王晶:华为云OCR文字识别服务技术实践、底层框架及应用场景 | AI ProCon 2019_华伟王晶-程序员宅基地
技术标签: OCR文字识别 程序员 开发者上云 华为云 人工智能 文字识别
演讲嘉宾 | 王晶(华为云人工智能高级算法工程师王晶)
出品 | AI科技大本营(ID:rgznai100)
近期,由 CSDN 主办的 2019 中国AI 开发者大会(AI ProCon 2019)在北京举办。在计算机视觉技术专题,华为云OCR人工智能高级算法工程师王晶分享了“文字识别服务的技术实践、底层框架及应用场景”的主题演讲。
演讲的第一部分,他分享了文字检测和识别的基础知识以及难点和最新进展。第二部分是华为云文字识别服务关键能力、关键技术,以及落地过程中遇到的“坑”,这对其他人工智能产品甚至以数据为驱动的产品都具有实践参考意义。第三部分,他主要介绍了文字识别应用场景以及典型的落地方案
在王晶看来,虽然现在人工智能很火,但真正能落地的场景比较少,能大规模应用的场景更是少之又少,不过,文字识别服务在经典落地场景中显然有一席之地。

以下为王晶演讲内容实录,由AI科技大本营(ID:rgznai100)整理:
文字识别基本概述和最新进展
几年前我们开始做服务的时候心里还是比较忐忑的,因为文字识别听起来没有像人脸识别或者自动驾驶那么高大上,但是后来证明我们的选择是非常对的,现在这个产品基本上是整个华为云EI部门的明星产品,应用范围非常广。

先说一个概念,光学字符识别,英文简写是OCR。它的意思是将图片、PDF中文字转换为可编辑的文本文件。首先是检测过程,检测是指判断是否存在文字实例并给出具体位置的过程。其次是识别,当我们找到了文字块之后可以把它转化成具体的可编辑的内容。一般大家会把2014年前的方法统称为传统方法,依靠的是传统手工设计特征,第二个方法是深度学习,左边是把发票和文档转化成可编辑文字的实例。

文字检测和识别的难点非常多,这些图是我们做产品过程中遇到的实际场景。首先可以看到背景很多样,非常复杂,字体也可以有很多种,比如第一张字体相对标准一点,最后一张则是有一些艺术字的特点,颜色也可以很多,比如可以是黄色、白色、黑色等各种各样的颜色。方向依然可以是随意的,语言也不统一,中国遇到的大多数场景是汉字和英语,海外的很多场景包含了各种语言。最后是板式不固定,这个很直接。

还有一个难点是日常生活的指示栏、窗户、砖块、图标、花草、栅栏和指示牌等,这些物体和文字的纹理有非常大的相似性。比如移动logo这个图标和这边文字纹理特征非常相近,是有极大可能被检测出来的,但是大部分字符集成没有这个字符,极其容易造成误识别。还有就是图像本身的成像等问题也会造成干扰,比如反光、各种遮挡等,这些都会影响文字的检测和识别。
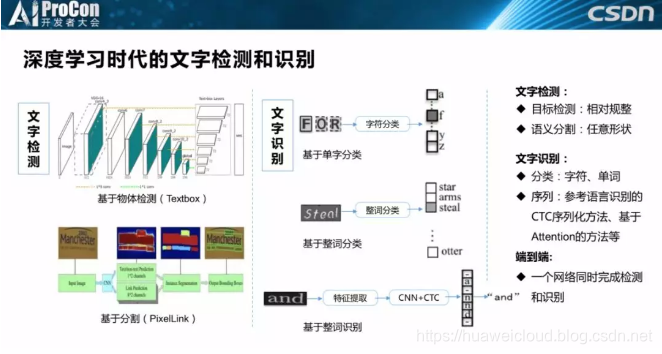
深度学习时代的文字检测和识别方法和物体检测类似,因为文字本身就是物体的一种,所以检测思路同样分为两种。相对规整文字是基于物体检测回归的方法,另一种是文字形状更加多变的,可以基于分割的方法,左上角这个论文核心的工作是就是把SSD的Anchor设计基于文字特点重新设计了。普通的物体检测Anchor设计偏于正方形或正方形按一定比例左右拉伸的变换。比如本次报告的标题就比较长,实际的场景可以非常长,比如超出我身后屏幕的容纳范围。
文字识别,非常容易想到的方法就是把字符一个个切割出来进行分类,这个方法在深度学习之前是最常用的方法。第二是整词分类,我们把一个单词直接进行分类。但是对于汉语来说,如果基于整词分类,大家会发现类别特别多,在实际应用场景中是不现实的。最后一个是现在最常用的方法,基于序列特征提取,比如从语音识别借鉴过来的CTC。除了检测和识别以外还有一个方法是端到端,同时做检测和识别,本质上还是需要检测识别的,只是在一个任务中同时做检测和识别。

一个文字检测的例子就是TextField,图中的文字弧形比较大、也比较密集,这个方法是基于像素进行分类,通过后处理把文字合在一起形成一个结果,这个工作的优点是可以检测比较密的文字,也可以检测出弧形比较大的文字。
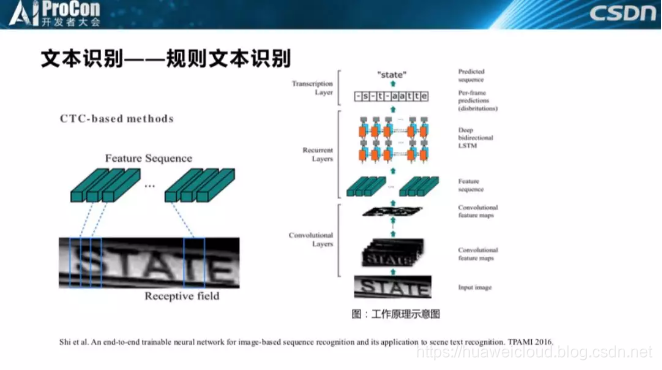
另一个例子是文字识别的一个非常典型的工作,据我所知很多的中国的公司都在用这个方法,就是CRNN,首先通过CNN特征提取,提取之后进入一个RNN网络,比如LSTM,这样更利于提取图片中文字的前后联系,最后通过CTC训练得到序列化的结果。
文字识别服务的关键能力和和关键技术
第二部分是我今天要讲的重点,也就是华为云文字识别服务的关键能力和关键技术。我会讲很多我们在做产品过程中遇到的问题和踩过的坑,其中很多问题和坑不只是文字识别,包括人工智能甚至数据驱动的服务基本都会遇到这些问题。我们是一个产品团队,我们的核心工作是做产品,但是我们也会顺便参加一些比赛,发一些论文,提交一些专利来提高影响力。

我们的服务主要分为五大类,包括通用类、票据类、证件类、行业类和定制类。通用类包括比如通用文字、通用表格、网络截图等比较通用的能力。票据类包括增值税发票、车辆通行费、火车票、行程单等。证件类包括身份证、驾驶证、行驶证、护照等等。行业类则是面向特定行业的,比如物流行业的纸质面单、电子面单,燃气表、医学检验单、医疗化验单等。最后是定制类,这些是需要特殊定制的,比如海外服务,助力企业提高生产力,降低成本。

核心步骤有五部分,第一是图像预处理,我们拿到的图像很多时候有各种各样的背景,第一步首先做的是把图片切割出来,如果有表格的话单独处理,然后是文字定位、文字识别,最后是后处理校验,返回结构化的json结果。
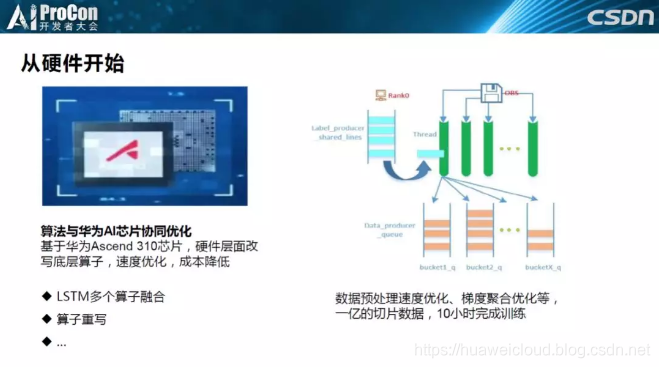
那这些能力是如何实现的?首先就是从硬件开始优化,结合我们自己的AI Ascend昇腾芯片,从底层算子开始改写,我们做产品的时候会把多个算子进行融合,基于芯片进行底层算子重写。
一个AI真的想特别落地的话一定需要考虑硬件场景,前面几个老师提过他们需要在手机侧落地,就一定需要考虑手机侧的特点,因为手机芯片的能力没有GPU那么强。为了训练速度的提升,我们会做非常多样的优化,比如图像预处理优化,会基于图片长度生成很多进程,对不同长度的文字进行不同的读取,queue还有辅助queue。
同时会对梯度进行系统聚合优化等等,我们可以在10小时内完成1亿的切片数据训练。所以不管是大公司还是小公司大家做产品的时候第一步都要考虑硬性条件,很多算法性能非常好,但是跑不起来又有什么用呢?
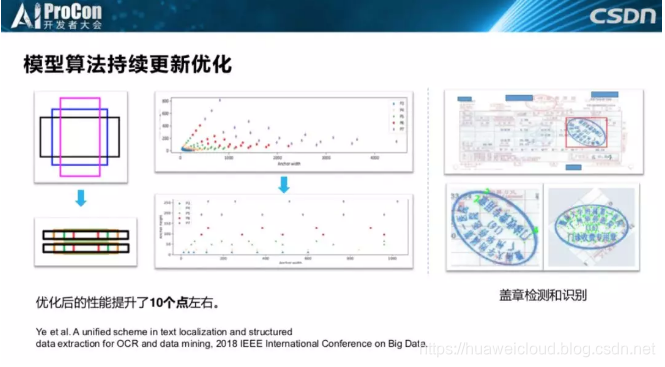
第二个是模型一定要持续优化,这是2018年发在IEEE上的一篇论文,我们做了类似Textbox的优化后,性能提升了10个点左右。右边的图也是我们实际遇到的场景,这是一个医疗的收费票据单,客户需要把盖章里面的文字识别出来,这个要求可能听起来比较奇葩,但是我们做产品的时候发现客户的需求总是多种多样的,很多需求你都想不到。里面的章也非常多样,除了椭圆章、圆章,还有方形章、三角形章等;同时票据的种类也非常多,大概有几千种。
我们开始尝试了非常多的弧形文字检测、不规则文字检测算法,实际的效果都没有那么好,后来加了一个单字符模块,最终的精度达到了96%以上,基本满足了客户的需求。
我要说的是做产品的时候,很多论文的性能非常好,但是当真正落地的时候遇到的情况和论文的差别非常大,这个时候就需要对模型进行持续的优化,如果不优化算法,要我们算法工程师做什么呢?算法工程师不优化算法,不如回家卖地瓜。

数据增强非常重要,在深度学习时代数据成为关键,对数据的需求量也大增。现实情况是数据总是有限的,如果我们标注数据的话首先耗时耗力,其次成本非常巨大,标一张图不同公司的收费是几毛到几块,成本非常大,合成数据基本成为文字检测和识别的必由之路,针对此种情况,我们内部自研了一套用于数据增强的算子库。
左边第一张图是SynthText,首先通过分割得到一些区域,计算景深,生成文字区域,中国有很大一部分公司在用这个算法进行合成数据。第二种办法是基于OpenCV、Pillow等一些传统方法合成整图的数据。我们也会用GAN进行切片风格转移,这两张放出来的图片效果不错,但实际情况是很多生成的图片基本不可用,你永远不知道算法会让你得到什么。这就涉及了深度学习的另一个问题,因为不可解释,你永远不知道你会得到什么。
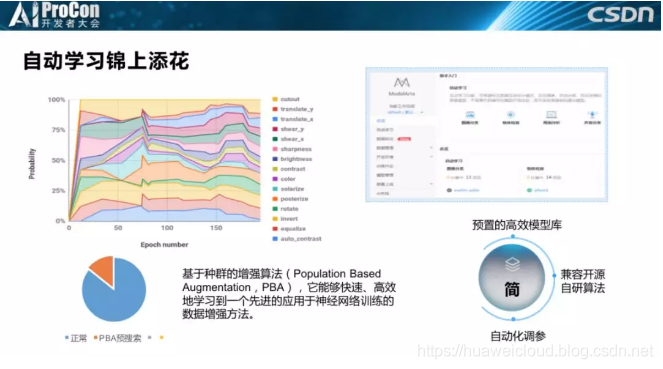
自动化学习锦上添花,也是我们实际中会用到的东西。比如基于种群的增强算法PBA,能够快速高效的学到一个先进的应用于神经网络训练的数据增强方法,大家可以看一下这张图,这是随着训练的迭代得到的不同的图片增强参数。有些场景我们训练如果需要3天的话用这种方法优化后可能减到0.5天,但并不是每个模型都能这样,因为实际情况是多种多样的,在有些算法上它可以辅助提高性能,但在另一些算法上则基本没有效果。
右边是基于NAS的搜索,我们的实现是基于ModelArts自动学习平台,同时也有海外的研究所帮我们专门做模型压缩、剪枝。我们的工程师则负责从算法自研到上线等所有的工作。
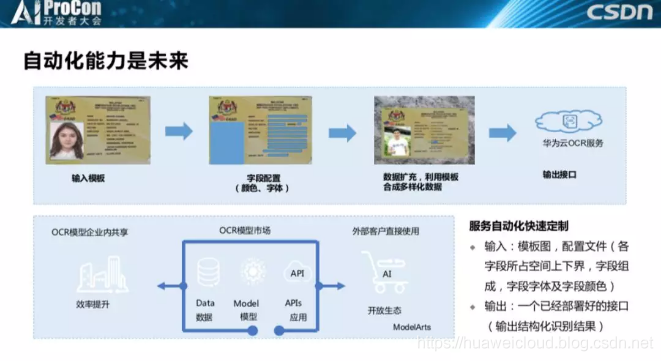
自动化能力是未来。现在人工智能基本都是定制化的,前面各个老师的讲座内容很多都是基于特定场景的,所以我们一定要做到自动化。现在人工智能界有句话叫做有多少人工就有多少智能,现在的人工智能是费时费力的,自动化成了必需。首先我们会输入一部分图片生成模板,进行数据扩充,最后自动生成一个模型部署到线上。我们的模型也会开放在模型市场上,客户可以使用这些模型形成他们自己的服务,也可以利用这些模型来提供服务。
速度和性能需要同时兼顾,这也是我们的一个实际案例,视频OCR就是从视频中识别文字。这是我们识别的几个图。我们做的时候会基于视频帧的前后联系来提高精度。但是这里就有一个问题了,日常情况下视频是1秒25帧,如果视频是高清度的话帧率会更高。一般情况下是我们的服务会1秒识别一张,因为如果每帧都识别的话,准确率确实会提升,但我们的成本却相应的提高了25倍,这是所有的公司都不可能承受的。所以我们做产品的时候一定要平衡性能和速度,在性能好的同时一定要考虑速度,速度意味着成本,不考虑成本的产品是没有意义的。
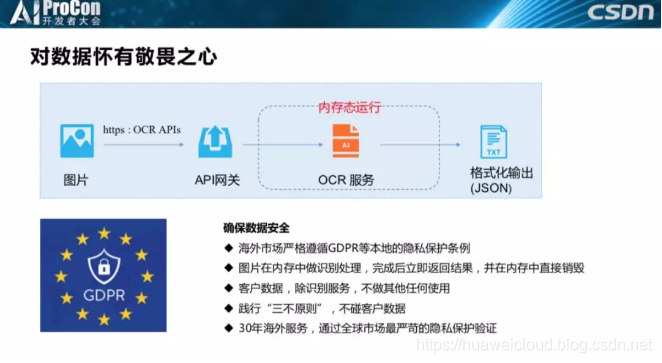
下一个我特别要讲的是一定要对数据怀有敬畏之心。现在做人工智能的时候其实需要大量的数据,很多公司对数据往往都非常饥渴,这个时候有些公司就会应用一些比较巧的手段获得数据,但是我要说的是我们一定要对数据怀有敬畏之心,数据非常珍贵,我们一定要取之有道。最近就有些公司因为不合理的采用爬虫爬取数据被公安机关审查了。
我们在海外市场一定会严格遵循GDPR等本地的隐私保护条例,这个也是华为30年海外服务积累下的经验和教训,如果我们不遵循这一条会对我们的声誉和经济造成不可估量的损失,甚至可能产生严重的政治事件。不只是国外,中国对数据隐私也越来越重视,近年出台了很多的法律法规。我们原来做PAAS服务的时候客户是欧洲的法国电信、德国电信,如果出现一点点数据隐私的问题都是影响非常大的。还有一个例子,比如说5G,因为中美贸易战,现在华为就在反复在向全世界证明我们是安全的,是非常尊重客户隐私的。
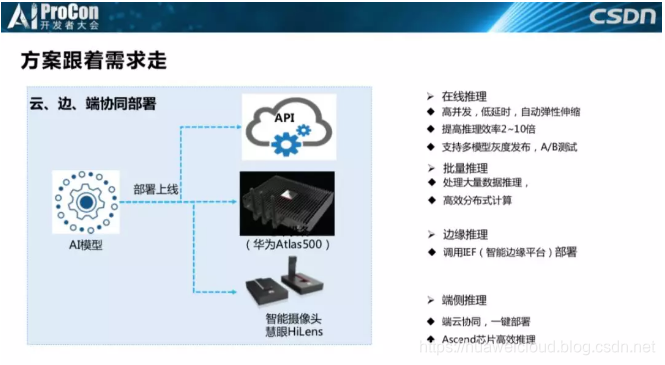
方案跟着需求走。我们现在的部署方式是云边端协同部署。最开始的方案是部署在云侧,我们觉得我们做的是云上服务,客户当然需要通过API服务调用了。后来我们接触的客户越来越多,发现很多金融、医疗、保险的客户虽然觉得我们会遵循数据保护条例,不会偷偷窃取他们的数据,但是他们依然不愿意把数据传出他们的网络。
所以后来我们的方案就变得越来越灵活,我们会在端侧部署一些包括智能摄像头在内的小盒子,在边侧部署Atlas服务器等满足不同的客户需求。这也是做产品的必需要注意的,客户才是上帝,在产品中工程师要为上帝服务。基于客户需求调整业务模式,也是产品成功的关键之一。
文字识别应用场景及典型落地方案
最后一部分是应用场景及落地方案。现在人工智能非常火,但能落地的场景不是那么多,能够大规模商用并产生经济价值的更不是那么多,但是我们的应用场景现在已经非常成熟了。应用场景包含并不限于物流与制造业、金融保险、医疗教育、政务政法、互联网,基本所有有文字的地方都需要OCR服务。
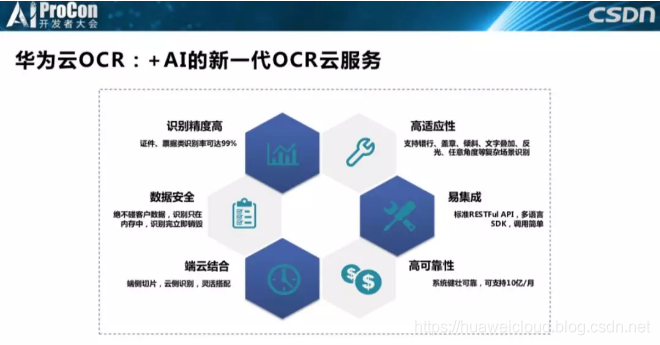
我们的识别精度非常高,证件、票据类识别率基本能达99%以上,当然个别场景例外。数据安全、端云协同前面已经提到了,还有高适应性,支持错行、盖章、倾斜、文字叠加、反光、任意角度等复杂场景识别能力。同时提供多种易用的SDK,易集成非常重要,你可以说我的产品非常好非常优秀,但是很多时候客户更关心的是它好不好用。你的产品再好,不好用,消费者也是不认可的。最后一个是高可靠,基本可以支持每月10亿级的调用。
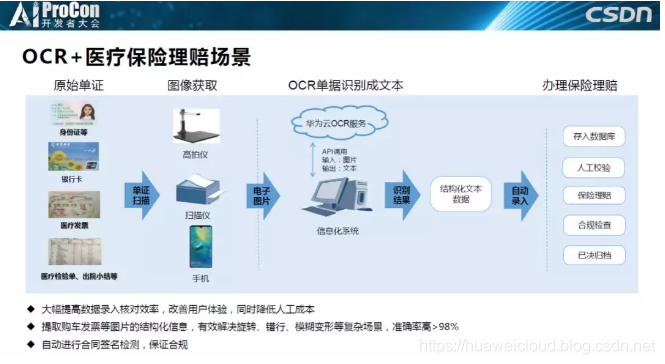
医学理赔是非常典型的应用场景。首先客户会把他们客户的身份证、银行卡、医疗发票、医疗检验单通过扫描转化成数字信息并调用云上的OCR服务,服务会返回一个结构化的json数据。客户收到json之后会传到数据库进行人工校验。其实很多时候,人工智能并不能达到100%的识别率,也不能取代人工,但是它依然有非常多的价值,能减少人的重复性劳动,提高效率,这本身就足够了。

下面是一个实际案例,客户要识别一些检验单,因为票据种类非常多,正常情况下医生和护士需要一张张的人工识别。现在我们可以支持上千家医院检验单的识别录入,能有效处理拍照不规范、上下左右翻转。大家可以听到我在反复强调我们可以支持上下左右翻转识别,做产品不同于做研究,我们希望模型越简单、运行步骤越少越好,模型太多了看护不过来。
比如我们团队有1/3以上的博士,每个人最多只能看护一个模型,实际情况非常复杂,大家手上的事情非常多,根本看护不过来太多的模型,所以一个非常重要的工作就是需要找到一个模型,不说包打天下,但它结合其他一两个模型需要能做到基本包打天下,模型太多了基本就没法用。

互联网电商实现的落地的场景包括淘宝京东等电商截图、手机截图、QQ、微信聊天对话、广告设计宣传图/海报等的识别。很多互联网公司有一个非常庞大的团队叫审核团队,比如字节跳动,审核团队就有几千人,他们要干的事情就是要确保用户发布的图片或文字是符合国家规定的,不然的话就有非常大的公关事件。
今年上半年我们的邻国领导人来访问就要求把所有互联网上关于他的戏谑称呼都删掉,现在大家可以baidu一下这位邻居领导人的称呼,基本再也找不到了。很多东西看着没有价值,但是实际价值是非常大的。还有一个场景,大家都寄快递,当我们截取一张地址图片传上去后,快递公司会自动把手机号、地址等填到快递单上去,背后用到的技术就是类似的技术。
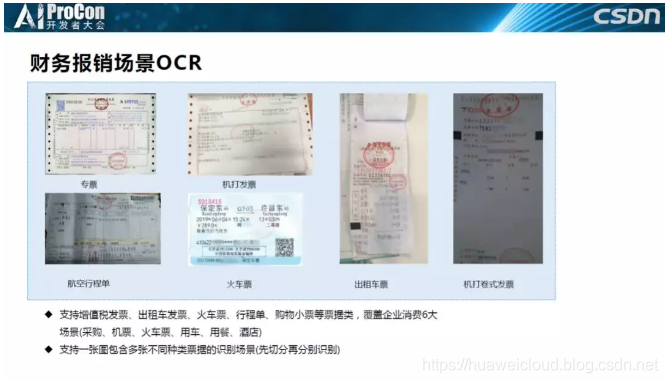
这个是财务报销场景,相信在座的很多人过来都是公费出差的。我们回去要把出租车票、火车票、航空票、酒店发票通通贴到一张纸上交给财务,财务看了说没问题就给我们报销了,如果有问题打回来重新填,其实用到的就是类似的一个场景。
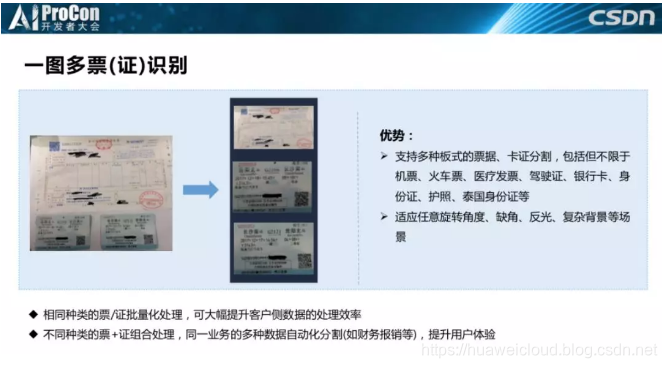
报销时大家会把很多票贴到一张纸上,我们的OCR服务会把每张票切割出来一张张识别最后返回结果,这个场景看着非常low,远远没有其他场景听着那么高大上,但是它非常有用,需求量非常大,很多客户都在咨询这个业务。
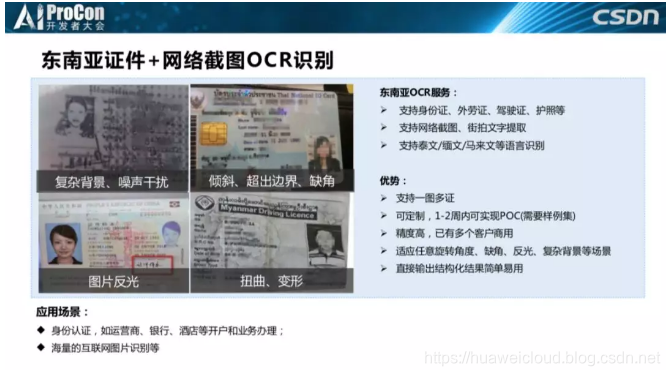
最后一个案例是海外案例。左上角这个图是缅甸的身份证,世界上有很多国家并没有我大中华这么先进,他们的身份证没有芯片,有的上面的字甚至是手写上去的,所以他们就需要把这些字自动化识别出来。
在缅甸,很多人需要经常要拿着这种身份证办各种业务,相关的服务需求量非常大。后来我们缅甸的客户经理找了很多当地的大学生给我们标注相关数据,标了之后我们把缅文OCR服务给孵化了出来。现在缅甸很多公司都在用这个服务。后面是泰国身份证、缅甸驾驶照、马来身份证等等,我们也在给阿拉伯国家做相应的阿拉伯文OCR服务,这些都是海外的文字识别的需求案例。
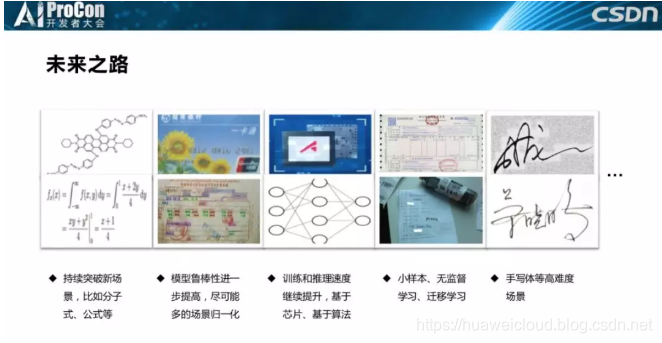
最后说一下未来之路,不只是OCR产品,我相信所有人工智能产品或其他数据为驱动的产品都需要走这条路。
首先是我们需要持续突破新场景,比如识别分子式,分子式千奇百怪,我们的工作是给客户把分子式符号转换为路易斯结构式;再比如说识别公式。第二是模型的鲁棒性进一步提高,比如我们希望把证件类和票据类的API归一,很多公司都希望用一个模型包打天下,省时省力。第三是训练和推理速度要持续优化,因为训练速度的提高意味着产品更快的迭代,而推理速度的提高意味着成本更可控。有的公司口号非常响,但挣钱就是另一回事了,做产品一定要考虑性能和收益。第四是小样本学习、无监督学习、迁移学习,很多时候客户给你的数据是非常少的,给你一两张图片就希望你给他一个服务,而且希望98%以上的精度。
最后一个是领域结合的人工智能,我们团队好几个博士在突破手写签名场景,到现在为止依然没有解决的特别好,手写签名识别需求量非常大,很多银行都要用这个东西。包括现在非常火的多模态识别依然解决不了这个问题,所以后面需要结合一些行业知识来提高精度。其实不只是OCR,人工智能的各个方向基本都这样,未来的人工智能一定是结合了行业知识的人工智能,这样才能真正的解决客户场景。
来源:AI科技大本营
智能推荐
已知num为无符号十进制整数,请写一非递归算法,该算法输出num对应的r进制的各位数字。要求算法中用到的栈采用线性链表存储结构(1<r<10)。-程序员宅基地
文章浏览阅读74次。思路:num%r得到末位r进制数,num/r得到num去掉末位r进制数后的数字。得到的末位r进制数采用头插法插入链表中,更新num的值,循环计算,直到num为0,最后输出链表。//重置,s指针与头指针指向同一处。//更新num的值,至num为0退出循环。//末位r进制数存入s数据域中。//头插法插入链表中(无头结点)//定义头指针为空,s指针。= NULL) //s不为空,输出链表,栈先入后出。
开始报名!CW32开发者扶持计划正式进行,将助力中国的大学教育及人才培养_cw32开发者扶持计划申请-程序员宅基地
文章浏览阅读176次。武汉芯源半导体积极参与推动中国的大学教育改革以及注重电子行业的人才培养,建立以企业为主体、市场为导向、产学研深度融合的技术创新体系。2023年3月,武汉芯源半导体开发者扶持计划正式开始进行,以打造更为丰富的CW32生态社区。_cw32开发者扶持计划申请
希捷硬盘开机不识别,进入系统后自动扫描硬件以识别显示_st2000dm001不认盘-程序员宅基地
文章浏览阅读5.7k次。2014年底买的一块2TB希捷机械硬盘ST2000DM001-1ER164,用了两年更换了主板、CPU等,后来出现开机不识别的情况,具体表现为:关机后开机,找不到硬盘,就进入BIOS了,只要在BIOS状态下待机半分钟左右再重启,硬盘就会出现。进入系统后,重启(这个过程中主板对硬盘始终处于供电状态),也不会出现不识别硬盘的现象。就好像是硬盘或主板上某个电容坏了一样,刚开始给硬盘通电的N秒钟内电容未能..._st2000dm001不认盘
ADO.NET包含主要对象以及其作用-程序员宅基地
文章浏览阅读1.5k次。ADO.NET的数据源不单单是DB,也可以是XML、ExcelADO.NET连接数据源有两种交互模式:连接模式和断开模式两个对应的组件:数据提供程序(数据提供者)&DataSetSqlConnectionStringBuilder——连接字符串Connection对象用于开启程序和数据库之间的连接public SqlConnection c..._列举ado.net在操作数据库时,常用的对象及作用
Android 自定义对话框不能铺满全屏_android dialog宽度不铺满-程序员宅基地
文章浏览阅读113次。【代码】Android 自定义对话框不能铺满全屏。_android dialog宽度不铺满
Redis的主从集群与哨兵模式_redis的主从和哨兵集群-程序员宅基地
文章浏览阅读331次。Redis的主从集群与哨兵模式Redis的主从模式全量同步增量同步Redis主从同步策略流程redis主从部署环境哨兵模式原理哨兵模式概述哨兵模式的作用哨兵模式项目部署Redis的主从模式1、Redis虽然读取写入的速度都特别快,但是也会产生读压力特别大的情况。2、为了分担读压力,Redis支持主从复制,保证主数据库的数据内容和从数据库的内容完全一致。3、Redis的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。全量同步Redis全量复制一般发_redis的主从和哨兵集群
随便推点
mysql utf-8的作用_为什么不建议在MySQL中使用UTF-8-程序员宅基地
文章浏览阅读116次。作者:brightwang原文:https://www.jianshu.com/p/ab9aa8d4df7d最近我遇到了一个bug,我试着通过Rails在以“utf8”编码的MariaDB中保存一个UTF-8字符串,然后出现了一个离奇的错误:Incorrect string value: ‘ð 我用的是UTF-8编码的客户端,服务器也是UTF-8编码的,数据库也是,就连要保存的这个字符串“????..._mysql utf8的作用
MATLAB中对多张图片进行对比画图操作(包括RGB直方图、高斯+USM锐化后的图、HSV空间分量图及均衡化后的图)_matlab图像比较-程序员宅基地
文章浏览阅读278次。毕业这么久了,最近闲来准备把毕设过程中的代码整理公开一下,所有代码其实都是网上找的,但都是经过调试能跑通的,希望对需要的人有用。PS:里边很多注释不讲什么意思了,能看懂的自然能看懂。_matlab图像比较
16.libgdx根据配置文件生成布局(未完)-程序员宅基地
文章浏览阅读73次。思路: screen分为普通和复杂两种,普通的功能大部分是页面跳转以及简单的crud数据,复杂的单独弄出来 跳转普通的screen,直接根据配置文件调整设置<layouts> <loyout screenId="0" bg="bg_start" name="start" defaultWinId="" bgm="" remark=""> ..._libgdx ui 布局
playwright-python 处理Text input、Checkboxs 和 radio buttons(三)_playwright checkbox-程序员宅基地
文章浏览阅读3k次,点赞2次,收藏13次。playwright-python 处理Text input和Checkboxs 和 radio buttonsText input输入框输入元素,直接用fill方法即可,支持 ,,[contenteditable] 和<label>这些标签,如下代码:page.fill('#name', 'Peter');# 日期输入page.fill('#date', '2020-02-02')# 时间输入page.fill('#time', '13-15')# 本地日期时间输入p_playwright checkbox
windows10使用Cygwin64安装PHP Swoole扩展_win10 php 安装swoole-程序员宅基地
文章浏览阅读596次,点赞5次,收藏6次。这是我看到最最详细的安装说明文章了,必须要给赞!学习了,也配置了,成功的一批!真不知道还有什么可补充的了,在此做个推广,喜欢的小伙伴,走起!_win10 php 安装swoole
angular2里引入flexible.js(rem的布局)_angular 使用rem-程序员宅基地
文章浏览阅读1k次。今天想实现页面的自适应,本来用的是栅格,但效果不理想,就想起了rem布局。以前使用rem布局,都是在原生html里,还没在框架里使用过,百度没百度出来,就自己琢磨,不知道方法规范不规范,反正成功了,操作如下:1、下载flexible.js2、引入到angular项目里3、根据自己的需要修改细节3.1、在flexible.js里修改每份的像素,3.2、引入cssrem插件,在设置里设..._angular 使用rem