【华为云技术分享】干货!!卷积神经网络之LeNet-5迁移实践案例_华为云卷积神经网络如何使用npu-程序员宅基地
技术标签: 机器学习 深度学习 人工智能 神经网络 昇腾 技术交流
摘要:LeNet-5是Yann LeCun在1998年设计的用于手写数字识别的卷积神经网络,当年美国大多数银行就是用它来识别支票上面的手写数字的,它是早期卷积神经网络中最有代表性的实验系统之一。可以说,LeNet-5就相当于编程语言入门中的“Hello world!”。
华为的昇腾训练芯片一直是大家所期待的,目前已经开始提供公测,如何在昇腾训练芯片上运行一个训练任务,这是目前很多人都在采坑过程中,所以我写了一篇指导文章,附带上所有相关源代码。注意,本文并没有包含环境的安装,请查看另外相关文档。
环境约束:昇腾910目前仅配套TensorFlow 1.15版本。
基础镜像上传之后,我们需要启动镜像命令,以下命令挂载了8块卡(单机所有卡):
docker run -it --net=host --device=/dev/davinci0 --device=/dev/davinci1 --device=/dev/davinci2 --device=/dev/davinci3 --device=/dev/davinci4 --device=/dev/davinci5 --device=/dev/davinci6 --device=/dev/davinci7 --device=/dev/davinci_manager --device=/dev/devmm_svm --device=/dev/hisi_hdc -v /var/log/npu/slog/container/docker:/var/log/npu/slog -v /var/log/npu/conf/slog/slog.conf:/var/log/npu/conf/slog/slog.conf -v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ -v /usr/local/Ascend/driver/tools/:/usr/local/Ascend/driver/tools/ -v /data/:/data/ -v /home/code:/home/local/code -v ~/context:/cache ubuntu_18.04-docker.arm64v8:v2 /bin/bash设置环境变量并启动手写字训练网络:
#!/bin/bash
export LD_LIBRARY_PATH=/usr/local/lib/:/usr/local/HiAI/runtime/lib64
export PATH=/usr/local/HiAI/runtime/ccec_compiler/bin:$PATH
export CUSTOM_OP_LIB_PATH=/usr/local/HiAI/runtime/ops/framework/built-in/tensorflow
export DDK_VERSION_PATH=/usr/local/HiAI/runtime/ddk_info
export WHICH_OP=GEOP
export NEW_GE_FE_ID=1
export GE_AICPU_FLAG=1
export OPTION_EXEC_EXTERN_PLUGIN_PATH=/usr/local/HiAI/runtime/lib64/plugin/opskernel/libfe.so:/usr/local/HiAI/runtime/lib64/plugin/opskernel/libaicpu_plugin.so:/usr/local/HiAI/runtime/lib64/plugin/opskernel/libge_local_engine.so:/usr/local/H
iAI/runtime/lib64/plugin/opskernel/librts_engine.so:/usr/local/HiAI/runtime/lib64/libhccl.so
export OP_PROTOLIB_PATH=/usr/local/HiAI/runtime/ops/built-in/
export DEVICE_ID=2
export PRINT_MODEL=1
#export DUMP_GE_GRAPH=2
#export DISABLE_REUSE_MEMORY=1
#export DUMP_OP=1
#export SLOG_PRINT_TO_STDOUT=1
export RANK_ID=0
export RANK_SIZE=1
export JOB_ID=10087
export OPTION_PROTO_LIB_PATH=/usr/local/HiAI/runtime/ops/op_proto/built-in/
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/Ascend/fwkacllib/lib64/:/usr/local/Ascend/driver/lib64/common/:/usr/local/Ascend/driver/lib64/driver/:/usr/local/Ascend/add-ons/
export PYTHONPATH=$PYTHONPATH:/usr/local/Ascend/opp/op_impl/built-in/ai_core/tbe
export PATH=$PATH:/usr/local/Ascend/fwkacllib/ccec_compiler/bin
export ASCEND_HOME=/usr/local/Ascend
export ASCEND_OPP_PATH=/usr/local/Ascend/opp
export SOC_VERSION=Ascend910
rm -f *.pbtxt
rm -f *.txt
rm -r /var/log/npu/slog/*.log
rm -rf train_url/*
python3 mnist_train.py
以下训练案例中我使用的lecun大师的LeNet-5网络,先简单介绍LeNet-5网络:
LeNet5诞生于1994年,是最早的卷积神经网络之一,并且推动了深度学习领域的发展。自从1988年开始,在多年的研究和许多次成功的迭代后,这项由Yann LeCun完成的开拓性成果被命名为LeNet5。
LeNet-5包含七层,不包括输入,每一层都包含可训练参数(权重),当时使用的输入数据是32*32像素的图像。下面逐层介绍LeNet-5的结构,并且,卷积层将用Cx表示,子采样层则被标记为Sx,完全连接层被标记为Fx,其中x是层索引。
层C1是具有六个5*5的卷积核的卷积层(convolution),特征映射的大小为28*28,这样可以防止输入图像的信息掉出卷积核边界。C1包含156个可训练参数和122304个连接。
层S2是输出6个大小为14*14的特征图的子采样层(subsampling/pooling)。每个特征地图中的每个单元连接到C1中的对应特征地图中的2*2个邻域。S2中单位的四个输入相加,然后乘以可训练系数(权重),然后加到可训练偏差(bias)。结果通过S形函数传递。由于2*2个感受域不重叠,因此S2中的特征图只有C1中的特征图的一半行数和列数。S2层有12个可训练参数和5880个连接。
层C3是具有16个5-5的卷积核的卷积层。前六个C3特征图的输入是S2中的三个特征图的每个连续子集,接下来的六个特征图的输入则来自四个连续子集的输入,接下来的三个特征图的输入来自不连续的四个子集。最后,最后一个特征图的输入来自S2所有特征图。C3层有1516个可训练参数和156 000个连接。
层S4是与S2类似,大小为2*2,输出为16个5*5的特征图。S4层有32个可训练参数和2000个连接。
层C5是具有120个大小为5*5的卷积核的卷积层。每个单元连接到S4的所有16个特征图上的5*5邻域。这里,因为S4的特征图大小也是5*5,所以C5的输出大小是1*1。因此S4和C5之间是完全连接的。C5被标记为卷积层,而不是完全连接的层,是因为如果LeNet-5输入变得更大而其结构保持不变,则其输出大小会大于1*1,即不是完全连接的层了。C5层有48120个可训练连接。
F6层完全连接到C5,输出84张特征图。它有10164个可训练参数。这里84与输出层的设计有关。
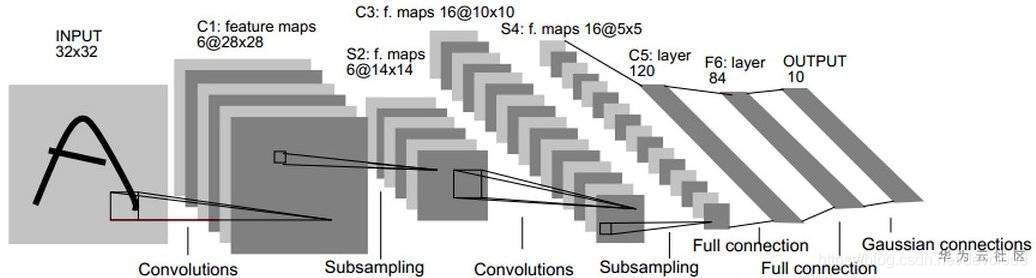
LeNet的设计较为简单,因此其处理复杂数据的能力有限;此外,在近年来的研究中许多学者已经发现全连接层的计算代价过大,而使用全部由卷积层组成的神经网络。
LeNet-5网络训练脚本是mnist_train.py,具体代码:
import os
import numpy as np
import tensorflow as tf
import time
from tensorflow.examples.tutorials.mnist import input_data
import mnist_inference
from npu_bridge.estimator import npu_ops #导入NPU算子库
from tensorflow.core.protobuf.rewriter_config_pb2 import RewriterConfig #重写tensorFlow里的配置,针对NPU的配置
batch_size = 100
learning_rate = 0.1
training_step = 10000
model_save_path = "./model/"
model_name = "model.ckpt"
def train(mnist):
x = tf.placeholder(tf.float32, [batch_size, mnist_inference.image_size, mnist_inference.image_size, mnist_inference.num_channels], name = 'x-input')
y_ = tf.placeholder(tf.float32, [batch_size, mnist_inference.num_labels], name = "y-input")
regularizer = tf.contrib.layers.l2_regularizer(0.001)
y = mnist_inference.inference(x, train = True, regularizer = regularizer) #推理过程
global_step = tf.Variable(0, trainable=False)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits = y, labels = tf.argmax(y_, 1)) #损失函数
cross_entropy_mean = tf.reduce_mean(cross_entropy)
loss = cross_entropy_mean + tf.add_n(tf.get_collection("loss"))
train_step = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss, global_step = global_step) #优化器调用
saver = tf.train.Saver() #启动训练#以下代码是NPU所必须的代码,开始配置参数
config = tf.ConfigProto(
allow_soft_placement = True,
log_device_placement = False)
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
#custom_op.parameter_map["profiling_mode"].b = True
#custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes("task_trace:training_trace")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF#配置参数结束
writer = tf.summary.FileWriter("./log_dir", tf.get_default_graph())
writer.close()#参数初始化
with tf.Session(config = config) as sess:
tf.global_variables_initializer().run()
start_time = time.time()
for i in range(training_step):
xs, ys = mnist.train.next_batch(batch_size)
reshaped_xs = np.reshape(xs, (batch_size, mnist_inference.image_size, mnist_inference.image_size, mnist_inference.num_channels))
_, loss_value, step = sess.run([train_step, loss, global_step], feed_dict={x:reshaped_xs, y_:ys})#每训练10个epoch打印损失函数输出日志
if i % 10 == 0:
print("****************************++++++++++++++++++++++++++++++++*************************************\n" * 10)
print("After %d training steps, loss on training batch is %g, total time in this 1000 steps is %s." % (step, loss_value, time.time() - start_time))
#saver.save(sess, os.path.join(model_save_path, model_name), global_step = global_step)
print("****************************++++++++++++++++++++++++++++++++*************************************\n" * 10)
start_time = time.time()
def main():
mnist = input_data.read_data_sets('MNIST_DATA/', one_hot= True)
train(mnist)
if __name__ == "__main__":
main()本文主要讲述了经典卷积神经网络之LeNet-5网络模型和迁移至昇腾D910的实现,希望大家快来动手操作一下试试看!
点击这里→了解更多精彩内容
相关推荐
智能推荐
zabbix短信告警oracle,zabbix 实现短信告警-程序员宅基地
文章浏览阅读402次。之前一直调用飞信接口发送告警信息,最近购买了第三方短信接口。所以准备使用接口发送告警。短信接口是基于https的摘要认证。https认证还是自己做的,调用接口的时候还需要load证书。感觉超级难用,不管那么多,先让它跑起来再说。废话不多说,先上代码。#!/usr/bin/envpython#coding:utf-8importrequestsfromrequests.authimport..._zabbix实现短信告警
soapui中文操作手册(四)----MOCK服务_soapui设置成中文-程序员宅基地
文章浏览阅读6.8k次,点赞2次,收藏12次。转载地址:http://www.cnblogs.com/zerotest/p/4670005.htmlWeb Service Mocking是武器库一个非常有用的工具。这是解决“如果没有Web服务如何创建针对性的Web服务测试”问题的办法。Web Service Mocking将在这里派上用场。它允许你实际的Web服务产生之前,创建近似或模拟的Web Service。在本教_soapui设置成中文
Swift 包管理器 (SPM):管理 iOS 中的依赖关系_ios spm-程序员宅基地
文章浏览阅读845次,点赞29次,收藏7次。Swift 包管理器 (SPM):管理 iOS 中的依赖关系_ios spm
SCI论文润色真有必要吗?-程序员宅基地
文章浏览阅读381次,点赞10次,收藏7次。总的来说,sci论文润色虽然不会改变论文的学术内容和贡献,但它能够显著的提升论文的质量和可读性,从而增加论文被接受和引用的机会。在论文投稿前都是需要润色的,特别是英文论文投稿,一定得靠谱。但如果是一些小问题,比如语法语句错误,专业言论不恰当,那么你的文章会在投稿过程中外审评定完以后,也会给你返修意见和修改机会。如果是新作者,或者是对自己的语言能力不那么自信,那么是很有必要的。其他人的视角可能会发现你忽略的错误或不清晰的表达,同时也可以提供有关论文结构和逻辑的反馈意见。关于SCI论文润色的常见方法。
Prometheus监控数据格式的学习-程序员宅基地
文章浏览阅读1.1k次,点赞33次,收藏9次。Prometheus 指标(metrics)的数据形式是一种简单的文本格式(容易通过 HTTP 协议被 Prometheus 服务器拉取)。每一行包含了一个指标的数据,通常包括指标名称、可选的一组标签以及指标的值。Prometheus 的指标数据可以有不同类型,如 Counter、Gauge、Histogram 和 Summary,它们的表示形式会有所不同。
数字图像处理(10): OpenCV 图像阈值化处理_binarization threshold-程序员宅基地
文章浏览阅读5.6k次,点赞26次,收藏43次。目录1 什么是阈值化-threshold()2 二进制阈值化3 反二进制阈值化4 截断阈值化5 反阈值化为06 阈值化为07 小结参考资料1 什么是阈值化-threshold()图像的二值化或阈值化 (Binarization)旨在提取图像中的目标物体,将背景以及噪声区分开来。通常会设定一个阈值,通过阈值将图像的像素划分为两类:大于阈值的..._binarization threshold
随便推点
使用安卓模拟器时提示关闭hyper-v_hyperv影响 模拟器-程序员宅基地
文章浏览阅读1.6w次。本电脑是宏碁传奇X,cpu是r7 5800u,显卡rtx3050;使用了雷电、mumu两款安卓模拟器,雷电启动报错g_bGuestPowerOff fastpipeapi.cpp:1161,使用了网上的所有方案都不行,包括开启VT(amd开启SVM),命令关闭hyper-v服务等;尝试mumu模拟器,安装时支持vt项检测不通过,后来发现mumu模拟器在amd的cpu上只支持32位版,换装32位版检测通过,但是只要打开模拟器就提示需要关闭hyper-v,我已经确认关闭后,启动依旧这样提示,查找了网上很_hyperv影响 模拟器
【大厂秘籍】系列 - Mysql索引详解-程序员宅基地
文章浏览阅读564次。MySQL官方对索引定义:是存储引擎用于快速查找记录的一种数据结构。需要额外开辟空间和数据维护工作。● 索引是物理数据页存储,在数据文件中(InnoDB,ibd文件),利用数据页(page)存储。● 索引可以加快检索速度,但是同时也会降低增删改操作速度,索引维护需要代价。
CSS实现当鼠标停留在一个元素上时,使得两个元素的样式发生改变_css鼠标悬浮修改其他元素样式-程序员宅基地
文章浏览阅读825次。使用兄弟选择器实现同时改变两个元素的样式_css鼠标悬浮修改其他元素样式
文献学习-40-基于可迁移性引导的多源模型自适应医学图像分割-程序员宅基地
文章浏览阅读4.8k次,点赞32次,收藏43次。香港中文大学袁奕萱教授团队提出了一种名为多源模型自适应 (MSMA) 的新型无监督域适应方法。MSMA 旨在仅利用预训练的源模型(而非源数据)将知识迁移到未标记的目标域,从而实现对目标域的有效分割。
(4)FPGA开发工具介绍(第1天)-程序员宅基地
文章浏览阅读8.8k次。(4)FPGA开发工具介绍(第1天)1 文章目录1)文章目录2)FPGA初级课程介绍3)FPGA初级课程架构4)FPGA开发工具介绍(第1天)5)技术交流6)参考资料2 FPGA初级课程介绍1)FPGA初级就业课程共100篇文章,目的是为了让想学FPGA的小伙伴快速入门。2)FPGA初级就业课程包括FPGA简介、Verilog HDL基本语法、Verilog HDL 入门实例、FPGA入门实例、Xilinx FPGA IP core设计、Xilinx FPGA原语与U_fpga开发工具
js中的定时器如何使用_js定时器用法-程序员宅基地
文章浏览阅读1.4k次。JS提供了一些原生方法来实现延时去执行某一段代码,下面来简单介绍一下setTiemout、setInterval、setImmediate、requestAnimationFrame。首先,我们先来了解一下什么是定时器:JS提供了一些原生方法来实现延时去执行某一段代码下面来简单介绍一下setTimeout() :在指定的毫秒数后调用函数或计算表达式。setTimeout(code,millisec,lang)参数 描述code 必需。要调用的函数后要执行的 JavaScript 代码串。_js定时器用法