【A情感文本分类实战】2024 Pytorch+Bert/Roberta+TextCNN/BiLstm/Lstm+Prompt-Tuning等实现IMDB情感文本分类完整项目(项目已开源)_roberta文本分类-程序员宅基地
技术标签: 情感分析 深度学习 pytorch 《深度学习》 bert 文本分类

顶会的代码干净利索,借鉴其完成了以下工程
本工程采用Pytorch框架,使用上游语言模型+下游网络模型的结构实现IMDB情感分析
预训练大语言模型可选择Bert、Roberta
应用提示学习,采用学术界最新Prompt-Tuning范式
下游网络模型可选择BiLSTM、LSTM、TextCNN、GRU、Attention以及其组合
语言模型和网络模型扩展性较好,可以此为BaseLine再使用你的数据集,模型
最终的准确率均在90%以上
项目已开源,clone下来再配个简单环境就能跑
适合新手初学NLP,考研复试项目
更新
2024-04:添加提示学习模块;保存模型与加载模型问题
2023-03:添加Attention+LSTM+TextCNN网络模型
2023-02:适配自己数据集问题;提高准确率问题;运行速度问题;奇异矩阵与F1-score问题
如果这篇文章对您有帮助,期待大佬们Github上给个️️️
一、Introduction
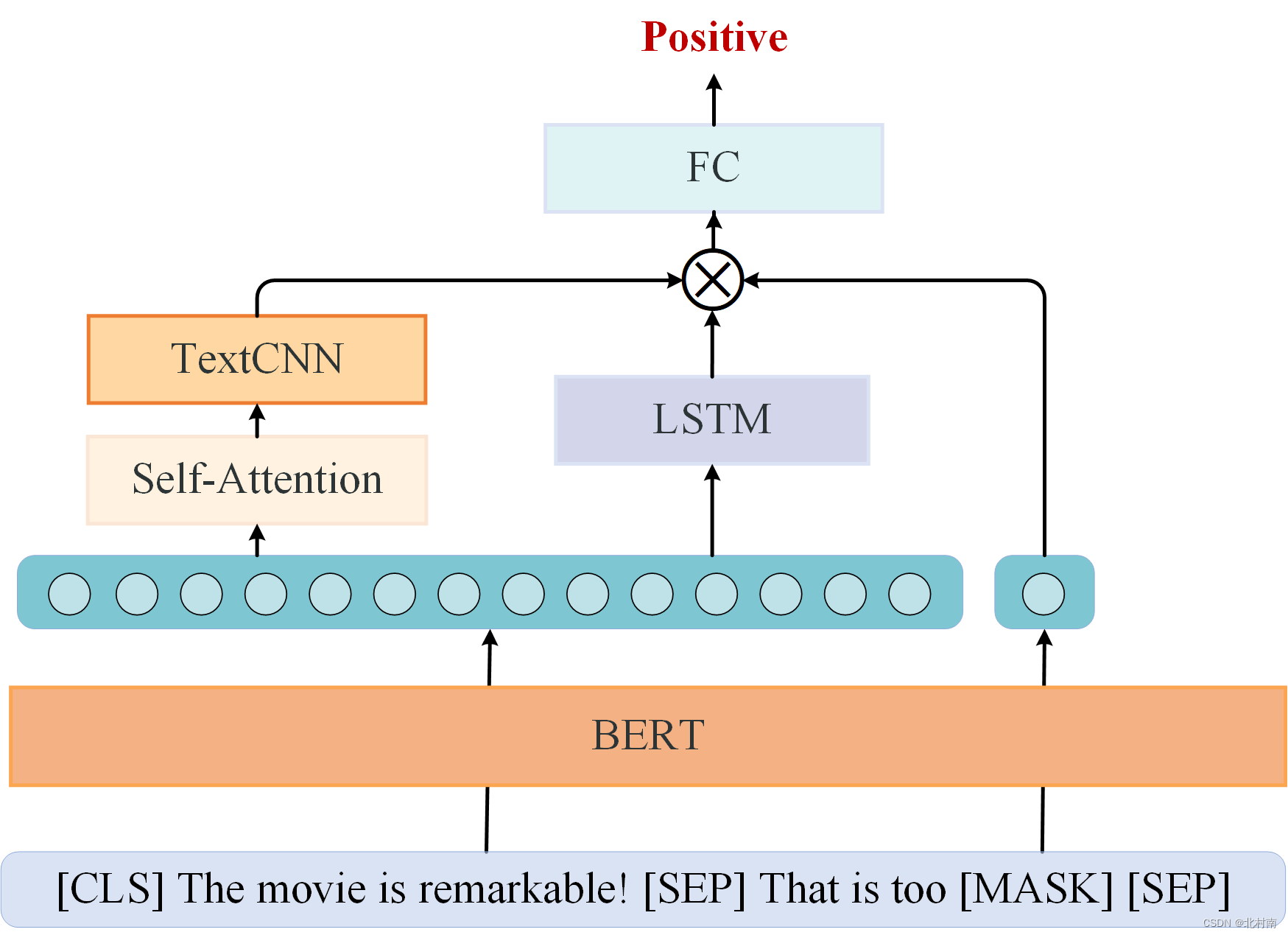
1.1 网络架构图
该网络主要使用上游预训练模型+下游情感分类模型组成

结合读者意见,可逐步修改成如下模型:Self-Attention+TextCNN+LSTM+Prompt-Tuning
1.2 快速使用
该项目已开源在Github上,地址为 sentiment_analysis_Imdb

主要环境要求如下(环境不要太老基本没啥问题的)

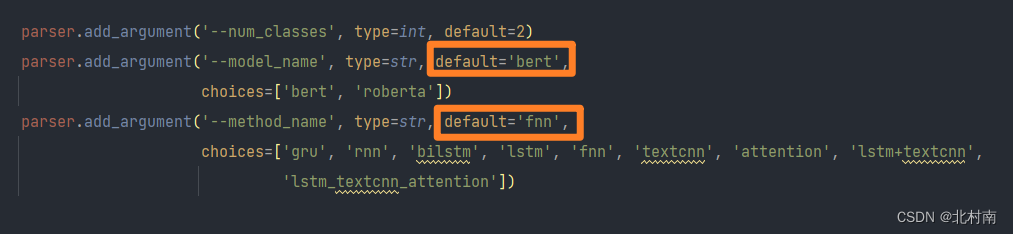
下载该项目后,配置相对应的环境,在config.py文件中选择所需的语言模型和神经网络模型如下图所示,运行main.py文件即可
1.3 工程结构
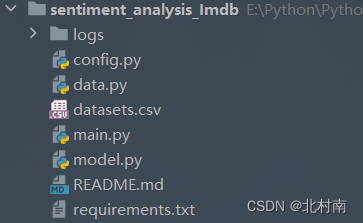
- logs 每次运行程序后的日志文件集合
- config.py 全局配置文件
- data.py 数据读取、数据清洗、数据格式转换、制作DataSet和DataLoader
- main.py 主函数,负责全流程项目运行,包括语言模型的转换,模型的训练和测试
- model.py 神经网络模型的设计和读取
二、Config
看了很多论文源代码中都使用parser容器进行全局变量的配置,因此作者也照葫芦画瓢编写了config.py文件(适配的话一般只改Base部分)
import argparse
import logging
import os
import random
import sys
import time
from datetime import datetime
import torch
def get_config():
parser = argparse.ArgumentParser()
'''Base'''
parser.add_argument('--num_classes', type=int, default=2)
parser.add_argument('--model_name', type=str, default='bert',
choices=['bert', 'roberta'])
parser.add_argument('--method_name', type=str, default='fnn',
choices=['gru', 'rnn', 'bilstm', 'lstm', 'fnn', 'textcnn', 'attention', 'lstm+textcnn',
'lstm_textcnn_attention'])
'''Optimization'''
parser.add_argument('--train_batch_size', type=int, default=4)
parser.add_argument('--test_batch_size', type=int, default=16)
parser.add_argument('--num_epoch', type=int, default=50)
parser.add_argument('--lr', type=float, default=1e-5)
parser.add_argument('--weight_decay', type=float, default=0.01)
'''Environment'''
parser.add_argument('--device', type=str, default='cpu')
parser.add_argument('--backend', default=False, action='store_true')
parser.add_argument('--workers', type=int, default=0)
parser.add_argument('--timestamp', type=int, default='{:.0f}{:03}'.format(time.time(), random.randint(0, 999)))
args = parser.parse_args()
args.device = torch.device(args.device)
'''logger'''
args.log_name = '{}_{}_{}.log'.format(args.model_name, args.method_name,
datetime.now().strftime('%Y-%m-%d_%H-%M-%S')[2:])
if not os.path.exists('logs'):
os.mkdir('logs')
logger = logging.getLogger()
logger.setLevel(logging.INFO)
logger.addHandler(logging.StreamHandler(sys.stdout))
logger.addHandler(logging.FileHandler(os.path.join('logs', args.log_name)))
return args, logger
三、Data
3.1 数据准备
首先需要下载IMDB数据集,并对其进行初步处理,其处理过程可参考一下文章IMDB数据预处理
也可以直接从Github上获取已处理好的数据集,处理好的数据格式如下
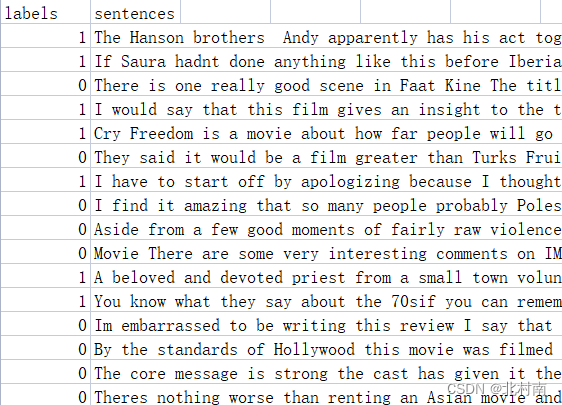
3.2 数据预处理
由于IMDB数据量非常庞大,使用全数据的训练时间非常长(算力好的小伙伴可忽略),因此这里使用10%的数据量进行训练
data = pd.read_csv('datasets.csv', sep=None, header=0, encoding='utf-8', engine='python')
len1 = int(len(list(data['labels'])) * 0.1)
labels = list(data['labels'])[0:len1]
sentences = list(data['sentences'])[0:len1]
# split train_set and test_set
tr_sen, te_sen, tr_lab, te_lab = train_test_split(sentences, labels, train_size=0.8)3.3 制作DataSet
划分训练集和测试集之后就可以制作自己的DataSet
# Dataset
train_set = MyDataset(tr_sen, tr_lab, method_name, model_name)
test_set = MyDataset(te_sen, te_lab, method_name, model_name)MyDataset的结构如下
- 使用split方法将每个单词提取出来作为后续bertToken的输入
- 后续制作DataLoader需要使用collate_fn函数因此需要重写__getitem__方法
class MyDataset(Dataset):
def __init__(self, sentences, labels, method_name, model_name):
self.sentences = sentences
self.labels = labels
self.method_name = method_name
self.model_name = model_name
dataset = list()
index = 0
for data in sentences:
tokens = data.split(' ')
labels_id = labels[index]
index += 1
dataset.append((tokens, labels_id))
self._dataset = dataset
def __getitem__(self, index):
return self._dataset[index]
def __len__(self):
return len(self.sentences)3.4 制作DataLoader
得到DataSet之后就可以制作DataLoader了
- 首先需要编写my_collate函数,该函数的功能是对每一个batch的数据进行处理
- 在这里的数据处理是将文本数据进行Tokenizer化作为后续Bert模型的输入
- 通过计算可得知80%句子的长度低于320,因此将句子长度固定为320,多截少补
- partial是Python偏函数,使用该函数后,my_collate的输入参数只有一个batch
def my_collate(batch, tokenizer):
tokens, label_ids = map(list, zip(*batch))
text_ids = tokenizer(tokens,
padding=True,
truncation=True,
max_length=320,
is_split_into_words=True,
add_special_tokens=True,
return_tensors='pt')
return text_ids, torch.tensor(label_ids) # DataLoader
collate_fn = partial(my_collate, tokenizer=tokenizer)
train_loader = DataLoader(train_set, batch_size=train_batch_size, shuffle=True, num_workers=workers,
collate_fn=collate_fn, pin_memory=True)
test_loader = DataLoader(test_set, batch_size=test_batch_size, shuffle=True, num_workers=workers,
collate_fn=collate_fn, pin_memory=True)到此我们就完成制作了DataLoader,后续从DataLoader中可获取一个个batch经Tokenizer化后的数据
四、Language model
对于网络模型来说,只能接受数字数据类型,因此我们需要建立一个语言模型,目的是将每个单词变成一个向量,每个句子变成一个矩阵。关于语言模型,其已经发展历史非常悠久了(发展历史如下),其中Bert模型是Google大神出的具有里程碑性质的模型,因此本篇博客也主要采用此模型

所用的模型都是通过API从 Hugging Face官网 中直接下载的
Hugging Face中有非常多好用的语言模型,小伙伴们也可尝试其他模型
使用AutoModel.from_pretrained接口下载预训练模型
使用AutoTokenizere.from_pretrained接口下载预训练模型的分词器
# Create model
if args.model_name == 'bert':
self.tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
self.input_size = 768
base_model = AutoModel.from_pretrained('bert-base-uncased')
elif args.model_name == 'roberta':
self.tokenizer = AutoTokenizer.from_pretrained('roberta-base', add_prefix_space=True)
self.input_size = 768
base_model = AutoModel.from_pretrained('roberta-base')
else:
raise ValueError('unknown model')下载创建好Bert之后,在训练和测试的时候,每次从DataLoadr中获取一个个经过Tokenizer分词之后Batch的数据,随后将其投放到语言模型中
- ** input :input的数据是Tokenizer化后的数据如{ 'input_id' : ~ , 'token_type_ids' : ~ , 'attention_mask' : ~},**是将里面的三个dict分成一个个独立的dict,即{ 'input_id' : ~} ,{ 'token_type_ids' : ~} ,{ 'attention_mask' : ~}
- raw_outputs获取的是Bert的输出,Bert的输出主要有四个,其中last_hidden_state表示的是最后一层隐藏层的状态,也就是每个单词的Token的集合
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state到此,上游语言模型全部结束,得到了一个个经过Bert后维度为[batch大小,句子长度,单词维度]的数据
五、Neural network model
关于RNN的原理解释,小伙伴可以看以下文章
5.1 RNN
Bilstm、lstm、gru本质上来说都是属于RNN模型,因此我们就以RNN模型为例子看看上游任务的数据是如何进入到下游文本分类的
RNN输入参数
- input_size:每个单词维度
- hidden_size:隐含层的维度(一般设置与句子长度一致)
- num_layers:RNN层数,默认是1,单层LSTM
- bias:是否使用bias
- batch_first:默认为False,如果设置为True,则表示第一个维度表示的是batch_size
- dropout:随机失活,一般在最终分类器那块写层Dropout,这里就不用了
- bidirectional:是否使用BiLSTM
由于是情感分析文本二分类任务,因此还需要一个FNN+Softmax分类器进行分类预测
class Rnn_Model(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
self.Rnn = nn.RNN(input_size=self.input_size,
hidden_size=320,
num_layers=1,
batch_first=True)
self.fc = nn.Sequential(nn.Dropout(0.5),
nn.Linear(320, 80),
nn.Linear(80, 20),
nn.Linear(20, self.num_classes),
nn.Softmax(dim=1))
for param in base_model.parameters():
param.requires_grad = (True)
再来看看RNN的传播过程
RNN输出参数
output, (hn, cn) = lstm(inputs)
output_last = output[:,-1,:]
- output:每个时间步输出
- output_last:最后一个时间步隐藏层神经元输出,也就是最终的特征表示
- hn:最后一个时间步隐藏层的状态
- cn:最后一个时间步隐藏层的遗忘门值
由于我们用不到hn和cn,因此直接使用_来代替
def forward(self, inputs):
# 上游任务
raw_outputs = self.base_model(**inputs)
cls_feats = raw_outputs.last_hidden_state
# 下游任务
outputs, _ = self.Rnn(cls_feats)
outputs = outputs[:, -1, :]
outputs = self.fc(outputs)
return outputs输出的outputs就是预测结果
5.2 GRU
其实熟悉了RNN网络模块之后,其他几个网络模块的也就非常好理解了
将nn.RNN修改为nn.GRU
class Gru_Model(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
self.Gru = nn.GRU(input_size=self.input_size,
hidden_size=320,
num_layers=1,
batch_first=True)
self.fc = nn.Sequential(nn.Dropout(0.5),
nn.Linear(320, 80),
nn.Linear(80, 20),
nn.Linear(20, self.num_classes),
nn.Softmax(dim=1))
for param in base_model.parameters():
param.requires_grad = (True)
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state
gru_output, _ = self.Gru(tokens)
outputs = gru_output[:, -1, :]
outputs = self.fc(outputs)
return outputs5.3 LSTM
将nn.RNN修改为nn.LSTM
class Lstm_Model(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
self.Lstm = nn.LSTM(input_size=self.input_size,
hidden_size=320,
num_layers=1,
batch_first=True)
self.fc = nn.Sequential(nn.Dropout(0.5),
nn.Linear(320, 80),
nn.Linear(80, 20),
nn.Linear(20, self.num_classes),
nn.Softmax(dim=1))
for param in base_model.parameters():
param.requires_grad = (True)
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state
lstm_output, _ = self.Lstm(tokens)
outputs = lstm_output[:, -1, :]
outputs = self.fc(outputs)
return outputs5.4 BILSTM
bilstm与其他几个网络模型稍微有点不同,需要修改的地方有三处
- 将nn.RNN修改为nn.LSTM
- 在nn.LSTM中添加 bidirectional=True
- 一个BILSTM是由两个LSTM组合而成的,因此FNN输入的维度也要乘2,即 nn.Linear(320 * 2, 80)
class BiLstm_Model(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
# Open the bidirectional
self.BiLstm = nn.LSTM(input_size=self.input_size,
hidden_size=320,
num_layers=1,
batch_first=True,
bidirectional=True)
self.fc = nn.Sequential(nn.Dropout(0.5),
nn.Linear(320 * 2, 80),
nn.Linear(80, 20),
nn.Linear(20, self.num_classes),
nn.Softmax(dim=1))
for param in base_model.parameters():
param.requires_grad = (True)
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
cls_feats = raw_outputs.last_hidden_state
outputs, _ = self.BiLstm(cls_feats)
outputs = outputs[:, -1, :]
outputs = self.fc(outputs)
return outputs5.5 TextCNN
既然RNN可以做文本分类,那CNN呢?答案当然是可以的,早在2014年就出现了TextCNN,原模型如下

欸,看起来可能有点抽象,看另一篇解释该模型的图可能好理解多了
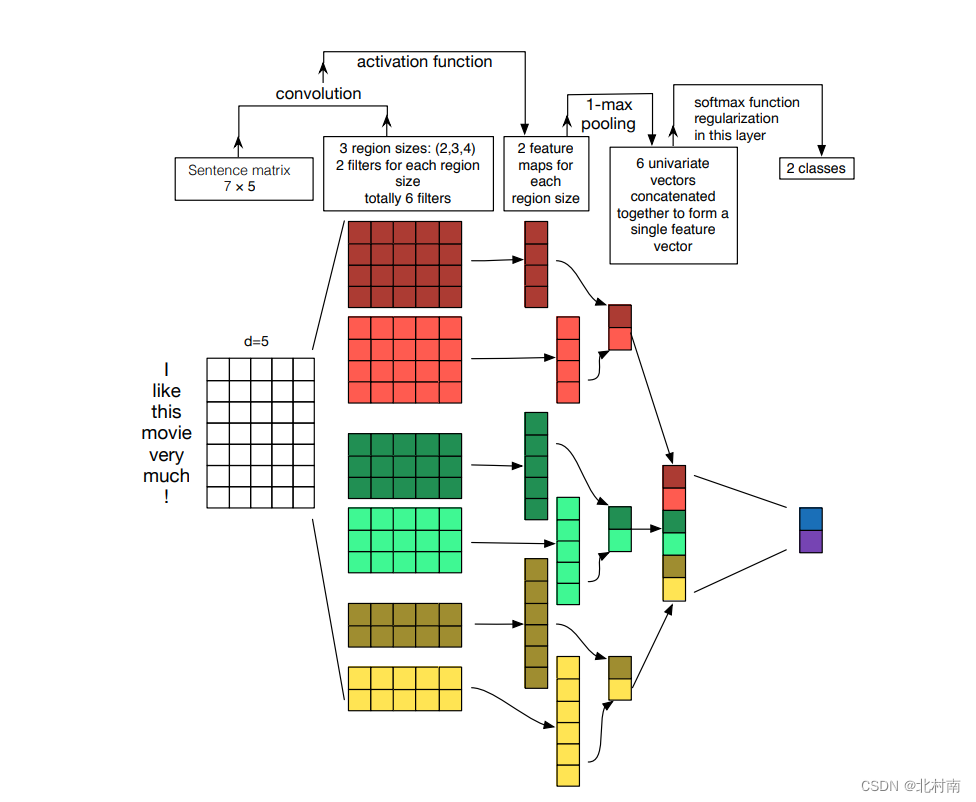
- 首先原句与卷积核分别为[2,768]、[3,768]、[4,768]且channels为2的filtet进行卷积运算得到6个一维向量
- 随后将每个一维向量中取出最大值,将这6个最大值拼接成[6,2]的Tensor
- 最后进行常规的分类预测
- 注意nn.ModuleList的Pytorch代码技巧,ModuleList可以理解为可存储卷积核的List
class TextCNN_Model(nn.Module):
def __init__(self, base_model, num_classes):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
for param in base_model.parameters():
param.requires_grad = (True)
# Define the hyperparameters
self.filter_sizes = [2, 3, 4]
self.num_filters = 2
self.encode_layer = 12
# TextCNN
self.convs = nn.ModuleList(
[nn.Conv2d(in_channels=1, out_channels=self.num_filters,
kernel_size=(K, self.base_model.config.hidden_size)) for K in self.filter_sizes]
)
self.block = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(self.num_filters * len(self.filter_sizes), self.num_classes),
nn.Softmax(dim=1)
)
def conv_pool(self, tokens, conv):
tokens = conv(tokens)
tokens = F.relu(tokens)
tokens = tokens.squeeze(3)
tokens = F.max_pool1d(tokens, tokens.size(2))
out = tokens.squeeze(2)
return out
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state.unsqueeze(1)
out = torch.cat([self.conv_pool(tokens, conv) for conv in self.convs],
1)
predicts = self.block(out)
return predicts5.7 FNN
因为我们使用的是Bert模型,其模型本身是由12层Transformer组成,每层Transformer又由复杂的Attention网络组成,所以Bert模型本身就是一个非常好的网络模型,所以可能我不太需要加RNN、CNN这些操作,直接使用FNN或许也可以实现不错的效果(7.Result部分的消融实验也证实了该想法)。
在讲解这个代码之前,不得不再次提起Bert的输出了,输入一个句子,Bert的输出是
【CLS】token1 token 2 token3 token4 ... token n 【SEP】
token表示每个输入单词的向量 ,【CLS】表示整个句子的向量,做FNN需要整个句子的输入,因此我们需要获取的是【CLS】。【CLS】是隐层0号位的数据,因此具体获取【CLS】的代码是
cls_feats = raw_outputs.last_hidden_state[:, 0, :]完整FNN网络模块代码如下
class Transformer(nn.Module):
def __init__(self, base_model, num_classes, input_size):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
self.input_size = input_size
self.linear = nn.Linear(base_model.config.hidden_size, num_classes)
self.dropout = nn.Dropout(0.5)
self.softmax = nn.Softmax()
for param in base_model.parameters():
param.requires_grad = (True)
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
cls_feats = raw_outputs.last_hidden_state[:, 0, :]
predicts = self.softmax(self.linear(self.dropout(cls_feats)))
return predicts5.8 Self-Attention
RNN和CNN都介绍过了,那Attention机制怎么能少呢?
关于Self-Attention的细节,可以参考这篇文章
在这里,为了方便对着公式阅读代码,我将Attention的公式放置如下
class Transformer_Attention(nn.Module):
def __init__(self, base_model, num_classes):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
for param in base_model.parameters():
param.requires_grad = (True)
# Self-Attention
self.key_layer = nn.Linear(self.base_model.config.hidden_size, self.base_model.config.hidden_size)
self.query_layer = nn.Linear(self.base_model.config.hidden_size, self.base_model.config.hidden_size)
self.value_layer = nn.Linear(self.base_model.config.hidden_size, self.base_model.config.hidden_size)
self._norm_fact = 1 / math.sqrt(self.base_model.config.hidden_size)
self.block = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(768, 128),
nn.Linear(128, 16),
nn.Linear(16, num_classes),
nn.Softmax(dim=1)
)
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state
K = self.key_layer(tokens)
Q = self.query_layer(tokens)
V = self.value_layer(tokens)
attention = nn.Softmax(dim=-1)((torch.bmm(Q, K.permute(0, 2, 1))) * self._norm_fact)
attention_output = torch.bmm(attention, V)
attention_output = torch.mean(attention_output, dim=1)
predicts = self.block(attention_output)
return predicts5.9 TextCNN+LSTM
在这里,我先抛出一个问题,我们为什么要用CNN和LSTM,它究竟有什么好处?
TextCNN是使用了卷积机制,提取了文本中最关键的信息,也就是最具有区分性的信息,比如5.5中的TextCNN展示图,一个7*5如此大的矩阵,最终竟然只用6*1的向量就可表征了
而LSTM恰巧相反,它是不断地关注了时间序列中每个隐藏层状态,目的是挖掘出深藏的语义信息
因此,我们可以将TextCNN和LSTM结合起来,就像你考CET6阅读理解一样一样,既要抓取最显著的信息快速判断,又要细读文章内容,理解内含的语义信息,二者结合来便于判断
说了这么多,看看代码到底如何实现
class Transformer_CNN_RNN(nn.Module):
def __init__(self, base_model, num_classes):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
for param in base_model.parameters():
param.requires_grad = (True)
# Define the hyperparameters
self.filter_sizes = [3, 4, 5]
self.num_filters = 100
# TextCNN
self.convs = nn.ModuleList(
[nn.Conv2d(in_channels=1, out_channels=self.num_filters,
kernel_size=(K, self.base_model.config.hidden_size)) for K in self.filter_sizes]
)
# LSTM
self.lstm = nn.LSTM(input_size=self.base_model.config.hidden_size,
hidden_size=320,
num_layers=1,
batch_first=True)
self.block = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(620, 128),
nn.Linear(128, 16),
nn.Linear(16, num_classes),
nn.Softmax(dim=1)
)
def conv_pool(self, tokens, conv):
# x -> [batch,1,text_length,768]
tokens = conv(tokens) # shape [batch_size, out_channels, x.shape[2] - conv.kernel_size[0] + 1, 1]
tokens = F.relu(tokens)
tokens = tokens.squeeze(3) # shape [batch_size, out_channels, x.shape[2] - conv.kernel_size[0] + 1]
tokens = F.max_pool1d(tokens, tokens.size(2)) # shape[batch, out_channels, 1]
out = tokens.squeeze(2) # shape[batch, out_channels]
return out
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
cnn_tokens = raw_outputs.last_hidden_state.unsqueeze(1) # shape [batch_size, 1, max_len, hidden_size]
cnn_out = torch.cat([self.conv_pool(cnn_tokens, conv) for conv in self.convs],
1) # shape [batch_size, self.num_filters * len(self.filter_sizes]
rnn_tokens = raw_outputs.last_hidden_state
rnn_outputs, _ = self.lstm(rnn_tokens)
rnn_out = rnn_outputs[:, -1, :]
# cnn_out --> [batch,300]
# rnn_out --> [batch,320]
out = torch.cat((cnn_out, rnn_out), 1)
predicts = self.block(out)
return predict5.10 Attention+LSTM+TextCNN
既然我们的网络模型同时加了LSTM和TextCNN,那Attention怎么能少呢?
从IO角度来看Self-Attention,它输入是什么尺寸的矩阵,输出也是什么尺寸的矩阵,因此一个简单的做法就是将Bert的输出,先放到Attention模块中,将Attention的输出放到后续的Lstm和TexCNN
代码如下
class Transformer_CNN_RNN_Attention(nn.Module):
def __init__(self, base_model, num_classes):
super().__init__()
self.base_model = base_model
self.num_classes = num_classes
for param in base_model.parameters():
param.requires_grad = (True)
# Define the hyperparameters
self.filter_sizes = [3, 4, 5]
self.num_filters = 100
# TextCNN
self.convs = nn.ModuleList(
[nn.Conv2d(in_channels=1, out_channels=self.num_filters,
kernel_size=(K, self.base_model.config.hidden_size)) for K in self.filter_sizes]
)
# LSTM
self.lstm = nn.LSTM(input_size=self.base_model.config.hidden_size,
hidden_size=320,
num_layers=1,
batch_first=True)
# Self-Attention
self.key_layer = nn.Linear(self.base_model.config.hidden_size, self.base_model.config.hidden_size)
self.query_layer = nn.Linear(self.base_model.config.hidden_size, self.base_model.config.hidden_size)
self.value_layer = nn.Linear(self.base_model.config.hidden_size, self.base_model.config.hidden_size)
self._norm_fact = 1 / math.sqrt(self.base_model.config.hidden_size)
self.block = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(620, 128),
nn.Linear(128, 16),
nn.Linear(16, num_classes),
nn.Softmax(dim=1)
)
def conv_pool(self, tokens, conv):
# x -> [batch,1,text_length,768]
tokens = conv(tokens) # shape [batch_size, out_channels, x.shape[2] - conv.kernel_size[0] + 1, 1]
tokens = F.relu(tokens)
tokens = tokens.squeeze(3) # shape [batch_size, out_channels, x.shape[2] - conv.kernel_size[0] + 1]
tokens = F.max_pool1d(tokens, tokens.size(2)) # shape[batch, out_channels, 1]
out = tokens.squeeze(2) # shape[batch, out_channels]
return out
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state
# Self-Attention
K = self.key_layer(tokens)
Q = self.query_layer(tokens)
V = self.value_layer(tokens)
attention = nn.Softmax(dim=-1)((torch.bmm(Q, K.permute(0, 2, 1))) * self._norm_fact)
attention_output = torch.bmm(attention, V)
# TextCNN
cnn_tokens = attention_output.unsqueeze(1) # shape [batch_size, 1, max_len, hidden_size]
cnn_out = torch.cat([self.conv_pool(cnn_tokens, conv) for conv in self.convs],
1) # shape [batch_size, self.num_filters * len(self.filter_sizes]
rnn_tokens = tokens
rnn_outputs, _ = self.lstm(rnn_tokens)
rnn_out = rnn_outputs[:, -1, :]
# cnn_out --> [batch,300]
# rnn_out --> [batch,320]
out = torch.cat((cnn_out, rnn_out), 1)
predicts = self.block(out)
return predicts六、Train and Test
最后就是编写对应的训练函数和测试函数啦
可能有些小伙伴不懂tqdm函数,它的功能就是能显示动态进度,如下图所示

训练函数
注意要开启训练模式,即self.Mymodel.train(),如此有些层如dropout层参数可以进行更新
def _train(self, dataloader, criterion, optimizer):
train_loss, n_correct, n_train = 0, 0, 0
# Turn on the train mode
self.Mymodel.train()
for inputs, targets in tqdm(dataloader, disable=self.args.backend, ascii='>='):
inputs = {k: v.to(self.args.device) for k, v in inputs.items()}
targets = targets.to(self.args.device)
predicts = self.Mymodel(inputs)
loss = criterion(predicts, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * targets.size(0)
n_correct += (torch.argmax(predicts, dim=1) == targets).sum().item()
n_train += targets.size(0)
return train_loss / n_train, n_correct / n_train测试函数
注意要开启验证模式,即self.Mymodel.eval(),如此有些层如dropout参数不会更新了
def _test(self, dataloader, criterion):
test_loss, n_correct, n_test = 0, 0, 0
# Turn on the eval mode
self.Mymodel.eval()
with torch.no_grad():
for inputs, targets in tqdm(dataloader, disable=self.args.backend, ascii=' >='):
inputs = {k: v.to(self.args.device) for k, v in inputs.items()}
targets = targets.to(self.args.device)
predicts = self.Mymodel(inputs)
loss = criterion(predicts, targets)
test_loss += loss.item() * targets.size(0)
n_correct += (torch.argmax(predicts, dim=1) == targets).sum().item()
n_test += targets.size(0)
return test_loss / n_test, n_correct / n_test
最后在run函数中进行多次训练和获取最佳训练准确率
# Get the best_loss and the best_acc
best_loss, best_acc = 0, 0
for epoch in range(self.args.num_epoch):
train_loss, train_acc = self._train(train_dataloader, criterion, optimizer)
test_loss, test_acc = self._test(test_dataloader, criterion)
if test_acc > best_acc or (test_acc == best_acc and test_loss < best_loss):
best_acc, best_loss = test_acc, test_loss
七、Result
到了最快乐的炼丹时间,看看最终的效果怎么样
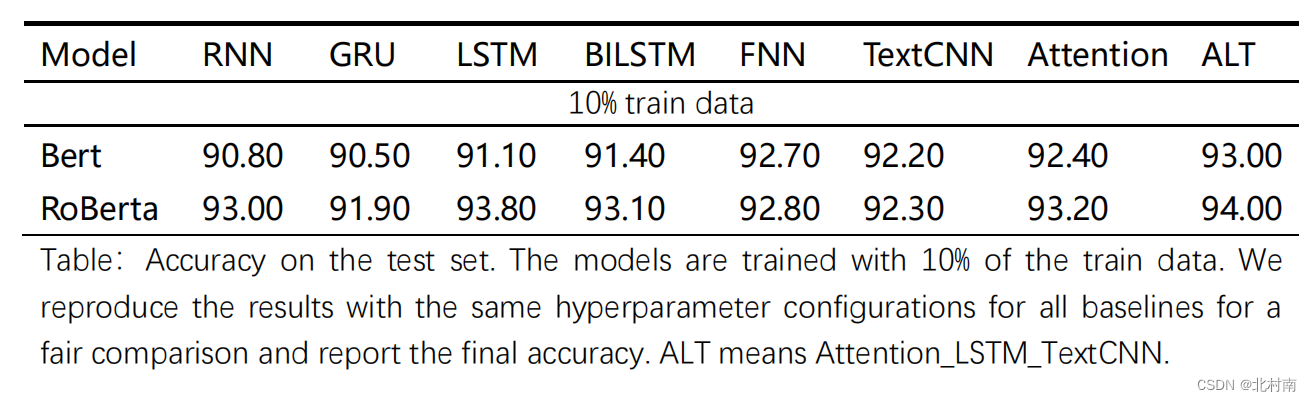
分析
- 总体表现看,ALT效果最好,终究是缝合怪赢了
- 从PLM角度看,Roberta较Bert好,不愧为升级版Bert
- FNN效果也不错,这是由于PLM本身携带了大量的参数,模型已经足够复杂了
- 纯TextCNN的效果有点鸡肋,因为CNN主要关注局部而RNN关注全局。
八、Conclusion
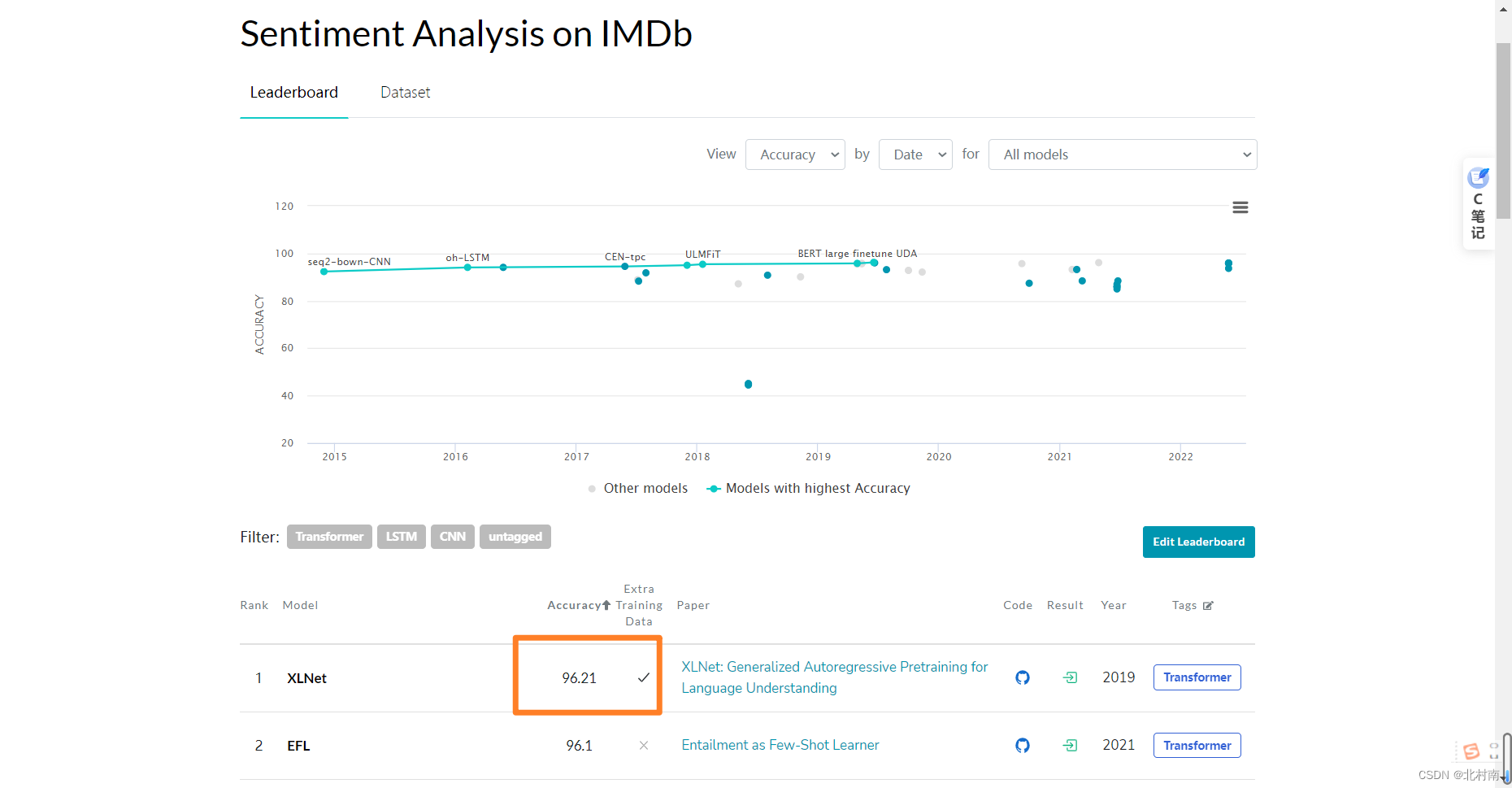
目前该数据集的SOTA是使用XLNet模型跑的96.21%,本模型只是用了10%的数据集+简单的网络架构+未调参就可以达到93%的准确率,效果还是不错的
白嫖时,麻烦大佬们动动鼠标给个star,这对我很重要
九、Reference
[1] Yoon Kim. 2014. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 1746–1751, Doha, Qatar. Association for Computational Linguistics.
[2] Vaswani, A. , Shazeer, N. , Parmar, N. , Uszkoreit, J. , Jones, L. , & Gomez, A. N. , et al. (2017). Attention is all you need. arXiv.
十、Another question(2023-11)
汇总一些评论区或私信的一些问题
Question 1:Add precision,recall,specificity and f1_scall?
在文本分类中一般是只使用Accuracy作为评判标准,因此其他的标准就没有放到开源代码中了,若想实现这些功能,在train()、test()中进行修改代码即可,在这里我以train()函数为例
现放上修改后完整的train()代码
def _train(self, dataloader, criterion, optimizer):
train_loss, n_correct, n_train = 0, 0, 0
# Confusion matrix
TP, TN, FP, FN = 0, 0, 0, 0
# Turn on the train mode
self.Mymodel.train()
for inputs, targets in tqdm(dataloader, disable=self.args.backend, ascii='>='):
inputs = {k: v.to(self.args.device) for k, v in inputs.items()}
targets = targets.to(self.args.device)
predicts = self.Mymodel(inputs)
loss = criterion(predicts, targets)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item() * targets.size(0)
n_correct += (torch.argmax(predicts, dim=1) == targets).sum().item()
n_train += targets.size(0)
ground_truth = targets
predictions = torch.argmax(predicts, dim=1)
TP += torch.logical_and(predictions.bool(), ground_truth.bool()).sum().item()
FP += torch.logical_and(predictions.bool(), ~ground_truth.bool()).sum().item()
FN += torch.logical_and(~predictions.bool(), ground_truth.bool()).sum().item()
TN += torch.logical_and(~predictions.bool(), ~ground_truth.bool()).sum().item()
precision = TP / (TP + FP)
recall = TP / (TP + FN)
specificity = TN / (TN + FP)
f1_score = 2 * precision * recall / (precision + recall)
return train_loss / n_train, n_correct / n_train, precision, recall, specificity, f1_scoretargets就是真实的标签,那预测结果呢,是predicts吗?当然不是,因为predicts中是预测每条句子的情感类别是positive和negative分别概率是多少,比如一条句子的预测结果是【0.2,0.8】,那么我们需要将该句的判定结果为0.8,也就是下标1,所以torch.argmax(predicts,dim=1)才是真正的预测结果。
有了这两个之后,我们便可以计算混淆矩阵,这里我使用了logical_and和bool()函数的技巧去实现它,而没有直接用各种库函数,目的是为了展示我是如何处理数据的,这样如果大家想要有其他评判标准也可以由此借鉴。
Question 2:Run so slowly?
在config.py,设置的默认环境为CPU,以及train_batch_size和test_batch_size都设置较小,目的是先跑通该程序,随后按自己资源配置来扩大batch_size以及将cpu改成cuda

Question 3:Improve the acc?
可能很多小伙伴在用了自己的数据集后发现准确率可能停在80%,我估计原因可能是:数据集质量(可进一步数据清理),参数调优问题
此外,也可以考虑融入更多的的模块,比如Prompt learning、Contrastive learning,CapsuleNet,Dual learning。再或者采用性能更优质的预训练大语言模型,比如Roberta-Large
也可以尝试最简单的模块,比如Layer Normalization、Batch Normalization、新的激活函数等等
在这里我展示Layer Normalization的技巧模块
以下取自LSTM的网络部分,大家需要关注的是#Layer Normalization下的两行代码
def forward(self, inputs):
raw_outputs = self.base_model(**inputs)
tokens = raw_outputs.last_hidden_state
lstm_output, _ = self.Lstm(tokens)
# Layer Normalization
norm_lstm = nn.LayerNorm([lstm_output.shape[1], lstm_output.shape[2]], eps=1e-8).cuda()
ln_lstm = norm_lstm(lstm_output)
outputs = lstm_output[:, -1, :]
outputs = self.fc(outputs)
return outputsQuestion 4: Adapt to own dataset?
想要适配自己数据集,比如一个新闻主题6分类,代码如何修改呢?
一个快速做法是首先保证数据集格式与IMDB格式一致
1)修改config.py文件中num_classes为6
2)修改data.py文件中max_length(文中已解释该变量)
Question 5:Add prompt learning module
提示学习的策略非常的多,具体可看刘鹏飞教授系统整理的《Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing》
这里附上提示学习分类图。首先将目光瞄向Prompt-based Training Strategies。文中一共介绍了5种训练方法,由于自己项目采用Fine-Tuning范式,与之类似的可以考虑Prompt-Tuning范式。传统的提示学习方法是将[MASK]做MLM任务,将其映射到词表中。
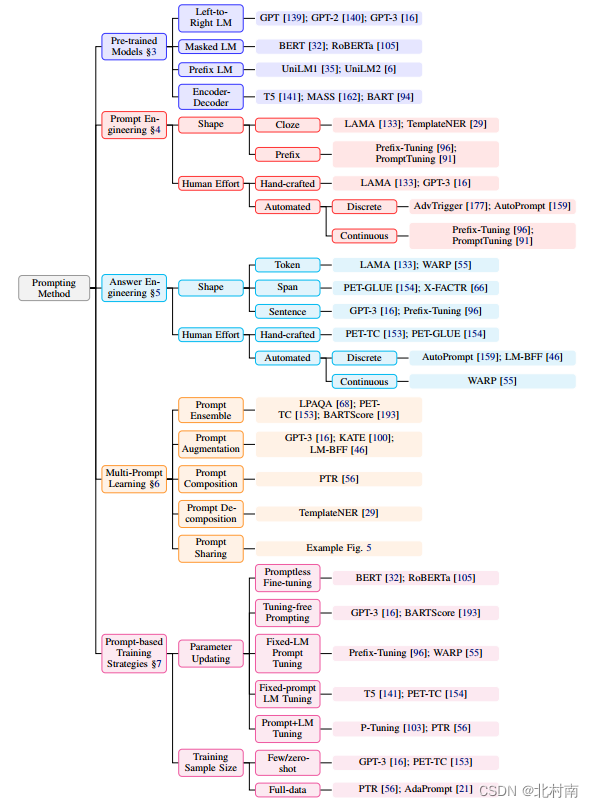
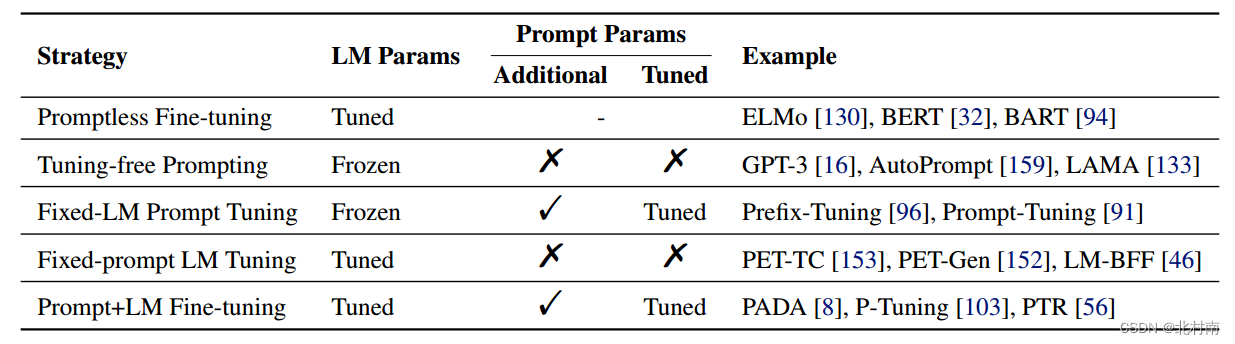
假如换种思路,将[MASK]视为与整个句子具有类似情感倾向的Token。
这里给出一种方案:从离散提示角度构建一个提示模板:This is too [MASK]。添加到原始文本序列中,注意提示模板有两种添加方式
① [CLS] The movie is remarkable [SEP] That is too [MASK] [SEP]
② [CLS] That is too [MASK] [SEP] The movie is remarkable [SEP]
读者可以将两种方式都去试试看,一般来说第①种方式的效果会更好一些
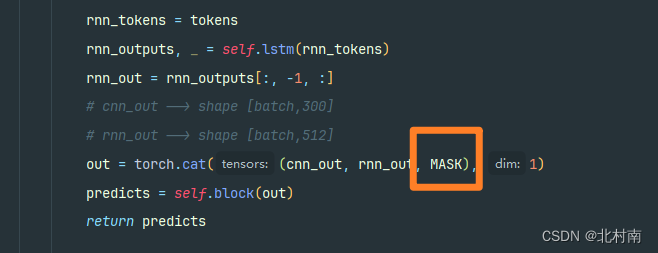
将新序列输入到Bert中进行Embedding编码,随后直接取出[MASK]对应的Token向量,尺寸大小为1*768。再取出TextCNN和LSTM提取的表征向量,联合[MASK]进行特征聚合得到最后的文本表征。输入到全连接分类器中即可。
关键代码修改部分
修改一:将模板添加到原始文本序列中

修改二:两种提示模板的实现难度是不一样的,因为在获取[MASK]的时候,第①种[MASK]的位置是随着样本内容变化而改变的,而第②种[MASK]位置是不变的。所以在这里介绍第①种该如何实现。由于文本输入到Bert种,首先会对token查找词表得到text_ids,而bert中[MASK]对应的序列号为103,所以需要先获取序号为103的下标位置mask_index

再根据mask_index取出对应的[MASK]向量
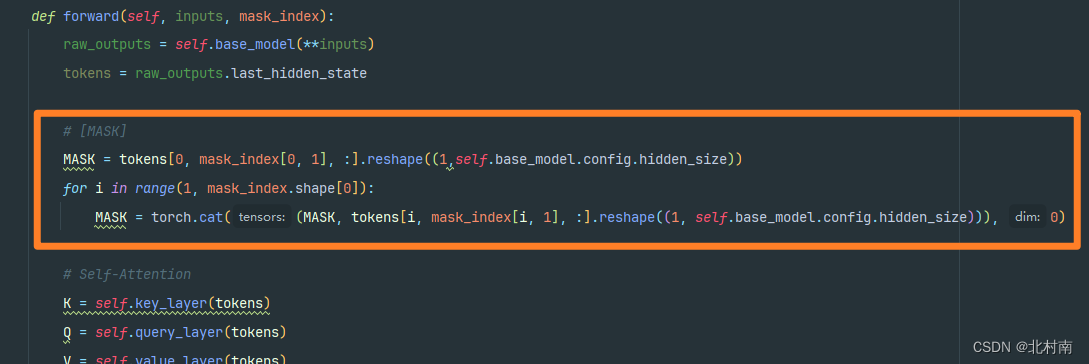
修改三:提取的三种文本表征进行信息聚合
Question 6:Save or load model
采用torch.save(***)保存模型

采用torch.load(***)加载模型

加载模型只需要验证无需训练,注意关掉训练代码

关注本博客,后期推出融合对偶理论、提示学习、对比学习、扩散模型模块的文章,希望大家多多关注。(有做这块内容的小伙伴欢迎交流!)
(2024-04) 很高兴有这么多小伙伴关注这篇文章,上年博主一边考研一边发论文,最终考研总分过了,但是408单科线被卡,主要问题还是复习不扎实,CO和OS大题30分基本空着;三篇论文到现在也还没有AC,核心的那篇CCFB处于第三次返修了。害,蛮糟糕的一年
考虑后决定二战,所以继续断更半年。这次将Prompt-Tuning更新到本项目中,并构建了新模型,关于对比学习,生成式技术,对偶理论如何融合,或许要等到今年12月考完了。
祝大家都能炼丹顺利,早日accept!!!
智能推荐
laravel注册页面(jquery验证)_$("#coderandom").val(data.message)-程序员宅基地
文章浏览阅读792次。html<form class="reg_info" action="" method="post"> <div class="col-md-6 login-do1 animated wow fadeInLeft" data-wow-delay=".5s"> @if(count($errors)>0) @if_$("#coderandom").val(data.message)
texstudio统计字数-程序员宅基地
文章浏览阅读2.5w次,点赞10次,收藏8次。texstudio:工具-分析文本不同的词组70个,意思是有70个单词_texstudio统计字数
python 七大数据类型-程序员宅基地
文章浏览阅读213次。python 七大数据类型
吉时利Keithley 4200-SCS参数分析仪_吉时利了4200-scs-程序员宅基地
文章浏览阅读51次。它可以帮助研究人员对不同材料的电学特性进行准确测量和分析。-KEITHLEY吉时利4200-SCS半导体特性分析系统还被广泛应用于功率器件的研究和测试。-在光电子学领域,KEITHLEY吉时利4200-SCS半导体特性分析系统可用于测量光电二极管和太阳能电池等器件的性能。它为学生和研究人员提供了一个实验平台,可以进行各种半导体器件的测量和分析实验,促进他们的学习和研究成果。-在半导体器件制造过程中,KEITHLEY吉时利4200-SCS半导体特性分析系统可用于对制造过程中的器件进行测试和质量控制。_吉时利了4200-scs
Casey 正统 Runes 协议的发行和转账|本地 Bitcoin 网络实操_比特币符文部署教程-程序员宅基地
文章浏览阅读991次,点赞22次,收藏18次。Casey 正统 Runes 协议的发行和转账|本地 Bitcoin 网络实操 _比特币符文部署教程
java outputstream api_java – 从OutputStream创建一个文件-程序员宅基地
文章浏览阅读648次。我有这个问题,我正在创建一个文件,但这是创建空文件.我使用的是Dropbox的API,Dropbox的代码运行良好,但我不知道我不好.我已经为我的应用程序使用了2º和3º代码,这是运行良好.这通过分层次操作.我正在发送outputStream用于功能.但这是空的.我正在使用outputStream,因为我需要它与outputstream一起运行.1º代码(Class Test || Call):F..._outputstream生成文件
随便推点
如何使用 ESlint + prettier 建立规范的vue3.0项目_eslint和vue3.0-程序员宅基地
文章浏览阅读1k次。如何使用 ESlint + prettier 建立规范的vue3.0项目前言 一个完整的项目必然是多人合作的开发项目,为了提升代码的质量,统一代码风格成了每个优秀的项目的必然选择,本期用现在最流行的ESlint + prettier在VUE3.0的环境下建立一个自动格式化符合eslint标准规范的项目。1 如何配置文件1 新建VUE3.0的项目 使用配置如下图 不一定要完全依照下面配置..._eslint和vue3.0
Android开发之PopupWindow(实现弹窗)_android popupwindow-程序员宅基地
文章浏览阅读6.8k次,点赞8次,收藏36次。包括唤出弹窗、弹窗内容的自定义与监听。_android popupwindow
TOMCAT 中间件安全加固_中间件加固方案-程序员宅基地
文章浏览阅读228次。对于一些常见的错误页面,我们可以在配置文件/etc/tomcat/web.xml中,重定向403、404以及500错误到指定页面。在这里插入图片描述我们现在在web.xml配置文件中加入error-page参数。在这里插入图片描述我们现在编辑我们的错误页面。该错误页默认放在我们webapps目录中。在这里插入图片描述这里是我们tomcat默认的页面所在位置。在这里插入图片描述重启tomcat服务,我们可以看到,页面为我们自定义的错误页面了。在这里插入图片描述。_中间件加固方案
layui实现数据表格table的搜索功能_layui table查询-程序员宅基地
文章浏览阅读3.1k次,点赞2次,收藏10次。layui根据特定信息对表格进行搜索并显示效果实现html部分js部分Controller层Mapper层注意总结效果先放效果图此处根据“角色名称”进行搜索,得到效果实现html部分此处注意!!需要要为input、table里边加上“id”属性,在js部分需要特定进行获取。<div class="layuimini-container"> <div class="layuimini-main"> _layui table查询
机器学习中的数学——深度学习优化的挑战:病态_优化函数 病态-程序员宅基地
文章浏览阅读1.5w次,点赞5次,收藏7次。优化通常是一个极其困难的任务。传统的机器学习会小心设计目标函数和约束,以确保优化问题是凸的,从而避免一般优化问题的复杂度。在训练神经网络时,我们肯定会遇到一般的非凸情况。即使是凸优化,也并非没有任何问题。在本文中,我们会总结几个训练深度模型时会涉及的主要挑战。病态在优化凸函数时,会遇到一些挑战。这其中最突出的是Hessian矩阵HHH的病态。这是数值优化、凸优化或其他形式的优化中普遍存在的问题。病态问题一般被认为存在于神经网络训练过程中。病态体现在随机梯度下降会“卡”在某些情况,此时即使很小的更新步长也_优化函数 病态
Spring Boot配置文件_server: port: 8084 spring: application: name: insi-程序员宅基地
文章浏览阅读356次。idea小技巧:Alt+Ins:快速调出getter、setter方法或toString等方法。二、配置文件1、配置文件SpringBoot使用一个全局的配置文件,配置文件名是固定的;application.propertiesapplication.yml配置文件的作用:修改SpringBoot自动配置的默认值;SpringBoot在底层都给我们自动配置好;YAML(YAML Ain’t Markup Language) YAML A Markup Langu._server: port: 8084 spring: application: name: insideoperation-server profile