基于深度正则化的少镜头图像三维高斯溅射优化-程序员宅基地
Depth-Regularized Optimization for 3D Gaussian Splatting in Few-Shot Images
基于深度正则化的少镜头图像三维高斯溅射优化
郑在义 1 郑泽吴 2 李京慕 1,2
1Department of ECE, ASRI, Seoul National University, Seoul, Korea
1 韩国首尔,首尔国立大学,ASRI,ECE系
2IPAI, ASRI, Seoul National University, Seoul, Korea
2 IPAI,ASRI,首尔国立大学,首尔,韩国
{robot0321, ohjtgood, kyoungmu}@snu.ac.kr
@snu.ac.kr
Abstract 摘要 [2311.13398] Depth-Regularized Optimization for 3D Gaussian Splatting in Few-Shot Images
In this paper, we present a method to optimize Gaussian splatting with a limited number of images while avoiding overfitting. Representing a 3D scene by combining numerous Gaussian splats has yielded outstanding visual quality. However, it tends to overfit the training views when only a small number of images are available. To address this issue, we introduce a dense depth map as a geometry guide to mitigate overfitting. We obtained the depth map using a pre-trained monocular depth estimation model and aligning the scale and offset using sparse COLMAP feature points. The adjusted depth aids in the color-based optimization of 3D Gaussian splatting, mitigating floating artifacts, and ensuring adherence to geometric constraints. We verify the proposed method on the NeRF-LLFF dataset with varying numbers of few images. Our approach demonstrates robust geometry compared to the original method that relies solely on images.
在本文中,我们提出了一种方法来优化有限数量的图像,同时避免过拟合的高斯飞溅。通过组合众多高斯splats来表示3D场景,产生了出色的视觉质量。然而,当只有少量图像可用时,它往往会过拟合训练视图。为了解决这个问题,我们引入了一个密集的深度图作为几何指导,以减轻过拟合。我们使用预训练的单目深度估计模型获得深度图,并使用稀疏COLMAP特征点对齐尺度和偏移。调整后的深度有助于3D高斯飞溅的基于颜色的优化,减轻浮动伪影,并确保遵守几何约束。我们在NeRF-LLFF数据集上验证了所提出的方法,这些数据集具有不同数量的少量图像。与仅依赖于图像的原始方法相比,我们的方法展示了强大的几何形状。
1Introduction 1介绍
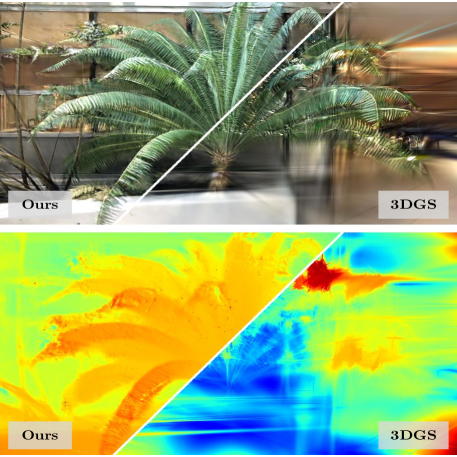
Figure 1:The efficacy of depth regularization in a few-shot setting We optimize Gaussian splats with a limited number of images, avoiding overfitting through the geometry guidance estimated from the images. Please note that we utilized only two images to create this 3D scene.
图一:深度正则化在少数镜头设置中的功效我们用有限数量的图像优化高斯splats,通过从图像估计的几何指导避免过拟合。请注意,我们只使用了两个图像来创建这个3D场景。
Reconstruction of three-dimensional space from images has long been a challenge in the computer vision field. Recent advancements show the feasibility of photorealistic novel view synthesis [3, 31], igniting research into reconstructing a complete 3D space from images. Driven by progress in computer graphics techniques and industry demand, particularly in sectors such as virtual reality [14] and mobile [11], research on achieving high-quality and high-speed real-time rendering has been ongoing. Among the recent notable developments, 3D Gaussian Splatting (3DGS) [23] stands out through its combination of high quality, rapid reconstruction speed, and support for real-time rendering. 3DGS employs Gaussian attenuated spherical harmonic splats [38, 12] with opacity as primitives to represent every part of a scene. It guides the splats to construct a consistent geometry by imposing a constraint on the splats to satisfy multiple images at the same time.
从图像重建三维空间一直是计算机视觉领域的一个挑战。最近的进展显示了真实感新颖视图合成的可行性[3,31],引发了从图像重建完整3D空间的研究。在计算机图形技术进步和行业需求的推动下,特别是在虚拟现实[14]和移动的[11]等领域,实现高质量和高速实时渲染的研究一直在进行中。在最近的显着发展中,3D高斯溅射(3DGS)[23]通过其高质量,快速重建速度和支持实时渲染的组合脱颖而出。3DGS采用高斯衰减球谐splats [38,12]与不透明度作为图元来表示场景的每个部分。它通过对splats施加约束来引导splats构造一致的几何形状,以同时满足多个图像。
The approach of aggregating small splats for a scene provides the capability to express intricate details, yet it is prone to overfitting due to its local nature. 3DGS [24] optimizes independent splats according to multi-view color supervision without global structure. Therefore, in the absence of a sufficient quantity of images that can offer a global geometric cue, there exists no precaution against overfitting. This issue becomes more pronounced as the number of images used for optimizing a 3D scene is small. The limited geometric information from a few number of images leads to an incorrect convergence toward a local optimum, resulting in optimization failure or floating artifacts as shown in Figure 1. Nevertheless, the capability to reconstruct a 3D scene with a restricted number of images is crucial for practical applications, prompting us to tackle the few-shot optimization problem.
为场景聚合小splats的方法提供了表达复杂细节的能力,但由于其局部性质,它易于过拟合。3DGS [24]根据没有全局结构的多视图颜色监督优化独立splats。因此,在没有足够数量的图像可以提供全局几何线索的情况下,不存在针对过拟合的预防措施。当用于优化3D场景的图像数量较少时,该问题变得更加明显。来自少数图像的有限几何信息导致向局部最优值的不正确收敛,从而导致优化失败或浮动伪影,如图1所示。然而,具有有限数量的图像重建3D场景的能力对于实际应用至关重要,这促使我们解决少镜头优化问题。
One intuitive solution is to supplement an additional geometric cue such as depth. In numerous 3D reconstruction contexts [6], depth proves immensely valuable for reconstructing 3D scenes by providing direct geometric information. To obtain such robust geometric cues, depth sensors aligned with RGB cameras are employed. Although these devices offer dense depth maps with minimal error, the necessity for such equipment also presents obstacles to practical applications.
一个直观的解决方案是补充额外的几何线索,如深度。在许多3D重建背景下[6],深度证明通过提供直接的几何信息来重建3D场景非常有价值。为了获得这种鲁棒的几何线索,采用与RGB相机对准的深度传感器。虽然这些设备提供了具有最小误差的密集深度图,但对这种设备的必要性也对实际应用构成了障碍。
Hence, we attain a dense depth map by adjusting the output of the depth estimation network with a sparse depth map from the renowned Structure-from-Motion (SfM), which computes the camera parameters and 3D feature points simultaneously. 3DGS also uses SfM, particularly COLMAP [41], to acquire such information. However, the SfM also encounters a notable scarcity in the available 3D feature points when the number of images is few. The sparse nature of the point cloud also makes it impractical to regularize all Gaussian splats. Hence, a method for inferring dense depth maps is essential. One of the methods to extract dense depth from images is by utilizing monocular depth estimation models. While these models are able to infer dense depth maps from individual images based on priors obtained from the data, they produce only relative depth due to scale ambiguity. Since the scale ambiguity leads to critical geometry conflicts in multi-view images, we need to adjust scales to prevent conflicts between independently inferred depths. We show that this can be done by fitting a sparse depth, which is a free output from COLMAP [41] to an estimated dense depth map.
因此,我们通过调整深度估计网络的输出来获得密集的深度图,该深度图具有来自著名的运动恢复结构(SfM)的稀疏深度图,该深度图同时计算相机参数和3D特征点。3DGS还使用SfM,特别是COLMAP [41]来获取这些信息。然而,SfM也遇到了一个显着的稀缺性,在可用的3D特征点时,图像的数量很少。点云的稀疏性质也使得正则化所有高斯splats变得不切实际。因此,用于推断密集深度图的方法是必不可少的。从图像中提取密集深度的方法之一是利用单目深度估计模型。虽然这些模型能够根据从数据中获得的先验知识从单个图像中推断出密集的深度图,但由于尺度模糊性,它们仅产生相对深度。 由于尺度模糊性导致多视图图像中的关键几何冲突,因此我们需要调整尺度以防止独立推断的深度之间的冲突。我们表明,这可以通过拟合稀疏深度来完成,这是从COLMAP [41]到估计的密集深度图的自由输出。
In this paper, we propose a method to represent 3D scenes using a small number of RGB images leveraging prior information from a pre-trained monocular depth estimation model [5] and a smoothness constraint. We adapt the scale and offset of the estimated depth to the sparse COLMAP points, solving the scale ambiguity. We use the adjusted depth as a geometry guide to assist color-based optimization, reducing floating artifacts and satisfying geometry conditions. We observe that even the revised depth helps guide the scene to geometrically optimal solution despite its roughness. We prevent the overfitting problem by incorporating an early stop strategy, where the optimization process stops when the depth-guide loss starts to rise. Moreover, to achieve more stability, we apply a smoothness constraint, ensuring that neighbor 3D points have similar depths. We adopt 3DGS as our baseline and compare the performance of our method in the NeRF-LLFF [30] dataset. We confirm that our strategy leads to plausible results not only in terms of RGB novel-view synthesis but also 3D geometry reconstruction. Through further experiments, we demonstrate the influence of geometry cues such as depth and initial points on Gaussian splatting. They significantly influence the stable optimization of Gaussian splatting.
在本文中,我们提出了一种使用少量RGB图像来表示3D场景的方法,该方法利用来自预训练的单目深度估计模型[5]和平滑度约束的先验信息。我们适应的规模和偏移量的估计深度的稀疏COLMAP点,解决规模模糊。我们使用调整后的深度作为几何指导,以协助基于颜色的优化,减少浮动工件和满足几何条件。我们观察到,即使是修改后的深度有助于引导场景的几何最佳解决方案,尽管其粗糙度。我们通过引入早期停止策略来防止过拟合问题,当深度引导损失开始上升时,优化过程停止。此外,为了实现更高的稳定性,我们应用了平滑约束,确保相邻3D点具有相似的深度。我们采用3DGS作为我们的基线,并比较我们的方法在NeRF-LLFF [30]数据集中的性能。 我们确认,我们的策略导致合理的结果,不仅在RGB新视图合成,但也3D几何重建。通过进一步的实验,我们证明了几何线索,如深度和初始点的高斯飞溅的影响。它们显著影响高斯溅射的稳定优化。
In summary, our contributions are as follows:
我们的贡献概括如下:
∙
We propose depth-guided Gaussian Splatting optimization strategy which enables optimizing the scene with a few images, mitigating over-fitting issue. We demonstrate that even an estimated depth adjusted with a sparse point cloud, which is an outcome of the SfM pipeline, can play a vital role in geometric regularization.
我们提出了深度引导的高斯溅射优化策略,该策略可以用少量图像优化场景,减轻过拟合问题。我们证明,即使是估计的深度调整与稀疏点云,这是一个结果的SfM管道,可以发挥至关重要的作用,在几何正则化。
∙
We present a novel early stop strategy: halting the training process when depth-guided loss suffers to drop. We illustrate the influence of each strategy through thorough ablation studies.
我们提出了一种新的早期停止策略:当深度引导损失下降时停止训练过程。我们通过彻底的消融研究来说明每种策略的影响。
∙
We show that the adoption of a smoothness term for the depth map directs the model to finding the correct geometry. Comprehensive experiments reveal enhanced performance attributed to the inclusion of a smoothness term.
我们表明,通过平滑项的深度图指导模型找到正确的几何形状。综合实验表明,增强的性能归因于包括一个平滑项。
2Related Work 2相关工作
Novel view synthesis 一种新的视图合成方法
Structure from motion (SfM) [46] and Multi-view stereo (MVS) [45] are techniques for reconstructing 3D structures using multiple images, which have been studied for a long time in the computer vision field. Among the continuous developments, COLMAP [41] is a widely used representative tool. COLMAP performs camera pose calibration and finds sparse 3D keypoints using the epipolar constraint [22] of multi-view images. For more dense and realistic reconstruction, deep learning based 3D reconstruction techniques have been mainly studied. [21, 51, 31] Among them, Neural radiance fields (NeRF) [31] is a representative method that uses a neural network as a representation method. NeRF creates realistic 3D scenes using an MLP network as a 3D space expression and volume rendering, producing many follow-up papers on 3D reconstruction research. [44, 18, 3, 54, 47, 4] In particular, to overcome slow speed of NeRF, many efforts continues to achieve real-time rendering by utilizing explicit expression such as sparse voxels[27, 56, 43, 16], featured point clouds[52], tensor [10], polygon [11]. These representations have local elements that operate independently, so they show fast rendering and optimization speed. Based on this idea, various representations such as Multi-Level Hierarchies [32, 33], infinitesimal networks [19, 39], triplane [9] have been attempted. Among them, 3D Gaussian splatting [23] presented a fast and efficient method through alpha-blending rasterization instead of time-consuming volume rendering. It optimizes a 3D scene using multi-million Gaussian attenuated spherical harmonics with opacity as a primitive, showing easy and fast 3D reconstruction with high quality.
运动恢复结构(SfM)[46]和多视图立体(MVS)[45]是使用多个图像重建3D结构的技术,在计算机视觉领域已经研究了很长时间。在不断发展中,COLMAP [41]是一个广泛使用的代表性工具。COLMAP执行相机姿态校准,并使用多视图图像的极线约束[22]找到稀疏的3D关键点。为了更密集和真实的重建,主要研究了基于深度学习的3D重建技术。[21其中,神经辐射场(NeRF)[31]是使用神经网络作为表示方法的代表性方法。NeRF使用MLP网络作为3D空间表达和体绘制来创建逼真的3D场景,产生了许多关于3D重建研究的后续论文。 [44特别是,为了克服NeRF的缓慢速度,许多努力继续通过利用显式表达式来实现实时渲染,例如稀疏体素[27,56,43,16],特征点云[52],张量[10],多边形[11]。这些表示具有独立操作的局部元素,因此它们显示出快速的渲染和优化速度。基于这一思想,人们尝试了各种表示方法,如多级层次[32,33],无穷小网络[19,39],三平面[9]。其中,3D高斯溅射[23]通过alpha混合光栅化而不是耗时的体绘制提出了一种快速有效的方法。它使用数百万高斯衰减球谐函数优化3D场景,以不透明度作为图元,显示高质量的简单快速3D重建。
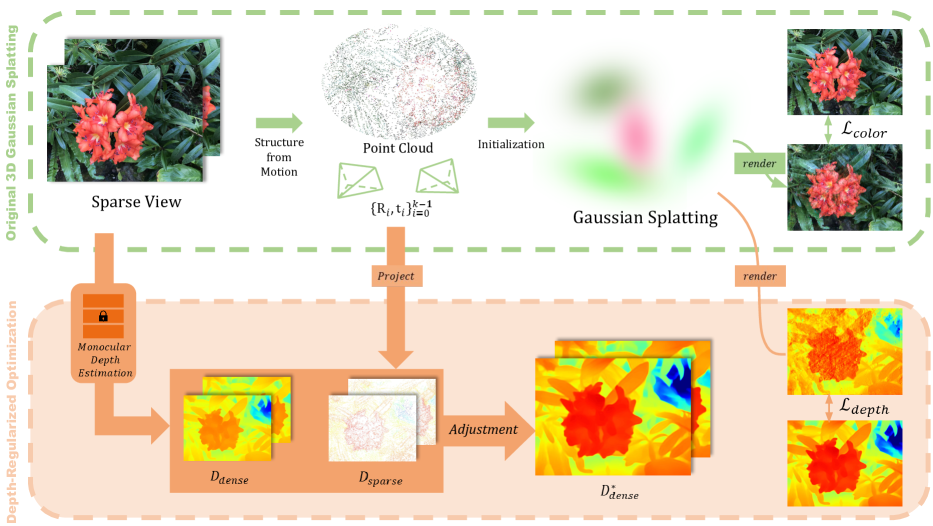
Figure 2:Overview. We optimize the 3D Gaussian splatting [23] using dense depth maps adjusted with the point clouds obtained from COLMAP [41]. By incorporating depth maps to regulate the geometry of the 3D scene, our model successfully reconstructs scenes using a limited number of images.
图2:概述。我们使用通过从COLMAP [41]获得的点云调整的密集深度图来优化3D高斯溅射[23]。通过结合深度图来调节3D场景的几何形状,我们的模型成功地使用有限数量的图像重建场景。
Few-shot 3D reconstruction
少拍三维重建
Since an image contains only partial information about the 3D scene, 3D reconstruction requires a large number of multi-view images. COLMAP uploads feature points matched between multiple images onto 3D space, so the more images are used, the more reliable 3D points and camera poses can be obtained.[41, 17] NeRF also optimizes the color and geometry of a 3D scene based on the pixel colors of a large number of images to obtain high-quality scenes. [48, 57] However, the requirements for many images hindered practical application, sparking research on 3D reconstruction using only a few number of images. Many few-shot 3D reconstruction studies utilize depth to provide valuable geometric cue for creating 3D scenes. Depth helps reduce the effort of inferring geometry through color consensus in multiple images by introducing a surface smoothness constraint [25, 35], supervising the sparse depth obtained from COLMAP [13, 49], using the dense depth obtained from additional sensors [2, 7, 15], or exploiting estimated dense depth from pretrained network. [37, 40, 34] These studies regularize geometry based on the globality of the neural network, so it is difficult to apply them to representations with large locality such as sparse voxel [16] or feature point [52]. Instead, they attempted to establish connectivity between local elements in a 3D space through the total variation (TV) loss [59, 16, 53], but it requires exhaustive hyperparameter tuning of total variation which varies on the scene and location. 3D Gaussian splatting [23] generates floating artifacts with a few number of images, due to its strong locality. The sparse COLMAP feature points that can be obtained from the Gaussian splat subprocess are a free depth guide that can be obtained without additional information [40], but the number of sparse points obtained from a small number of images is so small that it cannot guide all Gaussian splats with strong locality. We use a coarse geometry guide for optimization through a pretrained depth estimation model [5, 58, 29]. Even if they do not have an exact fine-detailed depth, they provide a rough guide to the location of splats, which greatly contributes to optimization stability in few-shot situations and helps eliminate floating artifacts that occur in random locations.
由于图像只包含关于3D场景的部分信息,因此3D重建需要大量的多视图图像。COLMAP将多幅图像之间匹配的特征点上传到3D空间,因此使用的图像越多,可以获得越可靠的3D点和相机姿态。[41 NeRF还根据大量图像的像素颜色优化3D场景的颜色和几何形状,以获得高质量的场景。[48然而,对许多图像的要求阻碍了实际应用,引发了仅使用少量图像进行3D重建的研究。许多少镜头3D重建研究利用深度为创建3D场景提供有价值的几何线索。 深度有助于通过引入表面平滑度约束[25,35],监督从COLMAP [13,49]获得的稀疏深度,使用从其他传感器[2,7,15]获得的密集深度或利用预训练网络的估计密集深度来减少通过多个图像中的颜色一致性推断几何形状的工作。[37这些研究基于神经网络的全局性来正则化几何形状,因此很难将它们应用于具有大局部性的表示,例如稀疏体素[16]或特征点[52]。相反,他们试图通过总变差(TV)损失建立3D空间中局部元素之间的连接性[59,16,53],但它需要对场景和位置变化的总变差进行详尽的超参数调整。3D高斯飞溅[23]由于其强局部性,会产生具有少量图像的浮动伪影。 可以从高斯splat子过程中获得的稀疏COLMAP特征点是一个自由的深度引导,可以在没有额外信息的情况下获得[40],但是从少量图像中获得的稀疏点的数量非常小,以至于它不能引导所有具有强局部性的高斯splat。我们使用粗略的几何指导通过预训练的深度估计模型进行优化[5,58,29]。即使它们没有精确的细节深度,它们也提供了对飞溅位置的粗略指导,这极大地有助于在少数拍摄情况下的优化稳定性,并有助于消除在随机位置发生的浮动伪影。
3Method 3方法
Our method facilitates the optimization from a small set of images {��}�=0�−1,��∈[0,1]�×�×3. As a preprocessing, we run SfM (such as COLMAP[41]) pipeline and get the camera pose Ri∈ℝ3×3,ti∈ℝ3, intrinsic parameters ��∈ℝ3×3, and a point cloud �∈ℝ�×3. With those informations, we can easily obtain a sparse depth map for each image, by projecting all visible point to pixel space:
我们的方法便于从一小部分图像 {��}�=0�−1,��∈[0,1]�×�×3 进行优化。作为预处理,我们运行SfM(如COLMAP[41])流水线并获得相机姿势 Ri∈ℝ3×3,ti∈ℝ3 ,内部参数 ��∈ℝ3×3 和点云 �∈ℝ�×3 。有了这些信息,我们可以很容易地获得每个图像的稀疏深度图,通过将所有可见点投影到像素空间:
| �=�homog[Ri|ti], | (1) | ||
| and�������,�=��∈[0,∞]�×�. | (2) |
Our approach builds upon 3DGS [23]. They optimize the Gaussian splats based on the rendered image with a color loss ℒ����� and D-SSIM loss ℒ�−����. Prior to the 3DGS optimization, we estimate a depth map for each image using a depth estimation network and fit the sparse depth mapSection 3.1). We render a depth from the set of Gaussian splattings leveraging the color rasterization process and add a depth constraint using the dense depth prior (Section 3.2). We add an additional constraint for smoothness between depths of adjacent pixels (Section 3.3) and refine optimization options for few-shot settings (Section 3.4).
我们的方法基于3DGS [23]。它们基于具有颜色损失 ℒ����� 和D-SSIM损失 ℒ�−���� 的渲染图像来优化高斯飞溅。在3DGS优化之前,我们使用深度估计网络估计每个图像的深度图,并拟合稀疏深度图(第3.1节)。我们利用颜色光栅化过程从高斯分裂集中渲染深度,并使用密集深度先验添加深度约束(第3.2节)。我们为相邻像素的深度之间的平滑度添加了一个额外的约束(第3.3节),并为少数镜头设置优化选项(第3.4节)。
3.1Preparing Dense Depth Prior
3.1准备密集深度先验
With the goal of guiding the splats into plausible geometry, we require to provide global geometry information due to the locality of Gaussian splats. The density depth is one of the promising geometry prior, but there is a challenge in constructing it. The density of SfM points depends on the number of images, so the number of valid points are too small to directly estimate dense depth in a few-shot setting. (For example, SfM reconstruction from 19 images creates a sparse depth map with 0.04% valid pixels on average. [40]) Even the latest depth completion models fail to complete dense depth due to the significant information gap.
由于高斯splats的局部性,我们需要提供全局的几何信息,以引导splats进入合理的几何。密度深度是一种很有前途的几何先验,但其构造存在一定的困难:SfM点的密度依赖于图像的数量,因此有效点的数量太少,无法直接在少炮集的情况下估计密度深度。(For例如,来自19个图像的SfM重建创建平均具有0.04%有效像素的稀疏深度图。[40])即使是最新的深度完井模型也无法完成密集深度,因为存在显著的信息差距。
When designing the depth prior, it is important to note that even rough depth significantly aids in guiding the splats and eliminating artifacts resulting from splats trapped in incorrect geometry. Hence, we employ a state-of-the-art monocular depth estimation model and scale matching to provide a coarse dense depth guide for optimization. From a train image �, the monocular depth estimation model �� outputs dense depth �dense,
在设计深度先验时,重要的是要注意,即使是粗略的深度也能显著地帮助引导飞溅并消除由被困在不正确的几何结构中的飞溅导致的伪影。因此,我们采用最先进的单目深度估计模型和尺度匹配来提供用于优化的粗糙密集深度指南。从训练图像 � ,单目深度估计模型 �� 输出密集深度 �dense ,
| �dense=�⋅��(�)+�. | (3) |
To resolve the scale ambiguity in the estimated dense depth �dense, we adjust the scale � and offset � of estimated depth to sparse SfM depth �sparse:
为了解决估计的密集深度 �dense 中的尺度模糊性,我们将估计深度的尺度 � 和偏移 � 调整为稀疏SfM深度 �sparse :
| �∗,�∗=argmin�,�∑�∈�sparse‖�(�)⋅�sparse(�)−�dense(�;�,�)‖2, | (4) |
where �∈[0,1] is a normalized weight presenting the reliability of each feature points calculated as the reciprocal of the reprojection error from SfM. Finally, we use the adjusted dense depth �dense∗=�∗⋅��(�)+�∗ to regularize the optimization loss of Gaussian splatting.
其中 �∈[0,1] 是表示每个特征点的可靠性的归一化权重,该可靠性被计算为来自SfM的重投影误差的倒数。最后,我们使用调整后的稠密深度 �dense∗=�∗⋅��(�)+�∗ 来正则化高斯溅射的优化损失。
3.2Depth Rendering through Rasterization
3.2通过光栅化进行深度渲染
3D Gaussian splatting utilizes a rasterization pipeline [1] to render the disconnected and unstructured splats leveraged on the parallel architecture of GPU. Based on differentiable point-based rendering techniques [50, 55, 26], they render an image by rasterizing the splats through �-blending. Point-based approaches exploit a similar equation to NeRF-style volume rendering, rasterizing a pixel color with ordered points that cover that pixel,
3D高斯飞溅利用光栅化流水线[1]来渲染GPU并行架构上利用的断开和非结构化飞溅。基于可微分的基于点的渲染技术[50,55,26],他们通过 � —混合光栅化splats来渲染图像。基于点的方法利用与NeRF风格的体绘制类似的等式,用覆盖该像素的有序点光栅化像素颜色,
| �=∑�∈N������ | (5) | ||
| where��=∏�=1�−1(1−��), |
� is the pixel color, � is the color of splats, and � here is learned opacity multiplied by the covariance of 2D Gaussian. This formulation prioritizes the color � of opaque splat positioned closer to the camera, significantly impacting the final outcome �. Inspired by the depth implementation in NeRF, we leverage the rasterization pipeline to render the depth map of Gaussian splats,
� 是像素颜色, � 是飞溅的颜色, � 是学习的不透明度乘以2D高斯的协方差。该公式优先考虑位于更靠近相机的不透明飞溅的颜色 � ,显著影响最终结果 � 。受NeRF中深度实现的启发,我们利用光栅化流水线来渲染高斯splats的深度图,
| �=∑�∈N������, | (6) |
where � is the rendered depth and ��=(����+��)� is the depth of each splat from the camera. Eqn. (6) enables the direct utilization of �� and �� calculated in Eqn. (5), facilitating rapid depth rendering with minimal computational load. Finally, we guide the rendered depth to the estimated dense depth using L1 distance,
其中, � 是渲染深度, ��=(����+��)� 是每个溅射距摄影机的深度。等式(6)使得能够直接利用在等式11中计算的 �� 和 �� 。(5)以最小的计算负荷促进快速深度渲染。最后,我们使用L1距离将渲染深度引导到估计的密集深度,
| ℒ����ℎ=‖�−�dense∗‖1 | (7) |
| PSNR↑ | SSIM↑ | LPIPS↓ | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2-view | 3-view | 4-view | 5-view | 2-view | 3-view | 4-view | 5-view | 2-view | 3-view | 4-view | 5-view | |||
| NeRF-LLFF[31] | Fern | 3DGS | 13.03 | 14.29 | 16.73 | 18.59 | 0.336 | 0.408 | 0.517 | 0.603 | 0.476 | 0.389 | 0.296 | 0.217 |
| Ours | 17.59 | 19.13 | 19.91 | 20.55 | 0.516 | 0.588 | 0.616 | 0.642 | 0.286 | 0.232 | 0.203 | 0.167 | ||
| Oracle | 18.18 | 20.30 | 20.78 | 21.81 | 0.524 | 0.636 | 0.654 | 0.701 | 0.278 | 0.201 | 0.185 | 0.157 | ||
| Flower | 3DGS | 14.90 | 17.75 | 19.71 | 21.39 | 0.351 | 0.508 | 0.605 | 0.671 | 0.406 | 0.257 | 0.190 | 0.146 | |
| Ours | 15.92 | 17.80 | 19.15 | 20.45 | 0.395 | 0.445 | 0.538 | 0.576 | 0.414 | 0.376 | 0.323 | 0.293 | ||
| Oracle | 19.71 | 22.16 | 23.26 | 24.65 | 0.570 | 0.673 | 0.714 | 0.760 | 0.250 | 0.163 | 0.128 | 0.097 | ||
| Fortress | 3DGS | 13.87 | 15.98 | 19.26 | 19.98 | 0.363 | 0.492 | 0.609 | 0.631 | 0.389 | 0.283 | 0.201 | 0.191 | |
| Ours | 19.80 | 21.85 | 23.07 | 23.72 | 0.567 | 0.655 | 0.724 | 0.740 | 0.232 | 0.191 | 0.162 | 0.144 | ||
| Oracle | 23.07 | 24.51 | 26.39 | 26.73 | 0.654 | 0.728 | 0.787 | 0.797 | 0.159 | 0.130 | 0.100 | 0.093 | ||
| Horns | 3DGS | 11.43 | 12.48 | 13.76 | 14.75 | 0.264 | 0.339 | 0.433 | 0.498 | 0.531 | 0.464 | 0.395 | 0.350 | |
| Ours | 15.91 | 16.22 | 18.09 | 18.39 | 0.420 | 0.466 | 0.527 | 0.565 | 0.362 | 0.349 | 0.306 | 0.296 | ||
| Oracle | 18.56 | 20.08 | 20.88 | 22.52 | 0.568 | 0.644 | 0.668 | 0.725 | 0.259 | 0.212 | 0.199 | 0.168 | ||
| Leaves | 3DGS | 12.33 | 12.36 | 12.49 | 12.26 | 0.260 | 0.275 | 0.298 | 0.297 | 0.412 | 0.397 | 0.397 | 0.401 | |
| Ours | 13.04 | 13.63 | 13.97 | 14.13 | 0.235 | 0.270 | 0.283 | 0.297 | 0.460 | 0.445 | 0.440 | 0.438 | ||
| Oracle | 13.52 | 14.23 | 14.78 | 14.85 | 0.287 | 0.353 | 0.377 | 0.397 | 0.380 | 0.348 | 0.341 | 0.356 | ||
| Orchids | 3DGS | 11.78 | 13.94 | 15.41 | 16.08 | 0.182 | 0.320 | 0.416 | 0.460 | 0.426 | 0.310 | 0.245 | 0.219 | |
| Ours | 12.88 | 14.71 | 15.40 | 16.13 | 0.216 | 0.297 | 0.343 | 0.391 | 0.462 | 0.383 | 0.366 | 0.352 | ||
| Oracle | 14.89 | 16.45 | 17.42 | 18.45 | 0.365 | 0.471 | 0.525 | 0.576 | 0.303 | 0.237 | 0.200 | 0.174 | ||
| Room | 3DGS | 10.18 | 11.51 | 11.59 | 12.21 | 0.404 | 0.494 | 0.510 | 0.552 | 0.606 | 0.559 | 0.556 | 0.515 | |
| Ours | 17.21 | 18.11 | 18.87 | 19.63 | 0.668 | 0.719 | 0.732 | 0.757 | 0.352 | 0.360 | 0.326 | 0.295 | ||
| Oracle | 20.66 | 22.31 | 23.80 | 24.59 | 0.758 | 0.801 | 0.839 | 0.864 | 0.217 | 0.188 | 0.160 | 0.156 | ||
| Trex | 3DGS | 10.72 | 11.72 | 13.11 | 14.14 | 0.322 | 0.417 | 0.492 | 0.548 | 0.520 | 0.446 | 0.394 | 0.351 | |
| Ours | 14.90 | 15.90 | 16.75 | 17.37 | 0.480 | 0.537 | 0.567 | 0.625 | 0.358 | 0.362 | 0.348 | 0.305 | ||
| Oracle | 17.76 | 19.58 | 20.84 | 22.83 | 0.591 | 0.669 | 0.714 | 0.786 | 0.284 | 0.226 | 0.192 | 0.134 | ||
| Mean | 3DGS | 12.25 | 13.75 | 15.26 | 16.17 | 0.306 | 0.407 | 0.485 | 0.533 | 0.471 | 0.388 | 0.334 | 0.299 | |
| Ours | 15.94 | 17.17 | 18.15 | 18.74 | 0.439 | 0.497 | 0.541 | 0.571 | 0.365 | 0.337 | 0.309 | 0.288 | ||
| Oracle | 18.29 | 19.95 | 21.02 | 22.05 | 0.539 | 0.622 | 0.660 | 0.701 | 0.266 | 0.213 | 0.188 | 0.167 | ||
Table 1:Quantitative results in NeRF-LLFF [30] dataset. The best performance except oracle is bolded.
表1:NeRF-LLFF [30]数据集中的定量结果。除oracle之外的最佳性能都用粗体表示。
3.3Unsupervised Smoothness Constraint
3.3无监督平滑约束
Even though each independently estimated depth was fitted to the COLMAP points, conflicts often arise. We introduce an unsupervised constraint for geometry smoothness inspired by [20] to regularize the conflict. This constraint implies that points in similar 3D positions have similar depths on the image plane. We utilize the Canny edge detector [8] as a mask to ensure that it does not regularize the area with significant differences in depth along the boundaries. For a depth �� and its adjacent depth ��, we regularize the difference between them:
即使每个独立估计的深度被拟合到COLMAP点,也经常出现冲突。我们引入了一个受[20]启发的几何平滑的无监督约束来正则化冲突。该约束意味着相似3D位置中的点在图像平面上具有相似的深度。我们利用Canny边缘检测器[8]作为掩模,以确保它不会使沿边界的深度沿着存在显著差异的区域规则化。对于深度 �� 及其相邻深度 �� ,我们正则化它们之间的差异:
| ℒ�����ℎ=∑��∈adj(��)��(��,��)⋅‖��−��‖2 | (8) |
where �� is a indicator function that signifies whether both depths are not in edge.
其中 �� 是表示两个深度是否不在边缘中的指示函数。
We conclude the final loss terms by incorporating the depth loss from Eqn. (7) and smoothness loss and smoothness loss from Eqn. (8) with their own hyperparameters �����ℎ and ������ℎ:
我们通过结合来自方程11的深度损失来得出最终损失项。(7)和平滑度损失和来自Eqn的平滑度损失。(8)使用它们自己的超参数 �����ℎ 和 ������ℎ :
| ℒ=(1−�����)ℒ����� | +�����ℒ�−���� | (9) | ||
| +�����ℎℒ����ℎ | +������ℎℒ�����ℎ |
where the preceding two loss terms ℒ�����,ℒ�−���� correspond to the original 3D Gaussian splatting losses. [23]
其中前面的两个损耗项 ℒ�����,ℒ�−���� 对应于原始3D高斯溅射损耗。[23]
3.4Modification for Few-Shot Learning
3.4对少镜头学习的改进
We modify two optimization techniques from the original paper to create 3D scenes with limited images. The techniques employed in 3DGS were designed under the assumption of utilizing a substantial number of images, potentially hindering convergence in a few-shot setting. Through iterative experiments, we confirm this and modify the techniques to suit the few-shot setting. Firstly, we set the maximum degree of spherical harmonics (SH) to 1. This prevents overfitting of spherical harmonic coefficients responsible for high frequencies due to insufficient information. Secondly, we implement an early-stop policy based on depth loss. We configure Eqn. (9) to be primarily driven by color loss, while employing the depth loss and the smoothness loss as guiding factors. Hence, overfitting gradually emerges due to the predominant influence of color loss. We use a moving averaged depth loss to halt optimization when the splats start to deviate from the depth guide. Lastly, we remove the periodic reset process. We observe that resetting the opacity � of all splats leads to irreversible and detrimental consequences. Due to a lack of information from the limited images, the inability to restore the opacity of splats led to scenarios where either all splats were removed or trapped in local optima, causing unexpected outcomes and optimization failures. As a result of the aforementioned techniques, we achieve stable optimization in few-shot learning.
我们修改了两个优化技术,从原来的文件,以创建有限的图像的3D场景。3DGS中采用的技术是在利用大量图像的假设下设计的,这可能会阻碍少数镜头设置中的收敛。通过迭代实验,我们证实了这一点,并修改的技术,以适应少数镜头设置。首先,我们将球谐函数(SH)的最大次数设置为1。这防止了由于信息不足导致的导致高频的球谐系数的过拟合。其次,我们实施基于深度损失的早期止损策略。我们配置Eqn. (9)主要由颜色损失驱动,同时采用深度损失和平滑度损失作为指导因素。因此,由于颜色损失的主要影响,过拟合逐渐出现。我们使用移动平均深度损失来在splats开始偏离深度指导时停止优化。 最后,我们删除了定期重置过程。我们观察到重置所有splats的不透明度 � 会导致不可逆和有害的后果。由于缺乏来自有限图像的信息,无法恢复splats的不透明度导致所有splats被移除或陷入局部最优的情况,从而导致意外结果和优化失败。作为上述技术的结果,我们在少量学习中实现了稳定的优化。
智能推荐
【HTML5期末作业】用HTML+CSS一个兰州交通大学官网网站-程序员宅基地
文章浏览阅读28次。 校园班级网页设计 、我的班级网页、我的学校、校园社团、校园运动会、等网站的设计与制作。️HTML我的班级网页设计,采用DIV+CSS布局,共有多个页面,排版整洁,内容丰富,主题鲜明,首页使用CSS排版比较丰富,色彩鲜明有活力,导航与正文字体分别设置不同字号大小。导航区域设置了背景图。子页面有纯文字页面和图文并茂页面。 一套优质的网页设计应该包含 (具体可根据个人要求而定)网站布局方面:计划采用目前主流的、能兼容各大主流浏览器、显示效果稳定的浮动网页布局结构。网站
攻防世界 insanity_攻防世界insanity-程序员宅基地
文章浏览阅读97次。insanity:首先启动题目,给了一个不知道格式的文件于是利用exeinfo 打开:发现它是ELF文件,且是32bit,于是利用,IDA打开得到:在查看字符串,按快捷键shift+f12得到flag:_攻防世界insanity
qt6.2 开发遇坑记_qt6 如何支持win7-程序员宅基地
文章浏览阅读1.1k次。一、第一道坑文档过时开发部分文档总是和代码对不上,我的qt最开始是在线安装包安装的,提示文档里面明明有的函数,用了编译却总是不能过,没办法,只能用原生c++,简直是泪崩,各种依赖库加苦二、第二道坑 c++通病依赖库qt过之不及build运行和debug运行都是正常的,一旦发布就是少各种dll,用windeployqt自动copy了dll之后运行闪退,手动copy了mingw目录下的plugins,modules,qml文件夹,终于跑起来了,兴奋的打包发测,结果..._qt6 如何支持win7
# 行动、任务、项目概念区分_工作中的todo指什么-程序员宅基地
文章浏览阅读5.8k次。行动、任务、项目概念区分1、行动(todo或action)行动就是确定时间节点,可以立即去做的事情。行动容易操作和衡量。2、任务(task)任务通常指所接受的工作,所担负的职责,是指为了完成某个有方向性的目的而产生的活动。任务有明确的执行目标和执行人,相比于项目,任务侧重于结果,也会有时间的约束性。任务里面可以嵌套任务,即一个主任务下面可以细分成若干个子任务,由这些子任务的完成结果组成为主..._工作中的todo指什么
Python读写xml文件_python xml读写保留编码-程序员宅基地
文章浏览阅读424次。python读写xml文件时会删除xml文件第一行的声明_python xml读写保留编码
( 图论专题 )【 最大费用最大流 】-程序员宅基地
文章浏览阅读2.6k次。( 图论专题 )【 最大费用最大流 】【 最大费用最大流 】只需要将【 最小费用最大流 】的w取相反数就好了,最后的mincost( 最小费用 )也取相反数就是最大费用了。( 图论专题 )【 最小费用最大流 】例题:HDU - 643710 3 1 101 5 1000 05 10 1000 1第一行n,m,K,M, 每天n个小时,m个视频,K个人,观看相同视频时失去W幸福值。接下来m行,每行S,T,w,op四个正整数,dii个视频的开始时间,结束时间,看完得到的幸福值,.._最大费用最大流
随便推点
java实现五子棋窗口_Java swing五子棋的实现方法-程序员宅基地
文章浏览阅读349次。今天给大家介绍一下如何用Java swing实现五子棋的开发即用Java开发图形界面程序五子棋,代码由于太多,只贴部分,最下面会附上下载地址,废话不多说,下面我们先看一下运行结果:接下来我们看代码:首先是创建主frame框架界面:package org.liky.game.frame;import java.awt.Color;import java.awt.Font;import java.aw..._org.liky.game.frame
基于JAVA电子商务网上户外用品购物商城电商系统设计与实现(Springboot框架)研究背景和意义、国内外现状_户外露营用品电商系统研究背景-程序员宅基地
文章浏览阅读3.2k次,点赞23次,收藏26次。基于JAVA电子商务网上户外用品购物商城电商系统设计与实现(Springboot框架)研究背景和意义、国内外现状,而电子商务通过提供线上购物平台,能够方便消费者随时随地进行购物,并且提供更多的商品选择和更便宜的价格。这些平台提供了丰富的户外用品商品,包括露营装备、登山用品、徒步鞋等,并且提供了更加详细的产品信息和用户评价,帮助消费者做出更准确的购买决策。因此,通过研究和实现这样一款系统,能够填补这一空白,为消费者提供更便捷、高效的购物体验,并且为户外用品行业的发展做出积极贡献。_户外露营用品电商系统研究背景
VS中Windows界面开发_vs写界面-程序员宅基地
文章浏览阅读9.2k次。1.环境:vs2017,.net4.52.步骤:(1)打开vs2017,新建项目Windows窗体应用(.NET Framework),新建后会出现一个Form1的窗体;(2)打开工具箱,将公共控件中的Label、Button、TextBox控件拉入窗体中,在右边属性栏中更改名字;(3)双击button控件,进入代码编辑器,并触发button控件的Click事件,即点击button按钮..._vs写界面
day01 windows编程入门-程序员宅基地
文章浏览阅读1.7k次,点赞5次,收藏16次。我们以前见过double,int,long,我们都可以很清晰的知道他们是什么意思,但是这玩意可读性这么差,而且还都是大写,怎么记得住啊。你可以会觉得,这是什么鬼,怎么这么多参数,我们以前写的C++的mina最多也就两个参数啊,但是,你必须接受这个现实,windows编程有非常多的复杂概念,和非常复杂的声明等等。Windows编程的本质就是使用好操作系统,想要用好操作系统必不可少的秘籍----MSDN。我们已经完成了第一个窗口的实例,接下来我们将学习如何编写一个正规的第一个窗口。_windows编程入门
给已有的linux系统增加磁盘容量_linux系统如何追加一个硬盘容量-程序员宅基地
文章浏览阅读309次。【代码】给已有的linux系统增加磁盘容量。_linux系统如何追加一个硬盘容量
操作系统的安全管理_安全操作系统设计技术(tcb)-程序员宅基地
文章浏览阅读1.1w次,点赞4次,收藏24次。OS的安全管理_安全操作系统设计技术(tcb)