计算机视觉迎来GPT时刻!UC伯克利三巨头祭出首个纯CV大模型!-程序员宅基地
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer知识星球,可以最快学习到最新顶会顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文,强烈推荐!

在CVer微信公众号后台回复:LVM,即可下载论文pdf和代码链接!快学起来!
转载自:机器之心
仅靠视觉(像素)模型能走多远?UC 伯克利、约翰霍普金斯大学的新论文探讨了这一问题,并展示了大型视觉模型(LVM)在多种 CV 任务上的应用潜力。
最近一段时间以来,GPT 和 LLaMA 等大型语言模型 (LLM) 已经风靡全球。
另一个关注度同样很高的问题是,如果想要构建大型视觉模型 (LVM) ,我们需要的是什么?
LLaVA 等视觉语言模型所提供的思路很有趣,也值得探索,但根据动物界的规律,我们已经知道视觉能力和语言能力二者并不相关。比如许多实验都表明,非人类灵长类动物的视觉世界与人类的视觉世界非常相似,尽管它们和人类的语言体系「两模两样」。
在最近一篇论文中,UC 伯克利和约翰霍普金斯大学的研究者探讨了另一个问题的答案 —— 我们仅靠像素本身能走多远?

论文地址:https://arxiv.org/abs/2312.00785
项目主页:https://yutongbai.com/lvm.html
研究者试图在 LVM 中效仿的 LLM 的关键特征:1)根据数据的规模增长进行扩展,2)通过提示(上下文学习)灵活地指定任务。
他们指定了三个主要组件,即数据、架构和损失函数。
在数据上,研究者想要利用视觉数据中显著的多样性。首先只是未标注的原始图像和视频,然后利用过去几十年产生的各种标注视觉数据源(包括语义分割、深度重建、关键点、多视图 3D 对象等)。他们定义了一种通用格式 —— 「视觉句子」(visual sentence),用它来表征这些不同的注释,而不需要任何像素以外的元知识。训练集的总大小为 16.4 亿图像 / 帧。
在架构上,研究者使用大型 transformer 架构(30 亿参数),在表示为 token 序列的视觉数据上进行训练,并使用学得的 tokenizer 将每个图像映射到 256 个矢量量化的 token 串。
在损失函数上,研究者从自然语言社区汲取灵感,即掩码 token 建模已经「让位给了」序列自回归预测方法。一旦图像、视频、标注图像都可以表示为序列,则训练的模型可以在预测下一个 token 时最小化交叉熵损失。
通过这一极其简单的设计,研究者展示了如下一些值得注意的行为:
随着模型尺寸和数据大小的增加,模型会出现适当的扩展行为;
现在很多不同的视觉任务可以通过在测试时设计合适的 prompt 来解决。虽然不像定制化、专门训练的模型那样获得高性能的结果, 但单一视觉模型能够解决如此多的任务这一事实非常令人鼓舞;
大量无监督数据对不同标准视觉任务的性能有着显著的助益;
在处理分布外数据和执行新的任务时,出现了通用视觉推理能力存在的迹象,但仍需进一步研究。
论文共同一作、约翰霍普金斯大学 CS 四年级博士生、伯克利访问博士生 Yutong Bai 发推宣传了她们的工作。
图源:https://twitter.com/YutongBAI1002/status/1731512110247473608
在论文作者中,后三位都是 UC 伯克利在 CV 领域的资深学者。Trevor Darrell 教授是伯克利人工智能研究实验室 BAIR 创始联合主任、Jitendra Malik 教授获得过 2019 年 IEEE 计算机先驱奖、 Alexei A. Efros 教授尤以最近邻研究而闻名。

从左到右依次为 Trevor Darrell、Jitendra Malik、Alexei A. Efros。
方法介绍
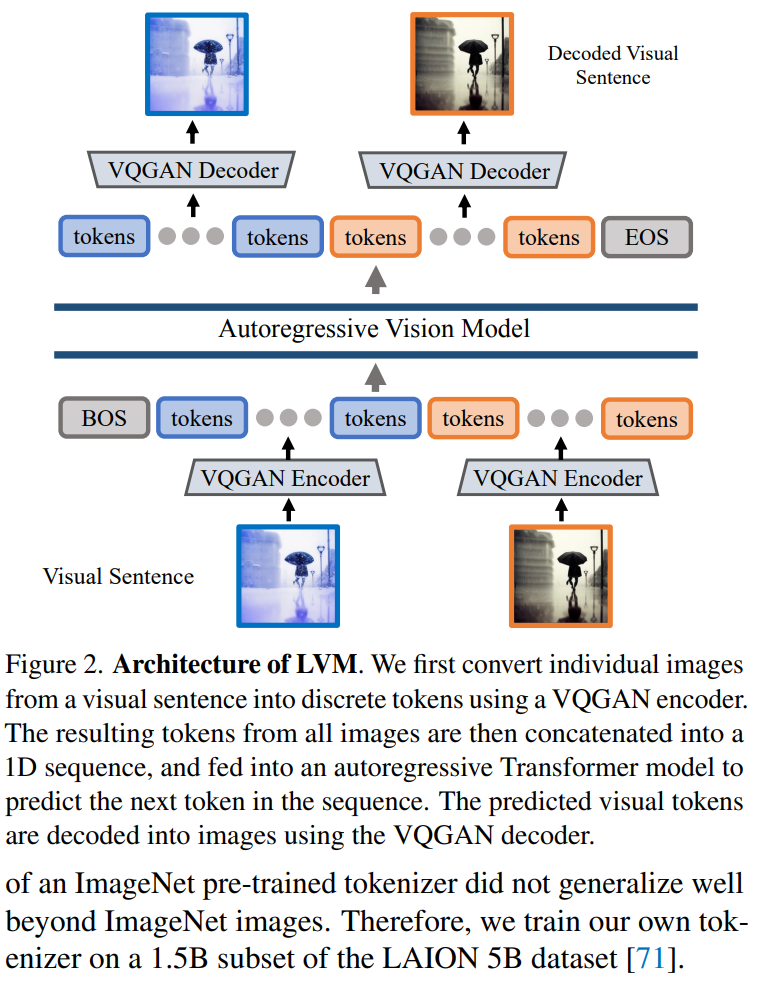
本文采用两阶段方法:1)训练一个大型视觉 tokenizer(对单个图像进行操作),可以将每个图像转换为一系列视觉 token;2)在视觉句子上训练自回归 transformer 模型,每个句子都表示为一系列 token。方法如图 2 所示:
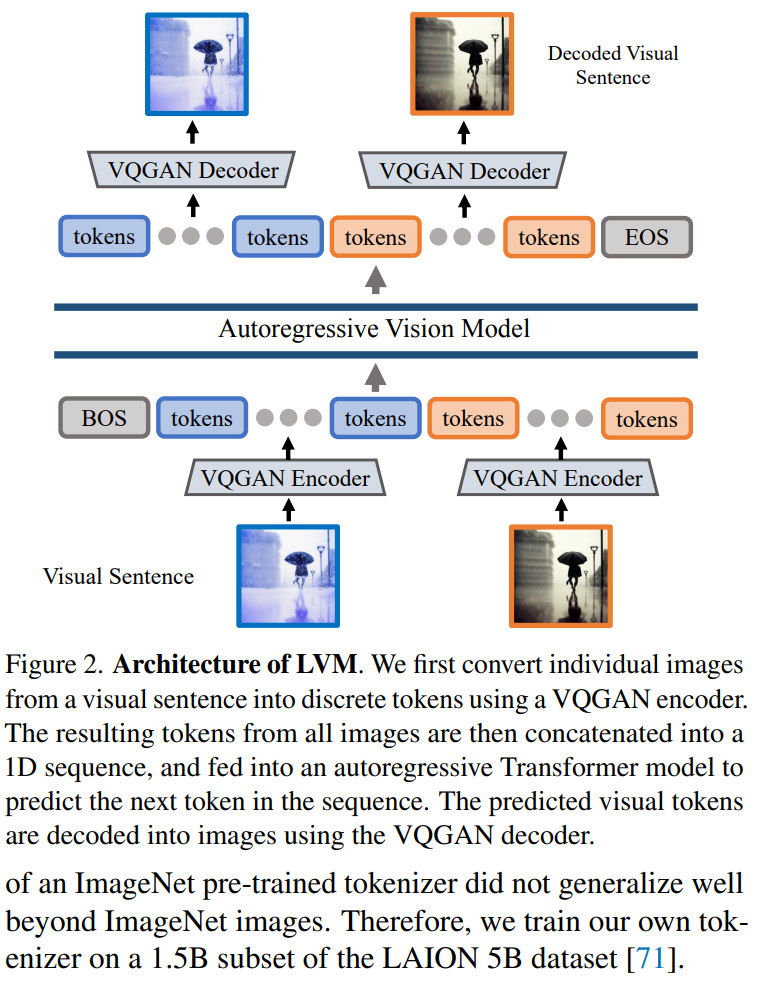
图像 Token 化
为了将 Transformer 模型应用于图像,典型的操作包括:将图像划分为 patch,并将其视为序列;或者使用预训练的图像 tokenizer,例如 VQVAE 或 VQGAN,将图像特征聚集到离散 token 网格中。本文采用后一种方法,即用 VQGAN 模型生成语义 token。
LVM 框架包括编码和解码机制,还具有量化层,其中编码器和解码器是用卷积层构建的。编码器配备了多个下采样模块来收缩输入的空间维度,而解码器配备了一系列等效的上采样模块以将图像恢复到其初始大小。对于给定的图像,VQGAN tokenizer 会生成 256 个离散 token。
实现细节。本文采用 Chang 等人提出的 VQGAN 架构,并遵循 Chang 等人使用的设置,在此设置下,下采样因子 f=16,码本大小 8192。这意味着对于大小为 256 × 256 的图像,VQGAN tokenizer 会生成 16 × 16 = 256 个 token,其中每个 token 可以采用 8192 个不同的值。此外,本文在 LAION 5B 数据集的 1.5B 子集上训练 tokenizer。
视觉句子序列建模
使用 VQGAN 将图像转换为离散 token 后,本文通过将多个图像中的离散 token 连接成一维序列,并将视觉句子视为统一序列。重要的是,所有视觉句子都没有进行特殊处理 —— 即不使用任何特殊的 token 来指示特定的任务或格式。
视觉句子允许将不同的视觉数据格式化成统一的图像序列结构。
实现细节。在将视觉句子中的每个图像 token 化为 256 个 token 后,本文将它们连接起来形成一个 1D token 序列。在视觉 token 序列上,本文的 Transformer 模型实际上与自回归语言模型相同,因此他们采用 LLaMA 的 Transformer 架构。
本文使用的上下文长度为 4096 个 token,与语言模型类似,本文在每个视觉句子的开头添加一个 [BOS](begin of sentence)token,在末尾添加一个 [EOS](end of sentence)token,并在训练期间使用序列拼接提高效率。
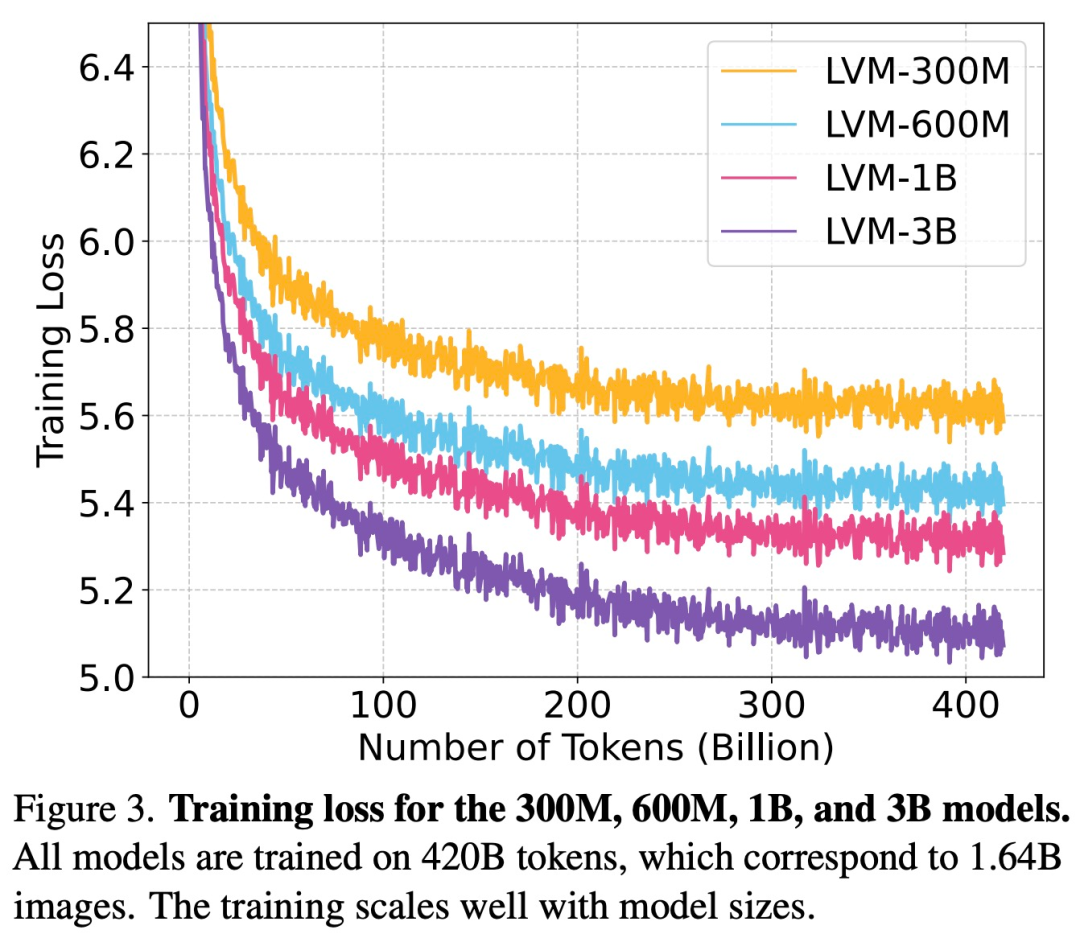
本文在整个 UVDv1 数据集(4200 亿个 token)上训练模型,总共训练了 4 个具有不同参数数量的模型:3 亿、6 亿、10 亿和 30 亿。
实验结果
该研究进行实验评估了模型的扩展能力,以及理解和回答各种任务的能力。
扩展
如下图 3 所示,该研究首先检查了不同大小的 LVM 的训练损失。
如下图 4 所示,较大的模型在所有任务中复杂度都是较低的,这表明模型的整体性能可以迁移到一系列下游任务上。
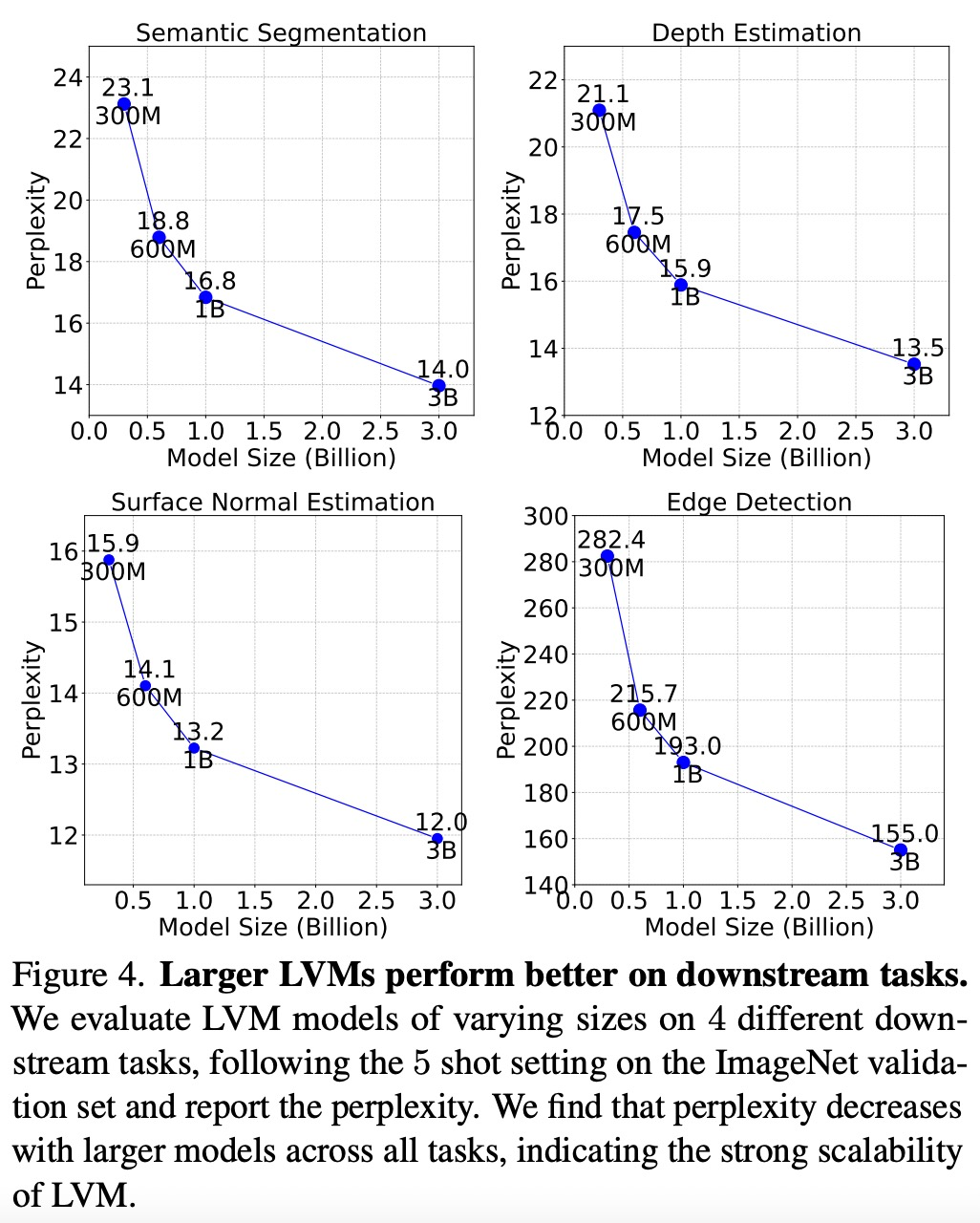
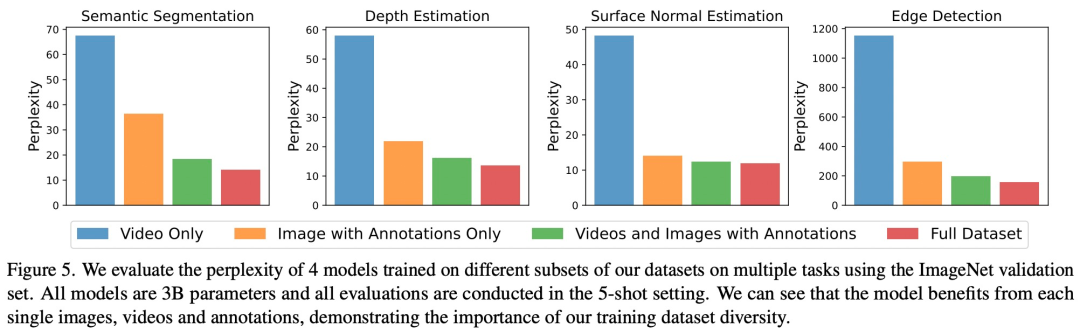
如下图 5 所示,每个数据组件对下游任务都有重要作用。LVM 不仅会受益于更大的数据,而且还随着数据集的多样性而改进。
序列 prompt
为了测试 LVM 对各种 prompt 的理解能力,该研究首先在序列推理任务上对 LVM 进行评估实验。其中,prompt 非常简单:向模型提供 7 张图像的序列,要求它预测下一张图像,实验结果如下图 6 所示:

该研究还将给定类别的项目列表视为一个序列,让 LVM 预测同一类的图像,实验结果如下图 15 所示:

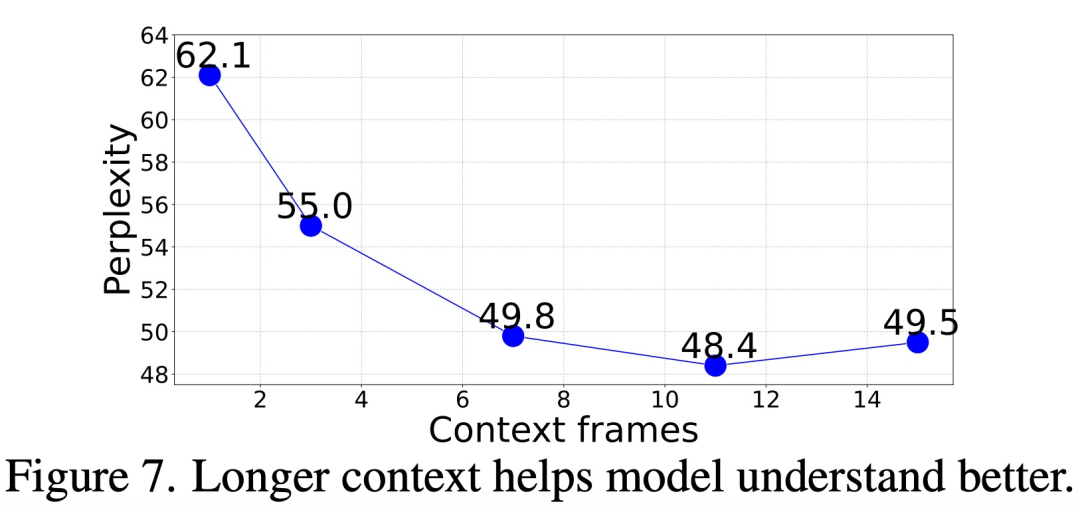
那么,需要多少上下文(context)才能准确预测后续帧?
该研究在给出不同长度(1 到 15 帧)的上下文 prompt 情况下,评估了模型的帧生成困惑度,结果如下图 7 所示,困惑度从 1 帧到 11 帧有明显改善,之后趋于稳定(62.1 → 48.4)。
Analogy Prompt
该研究还评估了更复杂的 prompt 结构 ——Analogy Prompt,来测试 LVM 的高级解释能力。
下图 8 显示了对许多任务进行 Analogy Prompt 的定性结果:

与视觉 Prompting 的比较如下所示, 序列 LVM 在几乎所有任务上都优于以前的方法。

合成任务。图 9 展示了使用单个 prompt 组合多个任务的结果。

其他 prompt
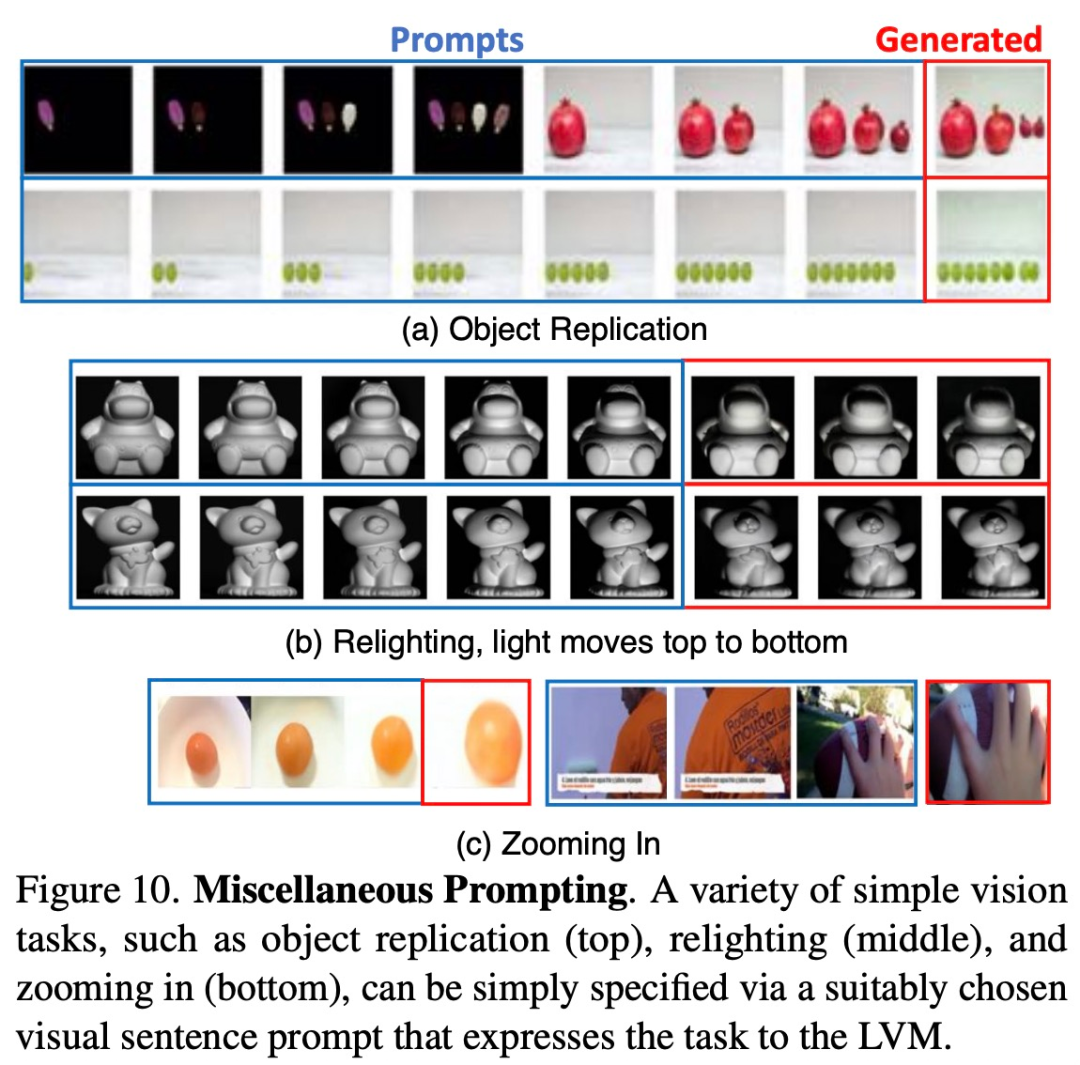
研究者试图通过向模型提供它以往未见过的各种 prompt,来观察模型的扩展能力到底怎样。下图 10 展示了一些运行良好的此类 prompt。
下图 11 展示了一些用文字难以描述的 prompt,这些任务上 LVM 最终可能会胜过 LLM。
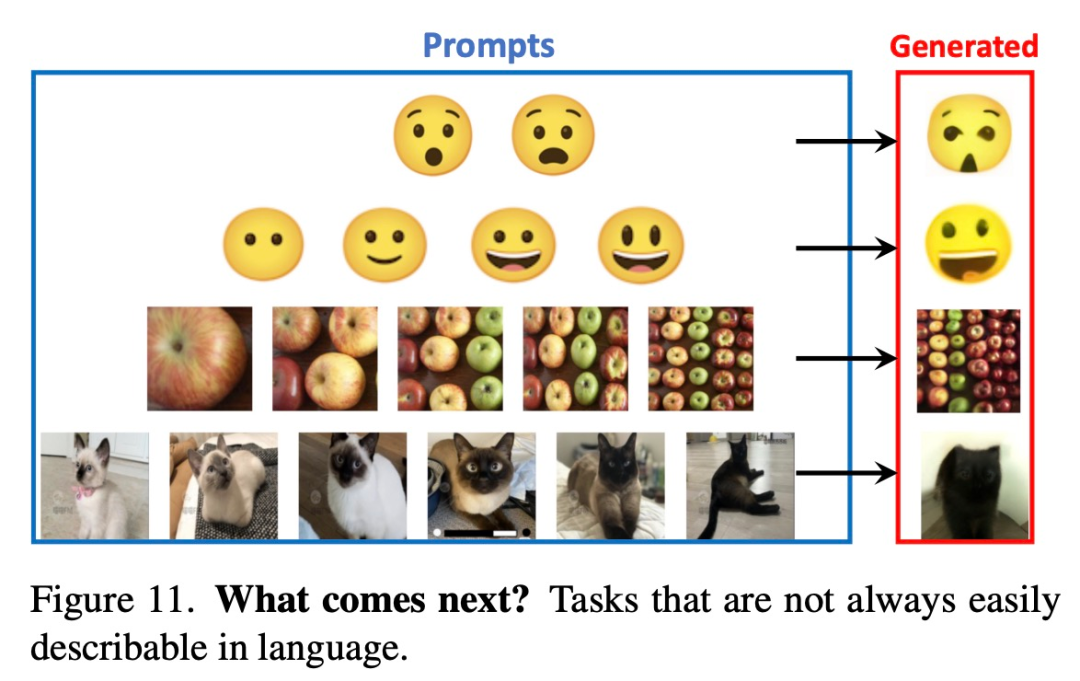
图 13 显示了在非语言人类 IQ 测试中发现的典型视觉推理问题的初步定性结果。

阅读原文,了解更多细节。
在CVer微信公众号后台回复:LVM,即可下载论文pdf和代码链接!快学起来!
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集计算机视觉和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群▲扫码或加微信号: CVer444,进交流群
CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
▲扫码加入星球学习▲点击上方卡片,关注CVer公众号智能推荐
从零开始搭建Hadoop_创建一个hadoop项目-程序员宅基地
文章浏览阅读331次。第一部分:准备工作1 安装虚拟机2 安装centos73 安装JDK以上三步是准备工作,至此已经完成一台已安装JDK的主机第二部分:准备3台虚拟机以下所有工作最好都在root权限下操作1 克隆上面已经有一台虚拟机了,现在对master进行克隆,克隆出另外2台子机;1.1 进行克隆21.2 下一步1.3 下一步1.4 下一步1.5 根据子机需要,命名和安装路径1.6 ..._创建一个hadoop项目
心脏滴血漏洞HeartBleed CVE-2014-0160深入代码层面的分析_heartbleed代码分析-程序员宅基地
文章浏览阅读1.7k次。心脏滴血漏洞HeartBleed CVE-2014-0160 是由heartbeat功能引入的,本文从深入码层面的分析该漏洞产生的原因_heartbleed代码分析
java读取ofd文档内容_ofd电子文档内容分析工具(分析文档、签章和证书)-程序员宅基地
文章浏览阅读1.4k次。前言ofd是国家文档标准,其对标的文档格式是pdf。ofd文档是容器格式文件,ofd其实就是压缩包。将ofd文件后缀改为.zip,解压后可看到文件包含的内容。ofd文件分析工具下载:点我下载。ofd文件解压后,可以看到如下内容: 对于xml文件,可以用文本工具查看。但是对于印章文件(Seal.esl)、签名文件(SignedValue.dat)就无法查看其内容了。本人开发一款ofd内容查看器,..._signedvalue.dat
基于FPGA的数据采集系统(一)_基于fpga的信息采集-程序员宅基地
文章浏览阅读1.8w次,点赞29次,收藏313次。整体系统设计本设计主要是对ADC和DAC的使用,主要实现功能流程为:首先通过串口向FPGA发送控制信号,控制DAC芯片tlv5618进行DA装换,转换的数据存在ROM中,转换开始时读取ROM中数据进行读取转换。其次用按键控制adc128s052进行模数转换100次,模数转换数据存储到FIFO中,再从FIFO中读取数据通过串口输出显示在pc上。其整体系统框图如下:图1:FPGA数据采集系统框图从图中可以看出,该系统主要包括9个模块:串口接收模块、按键消抖模块、按键控制模块、ROM模块、D.._基于fpga的信息采集
微服务 spring cloud zuul com.netflix.zuul.exception.ZuulException GENERAL-程序员宅基地
文章浏览阅读2.5w次。1.背景错误信息:-- [http-nio-9904-exec-5] o.s.c.n.z.filters.post.SendErrorFilter : Error during filteringcom.netflix.zuul.exception.ZuulException: Forwarding error at org.springframework.cloud..._com.netflix.zuul.exception.zuulexception
邻接矩阵-建立图-程序员宅基地
文章浏览阅读358次。1.介绍图的相关概念 图是由顶点的有穷非空集和一个描述顶点之间关系-边(或者弧)的集合组成。通常,图中的数据元素被称为顶点,顶点间的关系用边表示,图通常用字母G表示,图的顶点通常用字母V表示,所以图可以定义为: G=(V,E)其中,V(G)是图中顶点的有穷非空集合,E(G)是V(G)中顶点的边的有穷集合1.1 无向图:图中任意两个顶点构成的边是没有方向的1.2 有向图:图中..._给定一个邻接矩阵未必能够造出一个图
随便推点
MDT2012部署系列之11 WDS安装与配置-程序员宅基地
文章浏览阅读321次。(十二)、WDS服务器安装通过前面的测试我们会发现,每次安装的时候需要加域光盘映像,这是一个比较麻烦的事情,试想一个上万个的公司,你天天带着一个光盘与光驱去给别人装系统,这将是一个多么痛苦的事情啊,有什么方法可以解决这个问题了?答案是肯定的,下面我们就来简单说一下。WDS服务器,它是Windows自带的一个免费的基于系统本身角色的一个功能,它主要提供一种简单、安全的通过网络快速、远程将Window..._doc server2012上通过wds+mdt无人值守部署win11系统.doc
python--xlrd/xlwt/xlutils_xlutils模块可以读xlsx吗-程序员宅基地
文章浏览阅读219次。python–xlrd/xlwt/xlutilsxlrd只能读取,不能改,支持 xlsx和xls 格式xlwt只能改,不能读xlwt只能保存为.xls格式xlutils能将xlrd.Book转为xlwt.Workbook,从而得以在现有xls的基础上修改数据,并创建一个新的xls,实现修改xlrd打开文件import xlrdexcel=xlrd.open_workbook('E:/test.xlsx') 返回值为xlrd.book.Book对象,不能修改获取sheett_xlutils模块可以读xlsx吗
关于新版本selenium定位元素报错:‘WebDriver‘ object has no attribute ‘find_element_by_id‘等问题_unresolved attribute reference 'find_element_by_id-程序员宅基地
文章浏览阅读8.2w次,点赞267次,收藏656次。运行Selenium出现'WebDriver' object has no attribute 'find_element_by_id'或AttributeError: 'WebDriver' object has no attribute 'find_element_by_xpath'等定位元素代码错误,是因为selenium更新到了新的版本,以前的一些语法经过改动。..............._unresolved attribute reference 'find_element_by_id' for class 'webdriver
DOM对象转换成jQuery对象转换与子页面获取父页面DOM对象-程序员宅基地
文章浏览阅读198次。一:模态窗口//父页面JSwindow.showModalDialog(ifrmehref, window, 'dialogWidth:550px;dialogHeight:150px;help:no;resizable:no;status:no');//子页面获取父页面DOM对象//window.showModalDialog的DOM对象var v=parentWin..._jquery获取父window下的dom对象
什么是算法?-程序员宅基地
文章浏览阅读1.7w次,点赞15次,收藏129次。算法(algorithm)是解决一系列问题的清晰指令,也就是,能对一定规范的输入,在有限的时间内获得所要求的输出。 简单来说,算法就是解决一个问题的具体方法和步骤。算法是程序的灵 魂。二、算法的特征1.可行性 算法中执行的任何计算步骤都可以分解为基本可执行的操作步,即每个计算步都可以在有限时间里完成(也称之为有效性) 算法的每一步都要有确切的意义,不能有二义性。例如“增加x的值”,并没有说增加多少,计算机就无法执行明确的运算。 _算法
【网络安全】网络安全的标准和规范_网络安全标准规范-程序员宅基地
文章浏览阅读1.5k次,点赞18次,收藏26次。网络安全的标准和规范是网络安全领域的重要组成部分。它们为网络安全提供了技术依据,规定了网络安全的技术要求和操作方式,帮助我们构建安全的网络环境。下面,我们将详细介绍一些主要的网络安全标准和规范,以及它们在实际操作中的应用。_网络安全标准规范