Hadoop之MapReduce编程_hadoop搭建完后mapreduce怎么写-程序员宅基地
技术标签: mapreduce Hadoop hadoop Intellij打包jar 大数据
MapReduce编程基础
0. MR与Java的数据类型对比
| MR | Java |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| String | Text |
| map | MapWritable |
| array | ArrayWritable |
//hadoop数据类型所在java包
import org.apache.hadoop.io.IntWritable
import org.apache.hadoop.io.Text
...
1. MapReduce代码的组成
- Mapper
- Reducer
- Driver
MR代码需要由上述三个部分组成,每个部分单独成一个.java文件。其中,Mapper文件处理的是map阶段的逻辑;reducer文件处理的是reduce阶段的逻辑;Driver文件内含整个MR的main方法,用于设置参数、调度map和reduce等。
1.1 Mapper
- 用户自定义的Mapper需要继承自己的父类
- Mapper的输入、输出数据均是key-value形式的,且数据类型可以自定义
- Mapper的业务逻辑写在map()方法中
- map()方法处理过程中,一次读取一行数据,同一行数据只会被一个map()调用一次
1.2 Reducer
- 用户自定义的Reducer需要继承自己的父类
- Reducer的输入对应的是Mapper的输出
- Reducer的业务逻辑写在reduce()方法中
- reduce()方法处理过程中,每次读取Mapper()的一个输出key-value,同一个key-value只会被一个reduce()调用一次
1.3 Driver
- 设置MapReduce运行时的各种参数
- 指定运行时所需jar包路径
- 指定Mapper输出数据类型
- 指定最终结果输出数据类型
- 指定输入数据所在目录
- 指定输出数据写入目录
- 将代码提交到yarn集群执行
dirver相当于连接hadoop集群的客户端,用于设置MapReduce运行时的各种参数,并将编写好的代码提交到yarn上执行。
2. WordCount代码 - - 以Intellij IDEA为例
//处理的数据格式
hadoop,spark,java
kudu,hadoop,hbase
zookeeper,flink,sparkstreaming
hive,flink
hadoop
2.0 环境配置
- 添加依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>hadoop-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<repositories>
<repository>
<id>ali-maven</id>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</repository>
</repositories>
<!--
hadoop依赖的版本需要与集群中的hadoop版本一致
-->
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.2.1</version>
</dependency>
</dependencies>
</project>
- 日志设置
在项目的resources文件夹下创建log.properties文件,文件内容为如下
log4j.rootLogger=INFO, stdout, D
# Console Appender
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern= %d{
hh:mm:ss,SSS} [%t] %-5p %c %x - %m%n
# Custom tweaks
log4j.logger.com.codahale.metrics=WARN
log4j.logger.com.ryantenney=WARN
log4j.logger.com.zaxxer=WARN
log4j.logger.org.apache=WARN
log4j.logger.org.hibernate=WARN
log4j.logger.org.hibernate.engine.internal=WARN
log4j.logger.org.hibernate.validator=WARN
log4j.logger.org.springframework=WARN
log4j.logger.org.springframework.web=WARN
log4j.logger.org.springframework.security=WARN
# log file
log4j.appender.D = org.apache.log4j.DailyRollingFileAppender
log4j.appender.D.File = ..//log.log
log4j.appender.D.Append = true
log4j.appender.D.Threshold = DEBUG
log4j.appender.D.layout = org.apache.log4j.PatternLayout
log4j.appender.D.layout.ConversionPattern = %-d{
yyyy-MM-dd HH:mm:ss} [ %t:%r ] - [ %p ] %m%n
2.1 Mapper部分 - - WordCountMapper.java
package com.csd;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WordCountMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
/*
继承Mapper父类,这里的四个参数<LongWritable,Text,Text,IntWritable>分别是:
1.LongWritable 是读取的文件的偏移量(暂时照着写就行,还没接触更改此参数的意义)
2.Text map阶段需要从hdfs读取的数据的数据类型,因为现在处理的是字符串,所以指定为Text
3.Text map阶段输出的key-value中的key的数据类型,本次map的输出格式为("hadoop",1)、("spark",1)....,因此指定key类型为Text
4.IntWritable map阶段输出的key-value中的value的数据类型,本次map的输出的value为1,因此指定value类型为IntWritable
*/
// 下面两个变量为map输出的key和value,为了避免重复实例化,因此将其提到公共变量区域
//修改hadoop数据类型统一用其set()的方法 write_key.set("hadoop")
private static Text write_key = new Text();
private static IntWritable write_value = new IntWritable();
//重写map方法,此处写的是map的处理逻辑
//LongWritable offset, Text value即为Mapper<>的前两个变量
@Override
protected void map(LongWritable offset, Text value, Context context)
throws IOException, InterruptedException {
//将hadoop的Text转换为java的String,value是输入文件的一行数据,值如value=hadoop,spark,java
String line = value.toString();
//切分每一行数据
String[] words = line.split(",");
//将一行数据的多个单词拆分成多个(key,value)
for(String word:words){
write_key.set(word);
write_value.set(1);
//将(key,value)写入文件,供之后的reducer读取
context.write(write_key,write_value);
}
}
}
2.2 Reducer部分 - - WordCountReducer.java
package com.csd;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordCountReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
private static IntWritable tmp_val = new IntWritable();
/*
继承自Reducer,Reducer<Text,IntWritable,Text,IntWritable>的变量分别是:
1.reduce端输入,即map端输出的key-value对中的key的数据类型
2.reduce端输入,map端输出的key-value对中的value的数据类型
3.reduce端输出的key-value中key的数据类型
4.reduce端输出的key-value中value的数据类型
*/
//重写reduce方法,此处编写reduce处理逻辑
//Text key, Iterable<IntWritable> values 分别是:
//map端输出的key的数据类型
//Iterable<IntWritable>中Iterable内部的数据类型是map端输出的value的数据类型。reducer接收到的数据不是原封不动的map端的输出,而是经过加工的,一是key值会按照字典序排序;二是相同key的value值会被放到同一个迭代器Iterable中,即reducer接收到的数据其实类是与("hadoop",[1,1,1,1])、(“spark",[1,1,1])...
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
//遍历迭代器,计数每个key出现的次数
for(IntWritable val:values){
sum += val.get();
}
tmp_val.set(sum);
//将计数结果写入带最终的输出文件
context.write(key,tmp_val);
}
}
2.2 Driver部分 - - WordCountDriver.java
执行MR程序有多种方式
- 方法一:在开发环境下,直接通过IDEA执行(与hadoop集群环境无任何关系)
- 方法二:在开发环境下,直接通过IDEA执行,但输入输出使用的是hdfs(与hadoop集群环境有部分关系)
- 方法三:将java代码打包成jar,在集群环境下使用hadoop jar xxx,将MR放在yarn上执行
//方法一
package com.csd;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator;
import java.io.IOException;
public class WordCountDriver{
//路径为本地路径
private static String input_path = "/home/dong/Desktop/a/word_count.txt";
private static String output_path = "/home/dong/Desktop/a/b";
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//BasicConfigurator用于日志输出
BasicConfigurator.configure();
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,
new Path(input_path));
FileOutputFormat.setOutputPath(job,new Path(output_path));
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
//方法二
package com.csd;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.log4j.BasicConfigurator;
import java.io.IOException;
public class WordCountDriver{
//路径为hdfs路径
private static String HDFS_PATH = "hdfs://dong:9000";
private static String input_path = "hdfs:///data/test";//"/home/dong/Desktop/a/word_count.txt";
private static String output_path = "hdfs:///data/result";//"/home/dong/Desktop/a/b";
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
BasicConfigurator.configure();
Configuration conf = new Configuration();
//设置为hdfs模式
conf.set("fs.defaultFS", HDFS_PATH);
Job job = Job.getInstance(conf);
job.setJarByClass(WordCountDriver.class);
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.setInputPaths(job,
new Path(input_path));
FileOutputFormat.setOutputPath(job,new Path(output_path));
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
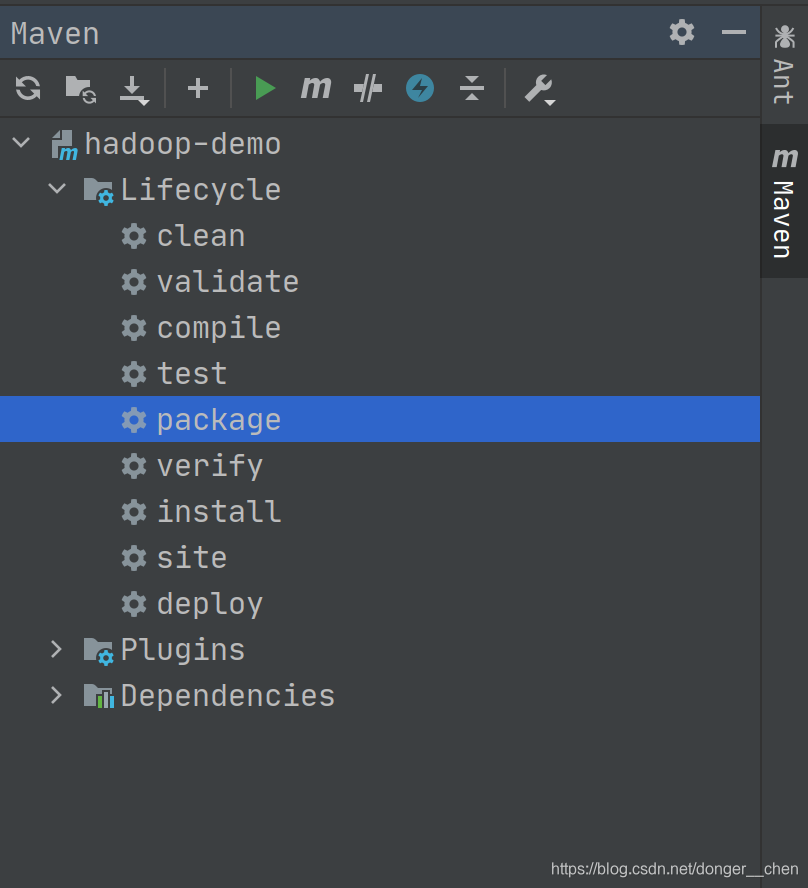
方法三:将方法二的代码打包成jar包
点击右侧Maven --> Lifecycle --> 点击package即可完成自动打包
成功后会有信息,显示build success并给出打包完的jar路径
//jar包所在路径
[INFO] Building jar: /home/dong/code/java/hadoop/target/hadoop-demo-1.0-SNAPSHOT.jar
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
执行方式
将上述打包好的jar拷贝至集群,并通过shell方式提交到yarn上运行
//xxxx.jar即为打包好的jar路径
//com.csd.WordCountDriver 是指定main方法所在的文件
hadoop jar xxxx.jar com.csd.WordCountDriver
智能推荐
鱼群算法在交通流控制中的实际效果-程序员宅基地
文章浏览阅读807次,点赞18次,收藏22次。1.背景介绍交通流控制是现代城市发展中的一个重要问题,随着城市人口和车辆数量的增长,交通拥堵成为了日常生活中不可避免的现象。传统的交通控制方法已经无法满足现代城市的需求,因此需要寻找更高效的交通流控制方法。鱼群算法是一种自然界的优化算法,它可以用于解决交通流控制中的各种问题。在本文中,我们将介绍鱼群算法在交通流控制中的实际效果,包括背景介绍、核心概念与联系、核心算法原理和具体操作步骤、数学模型...
php 私有变量混淆 gettokenall,解密 - 如何满足PHP源代码加密和混淆的需求-程序员宅基地
文章浏览阅读93次。最近被要求把产品代码加密,测试了几款容易获得的加密工具,当然对应的解密工具也一样容易找到!易维的那个加密工具貌似需要购买,否则存在使用时间限制,不知道有没有了解实情的兄弟!还有个开源的screw,加密方法是用C写的PHP扩展,但是不清楚的是:PHP screw加密后的代码是否只能运行在装有screw的Linux环境下?还有就是有没有好的PHP代码混淆工具?微盾的混淆工具很杯具,我的项目代码混淆后无..._php token_get_all 加密
清理outlook缓存_如何清理outlook缓存,to do list不行-程序员宅基地
文章浏览阅读9.4k次。1、关闭outlook客户端2、删除outlook本地缓存 win7系统,打开C:\Users\AppData\Local\Microsoft\Outlook\Offline Address Books目录,如该目录隐藏请先将隐藏目录显示出来,删除该目录下的所有内容。3、打开outlook客户端,更新全球通讯簿4、清空自动完成列表 依次打开outlook的文件——选项——邮件,下拉右边的滚动条,往下找到“清空自动完成列表”按钮,点击确认即可5、 ..._如何清理outlook缓存,to do list不行
[C++]利用可变模板将不定入参连接为字符串返回_c++ 使用可变模板返回字符串-程序员宅基地
文章浏览阅读39次。利用可变模板将不定入参连接为字符串返回,可用于构建一个入参不定的日志系统,用于代替C语言的可变参数。_c++ 使用可变模板返回字符串
MyEclipse连接MySQL报错:the server time zone value *** is unrecognized_myeclipse连接数据库用户登录失败-程序员宅基地
文章浏览阅读6k次,点赞6次,收藏13次。错误信息:解决办法:URL后加?serverTimezone=UTC_myeclipse连接数据库用户登录失败
人工智能——罗马利亚问题_根据上图以zerind为初始状态,bucharest为目标状态实现搜索,分别以贪婪搜索(只考虑-程序员宅基地
文章浏览阅读542次。题目:根据上图以Zerind为初始状态,Bucharest为目标状态实现搜索,分别以贪婪搜索(只考虑直线距离)和A算法求解最短路径。 按顺序列出贪婪算法探索的扩展节点和其估价函数值,A算法探索的扩展节点和其估计值。题目解析:1.构建罗马利亚图2.构建到B城市的直线距离3.实现贪婪算法4.实现A*算法5.对所求路径及总长度进行输出代码:# 罗马利亚图存储city_graph = [['A', 'Z', 75], ['A', 'T', 118], _根据上图以zerind为初始状态,bucharest为目标状态实现搜索,分别以贪婪搜索(只考虑
随便推点
案例分析:SQL 窗口函数实现高效分页查询_sql 窗口函数实现分页-程序员宅基地
文章浏览阅读2.3k次,点赞13次,收藏35次。使用 SQL 语句实现分页查询时,我们需要知道一些额外的参数信息,例如查询返回的总行数、当前所在的页数、最后一页的页数等。在传统的实现方法中我们需要执行额外的查询语句获得这些信息。本文介绍了如何利用 SQL 窗口函数在一个语句中返回分页查询的结果和所需的全部参数,这种方法比传统的分页查询实现更加简洁高效。_sql 窗口函数实现分页
OI生涯回忆录(Part1:至初二上学期期末考试)_邢健开-程序员宅基地
文章浏览阅读2.6k次,点赞5次,收藏6次。前言:这是一篇迟来的回忆录,想了一想,距离我退役也已经有10个月了,最开始是冲集训队失败心情比较低落,后来又接连去了两个公司实习所以一直没时间写,但是我怕很多事情再耽搁下去就忘了,所以开始动笔。由于这是一篇在CSDN上发表的OI生涯回忆录,所以虽然这六年来我经历了很多事情,有些事甚至很重要,但是在这里我只能一笔带过,主要还是写我这六年(五年)来的OI生活吧 (一)缘起凭借着小学出色的数..._邢健开
嵌入式qt-程序员宅基地
文章浏览阅读3.2k次,点赞5次,收藏15次。1 在自己的虚拟机里面编译配置打包好busybox文件系统,然后放在开发板的Linux中去2 开发板Linux烧录打包好的文件系统3 为了能使QT在开发板上运行,必须首先交叉编译QT源码,然后生成QT库,再移植到我们的开发板上。(在QT官网上下载QT源码) 这一步仅仅是为了测试用的4 将编译好的QT拷贝到根文件目录下5 将打包好的根文件系统烧写到开发板的Linux系统中6 交叉编译qt代码,一般我们都Windows上开发qt代码,但是我们最终还是要把我们的qt代码放在开发板上运行,这就必须用到_嵌入式qt
Word | 简单可操作的快捷公式编号、右对齐和引用方法_word公式编号-程序员宅基地
文章浏览阅读4.6k次,点赞7次,收藏22次。在理工科论文的写作中,涉及到大量的公式输入,我们希望能够按照章节为公式进行编号,并且实现公式居中,编号右对齐的效果。网上有各种各样的方法来实现,操作繁琐和简单的混在一起,让没有接触过公式编号的人感觉比较混乱。笔者自己博览相关博客,亲身实践,总结出一套自认为比较简便的公式编号、对齐和引用方法,在这里分享给大家~_word公式编号
企业信息化建设发展报告-程序员宅基地
文章浏览阅读182次。企业信息化建设 发展报告 wxwinter 目录1 软件架构 1 2 IT公司服务模式 1 3 企业应用模式 2 软件架构阶段结构年代第一阶段单机应用 - 1998第二阶段C/S 客户端/服务器1998 – 2000第三阶段B/S 浏览器/..._应用软件信息化建设开发报告
大促下热点数据写(库存扣减解决方案-程序员宅基地
文章浏览阅读2k次。针对交易系统大促场景下热点数据写优化的相关案例。当然,不同的企业有不同的解决方案和实现,但是万变不离其宗,还是那句话,对于大型网站而言,其架构一定是简单和清晰的,而不是炫技般的复杂化,毕竟解决问题采用最直接的方式直击要害才是最见效的,否则事情只会变得越来越糟。 在大部分情况下,商品库存都是直接在关系型数据库中进行扣减,那么在限时抢购活动正式开始后,那些单价比平时更给力、更具吸引力的_大促扣库存怎么