愉快地迁移到 Python 3-程序员宅基地
(点击上方公众号,可快速关注)
编译: Python开发者 - 冲动老少年 英文:Alex Rogozhnikov
http://python.jobbole.com/89031/
为数据科学家准备的 Python 3 特性指南
Python 已经成为机器学习和一些需处理大量数据的科学领域的主流语言。它支持了许多深度学习框架和其他已确立下来的数据处理和可视化的工具集。
然而,Python 生态系统还处于 Python 2 和 Python 3 并存的状态,且 Python 2 仍然被数据科学家们所使用。从 2019 年底开始,系统工具包将会停止对 Python 2 的支持。对于 numpy,2018 年之后任何更新将只支持 Python 3。
为了让大家能够顺利过渡,我收集了一系列 Python 3 特性,希望对大家有用。

图片来源于 Dario Bertini post (toptal)
使用 pathlib 更好的对路径进行处理
pathlib 是 Python 3 中的默认模块,能帮你避免过多的使用 os.path.join:
from pathlib import Path
dataset = 'wiki_images'
datasets_root = Path('/path/to/datasets/')
train_path = datasets_root / dataset / 'train'
test_path = datasets_root / dataset / 'test'
for image_path in train_path.iterdir():
with image_path.open() as f: # note, open is a method of Path object
# do something with an image
在之前的版本中总是不可避免的使用字符串连接(简洁但明显可读性很差),如今使用 pathlib 后,代码会更安全、简洁、易读。
同时 pathlib.Path 提供了一系列方法和特性,这样一来 python 的初学者就不需搜索了:
p.exists()
p.is_dir()
p.parts
p.with_name('sibling.png') # only change the name, but keep the folder
p.with_suffix('.jpg') # only change the extension, but keep the folder and the name
p.chmod(mode)
p.rmdir()
pathlib 会节省你大量的时间,具体用法请参考 文档 和 说明。
类型提示现在是 Python 的一部分啦
Pycharm 中类型提示示例:
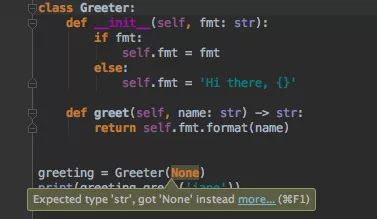
Python 已不再是一个小型的脚本语言了,如今的数据处理流程包含许多步骤,每步涉及不同的构架(而且有时会涉及不同的逻辑)
引入类型提示功能有助于处理日渐复杂的程序,因此机器就可以帮助实现代码验证。而以前是不同的模块需使用自定义的方式在文档字符串(doctrings)中指定类型(提示:pycharm 能够将旧的 doctrings 转换为新的 Type hinting)。
下图是一个简单的例子,这段代码对不同类型的数据均有效(这正是我们喜欢 Python 数据栈的原因)。
def repeat_each_entry(data):
""" Each entry in the data is doubled
<blah blah nobody reads the documentation till the end>
"""
index = numpy.repeat(numpy.arange(len(data)), 2)
return data[index]
这段代码样例适用于 numpy.array(含多维数组)、astropy.Table 及 astropy.Column、bcolz、cupy、mxnet.ndarray 等。
这段代码可用于 pandas.Series,但方式不对:
repeat_each_entry(pandas.Series(data=[0, 1, 2], index=[3, 4, 5])) # returns Series with Nones inside
这还仅是两行代码。想象一下一个复杂系统的行为将是多么的难以预测,仅因一个函数就有可能行为失常。在大型系统中,明确各类方法的期望类型是非常有帮助的,这样会在函数未得到期望的参数类型时给出警告。
def repeat_each_entry(data: Union[numpy.ndarray, bcolz.carray]):
如果你有重要的代码库, MyPy 这样的提示工具很可能成为持续集成途径的一部分。由 Daniel Pyrathon 发起的名为“让类型提示生效”的在线教程可为您提供一个很好的介绍。
旁注:不幸的是,类型提示功能还未强大到能为 ndarrays 或 tensors 提供细粒度分型,但是或许我们很快就可拥有,这也将是 DS 的特色功能。
类型提示→运行中的类型检查
在默认情况下,函数注释不会影响你代码的运行,但也仅能提示你代码的目的。
然而,你可以使用像 enforce 这样的工具在运行中强制类型检查,这有助你调试(当类型提示不起作用时会出现很多这样的情况)。
@enforce.runtime_validation
def foo(text: str) -> None:
print(text)
foo('Hi') # ok
foo(5) # fails
@enforce.runtime_validation
def any2(x: List[bool]) -> bool:
return any(x)
any ([False, False, True, False]) # True
any2([False, False, True, False]) # True
any (['False']) # True
any2(['False']) # fails
any ([False, None, "", 0]) # False
any2([False, None, "", 0]) # fails
函数注释的其他惯例
如前所述,函数注释不会影响代码的执行,但是它可提供一些供你随意使用的元信息(译者注:关于信息的信息)。
例如,计量单位是科学领域的一个常见问题,astropy 包能够提供一种简单装饰器来控制输入量的单位并将输出量转换成所需单位。
# Python 3
from astropy import units as u
@u.quantity_input()
def frequency(speed: u.meter / u.s, wavelength: u.m) -> u.terahertz:
return speed / wavelength
frequency(speed=300_000 * u.km / u.s, wavelength=555 * u.nm)
# output: 540.5405405405404 THz, frequency of green visible light
如果你正使用 Python 处理表格式科学数据(数据量很大),你应该试一试 astropy。
你也可以定义你的专用装饰器以同样的方法对输入量和输出量进行控制或转换。
使用 @ 进行矩阵乘积
我们来执行一个简单的机器学习模型,带 L2 正则化的线性回归(也称脊回归):
# l2-regularized linear regression: || AX - b ||^2 + alpha * ||x||^2 -> min
# Python 2
X = np.linalg.inv(np.dot(A.T, A) + alpha * np.eye(A.shape[1])).dot(A.T.dot(b))
# Python 3
X = np.linalg.inv(A.T @ A + alpha * np.eye(A.shape[1])) @ (A.T @ b)
使用 @ 的代码更可读也更容易在各深度学习架构间转译:一个单层感知器可以在 numpy、cupy、pytorch、tensorflow(和其他操作张量的框架)下运行相同的代码 X @ W + b[None, :] 实现。
使用 ** 作通配符
递归文件夹的通配符在 python 2 中实现起来并不简单,实际上我们要自定义 glob2 模块来克服这个问题。而从 Python 3.6 以后将支持遍历标志:
import glob
# Python 2
found_images =
glob.glob('/path/*.jpg')
+ glob.glob('/path/*/*.jpg')
+ glob.glob('/path/*/*/*.jpg')
+ glob.glob('/path/*/*/*/*.jpg')
+ glob.glob('/path/*/*/*/*/*.jpg')
# Python 3
found_images = glob.glob('/path/**/*.jpg', recursive=True)
在 python 3 中有更好的选择,那就是使用 pathlib(-1 导入!):
# Python 3
found_images = pathlib.Path('/path/').glob('**/*.jpg')
Print 现在是函数
没错,现在写代码需要这些烦人的圆括号,但是这有许多好处:
简化使用文件描述符的语法:
print >>sys.stderr, "critical error" # Python 2
print("critical error", file=sys.stderr) # Python 3
无需 str.join 输出制表符:
# Python 3
print(*array, sep='t')
print(batch, epoch, loss, accuracy, time, sep='t')
改写或重定义 print 的输出
# Python 3
_print = print # store the original print function
def print(*args, **kargs):
pass # do something useful, e.g. store output to some file
在 jupyter 中,可以将每一个输出记录到一个独立的文档(以跟踪断线之后发生了什么),这样一来我们就可以重写 print 函数了。
下面你可以看到名为 contextmanager 的装饰器暂时重写 print 函数的方式:
@contextlib.contextmanager
def replace_print():
import builtins
_print = print # saving old print function
# or use some other function here
builtins.print = lambda *args, **kwargs: _print('new printing', *args, **kwargs)
yield
builtins.print = _print
with replace_print():
<code here will invoke other print function>
这种方法并不推荐,因为此时有可能出现些小问题。
print 函数可参与列表理解和其他语言构建。
# Python 3
result = process(x) if is_valid(x) else print('invalid item: ', x)
数值中的下划线(千位分隔符)
PEP-515 在数值中引入下划线。在 Python 3 中,下划线可用于整数、浮点数、复数的位数进行分组,增强可视性。
# grouping decimal numbers by thousands
one_million = 1_000_000
# grouping hexadecimal addresses by words
addr = 0xCAFE_F00D
# grouping bits into nibbles in a binary literal
flags = 0b_0011_1111_0100_1110
# same, for string conversions
flags = int('0b_1111_0000', 2)
使用 f-strings 简便可靠的进行格式化
默认的格式化系统具有一定的灵活性,但这却不是数据实验所需要的。这样改动后的代码要么太冗长,要不太零碎。
典型的数据科学的代码会反复的输出一些固定格式的日志信息。常见代码格式如下:
# Python 2
print('{batch:3} {epoch:3} / {total_epochs:3} accuracy: {acc_mean:0.4f}±{acc_std:0.4f} time: {avg_time:3.2f}'.format(
batch=batch, epoch=epoch, total_epochs=total_epochs,
acc_mean=numpy.mean(accuracies), acc_std=numpy.std(accuracies),
avg_time=time / len(data_batch)
))
# Python 2 (too error-prone during fast modifications, please avoid):
print('{:3} {:3} / {:3} accuracy: {:0.4f}±{:0.4f} time: {:3.2f}'.format(
batch, epoch, total_epochs, numpy.mean(accuracies), numpy.std(accuracies),
time / len(data_batch)
))
样本输出:
120 12 / 300 accuracy: 0.8180±0.4649 time: 56.60
f-strings 全称为格式化字符串,引入到了 Python 3.6:
# Python 3.6+
print(f'{batch:3} {epoch:3} / {total_epochs:3} accuracy: {numpy.mean(accuracies):0.4f}±{numpy.std(accuracies):0.4f} time: {time / len(data_batch):3.2f}')
同时,写查询或者进行代码分段时也非常便利:
query = f"INSERT INTO STATION VALUES (13, {city!r}, {state!r}, {latitude}, {longitude})"
重点:别忘了转义字符以防 SQL 注入攻击。
‘真实除法’与‘整数除法’的明确区别
这对于数据科学而言是非常便利的改变(但我相信对于系统编程而言却不是)
data = pandas.read_csv('timing.csv')
velocity = data['distance'] / data['time']
在 Python 2 中结果正确与否取决于‘时间’和‘距离’(例如,以秒和米做测量单位)是否以整型来存储。而在 Python 3 中这两种除法的结构都正确,因为商是以浮点型存储的。
另一个案例是整数除法现在已经作为一个显式操作:
n_gifts = money // gift_price # correct for int and float arguments
注意:这个特性既适用于内置类型又适用于由数据包(比如:numpy 或者 pandas)提供的自定义类型。
严格排序
# All these comparisons are illegal in Python 3
3 < '3'
2 < None
(3, 4) < (3, None)
(4, 5) < [4, 5]
# False in both Python 2 and Python 3
(4, 5) == [4, 5]
防止不同类型实例的偶然分类
sorted([2, '1', 3]) # invalid for Python 3, in Python 2 returns [2, 3, '1']
有助于指示处理原始数据时发生的问题
旁注:适当的检查 None(两种版本的 Python 均需要)
if a is not None:
pass
if a: # WRONG check for None
pass
自然语言处理(NLP)中的统一编码标准(Unicode)
s = '您好'
print(len(s))
print(s[:2])
输出:
Python 2:
6n��Python 3:
2n您好.
x = u'со'
x += 'co' # ok
x += 'со' # fail
Python 2 失效而 Python 3 如期输出(因为我在字符串中使用了俄文字母)
在 Python 3 中 strs 是 unicode 字符串,这更方便处理非英语文本的 NPL。
还有其他好玩的例子,比如:
'a' < type < u'a' # Python 2: True
'a' < u'a' # Python 2: False
from collections import Counter
Counter('Möbelstück')
Python 2 是:Counter({‘xc3’: 2, ‘b’: 1, ‘e’: 1, ‘c’: 1, ‘k’: 1, ‘M’: 1, ‘l’: 1, ‘s’: 1, ‘t’: 1, ‘xb6’: 1, ‘xbc’: 1})
Python 3 是:Counter({‘M’: 1, ‘ö’: 1, ‘b’: 1, ‘e’: 1, ‘l’: 1, ‘s’: 1, ‘t’: 1, ‘ü’: 1, ‘c’: 1, ‘k’: 1})
虽然在 Python 2 中这些可以正确处理,但在 Python 3 下会更加友好。
字典和 **kwargs 的保存顺序
在 CPython 3.6+ 中,默认情况下字典的行为类似于 OrderedDict(这在 Python 3.6+ 版本中已被保证)。这样可在理解字典(及其他操作,例如:json 序列化或反序列化)时保持了顺序。
import json
x = { str(i):i for i in range(5)}
json.loads(json.dumps(x))
# Python 2
{ u'1': 1, u'0': 0, u'3': 3, u'2': 2, u'4': 4}
# Python 3
{ '0': 0, '1': 1, '2': 2, '3': 3, '4': 4}
这同样适用于 **kwargs(在 Python 3.6+ 中),即按照 **kwargs 在参数中出现的顺序来保存。在涉及到数据流这个顺序是至关重要的,而以前我们不得不用一种麻烦的方法来实现。
from torch import nn
# Python 2
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
# Python 3.6+, how it *can* be done, not supported right now in pytorch
model = nn.Sequential(
conv1=nn.Conv2d(1,20,5),
relu1=nn.ReLU(),
conv2=nn.Conv2d(20,64,5),
relu2=nn.ReLU())
)
你注意到了吗?命名的惟一性也是自动检查的。
迭代拆封
# handy when amount of additional stored info may vary between experiments, but the same code can be used in all cases
model_paramteres, optimizer_parameters, *other_params = load(checkpoint_name)
# picking two last values from a sequence
*prev, next_to_last, last = values_history
# This also works with any iterables, so if you have a function that yields e.g. qualities,
# below is a simple way to take only last two values from a list
*prev, next_to_last, last = iter_train(args)
使用默认的 pickle 工具更好的压缩数组
# Python 2
import cPickle as pickle
import numpy
print len(pickle.dumps(numpy.random.normal(size=[1000, 1000])))
# result: 23691675
# Python 3
import pickle
import numpy
len(pickle.dumps(numpy.random.normal(size=[1000, 1000])))
# result: 8000162
节省三倍空间,并且更快速。实际上 protocol=2 参数可以实现相同的压缩(但是速度不行),但是使用者基本上都会忽视这个选项(或者根本没有意识到)。
更安全的解析
labels = <initial_value>
predictions = [model.predict(data) for data, labels in dataset]
# labels are overwritten in Python 2
# labels are not affected by comprehension in Python 3
超级简单的 super 函数
在 Python 2 中,super(…) 是代码里常见的错误源。
# Python 2
class MySubClass(MySuperClass):
def __init__(self, name, **options):
super(MySubClass, self).__init__(name='subclass', **options)
# Python 3
class MySubClass(MySuperClass):
def __init__(self, name, **options):
super().__init__(name='subclass', **options)
更多关于 super 函数及其方法的解析顺序参见 stackoverflow.
更好的 IDE:支持变量注释
使用类似 Java、C# 这类编程语言最享受的就是 IDE 会给出非常棒的建议,因为在执行程序前每种标识符都是已知的。
在 Python 中这是很难实现的,但是变量注释可以帮你
以一种清晰的格式写出你的期望值
从 IDE 中得到很好的建议
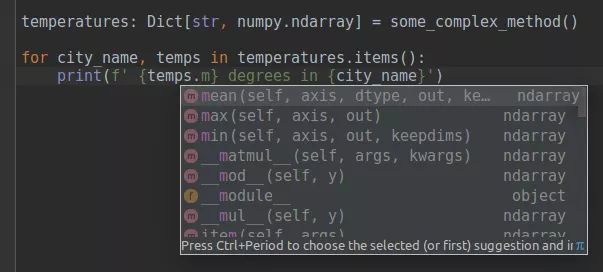
这是一个 PyCharm 中使用变量注释的例子。即使你使用的函数是未注释的(比如:由于向后兼容),这也仍然生效。
多重拆封
如下是现在如何合并两个字典:
x = dict(a=1, b=2)
y = dict(b=3, d=4)
# Python 3.5+
z = { **x, **y}
# z = {'a': 1, 'b': 3, 'd': 4}, note that value for `b` is taken from the latter dict.
可参见 StackOverflow 中的帖子与 Python 2 比较。
同样的方法也适用于列表(list),元组(tuple)和集合(set)(a,b,c 是任意可迭代对象):
[*a, *b, *c] # list, concatenating
(*a, *b, *c) # tuple, concatenating
{ *a, *b, *c} # set, union
对于使用的 *args 和 **kwargs 的函数也同样支持:
Python 3.5+
do_something(**{ **default_settings, **custom_settings})
# Also possible, this code also checks there is no intersection between keys of dictionaries
do_something(**first_args, **second_args)
永不过时的 API:使用仅带关键字的参数
我们考虑下这段代码
model = sklearn.svm.SVC(2, 'poly', 2, 4, 0.5)
很明显,这段代码的作者还没有掌握 Python 的代码风格(作者极可能是刚从 C++ 或者 Rust 跳过来的)。很不幸,这个问题不仅仅是风格的问题,因为在 SVC 函数中改变参数顺序(增或删)会导致代码崩溃。特别是函数 sklearn 会经常对大量的算法参数进行重拍序或重命名以保持和 API 的一致性。每次的重构都可能导致破坏代码。
在 Python 3 中,库的编写者可使用 * 来明确的命名参数:
class SVC(BaseSVC):
def __init__(self, *, C=1.0, kernel='rbf', degree=3, gamma='auto', coef0=0.0, ... )
现在使用者必须明确输入参数名,比如:sklearn.svm.SVC(C=2, kernel=’poly’, degree=2, gamma=4, coef0=0.5)
这种机制将 API 的可靠性和灵活性进行了极好的融合
次重点:math 模块中的常量
# Python 3
math.inf # 'largest' number
math.nan # not a number
max_quality = -math.inf # no more magic initial values!
for model in trained_models:
max_quality = max(max_quality, compute_quality(model, data))
次重点:单整型
Python 2 提供两种基本的整型:int 型(64 位有符整型)和用于长时计算的 long 型(C++ 后非常让人困惑)。
Python 3 有单精度的 int 型,它整合了长时计算的要求。
下面是怎样检查整型值:
isinstance(x, numbers.Integral) # Python 2, the canonical way
isinstance(x, (long, int)) # Python 2
isinstance(x, int) # Python 3, easier to remember
其他
Enums 理论是有用处的,但:
-
在 python 的数据栈中,字符串输入已被广泛采用
Enums 似乎并不与 numpy 交互,也不属于 pandas 范畴
协程听起来也很有希望做数据流程(参考 David Beazley 的幻灯片),但是我还没有看到他们被采用。
Python 3 有稳定的 ABI
Python 3 支持 unicode(因此 ω = Δφ / Δt 是可以的),但是最好还是使用虽旧但好用的 ASCII 码。
一些库,比如:jupyterhub(云服务版 jupyter)、django 和新版 ipython,只支持 Python 3,因此一些听起来对你无用的特性却对那些你也许只想用一次的库非常有用。
数据科学特有的代码迁移难题(以及如何解决它们)
放弃支持嵌套参数
map(lambda x, (y, z): x, z, dict.items())
然而,它依然能很好的对不同的理解起效。
{ x:z for x, (y, z) in d.items()}
通常来说,在 Python 2 和 Python 3 之间,理解也更好于‘翻译’。
map()、.keys()、.values()、.items() 返回的是迭代器而不是列表。迭代器的主要问题是:
没有琐碎的分片
不能迭代两次
几乎全部的问题都可以通过将结果转化为列表来解决。
当遇到麻烦时,参见 Python 问答:我如何迁移到 Python 3
使用 python 教授机器学习和数据科学的主要问题
教授者应该首先花时间讲解什么是迭代器,它不能像字符串一样被分片、级联、倍乘、迭代两次(以及如何处理)。
我认为大部分教授者会很高兴规避这些细节,但是现在这几乎是不可能的。
结论
Python 2 与 Python 3 共存了将近 10 年,但是我们应当转移到 Python 3 了。
迁移到仅有 Python 3 的代码库后,研究所写的代码和产品开发的代码都会变得更简短、更可读、更安全。
现在大部分库同时支持这两个 Python 版本。我都有点等不及了,工具包放弃支持 Python 2 享受新语言特性的美好时刻快来吧。
迁移后代码绝对会更顺畅,参见“我们再也不要向后兼容啦!”
参考
Key differences between Python 2.7 and Python 3.x
Python FAQ: How do I port to Python 3?
10 awesome features of Python that you can’t use because you refuse to upgrade to Python 3
Trust me, python 3.3 is better than 2.7 (video)
Python 3 for scientists
看完本文有收获?请转发分享给更多人
关注「Python开发者」,提升Python技能

智能推荐
【Unity】NavMeshAgent与Rigidbody冲突问题_navmeshagent不能和物理效果同时生效吗-程序员宅基地
文章浏览阅读4.7k次,点赞9次,收藏25次。同一物体同时开启NavMeshAgent和Rigidbody时,经常会发生一些意想不到的受力问题,经实测,NavMeshAgent在自动导航时,并不是直接改变物体的位移,会赋予物体一定的速度。关于组件:参考:Rigidbody、CharacterController和NavMeshAgent的区别Rigidbody是用来模拟真实物理效果的,它可以设置重力,可以为对象施加外力。注意它和..._navmeshagent不能和物理效果同时生效吗
docker部署php+nginx_dockerfile 安装php+nginx-程序员宅基地
文章浏览阅读275次。临近国庆,又回过头来鼓捣docker,因为从事php开发,所以还是先从环境入手。本来考虑搭建php+mysql+nginx+redis全部,但是由于使用的都是公司的mysql和redis,故只搭建php+nginx,因为我的操作系统是win10,一下操作都是在win下完成的。首先先拉取镜像,当然你也可以自己编写dockerfile去构建自己的镜像。这里先拉取nginx镜像:docker pu..._dockerfile 安装php+nginx
计算机毕业设计吊打导师Hadoop+Hive+PySpark旅游景点推荐 旅游推荐系统 景区游客满意度预测与优化 Apriori算法 景区客流量预测 旅游大数据 景点规划 知识图谱 机器学习 深度学习-程序员宅基地
文章浏览阅读1.2k次,点赞41次,收藏16次。计算机毕业设计吊打导师Hadoop+Hive+PySpark旅游景点推荐 旅游推荐系统 景区游客满意度预测与优化 Apriori算法 景区客流量预测 旅游大数据 景点规划 知识图谱 机器学习 深度学习 人工智能
Google APK Crash 解决方案-程序员宅基地
文章浏览阅读1.2k次。阅读五分钟,每日十点,和您一起终身学习,这里是程序员Android本篇文章主要介绍开发中我们没有源码的GMS Crash崩溃后的解决方案,通过阅读本篇文章,您将收获以下内容:一、gms.ui Service not registered CrashGMS(GoogleMobile Service)包是出口国外手机中Google限制必须要预制的,如果不预置无法过Google CTS认证,会导致手...
Java多线程(超详细!)-程序员宅基地
文章浏览阅读10w+次,点赞880次,收藏3.9k次。1、什么是进程?什么是线程?进程是:一个应用程序(1个进程是一个软件)。线程是:一个进程中的执行场景/执行单元。注意:一个进程可以启动多个线程。eg.对于java程序来说,当在DOS命令窗口中输入:java HelloWorld 回车之后。会先启动JVM,而JVM就是一个进程。JVM再启动一个主线程调用main方法。同时再启动一个垃圾回收线程负责看护,回收垃圾。最起码,现在的java程序中至少有两个线程并发,一个是垃圾回收线程,一个是执行main方法的主线程。3、进程和线程是什么关系?_java多线程
vue中使用webVideoCtrl播放海康插件_海康威视divplugin 浮层问题-程序员宅基地
文章浏览阅读2.2k次。<template> <div class="video-player"> <div id="divPlugin" class="divPlugin" ref="divPlugin" v-if="plugin"> </div> <!-- <div class="down" v-else> <a href="http://jbfsys.oss-cn-bei.._海康威视divplugin 浮层问题
随便推点
VLAN(虚拟局域网)_2019vlan-程序员宅基地
文章浏览阅读402次。创建VLAN的指令:VLAN +ID号(取值范围1-4094,1是默认存在)用来连接终端设备的(pc,打印机,监控摄像头)片面认为,access接口下面接的一定是终端。交换网络本身的工作原理是什么?交换机是基于MAC地址表转发的。hybrid(华为特有)_2019vlan
静态手势识别总体方案_手势识别有哪些方案-程序员宅基地
文章浏览阅读4.8k次,点赞3次,收藏44次。静态手势识别总体方案0.说明1.实现目标2.实现步骤1)总体思路2)每部分效果基于高斯肤色模型和动态阈值的手势分割基于Canny算法的轮廓提取基于Hu矩的量化基于傅里叶描述子的量化分类融合特征分类其他尝试0.说明静态手势识别是2019年四五月份做的一次设计,实验平台是Matlab。主要针对静态手势,采用肤色模型分离手部区域,提取手势的轮廓信息,采用不同的描述方式进行量化,最后采用BP神经网络和..._手势识别有哪些方案
机器学习(Machine Learning)&深度学习(Deep Learning)资料-程序员宅基地
文章浏览阅读1.4w次。##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 1)---#####注:机器学习资料[篇目一](https://github.com/ty4z2008/Qix/blob/master/dl.md)共500条,[篇目二](https://github.com/ty4z2008/Qix/blob/master/dl2.md)开始更新...
2021-05-03 GTX650刷入UEFI模块_gtx650 uefi-程序员宅基地
文章浏览阅读9.7k次。GTX650刷入UEFI模块gtx650黑苹果需要关闭csm模式,但是微软规定csm模式关闭必须得所有pcie设备开启uefi模式,但是老的gtx650中vbios没有uefi模块,所以需要先刷vbios,刷入方法在我的资源解压后的Inno3D UEFI Updater中的readme中,前提需要开启主板uefi模式,最好用gpuz备份好原来的bios。下面是简单的步骤,仅供参考,目前是实现了华硕GTX650-FMLII-1GD5的UEFI刷入,其他的显卡并没有实物卡测试。打开主板UEFI模式:._gtx650 uefi
【华为机试真题 Python实现】华为机试题整理(已更新211篇)_华为机试垂直矩阵-程序员宅基地
文章浏览阅读2.6w次,点赞26次,收藏269次。拆分输出字符串求n阶方阵里所有数的和合法的三角形个数整型数组求整数对最小和机器人走迷宫【2022 Q1 Q2 |200分】数格子两个超大整型数相加字符串格式化输出【2022 Q1 Q2 |100分】树形目录操作【2022 Q1 Q2 |200分】整型数组按个位值排序奥运会奖牌榜的排名【2022 Q1 | 100分】无重复字符的最长子串最长回文子串两个字符串的最长公共子串括号生成字符串处理一个正整数到 Excel 编号之间的转换字符串压缩搜索矩阵免单统计数组的转换藏宝_华为机试垂直矩阵
HZNUOJ1527_输入两个正整数x,y(其中x<y) 求x到y之间能被3整除的个数。 输入 输入两行,即x和y-程序员宅基地
文章浏览阅读853次。HZNUOJ1527(巨水题题解)Description输入两个正整数X,Y,求出[X,Y]内被除3余1并且被除5余3的整数的和Input输入两个正整数X,YOutput求所有满足条件的数的和对 x到 y进行遍历 并判断同时累计符合要求的个数。#include<stdio.h>int main(){ int x, y,sum=0; scanf("%d %d", &x, &y); for (int i = x; i <= y; i++) { i_输入两个正整数x,y(其中x