搭建一个卷积神经网络_不使用conv2d函数 自己搭建一个卷积神经网络-程序员宅基地
虽然对机器学习算法、神经网络、深度学习的接触也已经有一年了,但是还没有认真搭建过一个网络。为了帮助自己更好地理解,同时提高实践能力,自己动手搭建一个卷积神经网络,以备后面的学习使用。
使用比较熟悉的MNIST数据集,下载地址
包含四个部分
Training set images: train-images-idx3-ubyte.gz
Training set labels: train-labels-idx1-ubyte.gz
Test set images: t10k-images-idx3-ubyte.gz
Test set labels: t10k-labels-idx1-ubyte.gz
参考博客1:手把手教你用 TensorFlow 实现卷积神经网络(附代码)
参考博文2:深度学习四:tensorflow-使用卷积神经网络识别手写数字
为了方便自己理解,所以加了很多的注释。
# CNN.py
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
sess = tf.InteractiveSession()
# 读取数据集
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 函数申明
def weight_variable(shape):
# 正态分布,标准差为0.1,默认最大为1,最小为-1,均值为0
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
# 创建一个结构为shape矩阵也可以说是数组shape声明其行列,初始化所有值为0.1
initial = tf.constant(0.1, shape == shape)
return tf.Variable(initial)
def conv2d(x, W):
# 卷积遍历各方向步数为1,SAME:边缘外自动补0,遍历相乘
# padding 一般只有两个值
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
# 池化卷积结果(conv2d)池化层采用kernel大小为2*2,步数也为2,SAME:周围补0,取最大值。数据量缩小了4倍
# x 是 CNN 第一步卷积的输出量,其shape必须为[batch, height, weight, channels];
# ksize 是池化窗口的大小, shape为[batch, height, weight, channels]
# stride 步长,一般是[1,stride, stride,1]
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 定义输入输出结构
# 可以理解为形参,用于定义过程,执行时再赋值
# dtype 是数据类型,常用的是tf.float32,tf.float64等数值类型
# shape是数据形状,默认None表示输入图片的数量不定,28*28图片分辨率
xs = tf.placeholder(tf.float32, [None, 28*28])
# 类别是0-9总共10个类别,对应输出分类结果
ys = tf.placeholder(tf.float32, [None, 10])
keep_prob = tf.placeholder(tf.float32)
# x_image又把xs reshape成了28*28*1的形状,灰色图片的通道是1.作为训练时的input,-1代表图片数量不定
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# 搭建网络
# 第一层卷积池化
# 第一二参数值得卷积核尺寸大小,即patch
w_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32]) # 32个偏置值
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1)+b_conv1) # 得到28*28*32
h_pool1 = max_pool_2x2(h_conv1) # 得到14*14*32
# 第二层卷积池化
# 第三个参数是图像通道数,第四个参数是卷积核的数目,代表会出现多少个卷积特征图像;
w_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2)+b_conv2) # 得到14*14*64
h_pool2 = max_pool_2x2(h_conv2) # 得到7*7*64
# 第三层全连接层
w_fc1 = weight_variable([7*7*64, 1024])
b_fc1 = bias_variable([1024])
# 将第二层卷积池化结果reshape成只有一行7*7*64个数据
# [n_samples, 7, 7, 64] == [n_samples, 7 * 7 * 64]
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
# 卷积操作,结果是1*1*1024,单行乘以单列等于1*1矩阵,matmul实现最基本的矩阵相乘
# 不同于tf.nn.conv2d的遍历相乘,自动认为是前行向量后列向量
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, w_fc1)+ b_fc1)
# 对卷积结果执行dropout操作
h_fc1_dropout = tf.nn.dropout(h_fc1, keep_prob)
# 第四层输出操作
# 二维张量,1*1024矩阵卷积,共10个卷积,对应ys长度为10
w_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_dropout, w_fc2)+b_fc2)
# 定义损失函数
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(y_conv), reduction_indices=[1]))
# AdamOptimizer通过使用动量(参数的移动平均数)来改善传统梯度下降,促进超参数动态调整
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 训练验证
tf.global_variables_initializer().run()
# tf.equal(A, B)是对比这两个矩阵或者向量的相等的元素,如果相等返回True,否则返回False,返回的值的矩阵维度和A是一样的
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(ys, 1))
# print(correct_prediction)
# tf.arg_max(input, axis=None, name=None, dimension=None) 是对矩阵按行或列计算最大值(axis:0表示按列,1表示按行)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 数据类型转换
for i in range(1500):
batch_x, batch_y = mnist.train.next_batch(50)
if i%100 == 0:
train_accuracy = accuracy.eval(feed_dict={xs:batch_x, ys:batch_y, keep_prob: 1.0})
print('step:%d, training accuracy %g' %(i, train_accuracy))
train_step.run(feed_dict={xs:batch_x, ys:batch_y, keep_prob:0.5})
print(accuracy.eval({xs:mnist.test.images, ys:mnist.test.labels, keep_prob:1.0}))
运行结果
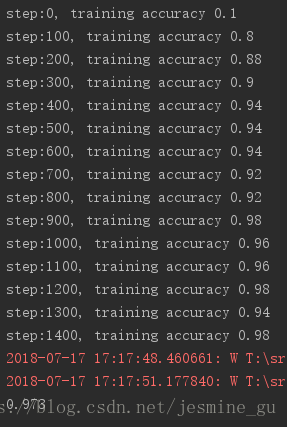
除了Adam算法的优化器外,tensorflow还提供了一些优化器,比如:
class tf.train.GradientDescentOptimizer–梯度下降算法的优化器
class tf.train.AdadeltaOptimizer – 使用adadelta算法的优化器
class tf.train.AdagradOptimizer – 使用adagradOptimizer算法的优化器
class tf.train.MomentumOptimizer – 使用Momentum算法的优化器
把激活函数换成sigmoid试了一下
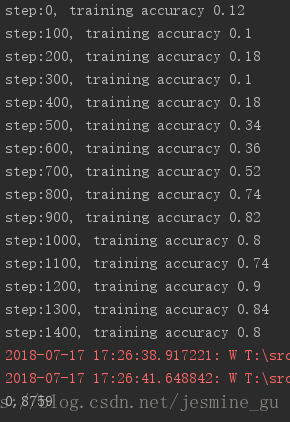
可以看到sigmoid的效果没有ReLU好
添加一个卷积池化层
# CNN.py
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
sess = tf.InteractiveSession()
# 函数申明
def weight_variable(shape):
# 正态分布,标准差为0.1,默认最大为1,最小为-1,均值为0
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)
def bias_variable(shape):
# 创建一个结构为shape矩阵也可以说是数组shape声明其行列,初始化所有值为0.1
initial = tf.constant(0.1, shape == shape)
return tf.Variable(initial)
def conv2d(x, W):
# 卷积遍历各方向步数为1,SAME:边缘外自动补0,遍历相乘
# padding 一般只有两个值
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')
def max_pool_2x2(x):
# 池化卷积结果(conv2d)池化层采用kernel大小为2*2,步数也为2,SAME:周围补0,取最大值。数据量缩小了4倍
# x 是 CNN 第一步卷积的输出量,其shape必须为[batch, height, weight, channels];
# ksize 是池化窗口的大小, shape为[batch, height, weight, channels]
# stride 步长,一般是[1,stride, stride,1]
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
def deep_CNN(xs):
# x_image又把xs reshape成了28*28*1的形状,灰色图片的通道是1.作为训练时的input,-1代表图片数量不定
x_image = tf.reshape(xs, [-1, 28, 28, 1])
# 搭建网络
# 第一层卷积池化
# 第一二参数值得卷积核尺寸大小,即patch
w_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32]) # 32个偏置值
h_conv1 = tf.nn.relu(conv2d(x_image, w_conv1)+b_conv1) # 得到28*28*32
#h_conv1 = tf.nn.sigmoid(conv2d(x_image, w_conv1)+b_conv1)
h_pool1 = max_pool_2x2(h_conv1) # 得到14*14*32
# 第二层卷积池化
# 第三个参数是图像通道数,第四个参数是卷积核的数目,代表会出现多少个卷积特征图像;
w_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, w_conv2)+b_conv2) # 得到14*14*64
#h_conv2 = tf.nn.sigmoid(conv2d(h_pool1, w_conv2)+b_conv2)
h_pool2 = max_pool_2x2(h_conv2) # 得到7*7*64
# 添加一层卷积池化层
w_conv3 = weight_variable([5, 5, 64, 128])
b_conv3 = bias_variable([128])
h_conv3 = tf.nn.relu(conv2d(h_pool2, w_conv3)+b_conv3) # 得到7*7*128
#h_conv3 = tf.nn.sigmoid(conv2d(h_pool1, w_conv2)+b_conv2)
h_pool3 = max_pool_2x2(h_conv3) # 得到4*4*128
# 第四层全连接层
w_fc1 = weight_variable([4*4*128, 1024])
b_fc1 = bias_variable([1024])
# 将第三层卷积池化结果reshape成只有一行7*7*128个数据
# [n_samples, 4, 4, 128] == [n_samples, 4 * 4 * 128]
h_pool3_flat = tf.reshape(h_pool3, [-1, 4*4*128])
# -1 表示不知道该填什么数字合适的情况下,可以选择
# 卷积操作,结果是1*1*1024,单行乘以单列等于1*1矩阵,matmul实现最基本的矩阵相乘
# 不同于tf.nn.conv2d的遍历相乘,自动认为是前行向量后列向量
h_fc1 = tf.nn.relu(tf.matmul(h_pool3_flat, w_fc1)+ b_fc1)
#h_fc1 = tf.nn.sigmoid(tf.matmul(h_pool2_flat, w_fc1)+ b_fc1)
# 对卷积结果执行dropout操作
keep_prob = tf.placeholder(tf.float32)
h_fc1_dropout = tf.nn.dropout(h_fc1, keep_prob)
# tf.nn.dropout(x, keep_prob, noise_shape=None, seed=None, name=None)
# 第二个参数keep_prob: 设置神经元被选中的概率,在初始化时keep_prob是一个占位符
# 第四层输出操作
# 二维张量,1*1024矩阵卷积,共10个卷积,对应ys长度为10
w_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv = tf.nn.softmax(tf.matmul(h_fc1_dropout, w_fc2)+b_fc2)
return y_conv, keep_prob
def main():
# 读取数据集
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# 定义输入输出结构
# tf.placeholder可以理解为形参,用于定义过程,执行时再赋值
# dtype 是数据类型,常用的是tf.float32,tf.float64等数值类型
# shape是数据形状,默认None表示输入图片的数量不定,28*28图片分辨率
xs = tf.placeholder(tf.float32, [None, 28 * 28])
# 类别是0-9总共10个类别,对应输出分类结果
ys = tf.placeholder(tf.float32, [None, 10])
y_conv, keep_prob = deep_CNN(xs)
# 定义损失函数
# cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys*tf.log(y_conv), reduction_indices=[1]))
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=ys, logits=y_conv))
# AdamOptimizer通过使用动量(参数的移动平均数)来改善传统梯度下降,促进超参数动态调整
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
# 训练验证
# tf.equal(A, B)是对比这两个矩阵或者向量的相等的元素,如果相等返回True,否则返回False,返回的值的矩阵维度和A是一样的
correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(ys, 1))
# print(correct_prediction)
# tf.arg_max(input, axis=None, name=None, dimension=None) 是对矩阵按行或列计算最大值(axis:0表示按列,1表示按行)
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32)) # 数据类型转换
print("start train")
sess.run(tf.global_variables_initializer())
for i in range(1500):
batch_x, batch_y = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={xs: batch_x, ys: batch_y, keep_prob: 1.0})
print('step:%d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={xs: batch_x, ys: batch_y, keep_prob: 0.5})
# 测试
print(accuracy.eval({xs: mnist.test.images, ys: mnist.test.labels, keep_prob: 1.0}))
if __name__ == '__main__':
main()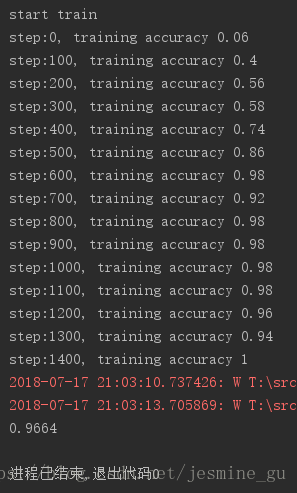
结果看来没太大差别,效果没有什么提升
接下来保存和恢复参数
为了方便调试,节省训练时间,我把迭代次数调到了1000
训练时
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
for i in range(1000):
batch_x, batch_y = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={xs: batch_x, ys: batch_y, keep_prob: 1.0})
print('step:%d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={xs: batch_x, ys: batch_y, keep_prob: 0.5})
saver.save(sess, "input_data/model")
得到的文件

测试时
saver = tf.train.Saver()
sess.run(tf.global_variables_initializer())
saver.restore(sess, "input_data/model")
# 测试
print(accuracy.eval({xs: mnist.test.images, ys: mnist.test.labels, keep_prob: 1.0}))直接得到测试结果
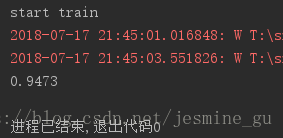
还需继续改进……
智能推荐
wordpress常用插件汇总_cαptⅰveportα1logⅰn是什么插件-程序员宅基地
文章浏览阅读9.9k次。WordPress之所以能成为目前最具人气的独立博客程序,除了无数爱好者为它开发的主题外,源源不断的插件支持也是重要的原因之一。wordpress的强大,也是在于无数爱好者源源不断的主题和插件。wordpress插件数量巨大,有改善用户体验的,有辅助SEO的,有增加功能的。要从这茫茫中的插件找出所需已属不易,外加无数英语系插件更让不熟悉英语中国用户难上加难。所谓群众的力量是强大的,每人找一_cαptⅰveportα1logⅰn是什么插件
(0011) iOS 开发之模拟HTTP请求与响应,返回自己想要的报文。_ios调试,修改http接口返回结果-程序员宅基地
文章浏览阅读2.2k次。iOS 本地模拟 HTTP请求的返回数据,用来先行开发。在新需求的确定之后,在开发的开始阶段,一般后台接口先开发,这时客户端是拿不到接口文档规定的报文数据的,那我们怎么模拟接口请求返回数据尼?直接利用网站:关键:利用一个工具网站来实现: http://www.mocky.io(生成请求的接口地址)第一步:设置接口返回数据,用来模拟正常的返回数据。_ios调试,修改http接口返回结果
在Ubuntu为Android硬件抽象层(HAL)模块编写JNI方法提供Java访问硬件服务接口 (学习老罗的)_hal还能编译出java?-程序员宅基地
文章浏览阅读4k次。主要是在~/Android_4.2.2_SourceCode/frameworks/base/services/jni个夹子里面操作的。根据老罗的方法我也是实现成功了。但是和上一篇文章一样,同样需要将LOGI改为ALOGI,LOGE改为ALOGE。他也写了很多知识方面的内容,但是目前还只是实现了部分,待后面JAVA方面调用的例程写好了,我串起来总结一下。。。_hal还能编译出java?
Identify3D部署金雅拓解决方案以确保对用户IP和制造数据的保护_identify3d做什么用的-程序员宅基地
文章浏览阅读307次。这家数字制造软件提供商利用SafeNet Data Protection on Demand云端HSM服务来提升其数据安全性阿姆斯特丹--(美国商业资讯)--全球数字安全领域的领导者金雅拓(Gemalto)今天宣布,数字制造供应链的最先进安全解决方案提供商Identify3D已部署金雅拓的SafeNet Data Protection On Demand,以确保其客户知识产权的安全性和云端数字..._identify3d做什么用的
基于VMD-SSA-LSTM的多维时序光伏功率预测_知乎 vmd-ssa-lstm的多维时序光伏功率预测-程序员宅基地
文章浏览阅读1.9k次,点赞3次,收藏19次。之前分享了预测的程序,该程序预测效果比较好,并且结构比较清晰,但是仍然有同学咨询混合算法的预测,本次分享基于VMD-SSA-LSTM的多维时序光伏功率预测,本程序参考文章《基于VMD-SSA-LSSVM的短期风电预测》和《基于改进鲸鱼优化算法的微网系统能量优化管理》,采用不同方法混合嫁接的方式实现了光伏功率预测,对于预测而言,包括训练和测试,因此,该方法仍然可以用于风电、负荷等方面的预测。_知乎 vmd-ssa-lstm的多维时序光伏功率预测
分享一个从IEEE Xplore上批量下载会议论文的方法_ieee xplore 脚本-程序员宅基地
文章浏览阅读1.8w次,点赞5次,收藏11次。博客地址标签(空格分隔): IEEE Xplore, bash 测试环境:Ubuntu 15.04, 中山大学首先,从下载一篇论文开始,在IEEE Xplore上任意下载一篇论文,获取下载链接, 如:http://ieeexplore.ieee.org/ielx7/6875427/6877223/06877226.pdf?tp=&arnumber=6877226&isnumber=687722_ieee xplore 脚本
随便推点
linux执行脚本中方法,Linux中执行shell脚本命令的4种方法总结-程序员宅基地
文章浏览阅读6.3k次,点赞2次,收藏11次。bash shell 脚本的方法有多种,现在作个小结。假设我们编写好的shell脚本的文件名为hello.sh,文件位置在/data/shell目录中并已有执行权限。方法一:切换到shell脚本所在的目录(此时,称为工作目录)执行shell脚本:复制代码 代码如下:cd /data/shell./hello.sh./的意思是说在当前的工作目录下执行hello.sh。如果不加上./,bash可能会响..._linux 怎么调用shell脚本中的方法
Dubbo服务调用过程?_dubbo status = 20, event = false, error = null,-程序员宅基地
文章浏览阅读685次。简单的想想大致流程在分析Dubbo的服务调用过程前我们先来思考一下如果让我们自己实现的话一次调用过程需要经历哪些步骤?首先我们已经知晓了远程服务的地址,然后我们要做的就是把我们要调用的方法具体信息告知远程服务,让远程服务解析这些信息。然后根据这些信息找到对应的实现类,然后进行调用,调用完了之后再原路返回,然后客户端解析响应再返回即可。调用具体的信息那客户端告知服务端的具体信息应该包含哪些呢?首先客户端肯定要告知要调用是服务端的哪个接口,当然还需要方法名、方法的参数类型、方法的参._dubbo status = 20, event = false, error = null,
ATR指标详细介绍-程序员宅基地
文章浏览阅读1.1w次。为想要了解外汇技术指标或者怎样分析做外汇以及如何使用市场ATR指标,以及ATR指标详细的计算方法、应用分析、使用方法、以及对外汇新手普及一些ATR知识。希望被采纳。工具/原料笔记本MT4平台方法/步骤 ATR指标详细介绍 ATR又称 Average _atr指标
iOS逆向学习笔记之--砸壳和导出应用头文件_dump.py -l-程序员宅基地
文章浏览阅读1.6k次。iOS逆向学习笔记之–砸壳和导出应用头文件dumpdecrypted砸壳工具的使用1、下载源代码git clone https://github.com/stefanesser/dumpdecrypted.git 2、进入dumpdecrypted文件夹目录。使用make命令生成dumpdecrypted.dylib文件 3、ssh登录越狱手机,关闭所有应用,启动需要砸壳的目标应用..._dump.py -l
python脚本运行gprMax3.0批量仿真GPR数据_gprmax 输出图像为txt-程序员宅基地
文章浏览阅读9.8k次,点赞11次,收藏98次。python脚本运行gprMax3.0批量仿真GPR B-scan图像1.引言2.Python脚本3.可能出现的报错4.数据展示1.引言探地雷达(GPR)结合深度学习通常需要大量的训练数据集,对于GPR仿真数据集的获取,我们一般通过gprMax生成,而gprMax3.0仿真数据时需要通过cmd命令提示符窗口人工一条一条地输入指令(通过cmd命令生成GPR B-scan图像:可以参考我的上一篇博客.),对于批量生成GPR数据非常不方便。因此,有必要写一些Python脚本,实现自动化批量生成GPR数据集。_gprmax 输出图像为txt
机器学习_factor_regression_data/factor_returns.csv-程序员宅基地
文章浏览阅读1.2k次。机器学习算法课程定位、目标定位课程以算法、案例为驱动的学习,伴随浅显易懂的数学知识作为人工智能领域(数据挖掘/机器学习方向)的提升课程,掌握更深更有效的解决问题技能目标应用Scikit-learn实现数据集的特征工程掌握机器学习常见算法原理应用Scikit-learn实现机器学习算法的应用,结合场景解决实际问题机器学习概述了解机器学习定义以及应用场景什么是机器学习1、 背景介..._factor_regression_data/factor_returns.csv