使用爬虫爬取各类新闻文本(从野生自编程到scrapy 爬虫框架)_谷歌新闻数量 爬虫-程序员宅基地
前言: 从国外新闻网站卫报 <the Guardian>上爬取各类新闻文本,构建文本分类训练的数据集。这次爬取内容较多,且包含两次爬取:先从主网站爬取文章对应的URL,然后再根据获取的URL爬取其对应的文本内容 。
按照以往单线程爬取,每类型新闻爬取数量预计 >2000 篇,效率十分低,慢到崩溃。野生自编使用多线程处理。代码惨不忍睹,便重拾 scrapy 爬虫框架,发现思路跟自编爬虫思路差不多。
1. 野生自编程
- 网页分析 <the Guardian>
最初考虑爬取谷歌新闻,但分析网页后发现,谷歌新闻都是爬取其他新闻网站的内容。因此会有一个问题,即从谷歌新闻上获取文章Url后,会引导到不同的新闻网站,但不同网站会有不同网页代码结构。
最后考虑用卫报。
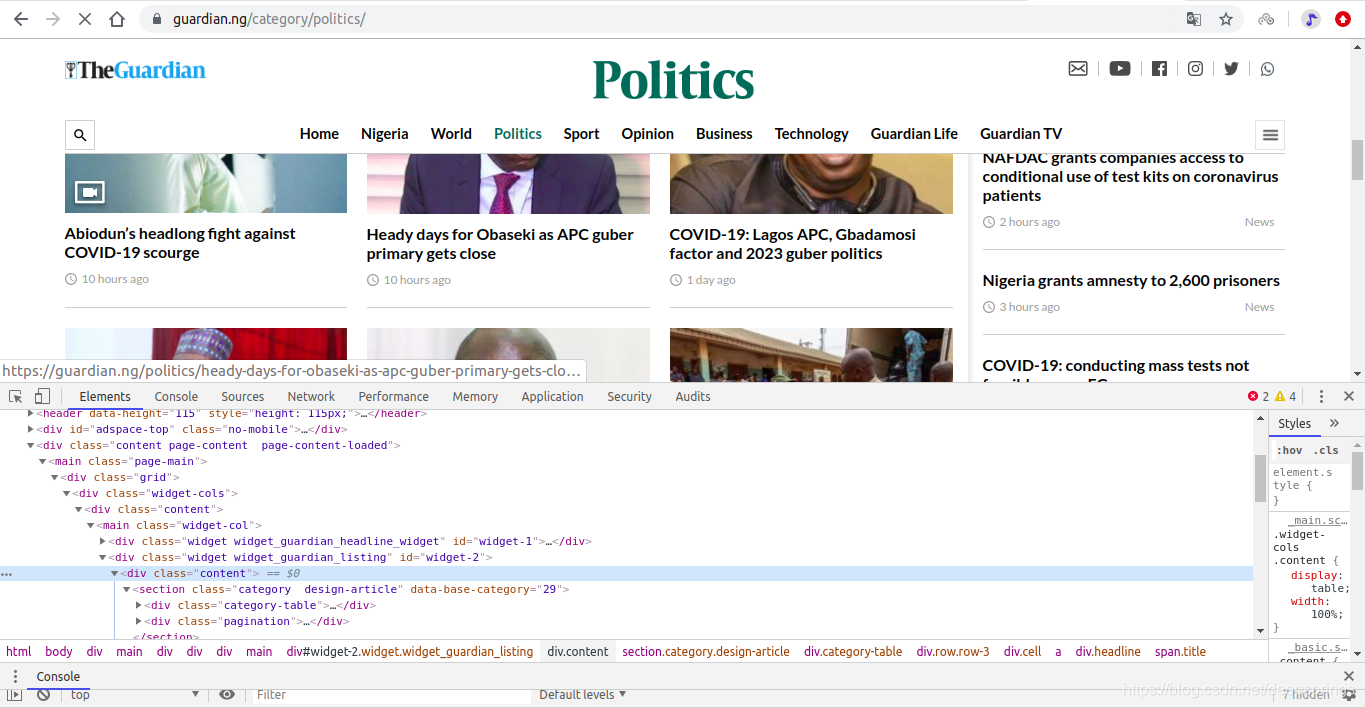
比较让人欣喜的一点时,网站没有使用动态加载方式,因此不需要抓包分析网址加载过程中传输的动态数据,而且网页代码层次十分分明,预定使用 beautifulsoup 进行网页解析分析。
- 极其不严谨和规范的编程实现
import requests as rt
import threading as td
import os
import time
from bs4 import BeautifulSoup
class googleNews():
def __init__(self):
self.initialize()
# 一些预设,对防防扒的一些尊重0.0
self.agent = 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36'
self.header = {
'user-agent': self.agent,
'referer': 'https://guardian.ng/'
}
# 初始化,在运行目录下,生成theGuardianNews文件夹,保存获取的各类别文章
def initialize(self):
try:
os.mkdir('./theGuardianNews/')
except:
pass
# 从主网站获取文章地址url池,并保存到txt文件中(减少内存占用,相当于临时文件,后面会再删除)
def getUrl(self, url):
resp = rt.get(url, headers = self.header)
soup = BeautifulSoup(resp.content, 'html.parser')
content = soup.body.main.find_all(class_ = 'cell')
pUrl = []
for item in content:
pUrl.append(item.a.get('href'))
print('getUrlNum:', len(pUrl))
return pUrl
# 爬取url对应网页文章内容,并分类保存
def write(self, url):
r = rt.get(url, headers = self.header, timeout = 5)
bs = BeautifulSoup(r.content, 'html.parser')
category = bs.body.find(class_ = 'category-header').a.string # 所属类别
title = bs.body.find(class_ = 'after-category').string # 文章标题
article = bs.main.article.find_all('p') # 文章
contentList = []
for a in article:
if(a.string!= None and a.string != '\xa0'):
contentList.append(a.string)
content = '\n'.join(contentList)
# 将获取的内容保存到当前目录下的 ./theGuardianNews/[Category] 下
urlSplit = [x for x in url.split('/') if x != '']
base_path = os.getcwd()
filename = urlSplit[-1]
if(not os.path.exists('theGuardianNews/%s'% category)):
os.mkdir('./theGuardianNews/%s'% category)
save_path = os.path.join(base_path, 'theGuardianNews', category, filename)
with open(save_path, 'w+') as f:
f.write(title)
f.write('\n')
f.write(content)
print(category,'(write): ', title)
# 线程函数,多线程获取
def batchGet(self, index, down, up):
# 新闻不同类别对应网址
categoryDict = {
'world/Africa': 'https://guardian.ng/category/news/world/africa/',
'world/Asia': 'https://guardian.ng/category/news/world/asia/',
'world/Europe': 'https://guardian.ng/category/news/world/europe/',
'world/US': 'https://guardian.ng/category/news/world/us/',
'politics': 'https://guardian.ng/category/politics/',
'sport/football': 'https://guardian.ng/category/sport/football/',
'sport/boxing': 'https://guardian.ng/category/sport/boxing/',
'sport/athletics': 'https://guardian.ng/category/sport/athletics/',
'sport/tennis': 'https://guardian.ng/category/sport/tennis/',
'sport/other': 'https://guardian.ng/category/sport/other/',
'opinion': 'https://guardian.ng/category/opinion/',
'business': 'https://guardian.ng/category/business-services/business/',
'technology': 'https://guardian.ng/category/technology/c55-technology/',
'features/health': 'https://guardian.ng/category/features/health/',
'features/education': 'https://guardian.ng/category/features/education/'
}
dic = {
}
if (index == -1):
dic = categoryDict
else:
dic[index] = categoryDict[index]
for category in dic:
url = dic[category]
for num in range(down, up):
url1 = os.path.join(url, 'page', str(num))
try:
url2 = self.getUrl(url1)
for u in url2:
self.write(u)
except:
continue
# go! go! go!
def go(self):
#t1 = td.Thread(target = self.batchGet, args = (0))
#t2 = td.Thread(target = self.batchGet, args = (1))
# 新闻类别和网址页数范围
t3 = td.Thread(target = self.batchGet, args = ('features/education',1,200,))
t4 = td.Thread(target = self.batchGet, args = ('features/health',1,200,))
t5 = td.Thread(target = self.batchGet, args = ('business',100,200,))
t6 = td.Thread(target = self.batchGet, args = ('technology',100,200,))
#t1.start()
#t2.start()
t3.start()
t4.start()
t5.start()
t6.start()
if __name__ == '__main__':
News = googleNews()
News.go()
-
结果(部分数据)
./theGuardianNews/:
-
心得
-
卫报官网对于爬虫的限制好像几乎没有,可能这是网站属性决定的,新闻就是用于爬虫爬取传播的。因此其实不用设置网站请求间隔,ip代理池等措施。
-
真正编程实现时,分析网址url规律的时候才发现,卫报官网新闻分类类别异常的多,并非显示的那些,而且大类里面包含小类。沿用了起初使用字典的方式存储不同类别时的起始url。
-
最初预想是分两步爬取,即爬取文章url,然后进入文章url爬取具体文章信息。如果使用单线程,按步骤执行,会出现问题。
一是因为爬取文章较多,效率奇慢;二是因为先获取url,需要保存url供后面用(全存在一个字典里,太占内存了,一旦第一步失败或断网,就需要从头再来)。针对一,使用多线程可以解决,同时进行两步的爬取;针对二,将第一步获取的url保存起来,数据量还行,自己就直接保存为 txt ,也可使用数据库mysql存储。<编程完成后,想到可以合并,泪目>
还有种方法是,两步的爬取,可以归到一起,即在主网站获取到文章url后就访问,获取文章内容。
-
多线程写的忒随意了,惨不忍睹,让代码规范些,想到了scrapy框架。框架也是主要包含上述几个步骤:网址请求,(中间文件存储,对应最初分两步的方法),内容获取/处理,文本保存等。
-
2. scrapy爬虫框架使用
-
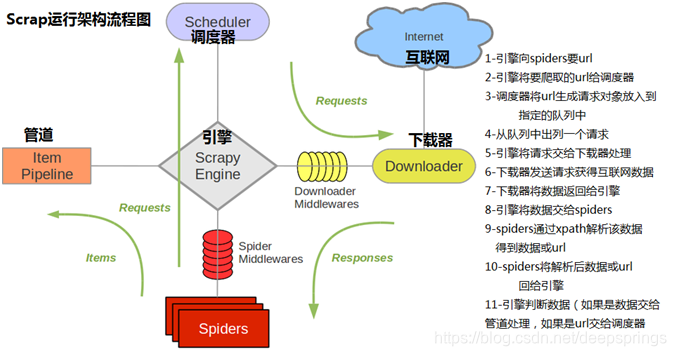
框架流程
-
实际应用
主要包含以下文件:
|—spider
|—spider
|—__init__.py
|— items.py 需要提取的数据,对应本例就是文本
|— middlewares.py 对网页的请求和响应
|— pipelines.py 对item中提取的数据进行处理,对应本例就是保存
|— __pycache__
|— settings.py 项目的配置文件
|— spiders 放置自己的爬虫代码
这框架跟 django 的配置过程挺像的。
复习 __init__.py和__pycache__的用处和Python编译执行原理和过程。本例具体代码,用scrapy框架实现起来不复杂。
智能推荐
解决Ubuntu下nvcc版本与CUDA版本不对应问题_linux安装了cuda,但是nvcc -v没有这个命令apt install nvidia-cud-程序员宅基地
文章浏览阅读9.5k次。最近在linux上安装了CUDA 8.0,但是在安装pycuda时却提示找不到nvcc命令。在terminal中输入nvcc,也是提示找不到command。但是可以确定的是,CUDA8.0,以及nvidia-cuda-toolkit已经从官方网站下载并正确安装。于是网上找了教程,说是需要在terminal中输入sudo apt-get install nvidia-cuda-toolkit安装..._linux安装了cuda,但是nvcc -v没有这个命令apt install nvidia-cuda-toolkit
win7和linux mint双系统安装总结_linux mint和win7双系统-程序员宅基地
文章浏览阅读2.9k次。先安装好win7,之后再安装好linux mint,安装好之后,再使用U盘的winPE,进行一下引导操作就可以了_linux mint和win7双系统
暑假总结_网络中心暑假总结-程序员宅基地
文章浏览阅读622次。暑假总结学到的新知识对几次考试的总结对这次暑假补课的看法学到的新知识对几次考试的总结对这次暑假补课的看法_网络中心暑假总结
ROS moveit 机械臂避障运动规划_moveit运动过程中规避干涉-程序员宅基地
文章浏览阅读6.6k次,点赞6次,收藏104次。机械臂moveit编程(python)moveit默认使用的运动规划库OMPL支持臂章规划,这里选用RRT算法,使用move group中的PlanningSceneInterface()添加障碍物,观察机械臂运动效果。程序流程:1.初始化需要控制的规划组,初始化场景;2.设置运动约束(可选);3.设置终端link;4.清理上一次运行的残留物体5.设置障碍物size和位姿,并使用sc..._moveit运动过程中规避干涉
java poi-tl处理world动态表格_dynamictablerenderpolicy+-程序员宅基地
文章浏览阅读1w次,点赞4次,收藏12次。简单的模板处理可以参考以下链接:https://blog.csdn.net/liushimiao0104/article/details/78520120我用的是一下版本 <dependency> <groupId>com.deepoove</groupId> <artifactId>poi-tl</..._dynamictablerenderpolicy+
【keras-DeepLearning_Models】_obtain_input_shape() got an unexpected keyword argument 'include_top'_shape为什么报错-程序员宅基地
文章浏览阅读1w次,点赞7次,收藏11次。最近想跑一些主流的网络感受感受。从github上找到了 deep-learning-models 提供的几个模型,包括:inception-v2, inception-v3, resnet50, vgg16, vgg19 等等。这些代码都是基于 keras 框架,正好我最近有在学 tensorflow 和 keras,所以很想跑跑这些代码。心动不如行动,准备工作都做得差不多了,准备开始跑代码。此时,出现了一些常见的问题,也正好借此机会整理下来。_shape为什么报错
随便推点
Flutter GridView网格布局_flutter布局grid-程序员宅基地
文章浏览阅读3.1k次,点赞2次,收藏3次。目录参数详解代码示例特别说明效果图完整代码在这里介绍两种实现网格布局方法:1、通过 GridView.count 实现网格布局2、通过 GridView.builder 实现网格布局参数详解属性 说明 scrollDirection 滚动方向 reverse 组件反向排序 controller 滚动控制(滚动监听) pri..._flutter布局grid
stm32 UART接收方式_stm32串口 判断 接收 接收 数组-程序员宅基地
文章浏览阅读1.3k次。1. 直接接收在主函数 main 中操作/** * @brief The application entry point. * @retval int */int main(void){ /* USER CODE BEGIN 1 */ unsigned char uRx_Data = 0; /* USER CODE END 1 */ /* MCU Configuration----------------------------------------.._stm32串口 判断 接收 接收 数组
【Spring MVC】Spring MVC启动过程源码分析_springmvc启动过程-程序员宅基地
文章浏览阅读4k次,点赞3次,收藏19次。Spring MVC启动时,Spring容器和Spring MVC组件的启动过程源码分析_springmvc启动过程
python如何删除代码_科学网—我的第一个Python程序——删除代码前行号的小工具 - 闫小勇的博文...-程序员宅基地
文章浏览阅读892次。(根据我在博客园上连载的四篇文章整理,见http://yanxy.cnblogs.com,转载请注明出处)近两天内的目标是在我博的每个栏目发一篇文章,先都占个坑再说,空着不好看:) 《程序设计》这个栏目里,就从我刚开始学的Python开始吧。一、引言Python是一种简单却又强大的语言,我觉得它很适合非专业程序员(特别是科研人员)使用。比如作一些科学计算、数据处理工作等,Python简单的语法和丰..._python怎么删除前面的代码
LeetCode 311. Sparse Matrix Multiplication(稀疏矩阵相乘)_leetcode sparsematrixmultiplication-程序员宅基地
文章浏览阅读2.8k次。原题网址:https://leetcode.com/problems/sparse-matrix-multiplication/Given two sparse matrices A and B, return the result of AB.You may assume that A's column number is equal to B's row number._leetcode sparsematrixmultiplication
成功解决numpy.core._internal.AxisError: axis -1 is out of bounds for array of dimension 0_numpy.axiserror: axis 1 is out of bounds for array-程序员宅基地
文章浏览阅读3.2w次,点赞4次,收藏16次。成功解决numpy.core._internal.AxisError: axis -1 is out of bounds for array of dimension 0目录解决问题解决思路解决方法解决问题numpy.core._internal.AxisError: axis -1 is out of bounds f..._numpy.axiserror: axis 1 is out of bounds for array of dimension 0