $$(numfmt --to iec $$((mem_available * one_meg)))"
echo
warning_resources="true"
fi
if (( cpus_available < 2 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough CPUS available for Docker.\e[0m"
echo "At least 2 CPUs recommended. You have $${cpus_available}"
echo
warning_resources="true"
fi
if (( disk_available < one_meg * 10 )); then
echo
echo -e "\033[1;33mWARNING!!!: Not enough Disk space available for Docker.\e[0m"
echo "At least 10 GBs recommended. You have $$(numfmt --to iec $$((disk_available * 1024 )))"
echo
warning_resources="true"
fi
if [[ $${warning_resources} == "true" ]]; then
echo
echo -e "\033[1;33mWARNING!!!: You have not enough resources to run Airflow (see above)!\e[0m"
echo "Please follow the instructions to increase amount of resources available:"
echo " https://airflow.apache.org/docs/apache-airflow/stable/start/docker.html#before-you-begin"
echo
fi
mkdir -p /sources/logs /sources/dags /sources/plugins
chown -R "${AIRFLOW_UID}:0" /sources/{logs,dags,plugins}
exec /entrypoint airflow version
# yamllint enable rule:line-length
environment:
<<: *airflow-common-env
_AIRFLOW_DB_UPGRADE: 'true'
_AIRFLOW_WWW_USER_CREATE: 'true'
_AIRFLOW_WWW_USER_USERNAME: ${
_AIRFLOW_WWW_USER_USERNAME:-airflow}
_AIRFLOW_WWW_USER_PASSWORD: ${
_AIRFLOW_WWW_USER_PASSWORD:-airflow}
user: "0:0"
#labels:
# - "traefik.frontend.rule=Host:jpyocndd127.jp.ao.ericsson.se; PathPrefixStrip:/airflow;"
volumes:
- .:/sources
airflow-cli:
<<: *airflow-common
profiles:
- debug
environment:
<<: *airflow-common-env
CONNECTION_CHECK_MAX_COUNT: "0"
# Workaround for entrypoint issue. See: https://github.com/apache/airflow/issues/16252
#labels:
# - "traefik.frontend.rule=Host:jpyocndd127.jp.ao.ericsson.se; PathPrefixStrip:/airflow;"
command:
- bash
- -c
- airflow
flower:
<<: *airflow-common
command: celery flower
ports:
- 5555:5555
healthcheck:
test: ["CMD", "curl", "--fail", "http://localhost:5555/"]
interval: 10s
timeout: 10s
retries: 5
restart: always
depends_on:
<<: *airflow-common-depends-on
airflow-init:
condition: service_completed_successfully
#volumes:
# postgres-db-volume:
更换数据库为mysl,上面docker-compose.yaml配置文件修改位置如下。
……
#AIRFLOW__CORE__SQL_ALCHEMY_CONN: postgresql+psycopg2://airflow:airflow@postgres/airflow
#AIRFLOW__CELERY__RESULT_BACKEND: db+postgresql://airflow:airflow@postgres/airflow
AIRFLOW__CORE__SQL_ALCHEMY_CONN: mysql://airflow_user:[email protected]:3305/airflow_db
AIRFLOW__CELERY__RESULT_BACKEND: db+mysql://airflow_user:[email protected]:3305/airflow_db
2、配置mysql数据库需要把airflow.cfg中的下面这个参数修改为mysql的链接
……
#sql_alchemy_conn = sqlite:opt/airflow/airflow.db
sql_alchemy_conn = mysql://airflow_user:airflow_pass@146.11.56.127:3305/airflow_db
……
#result_backend = db+postgresql://postgres:airflow@postgres/airflow
result_backend = db+mysql://airflow_user:airflow_pass@1.11.1.127:3305/airflow_db
3、启动docker-compose即可
docker-compose -f airflow-docker-compose.yml down
docker-compose -f airflow-docker-compose.yml up -d
三、配置LADP登录
1、修改配置文件webserver_config.py:
配置文件如下
"""Default configuration for the Airflow webserver"""
import os
#from airflow.www.fab_security.manager import AUTH_DB
from airflow.www.fab_security.manager import AUTH_LDAP
# from airflow.www.fab_security.manager import AUTH_OAUTH
# from airflow.www.fab_security.manager import AUTH_OID
# from airflow.www.fab_security.manager import AUTH_REMOTE_USER
basedir = os.path.abspath(os.path.dirname(__file__))
# Flask-WTF flag for CSRF
WTF_CSRF_ENABLED = True
#AUTH_TYPE = AUTH_DB
AUTH_TYPE = AUTH_LDAP
# Uncomment to setup Full admin role name
AUTH_ROLE_ADMIN = 'Admin'
# The default user self registration role
# AUTH_USER_REGISTRATION_ROLE = "Public"
# When using LDAP Auth, setup the ldap server
AUTH_LDAP_SERVER = "ldap://leojiang.com"
AUTH_LDAP_USE_TLS = False
# registration configs
# 指定Airflow允许LDAP用户在登录时自动注册
AUTH_USER_REGISTRATION = True # allow users who are not already in the FAB DB
# 这个必须配置要不会报认证的错误
AUTH_USER_REGISTRATION_ROLE = "Admin" # this role will be given in addition to any AUTH_ROLES_MAPPING
# 指定用户每次登陆都会刷新一次权限
AUTH_ROLES_SYNC_AT_LOGIN = True
# search configs(以下就是你自己ldap的一些用户信息,根据自己的配置即可)
AUTH_LDAP_SEARCH = "ou=ID,ou=Data,dc=leo,dc=se" # the LDAP search base
AUTH_LDAP_UID_FIELD = "uid" # the username field
AUTH_LDAP_BIND_USER = "CN=leojiangdm,OU=CA,OU=SvcAccount,OU=P1,OU=ID,OU=Data,DC=leo,DC=se" # the special bind username for search
AUTH_LDAP_BIND_PASSWORD = "Adfsadfasdfsd@123" # the special bind password for search
# 您可以通过配置来限制LDAP搜索范围:(注意如果用 AUTH_ROLES_MAPPING 参数,则该参数不能使用)
# only allow users with memberOf="cn=myTeam,ou=teams,dc=example,dc=com"
#AUTH_LDAP_SEARCH_FILTER = "(memberOf=cn=myTeam,ou=teams,dc=example,dc=com)"
# 您可以基于 LDAP 角色赋予 FlaskAppBuilder 角色(注意,这需要设置 AUTH_LDAP_SEARCH):
# a mapping from LDAP DN to a list of FAB roles
#AUTH_ROLES_MAPPING = {
# "cn=fab_users,ou=groups,dc=example,dc=com": ["User"],
# "cn=fab_admins,ou=groups,dc=example,dc=com": ["Admin"],
#}
2、修改docker-compose配置文件映射到web容器中即可
airflow-docker-compose.yml添加webserver_config.py挂载
---
……
x-airflow-common:
&airflow-common
……
volumes:
- ./dags:/opt/airflow/dags
- ./logs:/opt/airflow/logs
- ./plugins:/opt/airflow/plugins
- ./airflow.cfg:/opt/airflow/airflow.cfg
# 添加web的挂载
- ./webserver_config.py:/opt/airflow/webserver_config.py
……
3、重新启动
docker-compose -f airflow-docker-compose.yml down
docker-compose -f airflow-docker-compose.yml up -d
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法