深度学习论文:Deep learning-Yann LeCun-Nature 2015_deep learning yann lecun-程序员宅基地
技术标签: 学术夜谈
Deep learning(Yann LeCun, Yoshua Bengio & Geoffrey Hinton)
doi:10.1038/nature14539
Abstract:
Deep learning allows computational models that are composed of multiple processing layers to learn representations of data with multiple levels of abstraction. These methods have dramatically improved the state-of-the-art in speech recognition,visual object recognition, object detection and many other domains such as drug discovery and genomics. Deep learning discovers intricate structure in large data sets by using the backpropagation algorithm to indicate how a machine should change its internal parameters that are used to compute the representation in each layer from the representation in the previous layer. Deep convolutional nets have brought about breakthroughs in processing images, video, speech and audio, whereas recurrent nets have shone light on sequential data such as text and speech.
深度学习允许由多个处理层组成的计算模型学习多层次抽象的数据表示。这些方法极大地提高了语音识别、视觉对象识别、对象检测和许多其他领域(如药物发现和基因组学)的先进水平。深度学习通过使用反向传播算法来发现大型数据集中的复杂结构,以指示机器应该如何改变其内部参数,这些参数用于从上一层的表示中计算每一层的表示。深度卷积网在处理图像、视频、语音和音频方面带来了突破性的进展,而递归网则在文本和语音等顺序数据方面大放异彩。
机器学习技术为现代社会的许多方面提供了动力:从网络搜索到社交网络上的内容过滤,再到电子商务网站上的推荐,它越来越多地出现在相机和智能手机等消费产品中。机器学习系统被用于识别图像中的对象,将语音转录为文本,将新闻项目、帖子或产品与用户的兴趣相匹配,并选择相关的搜索结果。"这些应用越来越多地使用一类称为深度学习的技术。
传统的机器学习技术在处理原始形式的自然数据方面能力有限。几十年来,构建一个模式识别或机器学习系统需要精心的工程设计和大量的领域专业知识,以设计一个特征提取器,将原始数据(如图像的像素值)转化为合适的内部表示或特征向量,学习子系统(通常是分类器)可从中检测或分类输入的模式。
表征学习是一组方法,它可以让机器获得原始数据,并自动发现检测或分类所需的表征。深度学习方法是具有多级特征的表征学习方法,通过组成简单但非线性的模块获得,这些模块分别将一个级别的表示(从原始输入开始)转换为更高的、略微抽象的级别的表示。通过组成足够多的这种变换,可以学习到非常复杂的函数。对于分类任务来说,更高的表示层放大了输入中对识别很重要的方面,并抑制了不相关的变化。例如,一幅图像以像素值阵列的形式出现,第一层表示中学习到的特征通常表示图像中特定方向和位置上是否存在边缘。第二层通常通过发现边缘的特定排列来检测图案,而不管边缘位置的微小变化。第三层可以将图案组装成更大的组合,这些组合对应于熟悉的物体的部分,后续层将检测物体作为这些部分的组合。深度学习的关键方面是,这些特征层不是由人类工程师设计的:它们是使用通用的学习程序从数据中学习的。
深度学习在解决多年来抵制人工智能界最佳尝试的问题上取得了重大进展。事实证明,它非常擅长发现高维数据中的复杂结构,因此适用于科学、商业和政府的许多领域。除了击败图像识别1-4和语音识别的记录外,它还在预测潜在药物分子的活性、分析粒子加速器数据、重建大脑回路以及预测非编码DNA中的突变对基因表达和疾病的影响等方面击败了其他机器学习技术。也许更令人惊讶的是,深度学习已经为自然语言理解中的各种任务,特别是主题分类、情感分析、问题回答和语言翻译产生了极有希望的结果。
我们认为,深度学习在不久的将来会有更多的成功,因为它只需要很少的人工工程,所以它可以很容易地利用可用计算和数据量的增加。目前正在为深度神经网络开发的新的学习算法和架构,只会加速这一进展。
1 Supervised learning 监督学习
机器学习最常见的形式,不管是不是深度学习,都是监督学习。想象一下,我们想建立一个系统,可以将图像分类,比如说,包含房子、汽车、人或宠物。我们首先得收集一个大的数据集,包括房子、汽车、人和宠物的图像,每个图像都标有它的类别。在训练过程中,机器会显示一张图像,并以分数向量的形式产生输出,每个类别都有一个分数。我们希望所需的类别在所有类别中得分最高,但这在训练前不太可能发生。
我们计算一个目标函数,衡量输出分数与期望分数模式之间的误差(或距离)。然后,机器会修改其内部的可调节参数来减少这个误差。这些可调参数,通常被称为权重,是实数,可以看作是定义机器输入输出函数的 "旋钮"。在一个典型的深度学习系统中,可能有数以亿计的这些可调节权重,以及数以亿计的标签化例子,用来训练机器。
为了适当地调整权重向量,学习算法计算出一个梯度向量,对于每个权重,这个梯度向量表示如果权重增加一个微小的量,误差会增加或减少多少。然后以梯度向量的相反方向调整权重向量。
对所有训练实例进行平均的目标函数,可以看作是高维权值空间中的一种丘陵景观。负梯度向量表示这种景观中最陡峭的下降方向,使其接近最小值,在这种情况下,输出误差平均较低。
在实践中,大多数参与者使用一种称为随机梯度下降(SGD)的策略。这包括显示几个例子的输入向量,计算输出和误差,计算这些例子的平均梯度,并相应调整权重。对训练集的许多小例子集重复这个过程,直到目标函数的平均值停止下降。之所以称为随机,是因为每一个小例子集都给出了所有例子的平均梯度的噪声估计。与更复杂的优化技术相比,这个简单的过程通常能出人意料地迅速找到一个好的权重集。训练结束后,系统的性能是在不同的例子集上测量的,称为测试集。这是为了测试机器的泛化能力--它在训练期间从在(未见过)的新输入上产生合理答案的能力。
自20世纪60年代以来,我们就知道线性分类器只能将输入空间划分为非常简单的区域,即由超平面分隔的半空间。但图像和语音识别等问题要求输入输出函数对输入的不相关变化不敏感,如物体的位置、方向或光照度的变化,或语音的音调或口音的变化,而对特定的微小变化,例如,白狼和被称为萨摩耶德的狼类白狗品种之间的差异非常敏感。在像素级别上,两只萨摩耶犬在不同姿势和不同环境下的图像可能彼此非常不同,而两只萨摩耶犬和狼在相同姿势和相似背景下的图像可能彼此非常相似。一个线性分类器,或者其他任何在原始像素上操作的浅层分类器都不可能将后两者区分开来,从而将前两者归为同一类。这就是为什么浅层分类器需要一个好的特征提取器来解决选择性不变性的难题,它产生的表征对图像中的识别很重要的方面是有选择性的,但对不相关的方面,如动物的姿势是不变的。为了使分类器更加强大,人们可以使用通用的非线性特征,就像内核方法一样,但是通用的特征,如高斯内核产生的特征,不允许学习者在远离训练实例的地方进行良好的泛化。传统的选择是手工设计好的特征提取器,这需要相当多的工程技能和领域专业知识。但如果能使用通用的学习程序自动学习好的特征,这一切都可以避免。这是深度学习的关键优势。
深度学习架构是一个由简单模块组成的多层堆栈架构,所有的或绝大部分模块都要进行学习,其中很多模块计算非线性的输入输出映射,堆栈中的每个模块都会对其输入进行变换,以增加表示的选择性和不变性。有了多个非线性层,比如5到20个深度,一个系统就可以对其输入实现极其复杂的功能,这些功能同时对微小的细节敏感如区分萨摩耶犬和白狼,而对大的不相关的变化如背景、姿势、灯光和周围的物体不敏感。

-------------------------
图1 多层神经网络和反向传播
a:多层神经网络,由连接的小点显示,可以扭曲输入空间,使数据的类别如例子在红线和蓝线上,可以线性分离。请注意,输入空间中的规则网格如左图所示,如何将被隐藏单元转化如中图所示。这是一个只有两个输入单元、两个隐藏单元和一个输出单元的说明性例子,但用于对象识别或自然语言处理的网络包含数万或数十万个单元。经C.Olah(http://colah.github.io/)授权转载。
b、导数链规则告诉我们两个小的效应,x对y的小变化,和y对z的小变化是如何构成的。x的一个微小变化Δx通过得到乘以∂y/∂x,首先转化为y的一个小变化Δy,即部分导数的定义。将一个方程代入另一个方程,就得到了导数的连锁规则Δx如何通过乘以∂y/∂x和∂z/∂x的乘积而变成Δz。当x、y和z是向量时,它也能起作用。
c、这个方程用于计算神经网中的前传,神经网有两层隐藏层和一层输出层,每一层构成一个模块,通过这个模块可以反推梯度。在每一层,我们首先计算每个单元的总输入z,它是下面一层单元输出的加权和。然后将一个非线性函数f(.)应用于z,得到单元的输出。为了简单起见,我们省略了偏置项。神经网络中使用的非线性函数包括近年来常用的整流线性单元(ReLU)f(z)=max(0,z),以及比较传统的sigmoids,如hyberbolic切线,f(z)=(exp(z)-exp(-z))/(exp(z)+exp(-z))和logistic函数logistic,f(z)=1/(1+exp(-z))。
d、用于计算后的公式,在每个隐藏层,我们计算相对于每个单元的输出的误差导数,它是相对于上一层单元的总输入的误差导数的加权和。然后,我们将相对于输出的误差导数乘以f(z)的梯度,转换成相对于输入的误差导数。在输出层,相对于单位输出的误差导数是通过微分成本函数计算出来的。如果单位l的成本函数为0.5(yl-
tl)2,其中tl为目标值,则给出yl - tl。一旦知道了∂E/∂zk,那么从下层单位j的连接上的权重wjk的误差推导就只是yj ∂E/∂zk。
-----------------------
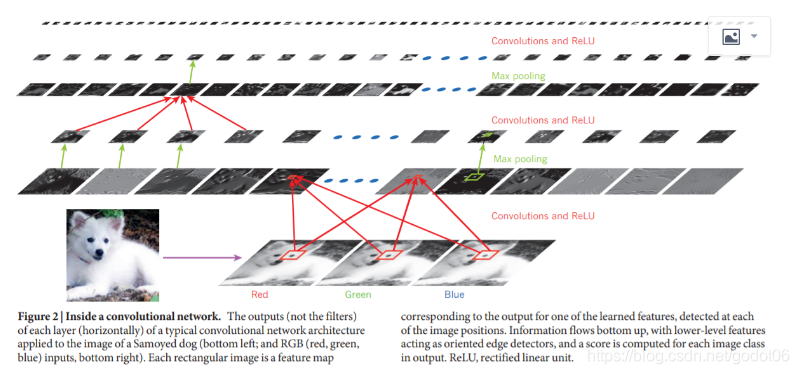
Fig2 :卷积网络内部
一个典型的卷积网络架构应用于萨摩耶犬图像,左下角和右下角为RGB红、绿、蓝输入的每一层在水平方向的输出不是滤波器。每个矩形图像是一个特征图对应于输出的一个学习特征,在每个图像位置检测到。信息自下而上流动,低级特征作为定向边缘检测器,在输出中为每个图像类计算得分。ReLU,整流线性单元。
2 Backpropagation to train multilayer architectures 训练多层架构的反向传播
从最早的模式识别开始,研究人员的目的就是用可训练的多层网络来代替手工设计的特征,但尽管它很简单,直到20世纪80年代中期,这个解决方案才被广泛理解。事实证明,多层架构可以通过简单的随机梯度下降来训练。只要模块的输入及其内部权重是相对平稳的函数,就可以使用反向传播程序计算其梯度。这个想法是可以做到的,而且是有效的,这是由几个不同的小组在20世纪70年代和80年代独立发现的。
计算目标函数相对于多层模块堆栈权重的梯度的反向传播过程,不过是导数链式规则的实际应用。最主要的是,目标函数相对于某个模块输入的导数或梯度可以通过对该模块输出或后续模块输入的梯度进行倒推计算,如图1。反向传播方程可以反复应用在所有模块中传播梯度,从顶部的输出即网络产生预测的地方,开始一直到底部即外部输入的地方。一旦计算出这些梯度,就可以直接计算出每个模块的权重的梯度。
深度学习的许多应用都使用前馈神经网络架构,如图1,它学习将一个固定大小的输入,例如,一个图像,映射到一个固定大小的输出,例如,几个类别中每个类别的概率。为了从一层到下一层,一组单元计算它们从上一层输入的加权和,并将结果通过一个非线性函数。目前,最流行的非线性函数是整流线性单元即ReLU,简单来说就是半波整流f(z)=max(z,0)。在过去的几十年里,神经网络使用了更平滑的非线性,如tanh(z)或1/(1+exp(-z)),但ReLU通常在具有许多层的网络中学习得更快,允许在没有无监督预训练的情况下训练深度监督网络。不在输入层或输出层的单元习惯上被称为隐藏单元。隐藏层可以看作是以非线性的方式对输入进行扭曲,使类别在最后一层变得可线性分离。
在20世纪90年代末,神经网和反向传播在很大程度上被机器学习界所抛弃,被计算机视觉和语音识别界所忽视。人们普遍认为,在几乎没有先验知识的情况下学习有用的、多阶段的特征提取器是不可行的。特别是,人们普遍认为,简单的梯度下降法会陷入局部最小值的困境,即权重配置的任何微小变化都不会减少平均误差。
在实践中,对于大型网络来说,表现差的局部最小值很少是一个问题。无论初始条件如何,系统几乎总是达到质量非常相似的解。最近的理论和经验结果强烈表明,局部最小值在一般情况下不是一个严重的问题。相反,景观被包装与梯度为零的大量鞍点的组合,和表面曲线在大多数维度和曲线除外。分析似乎表明,只有少数几个向下弯曲方向的鞍点以非常大的数量存在,但几乎所有鞍点的目标函数值都非常相似。因此,算法卡在这些鞍点中的哪一个并不太重要。
2006年前后,由加拿大高级研究所(CIFAR)召集的一组研究人员重新对深度前馈网络产生了兴趣。研究人员引入了无监督学习程序,可以在不需要标记数据的情况下创建特征检测器层。学习每一层特征检测器的目标是能够重建或模拟下一层特征检测器或原始输入的活动。通过使用这个重建目标来预训练几层逐渐复杂的特征检测器,深度网络的权重可以被初始化为合理的值。最后一层输出单元可以被添加到网络的顶部,整个深度系统可以使用标准的反向传播进行微调。这在识别手写数字或检测行人方面效果非常好,特别是当标签数据量非常有限时。
这种预训练方法的第一个主要应用是在语音识别中,它是由快速图形处理单元的出现而实现的,它方便编程,并允许研究人员以10或20倍的速度训练网络。2009年,该方法被用于将从声波中提取的系数的短时空窗口,映射为一组可能由窗口中心的帧所代表的各种语音片段的概率。它在使用小词汇量的标准语音识别基准上取得了破纪录的结果,并迅速发展到在大词汇量任务上给出破纪录的结果。到2012年,许多主要的语音集团都在开发2009年的深网版本,并且已经部署在Android手机中。对于较小的数据集,无监督的预训练有助于防止过度拟合,当标记的例子数量较少时,或者在转移环境中,我们对一些"源 "任务有很多例子,但对一些 "目标 "任务的例子很少时,会导致显著更好的泛化。一旦深度学习得到重建,就会发现预训练阶段只需要小数据集。
然而,有一种特殊类型的深层、前馈网络,比相邻层之间完全连接的网络更容易训练,泛化效果更好。这就是卷积神经网络。在神经网络不受欢迎的时期,它就取得了许多实际的成功,最近它被计算视觉界广泛采用。
3 Convolutional neural networks 卷积神经网络
ConvNets被设计用来处理以多个数组形式出现的数据,例如,一幅彩色图像由三个二维数组组成,其中包含三个颜色通道中的像素强度。许多数据方式都是以多个数组的形式出现的。1D的信号和序列,包括语言;2D的图像或音频谱图;3D的视频或体积图像。ConvNets背后有四个关键思想,即利用了自然信号的特性:局部连接、共享权重、池化和使用许多层。
一个典型的ConvNet的架构如图2,是由一系列阶段组成的。前几个阶段由两种类型的层组成:卷积层和池化层。卷积层中的单元被组织在特征图中,在特征图中,每个单元通过一组称为滤波库的权重与上一层特征图中的局部补丁相连。这个局部加权和的结果再通过一个非线性组件,如ReLU,一个特征图中的所有单元共享同一个滤波库。一个层中的不同特征图使用不同的滤波库。这种架构的原因有两个方面。首先,在图像等阵列数据中,局部的数值组往往高度相关,形成独特的局部图案,容易被检测到。其次,图像和其他信号的局部统计量相对位置是不变的。换句话说,如果一个图案可以出现在图像的某一部分,那么它可能出现在任何地方,因此,不同位置的单元共享相同的权重,在阵列的不同部分检测相同的图案。从数学上讲,特征图进行的滤波操作是一种离散卷积。
虽然卷积层的作用是检测上一层特征的局部联合,但池化层的作用是将语义相似的特征合并成一个特征。由于构成图案的特征的相对位置可能会有一定的变化,因此可以通过对每个特征的位置进行粗粒度检测,从而来可靠地检测图案。一个典型的池化单元计算一个特征图中或几个特征图中的局部斑块单元的最大值。邻近的池化单元从偏移超过一行或一列的斑块中获取输入,从而降低了表示的维度,并对小的偏移和失真产生了不变性。卷积、非线性和池化的两个或三个阶段被堆叠起来,然后是更多的卷积层和全连接层。通过ConvNet反传播梯度就像通过普通的深度网络一样简单,可以训练所有滤波器库中的所有权重。
深度神经网络利用了许多自然信号是组成层次结构的特性,其中高层次的特征是通过组成低层次的特征来获得的。在图像中,边缘的局部组合形成图案,图案组合成部件,部件形成对象。在语音和文本中,从声音到电话、音素、音节、单词和句子都存在类似的层次结构。当前一层的元素在位置和外观上发生变化时,池化使得表征的变化很小。
ConvNets中的卷积层和汇集层直接受到视觉神经科学中简单细胞和复杂细胞的经典概念的启发,整体架构让人联想到视觉皮层腹侧通路中的LGN-V1-V2-V4-IT层次结构。当ConvNet模型和猴子显示相同的图片,ConvNet中高级单位的激活解释了猴子的下颞皮层160个神经元随机集的一半方差。ConvNets的根源在于新认知器,其架构有些类似,但没有端到端监督学习算法,如反向传播。一种被称为延时神经网的原始1D ConvNet被用于音素和简单单词的识别。
卷积网络的大量应用可以追溯到20世纪90年代初,首先是用于语音识别和文档阅读的时间延迟神经网络。文档阅读系统使用一个ConvNet与一个实现语言约束的概率模型联合训练。到20世纪90年代末,这个系统已经读取了美国所有支票的10%以上。后来微软公司部署了一些基于ConvNet的光学字符识别和手写识别系统。在90年代初,ConvNets还被实验用于自然图像中的物体检测,包括人脸和手以及人脸识别。
4 Image understanding with deep convolutional networks 用深度卷积网络理解图像
自2000年初以来,ConvNets被成功地应用于图像中物体和区域的检测、分割和识别。这些都是标签数据相对丰富的任务,如交通标志识别,生物图像的分割特别是连接组学,以及自然图像中人脸、文本、行人和人体的检测.ConvNets最近取得的一个主要的实际成功是人脸识别。更重要的是,图像可以在像素级进行标记,这将在技术上得到应用,包括自主移动机器人和自动驾驶汽车。Mobileye和英伟达等公司正在他们即将推出的汽车视觉系统中使用这种基于ConvNet的方法。其他越来越重要的应用涉及自然语言理解和语音识别领域。

图3 从图像到文本 - 由循环神经网络生成的标题,作为额外的输入,由深度卷积神经网络,从测试图像中提取的表征,RNN被训练成将图像的高级表征"翻译"成标题。当RNN在生成每个单词时,被赋予将注意力集中在输入图像中不同位置的能力时,我们发现,它利用这一点来实现更好地将图像 "翻译"成标题。
尽管取得了这些成功,但ConvNets在很大程度上被主流计算机视觉和机器学习社区所抛弃,直到2012年的ImageNet竞赛。当深度卷积网络被应用于包含1000个不同类别的约100万张网络图像的数据集时,它们取得了惊人的结果,几乎将最佳竞争方法的错误率降低了一半。这种成功来自于GPU、ReLU、一种称为dropout的新正则化技术以及通过变形现有例子来生成更多训练例子的技术的有效使用。这一成功带来了计算机视觉的革命;ConvNets现在是几乎所有识别和检测任务的主导方法,并在一些任务上接近人类的性能。最近的一个惊人的演示结合了ConvNets和循环网模块来生成图像标题。
最近的ConvNet架构有10到20层的ReLU,数亿个权重,单元之间有数十亿个连接。仅在两年前,训练这样的大型网络可能需要数周的时间,而硬件、软件和算法并行化的进展已经将训练时间缩短到了几个小时。基于ConvNet的视觉系统的表现,使得包括谷歌、Facebook、微软、IBM、雅虎、Twitter和Adobe在内的大多数主要技术公司,以及迅速增长的初创企业纷纷启动研发项目,并部署基于ConvNet的图像理解产品和服务。ConvNets很容易在芯片或现场可编程门阵列中进行高效的硬件实现。英伟达、Mobileye、英特尔、高通和三星等多家公司正在开发ConvNet芯片,以实现智能手机、相机、机器人和自动驾驶汽车的实时视觉应用。
5 Distributed representations and language processing分布式表示和语言处理
深度学习理论表明,与不使用分布式表示的经典学习算法相比,深度网络有两个不同的指数优势。这两个优势都来自于组成的力量,并取决于底层数据生成分布具有适当的成分结构。首先,学习分布式表征能够泛化到学习特征值的新组合,超出训练期间看到的组合,例如,2n种组合是可能的n个二进制特征。其次,在深度网络中组成层的表征带来了另一个指数优势的潜力,即深度的指数。
多层神经网络的隐藏层学习以一种易于预测目标输出的方式来表示网络的输入。这一点可以通过训练多层神经网络,从早期单词的局部上下文中预测序列中的下一个单词来很好地证明。语境中的每个单词都以one-of-N向量的形式呈现给网络,也就是说,一个分量的值是1,其余的都是0.在第一层,每个单词都会产生不同的激活模式,或者说单词向量。在语言模型中,网络的其他层学习将输入的单词向量转换为预测下一个单词的输出单词向量,它可以用来预测词汇中任何单词作为下一个单词出现的概率。该网络学习的单词向量包含许多活跃的组件,其中每个组件都可以被解释为单词的一个独立特征,就像在学习符号的分布式表征的背景下首次展示的那样。这些语义特征并没有明确地存在于输入中。它们被学习程序发现,作为将输入和输出符号之间的结构关系因子化为多个 "微规则 "的好方法。当单词序列来自于大量真实文本的语料库,且单个微规则不可靠时,学习单词向量的效果也非常好。例如,当训练预测一个新闻报道中的下一个单词时,周二和周三的学习单词向量非常相似,瑞典和挪威的单词向量也是如此。这种表征被称为分布式表征,因为它们的元素特征并不相互排斥,它们的许多配置对应于观察到的数据中的变化。这些词向量由学习到的特征组成,这些特征不是由专家提前确定的,而是由神经网络自动发现的。从文本中学习到的词的向量表示目前在自然语言应用中得到了非常广泛的应用。
表征问题是认知的逻辑启发范式和神经网络启发范式之间争论的核心,在逻辑启发范式中,一个符号的实例是一个东西,对它来说,唯一的属性是它与其他符号实例要么相同,要么不相同。它没有与其使用相关的内部结构;而要对符号进行推理,就必须将其与明智地选择的推理规则中的变量进行绑定。相比之下,神经网络只是使用大的活动向量、大的权重矩阵和标量非线性来执行那种快速的 "直觉 "推理,而这种推理是毫不费力的常识推理的基础。
在引入神经语言模型之前,语言统计建模的标准方法并没有利用分布式表征:它是基于计算长度不超过N的短符号序列,称为N-grams的出现频率。可能的N-grams的数量在VN的数量级上,其中V是词汇量,因此考虑到上下文中超过一个 少数单词需要非常大的训练语料库,而N-gram将每个单词视为原子单位,因此它们无法在语义相关的单词序列中进行泛化,而神经语言模型则可以,因为它们将每个单词与实值特征向量相关联,而神经语言模型则可以。N-grams将每个单词视为一个原子单位,因此它们无法在语义相关的单词序列中进行泛化,而神经语言模型则可以,因为它们将每个单词与实值特征的向量相关联,语义相关的单词在该向量空间中最终相互接近。
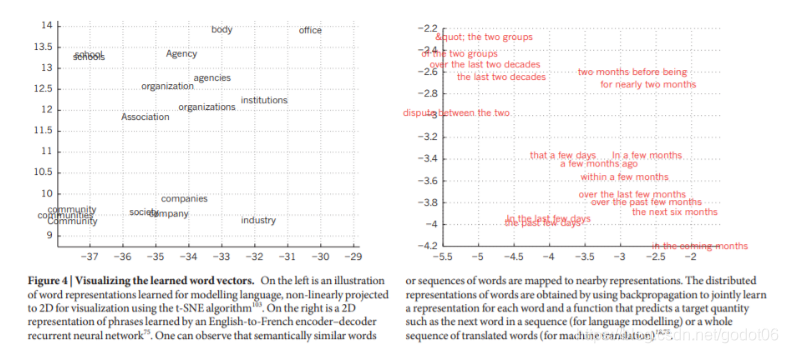
图4 可视化学习的单词向量
左边是为语言建模而学习的单词表示,非线性地投射到二维的可视化使用t-SNE算法。右边是由英语到法语的编码器-解码器循环神经网络学习的短语的2D表示。可以观察到,语义相似的单词或单词序列被映射到附近的表征上。词的分布式表征是通过使用反向传播来共同学习每个词的表征和预测目标量的函数,如序列中的下一个词或整个翻译词序列。
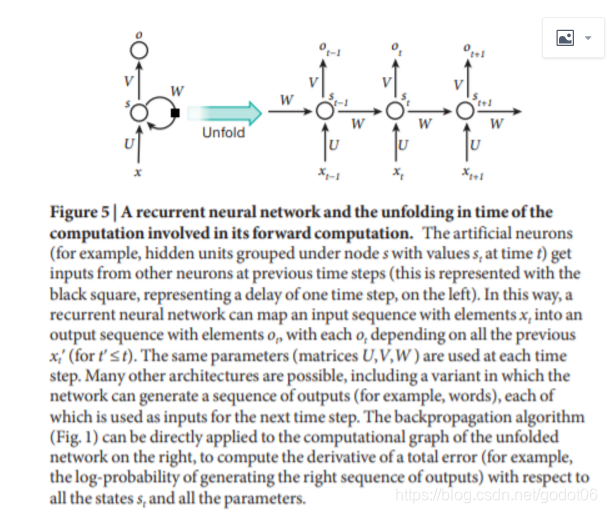
图5 一个递归神经网络及其前向计算中涉及的计算在时间上的展开
人工神经元,例如,在时间t的节点s下分组的隐藏单元,其值为st,在之前的时间步长中从其他神经元获得输入(这用左边的黑色方块表示,代表一个时间步长的延迟。这样一来,一个递归神经网络可以将一个具有元素xt的输入序列映射成一个具有元素ot的输出序列,每个ot取决于之前所有的xtʹ(对于tʹ≤t)。在每个时间步骤中使用相同的参数。许多其他的架构也是可能的,包括一种变体,在这种变体中,网络可以产生一系列的输出,例如,单词,,每一个输出都被用作下一个时间步的输入。反向传播算法(图1)可以直接应用于右边的展开网络的计算图,计算总误差的导数,例如,生成正确输出序列的对数概率与所有状态st和所有参数的关系。
6 Recurrent neural networks 循环神经网络
当反向传播刚被引入时,它最令人兴奋的用途是训练循环神经网络,即RNNs。对于涉及顺序输入的任务,如语音和语言,通常使用RNNs更好。RNNs每次只处理一个元素的输入序列,在它们的隐藏单元中维护着一个 "状态向量",它隐含着序列中所有过去元素的历史信息。当我们把隐藏单元在不同离散时间步长的输出看作是深层多层网络中不同神经元的输出时,我们如何应用反向传播来训练RNN就变得很清楚了。RNNs是非常强大的动态系统,但事实证明,训练它们是有问题的,因为反传播的梯度在每个时间步长或缩小,所以在许多时间步长,他们通常会爆炸或消失。
由于其架构和训练它们的方法的进步,RNNs已经被发现在预测文本中的下一个字符或序列中的下一个单词方面非常出色,但它们也可以用于更复杂的任务。例如,在一次一个单词阅读一个英语句子后,可以训练一个英语 "编码器 "网络,使其隐藏单元的最终状态向量很好地代表了该句子所表达的思想。然后,这个思想向量可以作为联合训练的法语 "解码器 "网络的初始隐藏状态或作为额外的输入,该网络输出法语翻译的第一个单词的概率分布。如果从这个分布中选择一个特定的第一个单词,并作为输入提供给解码器网络,那么它将输出翻译的第二个单词的概率分布,以此类推,直到选择一个完整的停止。总的来说,这个过程是根据一个取决于英语句子的概率分布来生成法语单词的序列。这种相当天真的执行机器翻译的方式已经迅速成为最先进的竞争力,这引起了严重的怀疑,即理解一个句子是否需要像使用推理规则操纵的内部符号表达。它更符合这样的观点,即日常推理涉及许多同时进行的类比,每个类比都为一个结论贡献了可信度。
与其将法语句子的意思翻译成英语句子,不如学习将图像的意思 "翻译 "成英语句子。这里的编码器是一个深度ConvNet,它在最后一个隐藏层中将像素转换为活动向量。解码器是一个类似于机器翻译和神经语言建模的RNN。最近,人们对这种系统的兴趣大增。RNNs,一旦在时间上展开,可以被看作是非常深的前馈网络,其中所有层共享相同的权重。虽然它们的主要目的是学习长期的依赖关系,但理论和经验证据表明,很难学习存储很长时间的信息。
为了纠正这种情况,一个想法是用显式记忆来增强网络。这种网络的第一个建议是使用特殊隐藏单元的长短期记忆(LSTM)网络,其自然行为是长期记忆输入。一个被称为记忆单元的特殊单元的行为就像一个累加器或一个门控漏电神经元:它在下一个时间步中与自己有一个权重为1的连接,所以它复制自己的实值状态并积累外部信号,但这个自连接被另一个单元乘法门控,它学会决定何时清除记忆内容。
LSTM网络随后被证明比传统的RNN更有效,特别是当它们的每个时间步骤有几个层时,使得整个语音识别系统能够从声学到转录中的字符序列的所有方式。LSTM网络或相关形式的门控单元目前也用于在机器翻译中表现出色的编码器和解码器网络。
在过去的一年里,有几位作者提出了不同的建议,用记忆模块来增强RNNs。这些建议包括神经图灵机和记忆网络,前者通过 "磁带式 "的存储器来增强网络,RNN可以选择从该存储器中读取或写入88,后者通过一种关联存储器来增强常规网络。记忆网络在标准问题回答基准上取得了优异的性能。记忆是用来记忆故事的,以后要求网络回答问题时,就会用到这个故事。
除了简单的记忆之外,神经图灵机和记忆网络正在被用于通常需要推理和符号操作的任务。神经图灵机可以被教会 "算法"。其中,当它们的输入由一个未排序的序列组成时,它们可以学习输出一个排序的符号列表,其中每个符号都伴随着一个表示其在列表中优先级的实际值。记忆网络可以被训练成在类似文字冒险游戏的环境中跟踪世界的状态,在阅读一个故事后,它们可以回答需要复杂推理的问题。在一个测试例子中,网络被展示了15个句子版本的《指环王》,并正确地回答了诸如 "佛罗多现在在哪里?"等问题。
7 The future of deep learning
无监督学习在恢复人们对深度学习的兴趣方面起到了催化作用,但后来被纯监督学习的成功所掩盖。虽然我们在这篇评论中没有关注它,但我们预计无监督学习在长期内会变得更加重要。人类和动物的学习在很大程度上是无监督的:我们通过观察世界来发现世界的结构,而不是通过被告知每个物体的名称。
人类的视觉是一个主动的过程,它以一种智能的、特定任务的方式,使用一个小的、高分辨率的蜂窝和一个大的、低分辨率的环绕,对视阵进行顺序采样。我们预计未来视觉领域的大部分进展将来自于端到端的训练系统,并将ConvNets与RNNs结合起来,使用强化学习来决定看哪里。结合深度学习和强化学习的系统还处于起步阶段,但它们已经在分类任务上优于被动视觉系统,并在学习玩许多不同的视频游戏方面产生了令人印象深刻的结果。
自然语言理解是另一个领域,深度学习将在未来几年内产生巨大影响。我们预计,当使用RNNs理解句子或整个文档的系统学习,到每次有选择地参加一个部分的策略时,它们将变得更好。
最终,人工智能的重大进展将通过结合表征学习和复杂推理的系统来实现。虽然深度学习和简单推理已经在语音和手写识别中使用了很长时间,但需要新的范式来取代基于规则的符号表达式操作,对大向量进行操作。
部分参考及图例说明参考来源:https://blog.csdn.net/zxggghjju/article/details/107594642
论文来源:doi:10.1038/nature14539
供大家一起学习交流,这是一篇对深度学习的详尽描述
智能推荐
Socket通信,实现简单的双人聊天功能_react+socket.io怎么进行两台电脑聊天-程序员宅基地
文章浏览阅读478次。Socket通信1.简单介绍学习Socket也只是通过一个小例子学习的,关于Socket原理目前只是了解到是基于TCP协议,关于TCP与UDP协议区别可以去百度详情查一下他们的区别之处,大体上是传输高效与安全方面的区别。2.代码实现关于双人聊天功能实现时候,大体分为一个客户端类,一个服务端类,服务器与客户端之间可以相互发送消息。在客户端和服务端中有监听类和发送类,实现互相之间发送消息。核心代码://监听消息及打印出ObjectInputStream ois = new Obje._react+socket.io怎么进行两台电脑聊天
[Java]JavaWeb学习笔记(尚硅谷2020旧版)_javaweb笔记 尚硅谷-程序员宅基地
文章浏览阅读2.7k次,点赞3次,收藏32次。 Tomcat JavaWeb相关概念 Web资源的分类 常用的 Web 服务器 Tomcat 服务器和 Servlet 版本的对应关系 Tomcat的使用 下载 Tomcat目录介绍 启动Tomcat服务器方式一 常见启动失败情况 双击 startup.bat 文件出现一个小黑窗口一闪而过 常见JAVA_HOME配置失败情况 启动Tomcat服务器方式二 Tomcat 的停止 修改 Tomcat 的端口号 部暑 web 工程到_javaweb笔记 尚硅谷
linux curl命令_curl 输出到文件-程序员宅基地
文章浏览阅读1.8k次。curl命令是一个利用URL规则在命令行下工作的文件传输工具。它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具。作为一款强力工具,curl支持包括HTTP、HTTPS、ftp等众多协议,还支持POST、cookies、认证、从指定偏移处下载部分文件、用户代理字符串、限速、文件大小、进度条等特征。做网页处理流程和数据检索自动化,curl可以祝一臂之力。语法curl(选项..._curl 输出到文件
Flutter 常用插件_flutter 插件集合-程序员宅基地
文章浏览阅读3.7k次,点赞3次,收藏18次。flutter 常用插件_flutter 插件集合
ESP32超详细学习记录:wifi配网,AP配网,浏览器配网,无线配网_esp32网页配置wifi-程序员宅基地
文章浏览阅读2.8w次,点赞105次,收藏408次。ESP32配网,wifi配网模式,可清除以前配网信息。移植方便!可改改函数用于无线调参。_esp32网页配置wifi
vscode使用git教程_vscode git 本地-程序员宅基地
文章浏览阅读1.5w次,点赞11次,收藏81次。vscode使用git教程git基本配置就不写了vscode配置直接上图清晰明了按照图片出现的顺序 "git.path": "D:/Git/bin/git.exe", "terminal.integrated.shell.windows": "D://Git//bin//bash.exe", "git.autofetch": true把上面代码写入setting.json..._vscode git 本地
随便推点
2023/9/17 基于pycharm的爬取豆瓣电影250(一)_如何用pycharm找电影-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏16次。最近用一周的时间进行学习,因此特地记录所学知识,并向外输出以此加深自己的印象。_如何用pycharm找电影
【网络】WireShark过滤 | WireShark实现TCP三次握手和四次挥手_tcp中过滤tcp三次握手-程序员宅基地
文章浏览阅读3.3k次,点赞135次,收藏157次。wireshark是非常流行的网络封包分析软件,功能十分强大。可以截取各种网络封包,显示网络封包的详细信息。常用来检测网络问题、攻击溯源、或者分析底层通信机制。_tcp中过滤tcp三次握手
MYSQL数据类型、范式及索引总结_mysql int和tyint-程序员宅基地
文章浏览阅读2.7k次,点赞3次,收藏2次。MySQL基础(MySQL5.1)MySQL的数据类型MySQL数据类型简介整数类型、浮点数类型和定点数类型日期与时间类型字符串类型二进制类型MySQL数据类型选择MySQL范式MySQL范式介绍MySQL范式联系与转化MySQL索引索引的含义及特点索引的分类MySQL建立索引原则MySQL创建索引MySQL删除索引MySQL索引的有效性索引的使用规则MySQL的数据类型MySQL数据类型简介整数类型、浮点数类型和定点数类型整数: 如上表所示INT和INTEGER的字节数与取值范围相同,其实,在M_mysql int和tyint
【HTTP】998- 经得住拷问的 HTTPS 原理解析-程序员宅基地
文章浏览阅读1.1k次。HTTPS 是在 HTTP 和 TCP 之间建立了一个安全层,HTTP 与 TCP 通信的时候,必须先进过一个安全层,对数据包进行加密,然后将加密后的数据包传送给 TCP,相应的 TCP ..._http status 998
MultipartHttpServletRequest 多文件上传。个人demo-程序员宅基地
文章浏览阅读6.5k次。编辑
python 类中的__call__是什么?-程序员宅基地
文章浏览阅读3k次,点赞3次,收藏12次。随便定义一个函数输入def say() : print("小白一起学python")输出小白一起学python -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- -- 小白一起学pythoncall方法是把对象当成函数来使用的时候,会自动调用。参考链接。___call__