数据仓库基础(通俗易懂,好文)数仓概念-程序员宅基地
技术标签: 大数据
1、数据仓库的概念
数据仓库(英语:Data Warehouse,简称数仓、DW),是一个用于存储、分析、报告的数据系统。数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。
数据仓库本身并不“生产”任何数据,其数据来源于不同外部系统;同时数据仓库自身也不需要“消费”任何的数据,其结果开放给各个外部应用使用,这也是为什么叫“仓库”,而不叫“工厂”的原因。
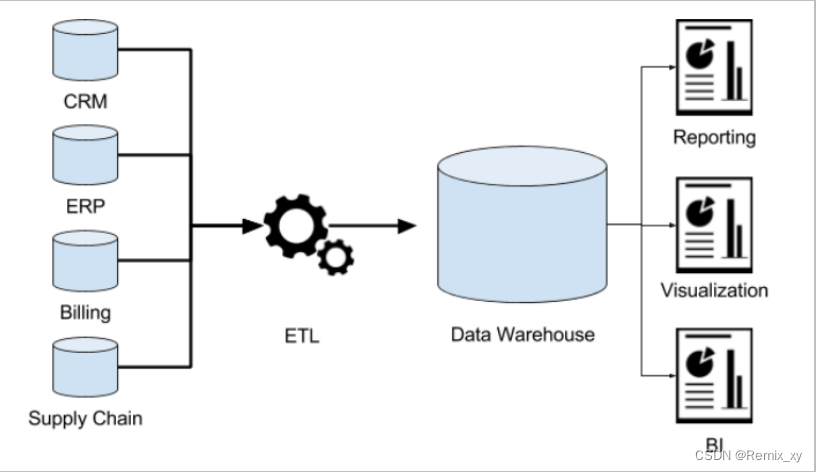
2、场景案例:数据仓库为何而来?
先下结论:为了分析数据而来,分析结果给企业决策提供支撑。
信息总是用作两个目的:操作型记录的保存和分析型决策的制定。数据仓库是信息技术长期发展的产物。
下面以中国人寿保险公司(chinalife)发展为例,阐述数据仓库为何而来?
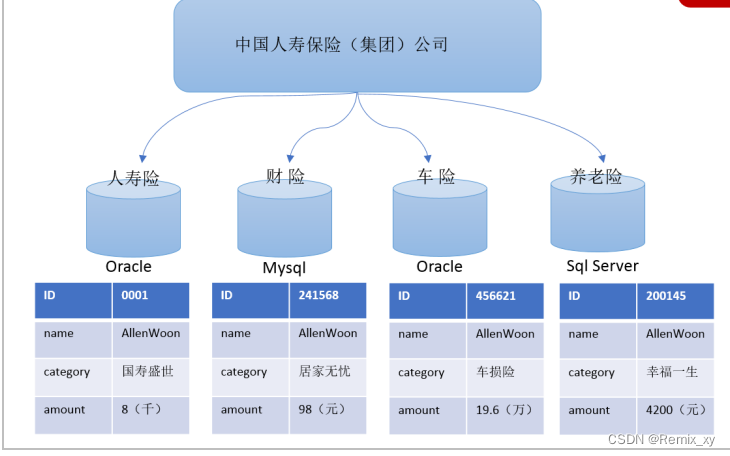
2、1操作型记录的保存
中国人寿保险(集团)公司下辖多条业务线,包括:人寿险、财险、车险,养老险等。各业务线的业务正常运营需要记录维护包括客户、保单、收付费、核保、理赔等信息。
联机事务处理系统(OLTP)正好可以满足上述业务需求开展, 其主要任务是执行联机事务和查询处理。其基本特征是前台接收的用户数据可以立即传送到后台进行处理,并在很短的时间内给出处理结果。关系型数据库是OLTP典型应用,比如:Oracle、Mysql、SQL Server等。
2、2分析型决策的制定
随着集团业务的持续运营,业务数据将会越来越多。由此也产生出许多运营相关的困惑:
能够确定哪些险种正在恶化或已成为不良险种?
能够用有效的方式制定新增和续保的政策吗?
理赔过程有欺诈的可能吗?
现在得到的报表是否只是某条业务线的?集团整体层面数据如何?
为了能够正确认识这些问题,制定相关的解决措施,瞎拍桌子是肯定不行的。最稳妥办法就是:基于业务数据开展数据分析,基于分析的结果给决策提供支撑。也就是所谓的数据驱动决策的制定。

然后,面临下一个问题:在哪里进行数据分析?数据库可以吗?
2、3 OLTP环境开展分析可行吗?
结论:可以,但是没必要。
OLTP的核心是面向业务,支持业务,支持事务。所有的业务操作可以分为读、写两种操作,一般来说读的压力明显大于写的压力。如果在OLTP环境直接开展各种分析,有以下问题需要考虑:
- 数据分析也是对数据进行读取操作,会让读取压力倍增;
- OLTP仅存储数周或数月的数据;
- 数据分散在不同系统不同表中,字段类型属性不统一;
当分析所涉及数据规模较小的时候,在业务低峰期时可以在OLTP系统上开展直接分析。但是为了更好的进行各种规模的数据分析,同时也不影响OLTP系统运行,此时需要构建一个集成统一的数据分析平台。
该平台的目的很简单:面向分析,支持分析。并且和OLTP系统解耦合。
基于这种需求,数据仓库的雏形开始在企业中出现了。
2、4 数据仓库的构建
如数仓定义所说,数仓是一个用于存储、分析、报告的数据系统,目的是构建面向分析的集成化数据环境。我们把这种面向分析、支持分析的系统称之为OLAP(联机分析处理)系统。数据仓库是OLAP一种。
中国人寿保险公司就可以基于分析决策需求,构建数仓平台。

3、数据仓库的主要特征
数据仓库是面向主题性(Subject-Oriented )、集成性(Integrated)、非易失性(Non-Volatile)和时变性(Time-Variant )数据集合,用以支持管理决策 。
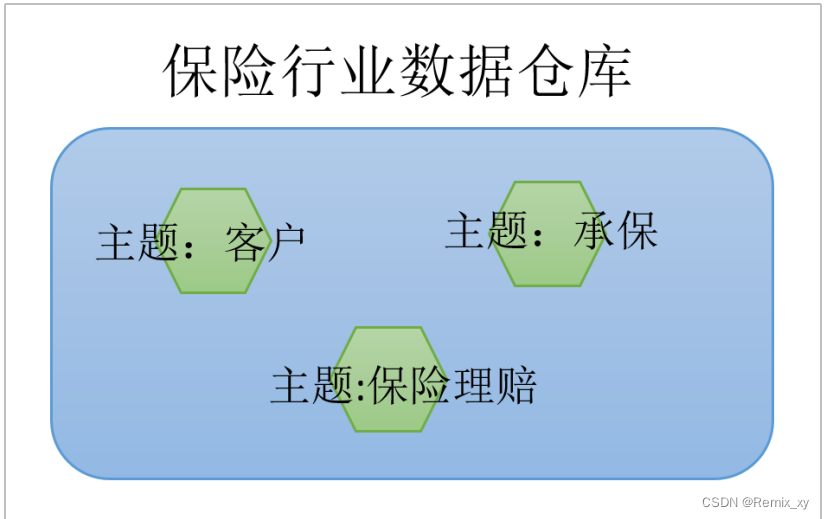
3、1 面向主题性
数据库中,最大的特点是面向应用进行数据的组织,各个业务系统可能是相互分离的。而数据仓库则是面向主题的。主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。在逻辑意义上,它是对应企业中某一宏观分析领域所涉及的分析对象。
操作型处理(传统数据)对数据的划分并不适用于决策分析。而基于主题组织的数据则不同,它们被划分为各自独立的领域,每个领域有各自的逻辑内涵但互不交叉,在抽象层次上对数据进行完整、一致和准确的描述。
3、2 集成性
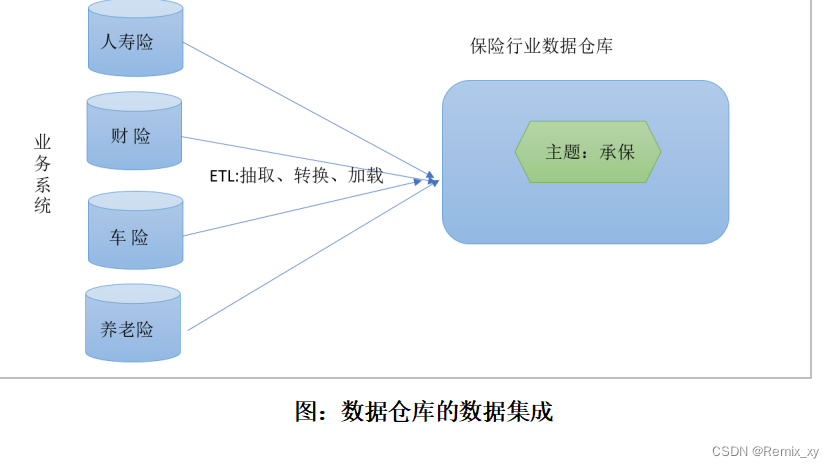
确定主题之后,就需要获取和主题相关的数据。当下企业中主题相关的数据通常会分布在多个操作型系统中,彼此分散、独立、异构。因此在数据进入数据仓库之前,必然要经过统一与综合,对数据进行抽取、清理、转换和汇总,这一步是数据仓库建设中最关键、最复杂的一步,所要完成的工作有:
(1)要统一源数据中所有矛盾之处,如字段的同名异义、异名同义、单位不统一、字长不一致,等等。
(2)进行数据综合和计算。数据仓库中的数据综合工作可以在从原有数据库抽取数据时生成,但许多是在数据仓库内部生成的,即进入数据仓库以后进行综合生成的。
下图说明了保险公司综合数据的简单处理过程,其中数据仓库中与“承保”主题有关的数据来自于多个不同的操作型系统。这些系统内部数据的命名可能不同,数据格式也可能不同。把不同来源的数据存储到数据仓库之前,需要去除这些不一致。
 3、3 非易失性
3、3 非易失性
数据仓库是分析数据的平台,而不是创造数据的平台。我们是通过数仓去分析数据中的规律,而不是去创造修改其中的规律。因此数据进入数据仓库后,它便稳定且不会改变。
操作型数据库主要服务于日常的业务操作,使得数据库需要不断地对数据实时更新,以便迅速获得当前最新数据,不至于影响正常的业务运作。在数据仓库中只要保存过去的业务数据,不需要每一笔业务都实时更新数据仓库,而是根据商业需要每隔一段时间把一批较新的数据导入数据仓库。
数据仓库的数据反映的是一段相当长的时间内历史数据的内容,是不同时点的数据库快照的集合,以及基于这些快照进行统计、综合和重组的导出数据。
数据仓库的用户对数据的操作大多是数据查询或比较复杂的挖掘,一旦数据进入数据仓库以后,一般情况下被较长时间保留。数据仓库中一般有大量的查询操作,但修改和删除操作很少。
3、4 时变性
数据仓库包含各种粒度的历史数据,数据可能与某个特定日期、星期、月份、季度或者年份有关。
虽然数据仓库的用户不能修改数据,但并不是说数据仓库的数据是永远不变的。分析的结果只能反映过去的情况,当业务变化后,挖掘出的模式会失去时效性。因此数据仓库的数据需要随着时间更新,以适应决策的需要。从这个角度讲,数据仓库建设是一个项目,更是一个过程 。
数据仓库的数据随时间的变化表现在以下几个方面。
(1)数据仓库的数据时限一般要远远长于操作型数据的数据时限。
(2)操作型系统存储的是当前数据,而数据仓库中的数据是历史数据。
(3)数据仓库中的数据是按照时间顺序追加的,它们都带有时间属性。
4、数据仓库、数据库、数据集市
4、1 OLTP、OLAP
操作型处理,叫联机事务处理OLTP(On-Line Transaction Processing),主要目标是做数据处理,它是针对具体业务在数据库联机的日常操作,通常对少数记录进行查询、修改。用户较为关心操作的响应时间、数据的安全性、完整性和并发支持的用户数等问题。传统的关系型数据库系统作为数据管理的主要手段,主要用于操作型处理。
分析型处理,叫联机分析处理OLAP(On-Line Analytical Processing),主要目标是做数据分析。一般针对某些主题的历史数据进行复杂的多维分析,支持管理决策。数据仓库是OLAP系统的一个典型示例,主要用于数据分析
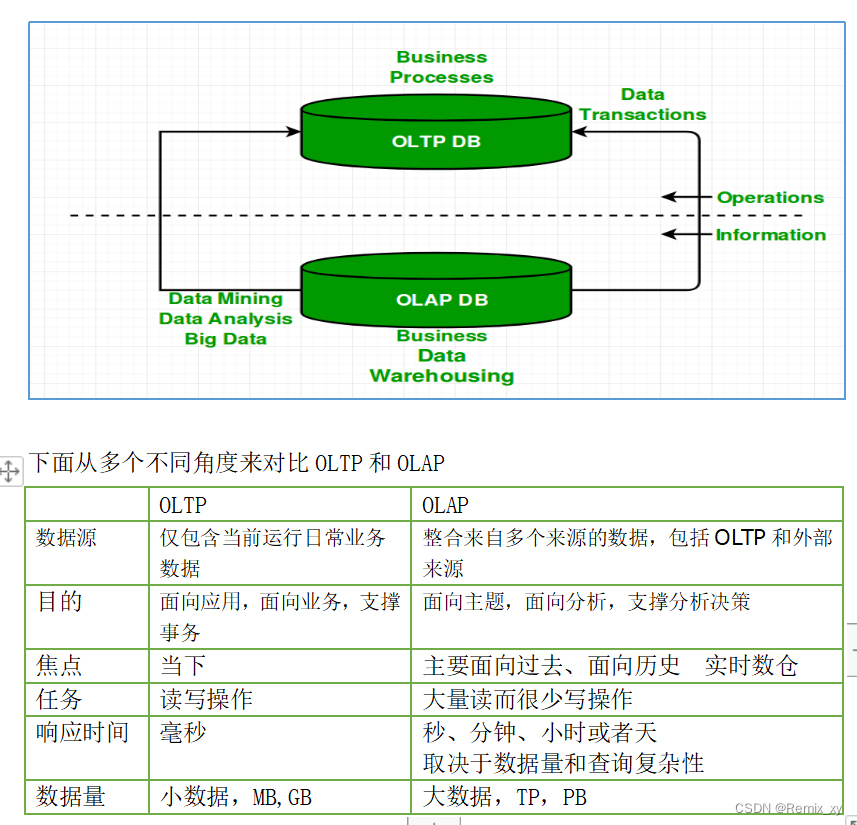
4、2 数据仓库、数据库
数据库与数据仓库的区别实际讲的是OLTP与OLAP的区别。
OLTP系统的典型应用就是RDBMS,也就是我们俗称的数据库,当然这里要特别强调此数据库表示的是关系型数据库,Nosql数据库并不在讨论范围内。
OLAP系统的典型应用就是DW,也就是我们俗称的数据仓库。
因此数据仓库和数据库的区别就很好掌握了。但是有几点需要着重强调:

- 数据仓库不是大型的数据库,虽然数据仓库存储数据规模大。
- 数据仓库的出现,并不是要取代数据库。
- 数据库是面向事务的设计,数据仓库是面向主题设计的。
- 数据库一般存储业务数据,数据仓库存储的一般是历史数据。
- 数据库是为捕获数据而设计,数据仓库是为分析数据而设计。
4、3 数据仓库、数据集市
数据仓库是面向整个集团组织的数据,数据集市是面向单个部门使用的。可以认为数据集市是数据仓库的子集,也有人把数据集市叫做小型数据仓库。数据集市通常只涉及一个主题领域,例如市场营销或销售。因为它们较小且更具体,所以它们通常更易于管理和维护,并具有更灵活的结构。
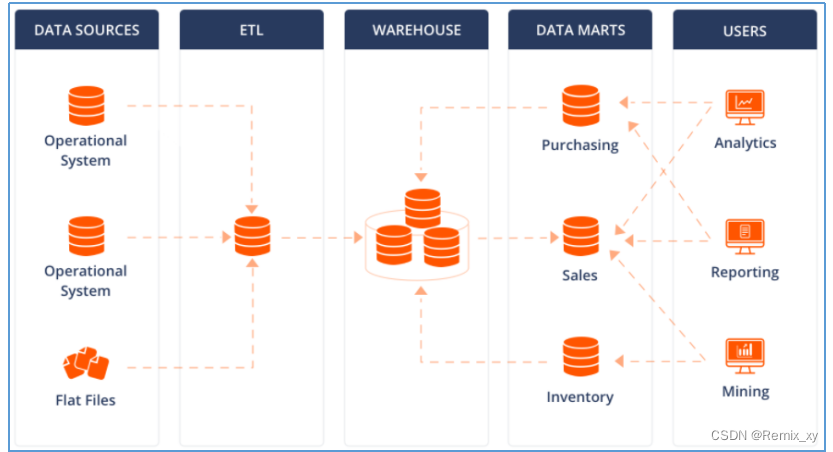
比如上图所示:
各种操作型系统数据和包括文件在内的等其他数据作为数据源,经过ETL(抽取转换加载)填充到数据仓库中;
数据仓库中有不同主题数据,数据集市则根据部门特点面向指定主题,比如Purchasing(采购)、Sales(销售)、Inventory(库存);
用户可以基于主题数据开展各种应用:数据分析、数据报表、数据挖掘。
5、数据仓库分层架构
5、1 数仓分层思想和标准
数据仓库的特点是本身不生产数据,也不最终消费数据。按照数据流入流出数仓的过程进行分层就显得水到渠成。
数据分层每个企业根据自己的业务需求可以分成不同的层次,但是最基础的分层思想,理论上数据分为三个层,操作型数据层(ODS)、数据仓库层(DW)和数据应用层(DA)。
企业在实际运用中可以基于这个基础分层之上添加新的层次,来满足不同的业务需求
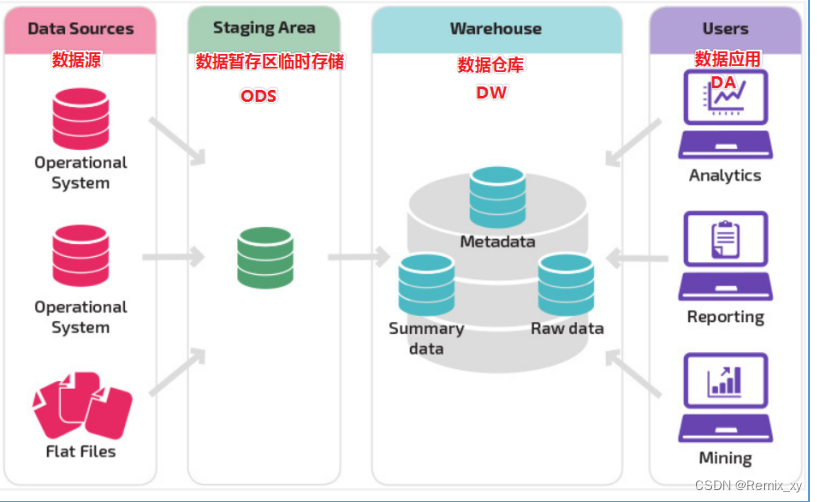
5、2 阿里巴巴数仓三层架构
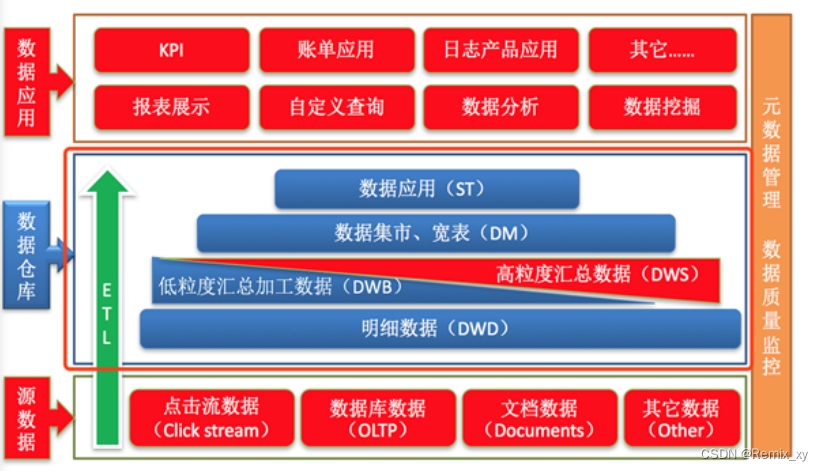
1、ODS层(Operation Data Store)
直译:操作型数据层。也称之为源数据层、数据引入层、数据暂存层、临时缓存层。此层存放未经过处理的原始数据至数据仓库系统,结构上与源系统保持一致,是数据仓库的数据准备区。主要完成基础数据引入到数仓的职责,和数据源系统进行解耦合,同时记录基础数据的历史变化。
2、DW层(Data Warehouse)
数据仓库层。内部具体包括DIM维度表、DWD和DWS,由ODS层数据加工而成。主要完成数据加工与整合,建立一致性的维度,构建可复用的面向分析和统计的明细事实表,以及汇总公共粒度的指标。
公共维度层(DIM):基于维度建模理念思想,建立整个企业一致性维度。
公共汇总粒度事实层(DWS、DWB):以分析的主题对象作为建模驱动,基于上层的应用和产品的指标需求,构建公共粒度的汇总指标事实表,以宽表化手段物理化模型
明细粒度事实层(DWD): 将明细事实表的某些重要维度属性字段做适当冗余,即宽表化处理。
3、数据应用层(DA或ADS)
面向最终用户,面向业务定制提供给产品和数据分析使用的数据。包括前端报表、分析图表、KPI、仪表盘、OLAP专题、数据挖掘等分析。
5、3 ETL 和 ELT
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extra, 转化Transfer, 装载Load)的过程。但是在实际操作中将数据加载到仓库却产生了两种不同做法:ETL和ELT。Extract,Transform,Load,ETL
首先从数据源池中提取数据,这些数据源通常是事务性数据库。数据保存在临时暂存数据库中。然后执行转换操作,将数据结构化并转换为适合目标数据仓库系统的形式。然后将结构化数据加载到仓库中,以备分析。
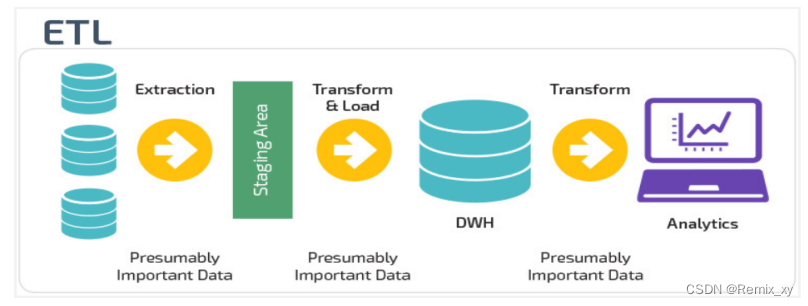
Extract,Load,Transform ,ELT
使用ELT,数据在从源数据池中提取后立即加载。没有临时数据库,这意味着数据会立即加载到单一的集中存储库中。数据在数据仓库系统中进行转换,以便与商业智能工具和分析一起使用。大数据时代的数仓这个特点很明显。

5、4 为什么要分层
分层的主要原因是在管理数据的时候,能对数据有一个更加清晰的掌控,详细来讲,主要有下面几个原因:
1、清晰数据结构
每一个数据分层都有它的作用域,在使用表的时候能更方便地定位和理解。
2、数据血缘追踪
简单来说,我们最终给业务呈现的是一个能直接使用业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。
3、减少重复开发
规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。
4、把复杂问题简单化
将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
5、屏蔽原始数据的异常
屏蔽业务的影响,不必改一次业务就需要重新接入数据
6、案列:美团点评酒旅数据仓库建设实践
下面通过一线互联网企业真实的数仓建设实践案例,来从宏观层面感受
- 数仓面向主题分析的特点
- 在企业中数仓是一个不断维护的工程。
- 数仓分层并不局限于经典3层,可以根据自身需求进行调整
- 没有好的架构,只有适合自己业务需求的架构
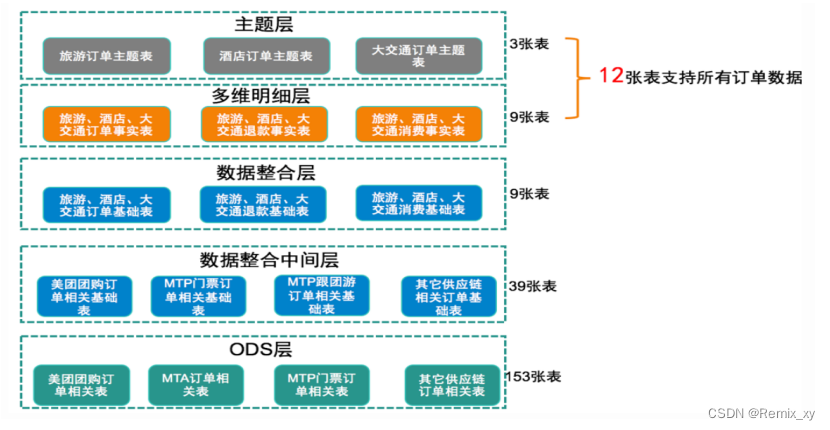
6、1 美团数仓技术架构:架构变迁
在美团点评酒旅事业群内,业务由传统的团购形式转向预订、直连等更加丰富的产品形式,业务系统也在迅速的迭代变化,这些都对数据仓库的扩展性、稳定性、易用性提出了更高要求。基于此,美团采取了分层次、分主题的方式不断优化并调整层次结构,下图展示了技术架构的变迁。

第一代数仓模型层次中,由于当时美团整体的业务系统所支持的产品形式比较单一(团购),业务系统中包含了所有业务品类的数据,所以由平台的角色来加工数据仓库基础层是非常合适的,平台统一建设,支持各个业务线使用,所以在本阶段中酒旅只是建立了一个相对比较简单的数据集市。
第二代数仓模型层次的建设,由建设数据集市的形式转变成了直接建设酒旅数据仓库,成为了酒旅自身业务系统数据的唯一加工者。
随着美团和点评融合,同时酒旅自身的业务系统重构的频率也相对较高,对第二代数仓模型稳定性造成了非常大的影响,原本的维度模型非常难适配这么迅速的变化。核心问题是在用业务系统和业务线关系错综复杂,业务系统之间差异性明显且变更频繁。
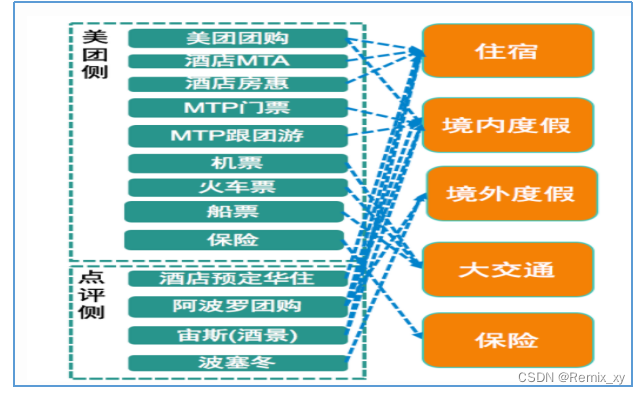
于是在ODS与多维明细层中间加入了数据整合层,参照Bill Inmon所提出的企业信息工厂建设的模式,基本按照三范式的原则来进行数据整合,由业务驱动调整成了由技术驱动的方式来建设数据仓库基础层。
使用本基础层的最根本出发点还是在于美团的供应链、业务、数据它们本身的多样性,如果业务、数据相对比较单一、简单,本层次的架构方案很可能将不再适用。
6、2 美团数仓业务架构:主题建设
实际上在传统的一些如银行、制造业、电信、零售等行业里,都有一些比较成熟的模型,如耳熟能详的BDWM模型,它们都是经过一些具有相类似行业的企业在二三十年数据仓库建设中所积累的行业经验,不断的优化并通用化。
但美团所处的O2O行业本身就没有可借鉴的成熟的数据仓库主题以及模型,所以,在摸索建设两年的时间里,美团总结了下面比较适合现状的七大主题(后续可能还会新增)
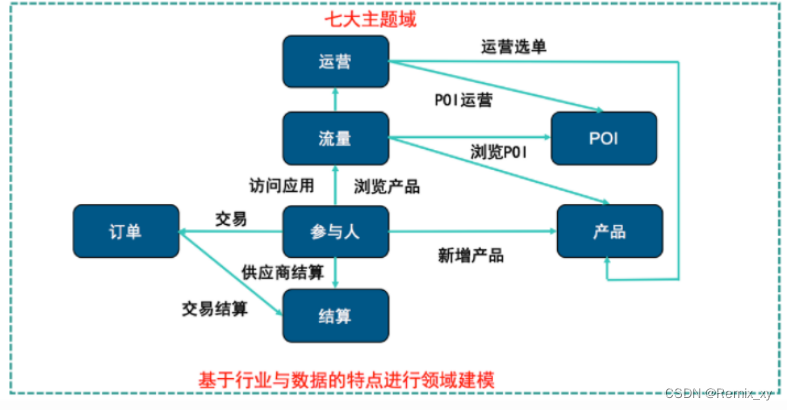
6、3 美团数仓整体架构
确定好技术和业务主题之后,数仓的整体架构就比较清晰了。美团酒旅数仓七个主题基本上都采用6层结构的方式来建设,划分主题更多是从业务的角度出发,而层次划分则是基于技术,实质上就是基于业务与技术的结合完成了整体的数据仓库架构。

比如,以订单主题为例。在订单主题的建设过程中,美团是按照由分到总的结构思路来进行建设,首先分供应链建设订单相关实体(数据整合中间层3NF),然后再进行适度抽象把分供应链的相关订单实体进行合并后生成订单实体(数据整合层3NF),后续在数据整合层的订单实体基础上再扩展部分维度信息来完成后续层次的建设。
7、总结
1、什么是数据仓库?
存储数据的仓库, 主要是用于存储过去既定发生的历史数据, 对这些数据进行数据分析的操作, 从而对未来提供决策支持
2、数据仓库最大的特点:
既不生产数据, 也不消耗数据, 数据来源于各个数据源
3、数据仓库的四大特征:
1) 面向于主题的: 面向于分析, 分析的内容是什么 什么就是我们的主题
2) 集成性: 数据是来源于各个数据源, 将各个数据源数据汇总在一起
3) 非易失性(稳定性): 存储在数据仓库中数据都是过去既定发生数据, 这些数据都是相对比较稳定的数据, 不会发生改变
4) 时变性: 随着的推移, 原有的分析手段以及原有数据可能都会出现变化(分析手动更换, 以及数据新增)。
4、ETL
ETL: 抽取 转换 加载
指的: 数据从数据源将数据灌入到ODS层, 以及从ODS层将数据抽取出来, 对数据进行转换处理工作, 最终将数据加载到DW层, 然后DW层对数据进行统计分析, 将统计分析后的数据灌入到DA层, 整个全过程都是属于ETL范畴
狭义上ETL: 从ODS层到DW层过程
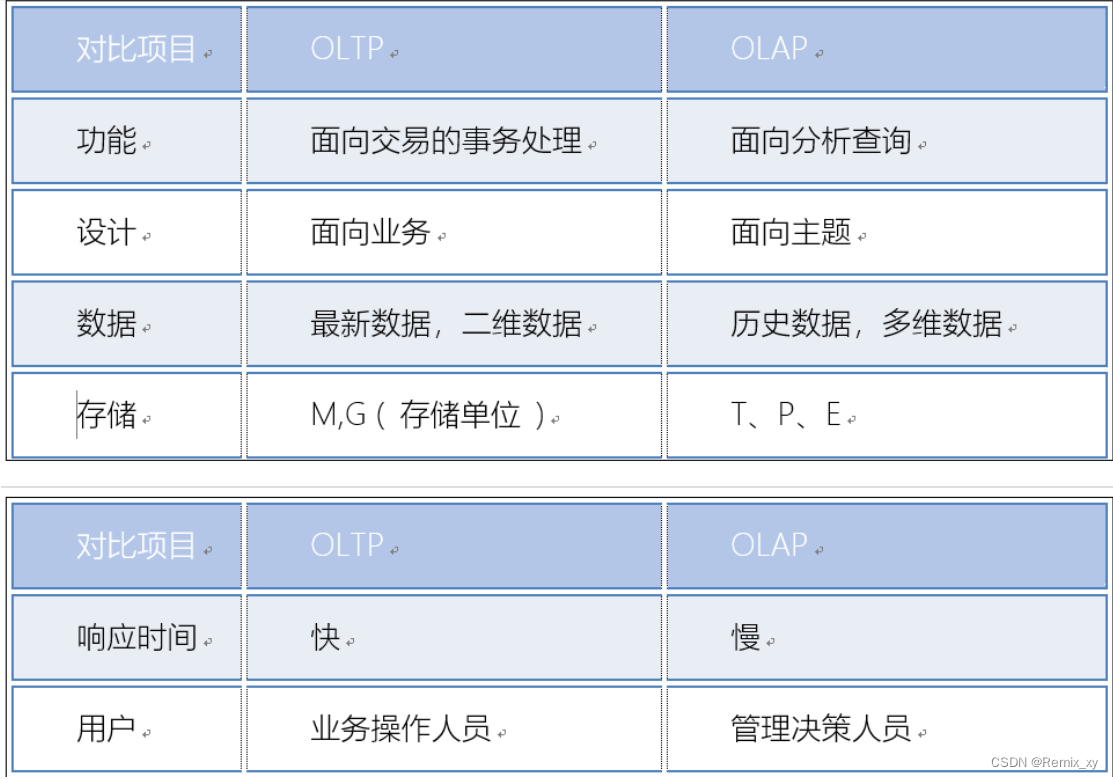
5、数据仓库和 数据库的区别
数据库(OLTP): 面向于事务(业务)的 , 主要是用于捕获数据 , 主要是存储的最近一段时间的业务数据, 交互性强 一般不允许出现数据冗余
数据仓库(OLAP): 面向于分析(主题)的 , 主要是用于分析数据, 主要是存储的过去历史数据 , 交互性较弱 可以允许出现一定的冗余。
6、数据仓库和数据集市:
数据仓库其实指的集团数据中心: 主要是将公司中所有的数据全部都聚集在一起进行相关的处理操作 (ODS层)
此操作一般和主题基本没有什么太大的关系
数据的集市(小型数据仓库): 在数据仓库基础之上, 基于主题对数据进行抽取处理分析工作, 形成最终分析的结果
一个数据仓库下, 可以有多个数据集市
7、维度分析
维度一般指的分析的角度, 看待一个问题的时候, 可以多个角度来看待, 而这些角度指的就是维度
比如: 有一份2020年订单数据, 请尝试分析
可以从时间, 地域 , 商品, 来源 , 用户....
维度的分类:
定性维度: 指的计算每天 每月 各个的维度 , 一般来说定性维度的字段都是放置在group by 中
定量维度: 指的统计某一个具体的维度或者某一个范围下信息, 比如说: 2020年度订单额, 统计20~30岁区间人群的人数 ,一般来说这种维度的字段都是放置在where中
维度的分层和分级: 本质上对维度进行细分的过程
比如按年统计:
按季度
按照月份
按照天
按照每个小时
比如: 按省份统计:
按市
按县
从实际分析中, 统计的层级越多, 意味统计的越细化 设置维度内容越多
维度的下钻和上卷: 以某一个维度为基准, 往细化统计的过程称为下钻, 往粗粒度称为上卷
比如: 按照 天统计, 如果需要统计出 小时, 指的就是下钻, 如果需要统计 季度 月 年, 称为上卷统计
从实际分析中, 下钻和上卷, 意味统计的维度变得更多了8、指标
指标指的衡量事务发展的标准, 就是度量值
常见的度量值: count() sum() max() min() avg() 还有一些 比例指标(转化率, 流失率, 同比..)
指标的分类:
绝对指标: 计算具体的值指标
count() sum() max() min() avg()
相对指标: 计算比率问题的指标
转化率, 流失率, 同比案列:
需求: 请求出在2020年度, 女性 未婚 年龄在18~25岁区间的用户每一天的订单量?
维度: 时间维度 , 性别, 婚姻状态, 年龄
定性维度: 每一天
定量维度: 2020年度,18~25岁,女性,未婚
指标: 订单量(绝对指标) --> count()
select day,count(1) from 表 where year ='2020' and age between 18 and 25 and 婚姻='未婚' and sex = '女性' group by day;9、数仓建模
数仓建模指的规定如何在hive中构建表, 数仓建模中主要提供两种理论来进行数仓建模操作: 三范式建模和维度建模理论
三范式建模: 主要是存在关系型数据库建模方案上, 主要规定了比如建表的每一个表都应该有一个主键, 数据要经历的避免冗余发生等等
维度建模: 主要是存在分析性数据库建模方案上, 主要一切以分析为目标, 只要是利于分析的建模, 都是OK的, 允许出现一定的冗余, 表也可以没有主键
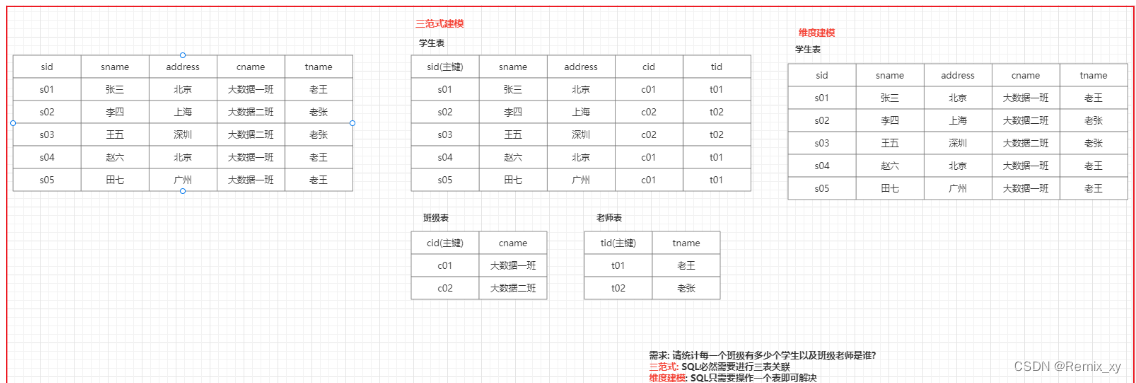
维度建模的两个核心概念:事实表和维度表
10、事实表
事实表: 事实表一般指的就是分析主题所对应的表,每一条数据用于描述一个具体的事实信息, 这些表一般都是一坨主键(外键)和描述事实字段的聚集
例如: 比如说统计2020年度订单销售情况
主题: 订单
相关表: 订单表(事实表)
思考: 在订单表, 一条数据, 是不是描述一个具体的订单信息呢? 是的
思考: 在订单表, 一般有那些字段呢?
订单的ID, 商品id,单价,购买的数量,下单时间, 用户id,商家id, 省份id, 市区id, 县id 商品价格...
进行统计分析的时候, 可以结合 商品维度, 用户维度, 商家维度, 地区维度 进行统计分析, 在进行统计分析的时候, 可能需要关联到其他的表(维度表)
注意:
一般需要计算的指标字段所在表, 都是事实表事实表的分类:
1) 事务事实表:
保存的是最原子的数据,也称“原子事实表”或“交易事实表”。沟通中常说的事实表,大多指的是事务事实表。
2) 周期快照事实表:
周期快照事实表以具有规律性的、可预见的时间间隔来记录事实,时间间隔如每天、每月、每年等等
周期表由事务表加工产生
3) 累计快照事实表:
完全覆盖一个事务或产品的生命周期的时间跨度,它通常具有多个日期字段,用来记录整个生命周期中的关键时间点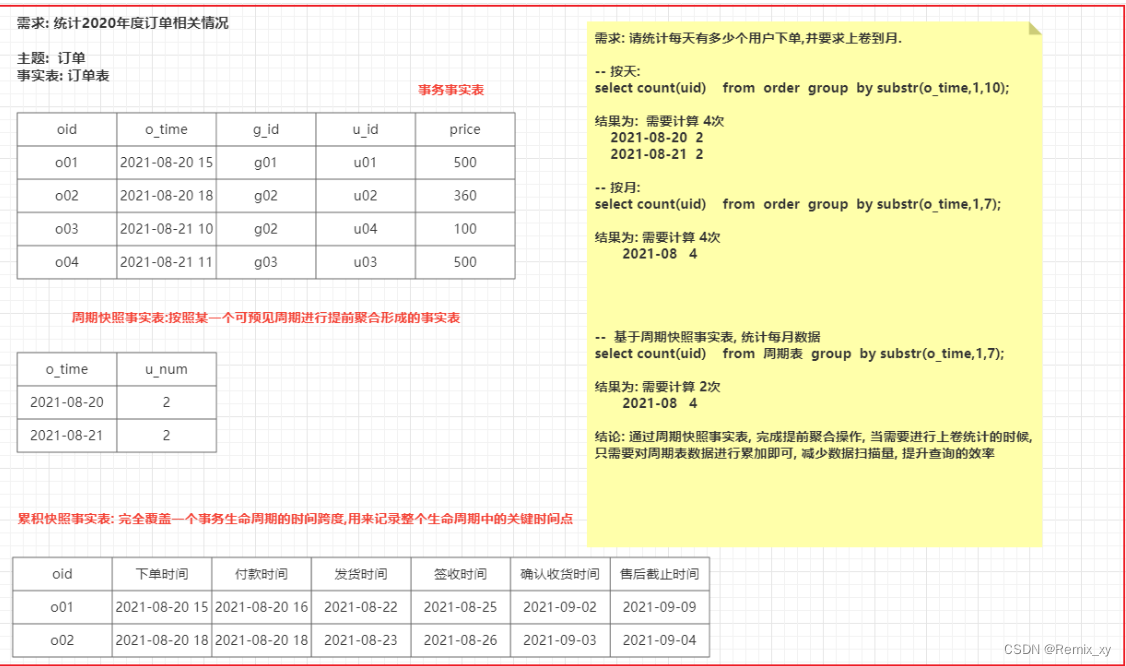
11、维度表
维度表: 指的在对事实表进行统计分析的时候, 基于某一个维度, 二这个维度信息可能其他表中, 而这些表就是维度表
维度表并不一定存在, 但是维度是一定存在:
比如: 根据用户维度进行统计, 如果在事实表只存储了用户id, 此时需要关联用户表, 这个时候就是维度表
比如: 根据用户维度进行统计, 如果在事实表不仅仅存储了用户id,还存储用户名称, 这个时候有用户维度, 但是不需要用户表的参与, 意味着没有这个维度表维度表的分类:
高基数维度表: 指的表中的数据量是比较庞大的, 而且数据也在发送的变化
例如: 商品表, 用户表
低基数维度表: 指的表中的数据量不是特别多, 一般在几十条到几千条左右,而且数据相对比较稳定
例如: 日期表,配置表,区域表12、维度建模的三种模型:
-
第一种: 星型模型
-
特点: 只有一个事实表, 那么也就意味着只有一个分析的主题, 在事实表的周围围绕了多个维度表, 维度表与维度表之间没有任何的依赖
-
反映数仓发展初期最容易产生模型
-
-
第二种: 雪花模型
-
特点: 只有一个事实表, 那么也就意味着只有一个分析的主题, 在事实表的周围围绕了多个维度表, 维度表可以接着关联其他的维度表
-
反映数仓发展出现了畸形产生模型, 这种模型一旦大量出现, 对后期维护是非常繁琐, 同时如果依赖层次越多, SQL分析的难度也会加大
-
此种模型在实际生产中,建议尽量减少这种模型产生
-
-
第三种: 星座模型
-
特点: 有多个事实表, 那么也就意味着有了多个分析的主题, 在事实表的周围围绕了多个维度表, 多个事实表在条件符合的情况下, 可以共享维度表
-
反映数仓发展中后期最容易产生模型
-
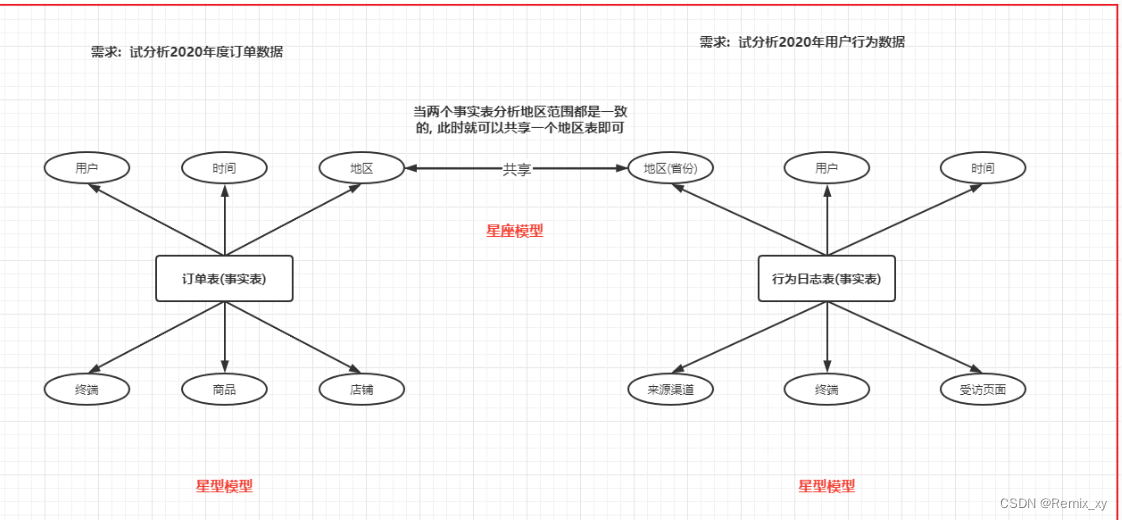
13、缓慢渐变维
解决问题: 解决历史变更数据是否需要维护的情况
-
SCD1: 直接覆盖, 不维护历史变化数据
-
主要适用于: 对错误数据处理
-
-
SCD2:不删除、不修改已存在的数据, 当数据发生变更后, 会添加一条新的版本记录的数据, 在建表的时候, 会多加两个字段(起始时间, 截止时间), 通过这两个字段来标记每条数据的起止时间 , 一般称为拉链表
-
好处: 适用于保存多个历史版本, 方便维护实现
-
弊端: 会造成数据冗余情况, 导致磁盘占用率提升
-
-
SCD3: 通过在增加列的方式来维护历史变化数据
-
好处: 减少数据的冗余, 适用于少量历史版本的记录以及磁盘空间不是特别充足情况
-
弊端: 无法记录更多的历史版本, 以及维护比较繁琐
-
面试题:
1) 在项目中, 如何实现历史变化维护工作的
2) 如何实现历史版本数据维护, 你有几种方案呢? 三种
3) 请简述如何实现拉链表智能推荐
Windows+Ubuntu双系统如何彻底删除Ubuntu操作系统_cmd卸载ubuntu-程序员宅基地
文章浏览阅读8.8k次,点赞27次,收藏103次。成功安装了Windows10+Ubuntu20.04双系统,还没怎么用ubuntu空间就小的可怜,连下载一个文件的空间都没有了,最终决定删除ubuntu,还原为原来的干净的Windows环境_cmd卸载ubuntu
漫步数学分析十三——路径连通_路径连续推导连续-程序员宅基地
文章浏览阅读2.2k次。第二个重要的主题是连通性,我们直观上知道想应用连通性到哪种集合上,然而,我们的直观在判断更复杂的集合时可能会失效,例如如果R2R^2中的集合为{(x,sin1/x)|x>0}∪{(0,y)|y∈[−1,1]}\{(x,\sin 1/x)|x>0\}\cup\{(0,y)|y\in[-1,1]\},那么它是连通的吗?如图???\ref{fig:3-3}所示,现在我们想用严格的定义来形式化这个概念。_路径连续推导连续
html中怎么获取搜索框中的值,input搜索框如何获取li标签中的值?-程序员宅基地
文章浏览阅读629次。这是个模糊搜索框,但是我要怎么做才能获取到下拉列表的中被填入input框中的值呢?比如说我输入pc,然会出来这些pc号码,我用键盘里的方向键或者鼠标点击其中一个pc4,这样input框就会显示pc4同时下拉菜单被收起来,问题就是我要怎么获取到这个input框中的pc4这个值呢???对了 我这些数据是从后台请求过来的,包括整个搜索框都是用js代码动态建立的,所以我本来是想用alert($("#sea..._获取input里面的值点击搜索按钮搜索相应的信息
ROS2学习笔记1--配置ros2环境_ubuntu ros2 domain_id-程序员宅基地
文章浏览阅读2.5k次,点赞7次,收藏15次。概要:这篇主要介绍是配置ros2环境.环境:ubuntu20.04,ros2-foxy,vscode2.1.1配置ros2环境(原文:https://docs.ros.org/en/foxy/Tutorials/Configuring-ROS2-Environment.html)>>教程>>配置ros2环境你正阅读的是ros2较老版本,但仍然支持的说明文档.想查看最新版本的信息,请看galactic版本链接( https://docs.ros.org/en/galactic/_ubuntu ros2 domain_id
浅谈对Promise的理解。_说说你对promise的理解-程序员宅基地
文章浏览阅读1k次,点赞16次,收藏21次。JS中用于处理异步操作的编程模式。一个Promise是一个代理,它代表一个创建Promise时不一定已知的值。它允许我们将处理的程序与异步操作的最终成功值或失败值原因想关联起来。这使得异步方法可以像同步方法一样返回值:异步方法不会立即返回最终值,而是返回一个Promise,以便在将来的某个时间点提供该值。_说说你对promise的理解
Win10家庭版怎么样添加hyper-v虚拟机功能_win10家庭版自带虚拟机怎么用-程序员宅基地
文章浏览阅读998次。下载文件链接: https://pan.baidu.com/s/1FiENCHjIMu-Unc1v36muAQ 提取码: v9q6打开配置就可以了_win10家庭版自带虚拟机怎么用
随便推点
语音匹配_什么是语音匹配?-程序员宅基地
文章浏览阅读2.1k次。语音匹配Google voice match feature has been rolled out. Now, your smart device will recognize you with the help of your voice. Bid adieu to complex configurations and authorizations while purchases and sw..._语音比对
WP-Syntax 插件使用方法-程序员宅基地
文章浏览阅读93次。技术博客中使用WP-Syntax将代码高亮是最常见的。而一段时间不用总会忘记每种语言的的pre标签的值。这里简单介绍下,WP-Syntax 是一个针对 Wordpress 的代码高亮插件,最大的优点是简单易用,兼容性非常好。由于安装好后,后台编辑器不会出现相应的按钮。所以网上有很多网友通过修改 \wp-includes\js\quicktags.js 这个文件来实现添加相应的按钮,方便编辑。..._wp-syntax设置
python生成随机IP,随机数字,随机日期,随机字符串_"print(\"0x%02x\" % secrets_generator.randint(0,25-程序员宅基地
文章浏览阅读4.2k次。随机IP:#定义4个0-255的随机数字,然后用.将四个随机数拼接起来m=random.randint(0,255)n=random.randint(0,255)x=random.randint(0,255)y=random.randint(0,255)randomIP=str(m)+’.’+str(n)+’.’+str(x)+’.’+str(y)随机数字:randomInt=ra..._"print(\"0x%02x\" % secrets_generator.randint(0,255), end="
路由器重温——WAN接入/互联-DCC配置管理2_dialer-rule-程序员宅基地
文章浏览阅读2k次,点赞3次,收藏5次。配置DCC拨号接口属性拨号接口(包括物理拨号接口和Dialer接口)一旦创建,就会被赋予一系列属性参数的缺省值,因此本项配置任务为可选。①链路空闲时间设置当链路空闲超过了指定时间后,DCC将断开链路。这个空闲时间也即是链路中不存在符合拨号访问控制列表的permit条件的报文传送时间。②下次呼叫发起前的链路断开时间当DCC呼叫链路因故障或挂断等原因导致进入断开状态,必须经过指定时间后才能建立新的拨号连接(即进行下一次呼叫的间隔时间),从而避免对端PBX设备过载。③接口竞争时的链路空闲时_dialer-rule
上百套springboot,python,ssm和小程序毕业设计作品(1)-程序员宅基地
文章浏览阅读692次,点赞9次,收藏11次。不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~给大家准备的学习资料包括但不限于:Python 环境、pycharm编辑器/永久激活/翻译插件python 零基础视频教程Python 界面开发实战教程Python 爬虫实战教程Python 数据分析实战教程python 游戏开发实战教程Python 电子书100本。
Java经典面试(三)_map<integer, int[]> positions = memorytest(numbers-程序员宅基地
文章浏览阅读500次。Java经典面试(三)一、java基础字符串常量Java内部加载-上二、JUC三、Spring四、Redis五、补充和总结一、java基础字符串常量Java内部加载-上代码:public class StringPoolDemo { public static void main(String[] args) { String str1 = new StringBuffer("mei").append("tuan").toString(); System.ou_map positions = memorytest(numbers)