TensorRT(8):动态batch进行推理_tensorrt动态batchsize-程序员宅基地
技术标签: c++ 计算机视觉 人工智能 推理框架|TensorRT
TensorRT系列传送门(不定期更新): 深度框架|TensorRT
一、引言
模型训练时,每次训练可以接受不同batch大小的数据进行迭代,同样,在推理时,也会遇到输入Tensor大小(shape)是不确定的情况,其中最常见的就是动态batch了。
动态batch,故名思意,就是只batch大小不确定的情况,比如这次推理了一张图像,下次推理就需要同时推理两张图像。
在Tensorflow中,定义一个动态batch的Tensor可以用 -1来表示动态的维度
tf.placeholder(tf.float32, shape=(-1, 1024))
而在TensorRT中,又是如何定义动态维度的呢?
本篇文章主要记录一下博主在TensorRT中使用动态batch的一些方法及技巧,如有错误,欢迎指正。
二、TRT在线加载模型,并序列化保存支持动态batch的引擎
这里与之前固定batch建立engine的流程相似,也需要经历以下几个步骤
- 1、创建一个builder
- 3、创建一个netwok
- 4、建立一个 Parser
- 5、建立 engine
- 6、建议contex
区别时建议engine时,config里需要设置一下OptimizationProfile文件
- step1 准备工作
首先准备一个具有动态batch的onnx模型,
至于如何从pytorch转支持动态batch的onnx模型,我在另一篇文章中,做过介绍,具体见
转出后,可以用netron来查看,转持的onnx模型,是否支持动态维度。
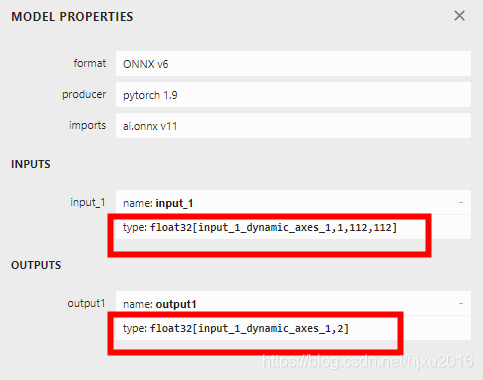
- step2 序列化保存模型的函数
#include <iostream>
#include "NvInfer.h"
#include "NvOnnxParser.h"
#include "logging.h"
#include "opencv2/opencv.hpp"
#include <fstream>
#include <sstream>
#include "cuda_runtime_api.h"
static Logger gLogger;
using namespace nvinfer1;
bool saveEngine(const ICudaEngine& engine, const std::string& fileName)
{
std::ofstream engineFile(fileName, std::ios::binary);
if (!engineFile)
{
std::cout << "Cannot open engine file: " << fileName << std::endl;
return false;
}
IHostMemory* serializedEngine = engine.serialize();
if (serializedEngine == nullptr)
{
std::cout << "Engine serialization failed" << std::endl;
return false;
}
engineFile.write(static_cast<char*>(serializedEngine->data()), serializedEngine->size());
return !engineFile.fail();
}
- step3 加载onnx模型,并构建动态Trt引擎
// 1、创建一个builder
IBuilder* pBuilder = createInferBuilder(gLogger);
// 2、 创建一个 network,要求网络结构里,没有隐藏的批量处理维度
INetworkDefinition* pNetwork = pBuilder->createNetworkV2(1U << static_cast<int>(NetworkDefinitionCreationFlag::kEXPLICIT_BATCH));
// 3、 创建一个配置文件
nvinfer1::IBuilderConfig* config = pBuilder->createBuilderConfig();
// 4、 设置profile,这里动态batch专属
IOptimizationProfile* profile = pBuilder->createOptimizationProfile();
// 这里有个OptProfileSelector,这个用来设置优化的参数,比如(Tensor的形状或者动态尺寸),
profile->setDimensions("input_1", OptProfileSelector::kMIN, Dims4(1, 1, 112, 112));
profile->setDimensions("input_1", OptProfileSelector::kOPT, Dims4(2, 1, 112, 112));
profile->setDimensions("input_1", OptProfileSelector::kMAX, Dims4(4, 1, 112, 112));
config->addOptimizationProfile(profile);
auto parser = nvonnxparser::createParser(*pNetwork, gLogger.getTRTLogger());
char* pchModelPth = "./res_hjxu_temp_dynamic.onnx";
if (!parser->parseFromFile(pchModelPth, static_cast<int>(gLogger.getReportableSeverity())))
{
printf("解析onnx模型失败\n");
}
int maxBatchSize = 4;
pBuilder->setMaxWorkspaceSize(1 << 30);
pBuilder->setMaxBatchSize(maxBatchSize);
设置推理模式
builder->setFp16Mode(true);
ICudaEngine* engine = pBuilder->buildEngineWithConfig(*pNetwork, *config);
std::string strTrtSavedPath = "./res_hjxu_temp_dynamic.trt";
// 序列化保存模型
saveEngine(*engine, strTrtSavedPath);
nvinfer1::Dims dim = engine->getBindingDimensions(0);
// 打印维度
print_dims(dim);
这里print_dims就是打印维度
void print_dims(const nvinfer1::Dims& dim)
{
for (int nIdxShape = 0; nIdxShape < dim.nbDims; ++nIdxShape)
{
printf("dim %d=%d\n", nIdxShape, dim.d[nIdxShape]);
}
}
可以看到,打印的dim0就是-1啦。

- step4 类IOptimizationProfile和枚举OptProfileSelector的简短介绍
我们可以看出,和固定batch构建engine不同之处,在设置build配置时时,增加了个IOptimizationProfile*配置文件,如设置维度需要增加以下操作
如
nvinfer1::IOptimizationProfile* createOptimizationProfile()
profile->setDimensions("input_1", OptProfileSelector::kMIN, Dims4(1, 1, 112, 112));
profile->setDimensions("input_1", OptProfileSelector::kOPT, Dims4(2, 1, 112, 112));
profile->setDimensions("input_1", OptProfileSelector::kMAX, Dims4(4, 1, 112, 112));
咱们来看看IOptimizationProfile这个类
class IOptimizationProfile
{
public:
//! 设置动态inputTensor的最小/最合适/最大维度
//! 不管时什么网络的输入的tensor,这个函数必须被调用三次(for the minimum, optimum, and maximum)
//! 一下列举了三种情况
//! (1) minDims.nbDims == optDims.nbDims == maxDims.nbDims == networkDims.nbDims
//! (2) 0 <= minDims.d[i] <= optDims.d[i] <= maxDims.d[i] for i = 0, ..., networkDims.nbDims-1
//! (3) if networkDims.d[i] != -1, then minDims.d[i] == optDims.d[i] == maxDims.d[i] == networkDims.d[i]
//! 如果选择了DLA,这三个值必须相同的
//!
virtual bool setDimensions(const char* inputName, OptProfileSelector select, Dims dims) noexcept = 0;
//! \brief Get the minimum / optimum / maximum dimensions for a dynamic input tensor.
virtual Dims getDimensions(const char* inputName, OptProfileSelector select) const noexcept = 0;
//! \brief Set the minimum / optimum / maximum values for an input shape tensor.
virtual bool setShapeValues(
const char* inputName, OptProfileSelector select, const int32_t* values, int32_t nbValues) noexcept
= 0;
//! \brief Get the number of values for an input shape tensor.
virtual int32_t getNbShapeValues(const char* inputName) const noexcept = 0;
//! \brief Get the minimum / optimum / maximum values for an input shape tensor.
virtual const int32_t* getShapeValues(const char* inputName, OptProfileSelector select) const noexcept = 0;
//! \brief Set a target for extra GPU memory that may be used by this profile.
//! \return true if the input is in the valid range (between 0 and 1 inclusive), else false
//!
virtual bool setExtraMemoryTarget(float target) noexcept = 0;
//! \brief Get the extra memory target that has been defined for this profile.
virtual float getExtraMemoryTarget() const noexcept = 0;
//! \brief Check whether the optimization profile can be passed to an IBuilderConfig object.
//! \return true if the optimization profile is valid and may be passed to an IBuilderConfig, else false
virtual bool isValid() const noexcept = 0;
protected:
~IOptimizationProfile() noexcept = default;
};
再看OptProfileSelector 这个枚举
这个枚举就三个值。最小、合适、和最大
// 最小和最大,指运行时,允许的最小和最大的范围
// 最佳值,用于选择内核,这里通常为运行时,最期望的大小
// 比如在模型推理时,有两路数据,通常batch就为2,batch为1或者为4出现的概率都比较低,
// 这时候,建议kOPT选择2, min选择1,如果最大路数为4,那max就选择四
enum class OptProfileSelector : int32_t
{
kMIN = 0, //!< This is used to set or get the minimum permitted value for dynamic dimensions etc.
kOPT = 1, //!< This is used to set or get the value that is used in the optimization (kernel selection).
kMAX = 2 //!< This is used to set or get the maximum permitted value for dynamic dimensions etc.
};
三、反序列化加载动态batch的引擎,并构建动态context,执行动态推理
定义一个加载engine的函数,和固定batch时一样的
ICudaEngine* loadEngine(const std::string& engine, int DLACore)
{
std::ifstream engineFile(engine, std::ios::binary);
if (!engineFile)
{
std::cout << "Error opening engine file: " << engine << std::endl;
return nullptr;
}
engineFile.seekg(0, engineFile.end);
long int fsize = engineFile.tellg();
engineFile.seekg(0, engineFile.beg);
std::vector<char> engineData(fsize);
engineFile.read(engineData.data(), fsize);
if (!engineFile)
{
std::cout << "Error loading engine file: " << engine << std::endl;
return nullptr;
}
IRuntime* runtime = createInferRuntime(gLogger);
if (DLACore != -1)
{
runtime->setDLACore(DLACore);
}
return runtime->deserializeCudaEngine(engineData.data(), fsize, nullptr);
}
然后按以下步骤执行推理
- 创建engine
- 创建context
- 在显卡上创建最大batch的的内存空间,这样只需要创建一次,避免每次推理都重复创建,浪费时间
- 拷贝动态tensor的内存
- 设置动态维度,调用context->setBindingDimensions()函数
- 调用context执行推理
- 查看输出结果
void test_engine()
{
std::string strTrtSavedPath = "./res_hjxu_temp_dynamic.trt";
int maxBatchSize = 4;
// 1、反序列化加载引擎
ICudaEngine* engine = loadEngine(strTrtSavedPath, 0);
// 2、创建context
IExecutionContext* context = engine->createExecutionContext();
int nNumBindings = engine->getNbBindings();
std::vector<void*> vecBuffers;
vecBuffers.resize(nNumBindings);
int nInputIdx = 0;
int nOutputIndex = 1;
int nInputSize = 1 * 112 * 112 * sizeof(float);
// 4、在cuda上创建一个最大的内存空间
(cudaMalloc(&vecBuffers[nInputIdx], nInputSize * maxBatchSize));
(cudaMalloc(&vecBuffers[nOutputIndex], maxBatchSize * 2 * sizeof(float)));
char* pchImgPath = "./img.bmp";
cv::Mat matImg = cv::imread(pchImgPath, -1);
std::cout << matImg.rows << std::endl;
cv::Mat matRzImg;
cv::resize(matImg, matRzImg, cv::Size(112, 112));
cv::Mat matF32Img;
matRzImg.convertTo(matF32Img, CV_32FC1);
matF32Img = matF32Img / 255.;
for (int i = 0; i < maxBatchSize; ++i)
{
cudaMemcpy((unsigned char *)vecBuffers[nInputIdx] + nInputSize * i, matF32Img.data, nInputSize, cudaMemcpyHostToDevice);
}
// 动态维度,设置batch = 1 0指第0个tensor的维度
context->setBindingDimensions(0, Dims4(1, 1, 112, 112));
nvinfer1::Dims dim = context->getBindingDimensions(0);
context->executeV2(vecBuffers.data());
//context->execute(1, vecBuffers.data());
float prob[8];
(cudaMemcpy(prob, vecBuffers[nOutputIndex], maxBatchSize * 2 * sizeof(float), cudaMemcpyDeviceToHost));
for (int i = 0; i < 8; ++i)
{
std::cout << prob[i] << " ";
}
std::cout <<"\n-------------------------" << std::endl;
// 动态维度,设置batch = 4
context->setBindingDimensions(0, Dims4(4, 1, 112, 112));
context->executeV2(vecBuffers.data());
//context->execute(1, vecBuffers.data());
(cudaMemcpy(prob, vecBuffers[nOutputIndex], maxBatchSize * 2 * sizeof(float), cudaMemcpyDeviceToHost));
for (int i = 0; i < 8; ++i)
{
std::cout << prob[i] << " ";
}
std::cout << "\n-------------------------" << std::endl;
//std::cout << prob[0] << " " << prob[1] << std::endl;
// call api to release memory
/// ...
return ;
}
结果打印中,可以看到,当batch为1时,输出后面6个值为0,当batch为4是,输出后面六个值都有正确的结果。咱们这里调用的是二分类的resnet50网络.

智能推荐
STM32芯片的ADC引脚的识别与选择_adc12_in4-程序员宅基地
文章浏览阅读1w次,点赞4次,收藏26次。1、以STM32F103ZET6芯片为例,ADC引脚分布为:2、可以看出,一共有IN0--IN15,16个ADC通道,通道IN0--IN9与芯片的其他功能复用了引脚。通道IN10--IN15是ADC独立的引脚。 且ADC1和ADC2有IN0--IN15 16个ADC通道。 而ADC3只有IN0、IN1、IN2、IN3、IN10、IN11、IN12、IN13通道。 ADC123_IN0表示ADC1、ADC2、ADC3都有通道IN0。 ADC12_IN4表示只有A..._adc12_in4
webpack test-程序员宅基地
文章浏览阅读1.3k次。webpack test_webpack test
java批量修改文件名后缀_java修改文件后缀名-程序员宅基地
文章浏览阅读1.4k次。java批量修改文件后缀名_java修改文件后缀名
jeecgboot按字段分表_jeecgboot 分表-程序员宅基地
文章浏览阅读1.3k次。在jeecgboot 使用mybatis框架,mybatis-plus3.1.1后支持分表,以下是在jeecg项目中实行分表一、修改mybatis-plus版本后,必须要在3.1.1版本后 <dependency> <groupId>com.baomidou</groupId> <artifactId>mybatis-plus-..._jeecgboot 分表
java字符串_gags69zzww-程序员宅基地
文章浏览阅读353次。一、字符串的特性:String 被声明为 final,因此它不可被继承。二、不同JDK版本中String的区别:①: 在 Java 8 中,String 内部使用 char 数组存储数据。②: 在 Java 9 之后,String 类的实现改用 byte 数组存储字符串,同时使用 coder 来标识使用了哪种编码。value 数组被声明为 final,这意味着 value 数组初始化之..._gags69zzww
虚拟机在PE系统下看不到硬盘_pe虚拟系统盘-程序员宅基地
文章浏览阅读9.2k次。故障说明:想在VM虚拟化系统里进入PE重置密码,结果PE系统看不到一个硬盘,空空荡荡的。解决方法:先在虚拟机设置里面看看SCSI控制器的当前类型,如果是准虚拟的情况下,就更改SAS类型即可更改SAS类型最后重新进入PE即可看到硬盘,更改这个参数并不会影响系统。..._pe虚拟系统盘
随便推点
航空航天数值分析matlab算法,数值分析 matlab-程序员宅基地
文章浏览阅读501次。"本书介绍数值方法的基本理论和计算方法,并讲述如何利用MATLAB软件实现各种数值算法。它的突出特点是把经典的数值方法内容与现代MATLAB计算软件相结合,书中每个概念均以实例说明,同时还包含大量习题与编程练习,通过这些实例提高读者的实践能力,并加深对数值计算方法的理解。本书经过缩编后适合一学期课"¥63.96定价:¥487.90(1.32折)1. 精心提炼数百个典型实例,全部源于作者的实际工作和..._数值分析在航空领域的应用
Zookeeper权限管理与Quota管理_zookeeper ip 和quota ip-程序员宅基地
文章浏览阅读598次。1 Zookeeper ACLZooKeeper的权限管理亦即ACL控制功能通过Server、Client两端协调完成:Server端:一个ZooKeeper的节点(znode)存储两部分内容:数据和状态,状态中包含ACL信息。创建一个znode会产生一个ACL列表,列表中每个ACL包括:l 验证模式(scheme)l 具体内容(Id)(当scheme=“digest”时,Id为用户名密码,例..._zookeeper ip 和quota ip
ocr数据集:图片数据集_ocr 图片集-程序员宅基地
文章浏览阅读684次。数据集数据集总数量为370万张图片图片数据集文件介绍测试数据集_ocr 图片集
python识图自动化_聊聊 Python 自动化截图的一些经验-程序员宅基地
文章浏览阅读357次。前言今天想先给大家分享 1 个小白用户的 Airtest 从入门到放弃的故事小 A 是一个自动化的小白,在逛测试论坛的时候,偶然间发现了 Airtest 这个基于图像识别的 UI 自动化框架出于好奇,小 A 试用了这个框架,发现只需要几条简单的截图脚本,就可以对设备进行各种自动化操作,于是小 A 成功种草了这个框架但几天之后,随着小 A 的深入使用,他发现截图脚本并不是他想象中那么“完美”;有时..._python识图框架
python语言的关键字是什么_Python语言的关键字有哪些特点?关键字列举-程序员宅基地
文章浏览阅读272次。在Python中,具有特殊功能的标识符称为关键字。关键字是Python语言自己已经使用的了,不允许开发者自己定义和关键字相同名字的标识符。Python中的关键字如下所示:FalseawaitelseimportpassNonebreakexceptinraiseTrueclassfinallyisretu..._python语言的关键字有哪些
pandas数据处理之groupby的常用用法_pandas怎么处理groupby的结果-程序员宅基地
文章浏览阅读2.8k次。groupby的数据处理简单用法groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)1、by:mapping, function, str, or iterable。用于确定gro..._pandas怎么处理groupby的结果