python——Thread类详解_python thread-程序员宅基地
threading
threading库是python的线程模型,利用threading库我们可以轻松实现多线程任务。
threading模块包含的类
包含常用的Thread,Queue,Lock,Event,Timer等类
threading模块常用方法
current_thread()
- threading.current_thread() : 返回当前的Thread类对象(线程对象)
在哪个线程中调用threading的current_thread方法就返回哪个线程。
import threading
# 在主线程中直接打印,可以看到返回主线程MainThread
print(threading.current_thread()) # <_MainThread(MainThread, started 22660)>
print(threading.current_thread().name) # MainThread
import threading
import time
# 创建子线程,在子线程中打印,打印的是正在执行的子线程
def task():
print('》》》线程:{thread}开始执行task'.format(thread=threading.current_thread().name))
time.sleep(1)
print('》》》线程:{thread}完成执行task'.format(thread=threading.current_thread().name))
t = threading.Thread(target=task, name='线程1')
t.start()
结果:
》》》线程:线程1开始执行task
》》》线程:线程1完成执行task
main_thread()
- threading.main_thread() : 返回当前主线程对象。即:启动python解释器的线程对象
import threading
import time
def task():
print('》》》线程:{thread}——开始执行task'.format(thread=threading.current_thread().name))
time.sleep(1)
print('》》》当前主线程:{thread}'.format(thread=threading.main_thread().name))
print('》》》线程:{thread}——完成执行task'.format(thread=threading.current_thread().name))
t = threading.Thread(target=task, name='线程1')
t.start()
结果
》》》线程:线程1——开始执行task
》》》当前主线程:MainThread
》》》线程:线程1——完成执行task
get_ident()
- threading.get_ident(): 返回当前线程的线程标识符。线程标识符是一个非负整数,并无特殊函数,只是用来标识线程,该整数可能会被循环利用。python3.3及以后版本支持该方法
import threading
import time
def task():
print('》》》线程号:{}——开始执行task'.format(threading.get_ident()))
time.sleep(5)
t1 = threading.Thread(target=task, name='线程1')
t1.start()
结果:
》》》线程号:35040——开始执行task
enumerate()
- threading.enumerate(): 返回当前处于alive状态的所有Thread对象的list
-alive状态指线程启动后、结束前,不包括启动前和终止后的线程。
import threading
import time
def task():
print('》》》线程:{}——开始执行task'.format(threading.current_thread().name))
time.sleep(5)
print('》》》线程:{}——完成执行task'.format(threading.current_thread().name))
t1 = threading.Thread(target=task, name='线程1')
t1.start()
t2 = threading.Thread(target=task, name='线程2')
t2.start()
t3 = threading.Thread(target=task, name='线程3')
t3.start()
print(threading.enumerate())
结果:
[<_MainThread(MainThread, started 25232)>, <Thread(线程1, started 32200)>, <Thread(线程2, started 13064)>, <Thread(线程3, started 10452)>]
active_count()
- threading.active_count() : 返回当前处于alive状态的线程个数
import threading
import time
def task():
print('》》》线程:{thread}——开始执行task'.format(thread=threading.current_thread().name))
time.sleep(5)
print('》》》线程:{thread}——完成执行task'.format(thread=threading.current_thread().name))
t1 = threading.Thread(target=task, name='线程1')
t1.start()
t2 = threading.Thread(target=task, name='线程2')
t2.start()
t3 = threading.Thread(target=task, name='线程3')
t3.start()
time.sleep(0.1)
print('》》》当前活跃线程数:{}'.format(threading.active_count()))
结果:
可以看到活跃线程数为4,包括:主线程,线程1,线程2,线程3
》》》线程:线程1——开始执行task
》》》线程:线程2——开始执行task
》》》线程:线程3——开始执行task
》》》当前活跃线程数:4
》》》线程:线程3——完成执行task
》》》线程:线程1——完成执行task
》》》线程:线程2——完成执行task
stack_size
- threading.stack_size([size]): 返回创建线程时使用的栈的大小。如果指定size参数,则用来指定后续创建的线程使用的栈大小,size必须是0(0表示使用系统默认值)或大于32K的正整数。
import threading
# 输出当前线程栈的大小
print(threading.stack_size()) # 0
# 设置后续线程栈的大小
threading.stack_size(43*1024) # 43*1024=44032
print(threading.stack_size()) # 44032
Thread类
Thread类是threading标准库中最重要的一个类。
你可以通过实例化Thread类,创建Thread对象,来创建线程。
你也可以通过继承Thread类创建派生类,并重写__init__和run方法,实现自定义线程对象类。
创建线程
1.实例化Thread类
通过实例化Thread类,来创建线程,通过target传入函数,即线程需要做的任务。
Thread类的构造函数:
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):
target:传入目标函数的名称
name:为线程名,一般命名格式为:Thread-N (N为small decimal number)
args:传入目标函数的参数,格式为元组。若目标函数需传关键字参数,可直接传入构造函数关键字组成的字典,无需传到任何参数。
daemon:标明此线程是否为守护线程(后文介绍),默认为False。
import threading
import time
def task(seconds):
print('》》》线程:{},开始执行task'.format(threading.current_thread().name))
time.sleep(seconds)
t1 = threading.Thread(target=task, args=(5,), name='Thread-1')
print(t1) # <Thread(Thread-1, initial)>
2.继承Thread类
创建子类继承Thread,通常重写run方法,在run方法写线程需要做的任务,然后实例化你创建的子类。
此方式具体原因请看下文的run方法。
启动线程
start()方法
调用Thread实例的start方法,会启动线程的活动。 每个线程对象最多只能调用一次。多次调用将引发RuntimeError错误。
线程启动后,将在子线程中,执行线程target传入的函数
import threading
import time
def task(seconds):
print('》》》线程:{},开始执行task'.format(threading.current_thread().name))
time.sleep(seconds)
print('》》》线程:{},结束执行task'.format(threading.current_thread().name))
t1 = threading.Thread(target=task, args=(1,), name='Thread-1')
t1.start() # 启动线程后,将在子线程中执行task函数
结果:
》》》线程:Thread-1,开始执行task
》》》线程:Thread-1,结束执行task
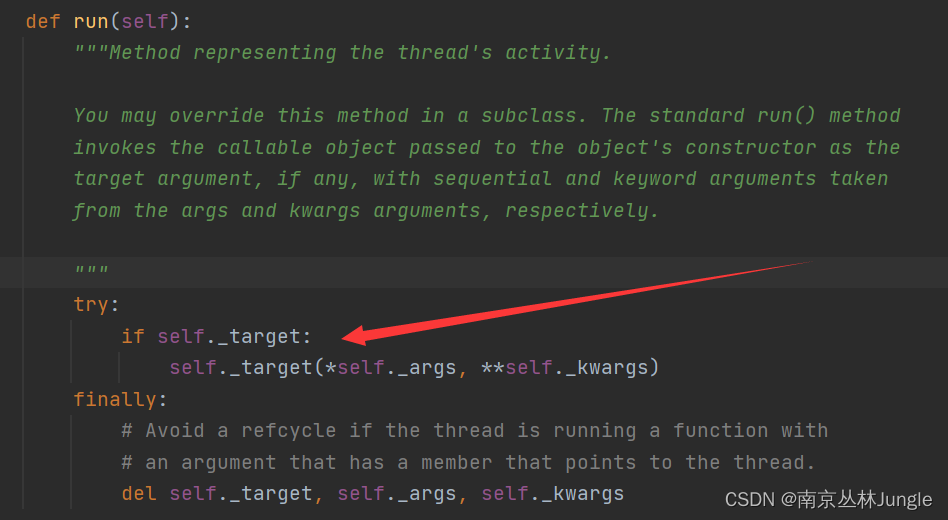
run()方法
用来实现线程的功能与业务逻辑,可以在子类中重写该方法来自定义线程的行为。
start()方法启动线程,实际上也是调用了run方法,在run方法中又调用了target传入的函数。
所以根本上,线程的功能和业务逻辑是在run方法去实现的,我们通过实例化Thread类target传入的功能函数也只是在run方法中去调了这个函数。
如果run方法没有被重写,并且target被定义,则会按照父类Thread的逻辑,直接调用实例化线程时传入target的方法,否则什么也不做。
如果你不想直接实例化Thread类,通过target传入线程的功能和业务逻辑,
你可以创建Thread的子类,且此子类的run方法被重写,启动此子类实例化的线程,则会直接调用重写的run方法的内容,target传入的函数则不会再被调用,除非你重写的run方法中人为调用了target传入的函数。所以在这种情况下,也不用再单独写个函数传入target。
import threading
import time
def task(seconds):
print('》》》线程:{},开始执行task'.format(threading.current_thread().name))
time.sleep(seconds)
print('》》》线程:{},结束执行task'.format(threading.current_thread().name))
class MyThread(threading.Thread):
def run(self) -> None:
print('run_test')
# Mythread类重写了run方法,则线程调用重写的run方法,target传入的函数将不起作用
t1 = MyThread(target=task, args=(1,), name='Thread-1')
t1.start()
结果:
run_test
综上,可以得出,如果你想创建线程:
1.可以直接通过创建实例化Thread类创建,并且通过target传入你想做的事情。
2.继承Thread类,重写run方法,在run方法中写你想做的事情,然后实例化你创建的子类。
线程执行顺序
在默认情况下,线程执行:
import threading
import time
def task(seconds):
print('》》》线程:{},开始执行task'.format(threading.current_thread().name))
while seconds > 0:
print('》》》线程:{0},倒计时:{1}秒'.format(threading.current_thread().name, seconds))
time.sleep(1)
seconds -= 1
print('》》》线程:{},结束执行task'.format(threading.current_thread().name))
t1 = threading.Thread(target=task, args=(2,), name='Thread-1')
t2 = threading.Thread(target=task, args=(2,), name='Thread-2')
t1.start()
t2.start()
print('》》》主线程打印:主线程的print')
print('》》》主线程打印:当前存活线程:{}'.format(threading.enumerate()))
结果:
》》》线程:Thread-1,开始执行task
》》》线程:Thread-1,倒计时:2秒
》》》线程:Thread-2,开始执行task
》》》主线程打印:主线程的print
》》》线程:Thread-2,倒计时:2秒
》》》主线程打印:当前存活线程:[<_MainThread(MainThread, started 19876)>, <Thread(Thread-1, started 24152)>, <Thread(Thread-2, started 35436)>]
》》》线程:Thread-1,倒计时:1秒
》》》线程:Thread-2,倒计时:1秒
》》》线程:Thread-1,结束执行task
》》》线程:Thread-2,结束执行task
由结果可以看出:
主线程代码顺序执行创建t1,t2两个Thread实例
子线程t1开始执行,并执行倒计时,遇到time的sleep阻塞时,释放GIL锁
此时,子线程t2开始执行
主线程的执行不受t1和t2两个子线程的影响,代码走到这,直接正常执行主线程打印
子线程t2执行倒计时,遇到time的sleep阻塞时,释放GIL锁,
主线程继续正常执行,打印当前存活线程。
子线程t2释放GIL锁之后,被子线程t1拿到,两者交替完成任务。
由以上可以看出:
1.主线程代码顺序执行,不会受子线程阻塞的影响。
2.主线程代码执行完毕后,会等待所有子线程执行完毕。
3.子线程遇到阻塞,会释放GIL锁,其他子线程继续执行,交替完成。
如果你想让子线程启动后,主线程代码阻塞,那么你可以使用子线程的join方法。
如果你想让主线程执行完毕后,不再等待未完成的子线程,可以将子线程设置为守护线程。
join()方法
Thread实例的join(timeout=None)方法用于阻塞主线程,可以想象成将某个子线程的执行过程插入(join)到主线程的时间线上,主线程的后续代码延后执行。
通俗地说就是是子线程告诉主线程,你要在设置join的位置等我执行完毕你再往下执行。
- 一个线程中调用另一个线程的join方法,调用者将被阻塞,直到被调用线程终止(正常退出或者抛出未处理的异常或者到达timeout的等待时间)。
- timeout参数指定调用者等待多久,如果没有设置超时,就一直等到被调用线程结束。
- 一个线程可以被join多次。
- join一定要在线程启动以后调用。
在上文线程执行顺序代码中,加入线程调用join方法:
import threading
import time
def task(seconds):
print('》》》线程:{},开始执行task'.format(threading.current_thread().name))
while seconds > 0:
print('》》》线程:{0},倒计时:{1}秒'.format(threading.current_thread().name, seconds))
time.sleep(1)
seconds -= 1
print('》》》线程:{},结束执行task'.format(threading.current_thread().name))
t1 = threading.Thread(target=task, args=(2,), name='Thread-1')
t2 = threading.Thread(target=task, args=(2,), name='Thread-2')
t1.start()
t2.start()
t1.join() # 主线程调用t1线程的join方法,那么主线程(调用者)将被阻塞,直到t1(被调用者)执行结束。
t2.join()
print('》》》主线程打印:主线程的print')
print('》》》主线程打印:当前存活线程:{}'.format(threading.enumerate()))
结果:
》》》线程:Thread-1,开始执行task
》》》线程:Thread-1,倒计时:2秒
》》》线程:Thread-2,开始执行task
》》》线程:Thread-2,倒计时:2秒
》》》线程:Thread-1,倒计时:1秒
》》》线程:Thread-2,倒计时:1秒
》》》线程:Thread-2,结束执行task
》》》线程:Thread-1,结束执行task
》》》主线程打印:主线程的print
》》》主线程打印:当前存活线程:[<_MainThread(MainThread, started 37320)>]
可以发现,主线程被阻塞掉,t1,t2线程执行完毕后,主线程打印函数才执行
daemon线程(守护线程)
上文提到,主线程代码执行完毕后,会等待所有子线程执行完毕,整个程序才退出。
因为子线程默认为【非守护线程】,主线程代码执行完毕,各子线程会继续运行,直到所有【非守护线程】结束,python程序退出。
如何理解守护线程:
是为守护别人而存在,当设置为守护线程后,被守护的主线程不存在后,守护线程也自然不存在,直接结束。
所以说,守护线程是不被考虑,爱允许到哪运行到哪,主线程不关心,不等待。可以理解为随时可以被终止的线程。
试用场景:
后台任务。如:发送心跳包,监控,这种场景最多
主线程工作时,才有用的线程。如:主线程中维护公共的资源,主线程已经清理了,准备退出,而工作线程使用这些资源工作也没有意义了,一起退出最合适。
注意:
如果daemon线程使用了join方法,主线程仍然会被阻塞,等待此线程执行完毕后主线程才会退出,所以这个线程的守护就没有意义了,它仍然是主线程需要等待线程。
所以如果你想让主线程执行完毕后,不再等待未完成的子线程,可以将子线程设置为守护线程(避开使用join方法):
daemon=True
- 实例化Thread时,传入daemon为True,标明此线程为守护线程
t1 = threading.Thread(target=task, args=(2,), name='Thread-1', daemon=True)
setDaemon(daemonic)方法
调用线程实例的setDaemon(daemonic)方法,daemonic传入True或者False。可以在线程创建以后再设置线程为守护线程。
- 务必在线程start前进行设置,否则会报异常。
t2 = threading.Thread(target=task, args=(2,), name='Thread-2')
t2.setDaemon(True)
直接对其daemon属性进行复制也行
t2 = threading.Thread(target=task, args=(2,), name='Thread-2')
t2.daemon = True
让我们来看一下守护线程的效果:
import threading
import time
def task(seconds):
print('》》》线程:{},开始执行task'.format(threading.current_thread().name))
while seconds > 0:
print('》》》线程:{0},倒计时:{1}秒'.format(threading.current_thread().name, seconds))
time.sleep(1)
seconds -= 1
print('》》》线程:{},结束执行task'.format(threading.current_thread().name))
t1 = threading.Thread(target=task, args=(2,), name='Thread-1', daemon=True)
t2 = threading.Thread(target=task, args=(2,), name='Thread-2')
t2.setDaemon(True)
t1.start()
t2.start()
print('》》》主线程打印:主线程的print')
print('》》》主线程打印:当前存活线程:{}'.format(threading.enumerate()))
结果:
》》》线程:Thread-1,开始执行task
》》》线程:Thread-1,倒计时:2秒
》》》线程:Thread-2,开始执行task
》》》主线程打印:主线程的print
》》》线程:Thread-2,倒计时:2秒》》》主线程打印:当前存活线程:[<_MainThread(MainThread, started 33608)>, <Thread(Thread-1, started daemon 36944)>, <Thread(Thread-2, started daemon 36532)>]
从以上结果可以看出,主线程打印完毕后,程序直接退出,因为t1和t2线程都是守护线程,都不被主线程关心,不被主线程等待。
Thread实例的其他属性和方法
| 属性 | 含义 |
|---|---|
| name | 只是一个名字,只是个标识,可以重复 |
| ident | 线程ID,它是非0整数,线程启动后才会有ID,否则为None,线程退出后此ID仍旧可以访问,此ID可以重复使用 |
| daemon | 是否为daemon线程的布尔值 |
| 方法 | 含义 |
|---|---|
| is_alive() | 返回线程是否活着 |
| isDaemon() | 返回线程是否为守护线程 |
| getName() | 返回线程名。 |
| setName() | 设置线程名。 |
多个线程创建使用
在需要创建多个线程时,可以将线程放入列表中,start,join方法都可以试用for循环进行调用。
第一个for循环同时启动了所有子线程,随后在第二个for循环中执行t.join() ,主线程实际被阻塞的总时长等于其中执行时间最长的一个子线程。
一定注意:所以线程必须全部start完毕,才可以进行join,所以start和join的for循环要分开写。
import threading
import time
def task(seconds):
print('》》》线程:{},开始执行task'.format(threading.current_thread().name))
time.sleep(1)
# while seconds > 0:
# print('》》》线程:{0},倒计时:{1}秒'.format(threading.current_thread().name, seconds))
# time.sleep(1)
# seconds -= 1
print('》》》线程:{},结束执行task'.format(threading.current_thread().name))
thread_list = []
for i in range(5):
t = threading.Thread(target=task, name="Thread-" + str(i + 1), args=(1,))
thread_list.append(t)
for thread in thread_list:
thread.start()
for thread in thread_list:
thread.join()
print('》》》主线程打印:主线程的print')
print('》》》主线程打印:当前存活线程:{}'.format(threading.enumerate()))
结果:
》》》线程:Thread-1,开始执行task
》》》线程:Thread-2,开始执行task
》》》线程:Thread-3,开始执行task
》》》线程:Thread-2,结束执行task
》》》线程:Thread-1,结束执行task
》》》线程:Thread-3,结束执行task
》》》主线程打印:主线程的print
》》》主线程打印:当前存活线程:[<_MainThread(MainThread, started 31036)>]
Process finished with exit code 0
Timer类
threading.Timer继承自Thread,所以就是线程类,具有线程的能力和特征,他的实例能够延时执行目标函数的线程,相当于一个定时器。
并且在到达既定时间真正执行目标函数之前,你都可以cancel,撤销执行。
实例创建:
threading.timer(interval, function, args=None, kwargs=None)
start方法执行以后,Timer对象处于等待状态,既定时间到后,开始执行function函数
import threading
def add(x, y):
print(x, y)
# 3秒钟之后执行线程
t = threading.Timer(3, add, args=(4, 5))
t.start()
print(threading.enumerate()) # [<_MainThread(MainThread, started 4301424000)>, <Timer(Thread-1, started 6184873984)>]
t.cancel()
只要这个Timer还没正式启动,还在等待,就可以使用cancel()方法停止掉
如果时间已经到了,函数已经开始执行了,那么这个cancel就没有任何效果了
import threading
import time
def add(x, y):
print(x, y)
t = threading.Timer(3, add, args=(4, 5))
t.start()
time.sleep(2)
t.cancel()
print('主线程打印')
以上代码在线程未到执行时间前,执行了cancel方法,进行了撤回,所以线程不会再启动。
智能推荐
linux devkmem 源码,linux dev/mem dev/kmem实现访问物理/虚拟内存-程序员宅基地
文章浏览阅读451次。dev/mem: 物理内存的全镜像。可以用来访问物理内存。/dev/kmem: kernel看到的虚拟内存的全镜像。可以用来访问kernel的内容。调试嵌入式Linux内核时,可能需要查看某个内核变量的值。/dev/kmem正好提供了访问内核虚拟内存的途径。现在的内核大都默认禁用了/dev/kmem,打开的方法是在 make menuconfig中选中 device drivers --> ..._dev/mem 源码实现
vxe-table 小众但功能齐全的vue表格组件-程序员宅基地
文章浏览阅读7.1k次,点赞2次,收藏19次。vxe-table,一个小众但功能齐全并支持excel操作的vue表格组件_vxe-table
(开发)bable - es6转码-程序员宅基地
文章浏览阅读62次。参考:http://www.ruanyifeng.com/blog/2016/01/babel.htmlBabelBabel是一个广泛使用的转码器,可以将ES6代码转为ES5代码,从而在现有环境执行// 转码前input.map(item => item + 1);// 转码后input.map(function (item) { return item..._让开发环境支持bable
FPGA 视频处理 FIFO 的典型应用_fpga 频分复用 视频-程序员宅基地
文章浏览阅读2.8k次,点赞6次,收藏29次。摘要:FPGA视频处理FIFO的典型应用,视频输入FIFO的作用,视频输出FIFO的作用,视频数据跨时钟域FIFO,视频缩放FIFO的作用_fpga 频分复用 视频
R语言:设置工作路径为当前文件存储路径_r语言设置工作目录到目标文件夹-程序员宅基地
文章浏览阅读575次。【代码】R语言:设置工作路径为当前文件存储路径。_r语言设置工作目录到目标文件夹
background 线性渐变-程序员宅基地
文章浏览阅读452次。格式:background: linear-gradient(direction, color-stop1, color-stop2, ...);<linear-gradient> = linear-gradient([ [ <angle> | to <side-or-corner>] ,]? &l..._background线性渐变
随便推点
【蓝桥杯省赛真题39】python输出最大的数 中小学青少年组蓝桥杯比赛 算法思维python编程省赛真题解析-程序员宅基地
文章浏览阅读1k次,点赞26次,收藏8次。第十三届蓝桥杯青少年组python编程省赛真题一、题目要求(注:input()输入函数的括号中不允许添加任何信息)1、编程实现给定一个正整数N,输出正整数N中各数位最大的那个数字。例如:N=132,则输出3。2、输入输出输入描述:只有一行,输入一个正整数N输出描述:只有一行,输出正整数N中各数位最大的那个数字输入样例:
网络协议的三要素-程序员宅基地
文章浏览阅读2.2k次。一个网络协议主要由以下三个要素组成:1.语法数据与控制信息的结构或格式,包括数据的组织方式、编码方式、信号电平的表示方式等。2.语义即需要发出何种控制信息,完成何种动作,以及做出何种应答,以实现数据交换的协调和差错处理。3.时序即事件实现顺序的详细说明,以实现速率匹配和排序。不完整理解:语法表示长什么样,语义表示能干什么,时序表示排序。转载于:https://blog.51cto.com/98..._网络协议三要素csdn
The Log: What every software engineer should know about real-time data's unifying abstraction-程序员宅基地
文章浏览阅读153次。主要的思想,将所有的系统都可以看作两部分,真正的数据log系统和各种各样的query engine所有的一致性由log系统来保证,其他各种query engine不需要考虑一致性,安全性,只需要不停的从log系统来同步数据,如果数据丢失或crash可以从log系统replay来恢复可以看出kafka系统在linkedin中的重要地位,不光是d..._the log: what every software engineer should know about real-time data's uni
《伟大是熬出来的》冯仑与年轻人闲话人生之一-程序员宅基地
文章浏览阅读746次。伟大是熬出来的 目录 前言 引言 时间熬成伟大:领导者要像狼一样坚忍 第一章 内圣外王——领导者的心态修炼 1. 天纵英才的自信心 2. 上天揽月的企图心 3. 誓不回头的决心 4. 宠辱不惊的平常心 5. 换位思考的同理心 6. 激情四射的热心 第二章 日清日高——领导者的高效能修炼 7. 积极主动,想到做到 8. 合理掌控自己的时间和生命 9. 制定目标,马..._当狼拖着受伤的右腿逃生时,右腿会成为前进的阻碍,它会毫不犹豫撕咬断自己的腿, 以
有源光缆AOC知识百科汇总-程序员宅基地
文章浏览阅读285次。在当今的大数据时代,人们对高速度和高带宽的需求越来越大,迫切希望有一种新型产品来作为高性能计算和数据中心的主要传输媒质,所以有源光缆(AOC)在这种环境下诞生了。有源光缆究竟是什么呢?应用在哪些领域,有什么优势呢?易天将为您解答!有源光缆(Active Optical Cables,简称AOC)是两端装有光收发器件的光纤线缆,主要构成部件分为光路和电路两部分。作为一种高性能计..._aoc 光缆
浏览器代理服务器自动配置脚本设置方法-程序员宅基地
文章浏览阅读2.2k次。在“桌面”上按快捷键“Ctrl+R”,调出“运行”窗口。接着,在“打开”后的输入框中输入“Gpedit.msc”。并按“确定”按钮。如下图 找到“用户配置”下的“Windows设置”下的“Internet Explorer 维护”的“连接”,双击选择“自动浏览器配置”。如下图 选择“自动启动配置”,并在下面的“自动代理URL”中填写相应的PAC文件地址。如下..._設置proxy腳本