【Java项目】1000w数据量的表如何做到快速的关键字检索?_java千万数据量查询-程序员宅基地
技术标签: 算法 java elasticsearch mysql 数据结构
需求
ok,这个需求是我提的,然后我问了我的一位杭州的朋友,然后我们最后一起敲定这个方法。
我的项目有一个根据关键字进行商品名称的搜索功能,用户输入部分关键字之后,那么就需要查询出这个关键字对应的所有商品。假设我现在有1000w行记录,并且不能使用ES做倒排索引解决这个问题。
那么你会如何解决这个问题?
我们先分析,如果我们使用数据库提供的 % 这种模糊匹配机制,首先我们的索引会失效,并且这基本意味着会走全表扫描,对于1000w行的记录如果我们走全表扫描,那么效率可想而知。
并且如果使用分库分表技术,那么维护的难度也大了,不论是业务代码还是数据库都得跟着修改,非常麻烦,那么如何解决这个问题?
解决思路
基本设计
大概流程如下:
我们可以自己实现一个倒排索引的算法,用户创建商品之后,将商品名称进行细粒度的分词,比如输入 “Java技术指导”,那么分词为“Java”,“技术”,“指导”。粒度越细越好。
可以看到此时我们得到的是一个数组,对吧。
然后我们创建两张表,一张表是商品表,存储商品的完整信息。
另一张表是倒排索引表,里面是什么内容?
包括id,word,goods_ids
这里的word就是我们的分词数据,goods_ids也就是我们这个关键字下面对应的所有商品id。
上面我们对一个字符串进行分词后得到的,其实是一个数组对吧,那么我们此时就可以向数据库中插入这三行的数据了,大概格式如下。
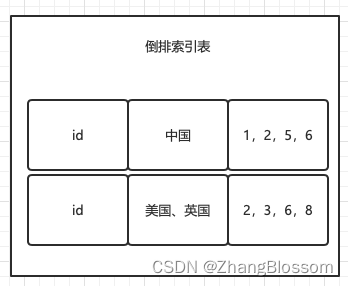
然后我们得到goods_ids是一个集合,我们在使用这个集合去商品表中查询出所有在这个集合中的记录即可。
查询流程
那么我现在大概简述一下一个数据的查询流程:
我们查询一个商品,通过关键字的方式,经过倒排索引的算法得到word值,去数据库中查询是否有这个word值,如果有,那么直接查询出来这个关键字对应的goods_ids这一段字符串,我们对字符串进行处理得到字符串包含的所有id,然后用这些id去商品表查询数据即可。
ok,那么如果有插入和修改,删除等操作怎么办呢?
插入流程
先说插入流程,一样的,当我们要插入一个数据的时候,我们先得到这个商品对应的word,也就是我们取出商品的name商品名称字段,然后对这个name字段进行分词算法,得到细粒度的分词。之后,我们我们将这个记录插入到商品表中,得到插入的id之后,返回id成功后,我们在将分词得到的数组,配合上我们得到的商品id,循环的去插入到这个分词表中,如果分词表中出现了重复的word,那么我们做的是取出goods_ids这个字段,然后再字段尾巴上补上这个id,而如果不存在这个字段,则新建一行记录,word为当前分词,goods_ids直接为刚才返回的id。
修改流程
修改流程其实已经和上面的流程差不多了,依旧是经过分词,然后去精确判断分词对应的行,然后修改对应的ids字段即可。
当然,其实没有必要这样子,因为会让代码更加复杂,我们只需要拿到所有的id之后,去商品表中判断的时候判断删除标志位即可,也就是使用逻辑删除即可。
删除流程
删除流程也差不多,只不过我们如何删除对应的goods_ids中的哪一个id呢?
我们首先取出goods_ids这个字段值,然后通过 “ ,”分隔符得到每一个id,然后我们删除指定的id即可,当然,为了加快速度,我们的商品表中的id是自增的,所以这样子就能尽可能快的删除指定数据了。
优化思路
其实,顺着上面的思路,我忽然想到。其实我们的数据库其实作用就是为了保存一个分词,然后分词后面对应的是一堆的id,这些id是字符串,也就是我们取出来之后还得先经过处理才能得到真正可用的id。
我想的是,上面的结构其实很简单,就是一个 word—goods_ids的结构,这种结构用Redis肯定可以呀对吧。
但是如果你直接K-V结构或者hash,那么结构其实相当于就是把磁盘空间变成了内存空间,我觉得也没有多好。当然,处理起来可能比刚才那个转字符串完毕之后,然后再查询来的快。
然后我就我想到了我常用的Bitmap结构,0101啊,对吧,我只需要把如果说存在这个id,那么我把对应的位置置1即可,这样子增删改的速度全都加快了不是嘛。
当然,有一个缺点就是,查询Redis是有网络开销的。
但是我觉得如果使用Redis的bitmap,那么由于增删改查的速度都更快了,并且也不需要字符串的处理了,可能效果更优。
当然,也可以直接使用Java提供的BitSet。
但是我实现了一下发现,BitSet的缺点在于,我不能很快的得到到底那些索引位为1,我需要不断的通过位运算的方式才能得到为1的位。
Redis的问题在于,如果我使用RedisTemplate然后去获取bitmap结构整个结构,会报错,就导致我依旧可能需要去循环遍历每个可能位1的位。
代码实现
代码单纯只是为了验证这种方式的可行性,对于数据库字段的设计,以及其他性能方面的考虑,代码方面的优化都还没有做。大致代码如下:
POJO类
@Data
@TableName("goods")
@AllArgsConstructor
@NoArgsConstructor
public class Goods implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
private String goodName;
@TableLogic(value = "false", delval = "true")
private boolean deleted;
}
@Data
@TableName("word_goods")
public class WordGoods implements Serializable {
private static final long serialVersionUID = 1L;
/**
* 主键
*/
@TableId(value = "id", type = IdType.AUTO)
private Long id;
private String goodsId;
private String word;
}
Service代码
package ebuy.campus.deal.service.impl;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import ebuy.campus.deal.mapper.GoodsMapper;
import ebuy.campus.deal.mapper.WordGoodsMapper;
import ebuy.campus.deal.model.pojo.Goods;
import ebuy.campus.deal.model.pojo.WordGoods;
import ebuy.campus.deal.service.GoodsService;
import ebuy.campus.framework.core.constant.DealConstant;
import ebuy.campus.framework.core.util.HanLPUtil;
import ebuy.campus.framework.redis.service.RedisService;
import org.jetbrains.annotations.NotNull;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.io.IOException;
import java.util.*;
/**
* @author: 张锦标
* @date: 2023/6/13 15:26
* GoodsServiceImpl类
*/
@Service
public class GoodsServiceImpl implements GoodsService {
@Autowired
private GoodsMapper goodsMapper;
@Autowired
private WordGoodsMapper wordGoodsMapper;
@Autowired
private RedisService redisService;
@Transactional
public boolean add(Goods goods) {
try {
//分词操作
List<String> texts = HanLPUtil.parse(goods.getGoodName());
//取出数据库中包含该分词的所有行
LambdaQueryWrapper<WordGoods> lqw = new LambdaQueryWrapper<>();
lqw.in(WordGoods::getWord, texts.toArray());
List<WordGoods> wordGoods = wordGoodsMapper.selectList(lqw);
//得到数据库中已有的所有分词
List<String> words = wordGoods.stream().map(x -> x.getWord()).toList();
//得到数据库中没有的分词
List<String> newWords = texts.stream().dropWhile(x -> words.contains(x)).toList();
//插入当前新数据
int success = goodsMapper.insert(goods);
if (success <= 0) {
return false;
}
Long id = goods.getId();
;
//修改数据库已有分词的数据
wordGoods.stream().forEach(x -> {
x.setGoodsId(x.getGoodsId() + "," + id);
wordGoodsMapper.updateById(x);
String goodsId = x.getGoodsId();
//保存到redis
for (String s : goodsId.split(",")) {
redisService.setBit(DealConstant.DEAL_SEARCH_KEY + x.getWord(), Long.valueOf(s), true);
}
});
//插入没有的分词
newWords.stream().forEach(word -> {
WordGoods x = new WordGoods();
x.setGoodsId(String.valueOf(id));
x.setWord(word);
wordGoodsMapper.insert(x);
//保存到redis
redisService.setBit(DealConstant.DEAL_SEARCH_KEY + x.getWord(), id, true);
});
} catch (IOException e) {
throw new RuntimeException(e);
}
return true;
}
@Override
public List<Goods> listByWord(String word) {
//分词操作
List<String> texts = null;
Set<Long> ids = new HashSet<>();
try {
texts = HanLPUtil.parse(word);
for (String x : texts) {
List<Long> bitsIndexes = redisService
.getBitIndexesByKey(DealConstant.DEAL_SEARCH_KEY + x);
ids.addAll(bitsIndexes);
}
//redis里面没有存储id
if (ids.isEmpty()) {
//取出数据库中包含该分词的所有行
LambdaQueryWrapper<WordGoods> lqw = new LambdaQueryWrapper<>();
lqw.in(WordGoods::getWord, texts.toArray());
List<WordGoods> wordGoods = wordGoodsMapper.selectList(lqw);
ids = getIds(wordGoods);
LambdaQueryWrapper<Goods> lqw1 = new LambdaQueryWrapper<>();
lqw1.in(!ids.isEmpty(), Goods::getId, ids);
List<Goods> goodsList = goodsMapper.selectList(lqw1);
return goodsList;
} else {
//redis里面有id了,直接查询
LambdaQueryWrapper<Goods> lqw1 = new LambdaQueryWrapper<>();
lqw1.in(!ids.isEmpty(), Goods::getId, ids);
List<Goods> goodsList = goodsMapper.selectList(lqw1);
return goodsList;
}
} catch (IOException e) {
throw new RuntimeException(e);
}
}
@NotNull
private Set<Long> getIds(List<WordGoods> wordGoods) {
Set<Long> ids = new HashSet<>();
for (WordGoods wordGood : wordGoods) {
String goodsId = wordGood.getGoodsId();
String[] split = goodsId.split(",");
for (int i = 0; i < split.length; i++) {
ids.add(Long.valueOf(split[i]));
}
}
return ids;
}
}
智能推荐
OpenSessionInViewFilter与Write operations are not allowed in read-only mode 独门问题解决之道_opensessioninview的时候数据库onlyread-程序员宅基地
文章浏览阅读647次。博主大三在实验室项目中使用 Spring 整合 Hibernate, 在懒加载的情况下,会出现一个异常,但为了查询效率,又需要利用懒加载用于关联表,查阅了网上资料说是在web.xml文件中加入一个过滤器OpenSessionInViewFilter如下方式 OpenSessionInViewFilter org.springframework.orm.hibe_opensessioninview的时候数据库onlyread
pdb模式下键用户_oracle12c 查询pdb模式下创建的用户-程序员宅基地
文章浏览阅读634次。,参考https://www.cnblogs.com/siyunianhua/p/4004361.html,模式切换为PDB1)查看版本SQL> select * from v$version;BANNER CON_ID------------------------------..._oracle12c 查询pdb模式下创建的用户
Android初级开发第八讲--ListView学习以及特性介绍-程序员宅基地
文章浏览阅读117次。博客出自:http://blog.csdn.net/liuxian13183,转载注明出处! All Rights Reserved !一般,安卓程序中要实现列表数据会用到ListView和GridView,相似度很高,今天主要拿前者来讲述。咱们先看代码private List<Object> data; private Context..._讲一下listview的特点??
这些Vue框架用起来很舒服_ionic vue 目前开发成熟吗-程序员宅基地
文章浏览阅读8.6k次,点赞63次,收藏289次。VUE3框架网站????导读????Vuestic????Ant Design Vue????Element+????Ionic????Naive UI????PrimeVUE????Wave UI最重要的事????导读最近再写web项目的时候找了一些个不错的VUE3的框架,好了我们废话不多说来看看这些优秀的资源怎么用我就不说了。里面的导航介绍都有而且都很详细。来吧我们开始今天的肥学。????Vuestic链接:传送门这款可以说是very beautiful了,哎呀忘了给大家贴一个动态_ionic vue 目前开发成熟吗
java中token原理及生成使用机制_java中token用法-程序员宅基地
文章浏览阅读7.1k次,点赞2次,收藏19次。常用认证机制介绍1、HTTP Basic AuthHTTP Basic Auth简单点说明就是每次请求API时都提供用户的username和password,简言之,Basic Auth是配合RESTful API 使用的最简单的认证方式,只需提供用户名密码即可,但由于有把用户名密码暴露给第三方客户端的风险,在生产环境下被使用的越来越少。因此,在开发对外开放的RESTful API时,尽量避免采用HTTP Basic Auth这种认证方法的优点是简单,容易理解。缺点有:不安全:认证身份信_java中token用法
前言技术之Oauth2全方面介绍-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏21次。一、Oauth2基本概念1、定义Oauth2是目前最流行的授权机制,用来授权第三方应用,获取用户数据2、场景带入1、外卖场景一户人家住在一个大型居住小区,小区有门禁系统,进入小区需要输入密码,这户人家经常性点外卖,必须让外卖人员进入到小区,如果把密码告诉外卖人员,这样的话,他就和户主拥有了一样的权限,这样安全隐患太大,给了外面人员密码之后,为了安全,必须要进行修改密码,这就很麻烦。这时候Oauth2就诞生了,外卖人员的职责只是送货,没必要知道小区密码..._oauth2
随便推点
java创建image类_关于java:如何使用文件作为参数创建BufferedImage新类-程序员宅基地
文章浏览阅读653次。我想创建一个新类,因为我想创建一些新方法,该方法扩展了BufferedImage并接受一个文件(一个bmp图片)作为参数。就像这里发生的事情:BufferedImage image = ImageIO.read(new File(dir +"coffeecup.png"));浏览文档时,我发现BufferedImage类具有两个构造函数:公共BufferedImage(ColorModel cm,..._hutool创建文件 bufferedimage
eclipse中配置Tomcat_在eclpise里面怎么关闭tomcat服务器-程序员宅基地
文章浏览阅读2.5w次,点赞79次,收藏433次。将Tomcat服务器整合到Eclipse工具中,可以通过Eclipse启动、关闭tomcat服务器,更重要的是,可以非常方便的将在Eclipse中创建的Web项目发布到Tomcat服务器中运行。文章目录在这里插入图片描述方式一:在window偏好设置中配置Tomcat方式二:在创建Web项目时配置Tomcat三、将整合到Eclipse中的tomcat从Eclipse中删除四、在Eclipse中创建Server及移除Server五、tomcat右键选项介绍六、tomcat启动失败常见原因方式一:在w._在eclpise里面怎么关闭tomcat服务器
计算机网络学习-001_在如图所示的交换网络中,所有交换机都启用了 stp 协议。swa 被选为了根桥。根据图-程序员宅基地
文章浏览阅读780次。计算机网络学习001以下工作于OSI 参考模型数据链路层的设备是______。(选择一项或多项)A. 广域网交换机 B. 路由器 C. 中继器 D. 集线器Answer: A注: 交换机为L2层设备,路由器为L3层,集线器和中继器为L1层设备下列有关光纤的说法中哪些是错误的?A. 多模光纤可传输不同波长不同入射角度的光 B. 多模光纤的纤芯较细C. 采用多模光纤时,信号的最大传输距离比单模光纤长 D. 多模光纤的成本比单模光纤低Answer: BC注: 多模光纤_在如图所示的交换网络中,所有交换机都启用了 stp 协议。swa 被选为了根桥。根据图
Methacrylate-PEG-Rhodamine,Methacrylate-PEG-RB高分子相关知识的分享-程序员宅基地
文章浏览阅读50次。Methacrylate-PEG-Rhodamine,Methacrylate-PEG-RB的分子量:Methacrylate-PEG-Rhodamine 1k,Methacrylate-PEG-RB 2000,甲基丙烯酸酯-聚乙二醇-罗丹明 3400,甲基丙烯酸酯-聚乙二醇-罗丹明 MW:5000,Methacrylate-PEG-Rhodamine 10k,甲基丙烯酸酯-聚乙二醇-罗丹明 20000.罗丹明-聚乙二醇-炔基,MW:3400,Rhodamine-PEG-Alkyne。
转载 | 防止页面图片过大出现横滚动条问题-程序员宅基地
文章浏览阅读696次。- JS方法 -就是一小段JS加到页面中就可以,下面把这段代码贴出来:1 jQuery(document).ready(function () { 2 jQuery("body").attr("style","overflow-x:hidden"); 3 });- CSS方法 -一、防止图片撑破DIV方法一原始处..._图片超过屏幕高度出现滑轮怎么办
js 银行卡每四位加空格正则表达式_银行账号允许空格正则-程序员宅基地
文章浏览阅读1.6k次。参考链接:https://blog.csdn.net/java_warplane/article/details/77769346<input name="" id="" value=""/><script>// 16位或者19位银行卡号var reg = /^(\d{16}|\d{19})$/;$("input").blur(function(){..._银行账号允许空格正则