hadoop+zookeeper高可用,yarn高可用,Hbase高可用集群部署_hadoop 的yarn的高可用-程序员宅基地
本篇博客基于上篇博客hadoop的配置:https://blog.csdn.net/aaaaaab_/article/details/82080751
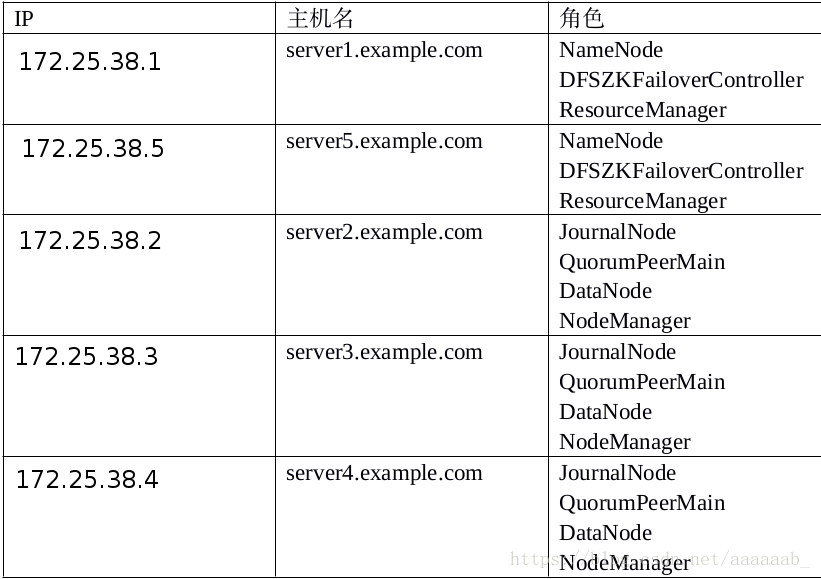
实验环境:
搭建zookeeper集群:
[root@server1 ~]# /etc/init.d/nfs start 开启服务
[root@server1 ~]# showmount -e
Export list for server1:
/home/hadoop *
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$
[hadoop@server1 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ rm -fr /tmp/*
[hadoop@server1 ~]$ ls
hadoop java zookeeper-3.4.9.tar.gz
hadoop-2.7.3 jdk1.7.0_79
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ tar zxf zookeeper-3.4.9.tar.gz 解压zookeeper包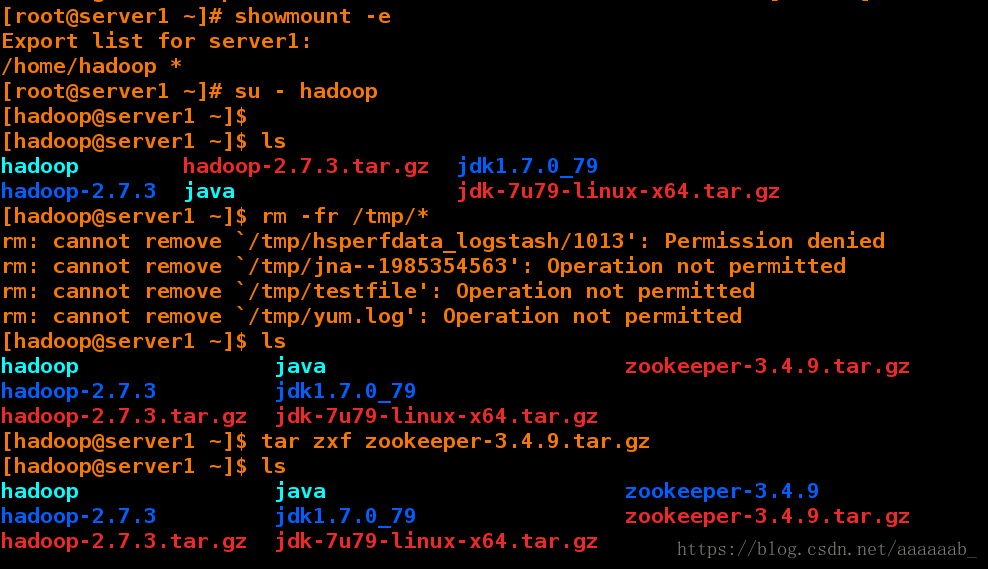
配置server5作为高可用节点:
[root@server5 ~]# yum install nfs-utils -y 安装服务
[root@server5 ~]# /etc/init.d/rpcbind start 开启服务 [ OK ]
[root@server5 ~]# /etc/init.d/nfs start 开启nfs服务
[root@server5 ~]# useradd -u 800 hadoop
[root@server5 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/ 挂载
[root@server5 ~]# df 查看挂载
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 929548 17232804 6% /
tmpfs 380140 0 380140 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
172.25.38.1:/home/hadoop/ 19134336 3289728 14872704 19% /home/hadoop
[root@server5 ~]# su - hadoop
[hadoop@server5 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79 主机均已经同步
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
[hadoop@server5 ~]$ rm -fr /tmp/*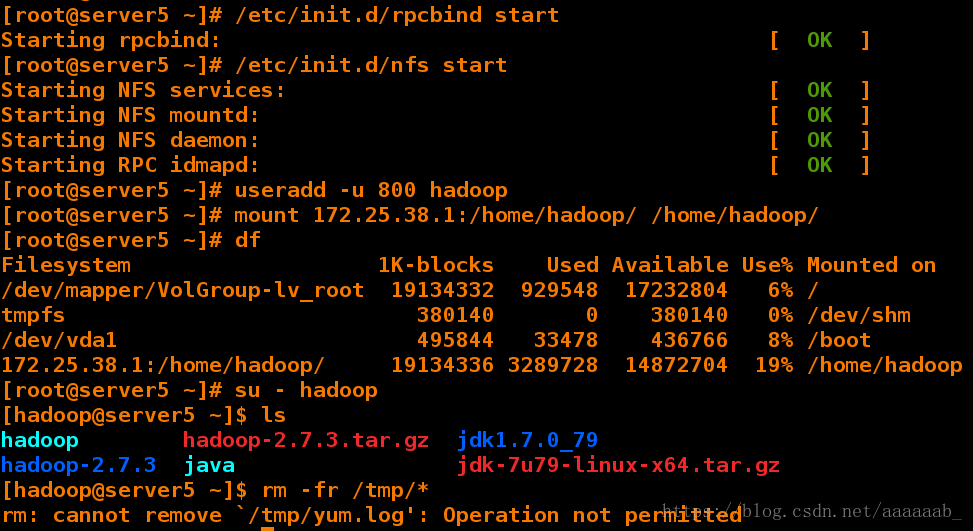
配置从节点:
[root@server2 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/ 挂载
[root@server2 ~]# df 查看挂载
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1860136 16302216 11% /
tmpfs 251120 0 251120 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
172.25.38.1:/home/hadoop/ 19134336 3289728 14872704 19% /home/hadoop
[root@server2 ~]# rm -fr /tmp/*
[root@server2 ~]# su - hadoop
[hadoop@server2 ~]$ ls
hadoop java zookeeper-3.4.9
hadoop-2.7.3 jdk1.7.0_79 zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server2 ~]$ cd zookeeper-3.4.9
[hadoop@server2 zookeeper-3.4.9]$ ls
bin dist-maven LICENSE.txt src
build.xml docs NOTICE.txt zookeeper-3.4.9.jar
CHANGES.txt ivysettings.xml README_packaging.txt zookeeper-3.4.9.jar.asc
conf ivy.xml README.txt zookeeper-3.4.9.jar.md5
contrib lib recipes zookeeper-3.4.9.jar.sha1
[hadoop@server2 zookeeper-3.4.9]$ cd conf/
[hadoop@server2 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg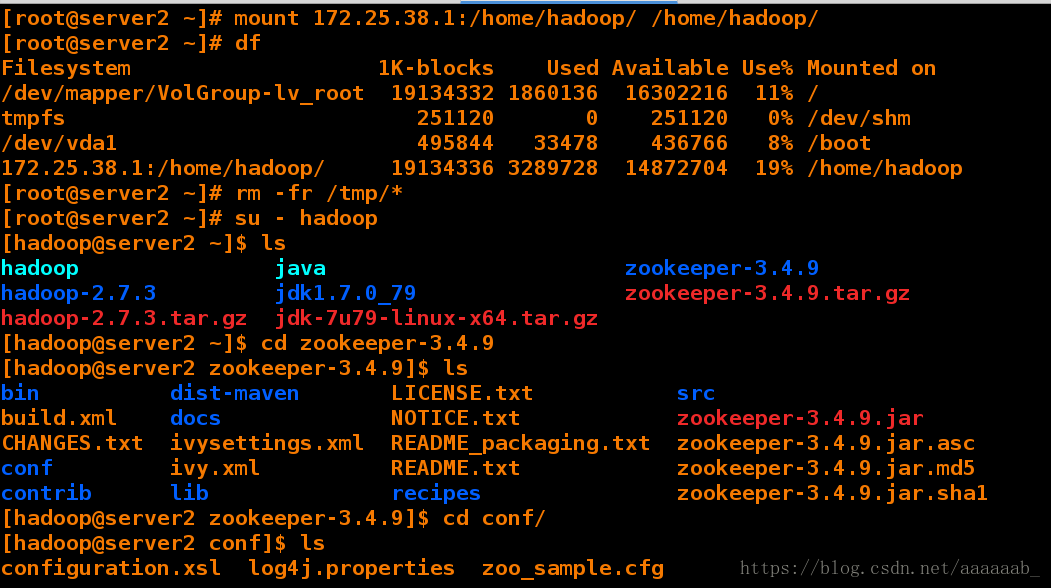
添加从节点信息:
[hadoop@server2 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@server2 conf]$ vim zoo.cfg
[hadoop@server2 conf]$ cat zoo.cfg | tail -n 3
server.1=172.25.38.2:2888:3888
server.2=172.25.38.3:2888:3888
server.3=172.25.38.4:2888:3888
[hadoop@server2 conf]$ mkdir /tmp/zookeeper
[hadoop@server2 conf]$ cd /tmp/zookeeper/
[hadoop@server2 zookeeper]$ ls
[hadoop@server2 zookeeper]$ echo 1 > myid
[hadoop@server2 zookeeper]$ ls
myid
[hadoop@server2 zookeeper]$ cd
[hadoop@server2 ~]$ cd zookeeper-3.4.9/conf/
[hadoop@server2 conf]$ ls
configuration.xsl log4j.properties zoo.cfg zoo_sample.cfg
[hadoop@server2 conf]$ cd ..
[hadoop@server2 zookeeper-3.4.9]$ cd bin/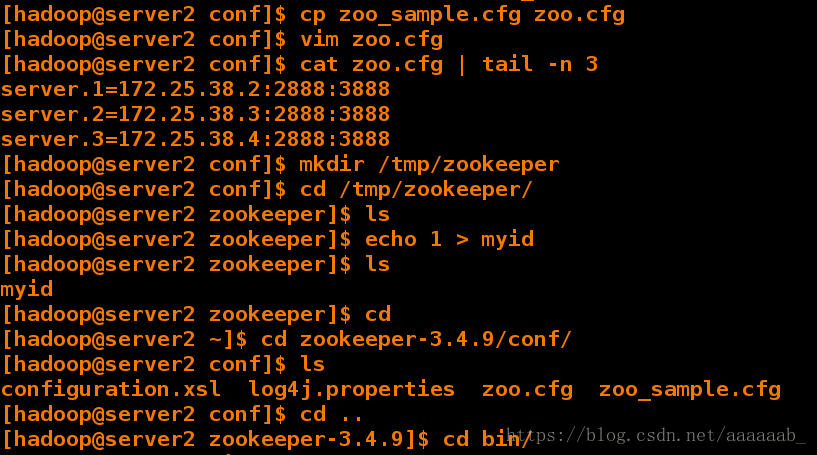
各节点配置文件相同,并且需要在/tmp/zookeeper 目录中创建 myid 文件,写入一个唯一的数字,取值范围在 1-255。
[hadoop@server2 zookeeper-3.4.9]$ cd bin/
[hadoop@server2 bin]$ ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
[hadoop@server2 bin]$ ./zkServer.sh start 开启服务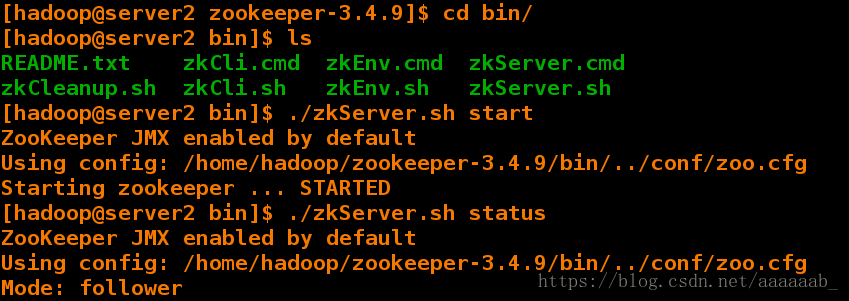
依次按照同样的方法配置其他节点:
[root@server3 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/
[root@server3 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1537052 16625300 9% /
tmpfs 251124 0 251124 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
172.25.38.1:/home/hadoop/ 19134336 3289728 14872704 19% /home/hadoop
[root@server3 ~]# rm -fr /tmp/*
[root@server3 ~]# su - hadoop
[hadoop@server3 ~]$ ls
hadoop java zookeeper-3.4.9
hadoop-2.7.3 jdk1.7.0_79 zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server3 ~]$ mkdir /tmp/zookeeper
[hadoop@server3 ~]$ cd /tmp/zookeeper/
[hadoop@server3 zookeeper]$ ls
[hadoop@server3 zookeeper]$ echo 2 > myid
[hadoop@server3 zookeeper]$ cd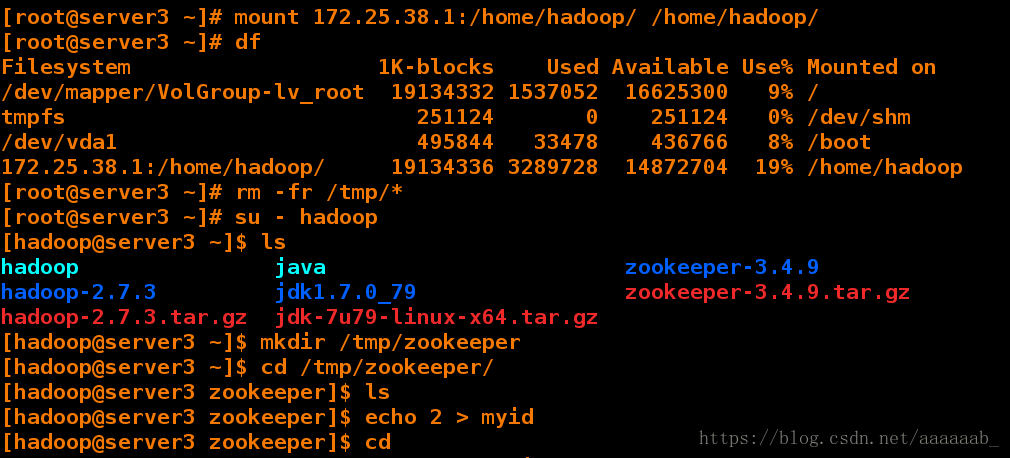
[hadoop@server3 ~]$ cd zookeeper-3.4.9/bin/
[hadoop@server3 bin]$ ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zookeeper.out
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
[hadoop@server3 bin]$ ./zkServer.sh start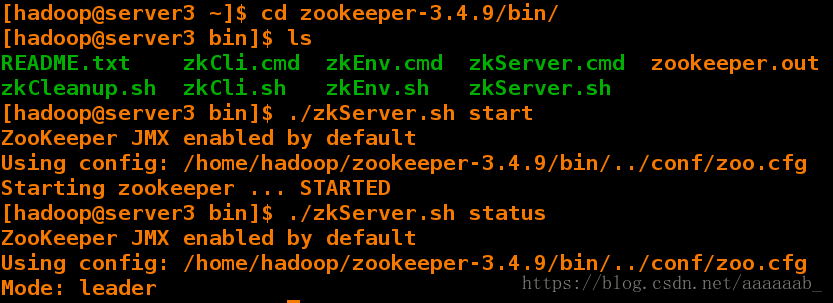
[root@server4 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/
[root@server4 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1350656 16811696 8% /
tmpfs 251124 0 251124 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
172.25.38.1:/home/hadoop/ 19134336 3289728 14872704 19% /home/hadoop
[root@server4 ~]# rm -fr /tmp/*
[root@server4 ~]# su - hadoop
[hadoop@server4 ~]$ mkdir /tmp/zookeeper
[hadoop@server4 ~]$ cd /tmp/zookeeper/
[hadoop@server4 zookeeper]$ ls
[hadoop@server4 zookeeper]$ echo 3 >myid
[hadoop@server4 zookeeper]$ ls
myid
[hadoop@server4 zookeeper]$ cd
[hadoop@server4 ~]$ cd zookeeper-3.4.9/bin/
[hadoop@server4 bin]$ ./zkServer.sh start
ZooKeeper JMX enabled by default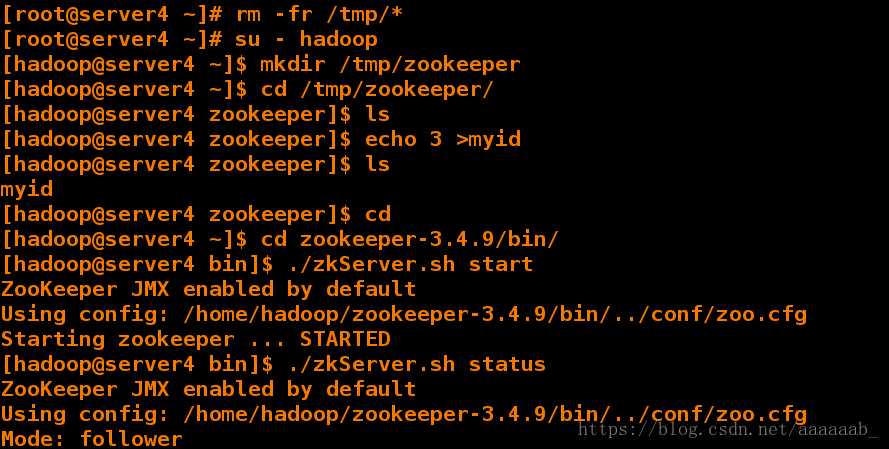
在server2进入命令行:
[hadoop@server2 bin]$ ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zookeeper.out
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
[hadoop@server2 bin]$ pwd
/home/hadoop/zookeeper-3.4.9/bin
[hadoop@server2 bin]$ ./zkCli.sh 连接zookeeper
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /zookeeper
[quota]
[zk: localhost:2181(CONNECTED) 2] ls /zookeeper/quota
[]
[zk: localhost:2181(CONNECTED) 3] get /zookeeper/quota
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0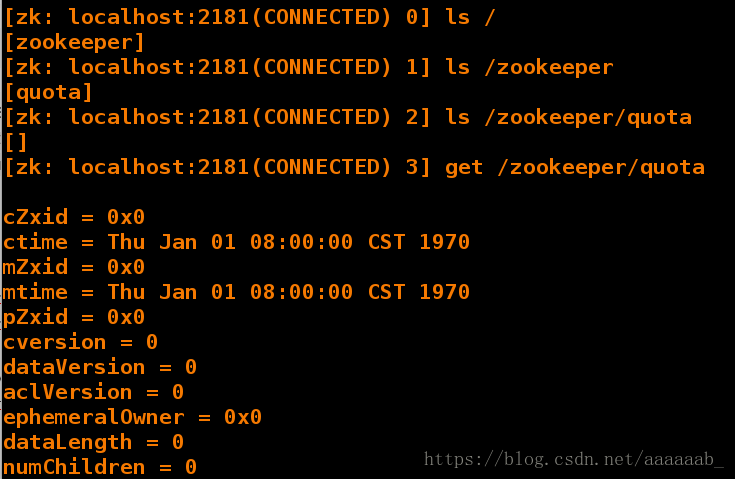
进行hadoop的配置详解:
[hadoop@server1 ~]$ ls
hadoop java zookeeper-3.4.9
hadoop-2.7.3 jdk1.7.0_79 zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ cd hadoop/etc/hadoop/
[hadoop@server1 hadoop]$ vim core-site.xml
<configuration>
指定 hdfs 的 namenode 为 masters (名称可自定义)
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
<property>
指定 zookeeper 集群主机地址
<name>ha.zookeeper.quorum</name>
<value>172.25.38.2:2181,172.25.38.3:2181,172.25.38.4:2181</value>
</property>
</configuration>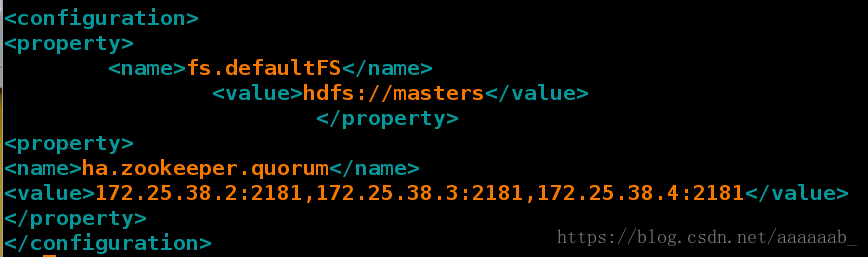
[hadoop@server1 hadoop]$ vim hdfs-site.xml
[hadoop@server1 hadoop]$ cat hdfs-site.xml | tail -n 74
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
指定 hdfs 的 nameservices 为 masters,和 core-site.xml 文件中的设置保持一致
<name>dfs.nameservices</name>
<value>masters</value>
</property>
masters 下面有两个 namenode 节点,分别是 h1 和 h2
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
指定 h1 节点的 rpc 通信地址
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.38.1:9000</value>
</property>
指定 h1 节点的 http 通信地址
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.38.1:50070</value>
</property>
指定 h2 节点的 rpc 通信地址
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.38.5:9000</value>
</property>
指定 h2 节点的 http 通信地址
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.38.5:50070</value>
</property>
指定 NameNode 元数据在 JournalNode 上的存放位置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.38.2:8485;172.25.38.3:8485;172.25.38.4:8485/masters</value>
</property>
指定 JournalNode 在本地磁盘存放数据的位置
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
开启 NameNode 失败自动切换
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
配置失败自动切换实现方式
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
配置隔离机制方法,每个机制占用一行
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
使用 sshfence 隔离机制时需要 ssh 免密码
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
配置 sshfence 隔离机制超时时间
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim slaves
[hadoop@server1 hadoop]$ cat slaves
172.25.38.2
172.25.38.3
172.25.38.4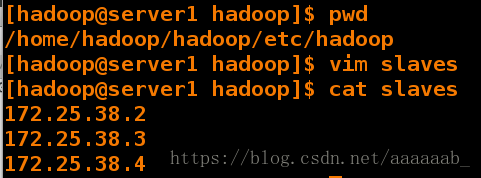
启动 hdfs 集群(按顺序启动)在三个 DN 上依次启动 zookeeper 集群
在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
[hadoop@server2 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server2 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server2 hadoop]$ sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-server2.out
[hadoop@server2 hadoop]$ jps
1459 JournalNode
1508 Jps
1274 QuorumPeerMain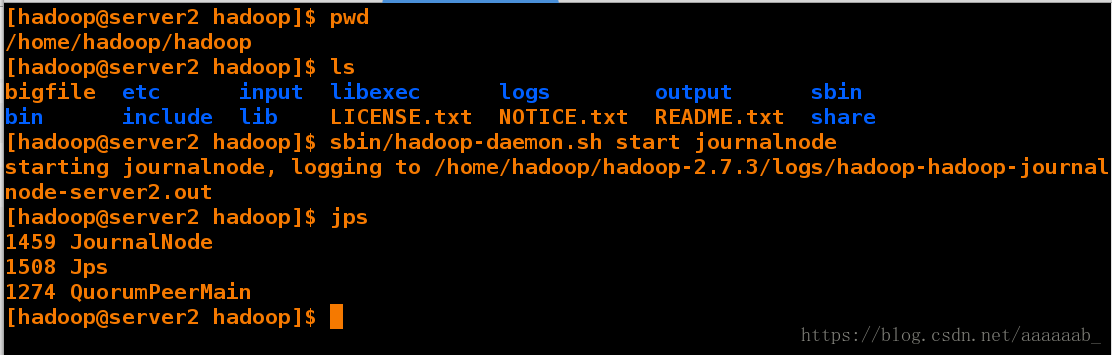
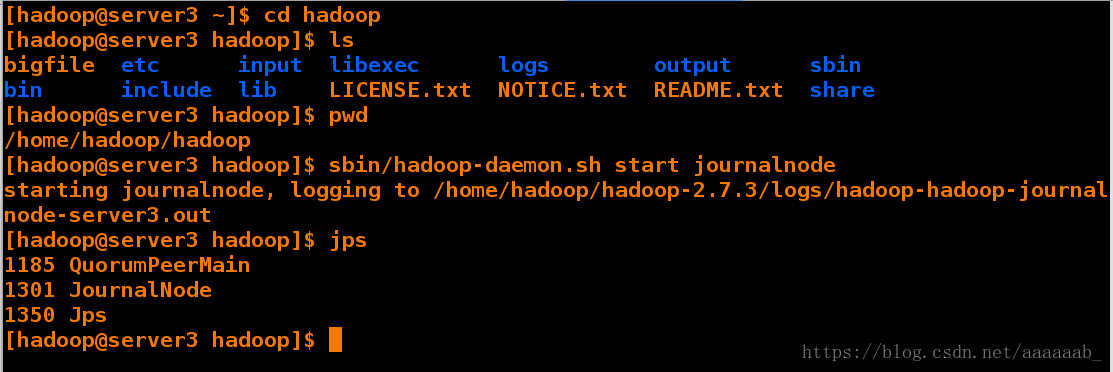
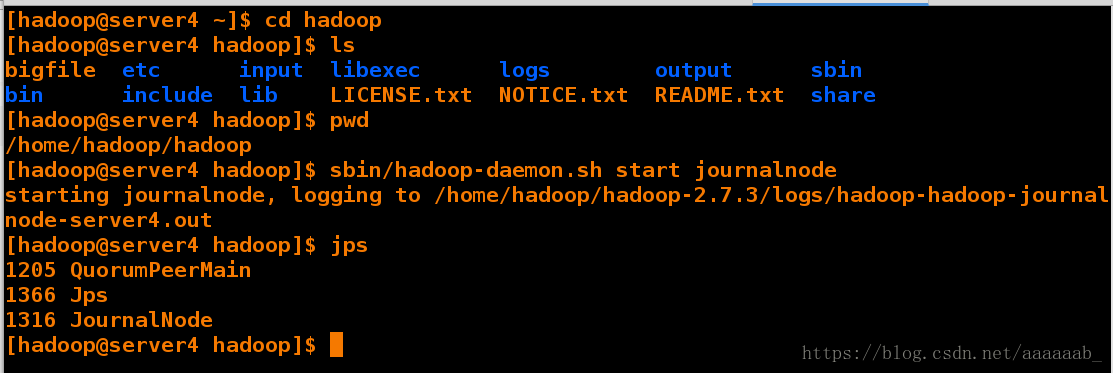
测试与server5的免密连接,传递配置文件搭建高可用:
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ ssh server5
[hadoop@server5 ~]$ exit
logout
Connection to server5 closed.
[hadoop@server1 hadoop]$ ssh 172.25.38.5
Last login: Tue Aug 28 10:40:53 2018 from server1
[hadoop@server5 ~]$ exit
logout
Connection to 172.25.38.5 closed.
[hadoop@server1 hadoop]$ scp -r /tmp/hadoop-hadoop/ 172.25.38.5:/tmp/
fsimage_0000000000000000000 100% 353 0.3KB/s 00:00
VERSION 100% 202 0.2KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00 
格式化 zookeeper (只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server1 hadoop]$ bin/hdfs zkfc -formatZK启动 hdfs 集群(只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ sbin/start-dfs.sh 免密没有做好的话需要卡住的时候输入yes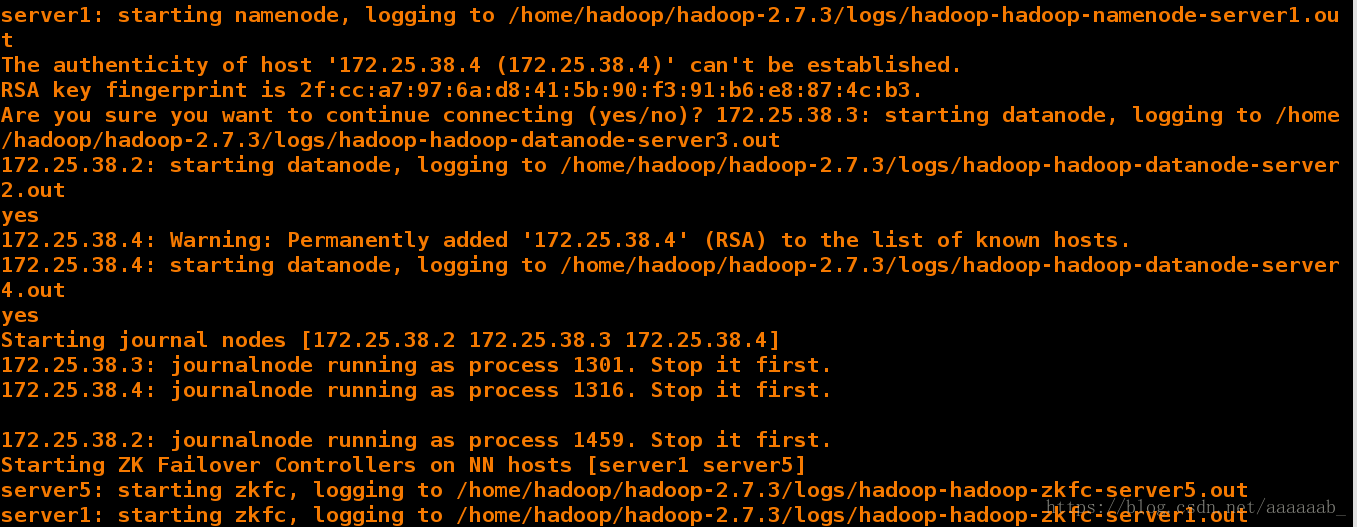
在server2进入命令行:
[hadoop@server2 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79 zookeeper-3.4.9
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz zookeeper-3.4.9.tar.gz
[hadoop@server2 ~]$ cd zookeeper-3.4.9
[hadoop@server2 zookeeper-3.4.9]$ ls
bin dist-maven LICENSE.txt src
build.xml docs NOTICE.txt zookeeper-3.4.9.jar
CHANGES.txt ivysettings.xml README_packaging.txt zookeeper-3.4.9.jar.asc
conf ivy.xml README.txt zookeeper-3.4.9.jar.md5
contrib lib recipes zookeeper-3.4.9.jar.sha1
[hadoop@server2 zookeeper-3.4.9]$ bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha
[masters]
[zk: localhost:2181(CONNECTED) 2] ls
[zk: localhost:2181(CONNECTED) 3] ls /hadoop-ha/masters
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: localhost:2181(CONNECTED) 4] ls /hadoop-ha/masters/Active
ActiveBreadCrumb ActiveStandbyElectorLock
[zk: localhost:2181(CONNECTED) 4] ls /hadoop-ha/masters/ActiveBreadCrumb
[]
[zk: localhost:2181(CONNECTED) 5] get /hadoop-ha/masters/ActiveBreadCrumb
mastersh2server5 �F(�> 当前master为server5
cZxid = 0x10000000a
ctime = Tue Aug 28 10:46:47 CST 2018
mZxid = 0x10000000a
mtime = Tue Aug 28 10:46:47 CST 2018
pZxid = 0x10000000a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 28
numChildren = 0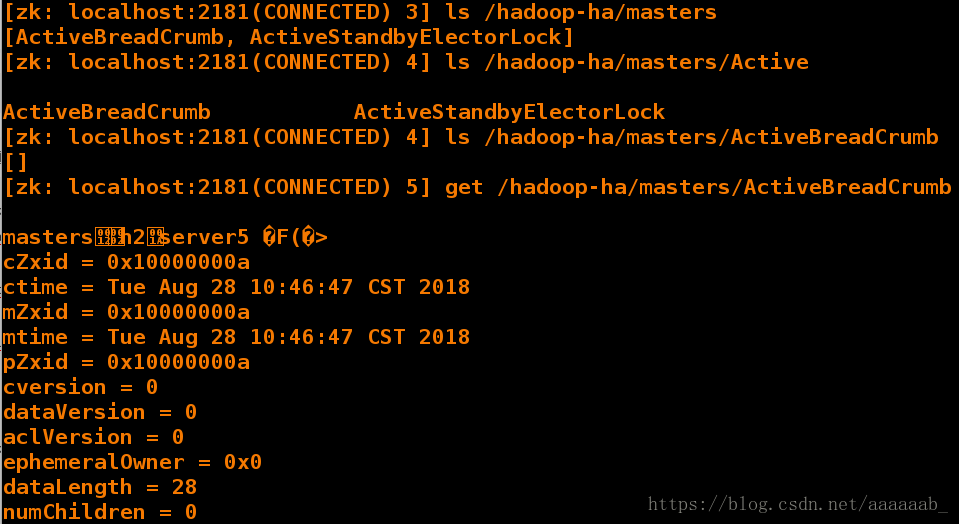
查看主从节点进程:
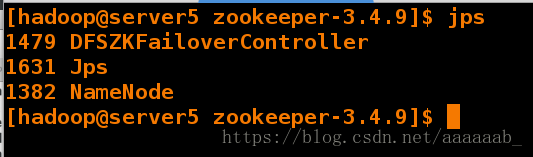
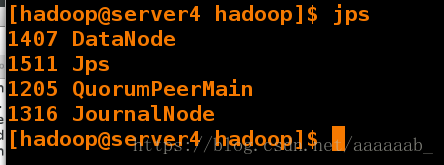
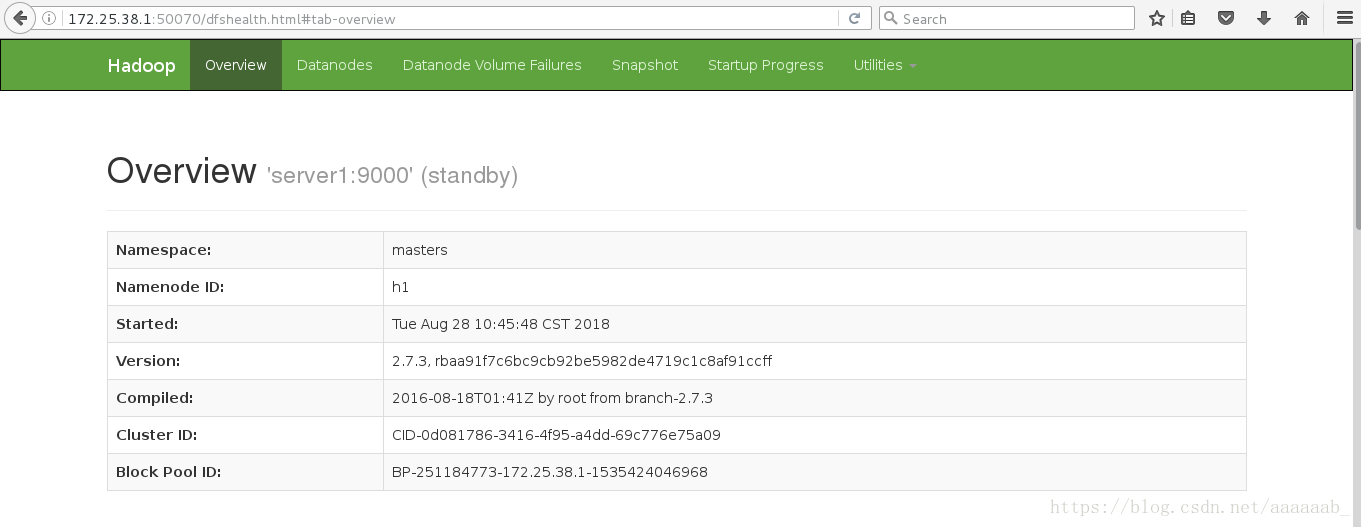
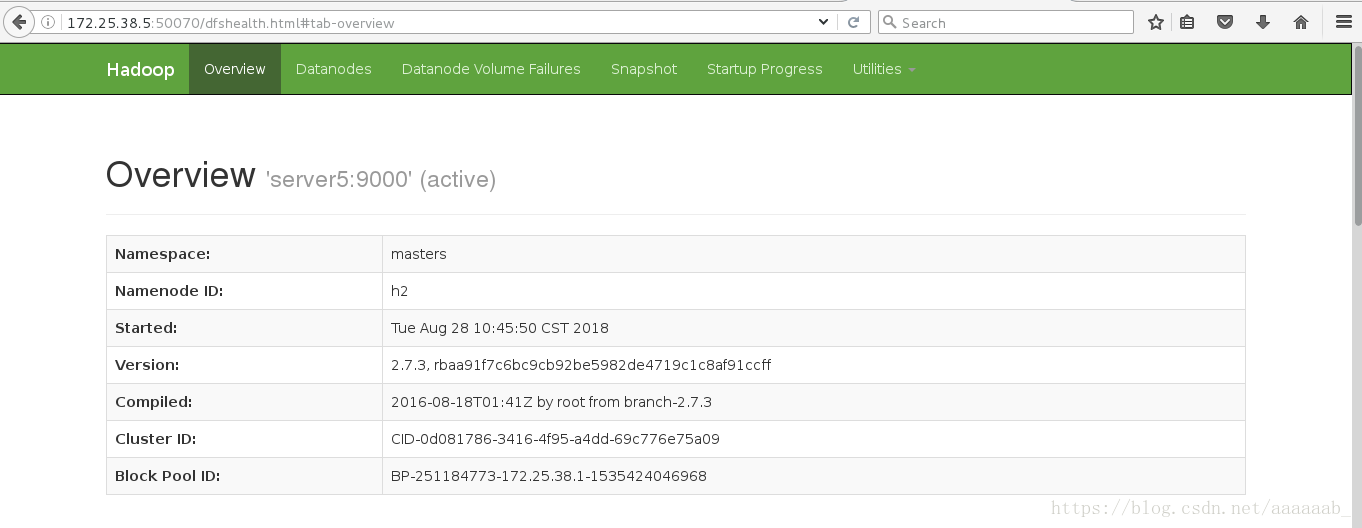
在网页查看server1和server5的状态,一个为active,一个为standby
测试故障自动切换:
[hadoop@server5 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79 zookeeper-3.4.9
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz zookeeper-3.4.9.tar.gz
[hadoop@server5 ~]$ cd hadoop
[hadoop@server5 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls
[hadoop@server5 hadoop]$ bin/hdfs dfs -put etc/hadoop/ input
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-08-28 10:59 input
[hadoop@server5 hadoop]$ jps
1479 DFSZKFailoverController
1382 NameNode
1945 Jps
[hadoop@server5 hadoop]$ kill -9 1382 直接结束进程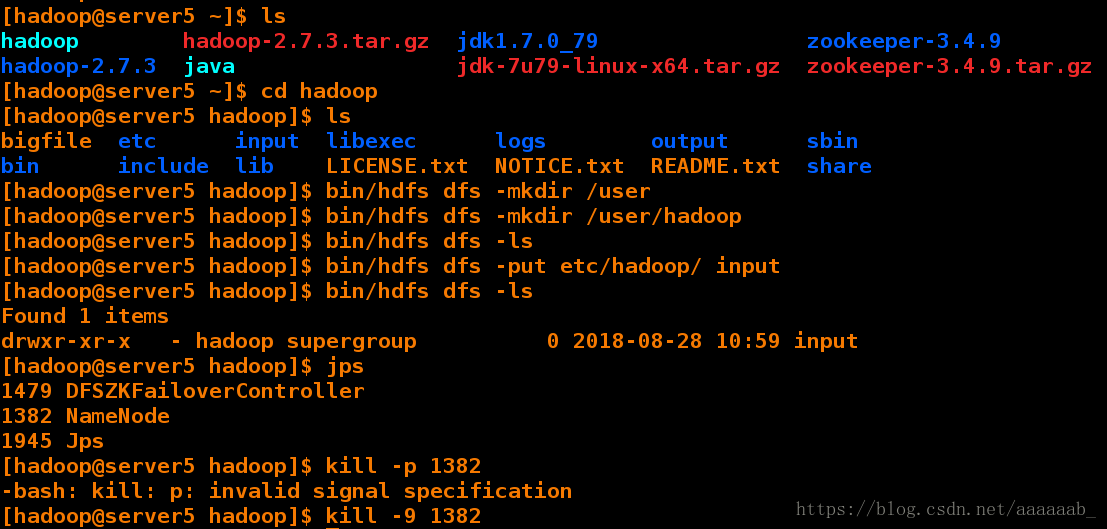
在server2的命令行查看:
[zk: localhost:2181(CONNECTED) 6] get /hadoop-ha/masters/ActiveBreadCrumb
mastersh1server1 �F(�> master已经变成了server1
cZxid = 0x10000000a
ctime = Tue Aug 28 10:46:47 CST 2018
mZxid = 0x10000000f
mtime = Tue Aug 28 11:00:22 CST 2018
pZxid = 0x10000000a
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 28
numChildren = 0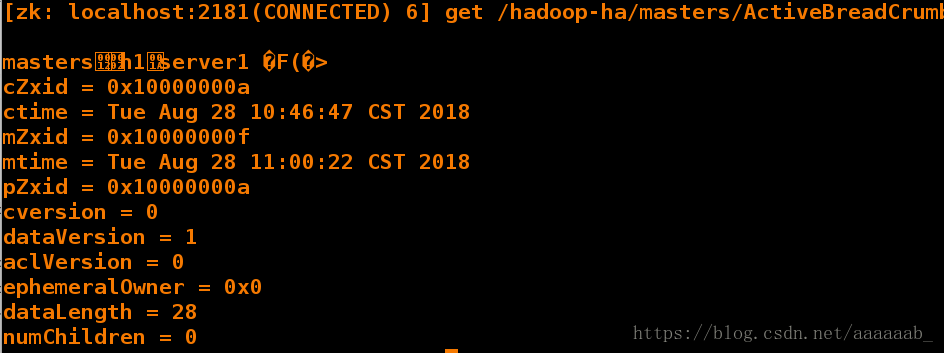
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ jps
1479 DFSZKFailoverController
1991 Jps
[hadoop@server5 hadoop]$ sbin/hadoop-daemon.sh start namenode 恢复节点
starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-server5.out
[hadoop@server5 hadoop]$ jps 查看进程已经恢复
1479 DFSZKFailoverController
2020 NameNode
2100 Jps
yarn 的高可用
[hadoop@server1 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[hadoop@server1 hadoop]$ vim mapred-site.xml
[hadoop@server1 hadoop]$ cat mapred-site.xml | tail -n 8
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>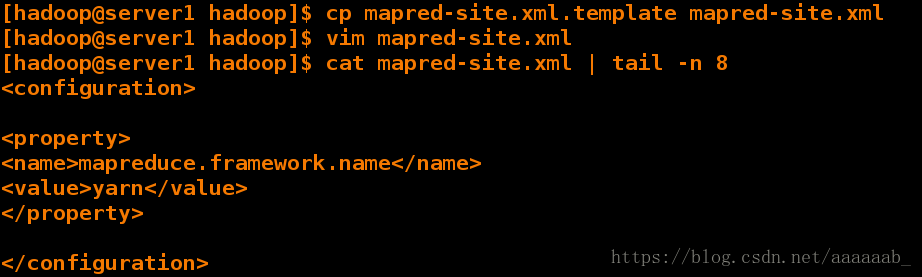
[hadoop@server1 hadoop]$ vim mapred-site.xml
[hadoop@server1 hadoop]$ cat mapred-site.xml | tail -n 8
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ vim yarn-site.xml
[hadoop@server1 hadoop]$ cat yarn-site.xml | tail -n 48
<configuration>
配置可以在 nodemanager 上运行 mapreduce 程序
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
激活 RM 高可用
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
指定 RM 的集群 id
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
定义 RM 的节点
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
指定 RM1 的地址
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.38.1</value>
</property>
指定 RM2 的地址
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.38.5</value>
</property>
激活 RM 自动恢复
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
配置 RM 状态信息存储方式,有 MemStore 和 ZKStore
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
配置为 zookeeper 存储时,指定 zookeeper 集群的地址
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.38.2:2181,172.25.38.3:2181,172.25.38.4:2181</value>
</property>
</configuration>启动 yarn 服务
[hadoop@server1 hadoop]$ cd ..
[hadoop@server1 etc]$ cd ..
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ sbin/start-yarn.sh
[hadoop@server1 hadoop]$ jps
1606 NameNode
2409 Jps
1900 DFSZKFailoverController
2335 ResourceManager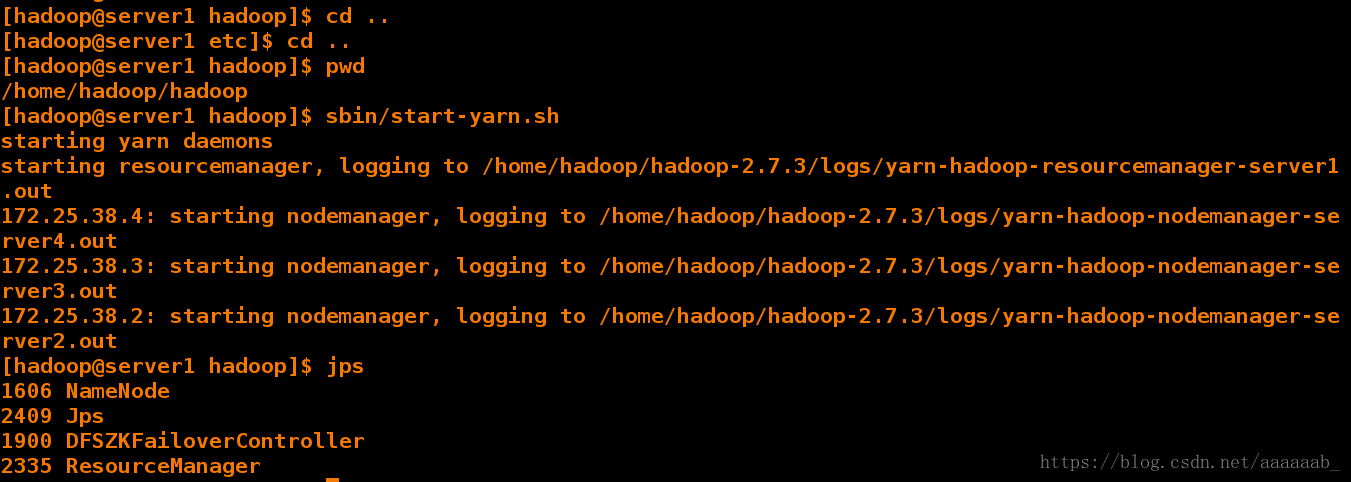
[hadoop@server4 hadoop]$ jps
1407 DataNode
1645 NodeManager
1205 QuorumPeerMain
1316 JournalNode
1759 Jps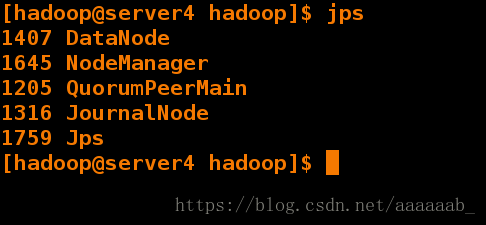
server5需要手动启动:
[hadoop@server5 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79 zookeeper-3.4.9
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz zookeeper-3.4.9.tar.gz
[hadoop@server5 ~]$ cd hadoop
[hadoop@server5 hadoop]$ sbin/yarn-daemon.sh start
[hadoop@server5 hadoop]$ jps
1479 DFSZKFailoverController
2762 Jps
2020 NameNode
2711 ResourceManager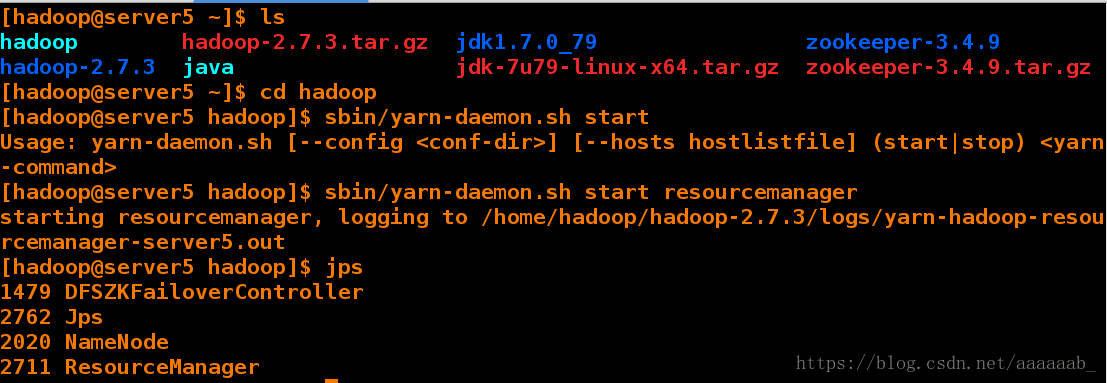
重点内容在网页查看server1状态:
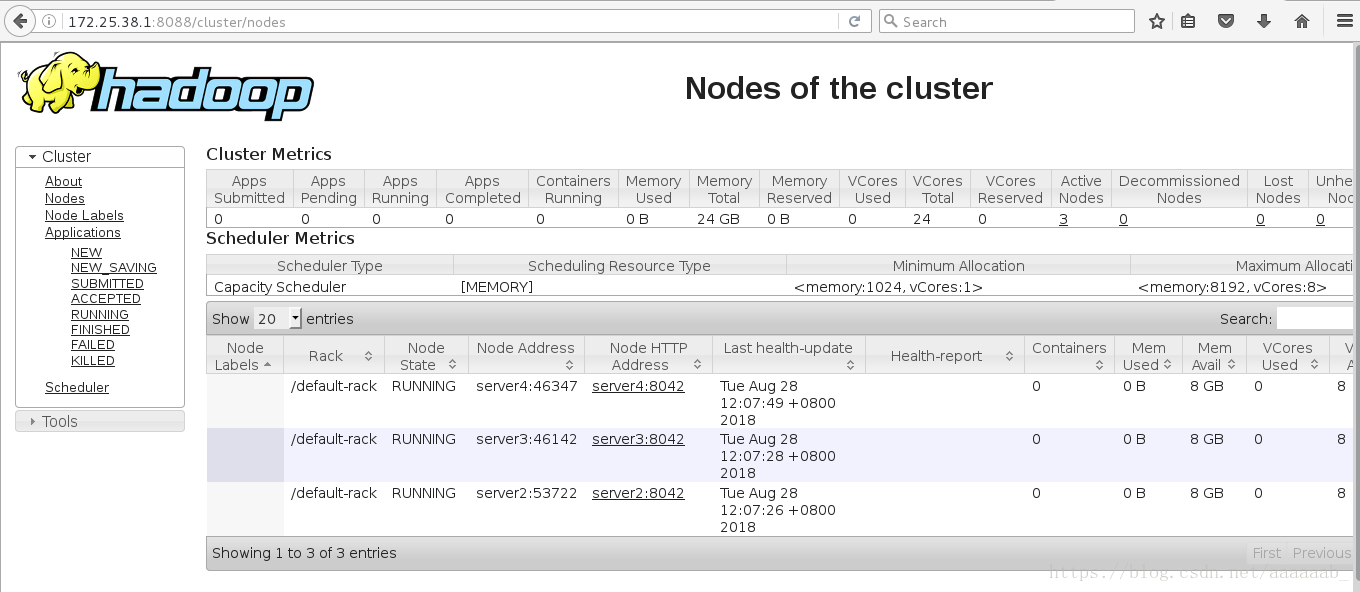
在server2的命令行查看当前master:
[hadoop@server2 zookeeper-3.4.9]$ bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, yarn-leader-election, hadoop-ha, rmstore]
[zk: localhost:2181(CONNECTED) 1] ls /yarn-leader-election
[RM_CLUSTER]
[zk: localhost:2181(CONNECTED) 2] ls /yarn-leader-election/RM_CLUSTER
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: localhost:2181(CONNECTED) 3] ls /yarn-leader-election/RM_CLUSTER/Active
ActiveBreadCrumb ActiveStandbyElectorLock
[zk: localhost:2181(CONNECTED) 3] ls /yarn-leader-election/RM_CLUSTER/ActiveBreadCrumb
[]
[zk: localhost:2181(CONNECTED) 4] get /yarn-leader-election/RM_CLUSTER/ActiveBreadCrumb
RM_CLUSTERrm1
cZxid = 0x100000016
ctime = Tue Aug 28 11:58:18 CST 2018
mZxid = 0x100000016
mtime = Tue Aug 28 11:58:18 CST 2018
pZxid = 0x100000016
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 17
numChildren = 0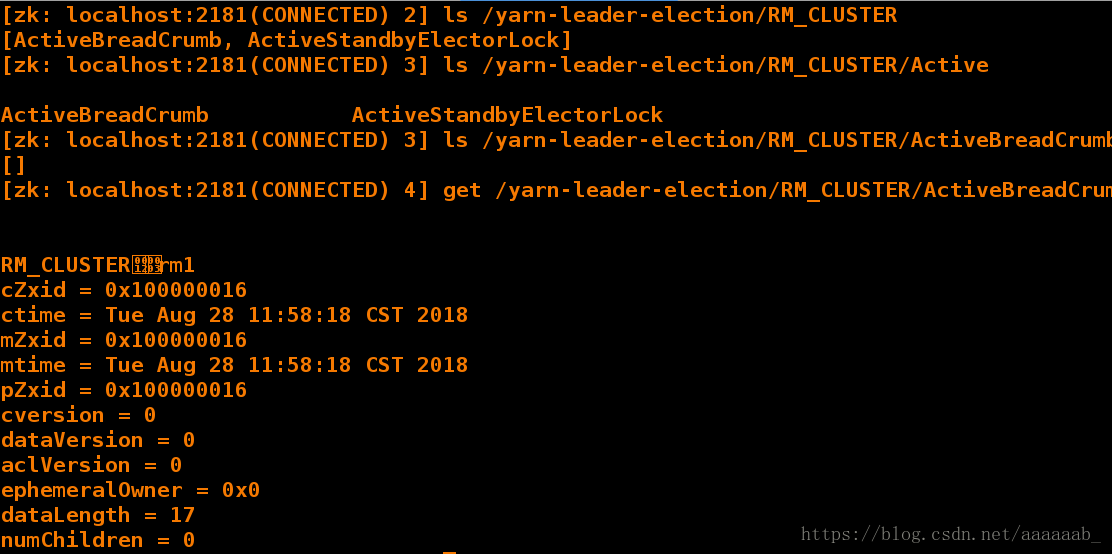
在网页分别访问server1为当前master:
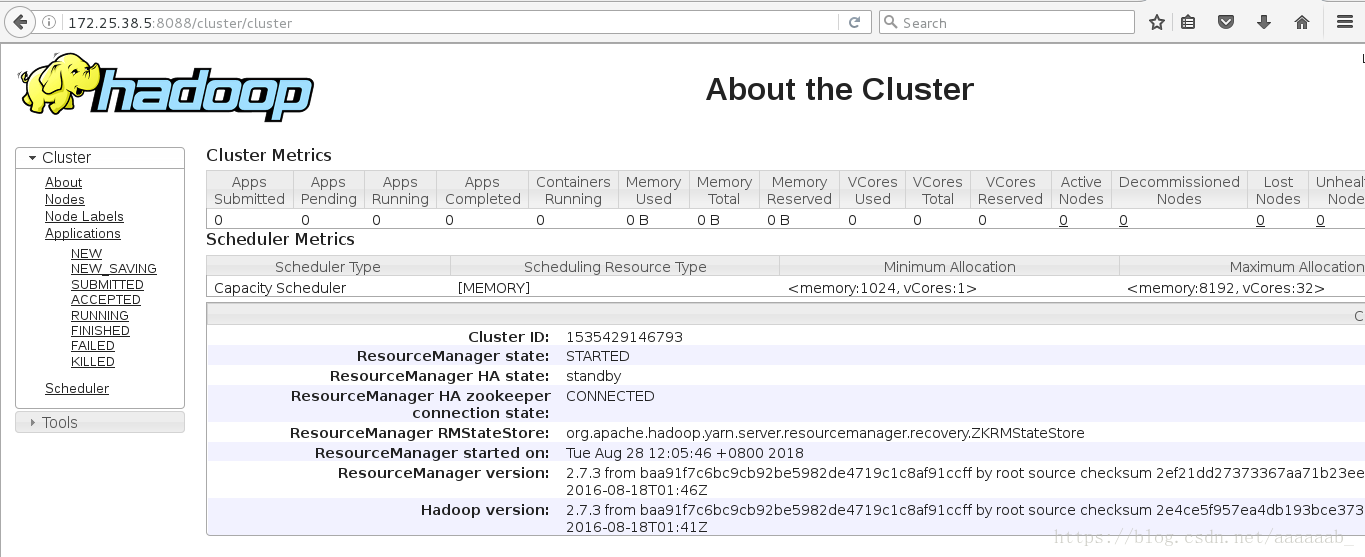
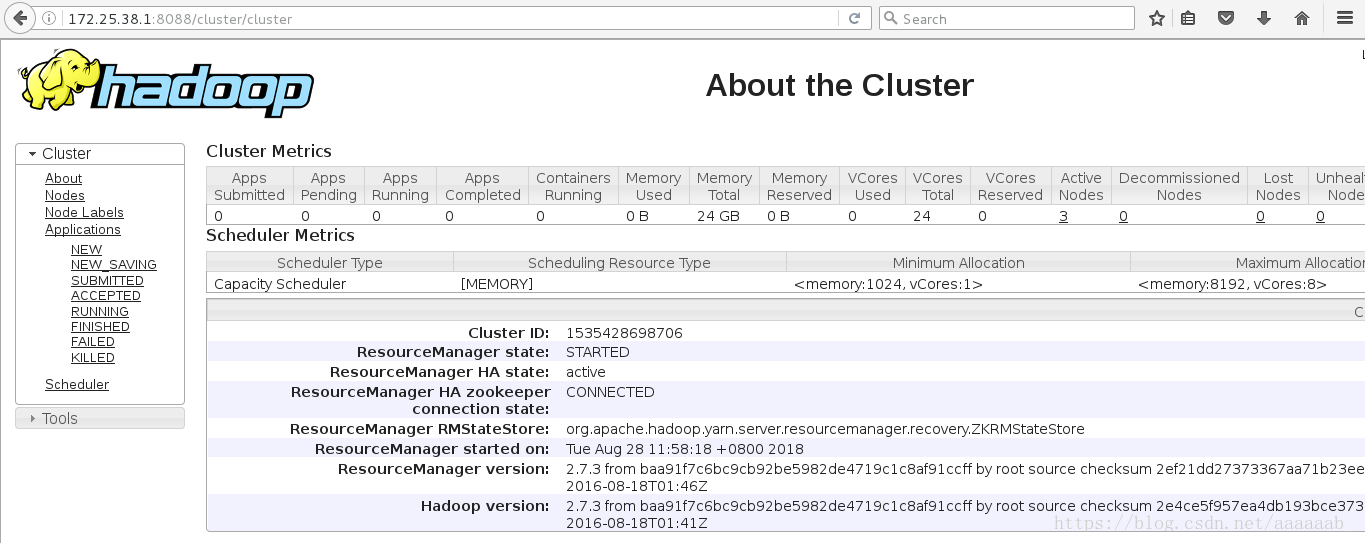
进行故障切换检测:
[hadoop@server1 hadoop]$ jps
1606 NameNode
1900 DFSZKFailoverController
2829 Jps
2335 ResourceManager
[hadoop@server1 hadoop]$ kill -9 2335 结束当前master进程
[hadoop@server1 hadoop]$ jps
1606 NameNode
2839 Jps
1900 DFSZKFailoverController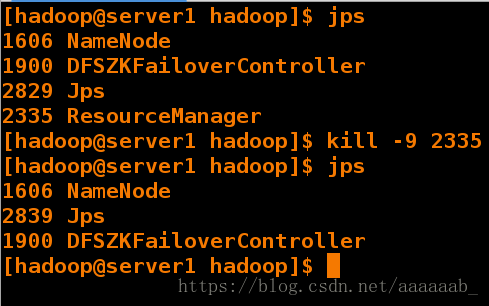
在网页查看server5变成了master:
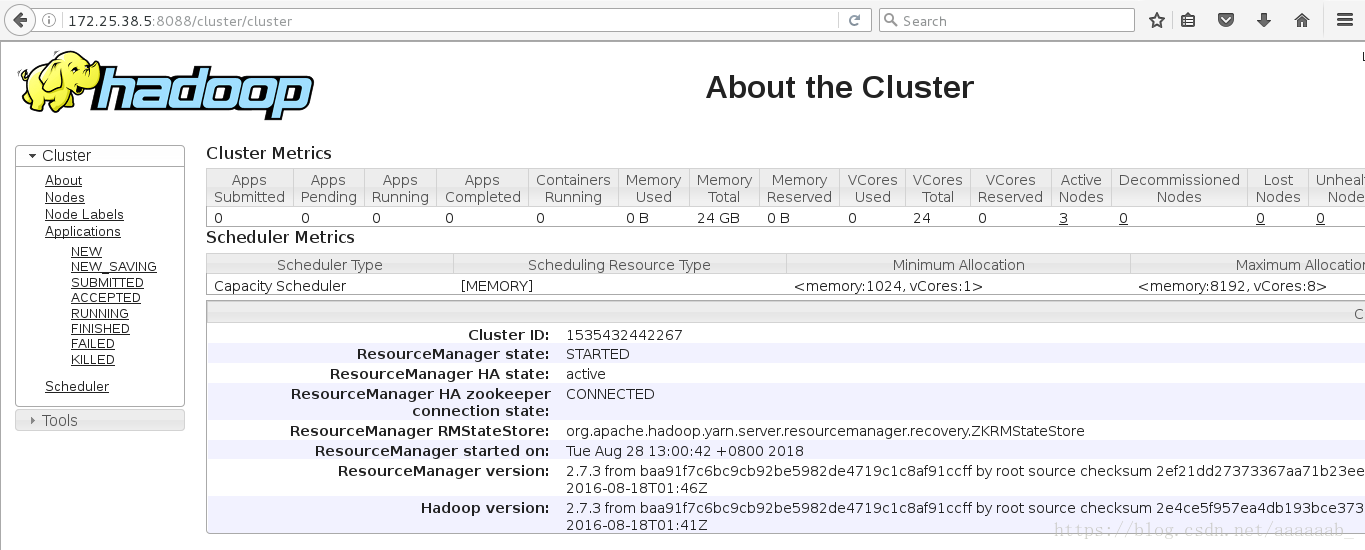
恢复server1的服务:
[hadoop@server1 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/hadoop-2.7.3/logs/yarn-hadoop-resourcemanager-server1.out
[hadoop@server1 hadoop]$ jps
2897 ResourceManager
1606 NameNode
1900 DFSZKFailoverController
2926 Jps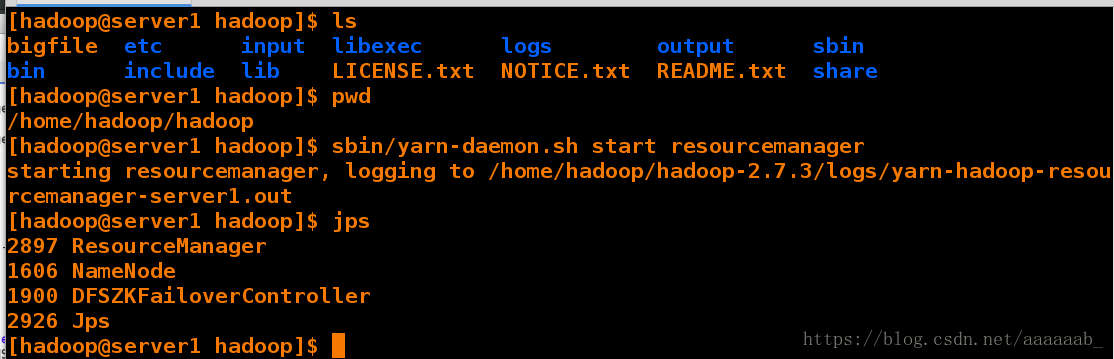
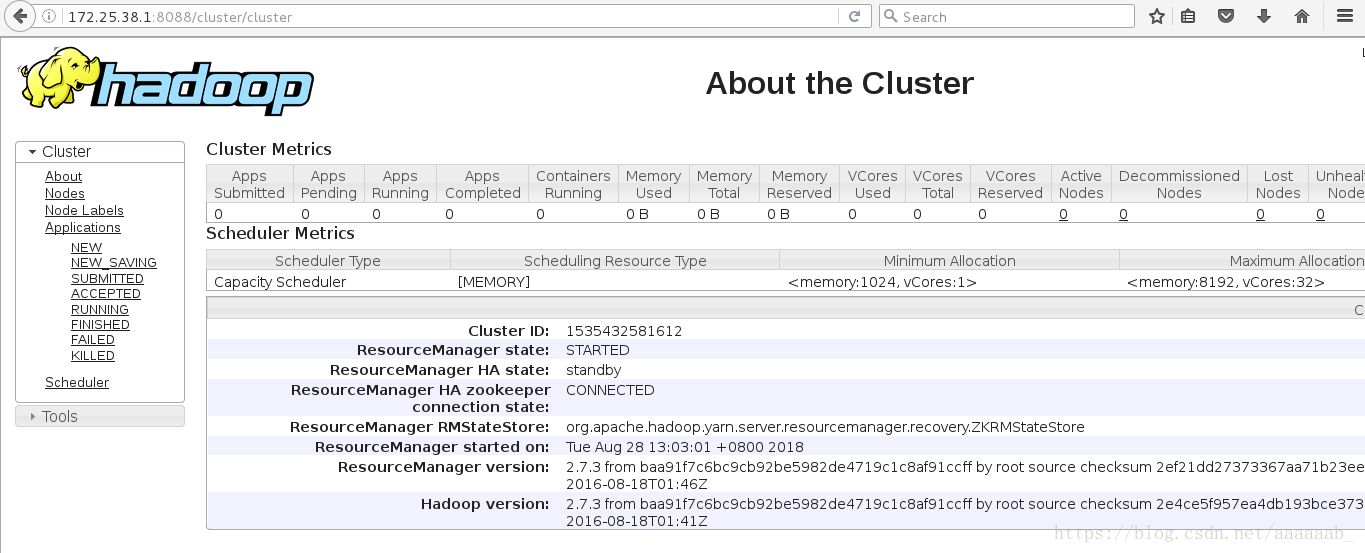
网页查看server1的状态为standby,作为备用节点:
hbase高可用
[hadoop@server1 ~]$ ls
hadoop hbase-1.2.4-bin.tar.gz jdk-7u79-linux-x64.tar.gz
hadoop-2.7.3 java zookeeper-3.4.9
hadoop-2.7.3.tar.gz jdk1.7.0_79 zookeeper-3.4.9.tar.gz
[hadoop@server1 ~]$ tar zxf hbase-1.2.4-bin.tar.gz 解压包
[hadoop@server1 ~]$ ls
hadoop hbase-1.2.4-bin.tar.gz zookeeper-3.4.9
hadoop-2.7.3 java zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk1.7.0_79
hbase-1.2.4 jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ cd hbase-1.2.4
[hadoop@server1 hbase-1.2.4]$ ls
bin conf hbase-webapps lib NOTICE.txt
CHANGES.txt docs LEGAL LICENSE.txt README.txt
[hadoop@server1 hbase-1.2.4]$ cd conf/
[hadoop@server1 conf]$ ls
hadoop-metrics2-hbase.properties hbase-env.sh hbase-site.xml regionservers
hbase-env.cmd hbase-policy.xml log4j.properties
[hadoop@server1 conf]$ vim hbase-env.sh
export JAVA_HOME=/home/hadoop/java 指定 jdk
export HBASE_MANAGES_ZK=false 默认值时 true,hbase 在启动时自
动开启 zookeeper,如需自己维护 zookeeper集群需设置为 false
export HADOOP_HOME=/home/hadoop/hadoop 指定 hadoop 目录,否则 hbase
无法识别 hdfs 集群配置。

[hadoop@server1 conf]$ vim hbase-site.xml
[hadoop@server1 conf]$ cat hbase-site.xml | tail -n 22
指定 region server 的共享目录,用来持久化 HBase。这里指定的 HDFS 地址
是要跟 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致
<property>
<name>hbase.rootdir</name>
<value>hdfs://masters/hbase</value>
</property>
启用 hbase 分布式模式
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
Zookeeper 集群的地址列表,用逗号分割。默认是 localhost,是给伪分布式用
的。要修改才能在完全分布式的情况下使用。
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.25.38.2,172.25.38.3,172.25.38.4</value>
</property>
指定 hbase 的 master
<property>
<name>hbase.master</name>
<value>h1</value>
</property>
</configuration>
[hadoop@server1 conf]$ vim regionservers
[hadoop@server1 conf]$ cat regionservers
172.25.38.2
172.25.38.3
172.25.38.4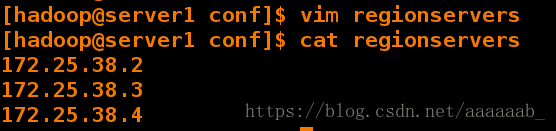
启动 hbase主节点运行:
[hadoop@server1 hbase-1.2.4]$ ls
bin conf hbase-webapps lib logs README.txt
CHANGES.txt docs LEGAL LICENSE.txt NOTICE.txt
[hadoop@server1 hbase-1.2.4]$ bin/start-hbase.sh
[hadoop@server1 hbase-1.2.4]$ jps
2897 ResourceManager
1606 NameNode
3451 Jps
1900 DFSZKFailoverController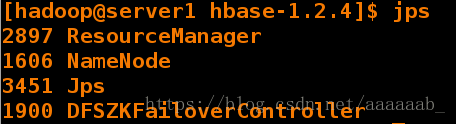
在server2命令行查看:
[hadoop@server2 bin]$ ./zkCli.sh
[zk: localhost:2181(CONNECTED) 2] ls /
[zookeeper, yarn-leader-election, hadoop-ha, hbase, rmstore]
[zk: localhost:2181(CONNECTED) 3] ls /habase
Node does not exist: /habase
[zk: localhost:2181(CONNECTED) 4] ls /hbase/master
[]
[zk: localhost:2181(CONNECTED) 5] get /hbase/master
�master:16000L��S���PBUF
server1�}����,�} 当前master为server1
cZxid = 0x100000278
ctime = Tue Aug 28 13:30:52 CST 2018
mZxid = 0x100000278
mtime = Tue Aug 28 13:30:52 CST 2018
pZxid = 0x100000278
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x3657e35d7150005
dataLength = 55
numChildren = 0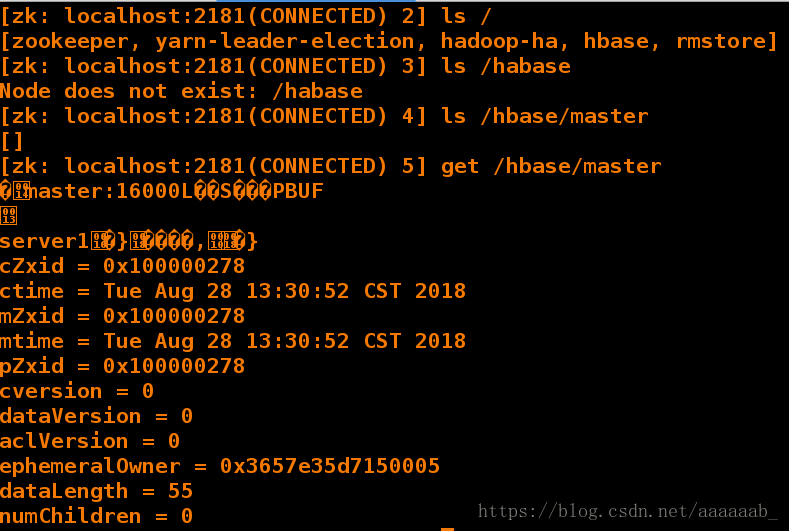
备节点运行:
[hadoop@server5 ~]$ ls
hadoop hbase-1.2.4-bin.tar.gz zookeeper-3.4.9
hadoop-2.7.3 java zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk1.7.0_79
hbase-1.2.4 jdk-7u79-linux-x64.tar.gz
[hadoop@server5 ~]$ cd hbase-1.2.4
[hadoop@server5 hbase-1.2.4]$ ls
bin conf hbase-webapps lib logs README.txt
CHANGES.txt docs LEGAL LICENSE.txt NOTICE.txt
[hadoop@server5 hbase-1.2.4]$ bin/hbase-daemon.sh start master
starting master, logging to /home/hadoop/hbase-1.2.4/bin/../logs/hbase-hadoop-master-server5.out
[hadoop@server5 hbase-1.2.4]$ jps
1479 DFSZKFailoverController
2020 NameNode
2711 ResourceManager
3978 Jps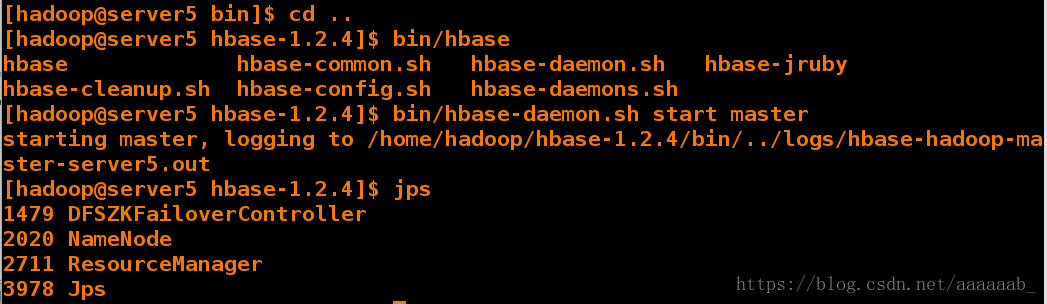
在网页查看server1为master,server5为backup master:
HBase Master 默认端口时 16000,还有个 web 界面默认在 Master 的 16010 端口
上,HBase RegionServers 会默认绑定 16020 端口,在端口 16030 上有一个展示
信息的界面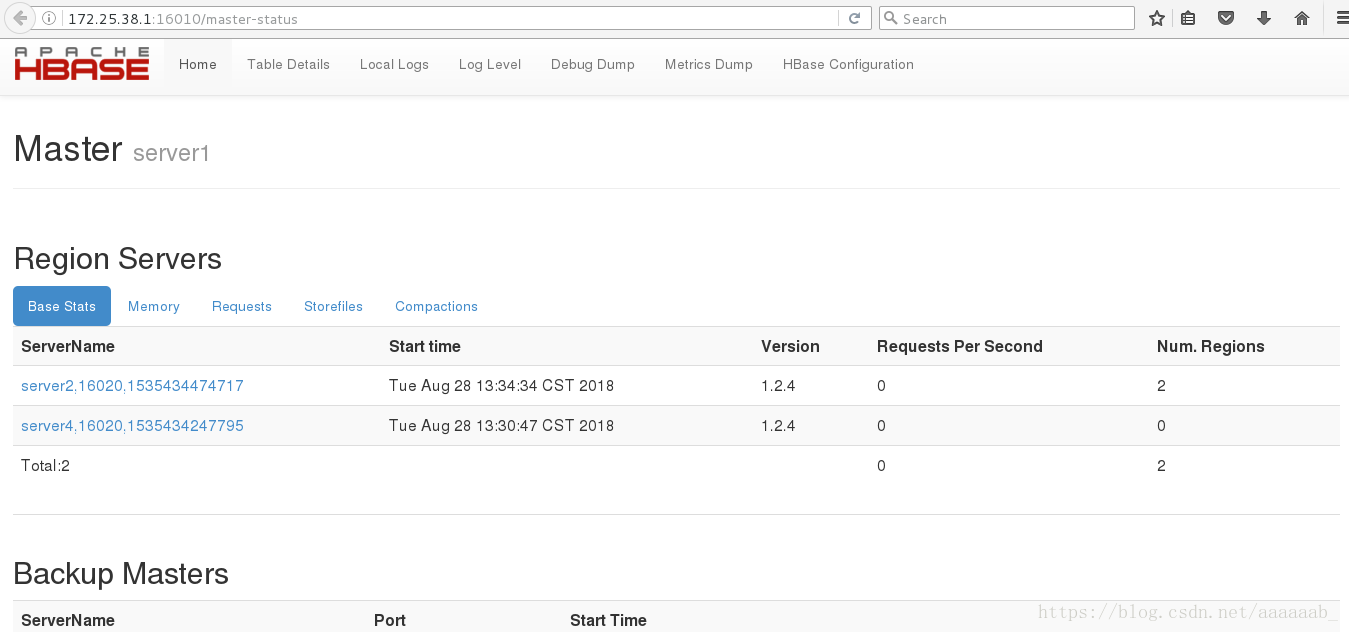
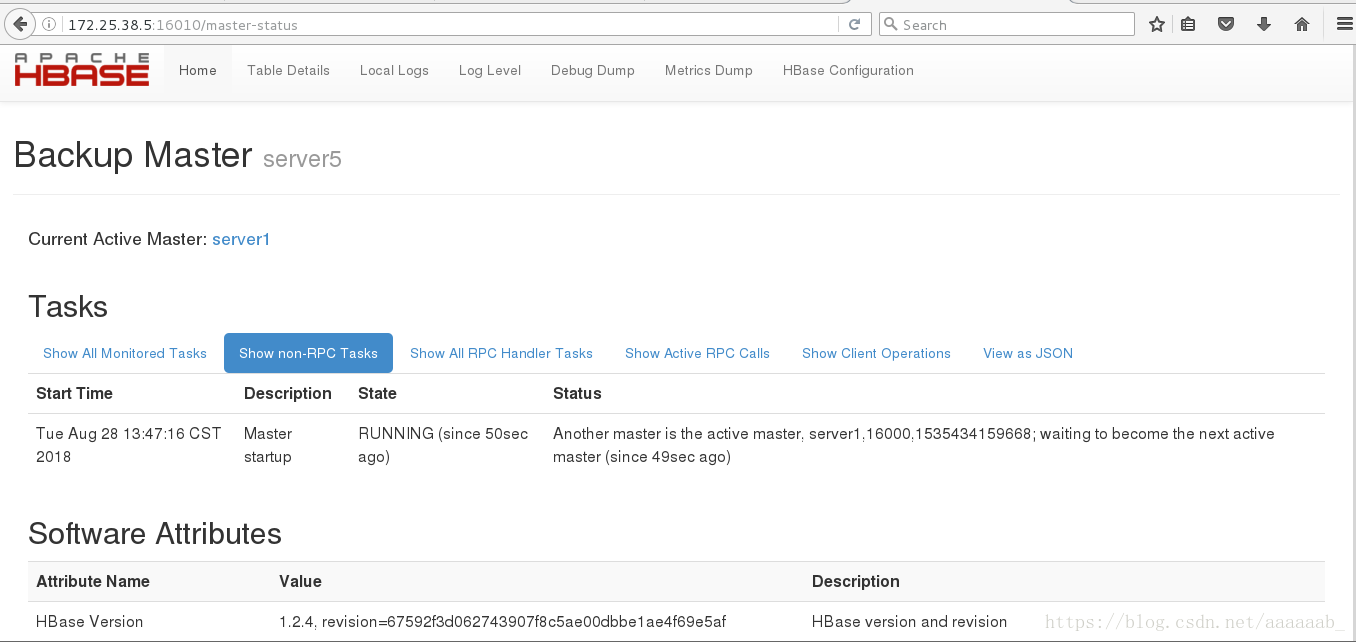
测试故障切换:
[hadoop@server1 ~]$ ls
hadoop hbase-1.2.4-bin.tar.gz zookeeper-3.4.9
hadoop-2.7.3 java zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk1.7.0_79
hbase-1.2.4 jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ cd hbase-1.2.4
[hadoop@server1 hbase-1.2.4]$ ls
bin conf hbase-webapps lib logs README.txt
CHANGES.txt docs LEGAL LICENSE.txt NOTICE.txt
[hadoop@server1 hbase-1.2.4]$ bin/hbase shell 打开一个shell
hbase(main):004:0> create 'linux', 'cf'
0 row(s) in 18.6610 seconds
=> Hbase::Table - linux
hbase(main):005:0> list 'linux'
TABLE
linux
1 row(s) in 0.0290 seconds
=> ["linux"]
hbase(main):006:0> put 'linux', 'row1', 'cf:a', 'value1'
0 row(s) in 1.6750 seconds
hbase(main):007:0> put 'linux', 'row2', 'cf:b', 'value2'
0 row(s) in 0.1740 seconds
hbase(main):008:0> put 'linux', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0470 seconds
hbase(main):009:0> scan 'linux' 创建字段信息
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1535435781214, value=value1
row2 column=cf:b, timestamp=1535435793162, value=value2
row3 column=cf:c, timestamp=1535435801252, value=value3
3 row(s) in 0.2010 seconds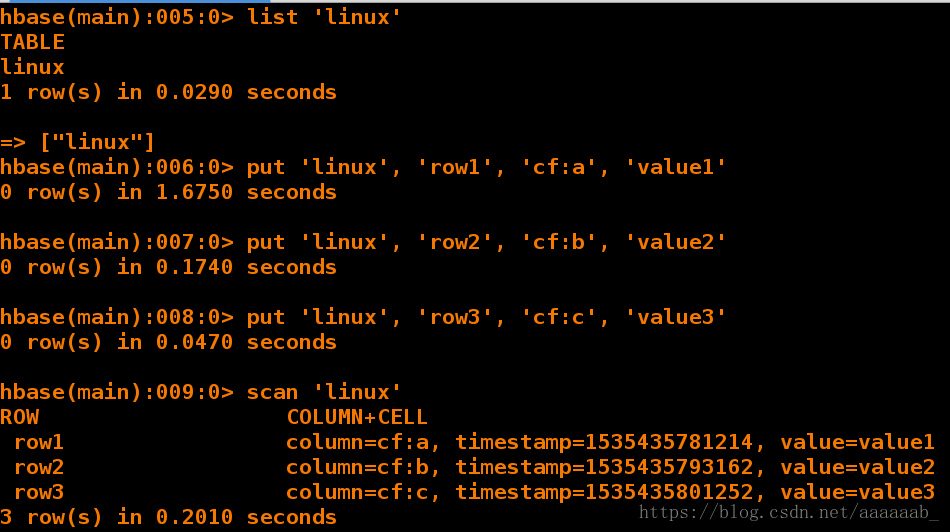
[hadoop@server1 ~]$ ls
hadoop hbase-1.2.4-bin.tar.gz zookeeper-3.4.9
hadoop-2.7.3 java zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk1.7.0_79
hbase-1.2.4 jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-08-28 10:59 input
[hadoop@server1 hadoop]$ bin/hdfs dfs -ls /
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2018-08-28 13:35 /hbase
drwxr-xr-x - hadoop supergroup 0 2018-08-28 10:59 /user
[hadoop@server1 hadoop]$ jps
5152 Jps
2897 ResourceManager
3829 HMaster
1606 NameNode
[hadoop@server1 hadoop]$ kill -9 3829 结束进程
[hadoop@server1 hadoop]$ jps
5200 Jps
2897 ResourceManager
5185 GetJavaProperty
1606 NameNode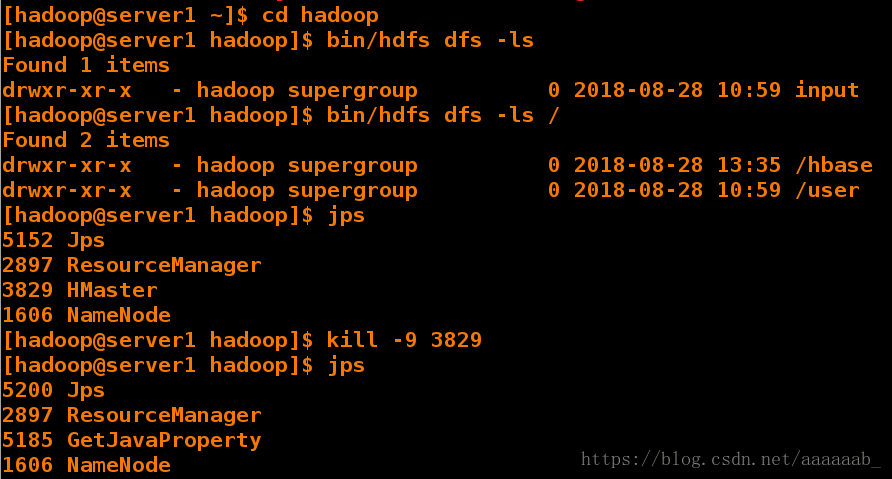
在网页查看server5接管成为新的master:
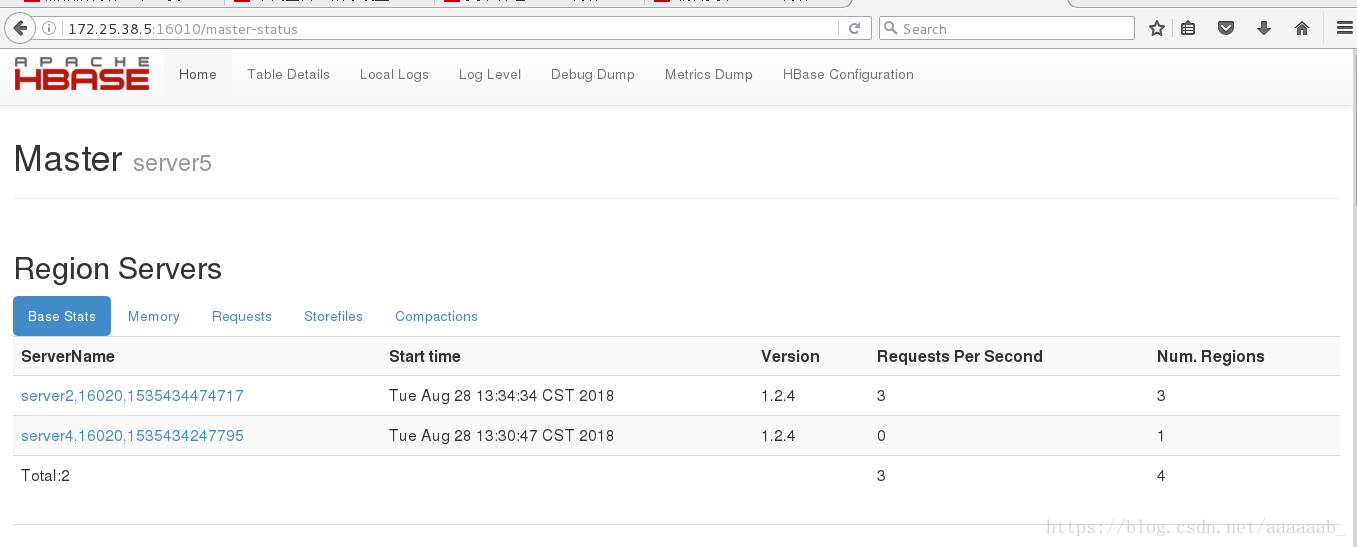
在server2的命令行也可以看到server5成为了master:
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, yarn-leader-election, hadoop-ha, hbase, rmstore]
[zk: localhost:2181(CONNECTED) 1] ls /hbase/master
[]
[zk: localhost:2181(CONNECTED) 2] get /hbase/master
�master:16000�2V��Ex�PBUF
server5�}�����,�}
cZxid = 0x1000003c8
ctime = Tue Aug 28 13:58:59 CST 2018
mZxid = 0x1000003c8
mtime = Tue Aug 28 13:58:59 CST 2018
pZxid = 0x1000003c8
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x2657e356bc6000d
dataLength = 55
numChildren = 0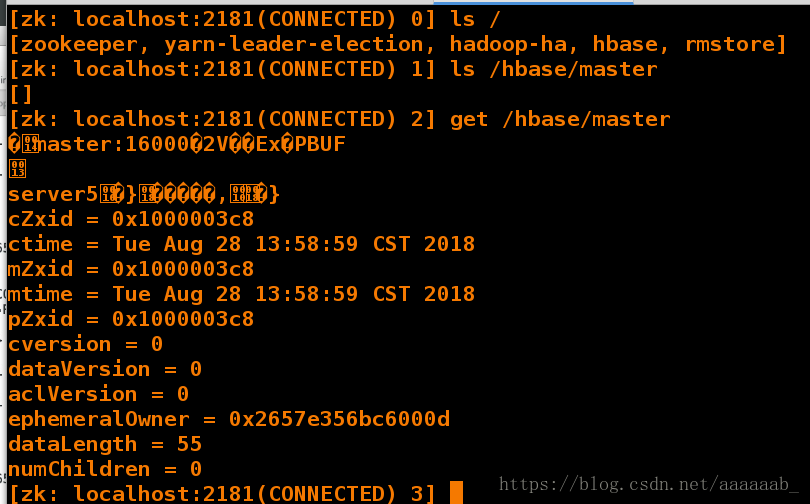
在server1可以查看字段信息:
[hadoop@server1 ~]$ ls
hadoop hbase-1.2.4-bin.tar.gz zookeeper-3.4.9
hadoop-2.7.3 java zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk1.7.0_79
hbase-1.2.4 jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ cd hbase-1.2.4
[hadoop@server1 hbase-1.2.4]$ bin/hbase shell
hbase(main):001:0> scan 'linux'
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1535435781214, value=value1
row2 column=cf:b, timestamp=1535435793162, value=value2
row3 column=cf:c, timestamp=1535435801252, value=value3
3 row(s) in 0.5400 seconds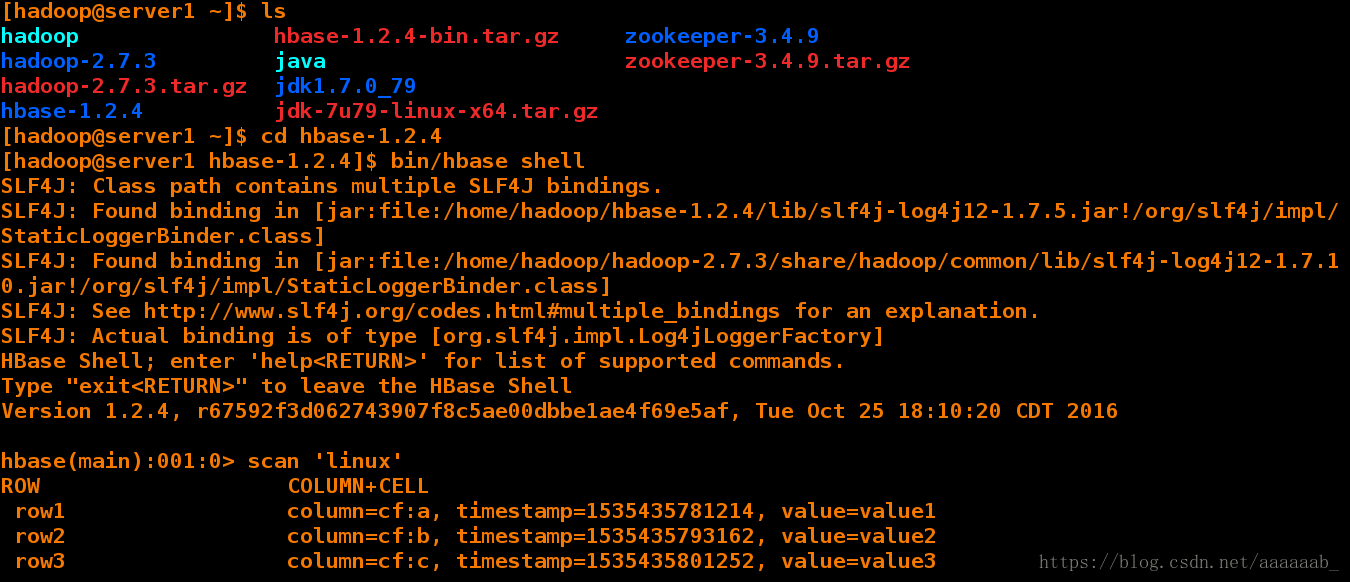
智能推荐
frp 远程连接内网主机详细教程_privilege_token-程序员宅基地
文章浏览阅读4.4k次。文章目录1. 准备工作2. 服务端配置(远程 server)2.1 下载与安装2.2 配置2.3 设置开机启动和后台运行2.4 测试3. 客户端配置(本地主机)3.1 下载与安装3.2 配置3.3 设置开机启动4. 连接测试1. 准备工作一台有公网 ip 的 server一台内网主机2. 服务端配置(远程 server)这里以阿里云 Centos 7 为例2.1 下载与安装进入 /tmp 目录cd /tmp在 Releases 页面下载与 server 系统、架构相符的 frp 版本_privilege_token
ShaderToy入门教程(1) - SDF 和 Raymarching 算法-程序员宅基地
文章浏览阅读8k次,点赞14次,收藏58次。许多演示场景中使用的技术之一称为光线跟踪。该算法与一种称为“有符号距离函数”的特殊函数结合使用,可以实时创建一些非常酷的东西。这是系列教程,陆续推出,这篇涵盖以下黑体所示内容符号距离函数Ray-marching算法曲面法线和光照移动相机构造实体几何模型转换轮换和翻译统一缩放非均匀缩放和超越把它们放在一起参考1、符号距离函数符号距离函数,或简称为SDF,当给出空间中一个..._shadertoy
解决gerrit merge冲突-程序员宅基地
文章浏览阅读3.9k次。出现问题原因:commit相互依赖。具体讲就是:gerrit上已经存在commit A(commit A还未merge入库),然后你在commit A的代码基础上进行了修改(划重点,基于A修改!),并做了新的commit B,commit B已经包含了commit A的修改,于是在gerrit 上abondon commit A,只留下commit B在gerrit上,这样一来,commit B..._gerrit merge
最新!互联网大厂各职级薪资对应关系图(2020年初)-程序员宅基地
文章浏览阅读2.9w次,点赞6次,收藏21次。来源:知乎普拉思驿站首先,还是要说一句,我当然不是猎头,但最近一段时间,我找到了业余生活的一大乐趣,就是在脉脉职言区看大家晒的 offer,然后觉得吧,光看不行,所以就顺手总结了一下,画..._快手职级多少对应p5
页面设置body高度height:100%不生效解决办法_document.body.style.height 不生效-程序员宅基地
文章浏览阅读696次。直接body{ height: 100%; }不生效的话,那就在前面加个html吧,如下:html,body { height: 100% }如果想要知道原理的可以参阅下面这篇文章,写得很好转自:https://blog.csdn.net/javaloveiphone/article/details/51098972..._document.body.style.height 不生效
Vue.js仿饿了么外卖App--(4)商品详情页实现_vue饿了么小程序商品页-程序员宅基地
文章浏览阅读1.7k次,点赞3次,收藏12次。文章目录一、内容介绍1、内容2、效果二、具体实现1、组件传值2、点击事件3、图片展示4、加入购物车5、分隔条组件一、内容介绍1、内容本篇文章主要实现的是商品详情页的展示,主要包括商品图片展示、商品信息展示和商品评价展示2、效果二、具体实现1、组件传值goods.vue <Food :food="selectedFood" ref="food"></Food>food.vue通过props属性接收 props: { food: { type: _vue饿了么小程序商品页
随便推点
BZOJ 3730 震波 - 点分树+线段树+容斥_点权修改,查询距离不超过k点权和-程序员宅基地
文章浏览阅读283次。题意:在一棵只有点权的树上在线求据一个点x距离为k的点权和一言不合又是200+,而且还卡常~~~卡常~~~,幸好机智地加了读入输出优化险险地卡了过去 /笑每个节点建立两个线段树,以到点的距离为下标,记录权值和。第一棵记录其作为点分数父节点遍历其统治的子树的以距离为下标的点权和。由于点分树树高仅logn,暴力翻树高,在其经过的点分树祖先节点上查询距离为的k-now的点权和(now即为_点权修改,查询距离不超过k点权和
数据结构之堆排序算法详解+C语言实现_c语言带结构体的小顶堆排序-程序员宅基地
文章浏览阅读5.5k次,点赞19次,收藏73次。堆 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆;或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆。堆排序 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序。在数据结构中,我们将堆的逻辑结构映射到数组中存储,如下图:于是在数组中,堆中节点的索..._c语言带结构体的小顶堆排序
txt文件转csv文件乱码问题_txt转csv乱码-程序员宅基地
文章浏览阅读5.5k次,点赞7次,收藏17次。新建文本文件这里我们新建一个记事本,注意里面的表格属性(列)之间要用英文的逗号隔开,现在我们把它保存,转换为一个csv文件转换为csv文件直接重命名文件扩展名即可,我们打开csv文件,发现是乱码修改编码方式我们继续将文件扩展名改为txt,打开后另存为,发现他的编码方式是UTF-8,我们将其修改为ANSI即可再次重命名为csv文件,打开就不会出现乱码..._txt转csv乱码
如何用电脑玩石器时代M 石器时代M手游PC电脑版教程_石器时代电脑-程序员宅基地
文章浏览阅读3.8k次。《石器时代M》是一款3D角色扮演手游,以“石器时代”为背景题材,我们将在开放式的大型地图上自由探索,超多的玩法内容,经典的策略回合制战斗,将给我们带来全新的游戏乐趣!接下来,和小编一起看下石器时代M电脑版教程哈!一、石器时代M电脑版教程1、首先呢,我们要做好玩前的准备工作,在电脑上下一个模拟器。因为要想在电脑上玩手游,就必须在电脑上装个模拟器,这个是电脑玩手游的前提条件,模拟器就相当于..._石器时代电脑
java在linux下新建文件夹_setwritable-程序员宅基地
文章浏览阅读1.7w次,点赞5次,收藏11次。java在linux下新建目录需要先获取权限File f=new File("/home/hay");f.setWritable(true, false); //设置写权限,windows下不用此语句f.mkdirs();_setwritable
GPS轨迹数据集免费下载资源整理_大西洋飓风数据下载-程序员宅基地
文章浏览阅读3.8w次,点赞48次,收藏175次。本文主要是整理了GPS轨迹数据集免费资源库,从这些库中能够免费下载到GPS数据,同时还整理出了这些数据的格式,数据集的简单描述等等。如果你发现更好的相关数据资源,欢迎共享 :)1. GeoLife GPS Trajectories该GPS轨迹数据集出自微软研究GeoLift项目。从2007年四月到2012年八月收集了182个用户的轨迹数据。这些数据包含了一系列以时间为序的点,每一个点包含经纬度、海拔_大西洋飓风数据下载