linux内存管理-几个重要的数据结构和函数_linux pgd-程序员宅基地
从硬件的角度来说,linux内核只要能为硬件准备好页面目录PGD、页面表PT以及全局段描述表GDT和局部段描述表LDT,并正确地设置有关的寄存器,就完成了内存管理机制中地址映射部分的准备工作。虽然最终的目的是地址映射,但是实际上内核所需要做的管理工作却要复杂的多。在与内存管理有关的内核代码中,有几个数据结构是很重要的,这些数据结构及其使用构成了代码中内存管理的基本框架。
页面目录PGD、中间目录PMD和页面表PT分别是由表项pgd_t、pmd_t记忆pte_t构成的数组,而这些表项又都是数据结构,定义如下:
/*
* These are used to make use of C type-checking..
*/
#if CONFIG_X86_PAE
typedef struct { unsigned long pte_low, pte_high; } pte_t;
typedef struct { unsigned long long pmd; } pmd_t;
typedef struct { unsigned long long pgd; } pgd_t;
#define pte_val(x) ((x).pte_low | ((unsigned long long)(x).pte_high << 32))
#else
typedef struct { unsigned long pte_low; } pte_t;
typedef struct { unsigned long pmd; } pmd_t;
typedef struct { unsigned long pgd; } pgd_t;
#define pte_val(x) ((x).pte_low)
#endif
#define PTE_MASK PAGE_MASK可见,当采用32位地址时,pgd_t、pmd_t和pte_t实际上就是长整型,而当采用36位地址时则是long long整数。之所以不直接定义成长整型的原因在于这样可以让gcc在编译时加以更严格的类型检查。同时,代码中又定义了几个简单的函数来访问这些数据结构的成分,如pte_val()、pgd_val()等(难怪有人说linux内核代码吸收可面向对象的程序设计手法)。但是,如我们以前说过的那样,表项PTE作为指针实际上只需要它的高20位。同时,所有的物理页面都是跟4K字节的边界对齐的,因而物理页面起始地址的高20位又可以看做物理页面的序号。所以,pte_t中的低12位用于页面的状态信息和访问权限。在内核代码中并没有在pte_t等结构中定义有关的位段,而是在page.h中另行定义了一个用来说明页面保存的结构pgprot_t:
typedef struct { unsigned long pgprot; } pgprot_t;
参数pgprof的值与i386 MMU的页面表项的低12位相对应,其中9位是标志位,表示所映射页面的当前状态和访问权限。内核代码中作了相应的定义:
#define _PAGE_PRESENT 0x001
#define _PAGE_RW 0x002
#define _PAGE_USER 0x004
#define _PAGE_PWT 0x008
#define _PAGE_PCD 0x010
#define _PAGE_ACCESSED 0x020
#define _PAGE_DIRTY 0x040
#define _PAGE_PSE 0x080 /* 4 MB (or 2MB) page, Pentium+, if present.. */
#define _PAGE_GLOBAL 0x100 /* Global TLB entry PPro+ */
#define _PAGE_PROTNONE 0x080 /* If not present */
注意这里的_PAGE_PROTNONE对应于页面表项中的bit7,在Intel的手册中说这一位保留不用,所以对MMU不起作用。
在实际使用中,pgprot的数值总是小于0x1000,而pte中的指针部分则总是大于0x1000,将二者合在一起就得到实际用于页面表中的表项。具体的计算是由pgtable.h中定义的宏操作mk_pte完成的:
#define __mk_pte(page_nr,pgprot) __pte(((page_nr) << PAGE_SHIFT) | pgprot_val(pgprot))
这里将页面序号左移12位,再与页面的控制、状况位段相或,就得到了表项的值。这里引用的两个宏操作定义如下:
#define pgprot_val(x) ((x).pgprot)
#define __pte(x) ((pte_t) { (x) } )内核中有个全局变量mem_map,是一个指针,指向一个page数据结构的数组(下面会讨论page结构),每个page数据结构代表着一个物理页面,整个数组就代表着系统中的全部物理页面。因此,页面表项的高20位对于软件和MMU硬件有着不同的意义。对于软件,这是一个物理页面的序号,将这个序号用作下标就可以从mem_map找到代表这个物理页面的page数据结构。对于硬件,则(在低位补上12个0后)就是物理页面的起始地址。
还有一个常用的宏操作set_pte(),用来把一个表项的值设置到一个页面表项中,这个宏操作定义如下:
#define set_pte(pteptr, pteval) (*(pteptr) = pteval)
在映射的过程中,MMU首先检查的是P标志位,就是上面的_PAGE_PRESENT,它指示着所映射的页面是否在内存中。只有在P标志位为1的时候MMU才会完成映射的全过程;否则就会因不能完成映射而产生一次缺页异常,此时表项中的其他内容对MMU就没有任何意义了。除MMU硬件根据页面表项的内容进行页面映射外,软件也可以设置或检测页面表项的内容,上面的set_pte就是用来设置页面表项。内核中还为检测页面表项的内容定义了一些工具性的函数或宏操作,其中最重要的有
#define pte_none(x) (!(x).pte_low)
#define pte_present(x) ((x).pte_low & (_PAGE_PRESENT | _PAGE_PROTNONE))
对软件来说,页面表项为0表示尚未为这个表项(所代表的虚存页面)建立映射,所以还是空白;而如果页面表项不为0,但P标志位为0,则表示映射已经建立,但是所映射的物理页面不在内存中(已经换出到交换设备上,详见后面的页面交换)。
static inline int pte_dirty(pte_t pte) { return (pte).pte_low & _PAGE_DIRTY; }
static inline int pte_young(pte_t pte) { return (pte).pte_low & _PAGE_ACCESSED; }
static inline int pte_write(pte_t pte) { return (pte).pte_low & _PAGE_RW; }当然,这些标志位只有在P标志位为1时才有意义。
如前所述,当页面表项的P标志位为1时,其高20位为相应物理页面起始地址的高20位,由于物理页面的起始地址必然是与页面边界对齐的,所以低12位一定是0。如果把整个物理内存看成一个物理页面的数组,那么这高20位(右移12位以后)就是数组的下标,也就是物理页面的序号。相应地,用这个下标,就可以在上述的page结构数组中找到代表目标物理页面的数据结构。代码中为此也定义了一个宏操作
#define pte_page(x) (mem_map+((unsigned long)(((x).pte_low >> PAGE_SHIFT))))
由于mem_map是page结构指针,操作的结果也是个page结构指针,mem_map+x与&mem_map[x]是一样的。在内核的代码中,还常常需要根据虚存地址找到相应物理页面的page数据结构,所以还为此定义了一个宏操作
#define virt_to_page(kaddr) (mem_map + (__pa(kaddr) >> PAGE_SHIFT))
代表物理页面的page数据结构的定义如下:
/*
* Try to keep the most commonly accessed fields in single cache lines
* here (16 bytes or greater). This ordering should be particularly
* beneficial on 32-bit processors.
*
* The first line is data used in page cache lookup, the second line
* is used for linear searches (eg. clock algorithm scans).
*/
typedef struct page {
struct list_head list;
struct address_space *mapping;
unsigned long index;
struct page *next_hash;
atomic_t count;
unsigned long flags; /* atomic flags, some possibly updated asynchronously */
struct list_head lru;
unsigned long age;
wait_queue_head_t wait;
struct page **pprev_hash;
struct buffer_head * buffers;
void *virtual; /* non-NULL if kmapped */
struct zone_struct *zone;
} mem_map_t;
内核中用来表示这个数据结构的变量名常常是page或map。
当页面的内容来自一个文件时,index代表着该页面在文件中的序号;当页面的内容被换出到交换设备上、但还保留着内容作为缓冲时,则index指明了页面的去向。结构中各个成分的次序是由讲究的,目的是尽量使得联系紧密的若干成分在执行时被装入高数缓存的同一缓冲线(16个字节)中。
系统中的每一个物理页面都有一个page结构(mem_map_t)。系统在初始化时根据物理内存的大小建立起一个page结构数组mem_map,作为物理页面的仓库,里面的每个page数据结构都代表着系统中的一个物理页面。每个物理页面的page结构在这个数组里的下标就是该物理页面的序号。仓库里的物理页面划分成ZONE_DMA和ZONE_NORMAL两个管理区(根据系统配置,还可能由第三个管理区ZONE_HIGHMEM,用于物理地址超过1GB的存储空间)。
管理区ZONE_DMA里的页面时专供DMA使用的。为什么供DMA使用的页面要单独加以管理呢?首先,DMA使用的页面是磁盘I/O所必须的,如果把仓库中所有的物理页面都分配光了,那就无法进行页面与盘区的交换了。此外,还有些特殊的原因。在i386 CPU中,页式存储管理的硬件支持是在CPU内核实现的,而不像另有些CPU那样由一个单独的MMU提供,所以DMA不经过MMU提供的地址映射。这样,外部设备就要直接提供访问物理页面的地址,可是有些外设(特别是插在ISA总线上的外设接口卡)在这方面往往有些限制,要求用于DMA的物理地址不能过高。另一方面,正因为DMA不经过MMU提供的地址映射,当DMA所需的缓冲区超过一个物理页面的大小时,就要求两个页面在物理上是连续的,因为此时DMA控制器不能依靠在CPU内部的MMU将连续的虚存页面映射到物理上不连续的页面。所以,用于DMA的物理页面是要单独加以管理的。
每个管理区都有一个数据结构,即zone_struct数据结构。在zone_struct数据结构中有一组空闲区间(free_area_t)队列。为什么是一组队列,而不是一个队列呢?这也是因为常常需要成块地分配在物理空间内连续的多个页面,所以要按块的大小分别加以管理。因此,在管理区数据结构中既要有一个队列来保持一些离散(连续长度为1)的物理页面,还要由一个队列来保持一些连续长度为2的页面块以及连续长度为4、8、16、32……、直至2^MAX_ORDER的页面块。常数MAX_ORDER定义为10,也就是说最大的连续页面块达到1024个页面,即4M字节。这两个数据结构以及几个常数定义如下:
/*
* Free memory management - zoned buddy allocator.
*/
#define MAX_ORDER 10
typedef struct free_area_struct {
struct list_head free_list;
unsigned int *map;
} free_area_t;
struct pglist_data;
typedef struct zone_struct {
/*
* Commonly accessed fields:
*/
spinlock_t lock;
unsigned long offset;
unsigned long free_pages;
unsigned long inactive_clean_pages;
unsigned long inactive_dirty_pages;
unsigned long pages_min, pages_low, pages_high;
/*
* free areas of different sizes
*/
struct list_head inactive_clean_list;
free_area_t free_area[MAX_ORDER];
/*
* rarely used fields:
*/
char *name;
unsigned long size;
/*
* Discontig memory support fields.
*/
struct pglist_data *zone_pgdat;
unsigned long zone_start_paddr;
unsigned long zone_start_mapnr;
struct page *zone_mem_map;
} zone_t;
#define ZONE_DMA 0
#define ZONE_NORMAL 1
#define ZONE_HIGHMEM 2
#define MAX_NR_ZONES 3
管理区结构中的offset表示该分区在mem_map中的起始页面号。一旦建立起了管理区,每个物理页面便永久地属于某一个管理区,具体取决于页面的起始地址,就好像一幢建筑物属于哪一个派出所管辖取决于其地址一样。空闲区free_area_struct结构中用来维护双向链表队列的结构list_head是一个通用的数据结构,linux内核中需要使用双向链表队列的地址都使用这种数据结构。结构很简单,就是prev和next两个指针。回到上面的page结构,其中的第一个成分就是一个list_head结构,物理页面的page结构正是通过它进入free_area_struct结构中的双向 链表队列的。在物理页面的分配博客中,我们将讲述内核怎样从它的仓库中分配一块物理空间,即若干连续的物理页面。
在传统的计算机结构中,整个物理空间都是均匀一致的,CPU访问这个空间中的任何一个地址所需的时间都相同,所以称为“均质存储结构”(uniform memory architecture)简称UMA。可是,在一些新的系统结构中,特别是在多CPU结构的系统中,物理存储空间在这方面的一致性却成了问题。试想有这么一种系统结构:
- 系统的中心是一条总线,例如PCI总线。
- 有多个CPU模块连接在系统总线上,每个CPU模块都有本地的物理内存,但是也可以通过系统总线访问其他CPU模块上的内存。
- 系统总线上还连接着一个公用的存储模块,所有的CPU模块都可以通过系统总线来访问它。
- 所有这些物理内存的地址互相连接而形成一个连续的物理地址空间。
显然,就某个特定的CPU而言,访问其本地的存储器是速度最快的,而穿过系统总线访问公用存储模块或其他CPU模块上的存储器就比较慢,而且还面临因可能的竞争而引起的不确定性。也就是说,在这样的系统中,其物理存储空间虽然地址连续,质地却不一致,所以称为“非均质存储结构”(non-uniform memory architecture)简称NUMA。在NUMA结构的系统中,分配连续的若干物理页面时一般都要求分配在质地相同的区间(称为node,即节点)。举例来说,要是CPU模块1要求分配4个物理页面,可是由于本模块上的空间已经不够,所以前3个页面分配在本模块上,而最后一个页面却分配到了CPU模块2上,那显然是不合适的。在这样的情况下,将4个页面都分配在公用模块上显然要好得多。
事实上,严格意义的UMA结构几乎是不存在的。就拿配置最简单的单CPU的PC来说,其物理存储空间就包括了RAM、ROM(用于BIOS),还有图形卡的静态RAM。但是在UMA结构中,除主存RAM以外的存储器都很小,所以把它们放在特殊的地址上成为小小的孤岛,再在编程时特别加以注意就可以了。然而,在典型的NUMA结构中就需要来自内核中内存管理机制的支持了。由于多处理器结构的系统日益广泛的应用,linux内核2.4.0版提供了对NUMA的支持(作为一个编译可选项)。
由于NUMA结构的引入,对于上述的物理页面管理机制也作了相应的修正。管理区不再是属于最高层的机构,而是在每个存储节点中都至少有两个管理区。而且前面的page结构数组也不再是全局性的,而是从属于具体的节点了。从而,在zone_struct结构(以及page结构数组)之上又有了另一层代表着存储节点的pglist_data数据结构,定义如下:
typedef struct pglist_data {
zone_t node_zones[MAX_NR_ZONES];
zonelist_t node_zonelists[NR_GFPINDEX];
struct page *node_mem_map;
unsigned long *valid_addr_bitmap;
struct bootmem_data *bdata;
unsigned long node_start_paddr;
unsigned long node_start_mapnr;
unsigned long node_size;
int node_id;
struct pglist_data *node_next;
} pg_data_t;
显然,若干存储节点的pglist_data数据结构可以通过指针node_next形成一个单链表队列。每个结构中的指针node_mem_map指向具体节点的page结构数组,而数组node_zones就是该节点的最多三个页面管理区。反过来,在zone_struct结构中也有一个指针zone_pgdat,指向所属节点的pglist_data数据结构。
同时,又在pglist_data结构里设置了一个数组node_zonelists,其类型定义也在同一个文件中:
typedef struct zonelist_struct {
zone_t * zones [MAX_NR_ZONES+1]; // NULL delimited
int gfp_mask;
} zonelist_t;这里的zones是个指针数组,各个元素按特定的次序指向具体的页面管理区,表示分配页面时先试着zones[0]所指向的管理区,如不能满足要求就试着zones[1]所指向的管理区,等等。这些管理区可以属于不同的存储节点。这样,针对上面所举的例子就可以规定:先试着本节点,即CPU模块1的ZONE_DMA管理区,若不够4个页面就全部从公共模块的ZONE_DMA管理区中分配,所以在pglist_data结构中提供的是一个zonelist_t数组,数组的大小为NR_GFPINDEX,定义为:
#define NR_GFPINDEX 0x100
就是说,最多可以规定256种不同的策略。要求分配页面时,要说明采用哪一种分配策略。
前面几个数据结构都是用于物理空间管理的,现在来看看虚拟空间的管理,也就是虚存页面的管理。虚存空间的管理不像物理空间的管理那样有一个总的物理页面仓库,而是以进程为基础的,每个进程都有各自的程序(用户)空间。不过,如前所述,每个进程的“系统空间”是统一为所有进程所共享的。以后我们对进程的虚存空间和用户空间这两个词常常会不加区分。
如果说物理空间是从供的角度来管理的,也就是:仓库中还有些什么;则虚存空间的管理是从需的角度来管理的,就是我们需要用虚存空间中的哪些部分。拿虚存空间中的用户空间部分来说,大概没有一个进程会真的需要使用全部的3G字节的空间。很自然地,对虚存空间的抽象是一个重要的数据结构。在linux内核中,这就是vm_area_struct数据结构,定义如下:
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
struct mm_struct * vm_mm; /* VM area parameters */
unsigned long vm_start;
unsigned long vm_end;
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next;
pgprot_t vm_page_prot;
unsigned long vm_flags;
/* AVL tree of VM areas per task, sorted by address */
short vm_avl_height;
struct vm_area_struct * vm_avl_left;
struct vm_area_struct * vm_avl_right;
/* For areas with an address space and backing store,
* one of the address_space->i_mmap{,shared} lists,
* for shm areas, the list of attaches, otherwise unused.
*/
struct vm_area_struct *vm_next_share;
struct vm_area_struct **vm_pprev_share;
struct vm_operations_struct * vm_ops;
unsigned long vm_pgoff; /* offset in PAGE_SIZE units, *not* PAGE_CACHE_SIZE */
struct file * vm_file;
unsigned long vm_raend;
void * vm_private_data; /* was vm_pte (shared mem) */
};
在内核的代码中,用于这个数据结构的变量名常常是vma。
结构中对的vm_start和vm_end决定了一个虚存区间。vm_start是包含在区间内的,而vm_end则不包含在区间内。区间的划分并不仅仅取决于地址的连续性,也取决于区间的其他属性,主要是对虚存页面的访问权限。如果一个地址范围内的前一半页面和后一半页面有不同的访问权限或其他属性,就得要分成两个区间。所以,包含在同一个区间里的所有页面都应有相同的访问权限(或者保护属性)和其他一些属性,这就是结构中的成分vm_page_prot和vm_flags的用途。属于同一个进程的所有区间都要按虚存地址的高低次序链接在一起,结构中的vm_next指针就是用于这个目的。由于区间的划分并不仅仅取决于地址的连续性,一个进程的虚存(用户)空间很可能会被划分成大量的区间。内核中给定一个虚拟地址而要找出其所属的区间是一个频繁用到的操作,如果每次都要顺着vm_next在链中做线性搜索的话,势必会显著地影响内核的效率。所以,除了通过vm_next指针把所有区间串联成一个线性队列以外,还可以在区间数量较大时为之建立一个AVL(Adelson-Velsky and Landis)树。AVL树是一种平衡的树结构,我们可以从有关的数据结构专著中了解到,在AVL树中搜索的速度快而代价是O(log n) ,即与树的大小的对数(而不是树的大小)成比例。虚存区间结构vm_area_struct中的vm_avl_left、vm_avl_right以及vm_avl_height三个成分就是用于AVL树,表示本区间在AVL树中的位置的。
在两种情况下虚存页面(或区间)会跟磁盘文件发生关系。一种是盘区交换(swap),当内存页面不够分配时,一些久未使用的页面可以被交换到磁盘上去,腾出物理页面以供更急需的进程使用,这就是大家所知道的一般意义上的按需调度页式虚存管理(demand paging)。另一种情况则是将一个磁盘文件映射到一个进程的用户空间中。linux提供了一个系统调用mmap(实际上是从Unix sysv r4.2开始的),使一个进程可以将一个已经打开的文件映射到其用户空间中,此后就可以像访问内存中一个字符数组那样来访问这个文件的内容,而不必通过lseek、read、write等进行文件操作。
由于虚存区间(最终是页面)与磁盘文件的这种联系,在vm_area_struct结构中相应的设置了一些成分,vm_next_share、vm_pprev_share、vm_file等,用以记录和管理此种联系。我们将在以后结合具体的情景介绍这些成分的使用。
虚存区间结构中另一个重要的成分是vm_ops,这是指向一个vm_operations_struct数据结构的指针。这个数据结构的定义如下:
/*
* These are the virtual MM functions - opening of an area, closing and
* unmapping it (needed to keep files on disk up-to-date etc), pointer
* to the functions called when a no-page or a wp-page exception occurs.
*/
struct vm_operations_struct {
void (*open)(struct vm_area_struct * area);
void (*close)(struct vm_area_struct * area);
struct page * (*nopage)(struct vm_area_struct * area, unsigned long address, int write_access);
};
结构中全是函数指针。其中open、close、nopage分别用于虚存区间的打开、关闭和建立映射。为什么要有这些函数呢?这是因为对于不同的虚存区间可能会需要一些不同的附加操作。函数指针nopage指示当因(虚存)页面不在内存中时而引起页面出错异常时所应调用的函数。
最后,vm_area_struct中还有一个指针vm_mm,该指针指向一个mm_struct数据结构,定义如下:
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct vm_area_struct * mmap_avl; /* tree of VMAs */
struct vm_area_struct * mmap_cache; /* last find_vma result */
pgd_t * pgd;
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
struct semaphore mmap_sem;
spinlock_t page_table_lock;
struct list_head mmlist; /* List of all active mm's */
unsigned long start_code, end_code, start_data, end_data;
unsigned long start_brk, brk, start_stack;
unsigned long arg_start, arg_end, env_start, env_end;
unsigned long rss, total_vm, locked_vm;
unsigned long def_flags;
unsigned long cpu_vm_mask;
unsigned long swap_cnt; /* number of pages to swap on next pass */
unsigned long swap_address;
/* Architecture-specific MM context */
mm_context_t context;
};
在内核的代码中,用于这个数据结构(指针)的变量名常常是mm。
显然,这是在比vm_area_struct更高层次上使用的数据结构。事实上,每个进程只有一个mm_struct结构,在每个进程的进程控制块,即task_struct结构中,有一个指针指向该进程的mm_struct结构。可以说,mm_struct数据结构是进程整个用户空间的抽象,也是总的控制结构。结构中的头三个指针都是关于虚存区间的。第一个mmap用来建立一个虚存区间结构的单链表线性队列。第二个mmap_avl用来建立一个虚存区间结构的AVL树,这在前面已经谈过。第三个指针mmap_cache,用来指向最近一次用到的那个虚存区间结构:这是因为程序中用到的地址常常带有局部性,最近一次用到的区间很可能就是下一次要用到的区间,这样就可以提高效率。另一个成分map_count,则说明在队列中(或AVL树中)有几个虚存区间结构,也就是说该进程有几个虚存区间。指针pgd显而易见是指向该进程的页面目录的,当内核调度一个进程进入运行时,就将这个指针转换成物理地址,并写入控制寄存器CR3,这在前面已经看到过了。另一方面,由于mm_struct以及其下属的vm_area_sturct结构都有可能在不同的上下文中受到访问,而这些访问又必须互斥,所以在结构中设置了用于P、V操作的信号量(semaphore),即mmap_sem。此外,page_table_lock也是为类似的目的而设置的。
虽然一个进程只使用一个mm_struct结构,反过来一个mm_struct结构去可能为多个进程所共享。最简单的例子就是,当一个进程创建(vfork或clone)一个子进程时,其子进程就可能与父进程共享一个mm_struct结构。所以,在mm_struct结构中还为此设置了计数器mm_users和mm_count。类型atomic_t实际上就是整数,但是对这种类型的整数进行的操作必须是原子的,也就是不允许因中断或其他原因而受到干扰。
结构中其他成分的用途比较显而易见,如start_code、end_code、 start_data、 end_data等等就是该进程映像中代码段、数据段、存储堆以及堆栈的起点和终点,这里就不多说了。注意,不要把进程映像中的这些段跟段式存储管理中的段相混淆。
如前所述,mm_struct结构以及其属下的各个vm_area_struct只是表明了对虚存空间的需求。一个虚拟地址有相应的虚存区间存在,并不保证该地址所在页面已经映射到某一个物理(内存或盘区)页面,更不保证该页面就在内存中。当一个未经映射的页面受到访问时,就会产生一个page fault异常(也称缺页异常、缺页中断),那时候page fault说明了对页面的需求;前面的page、zone_struct等结构则说明了对页面的供应;而页面目录、中间目录以及页面表则是二者中间的桥梁。
下面有个示意图,图中说明了用于进程虚存管理的各种数据结构之间的联系。
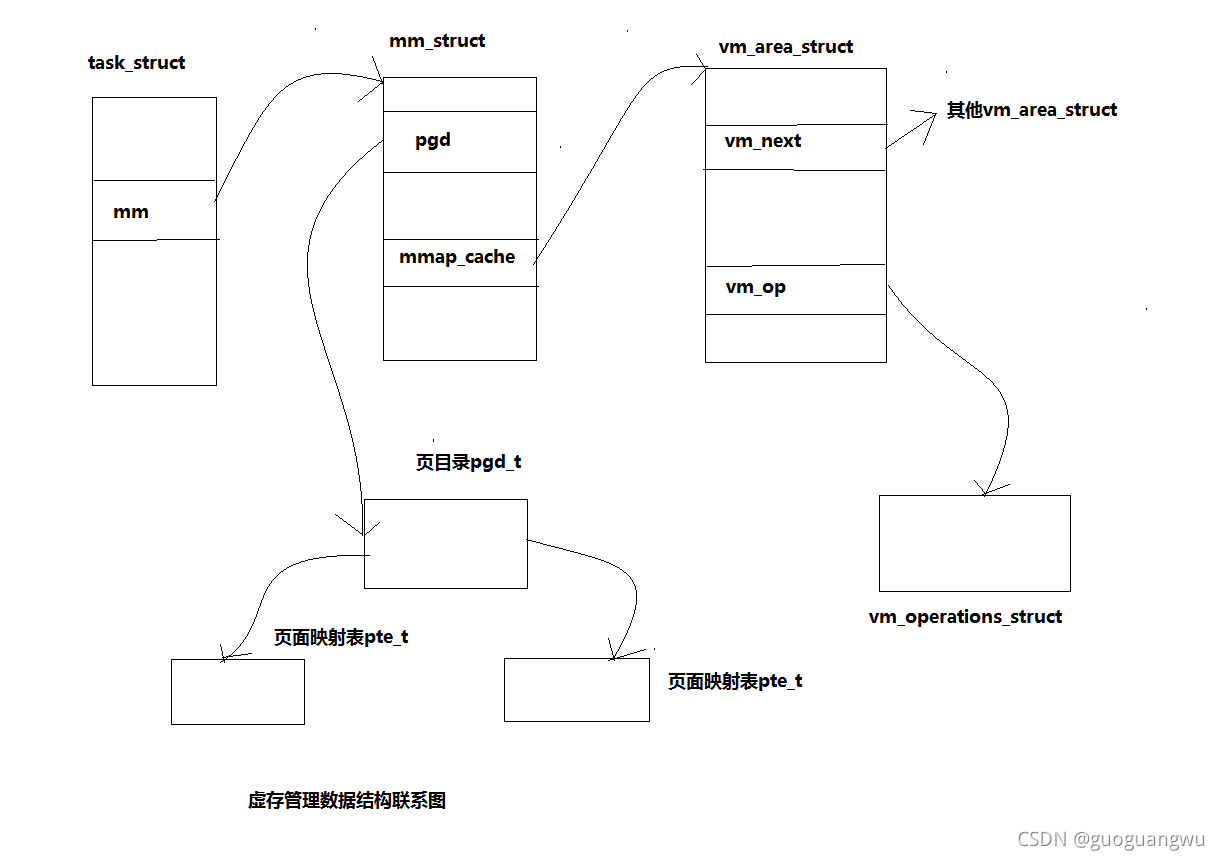
前面讲过,在内核中经常要用到这样的操作:给定一个属于某个进程的虚拟地址,要求找到其所属的区间以及相应的vm_area_struct结构。这是由find_vma来实现的,代码如下:
/* Look up the first VMA which satisfies addr < vm_end, NULL if none. */
struct vm_area_struct * find_vma(struct mm_struct * mm, unsigned long addr)
{
struct vm_area_struct *vma = NULL;
if (mm) {
/* Check the cache first. */
/* (Cache hit rate is typically around 35%.) */
vma = mm->mmap_cache;
if (!(vma && vma->vm_end > addr && vma->vm_start <= addr)) {
if (!mm->mmap_avl) {
/* Go through the linear list. */
vma = mm->mmap;
while (vma && vma->vm_end <= addr)
vma = vma->vm_next;
} else {
/* Then go through the AVL tree quickly. */
struct vm_area_struct * tree = mm->mmap_avl;
vma = NULL;
for (;;) {
if (tree == vm_avl_empty)
break;
if (tree->vm_end > addr) {
vma = tree;
if (tree->vm_start <= addr)
break;
tree = tree->vm_avl_left;
} else
tree = tree->vm_avl_right;
}
}
if (vma)
mm->mmap_cache = vma;
}
}
return vma;
}
当我们说到一个特定的用户空间虚拟地址时,必须说明是哪一个进程的虚存空间中的地址,所以函数的参数有两个,一个是地址,一个是指向该进程的mm_struct结构的指针。首先看一下这地址是否恰好在上一次(最近一次)访问过的同一个区间中。根据代码作者所加的注释,命中率一般可达35%,这也正是mm_struct结构中设置一个mmap_cache指针的原因。如果没有命中的话,那就要搜索了。如果已经建立过AVL结构(指针mmap_avl非0),就在AVL树中搜索,否则就在线性队列中搜索。最后,如果找到的话,就把mmap_cache指针设置成指向所找到的vm_area_struct结构。函数的返回值为0(NULL),表示改地址所属的区间还未建立。此时通常就得要建立起一个新的虚存区间结构,再调用insert_vm_struct将其插入到mm_struct中的线性队列或AVL树中去。函数insert_vm_struct的代码如下:
void insert_vm_struct(struct mm_struct *mm, struct vm_area_struct *vmp)
{
lock_vma_mappings(vmp);
spin_lock(¤t->mm->page_table_lock);
__insert_vm_struct(mm, vmp);
spin_unlock(¤t->mm->page_table_lock);
unlock_vma_mappings(vmp);
}
将一个vm_area_struct数据结构插入队列的操作实际是由__insert_vm_struct完成的,但是这个操作决不允许受到干扰,所以要对操作加锁。这里加了两把锁。第一把加在代表新区间的vm_area_struct数据结构中,第二把加在代表着整个虚存空间的mm_struct数据结构中,使得在操作过程中不让其他进程能够在中途插入进来,也对这两个数据结构进行队列操作。下面是__insert_vm_struct的主体,我们略去了与文件映射有关的代码。由于与find_vma很相似,这里就不加说明了。对AVL缺乏了解的读者可以只阅读不采用AVL树,即mm->mmap_avl为0的那一部分代码。
/* Insert vm structure into process list sorted by address
* and into the inode's i_mmap ring. If vm_file is non-NULL
* then the i_shared_lock must be held here.
*/
void __insert_vm_struct(struct mm_struct *mm, struct vm_area_struct *vmp)
{
struct vm_area_struct **pprev;
struct file * file;
if (!mm->mmap_avl) {
pprev = &mm->mmap;
while (*pprev && (*pprev)->vm_start <= vmp->vm_start)
pprev = &(*pprev)->vm_next;
} else {
struct vm_area_struct *prev, *next;
avl_insert_neighbours(vmp, &mm->mmap_avl, &prev, &next);
pprev = (prev ? &prev->vm_next : &mm->mmap);
if (*pprev != next)
printk("insert_vm_struct: tree inconsistent with list\n");
}
vmp->vm_next = *pprev;
*pprev = vmp;
mm->map_count++;
if (mm->map_count >= AVL_MIN_MAP_COUNT && !mm->mmap_avl)
build_mmap_avl(mm);
。。。。。。
}
当一个虚存空间中区间的数量较少时,在线性队列中搜索的效率并不成为问题,所以不需要为之建立AVL树。而当区间的数量增大到AVL_MIN_MAP_COUNT,即32时。就需要通过build_mmap_avl建立AVL树,以提高效率了。
智能推荐
使用radon变换进行直线检测_radon变换 直线检测-程序员宅基地
文章浏览阅读1.3w次,点赞5次,收藏41次。 最近做毕设,基础是利用radon变换进行直线检测。radon变换其实是对hough变换算法的优化,具体原理可自行查阅相关资料,在此不再赘述。本文要介绍的是利用matlab自带的radon变换函数进行直线检测,难点在于得到radon变换的结果后如何提取峰值并显示在原图上,下面将进行详细介绍。 matlab中自带的radon函数使用方法如下:[R,x]=radon(F,theta);..._radon变换 直线检测
Pytroch转Onnx实现(Unet的模型转Onnx)_pytorch unet onnx-程序员宅基地
文章浏览阅读1.5k次。主要是使用torch.onnx.export()这个方法来实现。Unet的实现参考:链接: https://blog.csdn.net/weixin_44791964/article/details/108866828.这位博主写的很详细,b站还有实现视频,手把手教学!!!Onnx转换实现代码import onnximport torch.onnxfrom unet import Unetunet=Unet()print(unet)model = torch.load('D:/Pycha_pytorch unet onnx
python函数myproduct_OpenERP与Python 元编程-程序员宅基地
文章浏览阅读61次。Python元编程被称为“黑魔法”。Python界的传奇人物Tim Peters有云:引用 Python的元编程这种黑魔法99%的人都无需了解,如果你拿不准是否应该用到它时,你不需要它.OpenERP基本遵循了Tim Peters的教诲,但是却在6.1版本之后忍不住触及了一点点,Technorati 标签: Openerp,Python,元编程从此游走于黑白两道之间:)其实OpenERP中用到的..._self.pool.get('product.product').create
mysql画本升级_MySQL 升级方法指南大全第4/5页-程序员宅基地
文章浏览阅读38次。MySQL 升级方法指南大全第4/5页更新时间:2008年01月26日 18:58:58 作者:通常,从一个发布版本升级到另一个版本时,我们建议按照顺序来升级版本。例如,想要升级 MySQL 3.23 时,先升级到 MySQL 4.0,而不是直接升级到 MySQL 4.1 或 MySQL 5.0。不兼容的变化:由于5.0中DECIMAL数据类型的实现方式发生了变化,因此如果使用就版本的库文...
.net托管与非托管以及GC(垃圾回收)_net 自定义的类都是非托管的吗-程序员宅基地
文章浏览阅读1.5k次。官方解释.NET Framework的核心是其运行库的执行环境,称为公共语言运行库(CLR)或.NET运行库。通常将在CLR的控制下运行的代码称为托管代码(managed code)。运行库环境(而不是直接由操作系统)执行的代码。托管代码应用程序可以获得公共语言运行库服务,例如自动垃圾回收、运行库类型检查和安全支持等。这些服务帮助提供独立于平台和语言的、统一的托管代码应用程序行为。托管代码是可以使用20多种支持Microsoft .NET Framework的高级语言编写的代码,它们包括:C._net 自定义的类都是非托管的吗
Vuex持久化插件(vuex-persistedstate)-解决刷新数据消失的问题-程序员宅基地
文章浏览阅读971次。vuex可以进行全局的状态管理,但刷新后刷新后数据会消失,这是我们不愿意看到的。怎么解决呢,我们可以结合本地存储做到数据持久化,也可以通过插件-vuex-persistedstate。1.手动利用HTML5的本地存储方法vuex的state在localStorage或sessionStorage或其它存储方式中取值在mutations,定义的方法里对vuex的状态操作的同时对存储也做对应..._解构导致vuex-persistedstate不进行缓存
随便推点
基于MFC的学生成绩管理系统_mfc fdlg.domodal()-程序员宅基地
文章浏览阅读483次。简单的MFC的课程设计,部分功能还没有优化,仅供参考_mfc fdlg.domodal()
C11新特性(部分)_c11特性-程序员宅基地
文章浏览阅读1.2k次,点赞6次,收藏15次。1.类型推导2.nullptr指针空值3.基于范围的for循环4.typedef与using5.新增容器_c11特性
bootstrap table的分页_bootstarp table 分页样式-程序员宅基地
文章浏览阅读419次。1:在官网上下载相关的文件之后,步骤下载之后引入:<!-- 引入的css文件 --><link href="bootstrap/css/bootstrap.min.css" rel="stylesheet" /><link href="bootstrap-table/dist/bootstrap-table.min.css" rel="styl..._bootstarp table 分页样式
编写一个简单的可加载内核模块-程序员宅基地
文章浏览阅读193次。2019独角兽企业重金招聘Python工程师标准>>> ..._listmonk 教程
合法的python赋值语句_Python基础 | 控制语句-程序员宅基地
文章浏览阅读1.6k次。选择结构选择结构有三种单分支,双分支,多分支单分支选择结构if ...1. 语法if 条件表达式:语句/语句块其中:1) 条件表达式: 可以是逻辑表达式,关系表达式,算术表达式等等2) 语句/语句块: 可以是一条语句,也可以是多条语句. 注意: 多条语句缩进要保持一致.# 单分支选择结构# 输入一个数字,小于10,则打印这个数字num = input("请输入一个数字: ")if float(nu..._输入一个数字,小于等于10,则打印这个数字;大于10,则打印“数字太大”
python判断手机号码是否正确_python检测手机号码是否合法-程序员宅基地
文章浏览阅读1.6k次。1 !/usr/bin/python2 #encoding:utf-83 #这是一个用来检测用户输入手机号码是否合法的小脚本。45 defphonecheck(s):6 #号码前缀,如果运营商启用新的号段,只需要在此列表将新的号段加上即可。7 phoneprefix=['130','131','132','133','134','135','136','137','..._python判断手机号是否有雄安