常见的多类别分类模型_多分类模型-程序员宅基地
今天给大家介绍两个多分类任务中的经典网络模型LeNet5和AlexNet。内容源来自“有三AI”,感兴趣的读者可以关注公众号“有三AI”。
首先要给大家普及以下网络深度和网络宽度的概念,强调一点,池化层是不算入网络深度的。
网络的深度:最长路径的卷积层+全连接层的数量,这是深度学习最重要的属性。
如图,以简单的LeNet5网络为例,网络中包含3个卷积层,2个全连接层,所以网络深度等于5。
C1+C3+C5+F6+OUTPUT
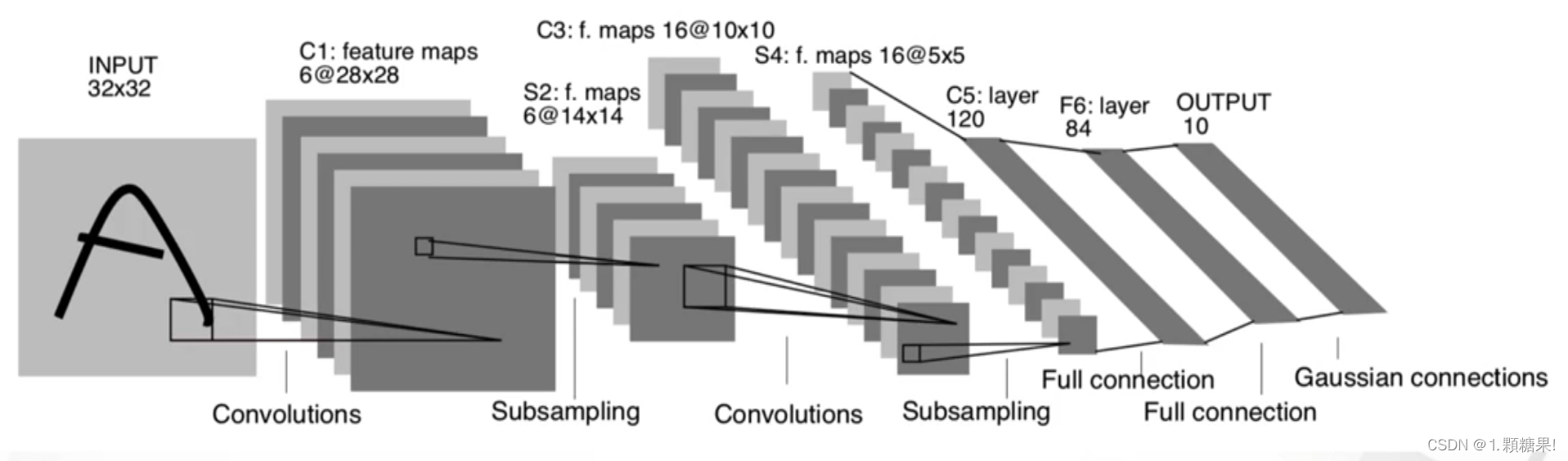
图1 LeNet5网络
网络的宽度:每一个网络层的通道数,以卷积网络层计算。LeNet5网络:C1(6),C3(16),
多类别图像分类的经典模型
一、LeNet网络
1. LeNet5模型结构
一共7层,3个卷积层,2个池化层,3个全连接层,输入图像大小为32*32(灰度图——单通道)。
- C1:6个5*5的卷积核
- C3:60个5*5的卷积核(为什么不是16*6个5*5的卷积核,下文会给出解释)
- C5:120*16个5*5卷积核
- 两个池化层S2和S4:都是2*2的平均池化,并添加了非线性映射
- 第一个全连接层:84个神经元(为什么不是2的整数次幂,解释见下文)
- 第二个全连接层:10个神经元
2. LeNet5的工程技巧
(1) C3层与S2层之间非密集的特征图连接关系:打破对称性,同时减少计算量,共60组卷积核。
 图2 C3层特征图与S2层特征图之间的连接关系
图2 C3层特征图与S2层特征图之间的连接关系
(2) 全连接层的设计
倒数第2层维度不是常见的2的指数次幂的维度,而是84,为什么?
计算机中字符的编码是ASCII编码,这些图是用7*12大小的位图表示,84可以用于对每一个像素点的值进行估计。
二、AlexNet网络
1. AlexNet模型结构
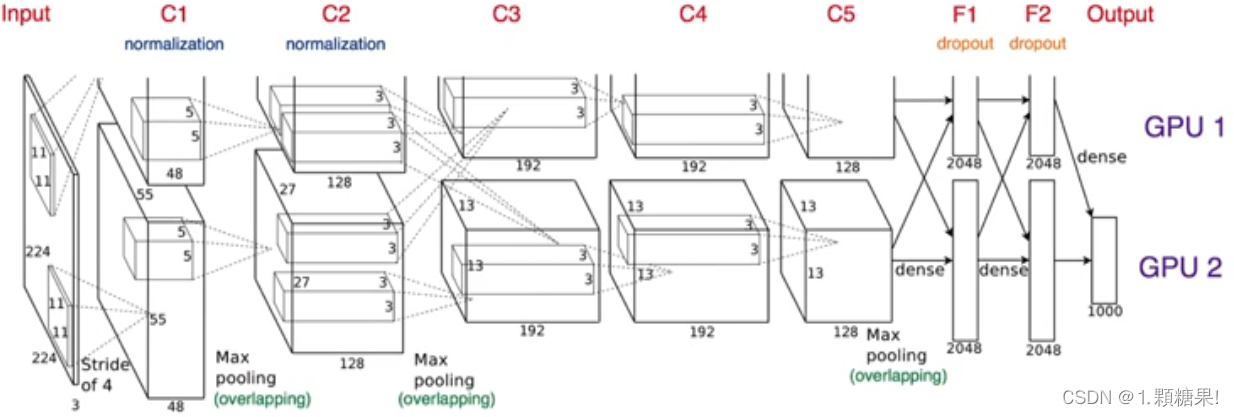
图3 AlexNet模型结构
一共8层,5个卷积层,3个全连接层,输入图像:224*224*3
- C1:96*3个11*11卷积核
- C2:256*96个5*5卷积核
- C3:384*256个3*3卷积核
- C4:384*384个3*3卷积核
- C5:256*384个3*3卷积核
- 全连接层F1,F2,Output神经元数量:4096,4096,1000
2. AlexNet工程技巧
- 多GPU训练:尽量使用更多特征图,并减少计算量。除了将模型的神经元进行了并行,还使得通信被限制在了某些网络层。第三层卷积要使用第二层所有的特征图,但是第四层却只需要同一块GPU中的第三次的特征图。
- ReLU激活函数:加快模型收敛。
- LRN归一化:抑制反馈较小的神经元,放大反馈较大的神经元,增强模型泛化能力
- Dropout正则化:防止过拟合,提高泛化能力。
- 重叠池化:更有利于减轻过拟合。
- 数据增强:提高模型泛化能力。
- 测试时增强:指的是在推理(预测)阶段,将原始图片进行水平翻转、垂直翻转等数据增强操作,得到多张图分别进行推理,再对结果融合。
三、分类任务中存在的难题——类别不平衡问题
不同类别下的样本数目相差过大,从而导致分类模型的性能变差。
解决方案:
- 基于数据层面的方法:ROS,RUS,采用预训练模型,动态采样
- 基于算法层面的方法:修改损失函数、代价敏感学习、阈值移动
- 基于数据和算法混合的方法:LMLE,DOS,难例挖局
提升样本法:
1. 对于类别数目较少的类别,从中随机选择一些图片进行复制并添加至该类别包含的图像内,知道这个类别的图片数目和最大数目类的个数相等为止。
2. 插值方法:
- 第一步:定义好特征空间,将每个样本对应到特征空间中的某一点,根据样本不平衡比例确定好一个采样倍率N;
- 第二步:对每一个少样本类样本
,按欧氏距离找出k个最近邻样本,从中随机选取一个样本点,假设选择的近邻点为
。在特征空间中样本点与最近邻样本点的连线段上随机选取一点作为新的样本点,满足以下公式:
- 第三步:重复以上的步骤,知道大、小样本数量平衡。
3. 动态采样:借鉴了提升样本的思想,根据训练结果对数据集进行调整。对结果较好的类别进行随机删除样本操作;对结果较差的类别进行随机复制操作。
4. 两阶段训练法
- 第一步:根据数据集分布情况设置一个阈值N,通常为最少类别所包含的样例个数。
- 第二步:对样例个数大于阈值的类别进行随机抽取,直到达到阈值。此时根据阈值抽取的数据集作为第一阶段的训练样本进行训练,并保存模型参数。
- 第三步:采用第一阶段的模型作为预训练数据,再在整个数据集上进行训练,对最终的分类结果有了一定的提升。
5. 优化目标设计——提高少类的权重(可以根据经验设置,或者基于样本数量进行自适应加权)
6.样本量过少的解决方案
迁移学习:ImageNet预训练模型的通用性
如果模型的训练数据足够大,且与任务相匹配,该预训练模型所学到的特征具备一定的通用性。
数据增强:有监督方法和无监督方法
- 有监督方法:平移、翻转、亮度、对比度、裁剪、缩放等
- 无监督方法:通过GAN网络生成所需样本,然后再进行训练。
智能推荐
试论软件的可靠性及其保证_软件可靠性需求怎么写-程序员宅基地
文章浏览阅读2.5w次,点赞4次,收藏17次。试论软件的可靠性及其保证来源:ChinaItLab 用软件系统规模越做越大越复杂,其可靠性越来越难保证。应用本身对系统运行的可靠性要求越来越高,在一些关键的应用领域,如航空、航天等,其可靠性要求尤为重要,在银行等服务性行业,其软件系统的可靠性也直接关系到自身的声誉和生存发展竞争能力。 特别是软件可靠性比硬件可靠性更难保证,会严重影响整个系统的可靠性。在许多项目开发过程中,对可_软件可靠性需求怎么写
新手前端微信小程序img图片无法显示问题_微信小程序js引入图片前端不显示-程序员宅基地
文章浏览阅读2.5w次,点赞21次,收藏23次。最近自己在做毕设,是一个微信小程序,虽然自己有一点前端开发经验,以为小程序前端和这个差不多可以直接开撸,但是这两天被一些图片问题烦了好久。这也是自己第一次写博客,实在太生气了,网上也没找到自己想要的结果,所以写下来记录下来,顺便让和我一样错误的人知道咋解决,笑cry,虽然真的很低级的错误。以下是遇到的问题。 1:在开发者工具可以显示图片,手机预览,真机调试却看不到。 2:在最开始的ipho..._微信小程序js引入图片前端不显示
JSON百科全书:学习JSON看这一篇就够了-程序员宅基地
文章浏览阅读2.8k次,点赞10次,收藏51次。JSON 对象包含两个方法:用于解析 JavaScript Object Notation(JSON)的 parse() 方法,以及将对象/值转换为 JSON 字符串的 stringify() 方法。除了这两个方法,JSON 这个对象本身并没有其他作用,也不能被调用或者作为构造函数调用。_json
【电子基础】总结·嵌入式硬件基础_哈佛j80c电源板-程序员宅基地
文章浏览阅读1.8k次,点赞2次,收藏9次。嵌入式系统硬件基础By 成鹏致远第一章 常用硬件——>嵌入式系统常用的硬件器件,主要包括分立器件、光电半导体、逻辑IC、模拟IC以及存储器共五大类——>分立器件主要有:二极管、三极管、电阻、电容、电感以及场效应管等——>二极管的主要特性是单向导电性——>二极管按其用途可分为:整流二极管、稳压二极管、开关二极管、发光二极管等——>整流二级管是一种将交流电转变为直流电的半导体器件,主要用于各种低频整流_哈佛j80c电源板
组件三大属性,state,props,refs_组件自带的属性-程序员宅基地
文章浏览阅读673次。一,组件实例三大属性(1)state查看状态:在写好的组件实例上有一个属性,state,就代表这个组件的状态。接下来我们写一个有状态的组件:<body> <div id="test"></div> <script type="text/babel"> // 创建组件 class Component extends React.Component { // 初始化,调_组件自带的属性
yii2框架-yii2的组件和服务定位器(四)_yii2 unknown component id: db-程序员宅基地
文章浏览阅读4.4k次,点赞3次,收藏4次。上一节主要是分析了yii2的自动加载函数,下面在分析一下yii2的核心组件与服务定位器。其实yii2的核心组件主要有以下://日志组件'log' => ['class' => 'yii\log\Dispatcher'],//视图组件,这个组件代表视图文件中的$this'view' => ['class' => 'yii\web\View'],//格式化组件,将一些输出按照一_yii2 unknown component id: db
随便推点
swagger 设置全局token_swagger加全局token-程序员宅基地
文章浏览阅读1.5k次,点赞2次,收藏5次。1. 在swaggerConfig 配置文件中定义一个bean如果不知道swaggerConfig可看之前发布swagger的配置文章https://blog.csdn.net/luChenH/article/details/90763812 @Bean SecurityScheme securityScheme() { return new ApiKey("token", "token", "header"); }名字根据自己需要变更,我这边就是tok._swagger加全局token
nginx + lua + redis 防刷和限流_nginx + lua + redis 限速带宽-程序员宅基地
文章浏览阅读3.1w次,点赞8次,收藏46次。防刷和限流的概念是:防刷的目的是为了防止有些IP来爬去我们的网页,获取我们的价格等信息。不像普通的搜索引擎,这种爬去行为我们经过统计最高每秒300次访问,平均每秒266次访问。由于我们的网站的页面都在CDN上,导致我们的CDN流量会定时冒尖。为了防止这种情况,打算将网页页面的访问从CDN切回主站。同时开启防刷功能,目前设置一秒200次访问即视为非法,会阻止10分钟的访问。限流的目的_nginx + lua + redis 限速带宽
hive 窗口函数总结及使用案例_hive 窗口函数的执行顺序-程序员宅基地
文章浏览阅读700次。1. 窗口函数和普通聚合函数的区别聚合函数是将多条记录合并为一条;窗口函数是每条记录都会执行,原来有几条记录最终执行完还是几条聚合函数也可以用于窗口函数:窗口函数在逻辑上的执行顺序是在FROM、JOIN、WHERE、GROUP BY 、HAVING 之后,在ORDER BY、LIMIT、SELECT DISTINCT之前。它执行之前GROUP BY的聚合过程已经完成了,所以不会再产生数据聚合。注:窗口函数是在 WHERE 之后执行的,所以如果 WHERE 子句需要用窗口函数作为条件,需要多套一层子_hive 窗口函数的执行顺序
Windows11 - 使用 sftp连接 CentOS 7,实现文件上传与下载_windows连接sftp-程序员宅基地
文章浏览阅读4.3k次。Windows11 -使用sftp连接CentOs 7,实现文件上传与下载_windows连接sftp
gflags的交叉编译_manually-specified variables were not used by the -程序员宅基地
文章浏览阅读2.6k次,点赞2次,收藏9次。gflags版本:gflags 2.2.2目录编译动态库的编译cmakelbw@DESKTOP-LBW22:/mnt/d/ref/gflags-master/_build$ cmake .. -DGFLAGS_NAMESPACE=gflags -DCMAKE_CXX_FLAGS=-fPIC -DBUILD_SHARED_LIBS=ON -DCMAKE_C_COMPILER=aarch64-linux-gnu-gcc -DCMAKE_CXX_COMPILER=aarch64-li._manually-specified variables were not used by the project:
SpringBoot mysql 时区问题总结_servertimezone=gmt+8-程序员宅基地
文章浏览阅读1.6k次。寻找原因后端开发中经常mysql8.x的jdbc升级了,增加了时区(serverTimezone)属性,并且不允许为空。_servertimezone=gmt+8