如何用人工智能自动玩游戏_ai玩游戏-程序员宅基地
技术标签: 机器学习散文 # Python小案例 Python
如何用人工智能自动玩游戏
一、前言
让AI玩游戏的思想早在上世纪就已经有了,那个时候更偏向棋类游戏。像是五子棋、象棋等。在上世纪“深蓝”就击败了国际象棋冠军,而到2016年“Alpha Go”击败了人类围棋冠军。
到现在,AI涉略的不仅仅是棋类游戏。像是超级马里奥、王者荣耀这种游戏,AI也能有比较好的表现。今天我们就来用一个实际的例子讨论AI自动玩游戏这一话题,本文会用非常简单的机器学习算法让AI自动玩Google小恐龙游戏。
二、Google小恐龙与监督学习
2.1、Google小恐龙
如果你使用的是Chrome浏览器,那么相信你应该见过下面这个恐龙:

当我们用Chrome断网访问网页时,就会显示这个恐龙,或者直接在地址栏输入:chrome://dino直接访问该游戏。
游戏的玩法非常简单,只需要按空格键即可。比如下面左图,快碰到障碍物,这时需要按空格,而下面右图没有障碍(或离障碍比较远),则不需要按按键。
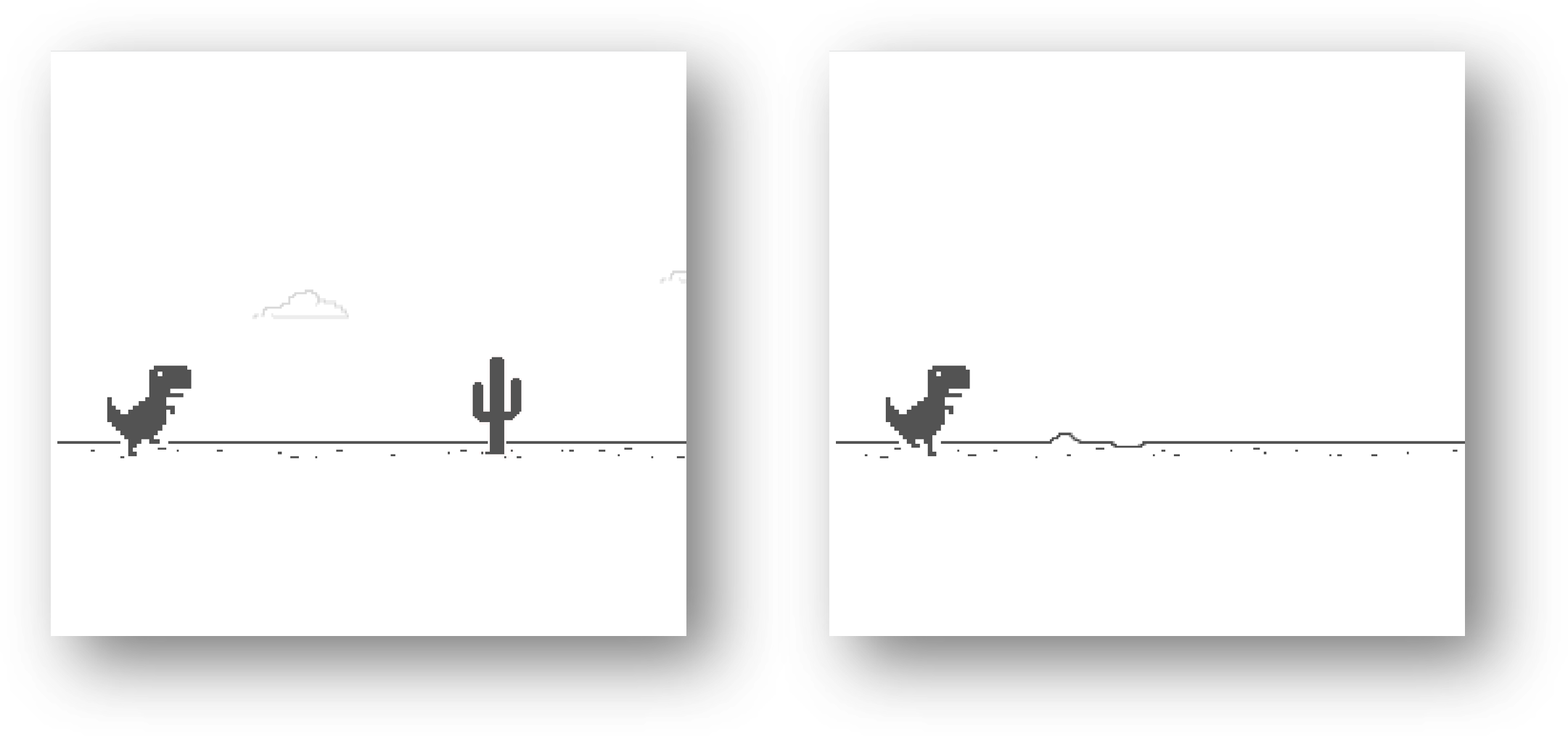
当然还有出现鸟的情况,我们也可以归为跳的情况。大家可以玩一下。
2.2、监督学习
玩游戏很多时候会使用一个叫强化学习的方式来实现,而本文使用比较简单的监督学习来实现。
本文会使用逻辑回归算法实现,其代码如下:
from sklearn.linear_model import LogisticRegression # 逻辑回归模型
from sklearn.model_selection import train_test_split # 数据集拆分
# 1、准备数据
X = [
# 天河区的坐标
[1, 1],
[1, 2],
[2, 0],
[3, 2],
[3, 3],
# 花都区的坐标
[7, 7],
[6, 7],
[7, 6],
[8, 6],
[8, 5]
]
y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# 2、拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 3、定义模型
model = LogisticRegression()
# 4、填充数据并训练
model.fit(X_train, y_train)
# 5、评估模型
score1 = model.score(X_train, y_train)
score2 = model.score(X_test, y_test)
print(score1, score2)
# 6、预测
input = [
[4, 4]
]
pred = model.predict(input)
print(pred)
关于逻辑回归的讲解可以查看:Python快速构建神经网络
。
我们可以把玩游戏看作一个分类问题,即输入为当前游戏的图像,输出为0、1的一个二分类问题(0表示跳,1表示不跳)。要让AI实现自动玩游戏,我们需要做几件事情。分别如下:
- 玩游戏,收集一些需要跳的图片和一些不需要条的图片
- 选择合适的分类算法,训练一个模型
- 截取当前游戏画面,预测结果,判断是否需要跳跃
- 如果需要跳跃,则用程序控制键盘,按下跳跃键
下面我们来依次完成上面的事情。
三、收集数据
收集数据我们需要在玩游戏的过程中不停地截图,这里可以用Pillow模块来实现截图。Pillow模块需要单独安装,安装语句如下:
pip install pillow
截图的代码如下:
import time
from PIL import ImageGrab # 截图
time.sleep(3)
while True:
# 截图
img = ImageGrab.grab()
# print(img.size) # 960 540 480 270
img = img.resize((960, 540))
# 保存图片
img.save(f'imgs/{
str(time.time())}.jpg')
# 修改name
time.sleep(0.1)
运行程序后就可以切换到Chrome开始游戏了。进行一段时间后,我们会截取一些图片,大致如下:

这时就轮到人类智能上场了,我们手动的把我们决定需要跳的场景放置到imgs/jump目录下,把觉得不需要跳的场景放到imgs/none目录下。然后就可以进行下一步了,这里截取的图片通常不需要跳的要多很多,所有可以多收集几次。
收集完成后我们就可以把图片读入,并转换成一个1维数组,这部分代码如下:
import os
import cv2
# 所有图片的全路径
files = [os.path.join(jump_path, jump) for jump in os.listdir(jump_path)] + \
[os.path.join(none_path, none) for none in os.listdir(none_path)]
X = []
y = [0] * len(os.listdir(jump_path)) + [1] * len(os.listdir(none_path))
# 遍历jump目录下的图片
for idx, file in enumerate(files):
filepath = os.path.join(none_path, file)
x = cv2.imread(filepath, 0).reshape(-1)
X.append(x)
此时X和y就是我们的特征和目标了。有了X和y就可以开始训练模型了。
四、训练分类模型
训练部分的代码非常简单,我们可以在训练完成后保存模型。代码如下:
import os
import cv2
import joblib
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
jump_path = os.path.join('imgs', 'jump') # 需要跳的图片的根目录
none_path = os.path.join('imgs', 'none') # 不需要跳的图片的根目录
# 所有图片的全路径
files = [os.path.join(jump_path, jump) for jump in os.listdir(jump_path)] + \
[os.path.join(none_path, none) for none in os.listdir(none_path)]
X = []
y = [0] * len(os.listdir(jump_path)) + [1] * len(os.listdir(none_path))
# 遍历jump目录下的图片
for file in files:
x = cv2.imread(file, 0).reshape(-1)
X.append(x)
# 2、拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
# 3、定义模型
model = LogisticRegression(max_iter=500)
# 4、训练模型
model.fit(X_train, y_train)
# 5、评估模型
train_score = model.score(X_train, y_train)
test_score = model.score(X_test, y_test)
print(train_score, test_score)
# 保存模型
joblib.dump(model, 'auto_play.m')
在我电脑上训练的准确率在90%以上,总体效果还是不错的。不过有几个可以改进的地方。这里说几点:
- 图像只有中间部分会对下一步操作有影响,因此可以选择对训练图片进行一些处理。把上面和下面部分设置为0。如果做了这个处理,那么在实际应用时也要做同样的处理。
- 这些图片如果移植到其它电脑可能不适用,因为分辨率等原因。所有可以选择使用更复杂的模型,比如CNN网络。
- 因为手动收集数据比较麻烦,可以选择做一下数据增强。
在这里我们不做这些改进,直接使用最简单的模型。
五、自动玩游戏
自动玩游戏需要借助pynput模块来实现,其安装如下:
pip install pynput
我们可以用下面的代码实现按下键盘的空格键:
from pynput import keyboard
from pynput.keyboard import Key
# 创建键盘
kb = keyboard.Controller()
# 按下空格键
kb.press(Key.space)
知道了如何控制键盘后,我们就可以使用模型截取预测,如何判断是否要按空格,代码如下:
import time
import cv2
import joblib
import numpy as np
from PIL import ImageGrab
from pynput import keyboard
from pynput.keyboard import Key
time.sleep(3)
# 0、创建键盘
kb = keyboard.Controller()
# 1、加载模型
model = joblib.load('auto_play.m')
while True:
# 2、准备数据
ImageGrab.grab().resize((960, 540)).save('current.jpg') # 保存当前屏幕截屏
x = cv2.imread('current.jpg', 0).reshape(-1)
x = [x]
# 3、预测
pred = model.predict(x)
print(pred)
# 如果需要跳,则按下空格
if pred[0] == 0:
kb.press(Key.space)
运行上面的程序后,打开浏览器即可开始游戏。程序的代码和图片文件:https://download.csdn.net/download/ZackSock/86543410
GitHub地址为:https://github.com/IronSpiderMan/AutoPlayGoogleDino
智能推荐
从零开始搭建自己的vue组件库——01创建_vue构建自己的组件库-程序员宅基地
文章浏览阅读1.5k次。从零开始搭建自己的vue组件库——01创建引言项目创建修改目录结构添加第一个组件以及样式文件夹引言因工作需要,要打造一套属于自己团队的组件库,本人也是第一次接到这种任务,虽然不着急,但是之前从来没做过,因此特意再此记录下过程,也希望自己能坚持下去,当然,过程中少不了查阅各种资料,也会再次记录下各种各样的问题,本组件库的开发基于vue2.0,主要用于pc端,会参考element-ui进行开发项目创建首先第一步是要创建一个vue工程vue create xxxx创建具体流程在这里不再详细说明,创建完_vue构建自己的组件库
数学建模系列-优化模型---(四)神经网络模型-程序员宅基地
文章浏览阅读1.3k次。神经网络在优化中的应用:万能的模型+误差修正函数“,每次根据训练得到的结果与预想结果进行误差分析,进而修改权值和阈值,一步一步得到能输出和预想结果一致的模型。举一个例子:比如某厂商生产一种产品,投放到市场之后得到了消费者的反馈,根据消费者的反馈,厂商对产品进一步升级,优化,从而生产出让消费者更满意的产品。这就是BP神经网络的核心。BP神经网络是一种按误差反向传播(简称误差反传)训练的多层前馈网络,其算法称为BP算法,它的基本思想是梯度下降法,利用梯度搜索技术,以期使网络的实际输出值和期望输出值的误差均方
android设计模式二十三式(六)——适配器模式(Adapter)_android 适配器adapter相当于service层次吗吗-程序员宅基地
文章浏览阅读282次。适配器模式我们先讲适配器模式,后面的装饰器模式,代理模式,外观模式,桥接模式,组合模式,享元模式,都是依赖于适配器模式中的对象的适配器模式为起源的。适配器模式,简单来讲,就是某个类的接口和另一个接口不匹配,将某个类的接口转换成客户端期望的另一个接口表示。目的是消除由于接口不匹配所造成的类的兼容性问题。1.类的适配器模式我们还是模拟一个场景,市电都是220V的交流电,但是手机充电是5..._android 适配器adapter相当于service层次吗吗
#PCIE# pcie总线的两种复位方式_pcie flr复位使用方法-程序员宅基地
文章浏览阅读3.3k次。本篇主要介绍PCIe总线的复位方式。PCIe总线规定了两个复位方式:Conventional Reset和FLR(Function Level Reset),而Conventional Reset又可以进一步分为两大类:Fundamental Reset和Non-Fundamental Reset。Fundamental Reset方式包括Cold和WarmReset方式,可以将PCIe将设备中的绝大多数内部寄存器和内部状态都恢复成初始值;而Non-FundamentalReset方式为Hot Res._pcie flr复位使用方法
基于STM32的仓库环境监测系统的毕业设计_基于stm32智能仓库管理 开源-程序员宅基地
文章浏览阅读814次,点赞21次,收藏13次。一、引言随着物流行业的快速发展,仓库管理对于整个供应链的顺畅运转起着至关重要的作用。为了确保仓库内的货物和设施安全,设计一个高效、智能的仓库环境监测系统显得尤为重要。本毕业设计旨在开发一个基于STM32的仓库环境监测系统,以实现对仓库内温度、湿度、空气质量等环境参数的实时监测,并通过WiFi模块将数据上传到APP,同时可在APP上控制仓库内的设备。二、系统架构设计本系统主要由传感器节点、数据传输模块、数据存储与处理模块以及用户界面模块四个部分组成。三、硬件设计。_基于stm32智能仓库管理 开源
python3 通过百度地图API获取城市POI点并存于CSV格式_百度怎么爬取poi数据并写入csv文件-程序员宅基地
文章浏览阅读2.2k次,点赞3次,收藏11次。原文信息:作者:WenWu_Both 出处:http://blog.csdn.net/wenwu_both/article/ 版权:本文版权归作者和程序员宅基地共有 转载:欢迎转载,但未经作者同意,必须保留此段声明;必须在文章中给出原文链接;否则必究法律责任话不多说,由于兴趣,需要一些POI点的位置信息,于是找到了这篇博客,因为原作是基于python2.写的,出于python2.和p..._百度怎么爬取poi数据并写入csv文件
随便推点
Twitter 应用的优缺点分析_tiwwer软件亮点-程序员宅基地
文章浏览阅读649次。总的来说,Twitter是一种强大的社交媒体工具,它有着许多优点,比如实时信息更新、广泛的观众和社区参与度高。用户可以实时获取和发布信息,无论是新闻、活动更新、产品发布,甚至是天气预报,这些都可以在Twitter上即时发布。限制的表达方式:Twitter的推文长度有限制(目前是280个字符),这限制了用户的表达方式。隐私问题:尽管Twitter提供了一些隐私设置,但用户的推文和信息仍然可能被大量的人看到。信息过载:由于Twitter上信息更新的速度非常快,用户可能会感到信息过载。_tiwwer软件亮点
mysql的索引结构_insert into userweight(jdate,name,height,weight)va-程序员宅基地
文章浏览阅读421次。前言Hello我又来了,快年底了,作为一个有抱负的码农,我想给自己攒一个年终总结。自上上篇写了手动搭建Redis集群和MySQL主从同步(非Docker)和上篇写了动手实现MySQL读写分离and故障转移之后,索性这次把数据库中最核心的也是最难搞懂的内容,也就是索引,分享给大家。这篇博客我会谈谈对于索引结构我自己的看法,以及分享如何从零开始一层一层向上最终理解索引结构。从一个简单的..._insert into userweight(jdate,name,height,weight)values(?,?,?,?)
【转载】人工智能Ai画画——stable diffusion 原理和使用方法详解!_stable diffusion 训练 ai画画-程序员宅基地
文章浏览阅读63次。简单来说Stable Diffusion是一个文本到图像的潜在扩散模型,由CompVis、Stability AI和LAION的研究人员和工程师创建。它使用来自LAION-5B数据库子集的512x512图像进行训练。使用这个模型,可以生成包括人脸在内的任何图像,因为有开源的预训练模型,所以我们也可以在自己的机器上运行它。****_stable diffusion 训练 ai画画
微软疯狂之举,25亿天价收购Mojang是否值得?_mojang 股票-程序员宅基地
文章浏览阅读1.1k次。微软最近宣布,它打算以25亿美金收购Minecraft的Mojang,然而这样天价的数字收购意思到底在哪儿?Xsolla今天带来一手海外专业人士对其收购做出的分析,与大家分享。丹·皮尔森首先, 收购问题的标准是价格吗?难道这笔交易对于双方都具有战略意义?再就是具体到本次收购的一些问题。微软将如何打破甚至拨出25亿的收购,到2015年六月底?它在哪里可以采取特_mojang 股票
架构师必知必会系列:容器编排与调度-程序员宅基地
文章浏览阅读1.6k次。容器编排与调度是当前云计算发展的热点方向之一。Kubernetes、Mesos、Docker Swarm等开源框架已经成为众多公司和组织选择容器编排工具的基础设施层级,通过编排技术,可以实现集群管理自动化,资源利用率提高,灵活应对业务变化,快速响应用户需求等诸多优势。本系列文章将系统地介绍Kubernetes中常用的容器编排组件及其工作原理。希望能够给需要学习和掌握容器编排技术的读者提供有价值的参考信息。Kubernetes集群中包含多个节点和资源,不同节点上的Pod需要运行在不同的物理机或虚拟机上。
flask中web表单的实现_flask中html中的表单实现-程序员宅基地
文章浏览阅读738次。web表单是web应用程序的基本功能。它是HTML页面中负责数据采集的部件。表单有三个部分组成:表单标签、表单域、表单按钮。表单允许用户输入数据,负责HTML页面数据采集,通过表单将用户输入的数据提交给服务器。在Flask中,为了处理web表单,我们一般使用Flask-WTF扩展,它封装了WTForms,并且它有验证表单数据的功能。WTForms中支持的HTML标准字段 ..._flask中html中的表单实现