python nltk 7 从文本提取信息_nltk 信息提取 python-程序员宅基地
7 从文本提取信息
英文文档 http://www.nltk.org/book/
中文文档 https://www.bookstack.cn/read/nlp-py-2e-zh/0.md
以下编号按个人习惯
Extracting Information from Text(从文本提取信息)
信息提取系统的典型结构:断句、分词、词性标注、搜索特定类型的实体、寻找指定关系
1 Information Extraction(信息提取)
首先,使用句子分段器将文档的原始文本分割成句子,然后使用记号赋予器将每个句子进一步细分为单词。接下来,用词性标记标记每个句子。以nltk中的默认工具为例,将句子分段器、分词器、词性标记器连接。
def ie_preprocess(document):
# nltk 默认的句子分段器
sentences = nltk.sent_tokenize(document)
# nltk默认分词器
sentences = [nltk.word_tokenize(sent) for sent in sentences]
# nltk默认词性标记
sentences = [nltk.pos_tag(sent) for sent in sentences]
之后进行命名实体检测。
2 Chunking(词块划分)
词块划分是实体识别的基本技术,分割和标注多词符的序列。
2.1 Noun Phrase Chunking(名词短语词块划分)
使用正则表达式来定义一个语法,来进行名词短语词块的划分
# 名词短语词块划分
def noun_phrase_chunking():
sentence = [("the", "DT"), ("little", "JJ"), ("yellow", "JJ"), ("dog", "NN"), ("barked", "VBD"), ("at", "IN"),
("the", "DT"), ("cat", "NN")]
# 语法。正则表达式规则。可选限定词(DT)后跟任意数量的形容词(JJ)和一个名词(NN)时,形成一个NP块
grammar = "NP:{<DT>?<JJ>*<NN>}"
# 创建一个块解析器
cp = nltk.RegexpParser(grammar)
# 测试。查看结果
result = cp.parse(sentence)
print(result)
result.draw()
2.2 Exploring Text Corpora(用正则表达式进行词块划分)
使用RegexpParser创建一个词块划分器,并使用正则表达式指定规则。一个正则表达式字符串中,可以写多个正则表达式,词块划分器轮流应用其规则,依次的更新词块结构,直到所有规则都被调用完,返回划分完的词块结构。当匹配重叠时,最左边的匹配优先。
# 用正则表达式进行词块划分
def chunking_with_regular_expressions():
# 表达式1 划分一个可选限定词或所有格代名词,0或多个形容词,一个名词
# 表达式2 划分一个或多个专有名词
grammar = r"""
NP: {<DT|PP\$>?<JJ>*<NN>} # chunk determiner/possessive, adjectives and noun
{<NNP>+} # chunk sequences of proper nouns
"""
cp = nltk.RegexpParser(grammar)
sentence = [("Rapunzel", "NNP"), ("let", "VBD"), ("down", "RP"), ("her", "PP$"), ("long", "JJ"), ("golden", "JJ"),
("hair", "NN")]
# 重叠匹配则按照左边匹配优先
print(cp.parse(sentence))
词缝:一个不包含在词块中的一个词符序列。以下划线部分就是一个词缝

3 Developing and Evaluating Chunkers( 开发和评估词块划分器)
3.1 Simple Evaluation and Baselines(简单的评估和基准)
词块划分器可使用evaluate()方法来评估一个划分器的性能好坏。
下面学习使用一元标注器建立一个词块划分器。但不是尝试确定每个词的正确的词性标记,而是根据每个词的词性标记,尝试确定正确的词块标记。
# 使用一元标注器建立一个词块划分器。根据每个词的词性标记,尝试确定正确的词块标记。
class UnigramChunker(nltk.ChunkParserI):
# constructor
def __init__(self, train_sents):
# 将训练数据转换成适合训练标注器的形式。tree2conlltags()方法将每个词块树映射到一个三元组(word,tag,chunk)的列表
train_data = [[(t, c) for w, t, c in nltk.chunk.tree2conlltags(sent)]
for sent in train_sents]
# 训练一元分块器
# self.tagger = nltk.UnigramTagger(train_data)
# 训练二元分块器
self.tagger = nltk.BigramTagger(train_data)
# sentence为一个已标注的句子
def parse(self, sentence):
# 提取词性标记
pos_tags = [pos for (word, pos) in sentence]
# 使用标注器为词性标记 标注IOB词块
tagged_pos_tags = self.tagger.tag(pos_tags)
# 提取词块标记
chunktags = [chunktag for (pos, chunktag) in tagged_pos_tags]
# 将词块标记与原句组合
conlltags = [(word, pos, chunktag) for ((word, pos), chunktag)
in zip(sentence, chunktags)]
# 转换成词块树
return nltk.chunk.conlltags2tree(conlltags)
# 简单的评估和基准
def simple_evaluation_and_baselines():
test_sents = conll2000.chunked_sents('test.txt', chunk_types=['NP'])
train_sents = conll2000.chunked_sents('train.txt', chunk_types=['NP'])
# 调用UnigramChunker类,创建对象.分块器是几元的可以在该类构造器中改变
unigram_chunker = code_unigram_chunker.UnigramChunker(train_sents)
print(unigram_chunker.evaluate(test_sents))
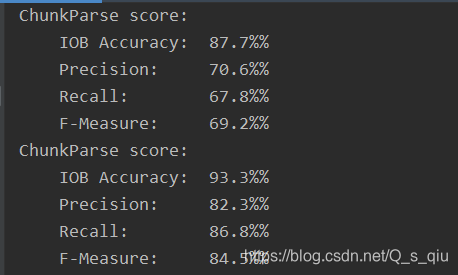
分别使用了一元标注器和二元标注器进行词块划分,评估结果依次如下,二元词块划分器的性能略高于一元词块划分器。
4 Recursion in Linguistic Structure(语言结构中的递归)
4.1 Building Nested Structure with Cascaded Chunkers( 用级联词块划分器构建嵌套结构)
通过创建包含递归规则的多阶段块语法,来构建任意深度的块结构。
正则表达式规则:名字短语、介词短语、动词短语、句子
def building_nested_structure_with_cascaded_chunkers():
# 四阶段的块语法。可用于创建深度最多为4的结构(深度不包括顶)
grammar = r"""
NP: {<DT|JJ|NN.*>+} # Chunk sequences of DT, JJ, NN
PP: {<IN><NP>} # Chunk prepositions followed by NP
VP: {<VB.*><NP|PP|CLAUSE>+$} # Chunk verbs and their arguments
CLAUSE: {<NP><VP>} # Chunk NP, VP
"""
cp = nltk.RegexpParser(grammar)
sentence = [("Mary", "NN"), ("saw", "VBD"), ("the", "DT"), ("cat", "NN"),
("sit", "VB"), ("on", "IN"), ("the", "DT"), ("mat", "NN")]
# 查看树图
print(cp.parse(sentence))
cp.parse(sentence).draw()
# 上述规则无法识别VP词块。解决方案是让词块划分器在他的模式中循环。loop指定循环次数。
cp_1 = nltk.RegexpParser(grammar, loop=2)
sentence_1 = [("John", "NNP"), ("thinks", "VBZ"), ("Mary", "NN"), ("saw", "VBD"), ("the", "DT"), ("cat", "NN"),
("sit", "VB"), ("on", "IN"), ("the", "DT"), ("mat", "NN")]
print(cp_1.parse(sentence_1))
5 Named Entity Recognition(命名实体识别)
命名实体是确切的名词短语,指示特定类型的个体例如组织、人、日期等。
NLTK提供了一个已经训练好的分类器,进行命名实体识别,可以通过函数nltk.ne_chunk()访问。
# 命名实体识别
def named_entity_recognition():
sent = nltk.corpus.treebank.tagged_sents()[22]
# 访问nltk提供的用来识别命名实体的分类器。binary设为True则命名实体被标记为NE,否则会添加类别标签如PERSON
ne_sent = nltk.ne_chunk(sent, binary=True)
ne_sent_1 = nltk.ne_chunk(sent)
print(ne_sent)
print(ne_sent_1)
6 Relation Extraction(关系提取)
关系提取是寻找指定类型的命名实体之间的关系。
过程:首先寻找所有(X,α,Y)形式的三元组,X,Y是指定类型的命名实体,α表示二者之间关系的字符串;然后使用正则表达式从α中提取查找的关系。
# 关系提取
def relation_extraction():
# 搜索包含词 in 的字符串。并且排除in后跟一个动名词
IN = re.compile(r'.*\bin\b(?!\b.+ing)')
for doc in nltk.corpus.ieer.parsed_docs('NYT_19980315'):
for rel in nltk.sem.extract_rels('ORG', 'LOC', doc, corpus='ieer', pattern=IN):
print(nltk.sem.rtuple(rel))
智能推荐
海康威视网络摄像头开发流程(五)------- 直播页面测试_ezuikit 测试的url-程序员宅基地
文章浏览阅读3.8k次。1、将下载好的萤石js插件,添加到SoringBoot项目中。位置可参考下图所示。(容易出错的地方,在将js插件在html页面引入时,发生路径错误的问题)所以如果对页面中引入js的路径不清楚,可参考下图所示存放路径。2、将ezuikit.js引入到demo-live.html中。(可直接将如下代码复制到你创建的html页面中)<!DOCTYPE html><html lan..._ezuikit 测试的url
如何确定组态王与多动能RTU的通信方式_组态王ua-程序员宅基地
文章浏览阅读322次。第二步,在弹出的对话框选择,设备驱动—>PLC—>莫迪康—>ModbusRTU—>COM,根据配置软件选择的协议选期期,这里以此为例,然后点击“下一步”。第四步,把使用虚拟串口打勾(GPRS设备),根据需要选择要生成虚拟口,这里以选择KVCOM1为例,然后点击“下一步”设备ID即Modbus地址(1-255) 使用DTU时,为下485接口上的设备地址。第六步,Modbus的从机地址,与配置软件相同,这里以1为例,点击“下一步“第五步,Modbus的从机地址,与配置软件相同,这里以1为例,点击“下一步“_组态王ua
npm超详细安装(包括配置环境变量)!!!npm安装教程(node.js安装教程)_npm安装配置-程序员宅基地
文章浏览阅读9.4k次,点赞22次,收藏19次。安装npm相当于安装node.js,Node.js已自带npm,安装Node.js时会一起安装,npm的作用就是对Node.js依赖的包进行管理,也可以理解为用来安装/卸载Node.js需要装的东西_npm安装配置
火车头采集器AI伪原创【php源码】-程序员宅基地
文章浏览阅读748次,点赞21次,收藏26次。大家好,小编来为大家解答以下问题,python基础训练100题,python入门100例题,现在让我们一起来看看吧!宝子们还在新手村练级的时候,不单要吸入基础知识,夯实自己的理论基础,还要去实际操作练练手啊!由于文章篇幅限制,不可能将100道题全部呈现在此除了这些,下面还有我整理好的基础入门学习资料,视频和讲解文案都很齐全,用来入门绝对靠谱,需要的自提。保证100%免费这不,贴心的我爆肝给大家整理了这份今天给大家分享100道Python练习题。大家一定要给我三连啊~
Linux Ubuntu 安装 Sublime Text (无法使用 wget 命令,使用安装包下载)_ubuntu 安装sumlime text打不开-程序员宅基地
文章浏览阅读1k次。 为了在 Linux ( Ubuntu) 上安装sublime,一般大家都会选择常见的教程或是 sublime 官网教程,然而在国内这种方法可能失效。为此,需要用安装包安装。以下就是使用官网安装包安装的教程。打开 sublime 官网后,点击右上角 download, 或是直接访问点击打开链接,即可看到各个平台上的安装包。选择 Linux 64 位版并下载。下载后,打开终端,进入安装..._ubuntu 安装sumlime text打不开
CrossOver for Mac 2024无需安装 Windows 即可以在 Mac 上运行游戏 Mac运行exe程序和游戏 CrossOver虚拟机 crossover运行免安装游戏包-程序员宅基地
文章浏览阅读563次,点赞13次,收藏6次。CrossOver24是一款类虚拟机软件,专为macOS和Linux用户设计。它的核心技术是Wine,这是一种在Linux和macOS等非Windows操作系统上运行Windows应用程序的开源软件。通过CrossOver24,用户可以在不购买Windows授权或使用传统虚拟机的情况下,直接在Mac或Linux系统上运行Windows软件和游戏。该软件还提供了丰富的功能,如自动配置、无缝集成和实时传输等,以实现高效的跨平台操作体验。
随便推点
一个用聊天的方式让ChatGPT写的线程安全的环形List_为什么gpt一写list就卡-程序员宅基地
文章浏览阅读1.7k次。一个用聊天的方式让ChatGPT帮我写的线程安全的环形List_为什么gpt一写list就卡
Tomcat自带的设置编码Filter-程序员宅基地
文章浏览阅读336次。我们在前面的文章里曾写过Web应用中乱码产生的原因和处理方式,旧文回顾:深度揭秘乱码问题背后的原因及解决方式其中我们提到可以通过Filter的方式来设置请求和响应的encoding,来解..._filterconfig selectencoding
javascript中encodeURI和decodeURI方法使用介绍_js encodeur decodeurl-程序员宅基地
文章浏览阅读651次。转自:http://www.jb51.net/article/36480.htmencodeURI和decodeURI是成对来使用的,因为浏览器的地址栏有中文字符的话,可以会出现不可预期的错误,所以可以encodeURI把非英文字符转化为英文编码,decodeURI可以用来把字符还原回来_js encodeur decodeurl
Android开发——打包apk遇到The destination folder does not exist or is not writeable-程序员宅基地
文章浏览阅读1.9w次,点赞6次,收藏3次。前言在日常的Android开发当中,我们肯定要打包apk。但是今天我打包的时候遇到一个很奇怪的问题Android The destination folder does not exist or is not writeable,大意是目标文件夹不存在或不可写。出现问题的原因以及解决办法上面有说报错的中文大意是:目标文件夹不存在或不可写。其实问题就在我们的打包界面当中图中标红的Desti..._the destination folder does not exist or is not writeable
Eclipse配置高大上环境-程序员宅基地
文章浏览阅读94次。一、配置代码编辑区的样式 <1>打开Eclipse,Help —> Install NewSoftware,界面如下: <2>点击add...,按下图所示操作: name:随意填写,Location:http://eclipse-color-th..._ecplise高大上设置
Linux安装MySQL-5.6.24-1.linux_glibc2.5.x86_64.rpm-bundle.tar_linux mysql 安装 mysql-5.6.24-1.linux_glibc2.5.x86_6-程序员宅基地
文章浏览阅读2.8k次。一,下载mysql:http://dev.mysql.com/downloads/mysql/; 打开页面之后,在Select Platform:下选择linux Generic,如果没有出现Linux的选项,请换一个浏览器试试。我用的谷歌版本不可以,换一个别的浏览器就行了,如果还是不行,需要换一个翻墙的浏览器。 二,下载完后解压缩并放到安装文件夹下: 1、MySQL-client-5.6.2_linux mysql 安装 mysql-5.6.24-1.linux_glibc2.5.x86_64.rpm-bundle