RCNN系列总结:RCNN -> Fast RCNN -> Faster RCNN概述_rcnn中的xy-程序员宅基地
RCNN
传统的目标检测方法分为区域选择、特征提取(SIFT、HOG等)、分类器(SVM等)三部分,其主要问题有两方面:
- 区域选择策略没有针对性、时间复杂度高,窗口冗余;
- 手工设计的特征鲁棒性较差;
RCNN ( Region-based Convolutional Neural Networks )
RCNN 创新点:
- 采用CNN提取图像特征,从经验驱动的人造特征范式HOG、SIFT到数据驱动的表示学习范式,提高特征对样本的表示能力;
- 采用大样本下有监督预训练(迁移学习)+小样本微调的方式解决小样本难以训练甚至过拟合等问题(迁移学习)。
训练流程:
- 使用 selective search 方法提取大约20k个 region proposal,再warp缩放到固定尺寸(227 x 227);
- 特征提取:CNN 从每个region proposal 中提取一个4096维的特征(Alexnet,5层conv,2层fc),输出为2000 x 4096;
- 类别分类:使用SVM对4096维的特征进行分类,得到2000 x 20的矩阵(20中类别),然后对每一列进行NMS非极大值抑制;
- 位置修正:回归器校正剩余的region,输入CNN网络pool5层的特征,输出为xy方向的缩放和平移;
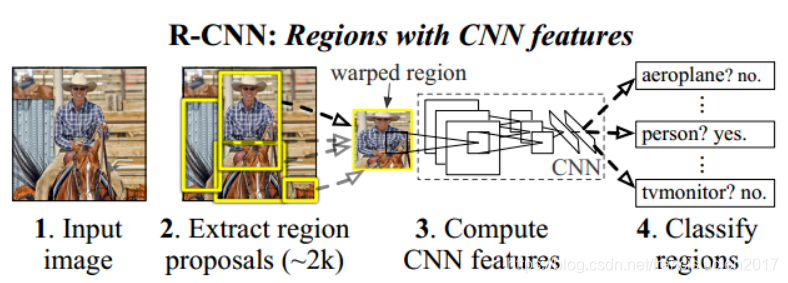
方法解析:
- selective search: 通过分割将图像分成小区域,输入10million的Region Proposal集合,计算每种6×6特征(AlexNet CNN网络中 pool5 层 的 size 是 6 x 6 x 256)的激活量,之后进行非极大值抑制,最后展示出每种特征前几个得分最高的Region Proposal,再通过颜色直方图、梯度直方图(纹理)相近、合并后总面积减小等合并规则进行合并,最后生成约2K个region proposals;
- 将region proposal 缩放至 227 x 227:原文中采用Alexnet CNN提取特征,为了适应Alexnet的输入图像大小而做了缩放;
- 缩放的变形方式:1. 用建议框周围像素扩充 2. 用建议框均值像素填充 3. zero padding(较好) 4. 直接缩放(resize)
- IoU:
- NMS (Non-Maximum Suppression) 非极大值抑制:
- 对2000 x 20 维矩阵每列按从大到小顺序排序;
- 从每列最大region proposal开始与后面的建议框计算IoU,若 IoU > 阈值,则剔除得分小的建议框;
- 遍历完整个矩阵所有列(即所有类别)
- Bounding-Box 回归器:窗口
,
表示窗口中心点坐标,
表示窗口宽和高;
- SVM训练:SVM是二分类器,所以对每个类别训练单独的SVM,由于负样本太多,采用hard negative mining的方法在负样本中选取有代表性的负样本;
- hard negative mining:比较容易被判定是负样本(比如全是背景)的对于训练并不能起到很好的监督作用。需要找一些难划分的负样本(hard negative),来增强网络的判别性能。在训练好分类器进行会分类得到错误的正样本,这些判别错误的样本可以作为负样本继续训练网络。
- 有监督预训练(迁移学习):使用功能相似的训练好的网络权重的前几层初始化参数,在其后添加所需的若干层网络,并对其随机初始化,再利用训练集训练整个网络;好处就是加快训练和网络收敛速度,解决了小样本数据训练深层网络易过拟合的问题;
- 微调region proposal 和 训练SVM是正负样本阈值不同(0.3 和 0.5):微调阶段是由于CNN对小样本容易过拟合,需要大量训练数据,故对IoU限制宽松;SVM适用于小样本训练,故对样本IoU限制严格;
- 不直接用微调后的Alexnet最后一层softmax进行分类:微调时和训练SVM时所采用的正负样本阈值不同,微调阶段正样本定义并不强调精准的位置,而SVM正样本只有Ground Truth;
RCNN存在的问题:
- 传统的CNN输入的map是固定尺寸的,而归一化过程中对图片产生的形变会导致图片大小改变,不利于CNN的特征提取;
- 需要事先提取多个候选区域对应的图像,占用空间大;
- 每个region proposal都需要进入CNN网络计算,导致过多次的重复的相同的特征提取,导致计算速度、训练和预测速度都很慢;
Fast RCNN
(参考:ref3)
Fast-RCNN 提升点(相对RCNN):
- 训练速度提升9倍;
- 测试速度提升200多倍;
- 无需SVM分类器分类;
创新之处:
- 全连接后使用softmax替代了RCNN中的SVM进行分类;
- 引入多任务函数边框回归(bbox regressor ),除Selective Search region proposal 阶段外实现了端到端训练;
- 引入ROI Pooling层(含有一层SPP),对图像输入没有尺寸限制;
训练流程:
-
selective search 在原图中获取2K左右region proposals;
-
CNN提取图片特征得到最后一层的feature map;
-
在得到的feature map之上对每个ROI求映射关系(同SPP-NET),并用一个ROI Pooling 层来将其统一到相同的大小(替代最后一个Pooling层,实际就是单层的SPP-NET,实现时将ROI对应的feature map区域下采样到7 x 7);
-
经过两个全连接层得到特征向量,分别输入至 softmax 和 bounding box 回归;利用 softmax loss 和 smooth L1 loss 联合训练;
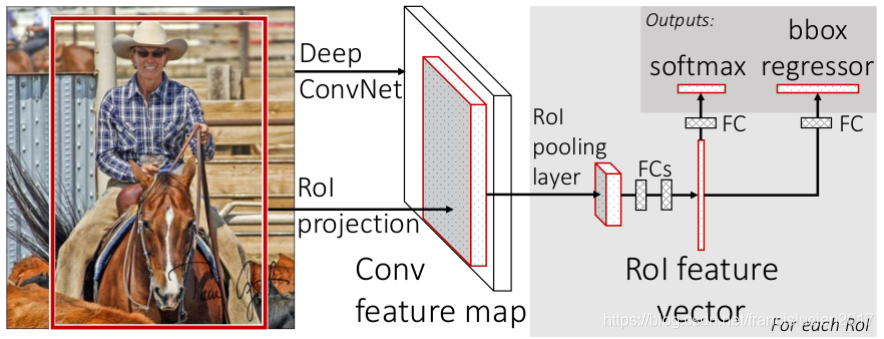
方法解析:
- 预训练:用了3种预训练的ImageNet网络(VGG16等)初始化Fast RCNN,最后一个max pooling层替换为 ROI pooling 层,设置为与第一个全连接层兼容;最后一个全连接层和softmax(原本为1000类)替换为 K + 1(类别+背景)类的分类层和 bounding box 回归层;
- 微调:采用 image-centric sampling,每个 mini-batch 由N张图片(N=2)的R个proposal组成(R=28),同一图像的ROI共享计算和内存,可以同时微调卷积层和全连接层(实验证明太浅的卷积层没有必要微调,可减少训练时间);
- 计算全连接层:在分类中比计算卷积层快,而在检测中由于一个图中要提取2000个ROI,所以大量时间都用在计算全连接层了,采用Truncated SVD奇异值分解(去掉最末尾的几个singular value来近似原矩阵)的方法来减少计算全连接层的时间
- ROI Pooling:
- ROI(region of interest)指的是SS后的候选框在卷积后得到的特征图上的映射;
- ROI Pooling层将每个候选区域划分为大小相同的sections(数量和输出维度相同),对每一个section执行max pooling,使得特征映射上不同大小的候选区域变为均匀大小的特征图(feature map),然后将其送入下一层;
- 论文中对于每一个RoI,RoI Pooling Layer将其对应的特征从共享卷积层上拿出来,并转化成一样的大小(6×6)
- 作用:
- 该层有效提高了training和testing的处理速度和准确度;
- 可以从不同大小的候选框对应的特征映射上,为每个ROI区域提取固定大小的feature map;
- 允许end-to-end的形式训练目标检测系统;
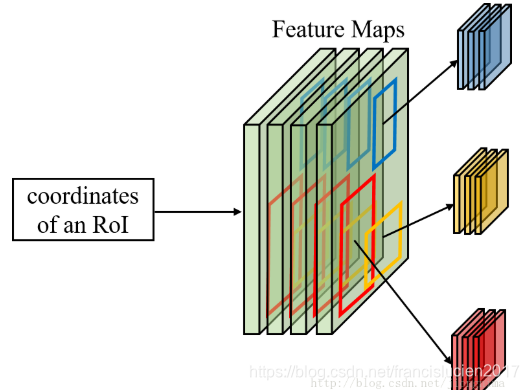
- bounding box 回归:先平移,再尺度缩放;当输入的proposal与ground truth相差较小时(原文为 IoU>0.6),可以认为这种变换是一种线性变换,就可以用线性回归来对窗口微调;
- Image-centric 采样: mini-batch 分层采样,先对图像采样,再对ROI采样,将采样的ROI限定在个别图像内,这样使得同一图像的ROI共享计算和内存,实现了端到端的反向传播,可以fine-tuning整个网络;
- 多尺度图像训练Fast R-CNN只提升微小的mAP,但是时间成本却增加了很多不推荐;过多region proposal不能提升性能
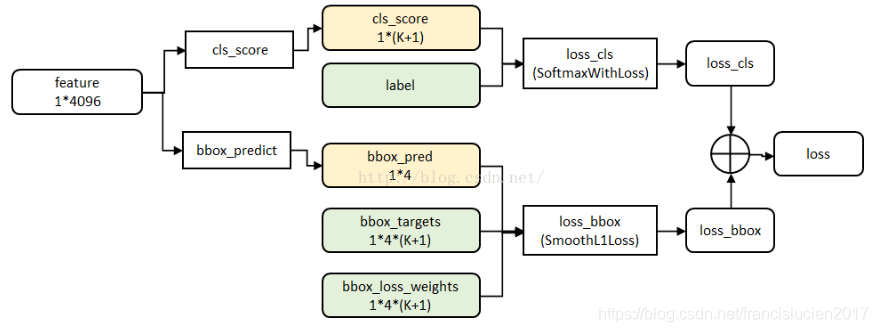
- Fast RCNN 的损失函数(ref)-- 多任务损失:
- Fast RCNN 网络有两个同级输出层(cls score 和 bbox predict),都是全连接层,称为 multi-task;
- cls_score 层:用于分类,输出为 k+1 维数组 p (k 个类别 和背景),对每个 ROI 输出离散型概率分布:
,p 由 k+1 类的全连接层利用softmax计算得出;
- bbox_predict 层:用于调整候选区域位置,输出 bounding box 回归的位移,输出 4*k 维数组 t 表示应该平移缩放的量:
,其中
是相对于proposal的尺度不变的平移;
- loss_cls 分类损失函数,由真实分类 u 对应的概率决定:
- loss_reg 检测框定位的损失函数,比较真实分类对应的预测平移缩放参数
和真实平移缩放参数
的差别:
- smooth L1 损失函数:
- 这样设置的目的是想让loss对于离群点更加鲁棒,相比于L2损失函数,其对离群点、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。
- 这样设置的目的是想让loss对于离群点更加鲁棒,相比于L2损失函数,其对离群点、异常值(outlier)不敏感,可控制梯度的量级使训练时不容易跑飞。
- 最后总损失为两者加权和(如果分类为背景则不考虑定位损失):
-
规定u=0为背景类(也就是负标签),那么艾弗森括号指数函数[u≥1]表示背景候选区域即负样本不参与回归损失,不需要对候选区域进行回归操作。λ控制分类损失和回归损失的平衡。Fast R-CNN论文中,所有实验λ=1。
-
源码中bbox_loss_weights用于标记每一个bbox是否属于某一个类;
- cls_score 层:用于分类,输出为 k+1 维数组 p (k 个类别 和背景),对每个 ROI 输出离散型概率分布:
- Fast RCNN 网络有两个同级输出层(cls score 和 bbox predict),都是全连接层,称为 multi-task;
Fast RCNN 的不足之处:
- selective search十分耗时,无法满足实时应用需求,并且没有实现真正意义上的端到端训练模式;
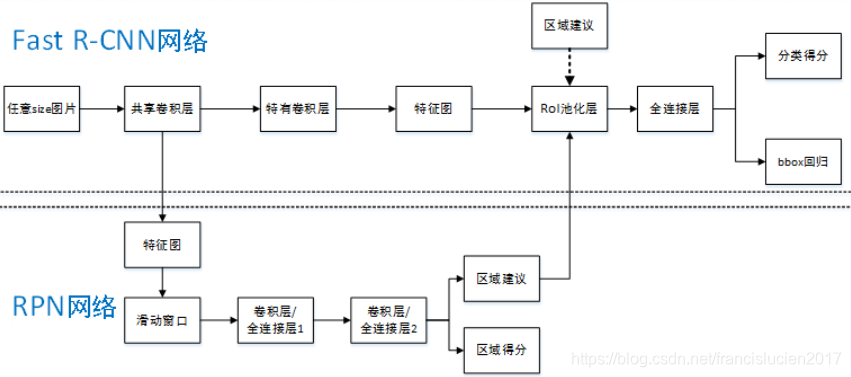
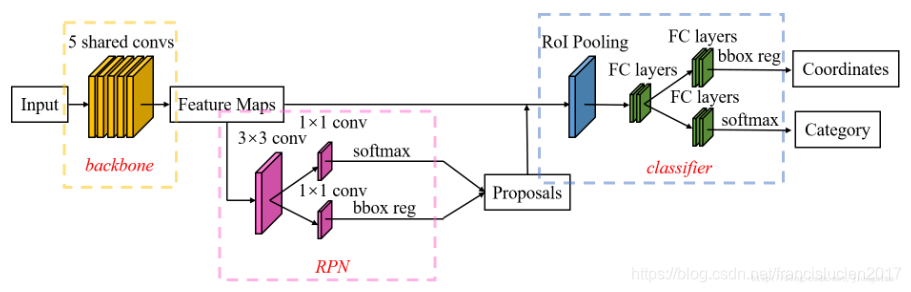
Faster RCNN
特点:
-
目标检测的四个步骤:候选区域生成 + 特征提取 + 分类器分类 + 回归器回归 全部由神经网络完成,并且可以全部在GPU上运行,实现了端到端(end-to-end)操作,大大提高了训练和检测效率;
-
由两个模块组成的----RPN候选框提取模块+Fast RCNN检测模块,两个模块共享特征;
训练流程:
- 输入图像经过CNN特征提取,通过RPN生成约300个 region proposals 送入ROI Pooling 层;
- Fast RCNN模块通过共享上述卷积层,特征提取后获得feature maps;
- softmax分类器分类;
- bounding box 回归器回归,进行位置调整;
方法解析:
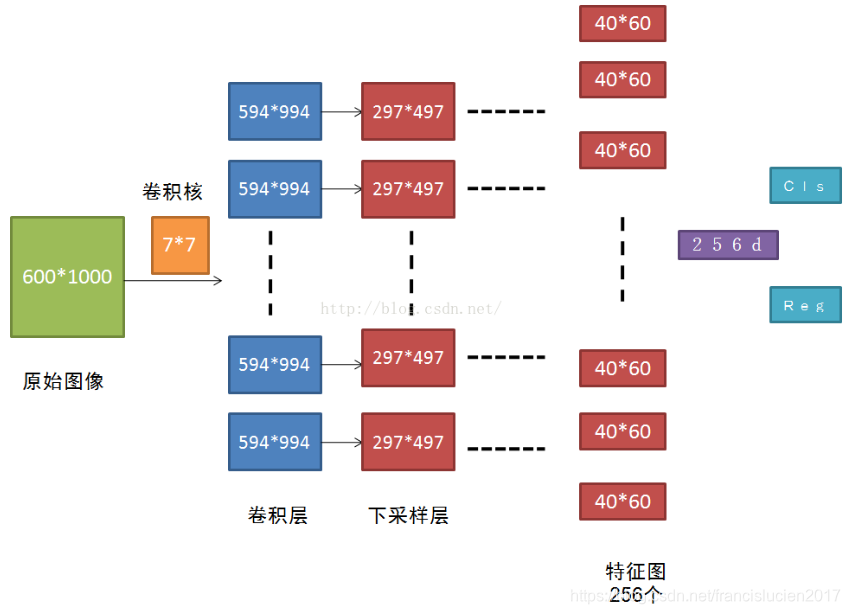
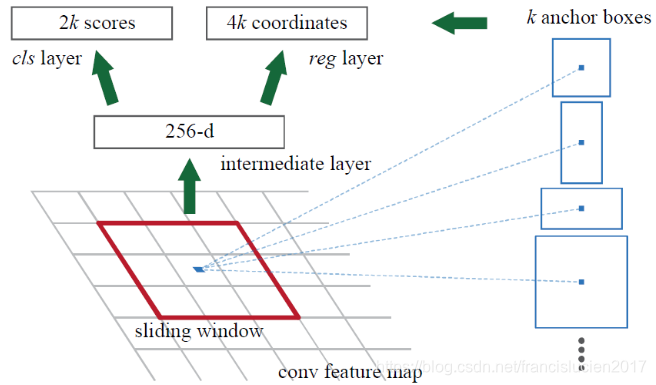
- RPN (Region Proposal Network) 是一个全卷积网络(即将CNN最后的全连接层换为全卷积层),在最后一层卷积的feature map上生成约 300 个 region proposals;
- RPN 操作流程(参考:ref):
- 使用小型网络在最后卷积得到的 feature map 上执行滑动扫描,这个网络每次与特征图上的 n x n (论文中 n=3)的窗口全连接(图像的有效感受野很大,ZF是171像素,VGG是228像素),每个滑动位置通过卷积层映射到一个低维向量(256d for ZF / 512d for VGG)
- 为每个滑窗位置考虑 k = 9 (3种尺度,3种比例) 中可能的参考窗口(anchor,在原图上,不在特征图上)。对于
的特征图,就会产生
个anchors。
- 低维特征向量输入到两个并行的全连接层(bbox回归层( reg)和 box分类层( cls))
- reg层:预测anchor对应的proposal的(x,y,w,h);
- cls层:判断该proposal是前景(object)还是背景(non-object),并为其打分(输出每一个位置上,9个anchor属于前景和背景的概率);
- 训练RPN:通过BP和SGD进行端到端训练
- 采样:同 Fast RCNN 一样采用 image-centric 采样策略,每一个mini-batch 包含从一张图像中随机提取的256个anchor (不是所有的anchor都用来训练),前景和背景样本各取128个,正负比 1 : 1,若图像中正样本少于128个,则多取一些负样本以满足256个proposal用于训练;
- 初始化:新增的两层用均值为0,标准差为0.01的高斯分布初始化,其余层(共享的卷积层)参数用ImageNet分类预训练模型来初始化;
- RPN 操作流程(参考:ref):
- Faster RCNN 的损失函数(ref):
- Faster RCNN 的loss分为训练RPN的loss和训练Fast RCNN的loss(都各自包含一个softmax loss和一个smooth L1 loss)
其中参数定义如下:
为 anchor 预测为目标的概率;
为 ground truth 标签,
,
是positive anchor对应的ground truth 的坐标向量;
是两个类别(目标和非目标)的对数损失:
是回归损失:
,其中 R 是smooth L1函数;
意味着只有前景 anchor (
)才有回归损失;
- cls 层 和 reg 层的输出分别由 {
} 和 {
} 组成,分别由
(cls项的归一化值,为mini-batch 大小,默认为256)和
(reg 项的归一化值为 anchor 位置的数量,即 2400 (40*60))以及一个平衡权重
归一化;
Faster RCNN 分类器和RoI边框修正流程:
- 通过RPN生成约20000个(40*60*9)anchor;
- 对20000个anchor进行第一次边框修正,得到修正后的proposal;
- 对超过图像边界的proposal的边进行clip,使得该proposal不超过图像范围;
- 忽略长或者宽太小的proposal;
- 将所有proposal按照前景分数从高到低排序,选取前12000个proposal;
- 使用0.7的阈值做NMS,排除掉重叠的proposal;
- 对上一步剩下的proposal,选取前2000个进行分类和第二次边框修正;
Faster RCNN 训练流程:
- 使用在ImageNet上预训练的模型初始化共享卷积层并训练RPN;
- 使用RPN参数生成 RoI proposals,再使用ImageNet上预训练的模型初始化共享卷积层,训练分类器和RoI边框修订(同Fast RCNN部分);
- 将训练后的共享卷积层参数固定,同时将Fast RCNN的参数固定,训练RPN;
- 将共享卷积层和RPN参数都固定,训练Fast RCNN部分;
Faster RCNN 测试流程:
- 通过RPN生成约20000个(40*60*9)anchor;
- 对20000个anchor进行第一次边框修正,得到修正后的proposal;
- 对超过图像边界的proposal的边进行clip,使得该proposal不超过图像范围;
- 忽略长或者宽太小的proposal;
- 将所有proposal按照前景分数从高到低排序,选取前6000个proposal;
- 使用0.7的阈值做NMS,排除掉重叠的proposal;
- 对上一步剩下的proposal,选取前300个进行分类和第二次边框修正;
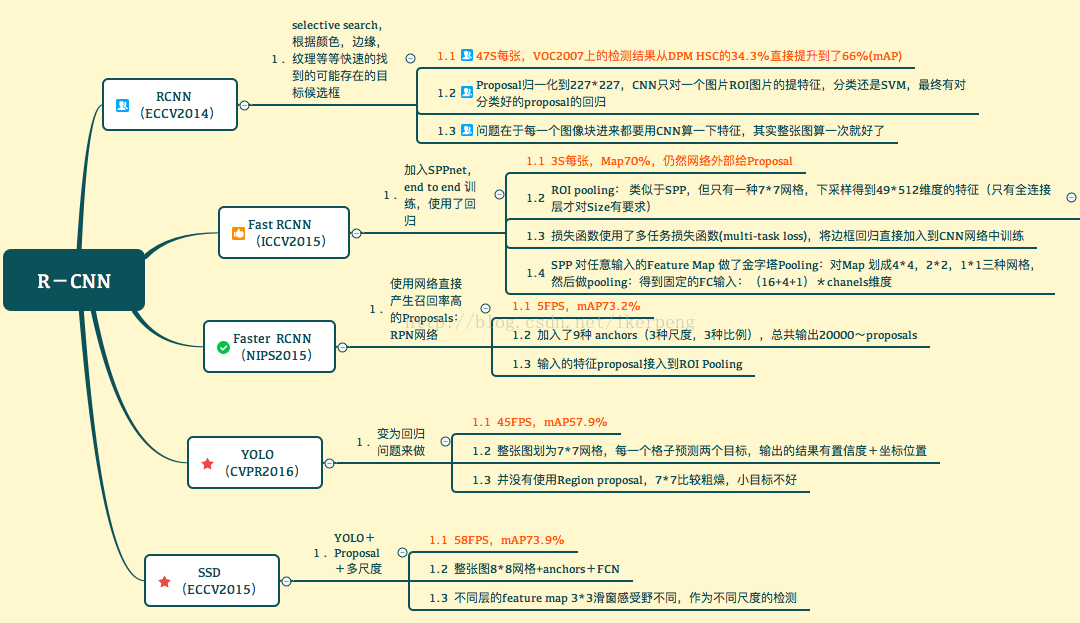
总结:三者对比
参考(ref)
| 流程 | 缺点 | 改进 | |
| RCNN |
|
|
|
| Fast RCNN |
|
|
|
| Faster RCNN |
|
|
|
下图来自:ref2
智能推荐
使用docker打包python项目并在本地模拟部署aws lambda-程序员宅基地
文章浏览阅读1.9k次,点赞2次,收藏7次。本文主要记录使用docker打包python项目并部署到lambda的流程以及遇到的一些问题。_docker打包python项目
Linux离线安装 elasticdump工具_npm-cache.tar-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏9次。elasticdump是一个对elasticsearch进行数据导入导出的工具安装包:https://download.csdn.net/download/fanzhijian110/11261855https://download.csdn.net/download/fanzhijian110/11261850node-v10.16.0-linux-x64.tar.xz 这个包..._npm-cache.tar
新洞察 - 智能产品行业出海趋势分享-程序员宅基地
文章浏览阅读621次,点赞29次,收藏20次。在智能产品行业出海的浪潮中,中国企业正扮演着重要角色。这个快速增长的行业正在经历着多样化产品形态、人工智能技术融合、生态化趋势以及隐私安全重视等发展趋势。中国智能产品出口规模持续扩大,不仅在传统市场表现强劲,新兴市场也呈现出令人鼓舞的增长势头。随着国际渗透率的提高,中国智能产品正逐步获得全球消费者的认可。为了在国际市场上取得成功,企业需要加快本地化布局,融入当地市场,提供优质的组织、营销和售后服务。在这个充满机遇的时代,把握住智能产品行业出海的红利,将为中国企业开启新的增长空间。
centos8安装mysql报错:The GPG keys listed for the “MySQL 8.0 Community Server“ repository are already ins_the gpg keys listed for the "mysql 8.0 community s-程序员宅基地
文章浏览阅读3.6k次。目录 centos8安装mysql报错:The GPG keys listed for the "MySQL 8.0 Community Server" repository are already installed but they are not correct for this package. 安装sql命令如下:原因分析:解决办法:1.可以先尝试这个:2.然后再执行: 3.不行的话,可以用这个:注意事项:报错信息、报错截图示下: 如上述命令,要安装MySQL数_the gpg keys listed for the "mysql 8.0 community server" repository are alre
js当前系统时间转换成日期格式转换成YYYYMMDD格式_js日期格式转换yyyymmdd-程序员宅基地
文章浏览阅读1.1k次。修改系统时间为指定格式_js日期格式转换yyyymmdd
window下MySQL8.0数据库cmd导出文件和备份_windows本地mysql8.0如何导出数据库-程序员宅基地
文章浏览阅读551次。数据库cmd导出文件和备份1.首先需要进入到mysql安装目录下的bin目录,执行cmd进入命令窗口。cd C:\Users\sus\Desktop\mysql2.导出(导出某个数据库,也可以针对某张表导出)2.1 导出数据结构以及数据的命令1.mysqldump -u root -p 数据库名称 > 想要导出的目录mysqldump -u root -p pharmacy > C:\Users\sus\Desktop\mysql\work.sql2.mysqldump -ur_windows本地mysql8.0如何导出数据库
随便推点
VUE3面试题及知识点,并且带答案!_vue3面试题必问题和答案-程序员宅基地
文章浏览阅读4.2k次,点赞5次,收藏27次。答:Vue 3.0是Vue.js框架的最新版本。Composition API:提供更灵活的逻辑组织方式,使组件更易于复用和测试。更好的性能:Vue 3.0使用了重写的响应式系统,使得渲染速度更快、内存占用更小。改进的TypeScript支持:Vue 3.0在TypeScript方面做出了改进,允许开发者更好地利用TypeScript的类型检查功能。答:在Vue 3.0中,可以使用directive方法注册自定义指令。具体来说,可以将一个包含mountedupdated和unmounted。_vue3面试题必问题和答案
Ubuntu 12.04 LTS 中文输入法的安装_ubuntu12.04如何安装中文输入法-程序员宅基地
文章浏览阅读1.9k次。转自:http://blog.csdn.net/muyang_ren/article/details/39211201本文是笔者使用 Ubuntu 操作系统写的第一篇文章!参考了红黑联盟的这篇文章:Ubuntu 12.04中文输入法的安装安装 Ubuntu 12.04 着实费力一番功夫,老是在用 Ubuntu 来引导 Windows,结果 Ubuntu 倒是能用,一进入 W_ubuntu12.04如何安装中文输入法
计算机组成原理-程序员宅基地
文章浏览阅读33次。经常使用的程序会从主存想cache复制写入一份,能够更快的更频繁的使用。辅存的速度越快,辅存读入主存的速度也就会越快,开机的速度也就越快。
数据挖掘与数据分析-程序员宅基地
文章浏览阅读1k次,点赞10次,收藏18次。1、数据挖掘(Data Mining)数据挖掘是指对大规模数据进行分析,以发现其中潜在的模式、规律或关联性的过程。其目的在于从数据中提取有价值的信息,以支持决策制定、预测未来趋势等。数据挖掘涉及多种技术和方法,包括机器学习、统计分析、数据库技术等。2、数据分析(Data Analysis)数据分析是指对数据进行收集、清洗、转换和建模等处理,以获得对问题的洞察和理解的过程。数据分析旨在揭示数据背后的意义,为决策提供支持和指导。它可以采用多种统计和计算方法,如描述性统计、推断统计、预测分析等。
停车场管理系统-计算机毕业设计源码75913-程序员宅基地
文章浏览阅读140次。该模块是为所有用户登录设计的,如注册用户这种普通用户登录后只能进行自己的普通功能操作(如个人信息修改),管理员和超级管理员登录后有不同的权限,管理员不能超越权限。超级管理员能对整个系统的数据进行管理,主要是用户的登录权限以及用户登录后在系统里的操作权限。停车位预约模块普通用户和停车位存在预约关系,关系为一对多,根据停车位编号来将停车位数据传入到预约数据中,操作人为普通用户,然后生成预约列表,普通用户查看个人历史预约列表,可以进行数据销毁。
[Vue五]:vue和echarts结合,echarts图表自适应问题_vue echarts-程序员宅基地
文章浏览阅读1.8w次,点赞21次,收藏87次。[Vue五]:vue和echarts结合,echarts图表自适应问题_vue echarts