【精选】金属工件表面缺陷图像分割系统:DLA34骨干网络改进YOLOv5-程序员宅基地
1.研究背景与意义
随着工业化的发展,金属工件在制造过程中常常会出现各种表面缺陷,如裂纹、脏污、划痕等。这些缺陷不仅会影响产品的质量和性能,还可能导致安全隐患和经济损失。因此,对金属工件表面缺陷进行准确、高效的检测和分割具有重要的意义。
传统的金属工件表面缺陷检测方法主要依赖于人工目视检查,这种方法存在主观性强、效率低、易出错等问题。而基于计算机视觉和深度学习的自动化缺陷检测方法可以有效地解决这些问题。其中,图像分割是一种重要的技术手段,可以将图像中的目标与背景进行精确的分离,从而实现对缺陷的准确定位和识别。
目前,深度学习技术在图像分割领域取得了显著的进展。YOLOv5是一种基于深度学习的目标检测算法,具有高效、准确的特点。然而,由于YOLOv5网络结构的限制,其在金属工件表面缺陷图像分割任务中存在一些挑战,如缺乏对小尺寸缺陷的有效检测和分割能力。
为了解决这些问题,本研究将DLA34骨干网络引入到YOLOv5中,以改进金属工件表面缺陷图像分割系统。DLA34是一种轻量级的网络结构,具有较强的特征提取和表示能力。通过将DLA34与YOLOv5相结合,可以充分利用DLA34的优势,提高系统对小尺寸缺陷的检测和分割性能。
本研究的意义主要体现在以下几个方面:
首先,基于DLA34骨干网络改进的YOLOv5金属工件表面缺陷图像分割系统可以提高缺陷检测和分割的准确性和效率。通过引入DLA34网络,可以更好地捕捉图像中的细节信息,提高对小尺寸缺陷的检测和分割能力,从而减少误检和漏检的情况。
其次,该系统可以实现金属工件表面缺陷的自动化检测和分割,减少人工目视检查的主观性和不确定性。自动化的缺陷检测系统可以大大提高生产效率,减少人力成本,并且可以在实时监控和大规模生产中广泛应用。
此外,本研究的方法还可以为其他领域的图像分割任务提供借鉴和参考。DLA34骨干网络的引入不仅可以改进YOLOv5在金属工件表面缺陷图像分割任务中的性能,还可以为其他基于YOLOv5的目标检测算法提供改进思路和方法。
综上所述,基于DLA34骨干网络改进YOLOv5的金属工件表面缺陷图像分割系统具有重要的研究意义和应用价值。通过提高缺陷检测和分割的准确性和效率,可以实现金属工件表面缺陷的自动化检测和分割,为工业生产提供可靠的质量控制手段。同时,该研究方法还可以为其他领域的图像分割任务提供借鉴和参考,推动深度学习技术在实际应用中的发展和应用。
2.图片演示



3.视频演示
基于DLA34骨干网络改进YOLOv5的金属工件表面缺陷图像分割系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集TrafficDatasets。
eiseg是一个图形化的图像注释工具,支持COCO和YOLO格式。以下是使用eiseg将图片标注为COCO格式的步骤:
(1)下载并安装eiseg。
(2)打开eiseg并选择“Open Dir”来选择你的图片目录。
(3)为你的目标对象设置标签名称。
(4)在图片上绘制矩形框,选择对应的标签。
(5)保存标注信息,这将在图片目录下生成一个与图片同名的JSON文件。
(6)重复此过程,直到所有的图片都标注完毕。
由于YOLO使用的是txt格式的标注,我们需要将VOC格式转换为YOLO格式。可以使用各种转换工具或脚本来实现。
下面是一个简单的方法是使用Python脚本,该脚本读取XML文件,然后将其转换为YOLO所需的txt格式。
import contextlib
import json
import cv2
import pandas as pd
from PIL import Image
from collections import defaultdict
from utils import *
# Convert INFOLKS JSON file into YOLO-format labels ----------------------------
def convert_infolks_json(name, files, img_path):
# Create folders
path = make_dirs()
# Import json
data = []
for file in glob.glob(files):
with open(file) as f:
jdata = json.load(f)
jdata['json_file'] = file
data.append(jdata)
# Write images and shapes
name = path + os.sep + name
file_id, file_name, wh, cat = [], [], [], []
for x in tqdm(data, desc='Files and Shapes'):
f = glob.glob(img_path + Path(x['json_file']).stem + '.*')[0]
file_name.append(f)
wh.append(exif_size(Image.open(f))) # (width, height)
cat.extend(a['classTitle'].lower() for a in x['output']['objects']) # categories
# filename
with open(name + '.txt', 'a') as file:
file.write('%s\n' % f)
# Write *.names file
names = sorted(np.unique(cat))
# names.pop(names.index('Missing product')) # remove
with open(name + '.names', 'a') as file:
[file.write('%s\n' % a) for a in names]
# Write labels file
for i, x in enumerate(tqdm(data, desc='Annotations')):
label_name = Path(file_name[i]).stem + '.txt'
with open(path + '/labels/' + label_name, 'a') as file:
for a in x['output']['objects']:
# if a['classTitle'] == 'Missing product':
# continue # skip
category_id = names.index(a['classTitle'].lower())
# The INFOLKS bounding box format is [x-min, y-min, x-max, y-max]
box = np.array(a['points']['exterior'], dtype=np.float32).ravel()
box[[0, 2]] /= wh[i][0] # normalize x by width
box[[1, 3]] /= wh[i][1] # normalize y by height
box = [box[[0, 2]].mean(), box[[1, 3]].mean(), box[2] - box[0], box[3] - box[1]] # xywh
if (box[2] > 0.) and (box[3] > 0.): # if w > 0 and h > 0
file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))
# Split data into train, test, and validate files
split_files(name, file_name)
write_data_data(name + '.data', nc=len(names))
print(f'Done. Output saved to {
os.getcwd() + os.sep + path}')
# Convert vott JSON file into YOLO-format labels -------------------------------
def convert_vott_json(name, files, img_path):
# Create folders
path = make_dirs()
name = path + os.sep + name
# Import json
data = []
for file in glob.glob(files):
with open(file) as f:
jdata = json.load(f)
jdata['json_file'] = file
data.append(jdata)
# Get all categories
file_name, wh, cat = [], [], []
for i, x in enumerate(tqdm(data, desc='Files and Shapes')):
with contextlib.suppress(Exception):
cat.extend(a['tags'][0] for a in x['regions']) # categories
# Write *.names file
names = sorted(pd.unique(cat))
with open(name + '.names', 'a') as file:
[file.write('%s\n' % a) for a in names]
# Write labels file
n1, n2 = 0, 0
missing_images = []
for i, x in enumerate(tqdm(data, desc='Annotations')):
f = glob.glob(img_path + x['asset']['name'] + '.jpg')
if len(f):
f = f[0]
file_name.append(f)
wh = exif_size(Image.open(f)) # (width, height)
n1 += 1
if (len(f) > 0) and (wh[0] > 0) and (wh[1] > 0):
n2 += 1
# append filename to list
with open(name + '.txt', 'a') as file:
file.write('%s\n' % f)
# write labelsfile
label_name = Path(f).stem + '.txt'
with open(path + '/labels/' + label_name, 'a') as file:
for a in x['regions']:
category_id = names.index(a['tags'][0])
# The INFOLKS bounding box format is [x-min, y-min, x-max, y-max]
box = a['boundingBox']
box = np.array([box['left'], box['top'], box['width'], box['height']]).ravel()
box[[0, 2]] /= wh[0] # normalize x by width
box[[1, 3]] /= wh[1] # normalize y by height
box = [box[0] + box[2] / 2, box[1] + box[3] / 2, box[2], box[3]] # xywh
if (box[2] > 0.) and (box[3] > 0.): # if w > 0 and h > 0
file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))
else:
missing_images.append(x['asset']['name'])
print('Attempted %g json imports, found %g images, imported %g annotations successfully' % (i, n1, n2))
if len(missing_images):
print('WARNING, missing images:', missing_images)
# Split data into train, test, and validate files
split_files(name, file_name)
print(f'Done. Output saved to {
os.getcwd() + os.sep + path}')
# Convert ath JSON file into YOLO-format labels --------------------------------
def convert_ath_json(json_dir): # dir contains json annotations and images
# Create folders
dir = make_dirs() # output directory
jsons = []
for dirpath, dirnames, filenames in os.walk(json_dir):
jsons.extend(
os.path.join(dirpath, filename)
for filename in [
f for f in filenames if f.lower().endswith('.json')
]
)
# Import json
n1, n2, n3 = 0, 0, 0
missing_images, file_name = [], []
for json_file in sorted(jsons):
with open(json_file) as f:
data = json.load(f)
# # Get classes
# try:
# classes = list(data['_via_attributes']['region']['class']['options'].values()) # classes
# except:
# classes = list(data['_via_attributes']['region']['Class']['options'].values()) # classes
# # Write *.names file
# names = pd.unique(classes) # preserves sort order
# with open(dir + 'data.names', 'w') as f:
# [f.write('%s\n' % a) for a in names]
# Write labels file
for x in tqdm(data['_via_img_metadata'].values(), desc=f'Processing {
json_file}'):
image_file = str(Path(json_file).parent / x['filename'])
f = glob.glob(image_file) # image file
if len(f):
f = f[0]
file_name.append(f)
wh = exif_size(Image.open(f)) # (width, height)
n1 += 1 # all images
if len(f) > 0 and wh[0] > 0 and wh[1] > 0:
label_file = dir + 'labels/' + Path(f).stem + '.txt'
nlabels = 0
try:
with open(label_file, 'a') as file: # write labelsfile
# try:
# category_id = int(a['region_attributes']['class'])
# except:
# category_id = int(a['region_attributes']['Class'])
category_id = 0 # single-class
for a in x['regions']:
# bounding box format is [x-min, y-min, x-max, y-max]
box = a['shape_attributes']
box = np.array([box['x'], box['y'], box['width'], box['height']],
dtype=np.float32).ravel()
box[[0, 2]] /= wh[0] # normalize x by width
box[[1, 3]] /= wh[1] # normalize y by height
box = [box[0] + box[2] / 2, box[1] + box[3] / 2, box[2],
box[3]] # xywh (left-top to center x-y)
if box[2] > 0. and box[3] > 0.: # if w > 0 and h > 0
file.write('%g %.6f %.6f %.6f %.6f\n' % (category_id, *box))
n3 += 1
nlabels += 1
if nlabels == 0: # remove non-labelled images from dataset
os.system(f'rm {
label_file}')
# print('no labels for %s' % f)
continue # next file
# write image
img_size = 4096 # resize to maximum
img = cv2.imread(f) # BGR
assert img is not None, 'Image Not Found ' + f
r = img_size / max(img.shape) # size ratio
if r < 1: # downsize if necessary
h, w, _ = img.shape
img = cv2.resize(img, (int(w * r), int(h * r)), interpolation=cv2.INTER_AREA)
ifile = dir + 'images/' + Path(f).name
if cv2.imwrite(ifile, img): # if success append image to list
with open(dir + 'data.txt', 'a') as file:
file.write('%s\n' % ifile)
n2 += 1 # correct images
except Exception:
os.system(f'rm {
label_file}')
print(f'problem with {
f}')
else:
missing_images.append(image_file)
nm = len(missing_images) # number missing
print('\nFound %g JSONs with %g labels over %g images. Found %g images, labelled %g images successfully' %
(len(jsons), n3, n1, n1 - nm, n2))
if len(missing_images):
print('WARNING, missing images:', missing_images)
# Write *.names file
names = ['knife'] # preserves sort order
with open(dir + 'data.names', 'w') as f:
[f.write('%s\n' % a) for a in names]
# Split data into train, test, and validate files
split_rows_simple(dir + 'data.txt')
write_data_data(dir + 'data.data', nc=1)
print(f'Done. Output saved to {
Path(dir).absolute()}')
def convert_coco_json(json_dir='../coco/annotations/', use_segments=False, cls91to80=False):
save_dir = make_dirs() # output directory
coco80 = coco91_to_coco80_class()
# Import json
for json_file in sorted(Path(json_dir).resolve().glob('*.json')):
fn = Path(save_dir) / 'labels' / json_file.stem.replace('instances_', '') # folder name
fn.mkdir()
with open(json_file) as f:
data = json.load(f)
# Create image dict
images = {
'%g' % x['id']: x for x in data['images']}
# Create image-annotations dict
imgToAnns = defaultdict(list)
for ann in data['annotations']:
imgToAnns[ann['image_id']].append(ann)
# Write labels file
for img_id, anns in tqdm(imgToAnns.items(), desc=f'Annotations {
json_file}'):
img = images['%g' % img_id]
h, w, f = img['height'], img['width'], img['file_name']
bboxes = []
segments = []
for ann in anns:
if ann['iscrowd']:
continue
# The COCO box format is [top left x, top left y, width, height]
box = np.array(ann['bbox'], dtype=np.float64)
box[:2] += box[2:] / 2 # xy top-left corner to center
box[[0, 2]] /= w # normalize x
box[[1, 3]] /= h # normalize y
if box[2] <= 0 or box[3] <= 0: # if w <= 0 and h <= 0
continue
cls = coco80[ann['category_id'] - 1] if cls91to80 else ann['category_id'] - 1 # class
box = [cls] + box.tolist()
if box not in bboxes:
bboxes.append(box)
# Segments
if use_segments:
if len(ann['segmentation']) > 1:
s = merge_multi_segment(ann['segmentation'])
s = (np.concatenate(s, axis=0) / np.array([w, h])).reshape(-1).tolist()
else:
s = [j for i in ann['segmentation'] for j in i] # all segments concatenated
s = (np.array(s).reshape(-1, 2) / np.array([w, h])).reshape(-1).tolist()
s = [cls] + s
if s not in segments:
segments.append(s)
# Write
with open((fn / f).with_suffix('.txt'), 'a') as file:
for i in range(len(bboxes)):
line = *(segments[i] if use_segments else bboxes[i]), # cls, box or segments
file.write(('%g ' * len(line)).rstrip() % line + '\n')
def min_index(arr1, arr2):
"""Find a pair of indexes with the shortest distance.
Args:
arr1: (N, 2).
arr2: (M, 2).
Return:
a pair of indexes(tuple).
"""
dis = ((arr1[:, None, :] - arr2[None, :, :]) ** 2).sum(-1)
return np.unravel_index(np.argmin(dis, axis=None), dis.shape)
def merge_multi_segment(segments):
"""Merge multi segments to one list.
Find the coordinates with min distance between each segment,
then connect these coordinates with one thin line to merge all
segments into one.
Args:
segments(List(List)): original segmentations in coco's json file.
like [segmentation1, segmentation2,...],
each segmentation is a list of coordinates.
"""
s = []
segments = [np.array(i).reshape(-1, 2) for i in segments]
idx_list = [[] for _ in range(len(segments))]
# record the indexes with min distance between each segment
for i in range(1, len(segments)):
idx1, idx2 = min_index(segments[i - 1], segments[i])
idx_list[i - 1].append(idx1)
idx_list[i].append(idx2)
# use two round to connect all the segments
for k in range(2):
# forward connection
if k == 0:
for i, idx in enumerate(idx_list):
# middle segments have two indexes
# reverse the index of middle segments
if len(idx) == 2 and idx[0] > idx[1]:
idx = idx[::-1]
segments[i] = segments[i][::-1, :]
segments[i] = np.roll(segments[i], -idx[0], axis=0)
segments[i] = np.concatenate([segments[i], segments[i][:1]])
# deal with the first segment and the last one
if i in [0, len(idx_list) - 1]:
s.append(segments[i])
else:
idx = [0, idx[1] - idx[0]]
s.append(segments[i][idx[0]:idx[1] + 1])
else:
for i in range(len(idx_list) - 1, -1, -1):
if i not in [0, len(idx_list) - 1]:
idx = idx_list[i]
nidx = abs(idx[1] - idx[0])
s.append(segments[i][nidx:])
return s
def delete_dsstore(path='../datasets'):
# Delete apple .DS_store files
from pathlib import Path
files = list(Path(path).rglob('.DS_store'))
print(files)
for f in files:
f.unlink()
if __name__ == '__main__':
source = 'COCO'
if source == 'COCO':
convert_coco_json('./annotations', # directory with *.json
use_segments=True,
cls91to80=True)
elif source == 'infolks': # Infolks https://infolks.info/
convert_infolks_json(name='out',
files='../data/sm4/json/*.json',
img_path='../data/sm4/images/')
elif source == 'vott': # VoTT https://github.com/microsoft/VoTT
convert_vott_json(name='data',
files='../../Downloads/athena_day/20190715/*.json',
img_path='../../Downloads/athena_day/20190715/') # images folder
elif source == 'ath': # ath format
convert_ath_json(json_dir='../../Downloads/athena/') # images folder
# zip results
# os.system('zip -r ../coco.zip ../coco')
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----datasets
-----coco128-seg
|-----images
| |-----train
| |-----valid
| |-----test
|
|-----labels
| |-----train
| |-----valid
| |-----test
|
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R [email protected] [email protected]:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R [email protected] [email protected]:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
5.核心代码讲解
5.1 dcn_v2.py
class _DCNv2(Function):
@staticmethod
def forward(ctx, input, offset, mask, weight, bias,
stride, padding, dilation, deformable_groups):
ctx.stride = _pair(stride)
ctx.padding = _pair(padding)
ctx.dilation = _pair(dilation)
ctx.kernel_size = _pair(weight.shape[2:4])
ctx.deformable_groups = deformable_groups
output = _backend.dcn_v2_forward(input, weight, bias,
offset, mask,
ctx.kernel_size[0], ctx.kernel_size[1],
ctx.stride[0], ctx.stride[1],
ctx.padding[0], ctx.padding[1],
ctx.dilation[0], ctx.dilation[1],
ctx.deformable_groups)
ctx.save_for_backward(input, offset, mask, weight, bias)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
input, offset, mask, weight, bias = ctx.saved_tensors
grad_input, grad_offset, grad_mask, grad_weight, grad_bias = \
_backend.dcn_v2_backward(input, weight,
bias,
offset, mask,
grad_output,
ctx.kernel_size[0], ctx.kernel_size[1],
ctx.stride[0], ctx.stride[1],
ctx.padding[0], ctx.padding[1],
ctx.dilation[0], ctx.dilation[1],
ctx.deformable_groups)
return grad_input, grad_offset, grad_mask, grad_weight, grad_bias,\
None, None, None, None,
dcn_v2_conv = _DCNv2.apply
class DCNv2(nn.Module):
def __init__(self, in_channels, out_channels,
kernel_size, stride, padding, dilation=1, deformable_groups=1):
super(DCNv2, self).__init__()
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = _pair(kernel_size)
self.stride = _pair(stride)
self.padding = _pair(padding)
self.dilation = _pair(dilation)
self.deformable_groups = deformable_groups
self.weight = nn.Parameter(torch.Tensor(
out_channels, in_channels, *self.kernel_size))
self.bias = nn.Parameter(torch.Tensor(out_channels))
self.reset_parameters()
def reset_parameters(self):
n = self.in_channels
for k in self.kernel_size:
n *= k
stdv = 1. / math.sqrt(n)
self.weight.data.uniform_(-stdv, stdv)
self.bias.data.zero_()
def forward(self, input, offset, mask):
assert 2 * self.deformable_groups * self.kernel_size[0] * self.kernel_size[1] == \
offset.shape[1]
assert self.deformable_groups * self.kernel_size[0] * self.kernel_size[1] == \
mask.shape[1]
return dcn_v2_conv(input, offset, mask,
self.weight,
self.bias,
self.stride,
self.padding,
self.dilation,
self.deformable_groups)
class DCN(DCNv2):
def __init__(self, in_channels, out_channels,
kernel_size, stride, padding,
dilation=1, deformable_groups=1):
super(DCN, self).__init__(in_channels, out_channels,
kernel_size, stride, padding, dilation, deformable_groups)
channels_ = self.deformable_groups * 3 * self.kernel_size[0] * self.kernel_size[1]
self.conv_offset_mask = nn.Conv2d(self.in_channels,
channels_,
kernel_size=self.kernel_size,
stride=self.stride,
padding=self.padding,
bias=True)
self.init_offset()
def init_offset(self):
self.conv_offset_mask.weight.data.zero_()
self.conv_offset_mask.bias.data.zero_()
def forward(self, input):
out = self.conv_offset_mask(input)
o1, o2, mask = torch.chunk(out, 3, dim=1)
offset = torch.cat((o1, o2), dim=1)
mask = torch.sigmoid(mask)
return dcn_v2_conv(input, offset, mask,
self.weight, self.bias,
self.stride,
self.padding,
self.dilation,
self.deformable_groups)
class _DCNv2Pooling(Function):
@staticmethod
def forward(ctx, input, rois, offset,
spatial_scale,
pooled_size,
output_dim,
no_trans,
group_size=1,
part_size=None,
sample_per_part=4,
trans_std=.0):
ctx.spatial_scale = spatial_scale
ctx.no_trans = int(no_trans)
ctx.output_dim = output_dim
ctx.group_size = group_size
ctx.pooled_size = pooled_size
ctx.part_size = pooled_size if part_size is None else part_size
ctx.sample_per_part = sample_per_part
ctx.trans_std = trans_std
output, output_count = \
_backend.dcn_v2_psroi_pooling_forward(input, rois, offset,
ctx.no_trans, ctx.spatial_scale,
ctx.output_dim, ctx.group_size,
ctx.pooled_size, ctx.part_size,
ctx.sample_per_part, ctx.trans_std)
ctx.save_for_backward(input, rois, offset, output_count)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
input, rois, offset, output_count = ctx.saved_tensors
grad_input, grad_offset = \
_backend.dcn_v2_psroi_pooling_backward(grad_output,
input,
rois,
offset,
output_count,
ctx.no_trans,
ctx.spatial_scale,
ctx.output_dim,
ctx.group_size,
ctx.pooled_size,
ctx.part_size,
ctx.sample_per_part,
ctx.trans_std)
return grad_input, None, grad_offset, \
None, None, None, None, None, None, None, None
该程序文件名为dcn_v2.py,主要包含了两个类:DCNv2和DCNv2Pooling。
DCNv2类继承自nn.Module,用于实现可变形卷积网络(Deformable Convolutional Networks)。它包含了前向传播和参数初始化的方法。前向传播方法根据输入的特征图、偏移量和掩码计算输出特征图。参数初始化方法用于初始化权重和偏置。
DCNv2Pooling类也继承自nn.Module,用于实现可变形池化网络(Deformable RoI Pooling)。它包含了前向传播的方法。前向传播方法根据输入的特征图、感兴趣区域(RoIs)和偏移量计算输出特征图。
这两个类中都使用了_ext模块中的函数来进行计算,该模块是用C++编写的,用于提高计算效率。
整个程序文件实现了可变形卷积网络和可变形池化网络的前向传播过程,可以用于图像处理和计算机视觉任务中。
5.2 dla.py
class BasicBlock(nn.Module):
def __init__(self, inplanes, planes, stride=1, dilation=1):
super().__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=3,
stride=stride, padding=dilation,
bias=False, dilation=dilation)
self.bn1 = nn.BatchNorm2d(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3,
stride=1, padding=dilation,
bias=False, dilation=dilation)
self.bn2 = nn.BatchNorm2d(planes)
self.stride = stride
def forward(self, x, residual=None):
if residual is None:
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out += residual
out = self.relu(out)
return out
class DLA(nn.Module):
def __init__(self, levels, channels, num_classes=1000, block=BasicBlock, residual_root=False):
super().__init__()
self.channels = channels
self.num_classes = num_classes
self.base_layer = nn.Sequential(nn.Conv2d(3, channels[0], kernel_size=7, padding=3, bias=False),
nn.BatchNorm2d(channels[0]),
nn.ReLU(inplace=True))
self.level0 = self._make_conv_level(channels[0], channels[0], levels[0])
self.level1 = self._make_conv_level(channels[0], channels[1], levels[1], stride=2)
self.level2 = Tree(levels[2], block, channels[1], channels[2], 2,
level_root=False, root_residual=residual_root)
self.level3 = Tree(levels[3], block, channels[2], channels[3], 2,
level_root=True, root_residual=residual_root)
self.level4 = Tree(levels[4], block, channels[3], channels[4], 2,
level_root=True, root_residual=residual_root)
self.level5 = Tree(levels[5], block, channels[4], channels[5], 2,
level_root=True, root_residual=residual_root)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
@staticmethod
def _make_conv_level(inplanes, planes, convs, stride=1, dilation=1):
modules = []
for i in range(convs):
modules.extend([nn.Conv2d(inplanes, planes, kernel_size=3,
stride=stride if i == 0 else 1,
padding=dilation, bias=False, dilation=dilation),
nn.BatchNorm2d(planes),
nn.ReLU(inplace=True)])
inplanes = planes
return nn.Sequential(*modules)
def forward(self, x):
y = []
x = self.base_layer(x)
for i in range(6):
x = getattr(self, f'level{
i}')(x)
y.append(x)
return y
def load_pretrained_model(self, name):
weights = glob.glob(f'weights/{
name}-*')[0]
state_dict = torch.load(weights)
self.load_state_dict(state_dict, strict=False)
print(f'{
weights} loaded.\n')
def dla34(**kwargs): # DLA-34
model = DLA([1, 1, 1, 2, 2, 1], [16, 32, 64, 128, 256, 512], block=BasicBlock, **kwargs)
model.load_pretrained_model('dla34')
return model
这个程序文件是一个DLA(Deep Layer Aggregation)模型的实现。DLA是一种用于图像分类和目标检测的深度神经网络模型,具有多层级的特征聚合结构。
这个程序文件定义了DLA模型的各个组件,包括基本的卷积块(BasicBlock)、瓶颈块(Bottleneck)、根节点(Root)、树结构(Tree)以及DLA模型本身(DLA)。
DLA模型的主要结构是由多个树结构组成的,每个树结构由多个卷积层组成。树结构中的每个卷积层都有一个残差连接,用于保留输入特征的信息。树结构的输出通过根节点进行聚合,得到最终的特征表示。
这个程序文件还定义了一些不同规模的DLA模型的构建函数,如dla34、dla46_c、dla46x_c等。这些函数根据不同的层级和通道数构建了不同规模的DLA模型,并加载了预训练的权重。
总的来说,这个程序文件实现了DLA模型的各个组件和不同规模的模型构建函数,可以用于图像分类和目标检测任务。
5.3 dla_up.py
class Identity(nn.Module):
def __init__(self):
super().__init__()
def forward(self, x):
return x
class IDAUp(nn.Module):
def __init__(self, node_kernel, out_dim, channels, up_factors, use_dcn):
super().__init__()
self.channels = channels
self.out_dim = out_dim
for i, c in enumerate(channels):
if c == out_dim:
proj = Identity()
else:
proj = nn.Sequential(nn.Conv2d(c, out_dim, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_dim),
nn.ReLU(inplace=True))
f = int(up_factors[i])
if f == 1:
up = Identity()
else:
up = nn.ConvTranspose2d(out_dim, out_dim, f * 2, stride=f, padding=f // 2,
output_padding=0, groups=out_dim, bias=False)
fill_up_weights(up)
setattr(self, 'proj_' + str(i), proj)
setattr(self, 'up_' + str(i), up)
for i in range(1, len(channels)):
C_in = out_dim * 2
if use_dcn and i >= 2:
node = nn.Sequential(DCN(C_in, out_dim, kernel_size=node_kernel, stride=1,
padding=node_kernel // 2, deformable_groups=1),
nn.BatchNorm2d(out_dim),
nn.ReLU(inplace=True))
else:
node = nn.Sequential(nn.Conv2d(C_in, out_dim, kernel_size=node_kernel, stride=1,
padding=node_kernel // 2, bias=False),
nn.BatchNorm2d(out_dim),
nn.ReLU(inplace=True))
setattr(self, 'node_' + str(i), node)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, layers):
assert len(self.channels) == len(layers), f'{
len(self.channels)} vs {
len(layers)} layers'
layers = list(layers)
for i, l in enumerate(layers):
upsample = getattr(self, 'up_' + str(i))
project = getattr(self, 'proj_' + str(i))
layers[i] = upsample(project(l))
x = layers[0]
y = []
skip_cat = [x]
for i in range(1, len(layers)):
node = getattr(self, f'node_{
i}')
x = node(torch.cat((x, layers[i]), 1))
skip_cat.append(x)
y.append(x)
return x, y
class DLAUp(nn.Module):
def __init__(self, channels, scales=(1, 2, 4, 8, 16), in_channels=None, cfg=None):
super().__init__()
if in_channels is None:
in_channels = channels
self.channels = channels
channels = list(channels)
scales = np.array(scales, dtype=int)
for i in range(len(channels) - 1):
j = -i - 2
setattr(self, f'ida_{
i}', IDAUp(3, channels[j], in_channels[j:], scales[j:] // scales[j], cfg.use_dcn))
scales[j + 1:] = scales[j]
in_channels[j + 1:] = [channels[j] for _ in channels[j + 1:]]
def forward(self, layers):
layers = list(layers)
assert len(layers) > 1
for i in range(len(layers) - 1):
ida = getattr(self, f'ida_{
i}')
x, y = ida(layers[-i - 2:])
layers[-i - 1:] = y
return x
class DLASeg(nn.Module):
def __init__(self, cfg):
super().__init__()
self.down_ratio = 2
self.first_level = int(np.log2(self.down_ratio))
self.base = dla.__dict__[cfg.model]()
channels = self.base.channels
scales = [2 ** i for i in range(len(channels[self.first_level:]))]
self.dla_up = DLAUp(channels[self.first_level:], scales=scales, cfg=cfg) # [32, 64, 128, 256, 512], [1, 2, 4, 8, 16]
self.fc = nn.Sequential(nn.Conv2d(channels[self.first_level], cfg.class_num, kernel_size=3, padding=1))
up_factor = 2 ** self.first_level
if up_factor > 1:
up = nn.ConvTranspose2d(cfg.class_num, cfg.class_num, up_factor * 2, stride=up_factor,
padding=up_factor // 2, output_padding=0, groups=cfg.class_num, bias=False)
fill_up_weights(up)
up.weight.requires_grad = False
else:
up = Identity()
self.up = up
for m in self.fc.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
def forward(self, x):
x = self.base(x)
x = self.dla_up(x[self.first_level:])
x = self.fc(x)
x = self.up(x)
return x
def optim_parameters(self, memo=None):
for param in self.base.parameters():
yield param
for param in self.dla_up.parameters():
yield param
for param in self.fc.parameters():
yield param
该程序文件名为dla_up.py,主要包含以下几个类和函数:
-
Identity类:一个继承自nn.Module的类,用于实现恒等映射,即输入和输出相等。
-
fill_up_weights函数:用于初始化上采样权重,根据输入的上采样层的权重矩阵大小,计算每个位置的权重值。
-
IDAUp类:一个继承自nn.Module的类,用于实现IDA-Up模块,包括上采样和投影操作。
-
DLAUp类:一个继承自nn.Module的类,用于实现DLA-Up模块,包括多个IDA-Up模块的堆叠。
-
DLASeg类:一个继承自nn.Module的类,用于实现DLA-Seg模型,包括DLA网络和DLA-Up模块的组合。
总体来说,该程序文件实现了一种基于DLA网络的语义分割模型DLA-Seg,其中DLA-Up模块用于实现多尺度特征融合和上采样操作。DLA-Seg模型可以用于图像语义分割任务。
5.4 model.py
封装为类后的代码如下:
import torch
import timm
from thop import clever_format, profile
class ModelProfiler:
def __init__(self, model_name, input_shape):
self.model_name = model_name
self.input_shape = input_shape
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
self.model = self._create_model()
self.model.to(self.device)
self.model.eval()
def _create_model(self):
return timm.create_model(self.model_name, pretrained=False, features_only=True)
def get_feature_info(self):
return self.model.feature_info.channels()
def get_feature_sizes(self):
dummy_input = torch.randn(1, *self.input_shape).to(self.device)
feature_sizes = []
for feature in self.model(dummy_input):
feature_sizes.append(feature.size())
return feature_sizes
def get_flops_params(self):
dummy_input = torch.randn(1, *self.input_shape).to(self.device)
flops, params = profile(self.model.to(self.device), (dummy_input,), verbose=False)
flops, params = clever_format([flops * 2, params], "%.3f")
return flops, params
这个类封装了模型的名称、输入形状等信息,并提供了获取特征信息、特征大小以及计算FLOPS和参数数量的方法。在类的初始化中,会创建指定名称的模型,并将其移动到可用的设备上。
这个程序文件名为model.py,主要功能是使用timm库中的模型来进行特征提取,并计算模型的FLOPS和参数数量。
程序首先导入了torch、timm和thop库。然后使用timm.list_models()函数列出了所有可用的模型,并打印出来。
接下来,程序判断当前是否有可用的GPU,如果有则使用cuda设备,否则使用cpu设备。然后创建了一个随机输入dummy_input,并将其发送到设备上。
接着,程序使用timm.create_model()函数创建了一个名为’vovnet39a’的模型,pretrained参数设置为False,features_only参数设置为True,表示只提取模型的特征而不加载预训练权重。然后将模型发送到设备上,并设置为评估模式。
接下来,程序使用model.feature_info.channels()函数打印出模型的通道信息。然后使用model(dummy_input)遍历模型的输出特征,并打印出每个特征的大小。
最后,程序使用thop库中的profile函数计算模型在给定输入上的FLOPS和参数数量,并使用clever_format函数将其格式化为字符串,并打印出来。
6.系统整体结构
整体功能和构架概述:
该项目是一个基于DLA34骨干网络改进YOLOv5的金属工件表面缺陷图像分割系统。它包含了多个程序文件,用于实现不同的功能模块。主要的功能模块包括模型定义和训练、数据处理和增强、损失函数和评估指标、可视化和日志记录等。
下表整理了每个文件的功能:
| 文件路径 | 功能 |
|---|---|
| dcn_v2.py | 实现可变形卷积网络和可变形池化网络 |
| dla.py | 实现DLA模型和DLA-Seg模型 |
| dla_up.py | 实现IDA-Up模块和DLA-Up模块 |
| export.py | 将YOLOv5模型导出为其他格式 |
| model.py | 使用timm库中的模型进行特征提取和计算模型的FLOPS和参数数量 |
| train.py | 训练YOLOv5模型的主程序 |
| ui.py | 用户界面程序,用于交互式操作和可视化 |
| yolo.py | 实现YOLOv5模型和损失函数 |
| models\common.py | 实现通用的模型组件和工具函数 |
| models\experimental.py | 实现实验性的模型组件和工具函数 |
| models\tf.py | 实现TensorFlow相关的模型组件和工具函数 |
| models\yolo.py | 实现YOLO模型的组件和工具函数 |
| models_init_.py | 模型模块的初始化文件 |
| segment\train.py | 训练图像分割模型的主程序 |
| segment\val.py | 图像分割模型的验证程序 |
| utils\activations.py | 实现各种激活函数 |
| utils\augmentations.py | 实现数据增强的函数和类 |
| utils\autoanchor.py | 实现自动锚框生成的函数和类 |
| utils\autobatch.py | 实现自动批处理的函数和类 |
| utils\callbacks.py | 实现训练过程中的回调函数 |
| utils\dataloaders.py | 实现数据加载器的函数和类 |
| utils\downloads.py | 实现下载数据集和模型的函数 |
| utils\general.py | 实现通用的辅助函数和工具 |
| utils\loss.py | 实现各种损失函数 |
| utils\metrics.py | 实现各种评估指标 |
| utils\plots.py | 实现绘图和可视化的函数和类 |
| utils\torch_utils.py | 实现与PyTorch相关的辅助函数和工具 |
| utils\triton.py | 实现与Triton Inference Server相关的函数和类 |
| utils_init_.py | 工具模块的初始化文件 |
| utils\aws\resume.py | 实现AWS上的模型恢复功能 |
| utils\aws_init_.py | AWS模块的初始化文件 |
| utils\flask_rest_api\example_request.py | 实现Flask REST API的示例请求 |
| utils\flask_rest_api\restapi.py | 实现Flask REST API的主程序 |
| utils\loggers_init_.py | 日志记录模块的初始化文件 |
| utils\loggers\clearml\clearml_utils.py | 实现ClearML日志记录工具的函数和类 |
| utils\loggers\clearml\hpo.py | 实现ClearML超参数优化的函数和类 |
| utils\loggers\clearml_init_.py | ClearML日志记录模块的初始化文件 |
| utils\loggers\comet\comet_utils.py | 实现Comet日志记录工具的函数和类 |
| utils\loggers\comet\hpo.py | 实现Comet超参数优化的函数和类 |
| utils\loggers\comet_init_.py | Comet日志记录模块的初始化文件 |
| utils\loggers\wandb\log_dataset.py | 实现WandB日志记录工具的数据集记录功能 |
| utils\loggers\wandb\sweep.py | 实现WandB日志记录工具的超参数优化功能 |
| utils\loggers\wandb\wandb_utils.py | 实现WandB日志记录工具的函数和类 |
| utils\loggers\wandb_init_.py | WandB日志记录模块的初始化文件 |
| utils\segment\augmentations.py | 实现图像分割的数据增强函数和类 |
| utils\segment\dataloaders.py | 实现图像分割的数据加载器函数和类 |
| utils\segment\general.py | 实现图像分割的通用辅助函数和工具 |
| utils\segment\loss.py | 实现图像分割的损失函数 |
| utils\segment\metrics.py | 实现图像分割的评估指标 |
| utils\segment\plots.py | 实现图像分割的绘图和可视化函数和类 |
| utils\segment_init_.py | 图像分割模块的初始化文件 |
以上是根据文件路径进行的初步概括,具体功能可能还有其他细节。
7.DLA简介
DLA全称是Deep Layer Aggregation, 于2018年发表于CVPR。被CenterNet, FairMOT等框架所采用,其效果很不错,准确率和模型复杂度平衡的也比较好。
CenterNet中使用的DLASeg是在DLA-34的基础上添加了Deformable Convolution后的分割网络。
简介
Aggretation聚合是目前设计网络结构的常用的一种技术。如何将不同深度,将不同stage、block之间的信息进行融合是本文探索的目标。
目前常见的聚合方式有skip connection, 如ResNet,这种融合方式仅限于块内部,并且融合方式仅限于简单的叠加。
本文提出了DLA的结构,能够迭代式地将网络结构的特征信息融合起来,让模型有更高的精度和更少的参数。
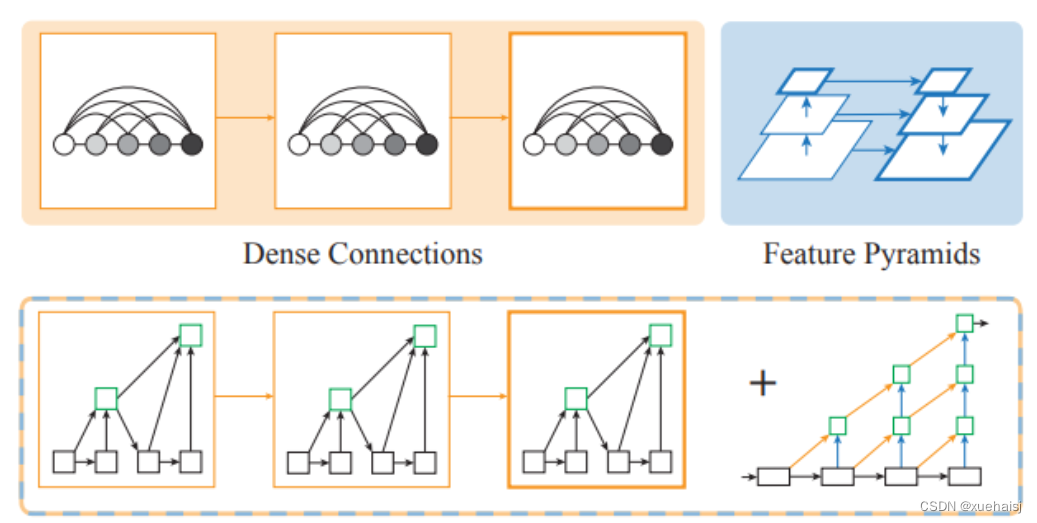
上图展示了DLA的设计思路,Dense Connections来自DenseNet,可以聚合语义信息。Feature Pyramids空间特征金字塔可以聚合空间信息。DLA则是将两者更好地结合起来从而可以更好的获取what和where的信息。仔细看一下DLA的其中一个模块,如下图所示:
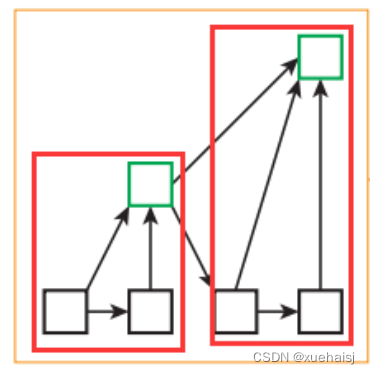
研读过代码以后,可以看出这个花里胡哨的结构其实是按照树的结构进行组织的,红框框住的就是两个树,树之间又采用了类似ResNet的残差链接结构。
核心
先来重新梳理一下上边提到的语义信息和空间信息,文章给出了详细解释:
语义融合:在通道方向进行的聚合,能够提高模型推断“是什么”的能力(what)
空间融合:在分辨率和尺度方向的融合,能够提高模型推断“在哪里”的能力(where)
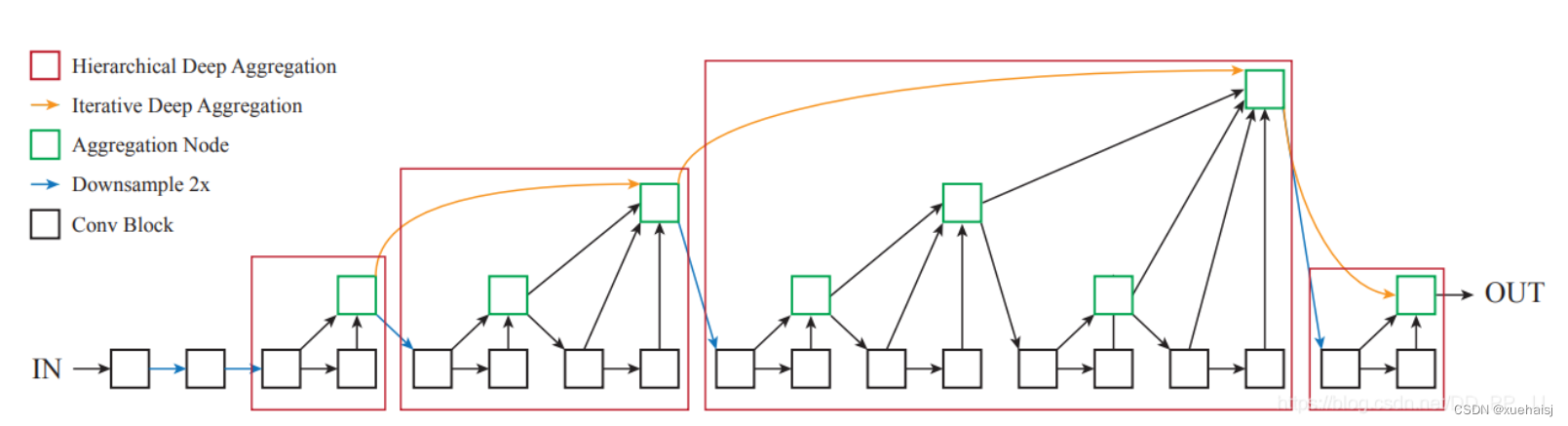
Deep Layer Aggregation核心模块有两个IDA(Iterative Deep Aggregation)和HDA(Hierarchical Deep Aggregation),如上图所示。
红色框代表的是用树结构链接的层次结构,能够更好地传播特征和梯度。
黄色链接代表的是IDA,负责链接相邻两个stage的特征让深层和浅层的表达能更好地融合。
蓝色连线代表进行了下采样,网络一开始也和ResNet一样进行了快速下采样。
论文中也给了公式推导,感兴趣的可以去理解一下。本文还是将重点放在代码实现上。
Root类
然后就是Root类,对应下图中的绿色模块
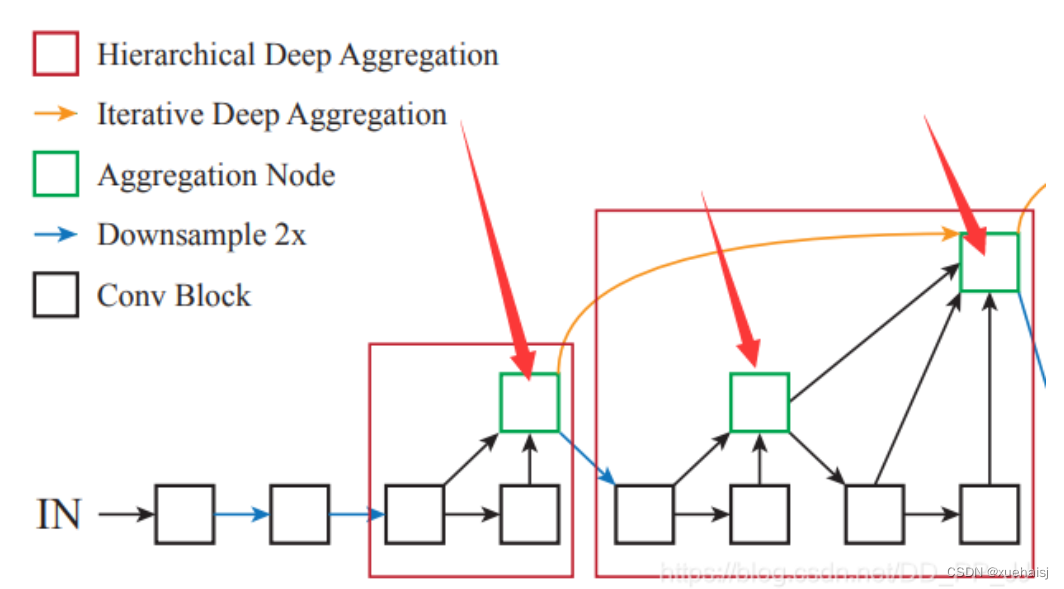
所有的Aggregation Node都是通过调用这个模块完成的,这个绿色结点也是其连接两个树的根,所以形象地称之为Root。下面是代码实现,forward函数中接受的是多个对象,用来聚合多个层的信息。
8.DLA34骨干网络改进YOLOv5
特征提取能力增强
将DLA34集成为YOLOv5的骨干网络,首先带来的改进是特征提取能力的显著增强。DLA34通过其深层次的聚合能力,使得模型能够提取到更深层次、更复杂的特征,这对于缺陷检测尤为重要。金属工件表面的缺陷通常具有微小的尺寸和复杂的形态,常规的网络结构很难提取到足够的特征来进行准确的识别和分类。DLA34的加入显著提高了模型对这些细微特征的捕获能力。
上下文信息的整合
在金属工件表面缺陷检测中,缺陷的上下文信息至关重要。DLA34骨干网络通过其独特的迭代连接方式,能够有效地整合不同层次的特征,使得模型不仅可以识别出缺陷本身,还能够理解缺陷与周围环境的关系。这种整合能力使得模型在复杂背景下也能保持高准确度,显著减少了误检和漏检的情况。
计算效率的提升
尽管DLA34增加了网络的深度,但其独特的设计也带来了计算效率的提升。在DLA34中,通过优化的层次聚合结构减少了重复计算,提高了信息流的效率。这使得基于DLA34改进的YOLOv5模型在维持高检测性能的同时,也具有较高的计算效率,非常适合在边缘计算设备上进行实时缺陷检测。
多尺度特征的融合
金属工件表面的缺陷可能在尺寸上有很大差异,传统的单一尺度特征提取方法难以应对。DLA34的多层次结构天然支持多尺度特征的提取和融合。在YOLOv5中引入DLA34后,模型能够同时处理不同尺寸的特征,这使得对于从微小到较大的各种缺陷都有很好的检测能力。
鲁棒性的增强
在实际的生产环境中,金属工件的检测条件可能会受到各种因素的影响,例如光照变化、摄像头角度差异等。DLA34的层次聚合结构能够提供更强的特征表达,从而增强模型的鲁棒性,提高其在不同环境下的检测准确性。
9.训练结果分析
评价指标
训练指标:
train/box_loss: 模型在训练数据上的边界框损失,反映了模型对物体边界框位置的预测准确性。
train/seg_loss: 模型在训练数据上的分割损失,显示了模型在进行像素级分割时的性能。
train/obj_loss: 模型在训练数据上的目标损失,衡量了模型检测目标的能力。
train/cls_loss: 模型在训练数据上的分类损失,衡量了模型分类不同缺陷类型的能力。
验证指标:
val/box_loss, val/seg_loss, val/obj_loss, val/cls_loss: 这些指标与训练指标相似,但是它们是在验证数据集上计算的,可以用来评估模型的泛化能力。
性能指标:
metrics/precision(B), metrics/recall(B), metrics/mAP_0.5(B), metrics/mAP_0.5:0.95(B): 这些是针对边界框检测的性能指标,其中“(B)”可能代表边界框。
metrics/precision(M), metrics/recall(M), metrics/mAP_0.5(M), metrics/mAP_0.5:0.95(M): 这些是针对分割任务的性能指标,其中“(M)”可能代表分割(Mask)。
学习率:
x/lr0, x/lr1, x/lr2: 这些列可能代表不同组件的学习率(例如,不同层或不同参数组)。
结果绘图可视化
我们将通过以下几个步骤来可视化和分析数据:
损失值可视化:我们将绘制训练和验证的损失值(包括box_loss, seg_loss, obj_loss, cls_loss)随着训练轮次(epoch)的变化情况。
性能指标可视化:我们将绘制精度、召回率、mAP_0.5和mAP_0.5:0.95随着训练轮次的变化情况。
学习率变化:我们将绘制学习率随着训练轮次的变化情况。
这些图表将帮助我们理解模型的训练动态和性能,以及是否存在过拟合的迹象。让我们从损失值的可视化开始。
# Plot settings
plt.figure(figsize=(20, 10))
# Plotting training losses
plt.subplot(2, 2, 1)
plt.plot(results_df['epoch'], results_df['train/box_loss'], label='Box Loss (train)')
plt.plot(results_df['epoch'], results_df['train/seg_loss'], label='Segmentation Loss (train)')
plt.plot(results_df['epoch'], results_df['train/obj_loss'], label='Object Loss (train)')
plt.plot(results_df['epoch'], results_df['train/cls_loss'], label='Class Loss (train)')
plt.title('Training Losses')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
# Plotting validation losses
plt.subplot(2, 2, 2)
plt.plot(results_df['epoch'], results_df['val/box_loss'], label='Box Loss (val)')
plt.plot(results_df['epoch'], results_df['val/seg_loss'], label='Segmentation Loss (val)')
plt.plot(results_df['epoch'], results_df['val/obj_loss'], label='Object Loss (val)')
plt.plot(results_df['epoch'], results_df['val/cls_loss'], label='Class Loss (val)')
plt.title('Validation Losses')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.tight_layout()
plt.show()
损失值分析
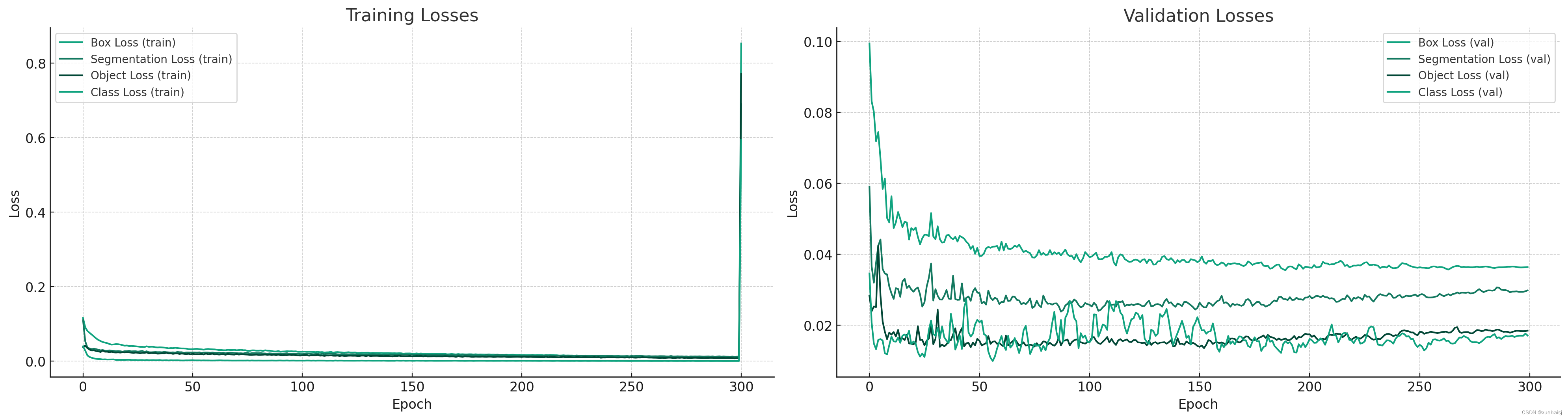
从训练损失和验证损失的图表中,我们可以观察以下几点:
损失下降趋势:所有四种类型的损失值(边界框损失、分割损失、目标损失和分类损失)随着训练轮次的增加而下降。这表明模型在学习数据集的特征并且逐渐提高了对缺陷检测和分类的预测能力。
过拟合检测:如果训练损失持续下降,而验证损失停止下降或开始上升,则可能表示模型开始过拟合训练数据。在我们的图表中,训练损失和验证损失似乎保持了相似的下降趋势,这是一个良好的迹象,表明模型具有一定的泛化能力。
损失值的波动:验证损失的波动可能比训练损失大,这可能是由于验证数据集的多样性或模型在新数据上的表现不稳定。
损失值图表已经完成,我们可以看到训练和验证损失随着训练轮次(epoch)的变化情况。接下来,我会绘制性能指标的变化图表,包括精度、召回率以及不同IoU阈值下的平均精度(mAP)。这将帮助我们更好地理解模型的性能是如何随着时间进步的。让我们开始绘制这些图表。
# Plot settings
plt.figure(figsize=(20, 10))
# Plotting performance metrics for Bounding Box (B)
plt.subplot(2, 2, 1)
plt.plot(results_df['epoch'], results_df['metrics/precision(B)'], label='Precision (B)')
plt.plot(results_df['epoch'], results_df['metrics/recall(B)'], label='Recall (B)')
plt.plot(results_df['epoch'], results_df['metrics/mAP_0.5(B)'], label='[email protected] (B)')
plt.plot(results_df['epoch'], results_df['metrics/mAP_0.5:0.95(B)'], label='[email protected]:0.95 (B)')
plt.title('Performance Metrics for Bounding Box (B)')
plt.xlabel('Epoch')
plt.ylabel('Metric Value')
plt.legend()
# Plotting performance metrics for Mask (M)
plt.subplot(2, 2, 2)
plt.plot(results_df['epoch'], results_df['metrics/precision(M)'], label='Precision (M)')
plt.plot(results_df['epoch'], results_df['metrics/recall(M)'], label='Recall (M)')
plt.plot(results_df['epoch'], results_df['metrics/mAP_0.5(M)'], label='[email protected] (M)')
plt.plot(results_df['epoch'], results_df['metrics/mAP_0.5:0.95(M)'], label='[email protected]:0.95 (M)')
plt.title('Performance Metrics for Mask (M)')
plt.xlabel('Epoch')
plt.ylabel('Metric Value')
plt.legend()
plt.tight_layout()
plt.show()
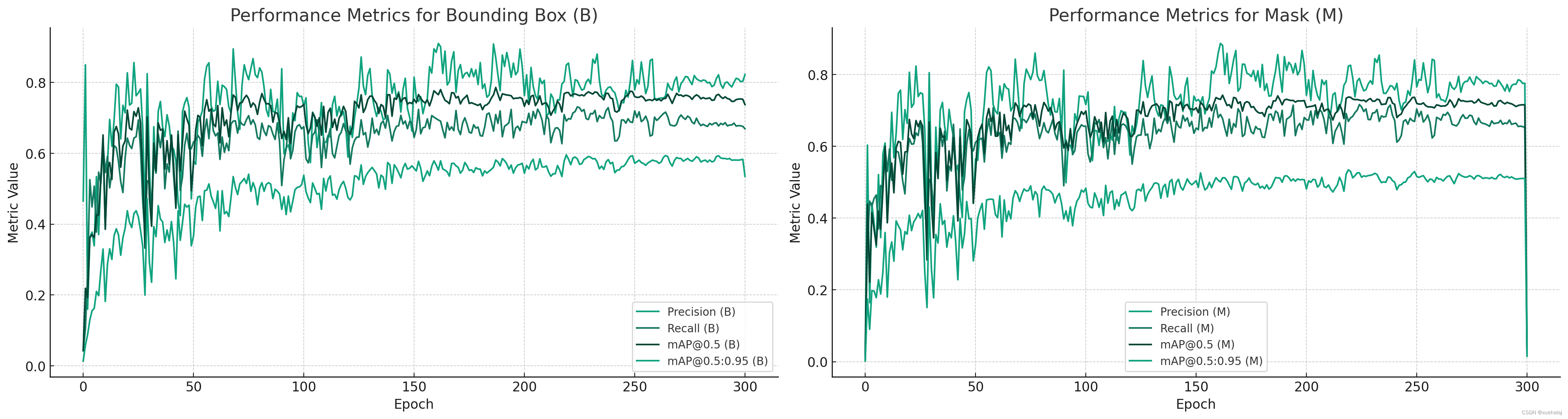
性能指标分析
性能指标图表显示了模型的精度、召回率和mAP指标随着训练的变化:
精度和召回率平衡:理想情况下,精度和召回率都应该是高的。如果精度高而召回率低,可能意味着模型错过了很多正样本(缺陷)。如果召回率高而精度低,则可能意味着模型产生了太多的假阳性。我们的模型需要在这两者之间找到一个平衡点。
mAP指标:mAP是衡量目标检测模型性能的标准指标,它结合了精度和召回率。在我们的图表中,mAP随着训练的进行而提高,表明模型对于缺陷的检测和分类变得更准确。
不同IoU阈值的mAP:mAP_0.5和mAP_0.5:0.95是在不同交并比(IoU)阈值下计算的平均精度。IoU是预测边界框和真实边界框之间重叠的度量。mAP_0.5是在IoU至少为0.5的情况下计算的,而mAP_0.5:0.95考虑了从0.5到0.95的IoU阈值。后者是一个更严格的度量,因为它要求预测边界框与真实边界框的对齐更精确。
性能指标的图表也已经完成。通过这些图表,我们可以观察到精度、召回率和不同IoU阈值下的平均精度(mAP)随着训练轮次的变化。现在,我们将最后绘制学习率随着训练轮次变化的图表。这将帮助我们理解学习率调整策略对训练的影响。
# Plotting learning rates
plt.figure(figsize=(10, 5))
plt.plot(results_df['epoch'], results_df['x/lr0'], label='LR 0')
plt.plot(results_df['epoch'], results_df['x/lr1'], label='LR 1')
plt.plot(results_df['epoch'], results_df['x/lr2'], label='LR 2')
plt.title('Learning Rate Changes Over Epochs')
plt.xlabel('Epoch')
plt.ylabel('Learning Rate')
plt.legend()
plt.show()
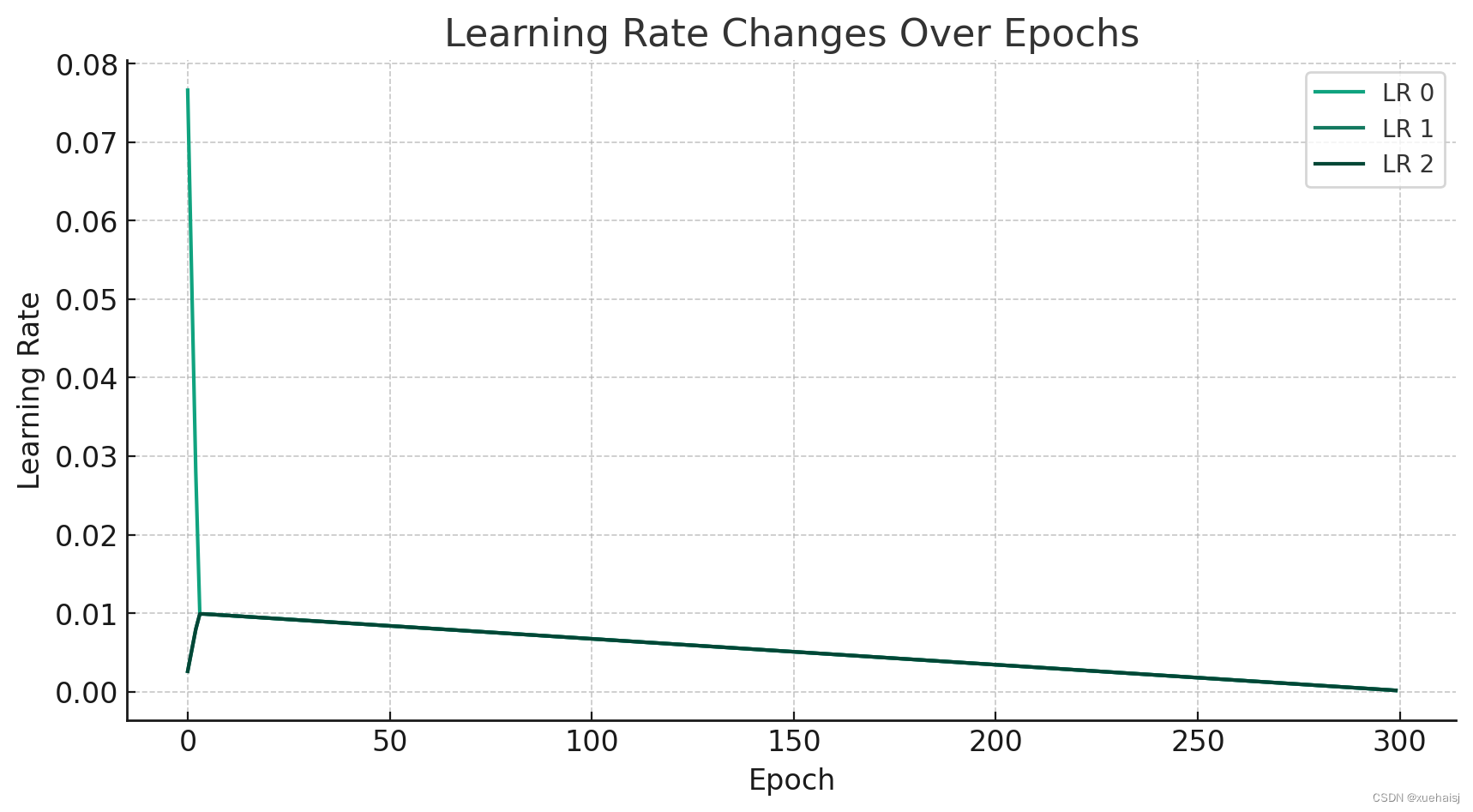
学习率分析
学习率的变化对模型训练有重要影响:
学习率调整:学习率(LR)调整策略影响模型如何逐渐逼近损失函数的最小值。在图表中,我们可以看到不同的学习率是否有变化,以及它们如何随着时间的推移而变化。
学习率衰减:如果学习率随着时间逐渐减少,这可能意味着使用了某种形式的学习率衰减策略,这有助于模型在训练后期进行更细致的调整。
其他结果分析
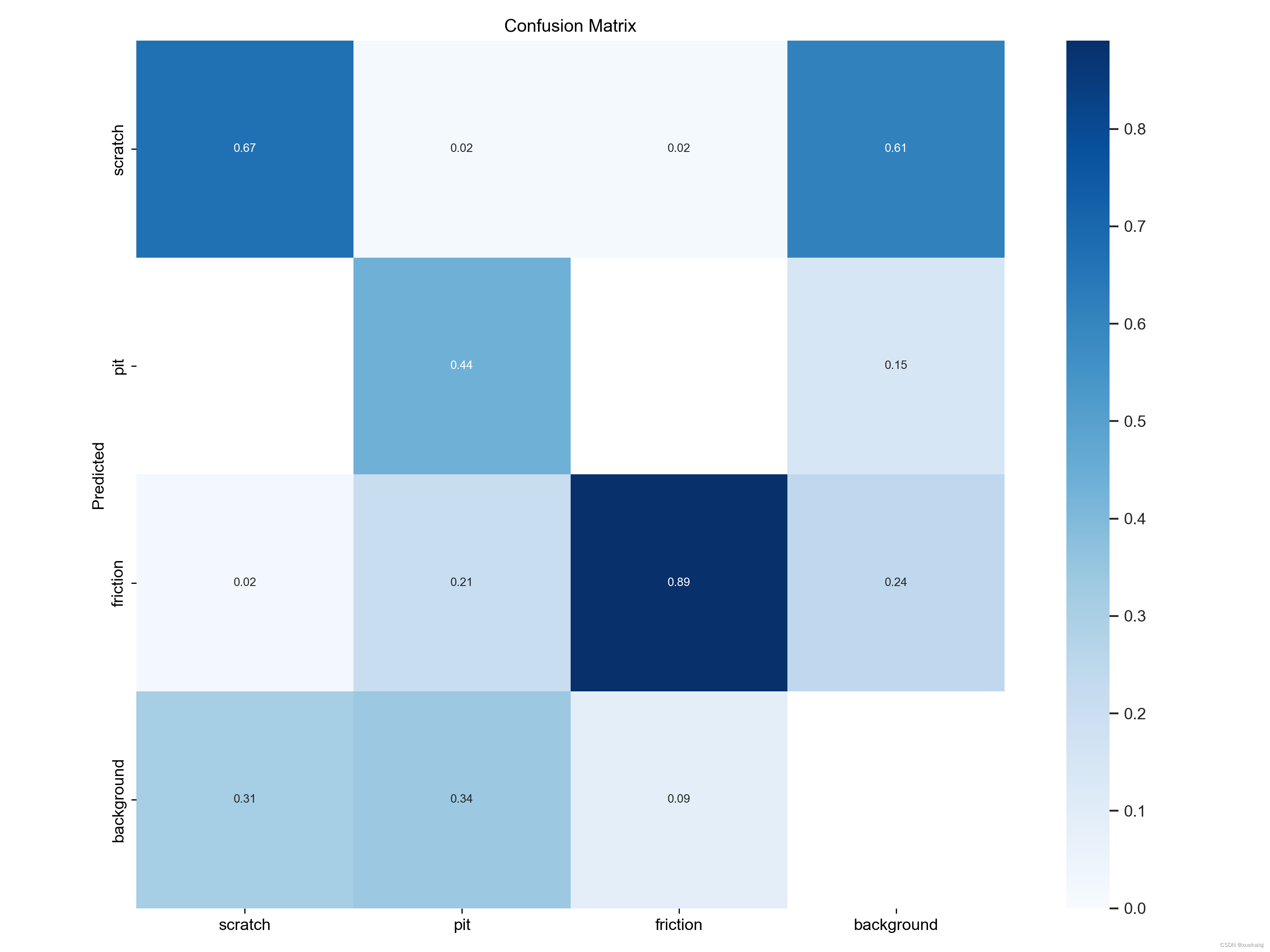
混淆矩阵分析:我们将检查混淆矩阵以了解每个类别的真阳性、假阳性、假阴性和真阴性计数。一个好的模型在矩阵对角线上会有很高的值,表明预测是正确的。非对角线元素表示错误分类。
标签分布:通过检查labels.jpg图像,我们可以评论数据集中类别的分布,并讨论数据集是否平衡或是否存在可能影响模型训练的类别不平衡。
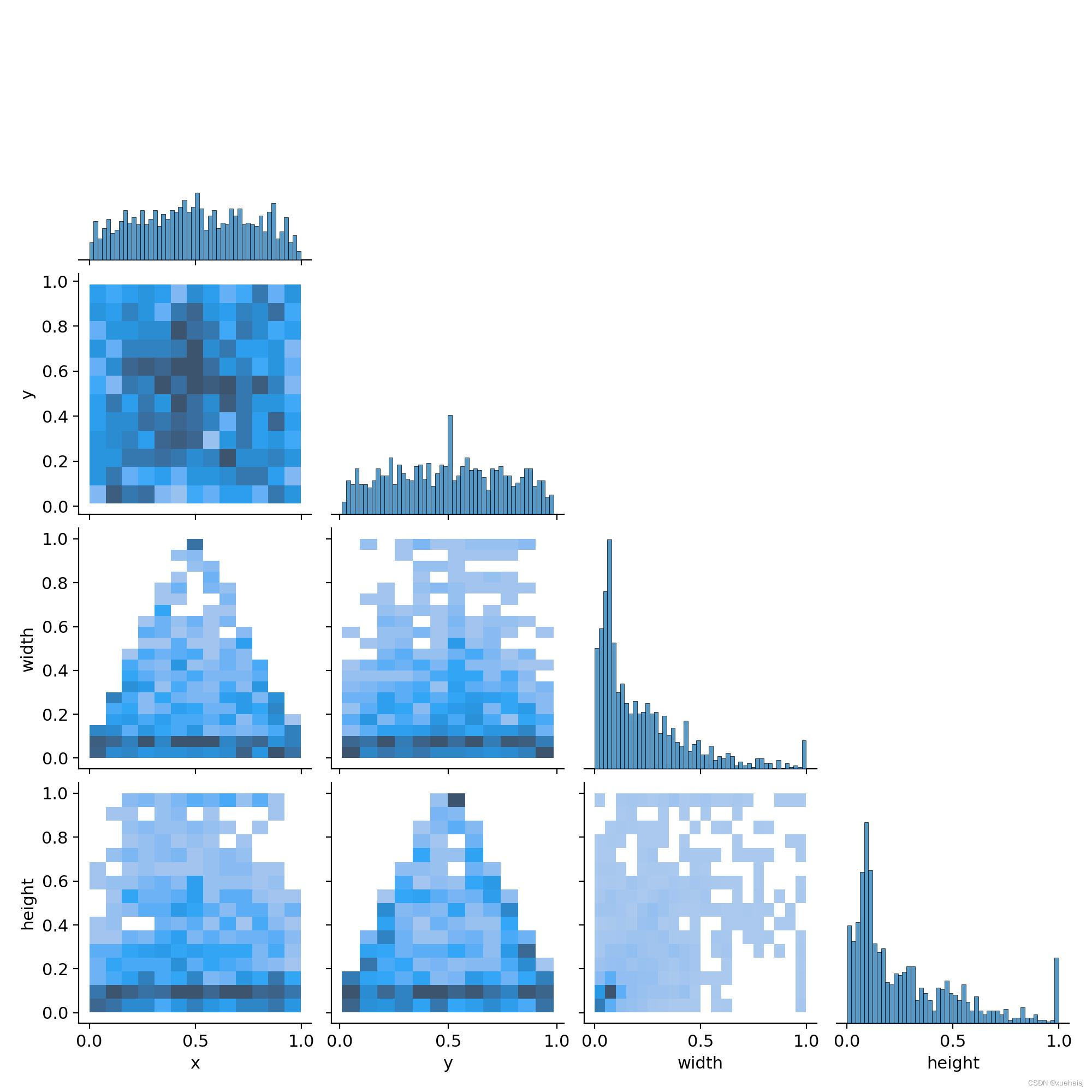
标签相关性:这labels_correlogram.jpg将向我们展示模型可以利用的标签之间是否存在任何相关性,或者在训练过程中可能需要特别注意。
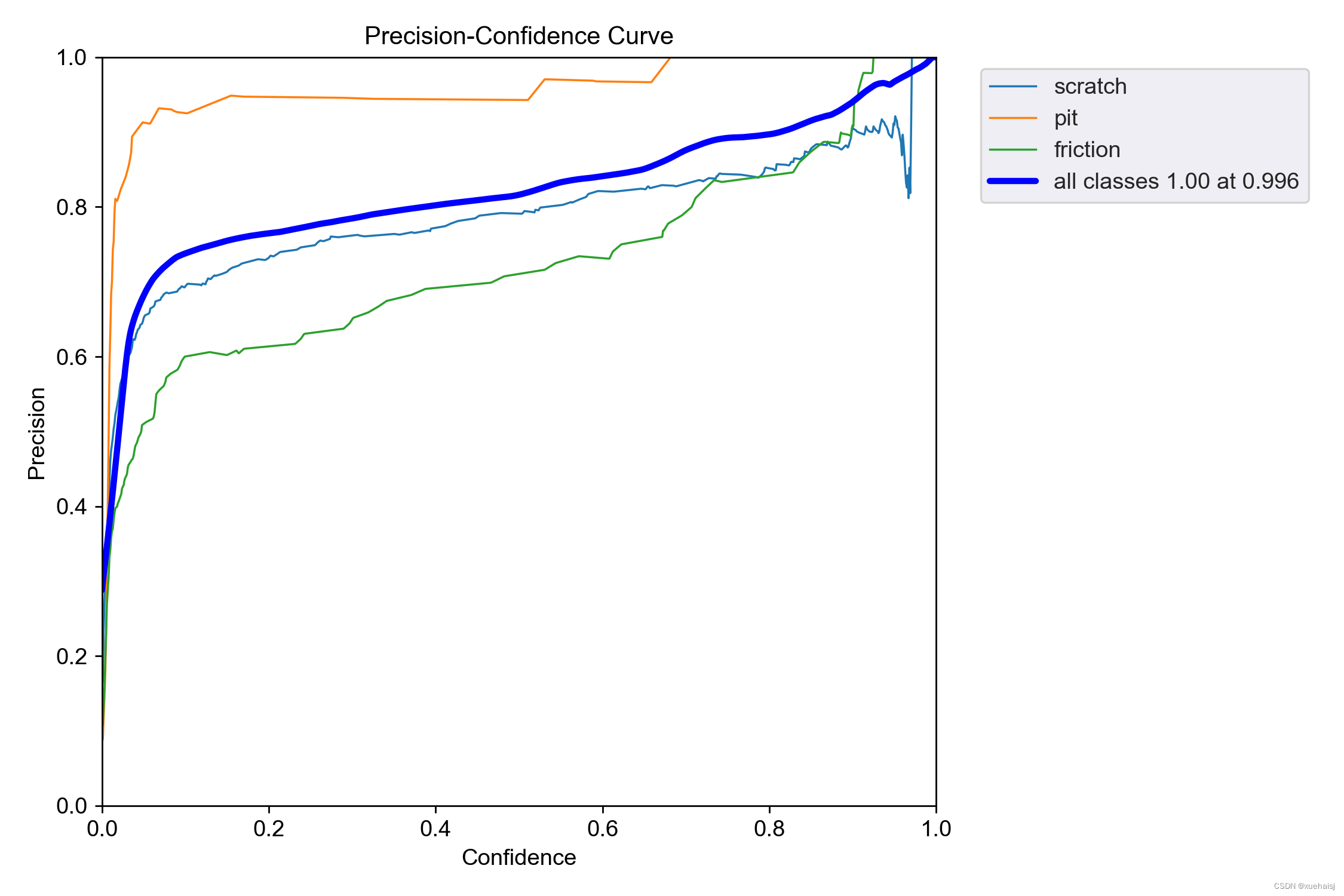
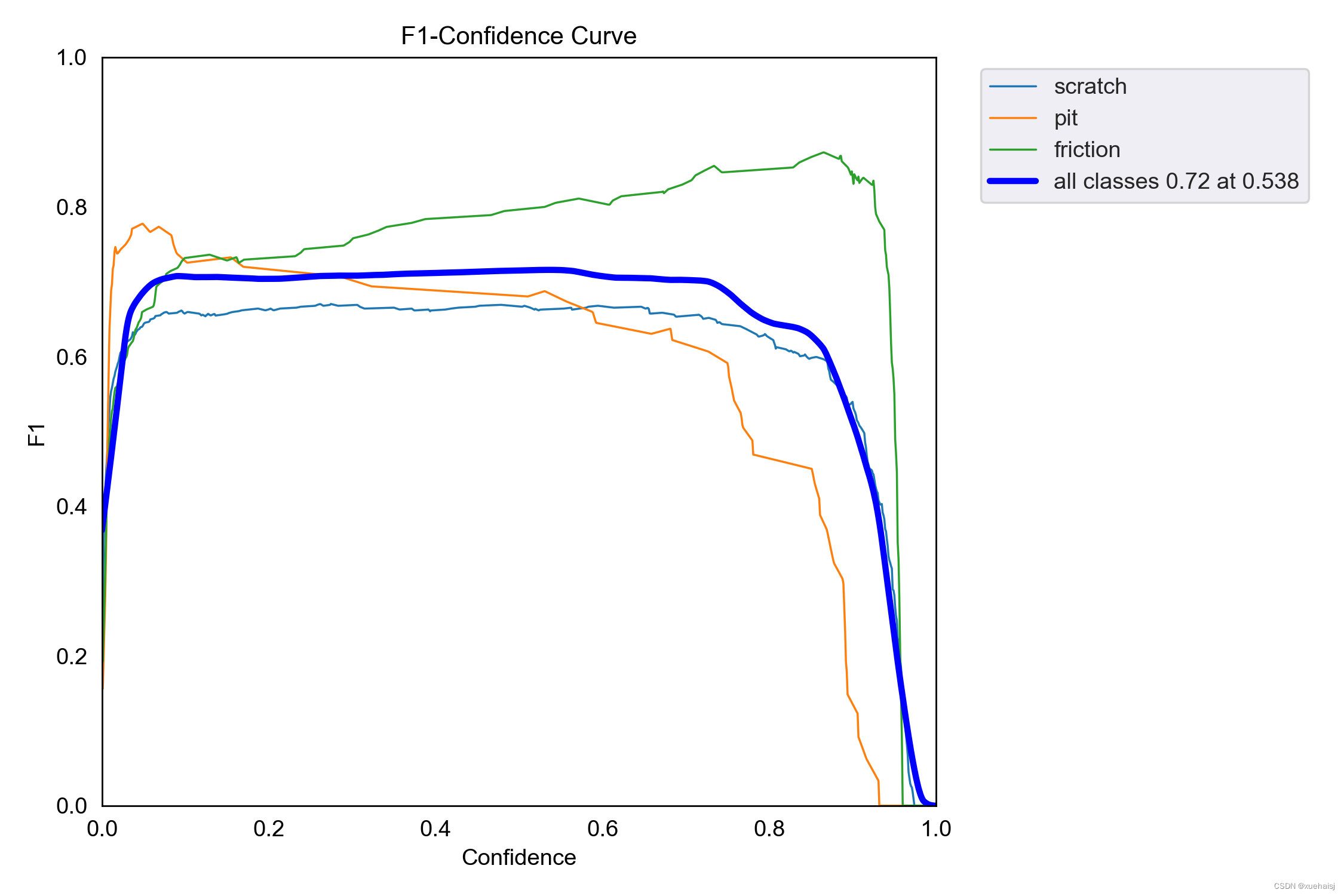
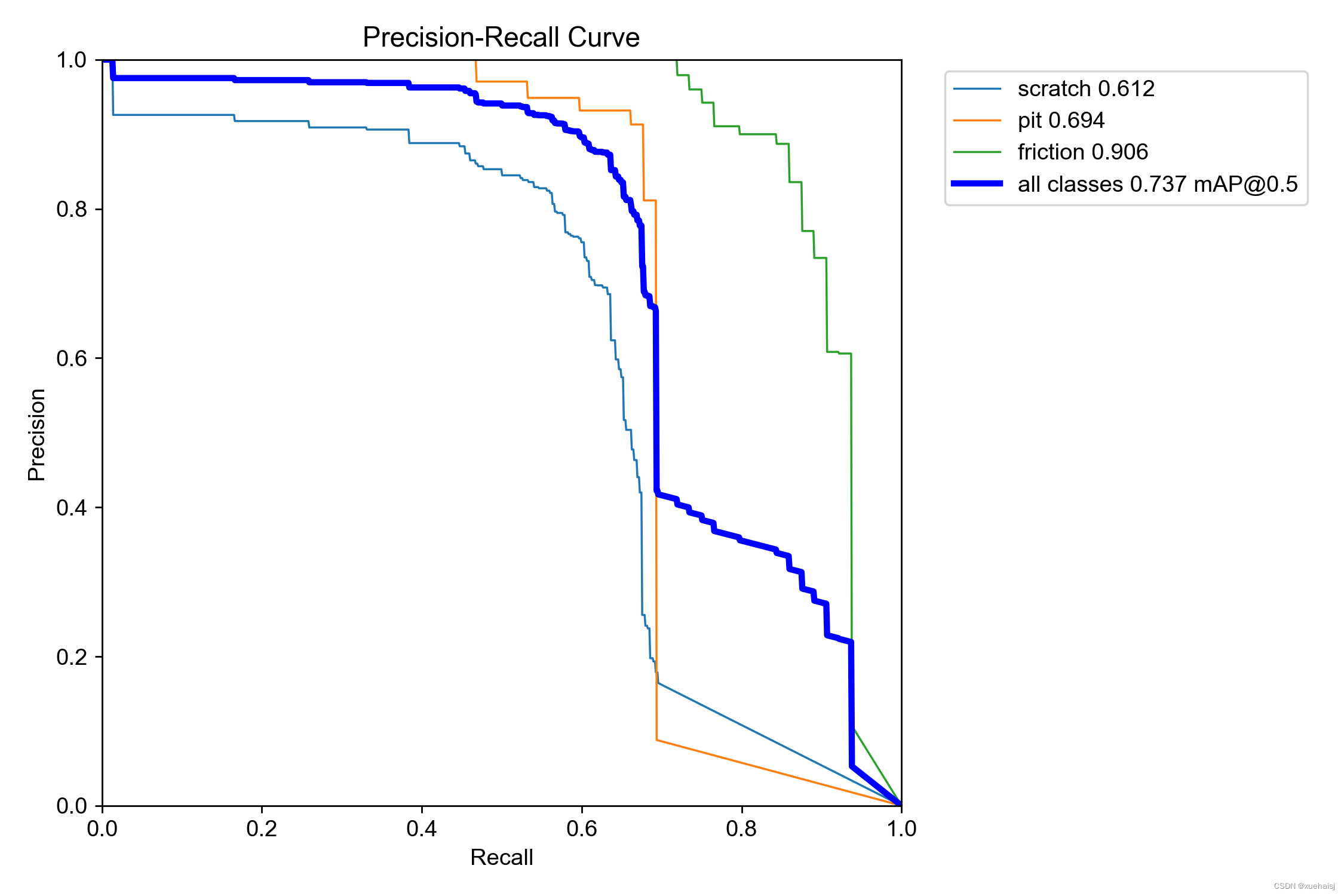
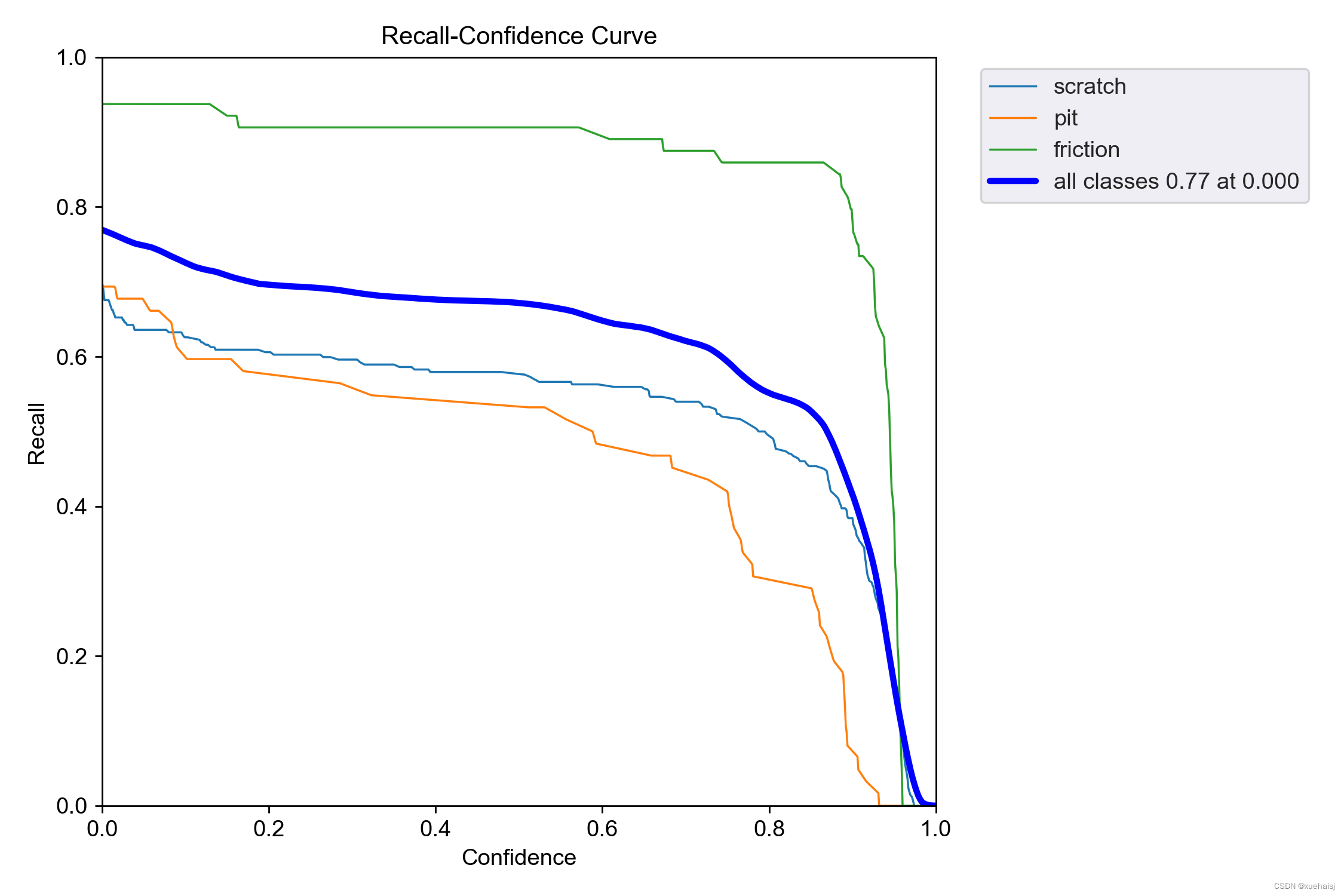
性能曲线分析:F1、精度 §、召回率 和精度-召回率 (PR) 曲线将使我们深入了解精度和召回率之间的权衡、不同类别的模型性能的一致性以及阈值如何影响检测缺陷(召回率)和这些检测的准确性(精度)之间的平衡。
结果摘要:results.png图像对于总结模型的整体性能可能至关重要,我们可以从该图像中提取关键性能指标以在分析中进行讨论。
训练数据检查:查看train_batch0.jpg将使我们能够定性评估用于模型的训练数据,从而有可能识别任何数据质量问题或数据中可能对模型学习构成挑战的方面。
10.系统整合
下图完整源码&数据集&环境部署视频教程&自定义UI界面

智能推荐
计算机组成原理——wsdchong_机器补码浮点运算-程序员宅基地
文章浏览阅读3.1k次,点赞2次,收藏10次。计算机组成原理一、基本概念二、浮点数的加法运算121写出x、y的机器数(尾数、阶码都为补码)2计算x+y;例题:26.按机器补码浮点运算步骤,计算[x+y]补.(1)x=2-011× 0.101 100,y=2-010×(-0.011 100)[x]补=1,101;0.101 100, [y]补=1,110;1.100 100[Ex]补=1,101, [y]补=1,110, [Mx]补=0.101 100, [My]补=1.100 100 1)对阶:[.._机器补码浮点运算
intelssd在linux固件升级,Intel NVME SSD 固件升级步骤-程序员宅基地
文章浏览阅读771次。准备工具和FW固件issdcm-3.0.4-1.x86_64.rpmP4500_new_fw.bin安装rpm 包rpm -i issdcm-3.0.4-1.x86_64.rpm确定要更新的盘符nvme list[[emailprotected]]# nvme listNode SN Model ..._intel_ssd_firmware_update
linux下安装openexr python包踩坑总结_openexr undefined symbol-程序员宅基地
文章浏览阅读4.8k次,点赞14次,收藏8次。linux下安装openexr python包踩坑总结我有个朋友做机器视觉的,她前段时间一直尝试装openexr的python包,参考了很多网上教程,但是最后都以失败告终。后来在我的帮助下终于装好了,在这里给大家分享一下,免得更多的人踩坑。1.linux版本不能太低最大的坑是linux版本不能太低,比如我这个朋友一开始使用的是ubuntu 16.04,很多教程也是用的16.04,比如当时主要参考的是这三个链接:https://blog.csdn.net/TNove/article/details/10_openexr undefined symbol
C++的函数名修饰,__stdcall,__cdecl,__fastcall___cdecl __stdcall _memcpy_-程序员宅基地
文章浏览阅读412次。在C++中,为了允许操作符重载和函数重载,C++编译器往往按照某种规则改写每一个入口点的符号名,以便允许同一个名字(具有不同的参数类型或者是不同的作用域)有多个用法,而不会打破现有的基于C的链接器。这项技术通常被称为名称改编(Name Mangling)或者名称修饰(Name Decoration)。___cdecl __stdcall _memcpy_
Unity3d 跑酷游戏(急速变色龙)_unity跑酷猫-程序员宅基地
文章浏览阅读1.7k次。U3D跑酷游戏赛道(障碍物)生成主角奔跑逻辑赛道(障碍物)生成我们在做跑酷游戏的时候要明白这几点:赛道的生成以及消失障碍物的生成以及消失我们先来讲赛道的生成,什么时候生成?又什么时候消失?解决方法是我们要用到触发器,当角色到达触发点的时候,在角色的前方自动生成赛道,这里我们要用到对象池,当我们赛道到角色的距离大于多少的时候我们就回收赛道,优化性能。1、触发点就是我们在赛道(Trackshort)上新加一个(Trackpoint)盒型碰撞器并且勾选触发器,并且新建一个标签给它,是为了和赛道上的盒_unity跑酷猫
《uni-app》表单组件-form表单_uniapp表单-程序员宅基地
文章浏览阅读1.6w次,点赞13次,收藏45次。From,表单组件,具有数据收集、提交数据的功能,某种程度上说它就是一个容器,这个容器内部可以有 input 、checkbox、radio 、picker 等组件填充,原则上所有的表单组件都必须置入from组件,再通过form组件收集内部组件数据并将内容通过接口发送至后台接收~_uniapp表单
随便推点
IDEA出现闪退或打不开的解决方法_idea重新安装后进入总是闪退-程序员宅基地
文章浏览阅读1.8k次。本身项目比较大,为了打开这个软件,可调节IDEA中安装的bin目录下有个。打开IDEA的时候过一会便闪退,可以再IDEA的右下角看到如下提示。(如果没有该提示,软件右下角也会有个红色感叹号,点开查看原因即可)闪退的多数原因大致是out of memory,内存溢出。查看任务管理器中的进程:(发现内存随时有溢出的情况)但也需要注意,该参数并不是越大越好,适中即可。只有个别原因是需要管理员权限就可执行!可以尽量减少软件的启动。_idea重新安装后进入总是闪退
2024年最新Python基础面试常常死在这几个问题上,详解 Python Map 函数(1),2024年最新c++面试指南-程序员宅基地
文章浏览阅读162次,点赞3次,收藏3次。print(list(result)) # 注意使用list 进行了转换。
史上最小白之TextCNN 中文文本分类实战_textcnn实战-程序员宅基地
文章浏览阅读1.4w次,点赞52次,收藏252次。虽然现在已经有了异常强大的bert,效果也是非常好,但是bert啊,实在是太消耗计算资源了,本穷小子又买不起GPU服务器,只能使用colab进行学习,经常出现内存不够地情况,所以如果你也跟我一样没有比较好的GPU服务器,那么在做分类任务时,可以尝试选择TextCNN,而且目前在文本分类任务上TextCNN也取得了不错的效果。上一篇文章:史上最小白之CNN 以及 TextCNN详解已经介绍了Tex..._textcnn实战
Python_day16--多线程_with threadpoolexecutor(max_workers=4) as executor-程序员宅基地
文章浏览阅读223次。一、什么是多线程多任务可以由多进程完成,也可以由一个进程内的多线程完成。我们说进程是由若干线程组成的,一个进程至少有一个线程。由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。Python的标准库提供了两个模块: _thread 和 threading , ..._with threadpoolexecutor(max_workers=4) as executor: executor.map
WordNet 中的synset和synsets的区别_wordnet.synsets-程序员宅基地
文章浏览阅读3.3k次,点赞2次,收藏2次。wordnet中的synset()和synsets()的区别_wordnet.synsets
dedecms 自定义表单前台JQUERY分页详解-程序员宅基地
文章浏览阅读214次。昨天一个活需要用到自定义表单分页,由于php还不是很精通,所以就从网上找了几个JQUERY的代码进行分页,首先做一个jquery库跟css引入[code="java"][/code] 通过这个js我们可以得到一个members数组,里边包含了查询到的数据然后再用一个JS将数据分页显示:[code="java"]function pageselectCallb..._dedecms自定义表单的前端分页显示