编译原理龙书第二版第六章习题题解(部分)_编译原理抽象语法树例题-程序员宅基地
6.1节
该节知识点,就是两个,DAG和值编码,掌握这两个就行了
DAG(Directed Acyclic Graph,有向无环图),指出了表达式中的公共子表达式。
值编码,存放DAG中结点的记录数组。数组的每一行表示一个记录,也就是一个结点。
6.1.1
为下面的表达式构造DAG
((x+y)-((x+y)*(x-y)))+((x+y)*(x-y))
解:

6.1.2
为下列表达式构造DAG,且指出它们的每个子表达式的值编码。假定+是左结合的。
1)a+b+(a+b)
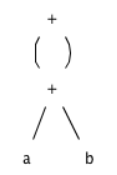
值编码
| 1 | id | a | |
| 2 | id | b | |
| 3 | + | 1 | 2 |
| 4 | + | 3 | 3 |
2)a+b+a+b

| 1 | id | a | |
| 2 | id | b | |
| 3 | + | 1 | 2 |
| 4 | + | 3 | 1 |
| 5 | + | 4 | 2 |
3)a+a+(a+a+a+(a+a+a+a))
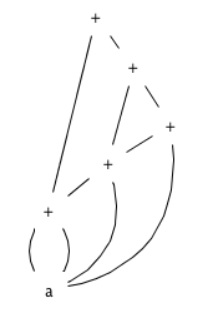
| 1 | id | a | |
| 2 | + | 1 | 1 |
| 3 | + | 2 | 1 |
| 4 | + | 3 | 1 |
| 5 | + | 3 | 4 |
| 6 | + | 2 | 5 |
6.2节
这一节需要理解4个点,即抽象语法树、四元式序列、三元式序列、间接三元师序列。
抽象语法树:略
四元式序列:有四个字段,op、arg1、arg2、result,例如x=y+z,其中op字段放入+,arg1为y,arg2为z,result为x。
但是需要注意一些特例:
①x = minus y的单目运算符指令和赋值指令x=y是不使用arg2。且对于x=y的情况,op是=
②像param这样的运算既不使用arg2,也不使用result(下面有例题会涉及到)
③条件或非条件转移指令将目标标号放入result字段。
三元式序列:只有三个字段,op,arg1,arg2。其中四元式的result主要用于临时变量名。而三元式中用运算的位置来表示结果。
间接三元式序列:相对与三元式,包含了一个指向三元式的指针的列表。
6.2.1
将算术表达式a+-(b+c)翻译成
1)抽象语法树

2)四元式序列
| op | arg1 | arg2 | result | |
| 0 | + | b | c | t1 |
| 1 | minus | t1 | t2 | |
| 2 | + | a | t2 | t3 |
3)三元式序列
| op | arg1 | arg2 | |
| 0 | + | b | c |
| 1 | minus | (0) | |
| 2 | + | a | (1) |
4)间接三元式序列
| instruction | |
| 0 | (0) |
| 1 | (1) |
| 2 | (2) |
| op | arg1 | arg2 | |
| 0 | + | b | c |
| 1 | minus | (0) | |
| 2 | + | a | (1) |
6.2.2
对下列赋值语句重复练习6.2.1
1)a=b[i]+c[j]
四元式
| op | arg1 | arg2 | result | |
| 0 | =[] | b | i | t1 |
| 1 | =[] | c | j |
t2 |
| 2 | + | t1 | t2 | t3 |
| 3 | = | t3 | a |
三元式
| op | arg1 | arg2 | |
| 0 | =[] | b | i |
| 1 | =[] | c | j |
| 2 | + | (0) | (1) |
| 3 | = | a | (2) |
间接三元式
| instruction | |
| 0 | (0) |
| 1 | (1) |
| 2 | (2) |
| 3 | (3) |
| op | arg1 | arg2 | |
| 0 | =[] | b | i |
| 1 | =[] | c | j |
| 2 | + | (0) | (1) |
| 3 | = | a | (2) |
2)a[i]=b*c-b*d
四元式
| op | arg1 | arg2 | result | |
| 0 | * | b | c | t1 |
| 1 | * | b | d | t2 |
| 2 | - | t1 | t2 | t3 |
| 3 | []= | a | i | t4 |
| 4 | = | t3 | t4 |
三元式
| op | arg1 | arg2 | |
| 0 | * | b | c |
| 1 | * | b | d |
| 2 | - | (0) | (1) |
| 3 | []= | a | i |
| 4 | = | (3) | (2) |
间接三元式
| instruction | |
| 0 | (0) |
| 1 | (1) |
| 2 | (2) |
| 3 | (3) |
| 4 | (4) |
| op | arg1 | arg2 | |
| 0 | * | b | c |
| 1 | * | b | d |
| 2 | - | (0) | (1) |
| 3 | []= | a | i |
| 4 | = | (3) | (2) |
3)x=f(y+1)+2
四元式
| op | arg1 | arg2 | result | |
| 0 | + | y | 1 | t1 |
| 1 | param | t1 | ||
| 2 | call | f | 1 | t2 |
| 3 | + | t2 | 2 | t3 |
| 4 | = | t3 | x |
三元式
| op | arg1 | arg2 | |
| 0 | + | y | 1 |
| 1 | param | (0) | |
| 2 | call | f | 1 |
| 3 | + | (2) | 2 |
| 4 | = | x | (3) |
间接三元式
| instruction | |
| 0 | (0) |
| 1 | (1) |
| 2 | (2) |
| 3 | (3) |
| 4 | (4) |
| op | arg1 | arg2 | |
| 0 | + | y | 1 |
| 1 | param | (0) | |
| 2 | call | f | 1 |
| 3 | + | (2) | 2 |
| 4 | = | x | (3) |
6.3节
6.3.1
确定下列声明序列中各个标识符的类型和相对地址。
float x;
record {float x; float y;} p;
record {int tag; float x; float y;} q;
SDT
S -> {top = new Evn(); offset = 0;}
D
D -> T id; {top.put(id.lexeme, T.type, offset);
offset += T.width}
D1
D -> ε
T -> int {T.type = interget; T.width = 4;}
T -> float {T.type = float; T.width = 8;}
T -> record '{'
{Evn.push(top), top = new Evn();
Stack.push(offset), offset = 0;}
D '}' {T.type = record(top); T.width = offset;
top = Evn.top(); offset = Stack.pop();}
标识符类型和相对地址
| line | id | type | offset | Evn |
| 1) | x | float | 0 | 1 |
| 2) | x | float | 0 | 2 |
| 2) | y | float | 8 | 2 |
| 2) | p | record() | 8 | 1 |
| 3) | tag | int | 0 | 3 |
| 3) | x | float | 4 | 3 |
| 3) | y | float | 12 | 3 |
| 3) | q | record() | 24 | 1 |
6.4节
6.4.1
向图 6-19 的翻译方案中加入对应于下列产生式的规则:
1)E -> E1 * E2
2)E -> +E1
| 产生式 | 语义规则 |
| E -> E1 * E2 | E.addr = new Temp() E.code = E1.code || E2.code || |
| E->+E1 | E.addr = E1.addr E.code = E1.code |
6.4.2
使用图 6-20 的增量式翻译方案重复练习 6.4.1
| 产生式 | 语义规则 |
| E -> E1 * E2 | {E.addr = new Temp(); gen(E.addr '=' E1.addr '*' E2.addr);} |
| E->+E1 | {E.addr = E1.addr;} |
6.4.3
使用图 6-22 的翻译方案来翻译下列赋值语句:
1)x = a[i] + b[j]
三地址代码
t_1 = i * awidth
t_2 = a[t_1]
t_3 = j * bwidth
t_4 = b[t_3]
t_5 = t_2 + t_4
x = t_5
注释语法分析树

2)x = a[i][j]+ b[i][j]
三地址代码
t_1 = i * ai_width
t_2 = j * aj_width
t_3 = t_1 + t_2
t_4 = a[t_3]
t_5 = i * bi_width
t_6 = j * bj_width
t_7 = t_5 + t_6
t_8 = b[t_7]
t_9 = t_4 + t_8
x = t_9
注释语法分析树

6.4.4
修改图 6-22 的翻译方案,使之适合 Fortran 风格的数据引用,也就是说 n 维数组的引用为 id[E1, E2, …, En]
需修改L产生式
若a表示一个i*j的数组,单元数宽度为k,
则
a.type = array(i, array(j, k))
a.type.length = i
a.type.elem = array(j, k)
| L->id[A] | { L.addr = A.addr; //数组名字就是id的值 |
| A->E | { A.array = global.array; //简单理解就是数组名仍然是全局的那个,新的地址等于E乘类型长度(这个类型长度其实是改为后面一位的类型长度) |
| A->A1,E | { A.array = A1.array; //简单理解就是A的地址是A1+E*数组A的第一个元素的值。关于array,就类似于数组名称还是继承 |
6.4.5
将公式 6.7 推广到多维数据上,并指出哪些值可以被存放到符号表中并用来计算偏移量。考虑下列情况:
1)一个二维数组 A,按行存放。第一维的下标从 l1 到 h1,第二维的下标从 l2 到 h2。单个数组元素的宽度为 w。
2)其他条件和 1 相同,但是采用按列存放方式。
3)一个 k 维数组 A,按行存放,元素宽度为 w,第 j 维的下标从 lj 到 hj。
4)其他条件和 3 相同,但是采用按列存放方式。
其实3)和4)就是1)和2)的一般情况。
所以这里直接写3)和4)
3)设ni为第i维数组的元素个数,其值为hi-li+1。
A[i1]]…[ik] = base +( (i1 - l1) * n_2 * … * n_k +… + (i_k-1 - l_k-1) * n_k +(ik - lk)) * w//这里由于k-1是下标,为了好区分,加上_。
4)A[i1]]…[ik] = base+((i1 - l1) +(i2 - l2) * n1 + … +(ik - lk) * n_k-1 * n_k-2 * … * n1 ) * w
6.4.6
一个按行存放的整数数组 A[i, j] 的下标 i 的范围为 1~10,下标 j 的范围为 1~20。每个整数占 4 个字节。假设数组 A 从 0 字节开始存放,请给出下列元素的位置:
1)A[4, 5]
2)A[10,8]
3)A[3, 17]
计算通用公式((i-1)*20+(j-1))*4,那么1)2)3)带进去即可,就不多说了。
6.4.7
假定 A 是按列存放的,重复练习 6.4.6
计算通用公式((i-1)+(j-1)*10)*4,带进去即可
6.4.8
一个按行存放的实数型数组 A[i, j, k] 的下标 i 的范围为 1~4,下标 j 的范围为 0~4,且下标 k 的范围为 5~10。每个实数占 8 个字节。假设数组 A 从 0 字节开始存放,计算下列元素的位置:
1)A[3, 4, 5]
2)A[1, 2, 7]
3)A[4, 3, 9]
计算通用公式((i-1)*5*6+j*6+(k-5))*8
6.4.9
假定 A 是按列存放的,重复练习 6.4.8
计算通用公式((i-1)+j*4+(k-5)*5*4)*8
6.5节
6.5.1
假定图6-26中的函数widen可以处理图6.25a的层次结构中的所有类型,翻译下列表达式。假定c和d是字符型,s和t是短整型,i和j为整数,x是浮点数。
1)x=s+c
t1 = (int) s
t2 = (int) c
t3 = t1 + t2
x = (float) t3
2)i=s+c
t1 = (int) s
t2 = (int) c
t3 = t1 + t2
3)x=(s+c)*(t+d)
t1 = (int) s
t2 = (int) c
t3 = t1 + t2
t4 = (int) t
t5 = (int) d
t6 = t4 + t5
t7 = t3 * t6
x = (float) t7
6.6节
6.6.1
在图6-36的语法制导定义中添加处理下列控制流构造的规则:
1)一个 repeat 语句:repeat S while B
2)一个 for 循环语句:for (S1; B; S2) S3
| 产生式 | 语义规则 |
| S -> repeat S1 while B | S1.next=newlabel() B.true=newlabel() B.false=S.next S.code=label(B.true)||S1.code ||label(S1.next)||B.code |
| S -> for (S1; B; S2) S3 | S1.next=newlabel() B.true=newlabel() B.false=S.next S2.next=S1.next//S1在for循环里其实只执行一次,S2是循环里最后执行的部分 S3.next=newlabel() S.code=S1.code||lable(S1.next) ||B.code||lable(B.true) ||S3.code||label(S3.next) ||S2.code||gen('goto', S1.next) |
6.6.2
现代计算机试图在同一个时刻执行多条指令,其中包括各种分支指令。因此,当计算机投机性地预先执行某个分支,但实际控制流却进入另一个分支时,付出的代价是很大的。因此我们希望尽可能地减少分支数量。请注意,在图 6-35c 中 while 循环语句的实现中,每个迭代有两个分支:一个是从条件 B 进入到循环体中,另一个分支跳转回 B 的代码。基于尽量减少分支的考虑,我们通常更倾向于将 while(B) S 当作 if(B) {repeat S until !(B)} 来实现。给出这种翻译方法的代码布局,并修改图 6-36 中 while 循环语句的规则。
| 产生式 | 语义规则 |
| S->if(B) {repeat S1 until !(B)} | B.true = newlabel() B.false = S.next S1.next=newlabel() S.code=B.code||label(B.true) ||S1.code||label(S1.next) ||B.code |
6.6.3
假设 C 中存在一个异或运算。按照图 6-37 的风格写出这个运算符的代码生成规则。
B1^B2可以等价于!B1 && B2 || B1 && !B2
| 产生式 | 语义规则 |
| B->B1^B2 | B1.true = newlabel() B1.false = newlabel()
B2.true = B.true B2.false = B1.true
b3 = newboolean()
b4 = newboolean() b4.true = B.false
S.code = B1.code |
6.6.4
使用 6.6.5 节中介绍的避免 goto 语句的翻译方案,翻译下列表达式:
1)if (a==b && c==d || e==f) x == 1
ifFalse a==b goto L3
if c==d goto L2
L3: ifFalse e==f goto L1
L2: x == 1
L1:
2)if (a==b || c==d || e==f) x == 1
if a==b goto L2
if c==d goto L2
ifFalse e==f goto L1
L2: x==1
L1:
3)if (a==b || c==d && e==f) x == 1
if a==b goto L2
ifFlase c==d goto L1
ifFlase e==f goto L1
L2:x==1
L1:
总结一下,一般在多个条件的最后一个或者与条件的第一个需要进行此操作
6.6.6
使用类似于图 6-39 和图 6-40 中的规则,修改图 6-36 和图 6-37 的语义规则,使之允许控制流穿越。
| 产生式 | 语义规则 |
| S->if(B)S1 | B.true=fall B.false=S1.next=S.next S.code=B.code||S1.code |
| S -> if(B) S1 else S2 | B.true=fall B.false=newlabel() S1.next=S2.next=S.next S.code=B.code||S1.code ||gen('goto' S1.next)||label(B.false) ||S2.code |
| S -> while(B) S1 | begin = newlabel() B.true = fall B.false = S.next S1.next = begin S.code=label(begin)||B.code ||S1.code||gen('goto' begin) |
| S->S1S2 | S1.next = fall S2.next = S.next S.code=S1.code||S2.code//以上这些就是把原来的所有的B.true都改为等于fall,去掉label(B.true)即可 |
| B->B1 || B2 | B1.true= if B.true != fall then B.true else newlabel()//虽然B1为真时B的值必然为真,但是B1.true必须保证控制流跳过B2的代码,而B.true为fall代表如果B为真时控制流穿越B。 B1.false=fall//B1为假,则B的真假由B2决定 B2.true=B.true B2.false=B.false B.code=if B.true != fall then B1.code || B2.code else B1.code || B2.code || label(B1.true) |
| B -> B1 && B2 | B1.true=fall B1.false=if B.false != fall then B.false else newlabel() B2.true=B.true B2.false = B.false B.code=if B.false!= fall then B1.code || B2.code else B1.code || B2.code || label(B1.false) |
6.7节
6.7.1
使用图 6-43 中的翻译方案翻译下列表达式。给出每个子表达式的 truelist 和 falselist。你可以假设第一条被生成的指令的地址是 100.
1)a==b && (c == d || e==f)

2)(a==b || c==d) || e==f

3)(a==b && c==d) && e==f

6.7.2


1)E3.false
E3.false=i1
2)S2.next
S2.next = i7
3)E4.false
E4.false = i7
4)S1.next
S1.next = i3
5)E2.true
E2.true = i3
ps:个人感觉这两题即使不学编译原理也能做,就像考验c语言基础语法一样,while的执行步骤与顺序,if的执行规则等等,当然最好是自己画个注释语法树分析一下。
6.7.3
当使用图 6-46 中的翻译方案对图 6-47 进行翻译时,我们为每条语句创建 S.next 列表。一开始是赋值语句 S1, S2, S3,然后逐步处理越来越大的 if 语句,if-else 语句,while 语句和语句块。在图 6-47 中有 5 个这种类型的结构语句:
S4: while (E3) S1
S5: if(E4) S2
S6: 包含 S5 和 S3 的语句块
S7: if(E2) S4 else S6
S8: 整个程序
对于这些结构语句,我们可以通过一个规则用其他的 Sj.next 列表以及程序中的表达式的列表 Ek.true 和 Ek.false 构造出 Si.next。给出计算下列 next 列表的规则:
1)S4.next
S4.next=E3.false=S3.next
2)S5.next
S5.next=E4.false=S2.next
3)S6.next
S6.next=S3.next=S4.next=E3.false
4)S7.next
S7.next=S3.next
5)S8.next
S8.next=E1.false
智能推荐
c# ( winform )/ javaswing 通信录管理系统源码_winform通讯录源码-程序员宅基地
文章浏览阅读48次。c#(winform)/javaswing 通信录管理系统源码此系统同时支持mysql,sqlserver,sqlite三种数据库,有javaswing窗体和C#窗体两套代码。_winform通讯录源码
sharding-datasource之JPA基于MultiTenant动态切换数据源_currenttenantidentifierresolver-程序员宅基地
文章浏览阅读1.1k次。介绍基于sharding-datasource, jpa进行分库操作, 基于AbstractDataSourceBasedMultiTenantConnectionProviderImpl, CurrentTenantIdentifierResolver动态切换数据源SaaS服务多租户介绍,每个租户的资源都是独立的,从入口到应用部署到数据,都是完全隔离的。每个租户相当于“托管”在提供服务的公司里面,公司做的其实是统一运维。好处在于,这个隔离非常彻底,基本不太会有相互影响;如果有特殊客户要求的定制化,_currenttenantidentifierresolver
Good Site-程序员宅基地
文章浏览阅读106次。[url=http://d.hatena.ne.jp/ntaku/searchdiary?word=%2A%5BAndroid%5D][Android]Androidの開発環境構築[/url][url]http://www.adakoda.com/android/000062.html[/url][url]http://www.cnmsdn.com/t/12/[/url][url]ht...
50w字+的Java技术类校招面试题汇总,HR的话扎心了_50w 面试-程序员宅基地
文章浏览阅读165次。前言刚刚过去的双十一,让“高性能”“高可用”“亿级”这3个词变成了技术热点词汇,也让很多人再次萌发成为「架构师」的想法。先问大家一个问题:你觉得把代码熟练、完成需求加上点勤奋,就能成为架构师么?如果你这么认为,那你注定只能是“码农”。从业这么多年,我见过太多普通程序员做到架构师的例子,但更多的人在听话地把需求做出来,既不考虑更优解,也不考虑技术原理,重复千篇一律的代码,以为只要代码写的好就能做「架构师」前段时间,还有哥们儿吐槽说,他们公司的架构师编程能力还不如他,伤感自己”怀才不遇“。但其实,架构师看的是_50w 面试
数据结构与算法之快速排序_数据结构快速排序-程序员宅基地
文章浏览阅读1.3w次,点赞12次,收藏25次。快速排序概念 代码实现 时间复杂度_数据结构快速排序
【路径规划】蚁群算法栅格地图路径规划及避障【含Matlab源码 2088期】_格栅地图蚁群算法-程序员宅基地
文章浏览阅读768次。蚁群算法栅格地图路径规划及避障完整的代码,方可运行;可提供运行操作视频!适合小白!_格栅地图蚁群算法
随便推点
巨杉数据库 CTO 王涛:新一代分布式数据库-程序员宅基地
文章浏览阅读944次。2019数据技术嘉年华于11月16日在京落下了帷幕。大会历时两天,来自全国各地上千名学术精英、数据库领袖人物、数据库专家、技术爱好者在这里汇聚一堂,围绕“开源 • 智能 ..._巨杉数据库 王涛
最全css居中:水平居中+垂直居中+水平/垂直居中总结_style 水平居中-程序员宅基地
文章浏览阅读285次。一.水平居中1. 行内元素<style> #father { width: 500px; height: 300px; background-color: skyblue; text-align: center; //看父级是否为块级元素,是则父级设置text-align:center //如果不是:父级先设置为块级元素,然后再居中 (即display:block ;text-alig_style 水平居中
【愚公系列】2024年02月 《网络安全应急管理与技术实践》 015-网络安全应急技术与实践(Web层-文件上传漏洞)-程序员宅基地
文章浏览阅读2.7w次,点赞8次,收藏9次。文件上传漏洞是指网站对于用户上传文件的验证过程不严格,导致攻击者可以上传恶意文件到服务器上执行任意代码或者获取敏感信息的安全漏洞。安全问题说明1. 代码执行攻击者可以上传包含恶意代码的可执行文件,通过执行这些代码来攻击服务器,例如获取敏感信息、操控服务器等。上传的可执行文件中包含恶意代码,攻击者可以通过执行该代码来实现攻击目的。2. 文件覆盖攻击者可以通过上传同名文件覆盖服务器上的原始文件,导致原始文件的内容被篡改或者删除。
从数据仓库到大数据,数据平台这25年是怎样进化的?[转]-程序员宅基地
文章浏览阅读76次。从数据仓库到大数据,数据平台这25年是怎样进化的?大数据平台 [email protected]年前 (2016-03-23)5778℃2评论从「数据仓库」一词到现在的「大数据」,中间经历了太多的知识、架构模式的演进与变革。数据平台这25年究竟是怎样进化的?让InfoQ特约老司机为你讲解。我是从2000年开始接触数据仓库,大约08年开始进入互联网行业。很多从传统企业数..._从数据仓库到大数据,数据平台这 25 年是怎样进化的
关于使用Java后台导入excel文件,读取数据后,更新数据库,并返回数据给到前端的相关问题总结_excel 导入时第一条导入后将第一条的数据返回-程序员宅基地
文章浏览阅读2.2k次。在之前的项目中,使用到了Java后台读取excel文件数据的功能点,本想着该功能点已经做过了,这一类的应该都大差不离,不过在刚结束的一个项目中,现实给我深深的上了一课,特此编写此片博客,以作记录,并给自己提个醒,Java真的是浩瀚如海呀,任何时候其实自己都是小白,懂得越多越发谨慎。Java后台读取excel文件数据该功能点一般与Java导出excel文件这个功能点配合使用。实际上此次的问题与之前的最大区别在于,之前导出excel文件时,明确知道导出的数据每一列的字段详情,导入excel文件数据时,数据格_excel 导入时第一条导入后将第一条的数据返回
一例JAVA多线程访问卡死的现象_http-nio-8181-exec-4 线程过多导致卡死-程序员宅基地
文章浏览阅读6.9k次。 最近适配摄像头,自然的就要接收、传递音频视频数据。而这些数据是非常频繁的,如果每次都新建缓冲区,一个是影响性能,另外也显得自己水平太低。怎么办?上缓存。 音频、视频当然要分开缓存。代码很类似,自然的吾就新建了一个类, 起名?Manager显然不合适,叫Worker最好。Queue、Cache都不是太适合。 数据队列LinkedBlockingDeque,缓存用Concurre..._http-nio-8181-exec-4 线程过多导致卡死