基于空洞卷积DCNN与长短期时间记忆模型LSTM的dcnn-lstm的回归预测模型-程序员宅基地
周末的时候有时间鼓捣的一个小实践,主要就是做的多因子回归预测的任务,关于时序数据建模和回归预测建模我的专栏和系列博文里面已经有了非常详细的介绍了,这里就不再多加赘述了,这里主要是一个模型融合的实践,这里的数据是仿真生成的领域数据集,典型的表格型数据集,首先看下数据样例:
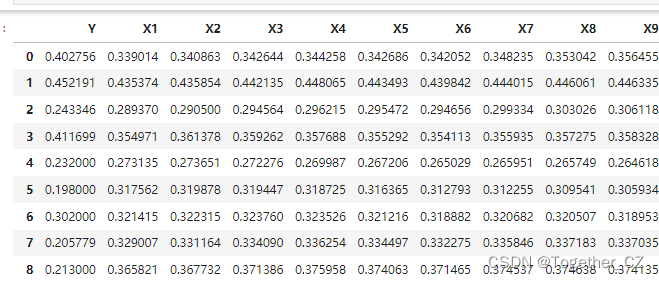
基础的数据处理实现如所示:
import pandas as pd
# 读取 "data" 工作表的内容
sheet_name = "data"
data = pd.read_excel("dataset.xlsx", sheet_name=sheet_name)
# 删除第一列日期列
data1= data.iloc[:, 1:]
print(data1.head(20))接下来随机划分数据集,实现如下所示:
from sklearn.model_selection import train_test_split
X = data.drop(columns=['Y']) # 这将删除名为'label'的列,并返回其余部分
y = data['Y']
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)接下来对数据进行归一化处理计算,如下所示:
# 创建特征标准化的对象
scaler = StandardScaler() # 或者使用 MinMaxScaler() 来进行 Min-Max 缩放
# 训练标准化对象并转换训练特征
x_train_scaled = scaler.fit_transform(x_train)
# 假设你有测试数据 x_test 和 y_test,对测试特征进行相同的变换
x_test_scaled = scaler.transform(x_test)
# 输出尺寸
print("训练特征(标准化后)的尺寸:", x_train_scaled.shape)
print("测试特征(标准化后)的尺寸:", x_test_scaled.shape)
print("特征列(x_train)的尺寸:", x_train.shape)
print("标签列(y_train)的尺寸:", y_train.shape)
print("特征列(x_test)的尺寸:", x_test.shape)
print("标签列(y_test)的尺寸:", y_test.shape)接下来是数据转化处理:
def reshape_to_window(data, window=window):
"""
数据转化
"""
n = data.shape[0]
m = data.shape[1]
result = np.zeros((n - window + 1, window, m))
for i in range(n - window + 1):
result[i] = data[i:i+window]
return result
x_train = reshape_to_window(x_train, window)
y_train = y_train.iloc[window-1:]
x_test = reshape_to_window(x_test, window)
y_test = y_test.iloc[window-1:]
print("新的x_train形状:", x_train .shape )
print("新的y_train形状:", y_train .shape)
print("新的x_test形状:", x_test.shape)
print("新的y_test形状:", y_test.shape)接下来基于keras框架初始化搭建模型,这里模型部分主要是运用了DCNN和LSTM,对其进行融合。首先来整体回归下DCNN和LSTM:
DCNN
空洞卷积(dilated convolution)是一种卷积神经网络(Convolutional Neural Network, CNN)中的卷积操作,它通过在卷积核上添加空洞(dilation)来扩展感受野(receptive field),从而提高模型的鲁棒性和泛化能力。
在传统的卷积操作中,卷积核只能覆盖一小部分特征图,但是通过在卷积核上添加空洞,可以让卷积核在相邻的特征图之间滑动,从而扩展了卷积核的感受野,增强了模型的表达能力。空洞卷积的基本原理是将传统卷积操作的滑动步长(stride)设置为1,然后将卷积核的大小(kernel size)除以2,使得卷积核中心点能够与特征图上任意位置的像素进行卷积运算。
在空洞卷积中,每个卷积层都具有不同数量的空洞率(dilation rate),表示在每个卷积层中添加的空洞数量。空洞率越高,则卷积核的感受野越大,能够提取更多的特征信息。但是,空洞率过高会导致特征图变得稀疏,难以捕捉到细节信息。因此,在空洞卷积中需要权衡空洞率和特征图的稀疏性。
空洞卷积在深度卷积神经网络中可以应用于多个任务,例如图像分类、目标检测、语义分割等。相比于传统的卷积操作,空洞卷积能够提高模型的鲁棒性和泛化能力,同时减少计算量和参数数量,使得模型更加轻量级和高效。
LSTM
LSTM(Long Short-Term Memory)是一种循环神经网络(RNN)的变体,特别适用于处理序列数据。相较于传统的RNN,LSTM在处理时间序列数据时具有更好的性能和稳定性。
LSTM由遗忘门(forget gate)、输入门(input gate)、输出门(output gate)和存储单元(cell state)组成。遗忘门决定了前一时刻的记忆状态中哪些信息应该被遗忘,输入门决定了当前输入的信息中哪些应该被用于计算输出,输出门决定了当前时刻的输出,而存储单元则用于存储和输出当前时刻的记忆状态。
LSTM的核心思想是通过遗忘门和输入门来控制信息的流动,从而在长期依赖和短期依赖之间取得平衡。遗忘门和输入门都是由sigmoid函数和线性层组成的,而输出门则是由sigmoid函数、线性层和ReLU函数组成的。这些门控制了信息的流动方向和强度,使得LSTM能够处理长期依赖关系。
除了LSTM之外,还有GRU(Gated Recurrent Unit)和SRU(Simple Recurrent Unit)等循环神经网络变体,它们在结构和性能上与LSTM类似。LSTM在自然语言处理、语音识别、图像处理等领域都有广泛的应用。
模型部分代码实现如下所示:
from tensorflow.keras import backend as K
# # 输入参数
input_size = 176 # 你的输入尺寸
lstm_units =16# 你的LSTM单元数
dropout = 0.01 # 你的dropout率
# 定义模型结构
inputs = Input(shape=(window, input_size))
# 第一层空洞卷积
model = Conv1D(filters=lstm_units, kernel_size=1, dilation_rate=1, activation='relu')(inputs)
# model = MaxPooling1D(pool_size=1)(model)
# model = Dropout(dropout)(model)
# 第二层空洞卷积
model = Conv1D(filters=lstm_units, kernel_size=1, dilation_rate=2, activation='relu')(model)
# model = MaxPooling1D(pool_size=1)(model)
# 第三层空洞卷积
model = Conv1D(filters=lstm_units, kernel_size=1, dilation_rate=4, activation='relu')(model)
# model = MaxPooling1D(pool_size=1)(model)
# model = BatchNormalization()(model)
# LSTM层
model = LSTM(lstm_units, return_sequences=False)(model)
# 输出层
outputs = Dense(1)(model)
# 创建和编译模型
model = Model(inputs=inputs, outputs=outputs)
model.compile(loss='mse', optimizer='adam', metrics=['mse'])
model.summary()摘要输出如下所示:
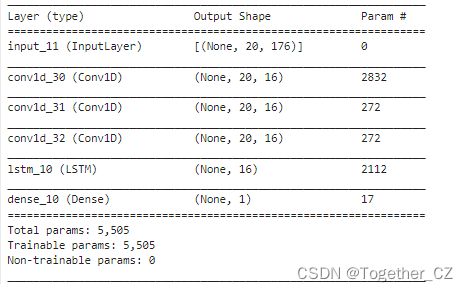
接下来就可以启动模型训练,日志输出如下所示:
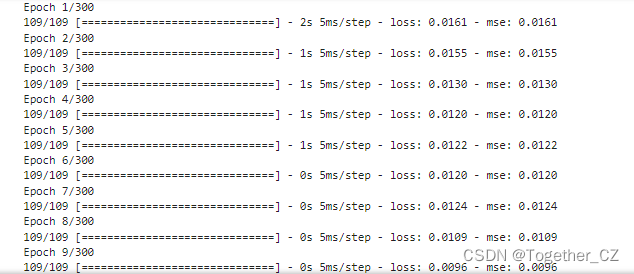
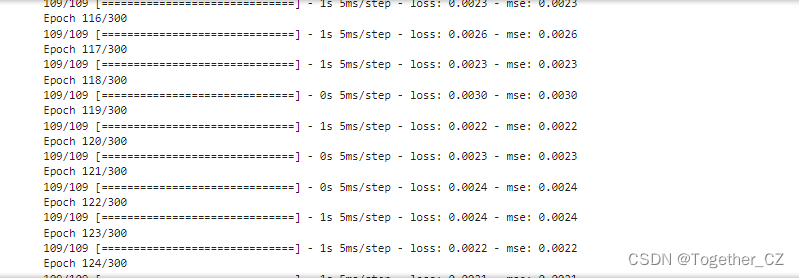
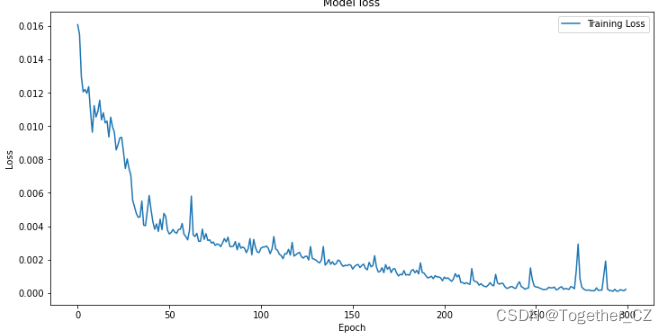
接下来对模型整体训练过程中的loss进行可视化,如下所示:
plt.figure(figsize=(12, 6))
plt.plot(history.history['loss'], label='Training Loss')
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(loc='upper right')
plt.show()结果如下所示:
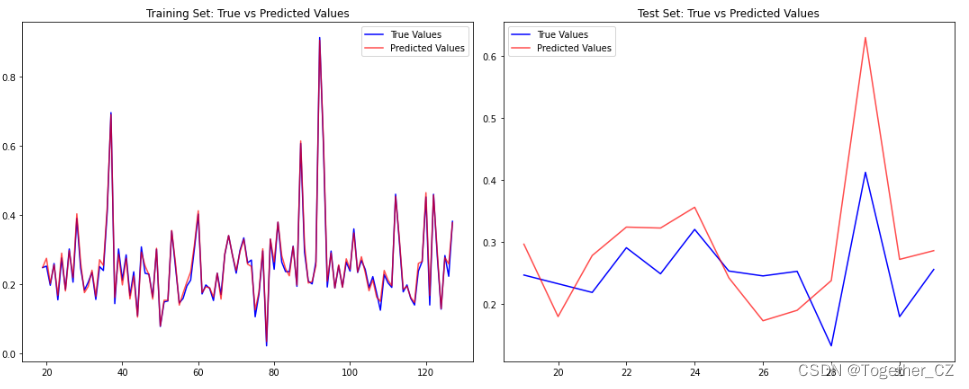
接下来对测试集进行预测对比分析,如下所示:
explained_variance_score:解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因变量
的方差变化,值越小则说明效果越差。
mean_absolute_error:平均绝对误差(Mean Absolute Error,MAE),用于评估预测结果和真实数据集的接近程度的程度
,其其值越小说明拟合效果越好。
mean_squared_error:均方差(Mean squared error,MSE),该指标计算的是拟合数据和原始数据对应样本点的误差的
平方和的均值,其值越小说明拟合效果越好。
r2_score:判定系数,其含义是也是解释回归模型的方差得分,其值取值范围是[0,1],越接近于1说明自变量越能解释因
变量的方差变化,值越小则说明效果越差。
基于回归模型评测指标对模型进行评估计算,核心代码实现如下所示:
#!usr/bin/env python
#encoding:utf-8
from __future__ import division
'''
__Author__:沂水寒城
功能:计算回归分析模型中常用的四大评价指标
'''
from sklearn.metrics import explained_variance_score, mean_absolute_error, mean_squared_error, r2_score
def calPerformance(y_true,y_pred):
'''
模型效果指标评估
y_true:真实的数据值
y_pred:回归模型预测的数据值
'''
model_metrics_name=[explained_variance_score, mean_absolute_error, mean_squared_error, r2_score]
tmp_list=[]
for one in model_metrics_name:
tmp_score=one(y_true,y_pred)
tmp_list.append(tmp_score)
print ['explained_variance_score','mean_absolute_error','mean_squared_error','r2_score']
print tmp_list
return tmp_list
def mape(y_true, y_pred):
return np.mean(np.abs((y_pred - y_true) / y_true)) * 100
from sklearn.metrics import r2_score
RMSE = mean_squared_error(y_train_predict, y_train)**0.5
print('训练集上的/RMSE/MAE/MSE/MAPE/R^2')
print(RMSE)
print(mean_absolute_error(y_train_predict, y_train))
print(mean_squared_error(y_train_predict, y_train) )
print(mape(y_train_predict, y_train) )
print(r2_score(y_train_predict, y_train) )
RMSE2 = mean_squared_error(y_test_predict, y_test)**0.5
print('测试集上的/RMSE/MAE/MSE/MAPE/R^2')
print(RMSE2)
print(mean_absolute_error(y_test_predict, y_test))
print(mean_squared_error(y_test_predict, y_test))
print(mape(y_test_predict, y_test))
print(r2_score(y_test_predict, y_test))
结果输出如下所示:
训练集上的/RMSE/MAE/MSE/MAPE/R^2
0.011460134959888058
0.00918032687965506
0.00013133469329884847
4.304916429848429
0.9907179432442654
测试集上的/RMSE/MAE/MSE/MAPE/R^2
0.08477191056357428
0.06885029105374023
0.007186276820598636
24.05688263657184
0.4264760739398442关于回归建模相关的内容感兴趣的话可以参考我前面的文章:
智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数