AI算法工程师 | 01人工智能基础-快速入门_人工智能算法-程序员宅基地
文章目录
一、我们身处人工智能的时代
人工智能的时代
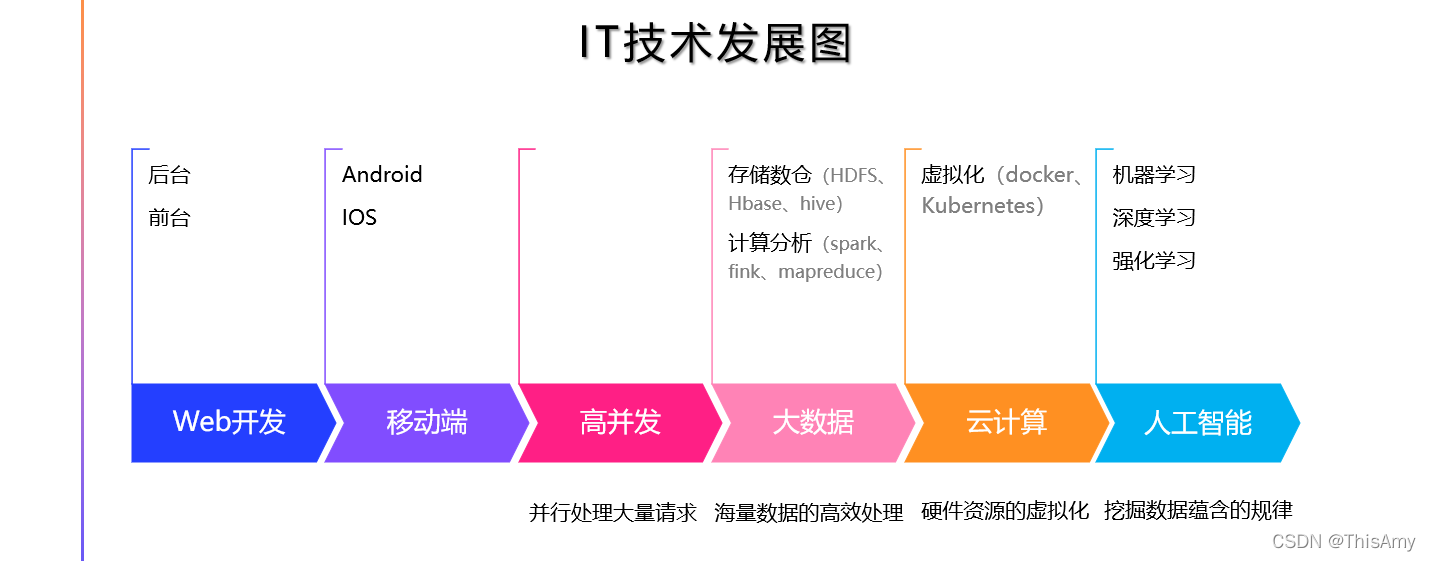
互联网时代的发展
站在互联网的角度理解人工智能:人工智能AI(artificial intelligence)是互联网时代发展的必然趋势。
人们从早期做web开发,到移动端的开发;之后随着数据量的增大,人们开始研究高并发的问题;当数据量不断的增大,而人们希望数据不被浪费时,产生了大数据的技术,包括:大数据的如何存储以及大量数据的如何计算分析;由于计算分析和存储需要资源,互联网便发展到通过云计算进行存储与计算,包括虚拟化的计算,如:docker,k8s;再到后来,人们不是仅仅局限于将数据进行存储和简单分析,更多的是想从数据中挖掘出价值,人们便想到了人工智能,因为人工智能中有很多的算法,可以帮助人们从数据中挖掘出价值。
注意,区分大数据和人工智能的概念:
① 大数据:专注于已有的数据的存储和计算,生成分析报表;
② 人工智能:专注于利用已有数据挖掘规律,对未来进行预测。
人工智能领域的技术
在人工智能领域中,其技术的发展具体有如下内容:
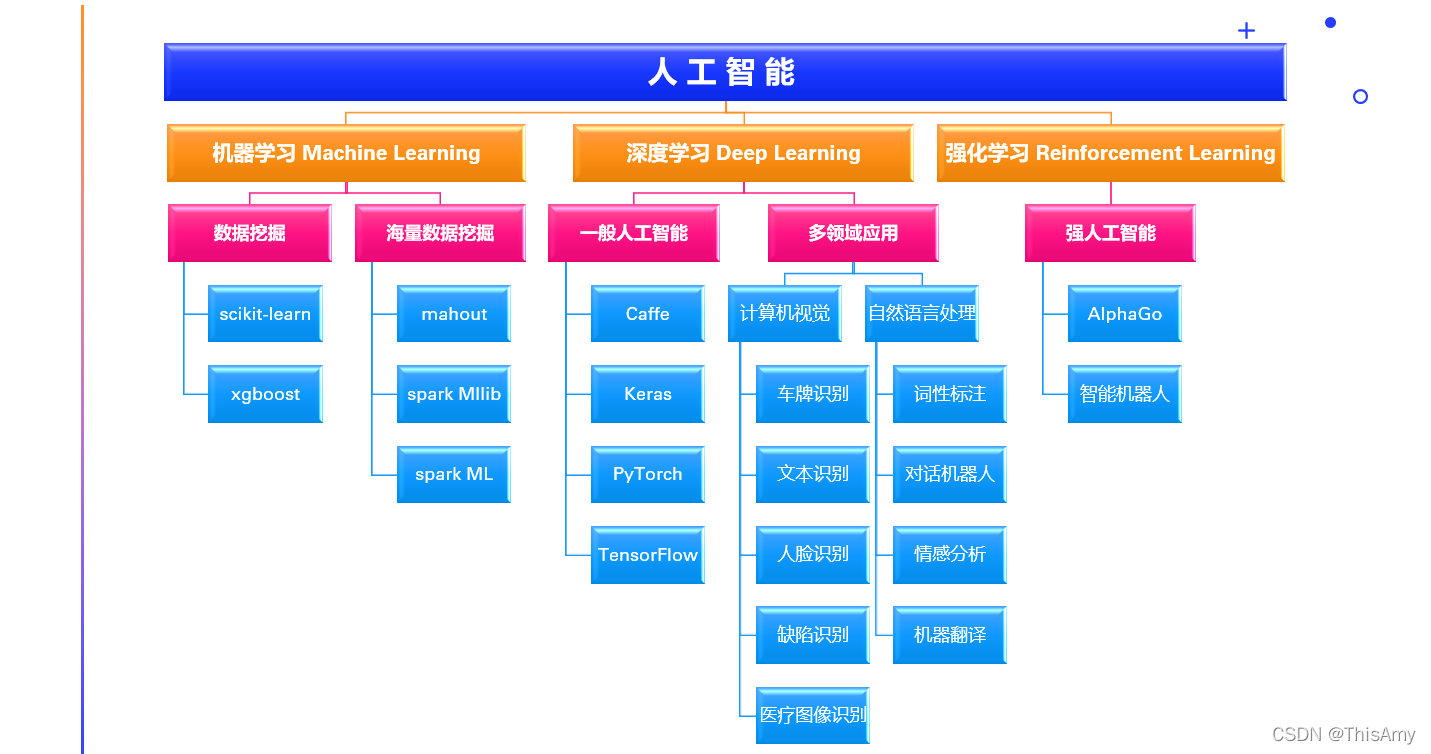
人工智能从早期的使用机器学习的算法来做数据挖掘,到分布式的进行数据挖掘;再到进一步的把算法研究得更加深入,走向了深度学习的领域,于是人们开始发现深度学习可以使更加复杂的问题(如:计算机视觉、自然语言处理)变得更加的准确,于是有了各种各样的应用;在人工智能发展过程中还存在强化学习,比如:利用强化学习的技术,在前几年有AlphaGo这样下围棋的机器人,近几年有各种各样的智能制造中使用到的机器人。这些都是应用人工智能产生的一些产业。
所以,人工智能是现在互联网中发展的一个大的趋势:如何更好的利用数据去挖掘数据中的价值,把挖掘到的数据的价值(规律)进行更好的应用,并对各行各业加以帮助。
人工智能的应用
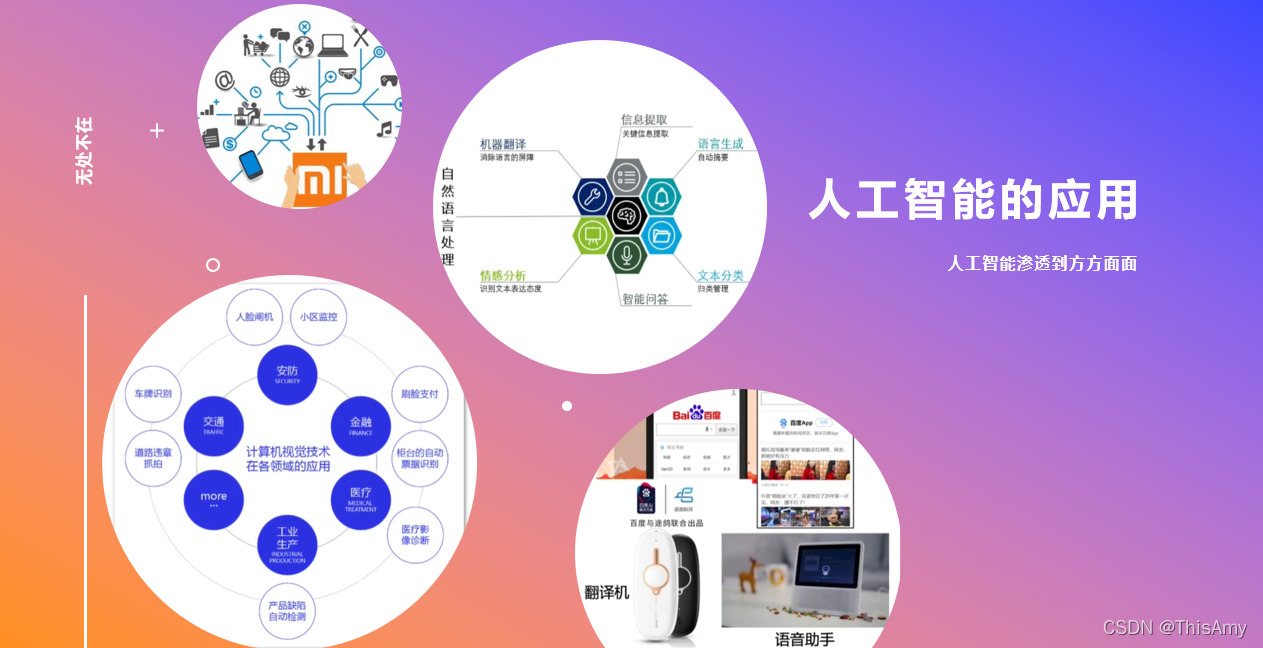
人工智能已经逐步渗透到生产生活中的方方面面,无论是医疗、教育、交通、物流,还是传统生产制造、金融、农业设置是军事、游戏,人工智能的身影无处不在,并发挥着越来越重要的作用。


二、人工智能的流程和基本概念
人工智能常见流程
人工智能是拟人
灵魂三连问:
- 为什么说 “人工智能是拟人” ?因为人工智能的流程与思考的过程非常相像。
- 如何看现在的人工智能做得有多好?其越像人的思考过程,越和人的准确率接近,则该人工智能做得越好。
- 怎么理解人工智能是 “拟人” 这两个字?且看下文讲解 ↓↓↓
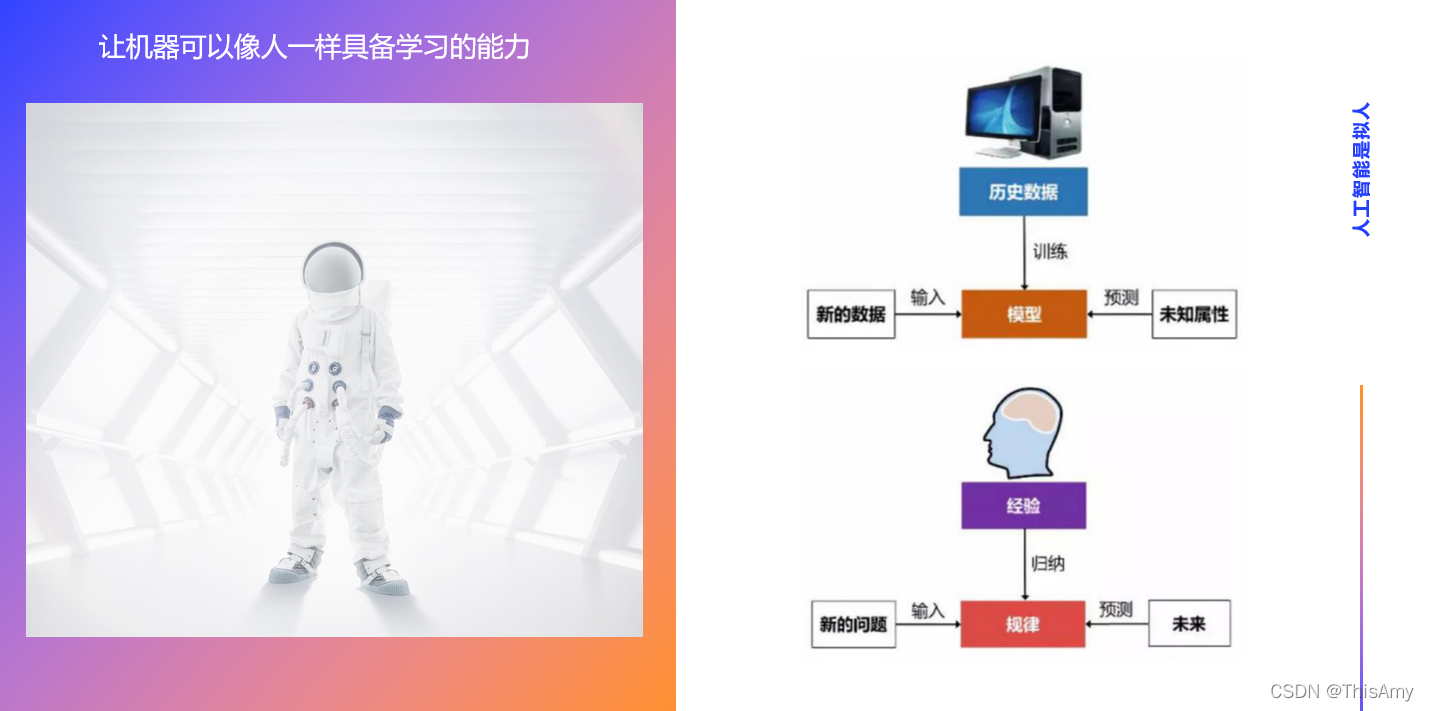
首先,需要理解的是何为人工智能?通俗来讲,人工智能就是让机器像人一样具备学习的能力。
其次,人工智能 AI 包含三大块内容,分别是:机器学习 ML(Machine Learning)、深度学习 DL(Deep Learning)、强化学习 RL(Reinforcement Learning)。
在早期的人工智能,人们会称为机器学习,是一些经典机器学习算法的统称。关于 “机器学习” ,可以用 “让机器像人一样具备学习的能力” 这句话来解释。但如何让机器像人一样具备学习的能力,做到人工智能呢?这需要先了解人类的思考过程。
- 人类的思考过程:人的大脑根据生活中的经验,归纳和总结出相对应的规律。这些规律可以使人们未来碰到新的问题时,能够将新的问题代入到脑海中,根据已有的规律来思考——当未来碰到该新问题时,应该给出什么样的预测结果,需进行怎样的决策。
- 人工智能流程对比人类思考的过程:
- 对于机器,它的大脑是计算能力(如CPU和内存,这些帮助机器来计算的,实际上就是它的大脑),而历史数据相当于人类的经验;
- 将数据交给计算机进行训练,训练的过程相当于像人一样归纳和总结相对应的规律;
- 在人工智能中,这些规律就是模型;
- 未来出现新的问题,即碰到新的数据,将新的数据代入到模型中去预测未知的属性,得到的结果便是预测值。
从中可以发现:这种对已有的数据进行训练得出某种模型,利用此模型预测结果的这一过程,与人类的思考过程非常类似。
人工智能的流程与本质
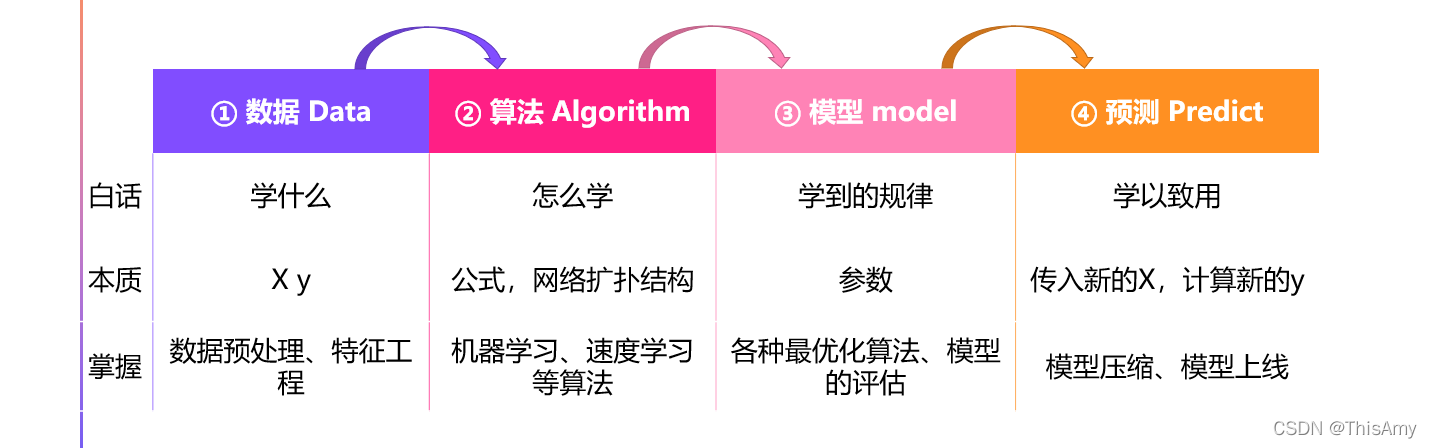
人工智能的流程:把数据代入到算法中,生成对应的模型,最终把模型上线,来进行预测。(即:数据预处理 → 算法求解 → 模型评估 → 模型上线)
人工智能的本质:把X、y代入公式中计算出参数(解方程组算出参数),当未来有新的X时,将其代入公式中得到预测的y(ŷ,叫做y hat)。
怎么才能猜的更准?“数据为王” 的思想。若拿到的历史数据,其数据质量越高,数据量越大,得到的参数就越可靠,于是通过该参数算出的值会越准确。
做工人智能的目的是——做预测;目标为——生成模型,而想要生成模型,需要数据和算法。
因此,对于人工智能来说,为了得到更好的模型结果,要不就是改算法(公式),要不就是找到更多等好的数据。
算法工程师:
① 核心任务是生成可以预测准确的模型
② 具备相关的代码能力
人工智能基本概念与区别
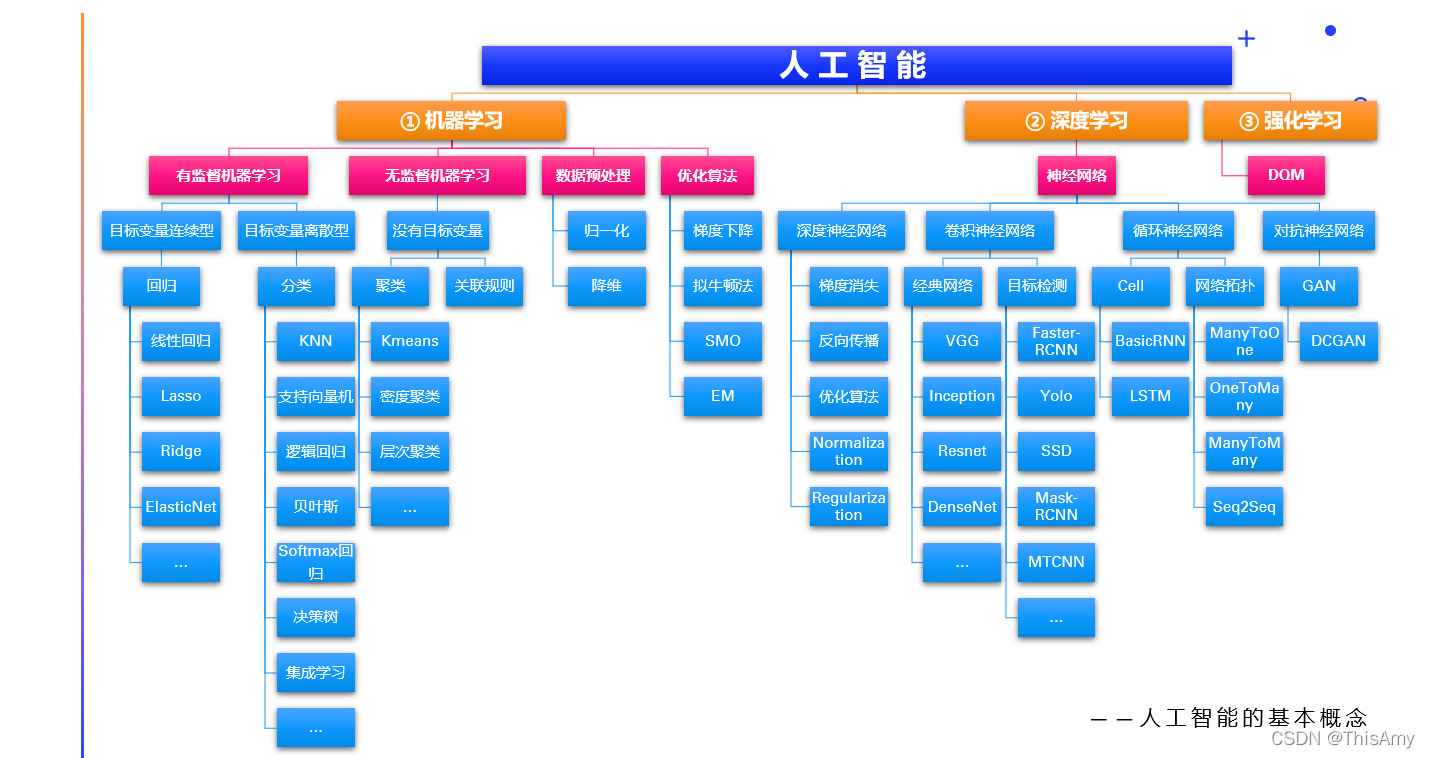
深度学习以前是机器学习的分支,因为深度学习是基于神经网络算法衍生出来的,由于近些年发展的很快,所有往往单独拎出来成为一门学科。
强化学习以前也只是机器学习的分支,随着现在深度强化学习(深度学习结合强化学习)的流行,也成为了一门学科,强化学习将来有望成为人工智能未来的明星。
机器学习不同的学习方式
人工智能中的核心是机器学习(Machine Learning,ML)。其原因是:机器学习研究的是各种各样的算法,算法是核心。
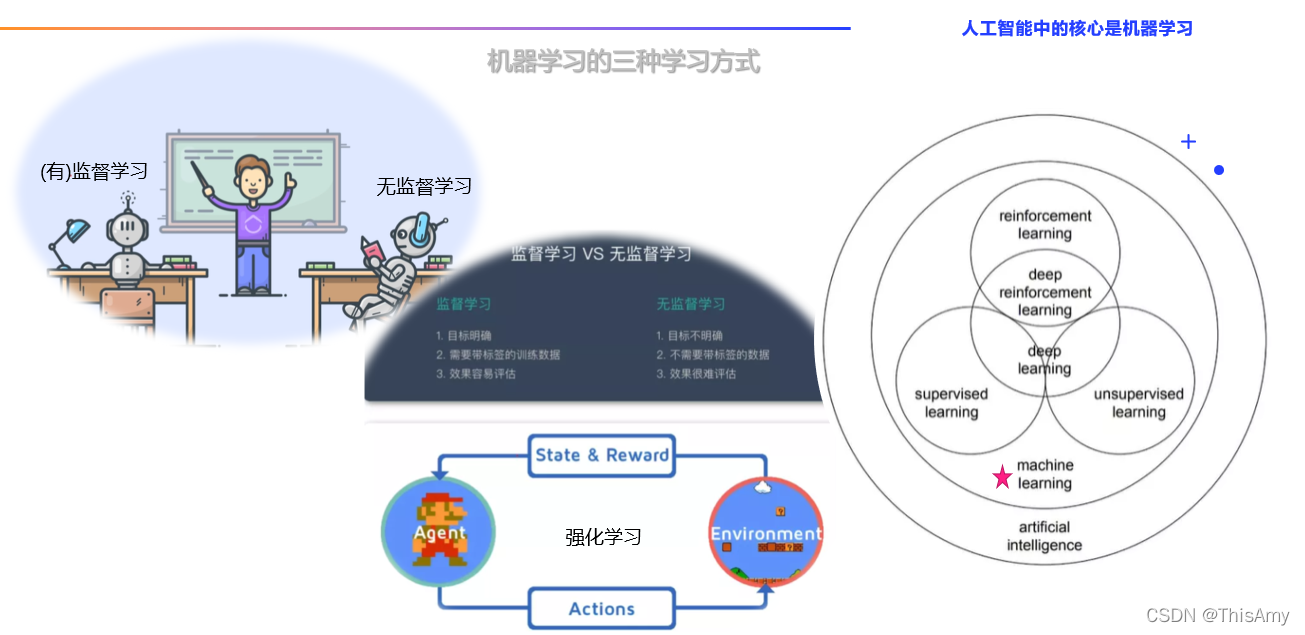
从学习方式上看,机器学习分为:有监督学习、无监督学习、强化学习
- 有监督学习(Supervised Learning, SL)
- 指原始数据中既有特征值也有标签值的机器学习
- 特点:① 目标明确 ② 需要带标签的训练数据 ③ 效果容易评估
- 无监督学习(Unsupervised Learning, UL)
- 其中没有需要预测或估计的目标变量(或标签值)
- 特点:① 目标不明确 ② 不需要带标签的训练数据 ③ 效果很难评估
- 强化学习(Reinforcement Learning, RL)
- 含义:让智能体与环境进行互动,不断学习以便调整策略的过程,这使智能体变得越来越聪明。
人工智能按照学习方式可分为:a. 有监督学习(数据集中有x和y)、b. 无监督学习(有x)、c. 半监督学习(有x和一部分y)、d. 强化学习(智能体与环境互动过程中产生数据,再代入算法中生成模型)。
深度学习比传统机器学习有优势
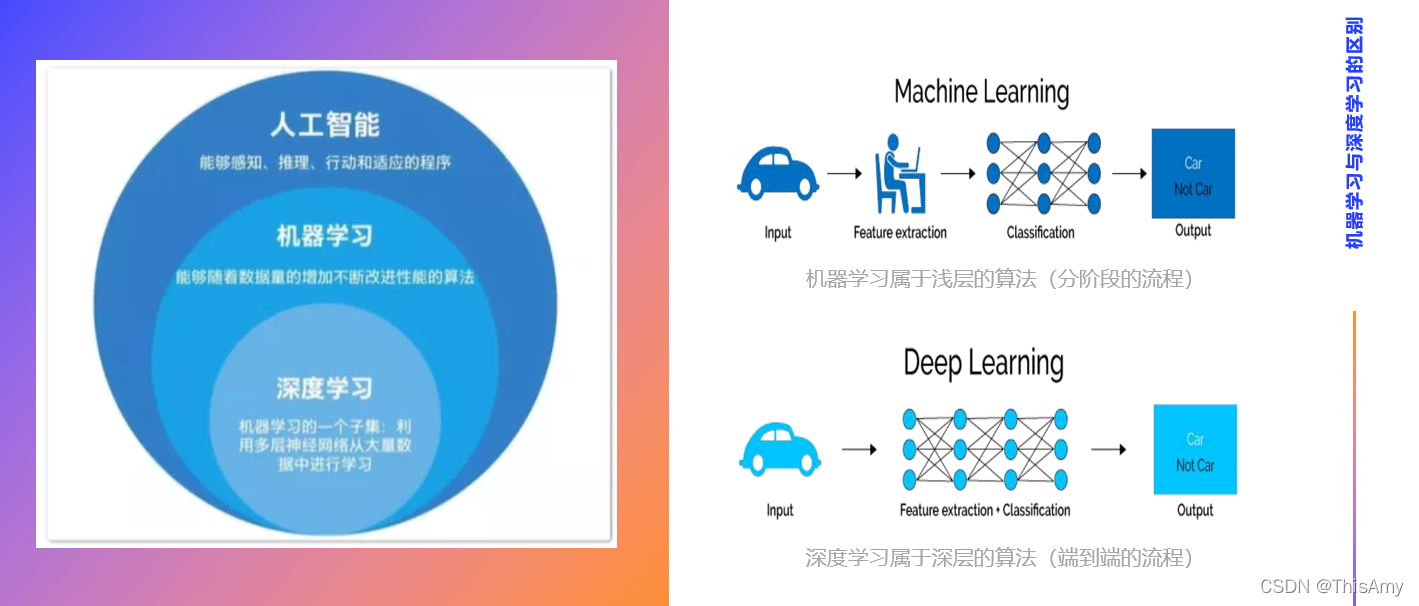
机器学习:人们更多的是把数据拿过来做特征的抽取(特征处理),这个过程更多的会有人为的参与,如:人为的选择用哪些算法,使用哪些数据做特征抽取。人为更多的参与预处理,将预处理后的数据交给后续的算法去生成算法中的参数。
机器学习和深度学习的区别:
① 机器学习属于浅层的算法(算法的公式不是特别复杂,更像分阶段的流程);
② 深度学习属于深层的算法(将提取特征的阶段放到整个神经网络中,更像端到端的流程)。
深度学习相比机器学习的优势:
① 是更端到端的学习方式;
② 由于网络层次更深,其可训练的参数更多(可以学习如何更好提取特征);
③ 可以解决更复杂的问题。
理解 —— 有多少人工就有多少智能(人工智能的本质)
- 机器学习:在特征工程中做的多好,最后的算法就能预测的有多准;
- 深度学习:设计的网络有多好,模型预测的就有多准确。
三、人工智能的常见任务和本质
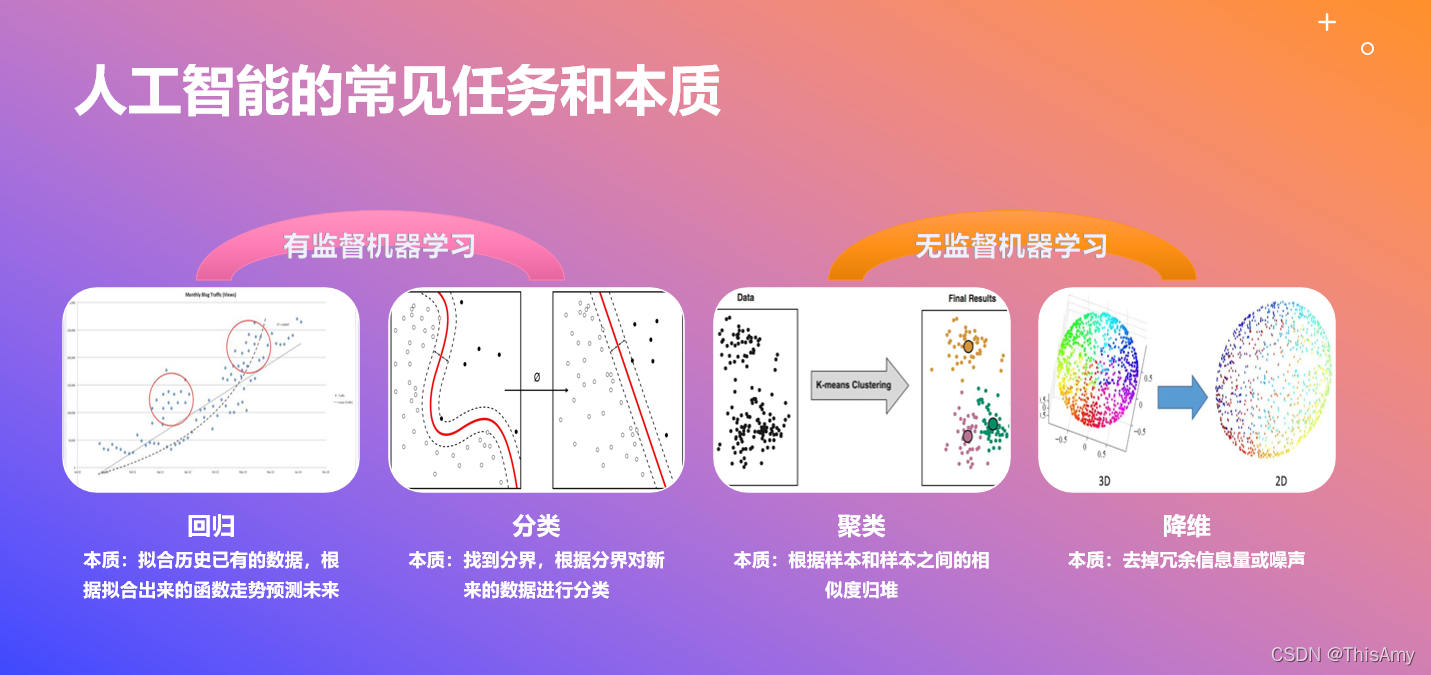
有监督机器学习任务与本质
做人工智能时,首先要明确需求是什么?预测的东西是什么?即:先明确有哪些任务,再选择相对应的算法。
回归、分类、聚类、降维都是机器学习中具体的任务。其中,① 回归和分类属于有监督机器学习;② 聚类和降维属于无监督机器学习。
回归 Regression
- 本质:拟合历史已有的数据,根据拟合出来的函数走势预测未来
- 目标:预测-inf 到+inf 之间具体的值,连续值
- 应用:股票预测(如:股票值的预测)、房价预测
分类 Classification
- 本质:找到分界,根据分界对新来的数据进行分类
- 目标:对新的数据预测出是各个类别的概率,正确的类别概率越大越好,最后通过选择概率最大的类别为最终类别,类别号 label 是离散值
- 应用:图像识别(如:识别该人是否戴安全帽)、情感分析(如:分析是正面情感还是负面情感)、银行风控(如:预测该人可承受怎样的风险,推荐不同的理财产品)
总结:
① 回归是做拟合,分类是找分界对应的超平面(通常超平面指:点、线、面)。
② 回归(连续型)和分类(离散型):有监督机器学习。具体看预测的值是离散型的还是连续型的,对应不同的分类。
③ 注意:股票预测中,若要预测未来某股票是会涨还是跌—— 分类任务,则需找分类所对应的算法去求相对应的分界线/面。
无监督机器学习任务与本质
无监督机器学习问题主要有两种:聚类、降维
聚类 Clustering
- 本质:根据样本和样本之间的相似度归堆
- 目标:将一批数据划分到多个组
- 应用:用户分组、异常检测、前景背景分离
降维 Dimensionality Reduction
- 本质:去掉冗余信息量或噪声
- 目标:将数据的维度减少
- 应用:数据的预处理、可视化、提高模型计算速度
总结:
① 聚类就是分组(归堆);降维类似于换个角度去审视原来的数据。
② 由于维度越多,速度越慢。所以,为提高模型运行速度,通常会做降维的任务。
智能推荐
WCE Windows hash抓取工具 教程_wce.exe -s aaa:win-9r7tfgsiqkf:0000000000000000000-程序员宅基地
文章浏览阅读6.9k次。WCE 下载地址:链接:https://share.weiyun.com/5MqXW47 密码:bdpqku工具界面_wce.exe -s aaa:win-9r7tfgsiqkf:00000000000000000000000000000000:a658974b892e
各种“网络地球仪”-程序员宅基地
文章浏览阅读4.5k次。Weather Globe(Mackiev)Google Earth(Google)Virtual Earth(Microsoft)World Wind(NASA)Skyline Globe(Skylinesoft)ArcGISExplorer(ESRI)国内LTEarth(灵图)、GeoGlobe(吉奥)、EV-Globe(国遥新天地) 软件名称: 3D Weather Globe(http:/_网络地球仪
程序员的办公桌上,都出现过哪些神奇的玩意儿 ~_程序员展示刀,产品经理展示枪-程序员宅基地
文章浏览阅读1.9w次,点赞113次,收藏57次。我要买这些东西,然后震惊整个办公室_程序员展示刀,产品经理展示枪
霍尔信号、编码器信号与电机转向-程序员宅基地
文章浏览阅读1.6w次,点赞7次,收藏63次。霍尔信号、编码器信号与电机转向从电机出轴方向看去,电机轴逆时针转动,霍尔信号的序列为编码器信号的序列为将霍尔信号按照H3 H2 H1的顺序组成三位二进制数,则霍尔信号翻译成状态为以120°放置霍尔为例如不给电机加电,使用示波器测量三个霍尔信号和电机三相反电动势,按照上面所说的方向用手转动电机得到下图① H1的上升沿对应电机q轴与H1位置电角度夹角为0°,..._霍尔信号
个人微信淘宝客返利机器人搭建教程_怎么自己制作返利机器人-程序员宅基地
文章浏览阅读7.1k次,点赞5次,收藏36次。个人微信淘宝客返利机器人搭建一篇教程全搞定天猫淘宝有优惠券和返利,仅天猫淘宝每年返利几十亿,你知道么?技巧分享:在天猫淘宝京东拼多多上挑选好产品后,按住标题文字后“复制链接”,把复制的淘口令或链接发给机器人,复制机器人返回优惠券口令或链接,再打开天猫或淘宝就能领取优惠券啦下面教你如何搭建一个类似阿可查券返利机器人搭建查券返利机器人前提条件1、注册微信公众号(订阅号、服务号皆可)2、开通阿里妈妈、京东联盟、拼多多联盟一、注册微信公众号https://mp.weixin.qq.com/cgi-b_怎么自己制作返利机器人
【团队技术知识分享 一】技术分享规范指南-程序员宅基地
文章浏览阅读2.1k次,点赞2次,收藏5次。技术分享时应秉持的基本原则:应有团队和个人、奉献者(统筹人)的概念,同时匹配团队激励、个人激励和最佳奉献者激励;团队应该打开工作内容边界,成员应该来自各内容方向;评分标准不应该过于模糊,否则没有意义,应由客观的基础分值以及分团队的主观综合结论得出。应有心愿单激励机制,促进大家共同聚焦到感兴趣的事情上;选题应有规范和框架,具体到某个小类,这样收获才有目标性,发布分享主题时大家才能快速判断是否是自己感兴趣的;流程和分享的模版应该有固定范式,避免随意的格式导致随意的内容,评分也应该部分参考于此;参会原则,应有_技术分享
随便推点
O2OA开源企业办公开发平台:使用Vue-CLI开发O2应用_vue2 oa-程序员宅基地
文章浏览阅读1k次。在模板中,我们使用了标签,将由o2-view组件负责渲染,给o2-view传入了两个参数:app="内容管理数据"和name="所有信息",我们将在o2-view组件中使用这两个参数,用于展现“内容管理数据”这个数据应用下的“所有信息”视图。在o2-view组件中,我们主要做的事是,在vue组件挂载后,将o2的视图组件,再挂载到o2-view组件的根Dom对象。当然,这里我们要在我们的O2服务器上创建好数据应用和视图,对应本例中,就是“内容管理数据”应用下的“所有信息”视图。..._vue2 oa
[Lua]table使用随笔-程序员宅基地
文章浏览阅读222次。table是lua中非常重要的一种类型,有必要对其多了解一些。
JAVA反射机制原理及应用和类加载详解-程序员宅基地
文章浏览阅读549次,点赞30次,收藏9次。我们前面学习都有一个概念,被private封装的资源只能类内部访问,外部是不行的,但这个规定被反射赤裸裸的打破了。反射就像一面镜子,它可以清楚看到类的完整结构信息,可以在运行时动态获取类的信息,创建对象以及调用对象的属性和方法。
Linux-LVM与磁盘配额-程序员宅基地
文章浏览阅读1.1k次,点赞35次,收藏12次。Logical Volume Manager,逻辑卷管理能够在保持现有数据不变的情况下动态调整磁盘容量,从而提高磁盘管理的灵活性/boot分区用于存放引导文件,不能基于LVM创建PV(物理卷):基于硬盘或分区设备创建而来,生成N多个PE,PE默认大小4M物理卷是LVM机制的基本存储设备,通常对应为一个普通分区或整个硬盘。创建物理卷时,会在分区或硬盘的头部创建一个保留区块,用于记录 LVM 的属性,并把存储空间分割成默认大小为 4MB 的基本单元(PE),从而构成物理卷。
车充产品UL2089安规测试项目介绍-程序员宅基地
文章浏览阅读379次,点赞7次,收藏10次。4、Dielecteic voltage-withstand test 介电耐压试验。1、Maximum output voltage test 输出电压试验。6、Resistance to crushing test 抗压碎试验。8、Push-back relief test 阻力缓解试验。7、Strain relief test 应变消除试验。2、Power input test 功率输入试验。3、Temperature test 高低温试验。5、Abnormal test 故障试验。
IMX6ULL系统移植篇-系统烧写原理说明_正点原子 imx6ull nand 烧录-程序员宅基地
文章浏览阅读535次。镜像烧写说明_正点原子 imx6ull nand 烧录