C语言数据结构-第六章、树和二叉树-电大同步进度_给出树的广义表形式怎样看度是多少-程序员宅基地
技术标签: 数据结构与算法
第六章、树和二叉树——内容简介
线性结构中结点间具有惟一前驱、惟一后继关系,而非线性结构中结点间前驱、后继的关系并不具有惟一性。
其中,在树型结构中结点间关系是前驱惟一而后继不惟一,即结点之间是一对多的关系;
直观地看,树结构是指具有分支关系的结构(其分叉、分层的特征类似于自然界中的树)。
树和图的理论基础属离散数学内容,数据结构讨论的重点在树和图结构的实现技术。
本章主要讨论树结构的特性、存储及其操作的实现。
第1讲树的基本概念——内容简介
本节主要介绍:
树的基本概念
树相关的术语
树的ADT定义
- 数据元素集合:同属于一个数据对象
- 关系集:一对多的层次关系
- 操作集:尤其遍历操作的重要性
第1 讲树的基本概念
本节主要介绍:
一、树的基本概念
(1)树的基本概念
树是 n(n≥0)个结点的有限集合 T。当 n=0 时,称为空树;当 n>0 时,该集合满足如下条件:
①其中必有一个称为根(root)的特定结点,它没有直接前驱,但有零个或多个直接后继。
②其余 n-1 个结点可以划分成 m(m≥0)个互不相交的有限集 T1,T2,T3,…,Tm,其中Ti 又是一棵树,称为根的子树。每棵子树的根结点有且仅有一个直接前驱,但有零个或多个直接后继。
下图给出了一棵树的逻辑结构图示,它如同一棵倒长的树。
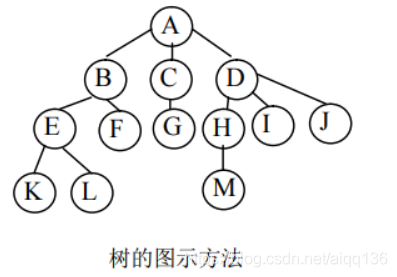
(2)树的图解表示法
①倒置树结构(树形表示法),如上图所示。
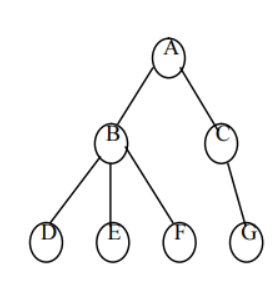
例如家族关系的表示,A 有 3 个孩子 B、C、D,B 有两个孩子 E、F,D 有 3 个孩子 H、I、J 等。
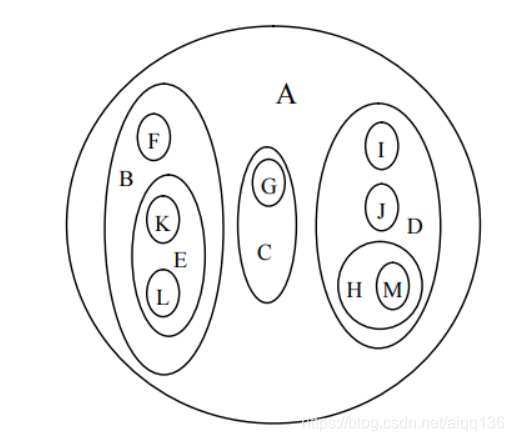
②文氏图表示法(嵌套集合表示法),如下图所示。
例如某个国家 A,分成 3 个省 B、C、D,B 省包括 F、E 市,E 市包括 K、L 县等。
③广义表形式(嵌套扩号表示法),(A(B(E(K,L),F),C(G),D(H(M),I,J)))。
例如一本书 A 分为 B、C、D 三章,B 章又分为 E、F 两节,E 节又分为 K、L 两段,等等。
④凹入表示法,用位置的缩进表示其层次,实际上程序的锯齿形结构就是这种结构。
如图所示。例如,书的目录表的编排格式

树相关的术语
结点:包括一个数据元素及若干指向其他结点的分支信息。
结点的度:一个结点的子树个数称为此结点的度。
叶结点:度为 0 的结点,即无后继的结点,也称为终端结点。
分支结点:度不为 0 的结点,也称为非终端结点。
结点的层次:从根结点开始定义,根结点的层次为 1,根的直接后继的层次为 2,依此类推。
结点的层序编号:将树中的结点按从上层到下层、同层从左到右的次序排成一个线性序列,依次给它们编以连续的自然数。
树的度:树中所有结点的度的最大值。
树的高度(深度):树中所有结点的层次的最大值。
有序树:在树 T 中,如果各子树 Ti 之间是有先后次序的,则称为有序树。
森林:m(m≥0)棵互不相交的树的集合。将一棵非空树的根结点删去,树就变成一个森林;反之,给森林增加一个统一的根结点,森林就变成一棵树。
同构:对两棵树,通过对结点适当地重命名,就可以使两棵树完全相等(结点对应相等,对应结点的相关关系也相等),则称这两棵树同构。
我们常常借助人类家族树的术语,以便于直观理解结点间的层次关系。
孩子结点:一个结点的直接后继称为该结点的孩子结点。在图 6.1 中,B 、C是 A 的孩子。
双亲结点:一个结点的直接前驱称为该结点的双亲结点。在图 6.1 中,A 是B 、C 的双亲。
兄弟结点:同一双亲结点的孩子结点之间互称兄弟结点。在图 6.1 中,结点 H、I、J 互为兄弟。
堂兄弟:父亲是兄弟关系或堂兄关系的结点称为堂兄弟结点。在图 6.1中,结点 E、G、H 互为堂兄弟。
祖先结点:一个结点的祖先结点是指从根结点到该结点的路径上的所有结点。在图 6.1 中,结点 K 的祖先是 A、B 、E。
子孙结点:一个结点的直接后继和间接后继称为该结点的子孙结点。在图6.1 中,结点 D 的子孙是 H、I、J、M。
前辈:层号比该结点小的结点,都称为该结点的前辈。在图 6.1 中,结点A、B 、C 、D 都可称为结点 E 的前辈。
后辈:层号比该结点大的结点,都称为该结点的后辈。在图 6.1 中,结点K、L、M 都可称为结点 E 的后辈。
三、树的 ADT 定义
树的抽象数据类型定义
ADT Tree
{ 数据对象 D:一个集合,该集合中的所有元素具有相同的特性。
结构关系 R:若 D 为空集,则为空树。若 D 中仅含有一个数据元素,则 R 为空集,否则 R={H},H 是如下的二元关系:
①在 D 中存在惟一的称为根的数据元素 root,它在关系 H 下没有前驱。
②除 root 以外,D 中每个结点在关系 H 下都有且仅有一个前驱。
基本操作:
① InitTree(Tree): 将 Tree 初始化为一棵空树。
② DestoryTree(Tree): 销毁树 Tree。
③ CreateTree(Tree): 创建树 Tree。
④ TreeEmpty(Tree): 若 Tree 为空,则返回 TRUE,否则返回 FALSE。
⑤ Root(Tree): 返回树 Tree 的根。
⑥ Parent(Tree,x): 树 Tree 存在,x 是 Tree 中的某个结点。若 x 为非根结点,则返回它的双亲,否则返回“空”。
⑦ FirstChild(Tree,x): 树 Tree 存在,x 是 Tree 中的某个结点。若 x 为非叶子结点,则返回它的第一个孩子结点,否则返回“空”。
⑧ NextSibling(Tree,x): 树 Tree 存在,x 是 Tree 中的某个结点。若 x 不是其双亲的最后一个孩子结点,则返回 x 后面的下一个兄弟结点,否则返回“空”。
⑨ InsertChild(Tree,p,Child): 树 Tree 存在,p 指向 Tree 中某个结点,非空树 hild与 Tree 不相交。将 Child 插入 Tree 中,做 p 所指向结点的子树。
⑩ DeleteChild(Tree,p,i): 树 Tree 存在,p 指向 Tree 中某个结点,1≤i≤d,d为 p 所指向结点的度。删除 Tree 中 p 所指向结点的第 i 棵子树。
11 TraverseTree(Tree,Visit()): 树 Tree 存在,Visit()是对结点进行访问的函数。按照某种次序对树 Tree 的每个结点调用 Visit()函数访问一次且最多一次。若 Visit()失败,则操作失败。
}
作业
树最适合用来表示( )
-
A.有序数据元素
-
B.无序数据元素
-
C.元素之间具有分支层次关系的数据
-
D.元素之间无联系的数据
若一棵树的广义表法表示为:A(B(E,F),C(G(H,I,J,K),L),D(M(N)))则该树的度为(4 );
若一棵树的广义表法表示为:A(B(E,F),C(G(H,I,J,K),L),D(M(N)))该树的深度为(4 );
若一棵树的广义表法表示为:A(B(E,F),C(G(H,I,J,K),L),D(M(N)))该树中叶子结点的个数为:(8 )

第2讲二叉树——内容简介
在进一步讨论树之前,先讨论一种简单而重要的树结构——二叉树。因为任何树都可以转化为二叉树进行处理,二叉树作为特殊的树,适合于计算机处理,所以二叉树是研究的重点。
本节主要介绍:
l 二叉树的定义与基本操作;
l 二叉树的性质;
l 二叉树的存储结构
n 顺序存储
n 链式存储(二叉树的二叉链表和三叉链表存储)
第2讲二叉树
在进一步讨论树之前,先讨论一种简单而重要的树结构——二叉树。因为任何树都可以转化为二叉树进行处理,二叉树作为特殊的树,适合于计算机处理,所以二叉树是研究的重点。
本节主要介绍:
一、二叉树的定义与基本操作
定义:把满足以下两个条件的树型结构叫做二叉树(Binary Tree):
(1) 每个结点的度都不大于 2;
(2) 每个结点的孩子结点次序不能任意颠倒。
由此定义可看出,一个二叉树中的每个结点只能含有 0、1 或 2 个孩子,而且每个孩子有左右之分。位于左边的孩子叫做左孩子,位于右边的孩子叫做右孩子。
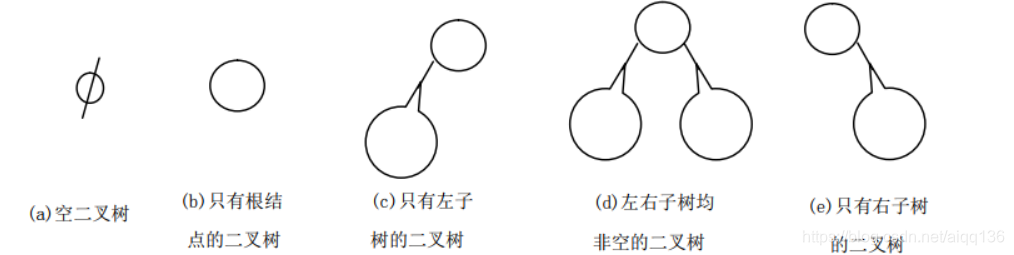
下给出了二叉树的五种基本形态:
图(a)所示为一棵空的二叉树;
图(b)所示为一棵只有根结点的二叉树;
图(c)所示为一棵只有左子树的二叉树(左子树仍是一棵二叉树);
图(d)所示为左、右子树均非空的二叉树(左、右子树均为二叉树);
图(e)所示为一棵只有右子树的二叉树(右子树也是一棵二叉树)。
二叉树也是树,故前面所介绍的有关树的术语都适用于二叉树。
与树的基本操作类似,二叉树有如下基本操作:
⑴ Initiate(bt):将 bt 初始化为空二叉树。
⑵ Create(bt):创建一棵非空二叉树 bt。
⑶ Destory(bt): 销毁二叉树 bt。
⑷ Empty(bt): 若 bt 为空,则返回 TRUE,否则返回 FALSE。
⑸ Root(bt): 求二叉树 bt 的根结点。若 bt 为空二叉树,则函数返回“空”。
⑹ Parent(bt,x):求双亲函数。求二叉树 bt 中结点 x 的双亲结点。若结点 x 是二叉树的根结点或二叉树 bt 中无结点 x,则返回“空”。
⑺ LeftChild(bt,x):求左孩子。返回结点 x 的左孩子,若结点 x 无左孩子或 x 不在bt 中,则返回“空”。
⑻ RightChild(bt,x):求右孩子。返回结点 x 的右孩子,若结点 x 无右孩子或 x 不在 bt 中,则返回“空”。
⑼ Traverse(bt): 遍历操作。按某个次序依次访问二叉树中每个结点一次且仅一次。
⑽ Clear(bt):清除操作。将二叉树 bt 置为空树。
二、二叉树的性质
性质 1:在二叉树的第 i 层上至多有![]() 个结点(i≥1)。
个结点(i≥1)。
证明:用数学归纳法。
归纳基础:当 i=1 时,整个二叉树只有一个根结点,此时![]() ,结论成立。
,结论成立。
归纳假设:假设 i=k 时结论成立,即第 k 层上结点总数最多为![]() 个。
个。
欲证明当 i=k+1 时,结论成立。
因为二叉树中每个结点的度最大为 2,则第 k+1 层的结点总数最多为第 k 层上结点最大数的 2 倍,即![]() ,故结论成立
,故结论成立
性质 2:深度为 k 的二叉树至多有![]() 个结点(k≥1)。
个结点(k≥1)。
 故结论成立
故结论成立
性质 3:对任意一棵二叉树 T,若终端结点数为 n0,而其度数为 2 的结点数为 n2,则 n0= n2+1
证明:设二叉树中结点总数为 n,n1 为二叉树中度为 1 的结点总数。因为二叉树中所有结点的度小于等于 2,所以有n= n0+ n1+n2
设二叉树中分支数目为 B,因为除根结点外,每个结点均对应一个进入它的分支,所以有n=B+1。
又因为二叉树中的分支都是由度为 1 和度为 2 的结点发出,所以分支数目为B=n1+2n2
整理上述两式,可得到n=B+1=n1+2n2+1
将 n= n0+ n1+n2 代入上式,得出 n0+ n1+n2=n1+2n2+1,整理后得 n0= n2+1,故结论成立。
下面先给出两种特殊的二叉树,然后讨论其有关性质。
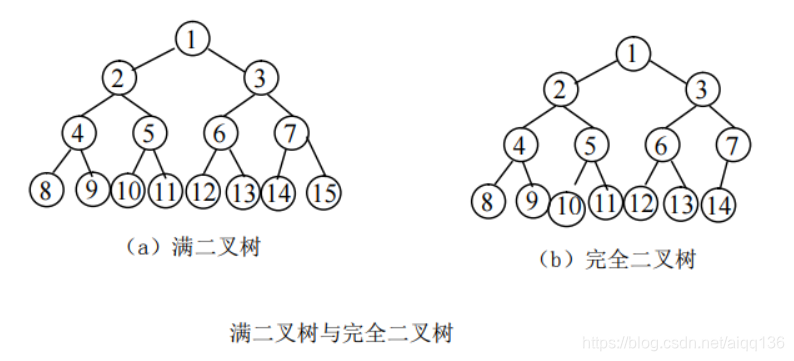
满二叉树:深度为 k 且有 2 -1 个结点的二叉树。在满二叉树中,每层结点都是满的,即每层结点都具有最大结点数。如下图(a)所示的二叉树即为一棵满二叉树。
满二叉树的顺序表示,即从二叉树的根开始,层间从上到下,层内从左到右,逐层进行编号(1,2,···,n)。
例如下图(a)所示的满二叉树的顺序表示为(1,2,3,4,5,6,7,8,9,10,11,12,13,14,15)。
完全二叉树:深度为 k,结点数为 n 的二叉树,如果其结点 1~n 的位置序号分别与满二叉树的结点 1~n 的位置序号一一对应,则为完全二叉树,如下图(b)所示。
可见,满二叉树必为完全二叉树,而完全二叉树不一定是满二叉树。
性质 4:具有 n 个结点的完全二叉树的深度为![]()
证明:假设 n 个结点的完全二叉树的深度为 k,根据性质 2 可知,k-1 层满二叉树的结点总数为:n1=2k-1-1
k 层满二叉树的结点总数为:n2=2k-1
显然有 n1<n≤n2,进一步可以推出 n1+1≤n<n2+1
将 n1=2k-1-1 和 n2=2k-1 代入上式,可得 2k-1≤n<2k,即 k-1≤log2n<k。
因为 k 是整数,所以 k-1= ![]() ,k=
,k= ![]() , 故结论成立。
, 故结论成立。
性质 5:对于具有 n 个结点的完全二叉树,如果按照从上到下和从左到右的顺序对二叉树中的所有结点从 1 开始顺序编号,则对于任意的序号为 i 的结点有:
(1)如 i=1,则序号为 i 的结点是根结点,无双亲结点;如 i>1,则序号为 i 的结点的双亲结点序号为![]() 。
。
(2)如 2×i>n,则序号为 i 的结点无左孩子;如 2×i≤n,则序号为 i 的结点的左孩子结点的序号为 2×i。
(3)如 2×i+1>n,则序号为 i 的结点无右孩子;如 2×i+1≤n,则序号为 i 的结点的右孩子结点的序号为 2×i+1。
可以用归纳法证明其中的(2)和(3):
当 i=1 时,由完全二叉树的定义知,如果 2×i=2≤n,说明二叉树中存在两个或两个以上的结点,所以其左孩子存在且序号为 2;
反之,如果 2>n,说明二叉树中不存在序号为 2的结点,其左孩子不存在。同理,如果 2×i+1=3≤n,说明其右孩子存在且序号为 3;如果3>n,则二叉树中不存在序号为 3 的结点,其右孩子不存在。
假设对于序号为 j(1≤j≤i)的结点,当 2×j≤n 时,其左孩子存在且序号为 2×j,当2×j>n 时,其左孩子不存在;当 2×j+1≤n 时,其右孩子存在且序号为 2×j+1,当 2×j+1>n时,其右孩子不存在。
当 i=j+1 时,根据完全二叉树的定义,若其左孩子存在,则其左孩子结点的序号一定等于序号为 j 的结点的右孩子的序号加 1,
即其左孩子结点的序号等于 (2×j+1)+1=2 (j+1)=2×i,且有 2×i≤n;如果 2×i>n,则左孩子不存在。若右孩子结点存在,则其右孩子结
点的序号应等于其左孩子结点的序号加 1,即右孩子结点的序号为=2×i+1,且有 2×i+1≤n;如果 2×i+1>n,则右孩子不存在。
故(2)和(3)得证。由(2)和(3)我们可以很容易证明(1)。
当 i=1 时,显然该结点为根结点,无双亲结点。
当 i>1 时,设序号为 i 的结点的双亲结点的序号为 m,如果序号为 i 的结点是其双亲结点的左孩子,
根据(2)有 i=2×m,即 m=i/2;如果序号为 i 的结点是其双亲结点的右孩子,根据(3)有 i=2×m+1,即 m=(i-1)/2=i/2-1/2,
综合这两种情况可以得到,当 i>1 时,其双亲结点的序号等于 ![]() 。证毕。
。证毕。
三、二叉树的存储结构
顺序存储
对于完全二叉树来说,可以将其数据元素逐层存放到一组连续的存储单元中,如下图所示。
用一维数组作存储结构,将二叉树中编号为 i 的结点存放在数组的第 i 个分量中。
根据二叉树的性质 5,可得结点 i 的左孩子的位置为 LChild(i)=2×i;右孩子的位置为 RChild(i)=2 ×i+1。
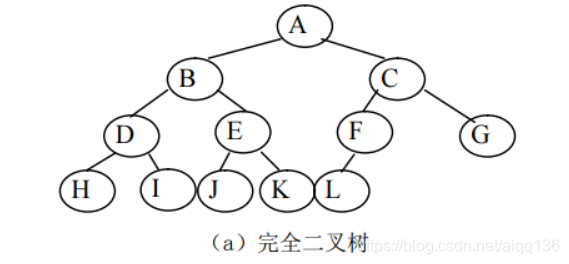
显然,这种存储方式对于一棵完全二叉树来说是非常方便的。
因为对完全二叉树采用顺序存储结构既不浪费空间,又可以根据公式计算出每一个结点的左、右孩子的位置。
但是,对于一般的二叉树,我们必须用(b)二叉树的顺序存储结构“虚结点”将其补成一棵“完全二叉树”来存储,这就会造成空间浪费。
一种极端的情况如下图所示,从中可以看出,对于一个深度为 k 的二叉树,在最坏二叉树与顺序存储结构k的情况下(每个结点只有右孩子)需要占用 2 -1 个存储单元,
而实际该二叉树只有 k 个结点,空间的浪费太大,这是顺序存储结构的一大缺点。
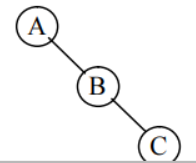

单支二叉树与其顺序存储结构
链式存储
对于任意的二叉树来说,每个结点只有两个孩子,一个双亲结点。可以设计每个结点至少包括三个域:数据域、左孩子域和右孩子域,如下图所示。
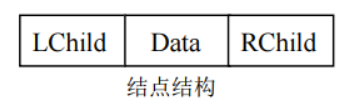
结点结构其中,LChild 域指向该结点的左孩子,Data 域记录该结点的信息,RChild 域指向该结点的右孩子。
此结点结构形成的二叉树称为二叉链表,如下图所示
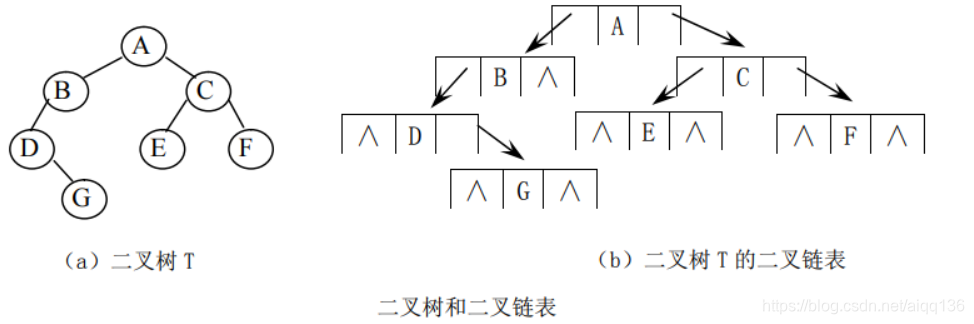
用 C 语言定义二叉树的二叉链表结点结构如下:
typedef struct Node
{
DataType data;
struct Node * LChild;
struct Node * RChild;
}BiTNode, *BiTree;
若一个二叉树含有 n 个结点,则它的二叉链表中必含有 2n 个指针域,其中必有 n+1 个空的链域。
证明:分支数目 B=n-1,即非空的链域有 n-1 个,故空链域有 2n-(n-1)=n+1 个。
有时,为了便于找到双亲结点,可以增加一个 Parent 域,以指向该结点的双亲结点。
采用这种结点结构的存放方式称做二叉树的三叉链表存储结构。
不同的存储结构实现二叉树的操作也不同。
如要找某个结点的父结点,在三叉链表中很容易实现;
在二叉链表中则需从根指针出发一一查找。
可见,在具体应用中,要根据二叉树的形态和要进行的操作来决定采用哪种二叉树的存储结构。
作业
按照二叉树的定义,具有3个结点的二叉树有( )种
-
A.3
-
B.4
-
C.5
-
D.6
若一棵二叉树有10个度为2的结点,5个度为1的结点,则度为0的结点有( )个。
-
A.9
-
B.11
-
C.15
-
D.不确定
一个高度为h的完全二叉树至少有( )个结点
-
A.
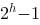
-
B.
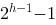
-
C.
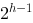
-
D.
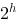
二叉树就是结点度不大于2的树。()
-
A.✓
-
B.×
不存在这样的二叉树:它有n个度为0的结点,n-1个度为1的结点,n-2个度为2的结点。( )
-
A.✓
-
B.×
具有n个结点的二叉树采用二叉链表存储结构,共有(n-1 )非空的指针域。
拥有100个结点的完全二叉树的最大层数是(7 )
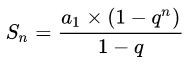
第3讲二叉树的遍历——内容简介
二叉树的遍历是指按一定规律对二叉树中的每个结点进行访问且仅访问一次。
二叉树是非线性数据结构,遍历操作就是将二叉树中结点按一定规律线性化的操作,目的在于将非线性化结构变成线性化的访问序列。二叉树的遍历操作是二叉树中最基本的运算。
本节主要介绍:
l 二叉树遍历的定义
l 二叉树遍历的规律及相关递归遍历算法
n 二叉树的先序遍历
n 二叉树的中序遍历
n 二叉树的后序遍历
第 3 讲二叉树的遍历
二叉树的遍历是指按一定规律对二叉树中的每个结点进行访问且仅访问一次。
二叉树是非线性数据结构,遍历操作就是将二叉树中结点按一定规律线性化的操作,目的在于将非线性化结构变成线性化的访问序列。
二叉树的遍历操作是二叉树中最基本的运算。
本节主要介绍:
一、二叉树遍历的定义
二叉树的遍历是指按一定规律对二叉树中的每个结点进行访问且仅访问一次。
其中的访问可指计算二叉树中结点的数据信息,打印该结点的信息,也包括对结点进行任何其他操作。
为什么需要遍历二叉树?二叉树是非线性数据结构,通过遍历可以将二叉树中的结点访问一次且仅一次,从而得到访问结点的顺序序列。
从这个意义上说,遍历操作就是将二叉树中结点按一定规律线性化的操作,目的在于将非线性化结构变成线性化的访问序列。
二叉树的遍历操作是二叉树中最基本的运算。
二、二叉树遍历的规律及相关递归遍历算法
二叉树的基本结构是由根结点、左子树和右子树三个基本单元组成的,因此只要依次遍历这三部分,就遍历了整个二叉树。
如果用 L、D、R 分别表示遍历左子树、访问根结点、遍历右子树,那么对二叉树的遍历顺序就可以有 6 种方式:
⑴ 访问根,遍历左子树,遍历右子树(记做 DLR)。
⑵ 访问根,遍历右子树,遍历左子树(记做 DRL)。
⑶ 遍历左子树,访问根,遍历右子树(记做 LDR)。
⑷ 遍历左子树,遍历右子树,访问根(记做 LRD)。
⑸ 遍历右子树,访问根,遍历左子树(记做 RDL)。
⑹ 遍历右子树,遍历左子树,访问根(记做 RLD)。
在以上 6 种遍历方式中,如果规定按先左后右的顺序,那么就只剩有 DLR 、LDR和 LRD三种。
根据对根的访问先后顺序不同,分别称 DLR 为先序遍历或先根遍历;LDR 为中序遍历(对称遍历);LRD 为后序遍历。
注意:先序、中序、后序遍历是递归定义的,即在其子树中亦按上述规律进行遍历。
下面就分别介绍三种遍历方法的递归定义。
(1)先序遍历(DLR)操作过程
若二叉树为空,则空操作,否则依次执行如下 3 个操作:
① 访问根结点;
② 按先序遍历左子树;
③ 按先序遍历右子树。
(2)中序遍历(LDR)操作过程
若二叉树为空,则空操作,否则依次执行如下 3 个操作:
① 按中序遍历左子树;
② 访问根结点;
③ 按中序遍历右子树。
(3)后序遍历(LRD)操作过程
若二叉树为空,则空操作,否则依次执行如下 3 个操作:
① 按后序遍历左子树;
② 按后序遍历右子树;
③ 访问根结点。
显然,遍历操作是一个递归过程。
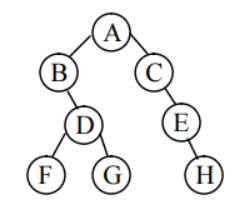
对于如下图所示的二叉树,其先序、中序、后序遍历的序列如下
先序遍历: A、B、D、F、G、C、E、H 。
中序遍历: B、F、D、G、A、C、E、H
后序遍历: F、G、D、B、H、E、C、A
最早提出遍历问题是对存储在计算机中的表达式求值。例如:(a+b*c)-d/e。该表达式用二叉树表示如上右图所示。
当对此二叉树进行先序、中序、后序遍历时,便可获得表达式的前缀、中缀、后缀书写形式:
前缀:-+a*bc/de
中缀:a+b*c-d/e
后缀:abc*+de/-
其中中缀形式是算术表达式的通常形式,只是没有括号。
前缀表达式称为波兰表达式。算术表达式的后缀表达式被称作逆波兰表达式。
在计算机内,使用后缀表达式易于求值。下面以二叉链表作为存储结构来具体讨论二叉树的遍历算法。
(1) 先序遍历
【算法描述】
void PreOrder(BiTree root)
/*先序遍历二叉树, root为指向二叉树(或某一子树)根结点的指针*/
{
if (root!=NULL)
{
Visit(root ->data); /*访问根结点*/
PreOrder(root ->LChild); /*先序遍历左子树*/
PreOrder(root ->RChild); /*先序遍历右子树*/
}
}(2)中序遍历
【算法描述】
void InOrder(BiTree root)
/*中序遍历二叉树, root为指向二叉树(或某一子树)根结点的指针*/
{
if (root!=NULL)
{
InOrder(root ->LChild); /*中序遍历左子树*/
Visit(root ->data); /*访问根结点*/
InOrder(root ->RChild); /*中序遍历右子树*/
}
}(3) 后序遍历
【算法描述】
void PostOrder(BiTree root)
/* 后序遍历二叉树,root为指向二叉树(或某一子树)根结点的指针*/
{
if(root!=NULL)
{
PostOrder(root ->LChild); /*后序遍历左子树*/
PostOrder(root ->RChild); /*后序遍历右子树*/
Visit(root ->data); /*访问根结点*/
}
}显然这三种遍历算法的区别表现在 Visit 语句的位置不同,但都采用了递归的方法。
为了便于理解递归算法,以中序遍历为例,说明中序遍历二叉树的递归过程,如下图所示。
当中序遍历图 (a)时,p 指针首先指向 A 结点。按照中序遍历的规则,先要遍历 A 的左子树。此时递归进层,p 指针指向 B 结点,进一步递归进层到 B 的左子树根。此时由于 p指针等于 NULL,对 B 的左子树的遍历结束,递归退层到 B 结点。访问 B 结点后递归进层到 B 的右子树。此时 p 指针指向 D 结点。进一步进层到 D 的左子树,由于 D 没有左子树,退层到 D 结点。访问 D 后进层到 D 的右子树,由于 D 没有右子树,又退层到 D 结点,此时完成了对 D 结点的遍历,退层到 B 结点。此时对 B 结点的遍历完成,递归退层到 A 结点,访问 A 结点后又进层到 A 的右子树。此时 p 指针指向 C 结点。同样,按照中序的规则,应该递归进层到 C 的左子树,此时 p 指针为 NULL,退层到 C 结点,访问 C 结点后又递归到C 的右子树。此时 p 指针指向 E 结点,进一步进层到 E 的左子树。因为 p 等于 NULL,所以退层到 E,访问 E 结点后,进层到 E 的右子树。由于 p 等于 NULL,又退层到 E,完成对E 结点的遍历,进一步退层到 C 结点,完成对 C 的遍历。最后退层到 A。至此完成了对整个二叉树的遍历。递归算法的时间复杂度分析:设二叉树有 n 个结点,对每个结点都要进行一次入栈和出栈的操作,即入栈和出栈各执行 n 次,对结点的访问也是 n 次。这些二叉树递归遍历算法的时间复杂度为 O(n)。
作业
某二叉树的先序序列和中序序列正好相同,则该二叉树一定是( )
-
A.空树或只有一个结点
-
B.完全二叉树
-
C.每个结点都没有左子
-
D.高度等于其结点数
在二叉树中,p所指向的结点为度为1的分支点的条件是( )
-
A.p->lchild= =NULL ||p->rchild= =NULL
-
B.!( p->lchild! =NULL &&p->rchild!=NULL)
-
C.!(p->lchild= =NULL &&p->rchild= =NULL)
-
D.(p->lchild= =NULL &&p->rchild! =NULL)||
(p->lchild! =NULL &&p->rchild= =NULL)
已知二叉树的先序和后序遍历序列可以唯一确定该二叉树。( )
-
A.✓
-
B.×
第4讲 二叉树遍历算法应用——内容简介
二叉树的遍历运算是一个重要的基础,对访问根结点操作的理解可包括各种各样的操作。
【本节要点】:
通过6个例子,扩展遍历算法解决二叉树的操作问题。
应用要点:
l 一是重点理解访问根结点操作的含义,
l 二是注意对具体的实现时是否需要考虑遍历的次序选择要求。
第 4 讲 遍历算法应用
二叉树的遍历运算是一个重要的基础。一是重点理解访问根结点操作的含义,二是注意对具体的实现时是否需要考虑遍历的次序选择要求。
1.输出二叉树中的结点
【算法思想】
输出二叉树中的结点并无次序要求,因此可用三种遍历算法中的任何一种完成,只需将访问操作具体变为输出操作即可。下面给出采用先序遍历实现的算法。
【算法描述】
void PreOrder(BiTree root)
/*先序遍历二叉树, root为指向二叉树根结点的指针*/
{
if (root!=NULL)
{
printf("%c ",root ->data); /*输出结点*/
PreOrder(root ->LChild); /*先序遍历左子树*/
PreOrder(root ->RChild); /*先序遍历右子树*/
}
}2.输出二叉树中的叶子结点
【算法思想】
输出二叉树中的叶子结点与输出二叉树中的结点相比,它是一个有条件的输出问题,即在遍历过程中走到每一个结点时需进行测试,看是否满足叶子结点的条件。
【算法描述】
void PreOrder(BiTree root)
/*先序遍历二叉树, root为指向二叉树根结点的指针*/
{
if (root!=NULL)
{
if (root ->LChild==NULL && root ->RChild==NULL)
printf("%c ",root ->data); /*输出叶子结点*/
PreOrder(root ->LChild); /*先序遍历左子树*/
PreOrder(root ->RChild); /*先序遍历右子树*/
}
}3.统计叶子结点数目
方法一【算法思想】
统计二叉树中的叶子结点数目并无次序要求,因此可用三种遍历算法中的任何一种完成,只需将访问操作具体变为判断是否为叶子结点及统计操作即可。下面给出采用后序遍历实现的算法。
方法二【算法思想】
给出求叶子点数目的递归定义:
1)如果是空树,返回 0;
2)如果只有一个结点,返回 1;
3)否则为左右子树的叶子结点数之和。
【算法描述】
/* LeafCount保存叶子结点的数目的全局变量,调用之前初始化值为0 */
void leaf_a(BiTree root)
{
if(root!=NULL)
{
leaf_a(root->LChild);
leaf_a(root->RChild);
if (root ->LChild==NULL && root ->RChild==NULL)
LeafCount++;
}
}
int leaf_b(BiTree root)
{
int LeafCount2;
if(root==NULL)
LeafCount2 =0;
else
if((root->LChild==NULL)&&(root->RChild==NULL))
LeafCount2 =1;
else
LeafCount2 =leaf_b(root->LChild)+leaf_b(root->RChild);
/* 叶子数为左右子树的叶子数目之和 */
return LeafCount2;
}4.建立二叉链表方式存储的二叉树
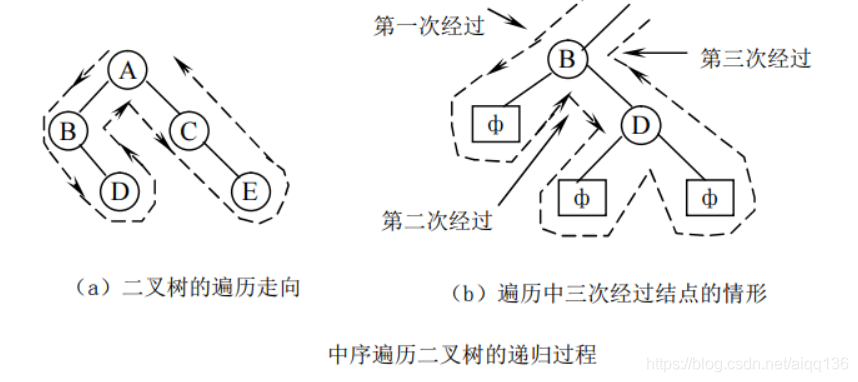
给定一棵二叉树,我们可以得到它的遍历序列;反过来,给定一棵二叉树的遍历序列,我们也可以创建相应的二叉链表。
这里所说的遍历序列是一种“扩展的遍历序列”。在通常的遍历序列中,均忽略空子树,而在扩展的遍历序列中,必须用特定的元素表示空子树。
例如,左图 中二叉树的“扩展先序遍历序列”为:AB.DF..G..C.E.H..。其中用小圆点表示空子树。
利用“扩展先序遍历序列” 创建二叉链表的算法如下:
【算法思想】
采用类似先序遍历的递归算法,首先读入当前根结点的数据,如果是“.”则将当前树根置为空,否则申请一个新结点,
存入当前根结点的数据,分别用当前根结点的左子域和右子域进行递归调用,创建左、右子树。
【算法描述】
算法 6.7 用“扩展先序遍历序列” 创建二叉链表
void CreateBiTree(BiTree *bt)
{
char ch;
ch = getchar();
if(ch=='.') *bt=NULL;
else
{
*bt=(BiTree)malloc(sizeof(BiTNode)); //生成一个新结点
(*bt)->data=ch;
CreateBiTree(&((*bt)->LChild)); //生成左子树
CreateBiTree(&((*bt)->RChild)); //生成右子树
}
}5.求二叉树的高度
二叉树的高度(深度)为二叉树中结点层次的最大值,也可视为其左、右子树高度的最大值加 1。
【算法思想】
二叉树 bt 高度的递归定义如下:
若 bt 为空,则高度为 0。
若 bt 非空,其高度应为其左、右子树高度的最大值加 1,如下图所示。

下面给出用后序遍历求二叉树高度的递归算法。
【算法描述】
int PostTreeDepth(BiTree bt) /* 后序遍历求二叉树的高度递归算法 */
{
int hl,hr,max;
if(bt!=NULL)
{
hl=PostTreeDepth(bt->LChild); /* 求左子树的深度 */
hr=PostTreeDepth(bt->RChild); /* 求右子树的深度 */
max=hl>hr?hl:hr; /* 得到左、右子树深度较大者*/
return(max+1); /* 返回树的深度 */
}
else return(0); /* 如果是空树,则返回0 */
}求二叉树的高度是也可用前序遍历的方式实现。
【算法思想】
二叉树的高度(深度)为二叉树中结点层次的最大值。
设根结点为第一层的结点,所有 h 层的结点的左、右孩子结点在 h+1 层。
故可以通过遍历计算二叉树中的每个结点的层次,其中最大值即为二叉树的高度。
下面给出用先序遍历求二叉树高度的递归算法。
【算法描述】
void PreTreeDepth(BiTree bt, int h)
/* 前序遍历求二叉树bt高度的递归算法,h为bt指向结点所在层次,初值为1*/
/*depth为当前求得的最大层次,为全局变量,调用前初值为0 */
{
if(bt!=NULL)
{
if(h>depth) depth = h; /*如果该结点层次值大于depth,更新depth的值*/
PreTreeDepth(bt->Lchild, h+1); /* 遍历左子树 */
PreTreeDepth(bt->Rchild, h+1); /* 遍历右子树 */
}
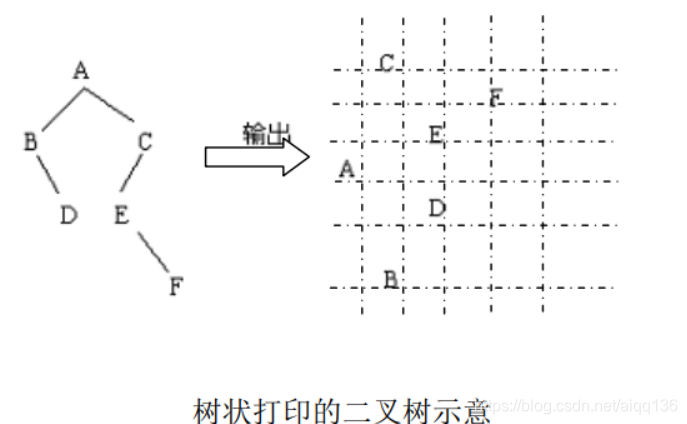
}6.按树状打印二叉树
假设以二叉链表存储的二叉树中,每个结点所含数据元素均为单字母。 要求实现二叉树的横向显示问题,如下图所示打印结果。
【算法思想】
这种树形打印格式要求先打印右子树,再打印根,最后打印左子树,按由上而下顺序看,其输出的结点序列为:CFEADB,这恰为逆中序顺序。
解决二叉树的横向显示问题采用“逆中序”遍历框架,所以横向显示二叉树算法为先右子树、再根结点、再左子树的 RDL 结构。
(2)在这种输出格式中,结点的左、右位置与结点的层深有关,
故算法中设置了一个表示当前根结点层深的参数,以控制输出结点的左、右位置,每当递归进层时层深参数加 1。
这些操作应在访问根结点时实现。
【算法描述】
void PrintTree(BiTree bt,int nLayer) /* 按竖向树状打印的二叉树 */
{
if(bt == NULL) return;
PrintTree(bt->RChild,nLayer+1);
for(int i=0;i<nLayer;i++)
printf(" ");
printf("%c\n",bt->data);
PrintTree(bt->LChild,nLayer+1);
}
作业
设二叉树采用二叉链表方式存储,root指向根结点,r所指结点为二叉树中任一给定的结点。则可以通过改写( )算法,求出从根结点到结点r之间的路径。
-
A.先序遍历
-
B.中序遍历
-
C.后序遍历
-
D.层次遍历
(多选)已知二叉树用二叉链表存储,则若实现二叉树实现左右子树交换,可以借助改写( )遍历算法实现。
-
A.先序遍历
-
B.中序遍历
-
C.后序遍历
-
D.以上三种都可以
第5讲 二叉树遍历算法(基于栈的递归消除)——内容简介
在第三章中,已介绍了尾递归的直接消除法,它可用循环代替递归。但在大量复杂的情况下如二叉树的遍历问题,该问题无法直接转换成循环,所以需要采用工作栈+循环结构消除递归。
【本节要点】
l 二叉树中序遍历递归转非递归算法
l 二叉树后序遍历递归转非递归算法
第 5 讲 二叉树遍历算法基于栈的递归消除
二叉树的遍历问题递归的问题无法直接转换成循环,所以需要采用工作栈消除递归。
工作栈提供一种控制结构,当递归算法进层时需要将信息保留;当递归算法出层时需要从栈区退出上层信息。
1.中序遍历二叉树的非递归算法
首先应用递归进层三件事与递归退层三件事的原则,直接先给出中序遍历二叉树的非递归算法基本实现思路。
【算法思想】
(1) 针对左递归,写出递归进层的三件事。
(2) 接着写出左递归返回时应执行的语句:访问根结点。
(3) 接着针对右递归,写出递归进层的三件事。
(4) 针对递归退层,写出递归退层的三件事(左、右递归公用)。
【算法描述】 中序遍历二叉树非递归算法初步
void inorder(BiTree root);
{
int top=0; p=bt;
L1: if (p!=NULL) /* 遍历左子树 */
{
top=top+2;
if(top>m) return; /*栈满溢出处理*/
s[top-1]=p; /* 本层参数进栈 */
s[top]=L2; /* 返回地址进栈 */
p=p->LChild; /* 给下层参数赋值 */
goto L1; /* 转向开始 */
L2: Visit(p->data); /* 访问根 */
top=top+2;
if(top>m) return; /*栈满溢出处理*/;
s[top-1]=p; /* 遍历右子树 */
s[top]=L3;
p=p->RChild;
goto L1;
}
L3: if(top!=0)
{ addr=s[top];
p=s[top-1]; /* 取出返回地址 */
top=top-2; /* 退出本层参数 */
goto addr;
}
}
/*算法a*/
可看到,直接按定义得到的上述算法结构并不好,为使程序合理组织,需去掉goto 语句,
用循环句代替 if 与 goto, 此时返回断点已无保留的必要,栈区只需保留本层参数即可。整理后的算法框图如下图:
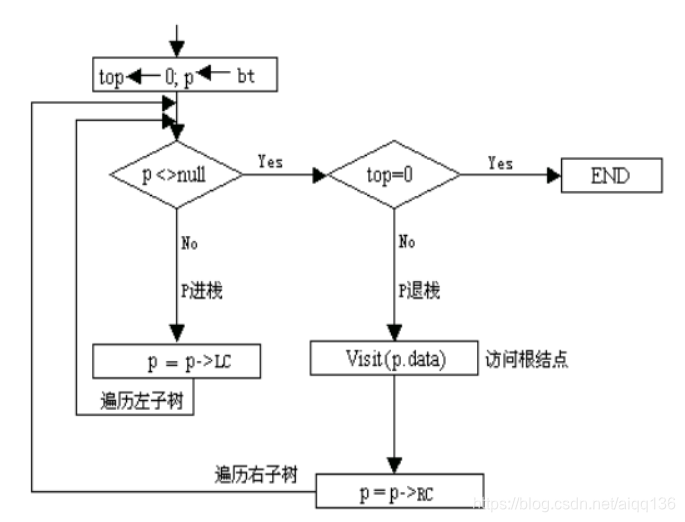
中序遍历非递归算法需要设置一个堆栈,用以保留结点指针,以便在遍历完某个结点的左子树后,由该结点指针找到该结点的右子树。
【算法思想】从根结点开始,只要当前结点存在,或者栈不空,则重复下面操作:
(1) 从当前结点开始,进栈并走左子树,直到左子树为空。
(2) 退栈并访问。
(3) 走右子树。
【算法描述】 中序遍历二叉树的非递归算法 b (直接实现桟操作)
void inorder(BiTree root) /* 中序遍历二叉树,root为二叉树的根结点 */
{
int top=0;
BiTree p;
BiTree s[Stack_Size];
int m;
m = Stack_Size-1;
p = root;
do
{
while(p!=NULL)
{
if (top>m) return;
top=top+1;
s[top]=p;
p=p->LChild;
}; /* 遍历左子树 */
if(top!=0)
{
p=s[top];
top=top-1;
Visit(p->data); /* 访问根结点 */
p=p->RChild; /* 遍历右子树 */
}
}
while(p!=NULL || top!=0);
}
/*算法b*/【算法思想】从根结点开始,只要当前结点存在,或者栈不空,则重复下面操作:
(1) 如果当前结点存在,则进栈并走左子树。
(2) 否则退栈并访问,然后走右子树。
【算法描述】中序遍历二叉树的非递归算法(c) (调用栈操作的函数)
void InOrder(BiTree root) /* 中序遍历二叉树的非递归算法 */
{
SeqStack S;
BiTree p;
InitStack (&S);
p=root;
while(p!=NULL || !IsEmpty(&S))
{
if (p!=NULL) /* 根指针进栈,遍历左子树 */
{
Push(&S,p);
p=p->LChild;
}
else
{ /*根指针退栈,访问根结点,遍历右子树*/
Pop(&S,&p);
Visit(p->data);
p=p->RChild;
}
}
}
/*算法c*/递归算法的时间复杂度分析:
对有 n 个结点二叉树,该算法每循环一次,p 指向一个结点或空(无左孩子或无右孩子的结点的空链域),
因此指向空的次数为n+1,n 为结点个数,故循环次数为 n+(n+1)=2n+1,因此算法的复杂度为 O(n)。
递归算法的空间复杂度分析:所需栈的空间最多等于二叉树深度 K 乘以每个结点所需空间数,记作 O(K)。
表面上看,递归算法好象并没有使用栈,实际上递归算法的执行需要反复多次的自己调用自己。
每调用一次,系统内部都有系统运行栈区在支持,这是隐含的栈,需要保留本层参数、临时变量与返回地址等。
随着函数递归调用,运行栈继续增长,直到函数执行完,才彻底释放占用的栈空间。因此递归算法比非递归算法占用的空间更多。
2.后序遍历二叉树的非递归算法
后序遍历的非递归算法比较复杂。
由于后序遍历是 LRD,要求左、右子树都访问完后,最后访问根结点。
如何判断当前栈顶结点的左、右子树都已访问过?
解决的方案有多种,采用的方法是:判断刚访问过的结点 q 是不是当前栈顶结点 p 的右孩子。
判别是否应该访问当前栈顶结点 p 时,有两种情况:
(1)p 无右孩子,此时应该访问根结点;
(2)如 p 的右孩子是刚被访问过的结点 q(表明 p 的右子树已遍历过),此时也应该访问根结点。
除这两种情况外,均不应访问根,而是要继续进入右子树中。
因此,算法采用了记录刚访问结点的方法,以便在遍历过程中利用前驱 q 与当前结点 p 的关系做判别。
【算法思想】从根结点开始,只要当前结点存在,或者栈不空,则重复下面操作:
(1) 从当前结点开始,进栈并走左子树,直到左子树为空;
(2) 如果栈顶结点的右子树为空,或者栈顶结点的右子孩子为刚访问过的结点,则退栈并访问,然后将当前结点指针置为空;
(3) 否则,走右子树。
【算法描述】后序遍历二叉树的非递归算法(调用栈操作的函数)
void PostOrder(BiTree root)
{
BiTNode *p,*q;
BiTNode **s;
int top=0;
q=NULL;
p=root;
s=(BiTNode**)malloc(sizeof(BiTNode*)*NUM);
/* NUM为预定义的常数 */
while(p!=NULL || top!=0)
{
while(p!=NULL)
{
top++;
s[top]=p;
p=p->LChild;
} /*遍历左子树*/
if(top>0)
{
p=s[top];
if((p->RChild==NULL) ||(p->RChild==q)) /* 无右孩子,或右孩子已遍历过 */
{
visit(p->data); /* 访问根结点*/
q=p; /* 保存到q,为下一次已处理结点前驱 */
top--;
p=NULL;
}
else
p=p->RChild;
}
}
free(s);
}
作业
在中序遍历非递归算法中,在进入子树进行访问前,需要在自定义栈中保存( )
-
A.本层根结点指针
-
B.本层根结点的右孩子指针
-
C.本层根结点的左孩子指针
-
D.无需保留任何信息
第6讲线索二叉树——内容简介
二叉树的遍历运算是将二叉树中结点按一定规律线性化的过程。当以二叉链表作为存储结构时,只能找到结点的左、右孩子信息,而不能直接得到结点在遍历序列中的前驱和后继信息。可以充分利用二叉链表中的空链域,将遍历过程中结点的前驱、后继信息保存下来。线索化实质上是将二叉链表中的空指针域填上相应结点的遍历前驱或后继结点的地址,而前驱和后继的地址只能在动态的遍历过程中才能得到。对二叉树按照不同的遍历次序进行线索化,可以得到不同的线索二叉树,包括先序线索二叉树、中序线索二叉树和后序线索二叉树。
【本节要点】
l 线索二叉树基本概念
l 二叉树的线索化
l 在线索二叉树中找前驱、后继结点
第6 讲线索二叉树——教学讲义
二叉树的遍历运算是将二叉树中结点按一定规律线性化的过程。
当以二叉链表作为存储结构时,只能找到结点的左、右孩子信息,而不能直接得到结点在遍历序列中的前驱和后继信息。
要得到这些信息可采用以下两种方法:
- 第一种方法是将二叉树遍历一遍,在遍历过程中便可得到结点的前驱和后继,但这种动态访问浪费时间;
- 第二种方法是充分利用二叉链表中的空链域,将遍历过程中结点的前驱、后继信息保存下来。
下面重点讨论第二种方法。
我们知道,在有 n 个结点的二叉链表中共有 2n 个链域,但只有 n-1 个有用的非空链域,其余 n+1 个链域是空的。
可以利用剩下的 n+1 个空链域来存放遍历过程中结点的前驱和后继信息。
现作如下规定:若结点有左子树,则其 LChild 域指向其左孩子,否则 LChild 域指向其前驱结点;
若结点有右子树,则其 RChild 域指向其右孩子,否则 RChild 域指向其后继结点。
为了区分孩子结点和前驱、后继结点,为结点结构增设两个标志域,如下图所示:

其中:

在这种存储结构中,指向前驱和后继结点的指针叫做线索。
以这种结构组成的二叉链表作为二叉树的存储结构,叫做线索链表。
对二叉树以某种次序进行遍历并且加上线索的过程叫做线索化。线索化了的二叉树称为线索二叉树。
一、二叉树的线索化
线索化实质上是将二叉链表中的空指针域填上相应结点的遍历前驱或后继结点的地址,
而前驱和后继的地址只能在动态的遍历过程中才能得到。
因此线索化的过程即为在遍历过程中修改空指针域的过程。
对二叉树按照不同的遍历次序进行线索化,可以得到不同的线索二叉树,包括先序线索二叉树、中序线索二叉树和后序线索二叉树。
这里重点介绍中序线索化的算法。
【算法思想】
(1)中序线索化采用中序递归遍历算法框架。
(2)加线索操作就是访问结点操作。
(3)加线索操作需要利用刚访问过结点与当前结点的关系,因此设置一个指针 pre,始终记录刚访问过的结点,其操作如下:
①如果当前遍历结点 root 的左子域为空,则让左子域指向 pre ;
②如果前驱 pre 的右子域为空,则让右子域指向当前遍历结点 root;
③为下次做准备,当前访问结点 root 作为下一个访问结点的前驱 pre。
【算法描述】 建立中序线索树
void Inthread(BiTree root)
/* 对root所指的二叉树进行中序线索化,其中pre始终指向刚访问过的结点,其初值为NULL*/
{
if (root!=NULL)
{
Inthread(root->LChild); /* 线索化左子树 */
if (root->LChild==NULL)
{
root->Ltag=1;
root->LChild=pre; /*置前驱线索 */
}
if (pre!=NULL&& pre->RChild==NULL) /* 置后继线索 */
{
pre->RChild=root;
pre->Rtag=1;
}
pre=root;
Inthread(root->RChild); /*线索化右子树*/
}
} 对于同一棵二叉树,遍历的方法不同,得到的线索二叉树也不同。图 6.20 所示为一棵二叉树的先序、中序和后序线索树。
二.在线索二叉树中找前驱、后继结点
我们以中序线索二叉树为例,来讨论如何在线索二叉树中查找结点的前驱和后继。
(1)找结点的中序前驱结点
根据线索二叉树的基本概念和存储结构可知,对于结点 p,当 p->Ltag=1 时,p->LChild 指向 p 的前驱。
当 p->Ltag=0 时,p->LChild 指向 p 的左孩子。
由中序遍历的规律可知,作为根 p 的前驱结点,它是中序遍历 p 的左子树时访问的最后一个结点,即左子树的“最右下端”结点。
其查找算法如下:
【算法描述】 在中序线索树中找结点前驱
BiTNode * InPre(BiTNode *p)
/* 在中序线索二叉树中查找p的中序前驱, 并用pre指针返回结果 */
{
BiTNode *q;
if(p->Ltag==1)
pre = p->LChild; /*直接利用线索*/
else
{ /* 在p的左子树中查找"最右下端"结点 */
for(q = p->LChild;q->Rtag==0;q=q->RChild);
pre=q;
}
return(pre);
}
(2)在中序线索树中找结点后继
对于结点 p,若要找其后继结点,当 p->Rtag=1 时,p->RChild 即为 p 的后继结点;
当 p->Rtag=0时,说明 p 有右子树,此时 p 的中序后继结点即为其右子树的“最左下端”的结点。其查找算法如下:
【算法描述】 在中序线索树中找结点后继
BiTNode * InNext(BiTNode * p)
/*在中序线索二叉树中查找p的中序后继结点,并用next指针返回结果*/
{
BiTNode *Next;
BiTNode *q;
if (p->Rtag==1)
Next = p->RChild; /*直接利用线索*/
else
{ /*在p的右子树中查找"最左下端"结点*/
if(p->RChild!=NULL)
{
for(q=p->RChild; q->Ltag==0 ;q=q->LChild);
Next=q;
}
else
Next = NULL;
}
return(Next);
}在先序线索树中找结点的后继比较容易,根据先序线索树的遍历过程可知,
若结点 p 存在左子树,则 p 的左孩子结点即为 p 的后继;
若结点 p 没有左子树,但有右子树,则 p 的右孩子结点即为 p 的后继;
若结点 p 既没有左子树,也没有右子树,则结点 p 的 RChild 指针域所指的结点即为 p 的后继。
用语句表示则为:
if (p→Ltag==0) Next=p→Lchild;
else Next =p→RChild;
同样,在后序线索树中查找结点 p 的前驱也很方便。
在先序线索树中找结点的前驱比较困难。
若结点 p 是二叉树的根,则 p 的前驱为空;
若 p是其双亲的左孩子,或者 p 是其双亲的右孩子并且其双亲无左孩子,则 p 的前驱是 p 的双亲结点;
若 p 是双亲的右孩子且双亲有左孩子,则 p 的前驱是其双亲的左子树中按先序遍历时最后访问的那个结点。
三.遍历中序线索树
遍历线索树的问题可以分解成两步,第一步是求出某种遍历次序下第一个被访问结点;
然后连续求出刚访问结点的后继结点,直至所有的结点均被访问。以遍历中序线索树为例。
(1)在中序线索树上求中序遍历的第一个结点
【算法描述】 在中序线索树上求中序遍历的第一个结点
BiTNode* TinFirst(BiTree root)
{
BiTNode *p;
p = root;
if(p)
while(p->LChild!=NULL)
p=p->LChild;
return p;
}(2)遍历中序二叉线索树:通过调用 InFirst 和 InNext ,可以实现对中序线索树的中序
遍历,且不需要使用递归栈。函数 TInOrder 实现了这种遍历,见算法。
【算法描述】遍历中序二叉线索树
void TinOrder(BiTree root)
{
BiTNode *p;
p=TinFirst(root);
while(p!=NULL)
{
printf("%c ",p->data);
p=InNext(p);
}
}四、线索二叉树的插入、删除运算(略)
作业
引入线索二叉树的目的是( )
-
A.加快查找指定遍历过程中结点的直接前驱和直接后继
-
B.为了能在二叉树中方便地插入和删除结点
-
C.为了方便找到结点的双亲
-
D.使二叉树遍历结果唯一
若判断线索二叉树中的p结点有右孩子结点则下列()表达式为真。
-
A.p!=NULL
-
B.p->rchild!=NULL
-
C.p->rtag= =0
-
D.p->rtag= =1
若线索二叉树中的p结点没有左孩子结点则下列( )表达式为真。
-
A.p==NULL
-
B.p->lchild==NULL
-
C.p->ltag= =0
-
D.p->ltag= =1
第7讲由遍历序列确定的二叉树——内容简介
在二叉树的遍历中,我们知道,给定一棵二叉树和一种遍历方法,就可以确定该二叉树相应的线性序列。
如何根据给定的遍历序列能否唯一的确定一棵二叉树?要根据遍历序列确定二叉树,至少需要知道该二叉树的两种遍历序列。
【本节要点】
l 已知中序和先序序列确定二叉树
l 已知中序和后序序列确定二叉树
第7 讲由遍历序列确定的二叉树——教学讲义
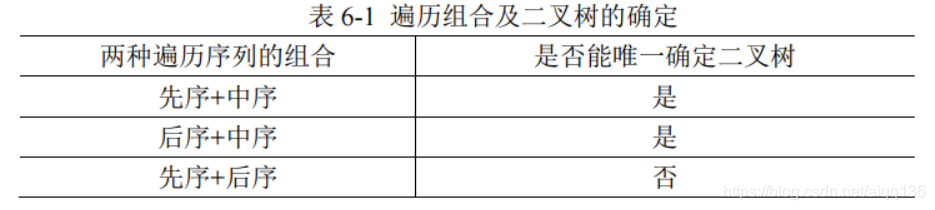
在二叉树的遍历中,我们知道,给定一棵二叉树和一种遍历方法,就可以确定该二叉树相应的线性序列。那么,根据给定的遍历序列能否唯一的确定一棵二叉树呢?
显然,只由一种序列是无法确定二叉树的,要根据遍历序列确定二叉树,至少需要知道该二叉树的两种遍历序列。表 6-1 列出了两种遍历序列组合确定二叉树的情况。
例已知一棵二叉树的先序序列与中序序列分别为:
A B C D E F G H I
B C A E D G H F I
试构造该二叉树。
分析:根据定义,二叉树的先序遍历是先访问根结点,
其次再按先序遍历方式遍历根结点的左子树,最后按先序遍历方式遍历根结点的右子树。
这就是说,在先序序列中,第一个结点一定是二叉树的根结点。如下图(a)所示。
另一方面,中序遍历是先遍历左子树,然后访问根结点,最后再遍历右子树。
这样,根结点在中序序列中必然将中序序列分割成两个子序列,前一个子序列是根结点的左子树的中序序列,
而后一个子序列是根结点的右子树的中序序列。如下图(b)所示。

根据这两个子序列,在先序序列中根据中序序列对应的左子树的先序序列和右子树的先序序列。
在先序序列中,左子序列的第一个结点是左子树的根结点,右子序列的第一个结点是右子树的根结点。
这样,就确定了二叉树的三个结点。
同时,左子树和右子树的根结点又可以分别把左子序列和右子序列划分为两个子序列,如此递归下去,当取尽先序序列中的结点时,便可以得到一棵二叉树。
具体到本题目,首先由先序序列可知,结点 A 是二叉树的根结点。
其次,根据中序序列,在 A 之前的所有结点都是根结点左子树的结点,在 A 之后的所有结点都是根结点右子树的结点,由此得到下图(a)所示的状态。
然后再对左子树进行分解,得知 B 是左子树的根结点,又从中序序列知道,B 的左子树为空,B 的右子树只有一个结点 C。
接着对 A 的右子树进行分解,得知 A 的右子树的根结点为 D;
而结点 D 把其余结点分成两部分,即左子树为 E,右子树为 F、G、H、I,如下图(b)所示。
接下去的工作就是按上述原则对 D 的右子树继续分解下去,最后得到如下图(c)所示的整棵二叉树。

作业
一棵二叉树的后序序列是:CBEFDA,中序序列是:CBAEDF,则该二叉树的先序序列是( )
-
A.ABCDEF
-
B.ABCEDF
-
C.ABDEFC
-
D.ABFECD
一棵二叉树的先序序列是:CEDBA,中序序列是:DEBAC ,则该二叉树的后序序列是( )
-
A.DABEC
-
B.DCBAE
-
C.DEABC
-
D.CBADE
第8讲 树、森林和二叉树的关系——内容简介
本讲主要讨论树的存储结构以及树、森林与二叉树的转换关系。
【本节要点】
n 树的存储结构
n 树、森林与二叉树的相互转换
n 树与森林的遍历
第8 讲 树、森林和二叉树的关系——教学讲义
本节主要讨论树的存储结构以及树、森林与二叉树的转换关系。
一、 树的存储结构
树的主要存储方法有以下三种:
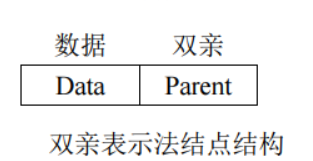
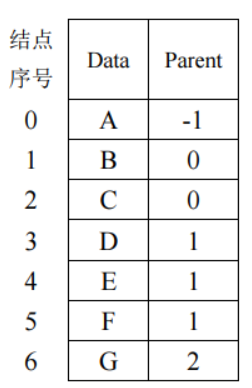
1.双亲表示法
这种方法用一组连续的空间来存储树中的结点,在保存每个结点的同时附设一个指示器来指示其双亲结点在表中的位置,其结点的结构如下图所示。
整棵树用含有 MAX 个上述结点的一维数组来表示,如下图所示。
种存储法利用了树中每个结点(根结点除外)只有一个双亲结点的性质,使得查找某个结点的双亲结点非常容易。
反复使用求双亲结点的操作,也可以较容易地找到树根。但是,在这种存储结构中,求某个结点的孩子时需要遍历整个数组。
双亲表示法的形式说明如下:
#define MAX 100
typedef struct TNode{
DataType data;
int parent;
} TNode;树可以定义为:
typedef struct{
TNode tree[MAX];
int nodenum; /*结点数*/
} ParentTree;2.孩子表示法
这种方法通常是把每个结点的孩子结点排列起来,构成一个单链表,称为孩子链表。
n 个结点共有 n 个孩子链表(叶子结点的孩子链表为空表),而 n 个结点的数据和 n 个孩子链表的头指针又组成一个顺序表。
树采用这种存储结构时,其结果如下图所示。

孩子表示法的存储结构定义如下:
typedef struct ChildNode /* 孩子链表结点的定义 */
{
int Child; /* 该孩子结点在线性表中的位置 */
struct ChildNode* next; /*指向下一个孩子结点的指针 */
} ChildNode;
typedef struct/* 顺序表结点的结构定义 */
{
DataType data;/* 结点的信息 */
ChildNode* FirstChild;/* 指向孩子链表的头指针 */
} DataNode;
typedef struct /*树的定义*/
{
DataNode nodes[MAX]; /* 顺序表 */
int root;/* 该树的根结点在线性表中的位置 */
int num;/* 该树的结点个数 */
} ChildTree;
3.孩子兄弟表示法
这种表示法又称为树的二叉表示法,或者二叉链表表示法,即以二叉链表作为树的存储结构。链表中每个结点设有两个链域,分别指向该结点的第一个孩子结点和下一个兄弟(右兄弟)结点。
下图为树的孩子兄弟表示结构
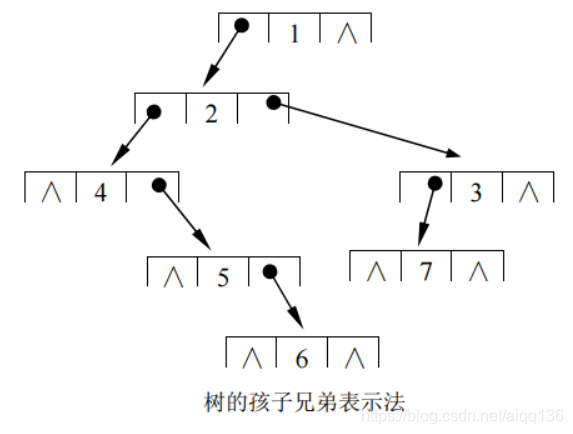
孩子兄弟表示法的类型定义如下:
typedef struct CSNode
{
DataType data; /*结点信息*/
Struct CSNode* FirstChild; /*第一个孩子*/
Struct CSNode* Nextsibling; /*下一个兄弟*/
} CSNode, * CSTree;
这种存储结构便于实现树的各种操作,例如,如果要访问结点 x 的第 i 个孩子,则只要先从FirstChild 域找到第一个孩子结点,
然后沿着这个孩子结点的 Nextsibling 域连续走 i-1步,便可找到 x 的第 i 个孩子。如果在这种结构中为每个结点增设一个 Parent 域,则同样可以方便地实现查找双亲的操作。
二、树、森林与二叉树的相互转换
前面介绍了树的存储结构和二叉树的存储结构,
从中可以看到,树的孩子兄弟链表结构与二叉树的二叉链表结构在物理结构上是完全相同的,
只是它们的逻辑含义不同,所以树和森林与二叉树之间必然有着密切的关系。
本节介绍树和森林与二叉树之间的相互转换方法。
1.树转换为二叉树
对于一棵无序树,树中结点的各孩子的次序是无关紧要的,而二叉树中结点的左、右孩子结点是有区别的。
为了避免混淆,约定树中每一个结点的孩子结点按从左到右的次序顺序编号,也就是说,把树作为有序树看待。
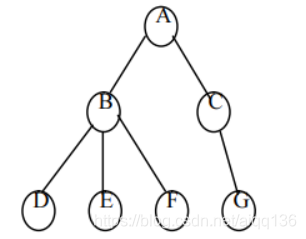
如图所示的一棵树,根结点 A 有三个孩子 B、C、D,可以认为结点 B 为 A 的第一个孩子结点,结点 D 为 A 的第三个孩子结点。
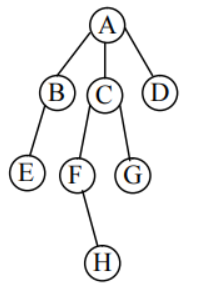
将一棵树转换为二叉树的方法是:
⑴ 树中所有相邻兄弟之间加一条连线。
⑵ 对树中的每个结点,只保留其与第一个孩子结点之间的连线,删去其与其他孩子结点之间的连线。
⑶ 以树的根结点为轴心,将整棵树顺时针旋转一定的角度,使之结构层次分明。可以证明,树做这样的转换所构成的二叉树是惟一的。下图给出了右上图中的树转换为二叉树的转换过程示意。
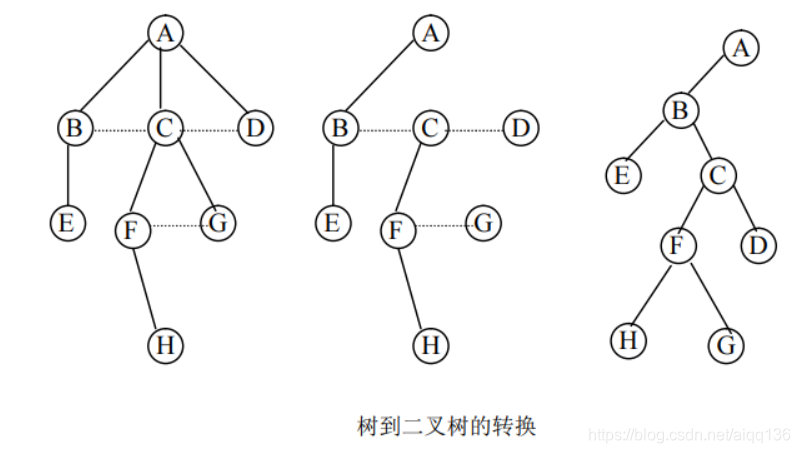
通过转换过程可以看出,树中的任意一个结点都对应于二叉树中的一个结点。
树中某结点的第一个孩子在二叉树中是相应结点的左孩子,树中某结点的右兄弟结点在二叉树中是相应结点的右孩子。
也就是说,在二叉树中,左分支上的各结点在原来的树中是父子关系,而右分支上的各结点在原来的树中是兄弟关系。
由于树的根结点没有兄弟,所以变换后的二叉树的根结点的右孩子必然为空。
事实上,一棵树采用孩子兄弟表示法所建立的存储结构与它所对应的二叉树的二叉链表存储结构是完全相同的,
只是两个指针域的名称及解释不同而已,通过下图直观地表示了树与二叉树之间的对应关系和相互转换方法。
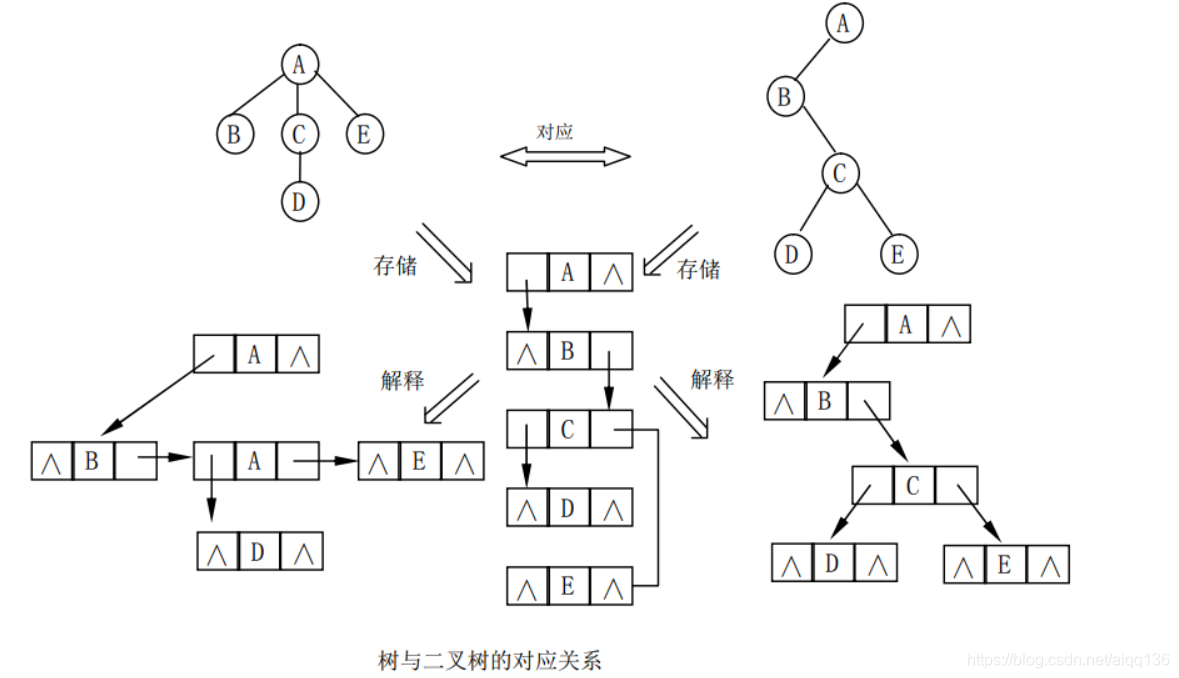
因此,二叉链表的有关处理算法可以很方便地转换为树的孩子兄弟链表的处理算法。
2.森林转换为二叉树
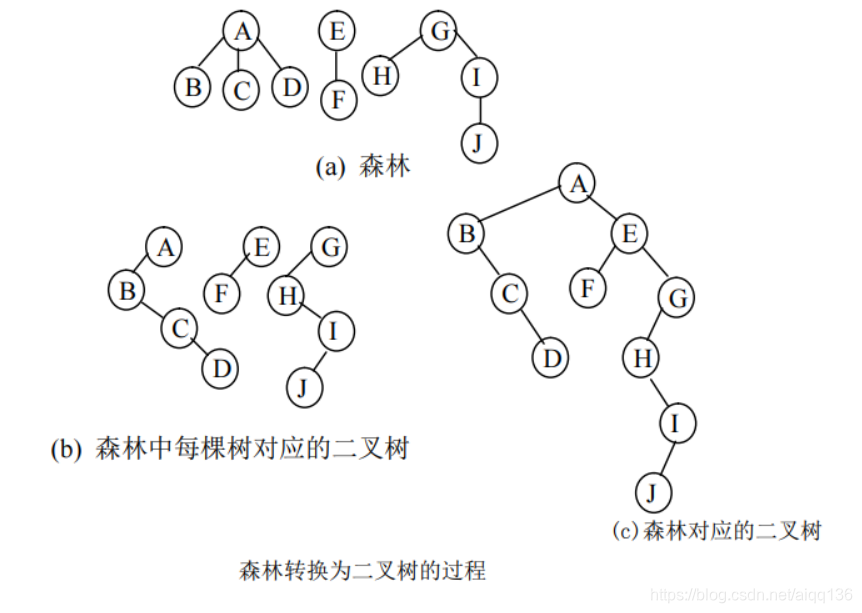
森林是若干棵树的集合。树可以转换为二叉树,森林同样也可以转换为二叉树。因此,森林也可以方便地用孩子兄弟链表表示。森林转换为二叉树的方法如下:
(1) 将森林中的每棵树转换成相应的二叉树。
(2) 第一棵二叉树不动,从第二棵二叉树开始,依次把后一棵二叉树的根结点作为前
一棵二叉树根结点的右孩子,当所有二叉树连在一起后,所得到的二叉树就是由森林转换得到的二叉树。
森林转换为二叉树的过程,还可以用递归的方法描述上述转换过程:
将森林 F 看作树的有序集 F={T1,T2,…,TN},它对应的二叉树为 B(F):
(1)若 N=0,则 B(F)为空。
(2)若 N>0,二叉树 B(F)的根为森林中第一棵树 T1 的根; B(F)的左子树为 B({T11,…,T1m}),其中{T11,…,T1m}是 T1 的子树森林;B(F)的右子树是 B({T2,…,TN})。
根据这个递归的定义,可以很容易地写出递归的转换算法。
例:给出将下图(a)给出了森林转换为二叉树的过程。
3.二叉树还原为树或森林
树和森林都可以转换为二叉树,二者的不同是:树转换成的二叉树,其根结点必然无右孩子,而森林转换后的二叉树,其根结点有右孩子。将一棵二叉树还原为树或森林,具体方法如下:
(1) 若某结点是其双亲的左孩子,则把该结点的右孩子、右孩子的右孩子、……都与该结点的双亲结点用线连起来。
(2) 删掉原二叉树中所有双亲结点与右孩子结点的连线。
(3) 整理由(1)、(2)两步所得到的树或森林,使之结构层次分明。
例 6-4 给出将下图(a)的一棵二叉树还原为森林的过程示意图。

同样,可以用递归的方法描述上述转换过程。
若 B 是一棵二叉树,T 是 B 的根结点,L 是 B 的左子树,R 为 B 的右子树,且 B 对应的森林 F(B)中含有的 n 棵树为 T1,T2, …,Tn,则有:
(1) B 为空,则 F(B)为空的森林(n=0)。
(2) B 非空,则 F(B)中第一棵树 T1 的根为二叉树 B 的根 T;T1 中根结点的子树
森林由 B 的左子树 L 转换而成,即 F(L)={T11,…,T1m};B 的右子树 R 转换为 F(B)中其余树组成的森林,即 F(R)={ T2, T3, …,Tn}。
根据这个递归的定义,同样可以写出递归的转换算法。
6.4.3树与森林的遍历
1.树的遍历
树的遍历方法主要有以下两种:
(1)先根遍历
若树非空,则遍历方法为:
① 访问根结点。
② 从左到右,依次先根遍历根结点的每一棵子树。
例如,图中树的先根遍历序列为 ABECFHGD。

2)后根遍历
若树非空,则遍历方法为:
①从左到右,依次后根遍历根结点的每一棵子树。
②访问根结点。
例如,右图中树的后根遍历序列为 EBHFGCDA。
树的遍历结果与由树转化成的二叉树有如下对应关系:
树的先根遍历 转化二叉树的前序遍历
树的后根遍历 转化二叉树的中序遍历
2.树的遍历的算法实现
在选定了存储结构后可按上述对应规则写出相应实现算法。
例如:用孩子兄弟链表实现树的先根遍历。
[方法一]:
void RootFirst(CSTree root)
{
if (root != NULL)
{
Visit(root->data); /* 访问根结点 */
p = root->FirstChild;
while (p != NULL)
{
RootFirst(p); /* 访问以 p 为根的子树 */
p = p->Nextsibling;
}
}
}[方法二]:
void RootFirst(CSTree root)
{
if (root != NULL)
{
Visit(root->data); /*访问根结点*/
RootFirst(root->FirstChild); /*先根遍历首子树*/
RootFirst(root->Nextsibling); /*先根遍历兄弟树*/
}
}
3. 森林的遍历
森林的遍历方法主要有以下三种:
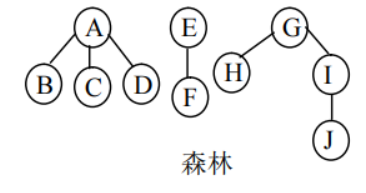
(1)先序遍历
若森林非空,则遍历方法为:
①访问森林中第一棵树的根结点。
②先序遍历第一棵树的根结点的子树森林。
③先序遍历除去第一棵树之后剩余的树构成的森林。
例如,图中森林的先序遍历序列为 ABCDEFGHIJ。
(2)中序遍历
若森林非空,则遍历方法为:
①中序遍历森林中第一棵树的根结点的子树森林。
②访问第一棵树的根结点。
③中序遍历除去第一棵树之后剩余的树构成的森林。
例如,右图中森林的中序遍历序列为 BCDAFEHJIG。
(3)后序遍历
若森林非空,则遍历方法为:
①后序遍历森林中第一棵树的根结点的子树森林。
② 后序遍历除去第一棵树之后剩余的树构成的森林。
③访问第一棵树的根结点。
例如,右图中森林的后序遍历序列为 DCBFJIHGEA。
对照二叉树与森林之间的转换关系可以发现,森林的先序遍历、中序遍历和后序遍历与其相应二叉树的先序遍历、中序遍历和后序遍历是对应相同的,
因此可以用相应二叉树的遍历结果来验证森林的遍历结果。
另外,树可以看成只有一棵树的森林,所以树的先根遍历和后根遍历分别与森林的先序遍历和中序遍历对应。
森林的遍历算法可以采用其对应的二叉树的遍历算法来实现。
作业
如图所示的二叉树BT是由森林T1转换而来的二叉树,那么森林T1中有( )叶子结点。
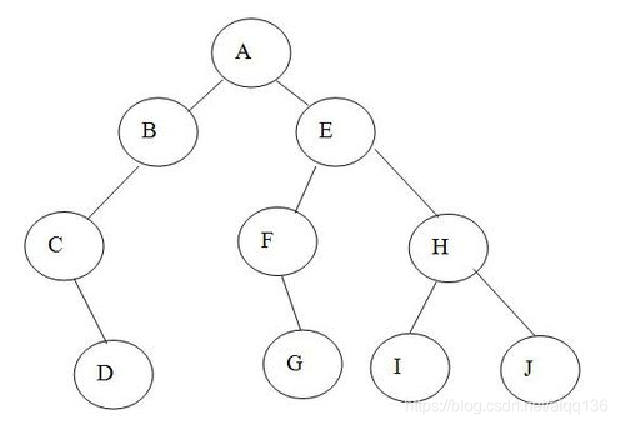
-
A.4
-
B.5
-
C.6
-
D.7
与树等价的二叉树,根没有( )子树。
第9讲 哈夫曼树及其构造——内容简介
哈夫曼树可用来构造最优编码,用于信息传输、数据压缩等方面,哈夫曼树是一种应用广泛的二叉树。
【本节要点】
l 哈夫曼树基本概念
l 哈夫曼树构造算法
第9 讲 哈夫曼树及其构造——教学讲义
哈夫曼树可用来构造最优编码,用于信息传输、数据压缩等方面,哈夫曼树是一种应用广泛的二叉树。
一、 哈夫曼树
1.哈夫曼树的基本概念
在介绍哈夫曼树之前,先给出几个基本概念。
l 结点间的路径和路径长度
路径是指从一个结点到另一个结点之间的分支序列,路径长度是指从一个结点到另一个结点所经过的分支数目。
l 结点的权和带权路径长度
在实际的应用中,人们常常给树的每个结点赋予一个具有某种实际意义的实数,称该实数为这个结点的权。
在树型结构中,把从树根到某一结点的路径长度与该结点的权的乘积,叫做该结点的带权路径长度。
l 树的带权路径长度
树的带权路径长度为树中从根到所有叶子结点的各个带权路径长度之和,通常记为:
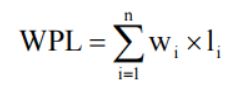
其中 n 为叶子结点的个数,wi 为第 i 个叶子结点的权值,li 为第 i 个叶子结点的路径长度。
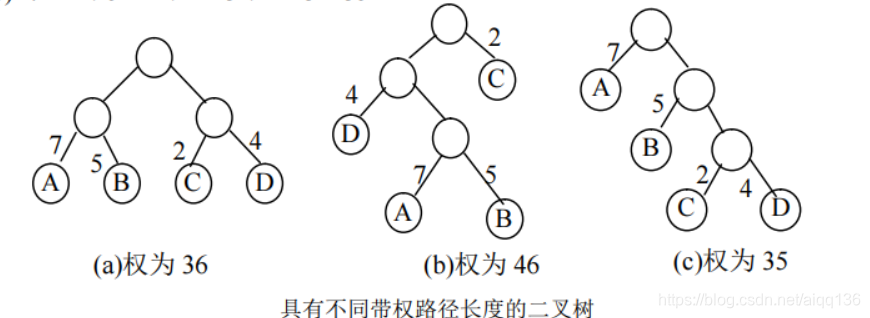
例 6-5 计算下图中三棵二叉树的带权路径长度。
WPL(a)=7×2+5×2+2×2+4×2=36
WPL(b)=4×2+7×3+5×3+2×1=46
WPL(c)=7×1+5×2+2×3+4×3=35
研究树的路径长度 PL 和带权路径长度 WPL,目的在于寻找最优分析。
问题 1: 什么样的二叉树的路径长度 PL 最小?
一棵树的
路径长度为 0 结点至多只有 1 个 (根)
路径长度为 1 结点至多只有 2 个 (两个孩子)
路径长度为 2 结点至多只有 4 个
路径长度为 k 结点至多只有 ![]() 个
个
所以 n 个结点二叉树其路径长度至少等于如下图所示序列的前 n 项之和。

由上图可知,结点 n 对应的路径长度为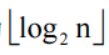 所以前 n 项之和为
所以前 n 项之和为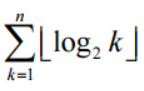
完全二叉树的路径长度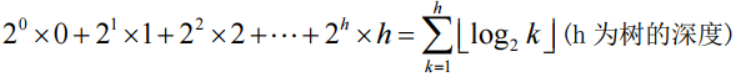
所以完全二叉树具有最小路径长度的性质,但不具有惟一性。有些树并不是完全二叉树,但也可以具有最小路径长度。如下图所示。

问题 2:什么样的带权的树路径长度最小?
例如:给定一个权值序列{2,3,4,7},可构造如下图所示的多种二叉树的形态。
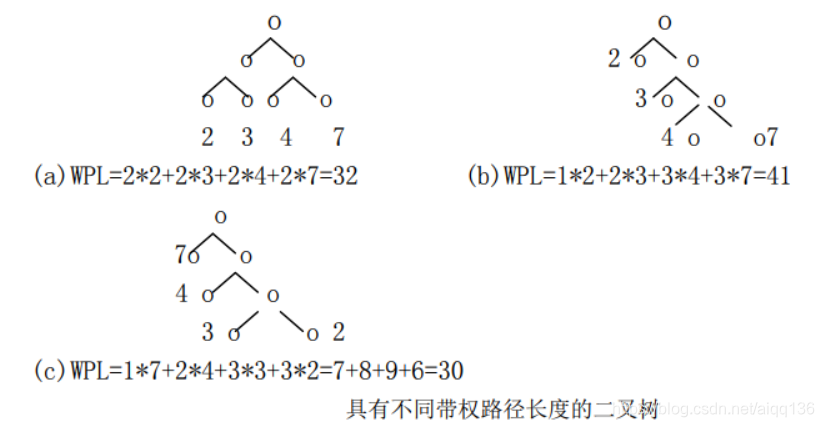
上图(a)所示二叉树是完全二叉树,但并不具有最小带权的路径长度,由此可见完全二叉树不一定 WPL 最小,如何在 Min{m(T)}中找最小呢?
给定 n 个实数 w1,....wn(n>=2),求一个具有 n 个终端结点的二叉树,使其带权路径长度 ∑wili 最 小。 其中每个 终端结 点 ki 有 一个权值 wi 与它 对应, li 为根到 叶子的 路
径长度。由于哈夫曼给出了构造这种树的规律,将给定结点构成一棵(外部通路)带权树的路径长度最小的二叉树,因此就称为哈夫曼树。
2. 构造哈夫曼树
哈夫曼树:它是由 n 个带权叶子结点构成的所有二叉树中带权路径长度最短的二叉树。
因为这种树最早由哈夫曼(Huffman)研究,所以称为哈夫曼树,又叫最优二叉树,图 6.38(c)所示的二叉树就是一棵哈夫曼树。
构造哈夫曼树的算法步骤如下:
(1) 初始化:用给定的 n 个权值 {w1, w2, … , wn} 对应的由 n 棵二叉树构成的森林F={T1,T2, …,Tn},其中每一棵二叉树 Ti (1≤i≤n)都只有一个权值为 wi 的根结点,其左、右子树为空。
(2) 找最小树:在森林 F 中选择两棵根结点权值最小的二叉树,作为一棵新二叉树的左、右子树,标记新二叉树的根结点权值为其左、右子树的根结点权值之和。
(3) 删除与加入:从 F 中删除被选中的那两棵二叉树,同时把新构成的二叉树加入到森林F 中。
(4) 判断:重复(2)、(3)操作,直到森林中只含有一棵二叉树为止,此时得到的这棵二叉树就是哈夫曼树。
直观地看,先选择权小的,所以权小的结点被放置在树的较深层,而权较大的离根较近,
这样自然在哈夫曼树中权越大叶子离根越近,这样一来,在计算树的带权路径长度时,自然会具有最小带权路径长度,这种生成算法就是一种典型的贪心法。
手工构造的方法也非常简单:给定一组权值 { w1, w2, … , wn},用 n 个权值构成 n 棵单根树的森林 F;将 F={T1,T2,… ,Tn}按权值从小到大排列; 取 T1 和 T2 合并组成一棵树,
使其根结点的权值 T=T1+T2,再按大小插入 F,重复此过程,直到只有一棵树为止。给定一组权值 {7,4,3,2 },用上述方法构造哈夫曼树,将得到图 6.38(c)所示的二叉树。
3. 哈夫曼树的类型定义
(1) 存储结构
哈夫曼树是一种二叉树,当然可以采用前面已经介绍过的通用存储方法,而哈夫曼树是求某种最优方案,由于哈夫曼树中没有度为 1 的结点,因此一棵有 n 个叶子的哈夫曼树共有 2×n-1 个结点,可以用一个大小为 2×n-1 的一维数组存放哈夫曼树的各个结点。由于每个结点同时还包含其双亲信息和孩子结点的信息,所以构成一个静态三叉链表。静态三叉链表中:每个结点的结构如下图所示。

各结点存储在一维数组中,0 号单元不使用,从 1 号位置开始使用。下图给出了一棵二叉树及其静态三叉链表。
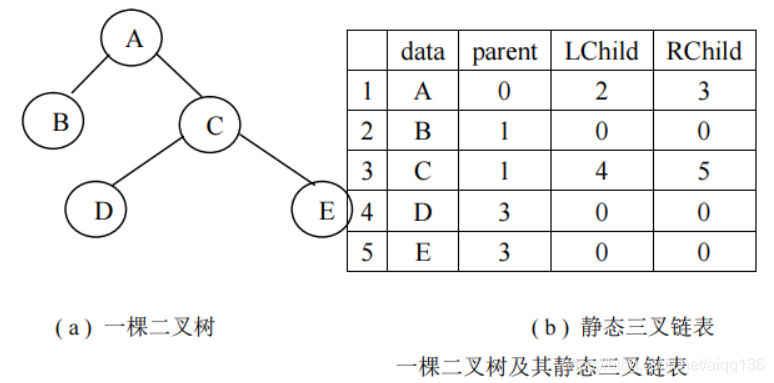
对于有 n 个叶子结点的哈夫曼树,结点总数为 2n-1 个,为实现方便,将叶子结点集中存储在前面部分 1~n 个位置,而后面的 n-1 个位置中存储其余非叶子结点。
(2)哈夫曼树的类型定义
用静态三叉链表实现的哈夫曼树类型定义如下:
#define N 20 /* 叶子结点的最大值。*/
#define M 2*N-1 /* 所有结点的最大值。*/
typedef struct
{
int weight; /* 结点的权值*/
int parent; /* 双亲的下标*/
int LChild; /* 左孩子结点的下标*/
int RChild; /* 右孩子结点的下标*/
} HTNode, HuffmanTree[M + 1]; /* HuffmanTree 是一个结构数组类型,0 号单元不
用。 */
4.哈夫曼树的算法实现
【算法描述】 创建哈夫曼树算法
void CrtHuffmanTree(HuffmanTree *ht , int *w, int n)
{ /* w存放已知的n个权值,构造哈夫曼树ht */
int m,i;
int s1,s2;
m=2*n-1;
*ht=(HuffmanTree)malloc((m+1)*sizeof(HTNode)); /*0号单元未使用*/
for(i=1;i<=n;i++)
{/*1-n号放叶子结点,初始化*/
(*ht)[i].weight = w[i];
(*ht)[i].LChild = 0;
(*ht)[i].parent = 0;
(*ht)[i].RChild = 0;
}
for(i=n+1;i<=m;i++)
{
(*ht)[i].weight = 0;
(*ht)[i].LChild = 0;
(*ht)[i].parent = 0;
(*ht)[i].RChild = 0;
} /*非叶子结点初始化*/
/* ------------初始化完毕!对应算法步骤1---------*/
for(i=n+1;i<=m;i++) /*创建非叶子结点,建哈夫曼树*/
{ /*在(*ht)[1]~(*ht)[i-1]的范围内选择两个parent为0且weight最小的结点,其序号分别赋值给s1、s2返回*/
select(ht,i-1,&s1,&s2);
(*ht)[s1].parent=i;
(*ht)[s2].parent=i;
(*ht)[i].LChild=s1;
(*ht)[i].RChild=s2;
(*ht)[i].weight=(*ht)[s1].weight+(*ht)[s2].weight;
}
}/*哈夫曼树建立完毕*/该算法分成两大部分,其中第一部分是初始化,先初始化 ht 的前 1~n 号元素,存放叶子结
点(相当初始森林),它们都没有双亲与孩子。再初始化 ht 的后 n-1 个(从 n+1~2n-1)非叶
结点元素;第二部分为实施选择、删除合并 n-1 次(相当步骤(2)~(4)):选择是从当前
森林中(在森林中树的根结点的双亲为 0)选择两棵根的权值最小的树;删除合并是将选到
的两棵树的根权和存入 ht 的当前最前面的空闲元素中(相当于合并树中新结点),并置入相
应的双亲与孩子的位置指示。
例 数据传送中的二进制编码。要传送数据 state, seat, act, tea, cat, set, a ,eat ,如何使传送的
长度最短?
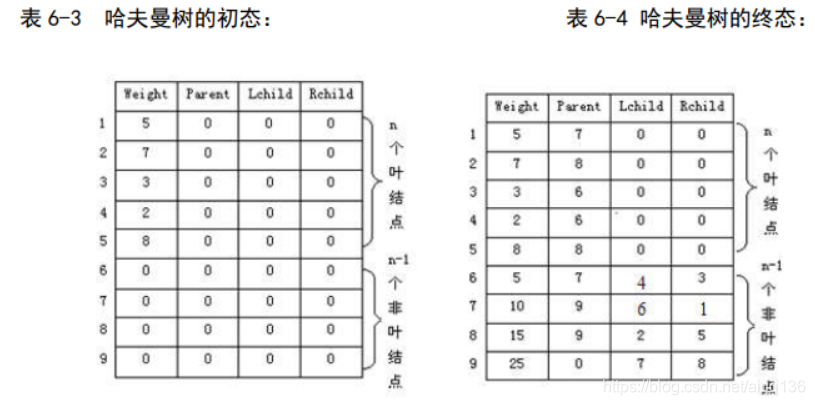
为了保证长度最短,先计算各个字符出现的次数,将出现次数当作权,如表 6-2 所示
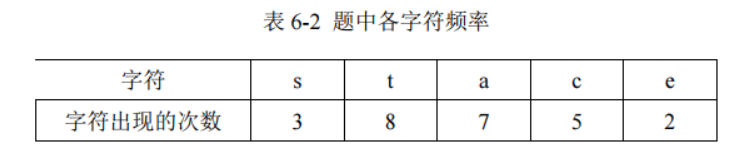
树算法,该例建立哈夫曼树的结果如图所示
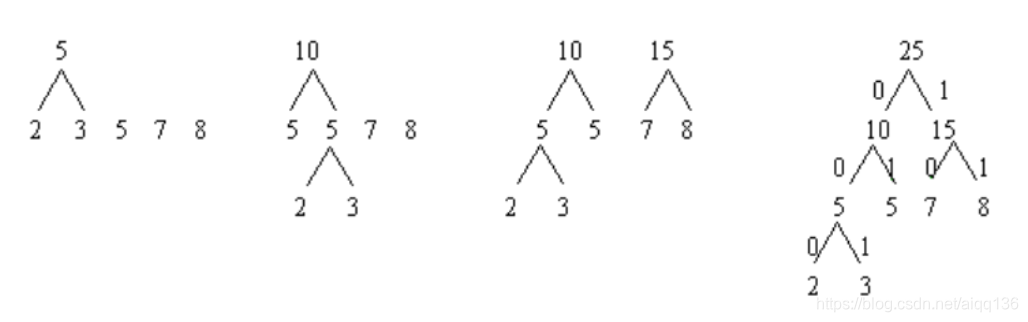
按照创建哈夫曼树算法,该例建立哈夫曼树的结果如下表 6-3 与表 6-4:
作业
有13个叶子结点的哈夫曼树,该树中结点总数为( )
-
A.13
-
B.26
-
C.12
-
D.25
在哈夫曼树中,权值相同的叶子点一定在同一层上。( )
-
A.✓
-
B.×
在哈夫曼树中,权值较大的叶子点一般离根比较近。( )
-
A.✓
-
B.×
若以{4,5,6,7,8}作为叶子点构造哈夫曼树,则其带全路径长度为( )
第10讲 哈夫曼编码及构造——内容简介
哈夫曼树可用来构造最优编码,用于信息传输、数据压缩等方面,哈夫曼树是一种应用广泛的二叉树。
【本节要点】
l 哈夫曼编码基本概念
l 哈夫曼编码构造算法
第 10 讲 哈夫曼编码与构造——教学讲义
哈夫曼编码
由于哈夫曼树是具有相同叶子个数的二叉树中带权路径长度最小的二叉树,涉及求根据给定叶子(带权)求其“规模最小”的二叉树问题,用哈夫曼树构造哈夫曼编码就是其典型应用。
1.哈夫曼编码的概念
用电子方式处理符号时,需先对符号进行二进制编码。例如,在计算机中使用的英文字
符的 ASCII 编码就是 8 位二进制编码,ASCII 编码是一种定长编码,即每个字符用相同数目
的二进制位编码。
为了缩短数据文件(报文)长度,可采用不定长编码。其基本思想是,给使用频度较高
的字符编以较短的编码。这是数据压缩技术的最基本的思想。如何给数据文件中的字符编以
不定长编码,使各种数据文件平均最短呢?这也是个与哈夫曼树相关的最优问题。通过实例
介绍概念。
(1)前缀码:如果在一个编码系统中,任一个编码都不是其他任何编码的前缀(最左
子串),则称该编码系统中的编码是前缀码。例如,一组编码 01,001,010,100,110 就不
是前缀码,因为 01 是 010 的前缀,若去掉 01 或 010 就是前缀码。例如,名字中的郑霞、郑
霞锦就不是前缀码。
若是前缀码,则在电文中,各字符对应的编码之间不需要分隔符。如果不是前缀码,则
若不使用分隔符,会产生二义性。
(2)哈夫曼编码:对一棵具有 n 个叶子的哈夫曼树,若对树中的每个左分支赋予 0,
右分支赋予 1(也可规定左 1 右 0),则从根到每个叶子的通路上,各分支的赋值分别构成一
个二进制串,该二进制串就称为哈夫曼编码。
下面给出哈夫曼编码的相关特性。
定理 6-1 哈夫曼编码是前缀码。
证明:哈夫曼编码是根到叶子路径上的边的编码的序列,也就是等价边序列,而由树的
特点可知,若路径 A 是另一条路经 B 的最左部分,则 B 经过了 A,因此,A 的终点不是叶子。
而哈夫曼编码都对应终点为叶子的路径,所以,任一哈夫曼码都不会与任意其他哈夫曼编码
的前部分完全重叠,因此哈夫曼编码是前缀码。
定理 6-2 哈夫曼编码是最优前缀码。
即对于 n 个字符,分别以它们的使用频度为叶子权构造哈夫曼树,则该树对应的哈夫曼编码能使各种报文(由这 n 种字符构成的文本)对应的二进制串的平均长度最短。
证明:由于哈夫曼编码对应叶权为各字符使用频度的哈夫曼树,因此,该树为带权长度最小的树,即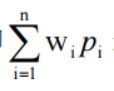
最小,其中 Wi 是第 i 个字符的使用频度,而 Pi 是第 i 个字符的编码长度,这正是度量报文的平均长度的式子。
由哈夫曼树的构造方法知,使用频度较高的字符对应的编码较短,这也直观地说明了本定理。
2.哈夫曼编码的作用
哈夫曼树被广泛的应用,最典型的就是在编码技术上的应用。利用哈夫曼树,可以得到平均长度最短的编码。
研究操作码的优化问题主要是为了缩短指令字的长度,减少程序的总长度以及增加指
令所能表示的操作信息和地址信息。要对操作码进行优化,就要知道每种操作指令在程序
中的使用频率。这一般是通过对大量已有的典型程序进行统计得到的。
这里以计算机操作码的优化问题为例来分析说明。
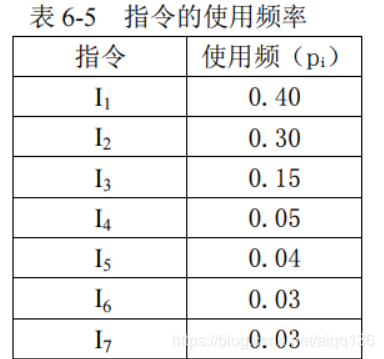
例 6-7 设有一台模型机,共有 7 种不同的指令,其使用频率如表 6-5 所示。
由于计算机内部只能识别 0、1 代码,所以若采用定长操作码,则需要 3 位(2^3=8)
一段程序中若有 n 条指令,每条指令编码占 3 位,那么程序的总位数为 3×n。为了充分地
利用编码信息和减少程序的总位数,我们可以采用变长编码。如果对每一条指令指定一条
编码,并使这些编码互不相同且最短,是否可以满足要求呢?可否采用如表 6-6 所示这样编
码呢?
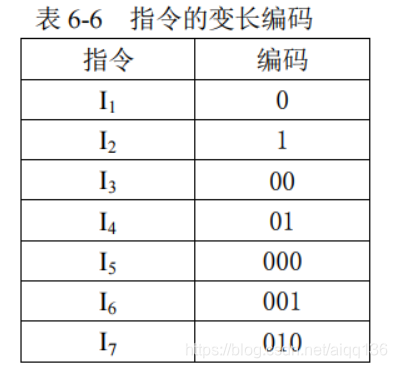
这样虽然可以使得程序的总位数达到最小,但机器却无法解码。
例如,对编码串 0010110该怎么识别呢?
第一个 0 可以识别为 I1,也可以和第二个 0 组成的串 00 一起被识别为 I3,还可以将前三位识别为 I6,这样一来,这个编码串就有多种译法。
因此,若要设计变长的编码,则这种编码必须满足这样一个条件:任意一个编码不能成为其他任意编码的前缀。把满足这个条件的编码叫做前缀编码。
利用哈夫曼算法,就可以设计出最优的前缀编码。首先,以每条指令的使用频率为权值构造哈夫曼树,据表 6-5 构造的哈夫曼树如图所示。
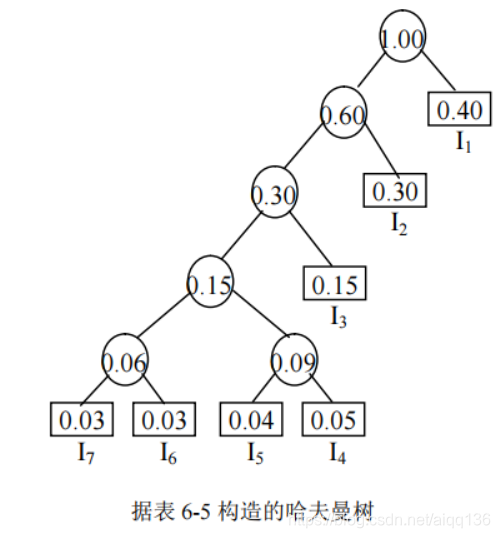
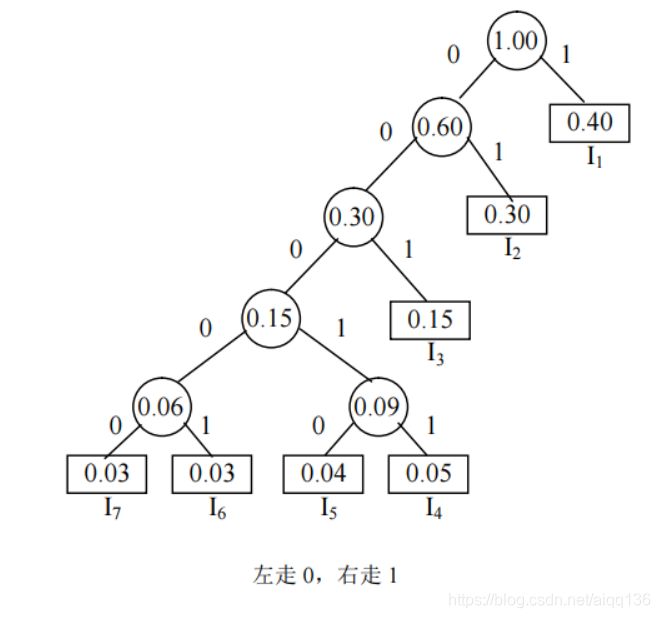
对于该哈夫曼树,规定向左的分支标记为 0,向右的分支标记为 1,如下图所示。这样,
从根结点开始,沿线到达各频度指令对应的叶结点,每个叶结点对应的编码长度不等,但最
长不超过 n,所经过的分支代码序列,就构成了相应频度指令的哈夫曼编码,如表 6-7 所示。
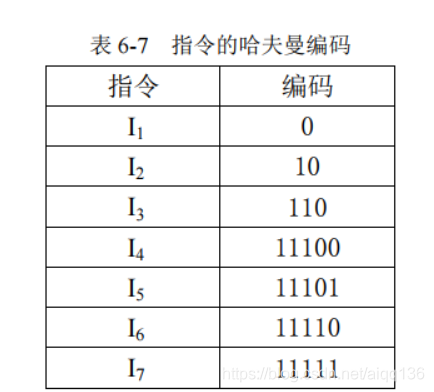
可以验证,该编码是前缀编码。若一段程序有 1000 条指令,其指令使用频率如表 6-5,
即I1 有 400 条,I2 有 300 条,I3 有 150 条,I4 有 50 条,I5 有 40 条,I6 有 30 条,I7 有 30 条。
对于定长编码,该段程序的总位数为 3×1000=3000。而采用哈夫曼编码方案(表 6-5),
该段程序的总位数为 1×400+2×300+3×150+5×(50+40+30+30)=2200。
可见,哈夫曼编码中虽然大部分编码的长度大于定长编码的长度 3,但使用频率高的编码长度短,使得程序总位数变小了。可以算出用该哈夫曼编码的平均码长为:
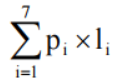 =0.40×1+0.30×2+0.15×3+0.05×5+0.04×5+0.03×5+0.03×5=2.20
=0.40×1+0.30×2+0.15×3+0.05×5+0.04×5+0.03×5+0.03×5=2.20
3.哈夫曼编码的算法实现
typedef char * HuffmanCode[N+1]; /* 存储哈夫曼编码串的头指针数组 */
由于每个哈夫曼编码是变长编码,因此使用指针数组存放每个编码串的头指针。
【算法描述】 求哈夫曼树的哈夫曼编码的算法
void CrtHuffmanCode(HuffmanTree *ht, HuffmanCode *hc, int n)
/*从叶子结点到根,逆向求每个叶子结点对应的哈夫曼编码*/
{
char *cd;
int i;
unsigned int c;
int start;
int p;
hc=(HuffmanCode *)malloc((n+1)*sizeof(char *)); /*分配n个编码的头指针*/
cd=(char * )malloc(n * sizeof(char )); /*分配求当前编码的工作空间*/
cd[n-1]='\0'; /*从右向左逐位存放编码,首先存放编码结束符*/
for(i=1;i<=n;i++) /*求n个叶子结点对应的哈夫曼编码*/
{
start=n-1; /*初始化编码起始指针*/
for(c=i,p=(*ht)[i].parent; p!=0; c=p,p=(*ht)[p].parent) /*从叶子到根结点求编码*/
if( (*ht)[p].LChild == c)
cd[--start]='0'; /*左分支标0*/
else
cd[--start]='1'; /*右分支标1*/
hc[i]=(char *)malloc((n-start)*sizeof(char)); /*为第i个编码分配空间*/
strcpy(hc[i],&cd[start]);
}
free(cd);
for(i=1;i<=n;i++)
printf("%d编码为%s\n",(*ht)[i].weight,hc[i]);
}
作业
在哈夫曼编码中,当两个字符出现的频率相等时,则两个字符的哈夫曼编码也相同。( )
-
A.✓
-
B.×
总结与提高——内容简介
【主要知识点】
l 树与二叉树定义:
l 存储结构:
l 掌握二叉树遍历算法是本章的重点。其一,通过遍历得到了二叉树中结点访问的线性序列,实现了非线性结构的线性化,遍历运算是基础。其二,二叉树遍历运算中的递归实现是程序设计中重要技术,理解递归含义、使用递归控制条件都非常重要。
l 明确递归到非递归的转换
l 注意理解遍历应用,一要注意访问操作的可以包罗对访问结点的所有操作;二要注意分析应用问题对遍历顺序的要求。
l 掌握哈夫曼树的概念,应用哈夫曼树构造哈夫曼编码,为解决数据压缩问题提供方法。
【典型题例】
l 二叉树相似性判断
l 求从二叉树根结点到r结点之间的路径
l 层次遍历二叉树
总结与提高——教学讲义
一、主要知识点
(1)理解定义:本章介绍的一般树与二叉树均为树结构,树结构是最重要的非线性结构。
注意树结构与线性结构的差别:在线性结构中前驱结点是惟一的,而树结构中结点的前驱只
有一个(除根结点无前驱外),后继个数可有 m(m≥0)个,其中二叉树是后继个数最多为 2
的树。
(2)存储结构:
①二叉树采用顺序存储与二叉链表存储,其孩子个数最大为 2,故采用二叉树的二叉链
表表示法实现存储。
②对一般树,由于结点的后继个数变化范围较大,常采用树的二叉链表表示法实现存储
(即孩子兄弟法);
③树与二叉树之间的转换方法,最简单的是通过树与二叉树各自的二叉链表存储方法实
现转换,只不过是解释不同而已。
(3)掌握二叉树遍历算法是本章的重点,原因有二:其一,通过遍历得到了二叉树中结点
访问的线性序列,实现了非线性结构的线性化,遍历运算是基础。其二,二叉树遍历运算中
的递归实现是程序设计中重要技术,理解递归含义、使用递归控制条件都非常重要。
(4)明确递归到非递归的转换需求原因:因为递归执行时需要系统提供隐式栈实现递归,
效率较低;适应无应用递归语句的语言设施环境条件;由于递归算法是一次执行完,这在处
理有些问题时不适合。
(5).注意理解遍历应用,一要注意访问操作的可以包罗对访问结点的所有操作,并不
只有打印等操作(如线索化题例);二要注意分析应用问题对遍历顺序的要求(如树状打印
题例)。
(6)掌握哈夫曼树的概念,应用哈夫曼树构造哈夫曼编码,为解决数据压缩问题提供方法。
(7)理解并查集。掌握并查集中的查找、合并等运算。并能运用并查集进行等价类划分。
二、典型题例
例 1 二叉树相似性判断
试设计算法,判断两棵二叉树是否相似。所谓二叉树 t1 与 t2 相似,指的是 t1 和 t2 都
是空的二叉树;或者 t1 的左子树与 t2 的左子树相似,同时 t1 的右子树与 t2 的右子树相似。
【问题分析】依题意,本题的递归函数如下:
f(t1, t2)=TRUE 若 t1=t2=NULL
f(t1, t2)=FALSE 若 t1 与 t2 之一为 NULL,另一个不为 NULL
f(t1, t2)= f(t1->left, t2->left) && f(t1->right, t2->right) 若 t1 与 t2 均不为 NULL
【算法描述】 判断二叉树 b1 和 b2 是否相似算法
int like(BiTree b1, BiTree b2)
/*判断二叉树 b1 和 b2 是否相似,若相似,返回 1,否则返回 0*/
{
int like1, like2;
if (b1 == NULL && b2 == NULL)
return(1); /*b1 和 b2 均为空树,相似,返回 1*/
else if (b1 == NULL || b2 == NULL)
return(0); /*b1 和 b2 其中之一为空树,不相似,返回 0*/
else
{
like1 = like(t1->left, t2->left);/*判断 b1 和 b2 的左子树是否相似*/
like2 = like(t1->right, t2->right);/*判断 b1 和 b2 的右子树是否相似*/
return (like1 && like2);
}
}
例 2 求从二叉树根结点到 r 结点之间的路径
假设二叉树采用二叉链表方式存储,root 指向根结点,r 所指结点为任一给定的结点。
编写算法,求出从根结点到结点 r 之间的路径。
【问题分析】按题意要求,本题要求出从根结点到结点 r 之间的路径。①由于后序遍历访问
到 r 所指结点时,此时栈中所有结点均为 r 所指结点的祖先,由这些祖先便构成了一条从根
结点到 r 所指结点之间的路径,故应采用后序遍历方法。 ②由于递归方式的栈区是由系统
隐式控制,为了能在找到结点 r 时控制输出,需要将递归方式中系统隐含的栈变成为用户自
己控制的栈,故应使用非递归的后序遍历算法。此算法与后序遍历非递归算法 6.12 类似,
不同之处在下述算法中用方框标明。
【算法描述】 求出从二叉树中根结点到 r 所指结点之间的路径并输出算法
void path(BiTree root, BiTNode* r)
/*求出从二叉树根结点到 r 结点之间的路径并输出*/
{
BiTNode* p, * q;
int i, top = 0;
BiTree s[Stack_Size];
q = NULL; /* 用 q 保存刚遍历过的结点,初始为空*/
p = root;
while (p != NULL || top != 0)
{
while (p != NULL)
{
top++;
if (top >= Stack_Size)
OverFlow(); /*栈溢出处理*/
s[top] = p;
p = p->LChild;
} /* 遍历左子树 */
if (top > 0)
{
p = s[top]; /* 根结点 */
if (p->RChild == NULL || p->RChild == q)
{
if (p == r) /*找到 r 所指结点,则显示从根结点到 r 所指结点之间的路径*/
{
for (i = 1; i <= top; i++)
printf("% d", s[i]->data);
return;
}
else
{
q = p;
top--;
p = NULL;
/* 用 q 保存刚遍历过的结点 */
/* 跳过前面左遍历,继续退栈 */
}
}
else
p = p->RChild;/* 遍历右子树 */
}
}
}
例 3 层次遍历二叉树
层次遍历是指从二叉树的第一层(根结点)开始,从上至下逐层遍历,在同一层中,
则按照从左到右的顺序对结点逐个访问。以此类推,直到二叉树中所有结点均被访问且仅
访问一次。对于图 6.11 所示的二叉树,按照层次遍历得到的结点序列为:A B C D E F G H
【问题分析】实现层次遍历,需要设置一个队列 Q,暂存某层已访问过得结点,同时也保存
了该层结点访问的先后次序。按照对该层结点访问的先后次序实现对其下层孩子结点的按
次序访问。
【算法思想】
(1)初始化空队列 Q;
(2)若二叉树 bt 为空树,则直接返回;
(3)将二叉树的根结点指针 bt 放入队列 Q;
(4)若队列非空,则重复如下操作:
a. 队头元素出队并访问该元素;
b. 若该结点的左孩子非空,则将该结点的左孩子结点指针入队;
c. 若该结点的右孩子非空,则将该结点的右孩子结点指针入队;
【算法描述】 层次遍历二叉树算法
int LayerOrder(BiTree bt)
/*层次遍历二叉树 bt*/
{
SeqQueue* Q;
BiTree p;
InitQueue(Q); /*初始化空队列 Q*/
if (bt == NULL) return ERROR; /* 若二叉树 bt 为空树,则结束遍历*/
EnterQueue(Q, bt); /* 若二叉树 bt 非空,则根结点 bt 入队,开始层次遍历*/
while (!IsEmpty(Q)) /*若队列非空,则遍历为结束,继续进行*/
{
DeleteQueue(Q, &p); /*队头元素出队并访问 */
visit(p->data);
if (p->LChild) EnterQueue(Q, p->LChild); /*若 p 的左孩子非空,则进队*/
if (p->RChild) EnterQueue(Q, p->RChild); /*若 p 的右孩子非空,则进队*/
} /*while*/
return OK;
} /* LayerOrder */
智能推荐
Layui的日期时间控件错误问题解决_laydate日期按钮样式错误-程序员宅基地
文章浏览阅读3.8k次。一、未调用Layui相关组件方法一:在Layui模块中使用。下载Layui后,引入本地的layui.css和layui.js即可,调用的时候通过layui.use('laydate', callback)加载模块后,再调用方法 方法二:作为独立组件使用。去layDate独立版本官网下载组件包,引入 laydate.js 即可,直接调用方法就可以了。二、没有正确绑定元素<!..._laydate日期按钮样式错误
Word和WPS插入代码(高亮显示)-程序员宅基地
文章浏览阅读1.1k次。2019独角兽企业重金招聘Python工程师标准>>> ..._wps代码格式化插件
OpenCV错误(-215:Assertion failed) npoints > 0 in function_error: (-215:assertion failed) npoints > 0 in func-程序员宅基地
文章浏览阅读3k次,点赞7次,收藏3次。在使用OpenCV绘图函数时容易遇到(-215:Assertion failed) npoints > 0 错误。代码如下:import numpyimport cv2mask = numpy.zeros([4000, 4000, 3])cnt=[[ 1626. 360.] [ 1776. 3108.] [ 126. 3048.] [ 330. 486.]]cv2.drawContours(mask, [cnt], 0, (0, 255, 0), -1)出错._error: (-215:assertion failed) npoints > 0 in function 'cv::drawcontours
【OpenGL手册17】数据输入工具Assimp_opengl assimp-程序员宅基地
文章浏览阅读1k次,点赞8次,收藏20次。我们一直都在用一个破木箱渲染,但时间久了甚至是我们最好的朋友也会感到无聊。在日常的图形程序中,通常都会使用非常复杂且好玩的模型,它们比静态的箱子要好看多了。然而,和箱子对象不同,我们不太能够对像是房子、汽车或者人形角色这样的复杂形状手工定义所有的顶点、法线和纹理坐标。我们想要的是将这些模型(Model)导入(Import)到程序当中。模型通常都由3D艺术家在Blender、3DS Max或者Maya这样的工具中精心制作。_opengl assimp
【CodeForces - 988C 】Equal Sums (思维,STLmap,STLset,tricks)_小a有 n 个整数数列 a1,a2,…an ,每个数列的长度为li。 请你找出两个编号不同的数列,并-程序员宅基地
文章浏览阅读294次。题干:You are given kk sequences of integers. The length of the ii-th sequence equals to nini.You have to choose exactly two sequences ii and jj (i≠ji≠j) such that you can remove exactly one element ..._小a有 n 个整数数列 a1,a2,…an ,每个数列的长度为li。 请你找出两个编号不同的数列,并从这两个数列中各恰好删除一个数,使得这两个数列的和相等。
API与EDI的区别?_api和edi指的什么-程序员宅基地
文章浏览阅读3.2k次。从下图可以看出,有时EDI和API都是基于Http通过互联网进行安全可靠的数据交换。从上图看出,API缺少EDI特定的传输协议,如OFTP,AS2。另外也没有任何定义的消息类型,例如EDIFACT,X12。EDI消息类型和特定的传输协议是EDI的重要组成部分,而且EDI消息类型几乎覆盖了供应链领域所有业务,使得其对于增长的对接需求更加友好。而API呢?通俗的说就是:API实际上就是..._api和edi指的什么
随便推点
Python之问题详解(一):AttributeError: ‘NoneType‘ object has no attribute ‘shape‘_attributeerror: 'nonetype' object has no attribute-程序员宅基地
文章浏览阅读3w次,点赞15次,收藏22次。解决的方法:图片的名字不能为中文,在运行代码相同文件夹下......_attributeerror: 'nonetype' object has no attribute 'shape
c++ windows wmi修改网卡ip+dns_c++修改网卡地址-程序员宅基地
文章浏览阅读3.6k次,点赞2次,收藏12次。c++ windows wmi修改网卡ip+dns注意事项:项目必须以管理员权限运行参考main.cpp使用方法网卡的key可以从注册表获取, 路径: 计算机\HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Interfaces\项目下载地址: https://github.com/w123l..._c++修改网卡地址
input-42-data.zip数据集(Natural image stitching with the global similarity prior论文数据)-程序员宅基地
文章浏览阅读729次。GSP算法github:https://github.com/nothinglo/NISwGSPinput-42- data.zip数据集下载:链接:https://pan.baidu.com/s/1YbDBADw9WNGnV4cvWyJhcg 提取码:wq0v_input-42-data
叶梓老师 人工智能兼职讲师之深度学习《计算机视觉的深度学习实践》_计算机视觉的深度学习课件 叶梓-程序员宅基地
文章浏览阅读1.9k次。人工智能的时代,深度学习这个热点是每个程序员必须了解的内容。近年来深度学习研究得到了充分的发展,但系统的课程少之又少,能够理论联系实际,适合初学程序员学习的课程更是凤毛麟角。叶梓老师,拥有多年的企业实践经验,结合实践在小象学院平台直播《计算机视觉的深度学习实践》14堂课细说深度学习之计算机视觉第一讲 课程概述第二讲 图像预处理第三讲 图像特征提取第四讲 未有深度学习之..._计算机视觉的深度学习课件 叶梓
Android - WebView 全面干货指南_android webview-程序员宅基地
文章浏览阅读643次。前言总结 Android WebView 常用的相关知识点,令包含以下干货内容分析:Js注入漏洞、WebView 遇到的坑、JsBridge 原理以及框架使用(JsBridge,DSBridge-Android)、缓存机制应用、性能优化、腾讯开源框架 VasSonic (之后会进行代码分析)。目录一、简介这部分主要介绍下 WebView,WebView 是一个用来显示 Web ..._android webview
使用eclipse遇到问题:the-package-collides-with-a-type-程序员宅基地
文章浏览阅读743次。相似问题:http://stackoverflow.com/questions/12236909/the-package-collides-with-a-type_the package com.csii.pe.action.twophase collides with a type