Apache Kylin(麒麟)_ebay 麒麟-程序员宅基地
技术标签: 大数据
为什么需要Kylin?
Hadoop帮助我们解决了海量数据的存储。
早期使用Hadoop的MapReduce计算模型,太慢了,只能做离线计算,无法做实时计算与迭代式计算。
Spark应运而生,并带动了Scala语言的发展,Spark的MapReduce计算模型比Hadoop的MapReduce计算模型性能提升了数十倍。
在现今的企业发展中,数据的增量是每日以百MB、G为单位的增长,面对如此之大的规模性数据增长,及运营成本、硬件成本、响应速度等各方面影响下,Spark也够呛。
在这种情况下,企业查询一般分为即席查询和定制查询。
即席查询:Hive、SparkSQL等OLAP引擎,虽然在一定程度上降低了数据分析的难度,但他们只用于即席查询的场景,优点就是用户根据自己的需求,自定义、灵活的选择查询条件,与普通查询最大的区别在于普通查询时根据应用定制的开发查询条件,但随着数据量和计算复杂度的增长,响应数据无法得到保证。
实时查询:多数情况下是对用户的操作做出实时反应,Hive等查询引擎很难满足实时查询,一般只能对数据库中的数据进行提取计算,然后将结果存入MySQL等关系型数据库,最后提供给用户进行查询,随着后面海量数据的递增,这种方式的代价很大。
Kylin不同于大规模并行处理的Hive等架构,Kylin是预计算的模式,我们提前定义好查询的维度,Kylin就会帮助我们进行计算,并将结果存储到Hbase,当我们在去查询海量数据和分析时,提供亚秒级返回。
Kylin很明显采用的是空间换时间的策略,先将定义好的各个字段进行交叉查询,将这些查询好的数据放到数据库中,当我们去查询时这个时候数据量也少了,如果查询语句和预计算的语句是一样的,那样则可以直接返回,因此Kylin查询速度很快。
阅读以下内容前,请先阅读:https://blog.csdn.net/Su_Levi_Wei/article/details/89501304
什么是Kylin?
Apache Kylin(Extend OLAP Engine For Big Data)中文名为麒麟,是Hadoop生态圈的重要成员,是一个开源的分布式分析引擎,最初是由eBay开发的,提供了Hadoop之上的SQL查询接口及多维分析(OLAP)功能,支持高并发处理TB至PB级别的大规模海量数据,能够在亚秒级查询巨大的Hive表。
Kylin在2014年10月在Github开源,2014年11月加入Apache,2015年11月成为顶级项目,也是第一个完全由中国团队设计开发的Apache顶级项目,2016年3月Kylin核心开发成员成立了Kyligence公司来推动项目和社区的发展。
Cube & Cuboid
Cube可以说是Kylin的核心,Kylin就是通过构建Cube,进而达到亚秒级的海量数据搜索。
在构建Cube前,要先进行数据仓库的设计和架构,进而确定好要分析维度和指标(度量),根据定义好的维度和指标(度量)就可以构建Cube了。
Cube是对于一个给定的数据模型的所有维度进行组合、计算。
对于N个维度来说,组合的可能性共有2的N次方,对于每一种维度的组合,将指标(度量)做聚合计算。
其中每一种维度组合称为Cubeid,一个Cubeid包含一种具体维度组合下所有指标的值。
如下图,是一个四维的Cube构建过程。
假设有一个点上的销售数据集,其中的维度包括时间、商品、地点、供应商四个维度,指标为销售额,那么所有维度的组合就有2的4次方,刚好对应下图。
如果提前计算好,那么在写SQL连表操作时,一下子就出来结果了。
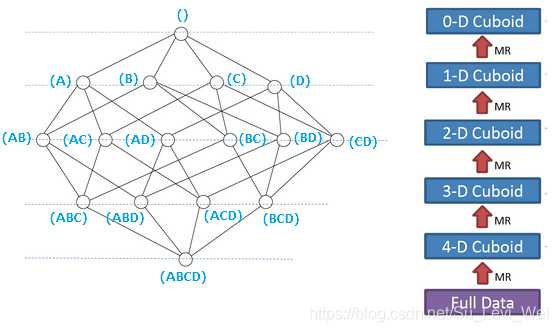
Cube & Cuboid构建过程
Kylin的核心思想是预计算,即对多维分析可能用到的指标(度量)进行计算,将计算好的结果保存成Cube,供查询时,直接访问,把高复杂度的聚合运算、多表连接等操作转换成对预计算结果的查询,这决定了Kylin能够拥有很好的快速查询和高并发的能力。
进而Kylin提供了一个称为Layer Cubing的算法来构建Cube,这个算法是按照维度(Dimension)数量从大到小的顺序,从Base Cuboid开始,依次给予上一层的结果进行再次聚合,每一层的计算都是一个单独的MapReduce任务。
这里面的Map和Reduce还是比较简单的,Mapper以上一层Cuboid的结果作为输入,由于Key是由各维度值拼接在一起,从其中找出要聚合的维度,去掉它的值成新的Key,并对Value进行操作,然后把新Key和Value输出,进而对所有新Key进行排序,洗牌(Shuffle),再Reduce,Reduce的输入是一组有相同Key的Value集合,对这些Value做聚合计算,再结合Key输出就完成了一轮计算。
每一轮的计算都是一个MapReduce任务,而且是串行执行,一个N维的Cube,至少需要N次MapReduce Job。
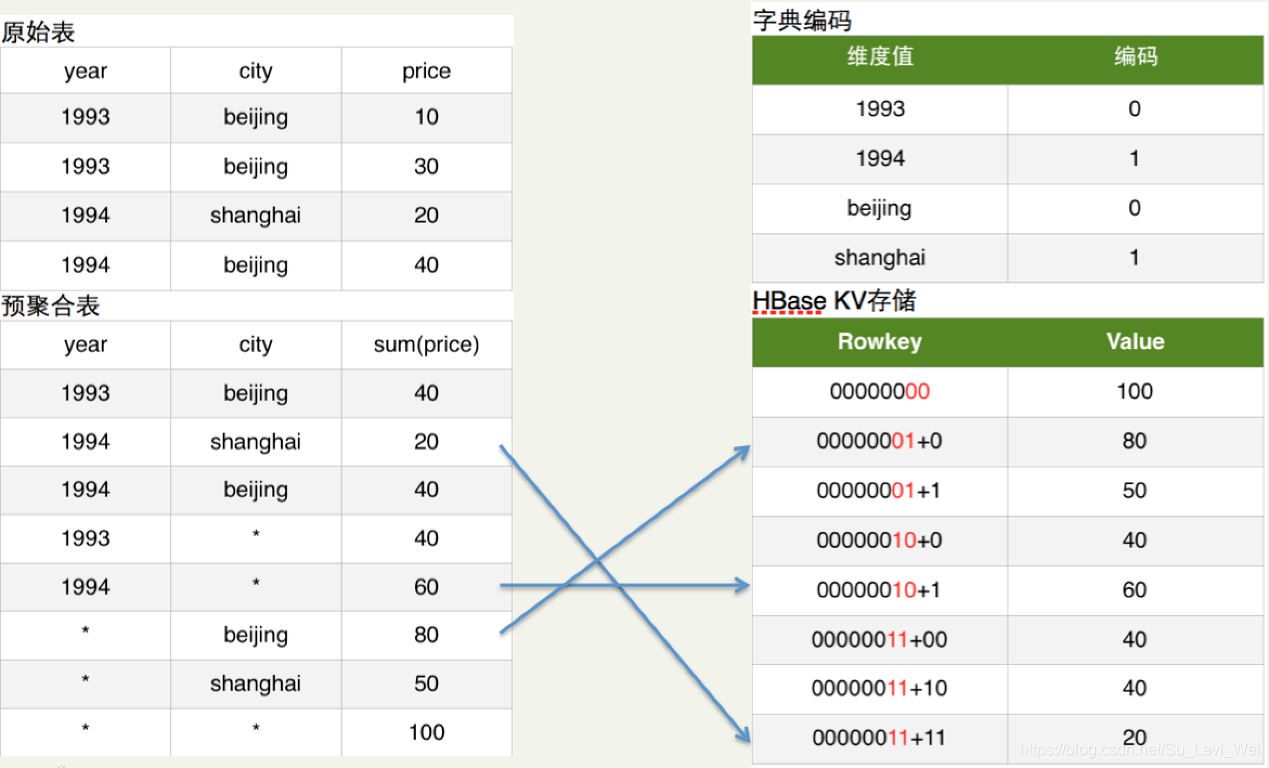
Kylin是把MapReduce的计算结果最终保存在HBase中,对于跨度查询(年、季度、月等)Kylin是使用Cube的Data Segment分区存储管理解决。
而HBase中每行记录的RowKey由维度(Dimension)组成,Cuboid的指标会保存在Column Family中映射为Value,为了减少存储的代价,这里会对维度和指标进行编码。
查询阶段利用HBase列存储的特性就可以保证Kylin有良好的快速响应和高并发。
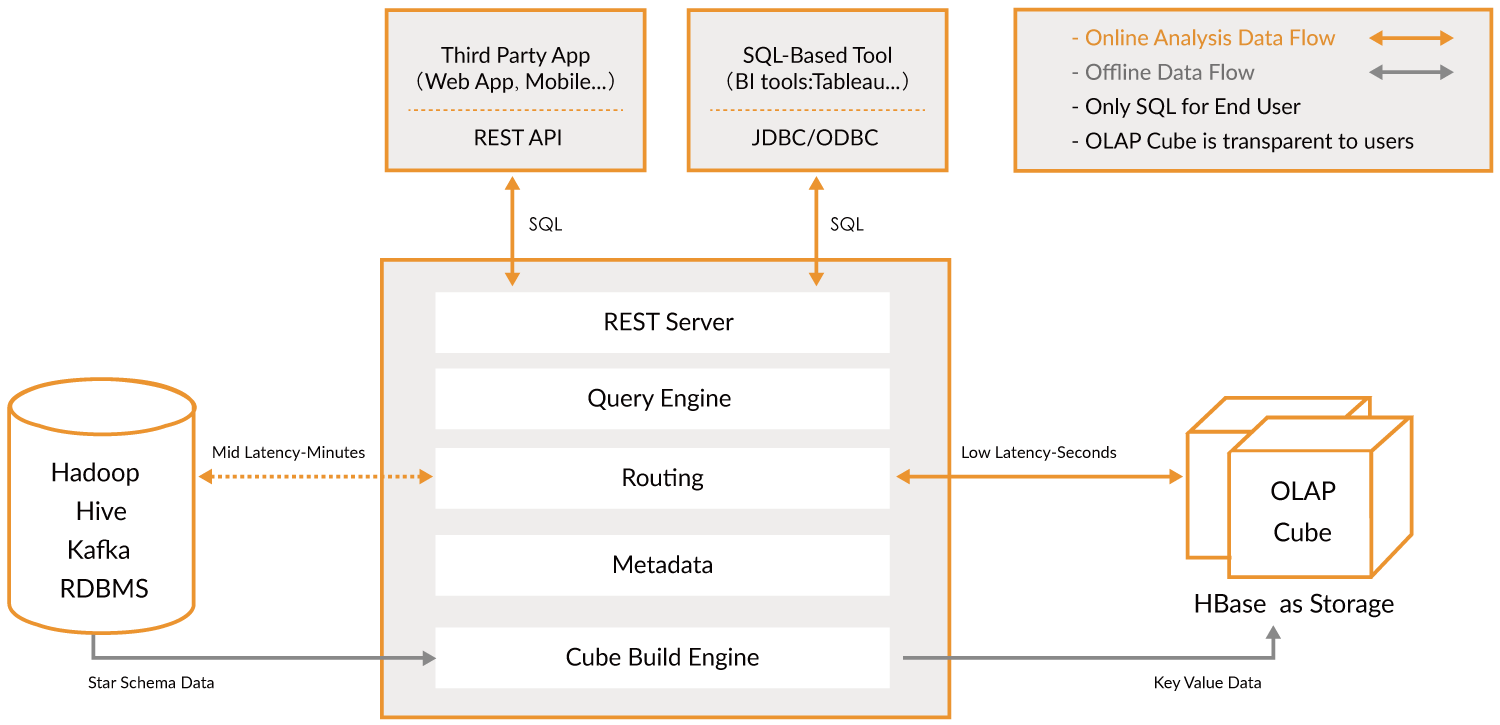
Kylin技术架构
数据源
Kylin支持多种数据源,默认的数据源是Hive。
存储引擎
Kylin采用预计算的方式,默认的预计算结果存储引擎是HBase。
REST Server
REST Server是一条面向应用程序开发的入口点,此类应用程序可以提供查询、获取结果、触发Cube构建任务、获取元数据及用户权限等,还可以通过Restful接口实现SQL查询。
Query Engine(查询引擎)
当Cube准备就绪后,查询引擎能够获取并解析用户查询的语句,并与其他组件交互,返回用户对应的结果。
Routing(路由)
将解析SQL生成的执行计划转为Cube缓存查询,Cube通过预计算缓存在HBase中,用户查询时,利用router查询算法和优化的HBase Coprocessor解决。
Metadata(元数据)
管理保存在Kylin中的所有元数据,包括Cube元数据,其他的组件都是以此为基础,Kylin的技术元数据和业务元数据都是存储在HBase的。
Cube Build Engine(任务引擎)
处理并协调所有离线任务,包括Shell脚本、JavaApi、MapReduc任务等。
Cube 三种构建
Kylin Cube构建分为三种,全量构建、增量构建、流式构建。
全量构建:每次都对Hive表进行全表构建,但这种构建方式在实际环境中并不常用,只有在初始化时用的较多,因为大多数业务场景下,事实表的数据是不断的增长的。
增量构建:使得Cube每次只构建Hive表中新增的部分数据,而不是全部数据,因此降低了构建成本,Kylin将Cube分为多个Segment,每个Segment用起始时间和结束时间来标识。
增量构建的方式解决了业务数据动态增长的问题,但是却不能满足分钟级近实时返回结果的需求,因为增量构建他们使用的是Hive作为数据量,Hive中的数据由ETL定时导入(如每天一次),数据的时效性对于数据价值的重要性不言而喻。
增量构建和全量构建的区别:
1.创建Model时需要制定Partition Date Column(分区日期数据列),用日期对Cube进行分割。
2.创建Cube时需要制定Partition Start Date,即Cube默认的第一个Segemnt的起始时间。
官方文档:http://kylin.apache.org/docs20/tutorial/create_cube.html
http://kylin.apache.org/docs20/tutorial/cube_build_job.html
流式构建:为了解决数据实时增长的问题,流式构建使用Kafka作为数据源,构建引擎定时从Kafka中拉取数据进行构建,这个设计和Spark Streaming的定时微批次很类似,这个是在Kylin 1.6版本后存在的。
Kylin特性
SQL接口
Kylin主要对外的接口是以SQL的形式提供的,SQL简单易用的特性极大的降低了Kylin的学习成本。
支持海量数据集
不论是Hive、SparkSQL、还是Impala,它们的查询时间都随着数据量的增长而线性增长,而Apache Kylin使用预计算技术打破这一点,Kylin在数据集规模上的局限性主要取决于维度的个数和基数(维度表内的数据量),而不是数据集的大小,所以Kylin能更好的支持海量数据集的查询。
亚秒级响应
Kylin是采用预计算的技术,所以查询速度非常快,因为复杂的连接、聚合等操作都在Cube的构建过程中已经完成了。
水平扩展
Apache Kylin同样可以使用集群部署方式进行水平扩展,但部署多个节点只能提高Kylin处理查询的能力,而不能提升它的预计算能力(算法)。
可视化集成
Kylin提供与BI工具整合的能力,如Tableau、PowerBI/Excel、MSTR、QlikSense、Hub、SuperSet等。
构建多维立方体(Cube)
用户能够在Kylin里为百亿级以上数据集定义数据模型并构建立方体。
Kylin服务器模式
Kylin实例是无状态的,运行时状态(元数据)是存储在HBase(由conf/kylin.properties中的kylin.metadata.url指定)中的metadata中,因此在表结构中共享统一个状态(job状态,Cube状态等)。
每一个Kylin实例在conf/kylin.properties中都有一个Kylin.server.mode entry,指定运行时的模式。
job:在实例运行中job engine负责管理集群中的jobs
query:只运行query engine,负责接收和回应SQL查询。
all:在实例中即运行job engine,也可以运行query engines。
注:默认情况下只有一个实例可以运行job engine(all或job模式),其余需要query模式,类似Master/Slave模式。
智能推荐
TCP三次握手与四次挥手_tcp的3次握手和4次挥手-程序员宅基地
文章浏览阅读1.4k次。Tcp三次握手与四次挥手,自己的见解_tcp的3次握手和4次挥手
自然语言处理核心期刊_中国中文信息学会-程序员宅基地
文章浏览阅读467次。全国第十六届计算语言学会议(CCL 2017)及第五届基于自然标注大数据的自然语言处理国际学术研讨会(NLP-NABD 2017)联合征稿启事2017-03-20“第十六届全国计算语言学学术会议”(The Sixteenth China National Conference on Computational Linguistics, CCL 2017)将于2017年10月13日—15日在南京师范..._ccl是中文核心吗
html中的li标签不换行,css li 不换行(布局,内容)-程序员宅基地
文章浏览阅读3k次。参考这里------不换行的策略:不换行原理:ul 和 li 默认都是 display:block; 的标签,可以通过2种方式实现 li 的 不换行显示:* 将 li 设为 display:inline; ,然后通过 marging 和 padding 设置 li 的间距,* 将 li 设为 float:left; ,然后通过 ( margin & padding ) 设置 li 的间距,...
Java重要知识点以及面试题常问(如:抽象类和接口是Java中两种重要的抽象机制,它们有相似之处,也有不同之处。)-程序员宅基地
文章浏览阅读37次。2.抽象类和接口的区别。
强大的虚拟音频器:Loopback for Mac_音频虚拟器作用-程序员宅基地
文章浏览阅读1.5k次。loopback mac 激活版是mac上一款强大的虚拟音频器,可以帮助您创建聚合来自多个源(如麦克风或各种应用程序)的输入的虚拟设备,然后可以将其设置为其他应用程序中的默认输入设备。每个设备都可以配置为从任何应用程序或输入源绘制音频,甚至可以实时监视输出。而且通道映射是自动执行的,但您也可以通过将项目从音频源表拖动到通道映射表来手动配置虚拟设备。原文链接:https://mac.orsoon.com/Mac/164753.html(附安装下载教程)适用于MAC的无线音频路由突然间,在Mac上的应_音频虚拟器作用
linux中vi编辑的使用_linux如何进入vi编辑模式-程序员宅基地
文章浏览阅读5.7k次,点赞2次,收藏37次。1.1 vi的三种模式命令模式、插入模式/编辑模式、末行模式三种模式的用法:命令模式:进入vi编辑器之后就是命令模式,命令模式不可编辑,只可以执行命令。插入模式/编辑模式:在命令模式中,按i进入插入模式/编辑模式末行模式:编辑完成后,按ESC返回命令模式,在命令模式中,按:进入末行模式,在末行模式中wq保存并退出vi模式,按q!不保存并退出。1.2 如何进入vi编辑模式① vi 新文件 ---创建新文件并打开vi命令模式。 例:vi a.txt ---创建新文..._linux如何进入vi编辑模式
随便推点
Android中轮播图的实现_安卓轮播图-程序员宅基地
文章浏览阅读502次。—————–纯粹图片的轮播图——————–导包 //banner广告轮播图 compile 'com.youth.banner:banner:1.4.9'布局中使用
北京口袋时尚科技公司-微店内推技术一面-程序员宅基地
文章浏览阅读185次。今天下午预约的面试,如期到来,回顾一下面试的过程.1.简单的自我介绍2.开始面试(看简历问),一面一般是压力面试,我简历上写的可以开发手机游戏(Cocos2d-x),他就问知道Dijkstra算法吗,面试时面试官说他电话有问题(确实信号不信),但面试官很nice,我一时没听清,就说不知道,以前写过单源最短路径的题。3.看了我研究过安全与劫持,他就问内核态和用户态的转化过程,感觉答的不是..._北京口袋时尚科技有限公司的微店
2020年末知识大总结:Java程序员转Android开发必读经验一份,嵌入式开发入门教程_软件开发转移动端开发需要学什么-程序员宅基地
文章浏览阅读815次。Android是主流智能手机的操作系统,Java是一种开发语言,两者没有好坏优劣之分,只是两种职业岗位的选择。学安卓从事移动互联方向开发,学Java从事软件、网站开发。而安卓上的应用大多是Java编写的,所以建议在安卓前期的Java学习阶段中,要用心学好。言简意赅的说说“转”前的准备:其实Java程序员要自学安卓开发的基础知识还是没有什么难度的,毕竟语言相通,特性相似, 阅读安卓源代码的门槛以比较低一些,作为能够考虑“转”的合格的程序员的你,自学能力和相关的基础知识应该不是问题,学习安卓也相对比较轻松._软件开发转移动端开发需要学什么
Stm32CubeIDE设置补全快捷键和主题_cubeide快捷键设置-程序员宅基地
文章浏览阅读8.2k次,点赞8次,收藏32次。Stm32CubeIDE设置补全快捷键和主题stm32CubeIde的设置,省的自己忘记了。一、主题设置提示:这里可以添加要学的内容例如:1、 help->Eclipse Market->输入"Devstyle"查找主题插件->install安装2、窗口->首选项 找到主题3、按照如下设置完成后会提示重启,重启后效果如下所示二、补全设置用于设置代码的自动补全搜索: key->content assist默认的补全快捷键时alt+/,这里我改成双击两次_cubeide快捷键设置
【QBKbupt】洛谷P2525Uim的情人节礼物·其之壱-程序员宅基地
文章浏览阅读142次。(题目链接:https://www.luogu.com.cn/problem/P2525)#include<bits/stdc++.h>using namespace std;int main(){ int tmp,pos,s,n,number,symbol=1,input[10],data[10],memory[10]; scanf("%d",&n); for(int i=1;i<=n;i++) { scanf("%d",&input[i]);
CSS入门|空余空间、换行和省略-程序员宅基地
文章浏览阅读241次,点赞3次,收藏7次。text-overflow:ellipsis(省略号);(如果用clip(裁剪),就没有三个点)nowrap 文本不换行,直到遇到标签【最常用】pre 预格式化文本-保留空格,tab,回车。pre-line 显示回车,不显示换行,空格。做出多的文本省略、显示三个点的效果——容器宽度:width:200px;White-space空余空间。pre-wrap 自然换行。