附源码|paddle paddle实现猫狗识别_paddle 犬只识别-程序员宅基地
技术标签: python 深度学习 paddle paddle
本文是基于paddle paddle采用CNN实现猫狗识别案例。
author:小黄
缓慢而坚定的生长
图像分类是根据图像的语义信息将不同类别图像区分开来,是计算机视觉中重要的基本问题
猫狗分类属于图像分类中的粗粒度分类问题
step1.数据准备
#导入需要的包
import paddle as paddle
import paddle.fluid as fluid
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import os
(1)数据集介绍
我们使用CIFAR10数据集。CIFAR10数据集包含60,000张32x32的彩色图片,10个类别,每个类包含6,000张。其中50,000张图片作为训练集,10000张作为验证集。这次我们只对其中的猫和狗两类进行预测。
(2)train_reader和test_reader
paddle.dataset.cifar.train10()和test10()分别获取cifar训练集和测试集
paddle.reader.shuffle()表示每次缓存BUF_SIZE个数据项,并进行打乱
paddle.batch()表示每BATCH_SIZE组成一个batch
(3)数据集下载
由于本次实践的数据集稍微比较大,以防出现不好下载的问题,为了提高效率,可以用下面的代码进行数据集的下载。
#!mkdir -p /home/aistudio/.cache/paddle/dataset/cifar/
#!wget “http://ai-atest.bj.bcebos.com/cifar-10-python.tar.gz” -O cifar-10-python.tar.gz
#!mv cifar-10-python.tar.gz /home/aistudio/.cache/paddle/dataset/cifar/
BATCH_SIZE = 128
#用于训练的数据提供器
train_reader = paddle.batch(
paddle.reader.shuffle(paddle.dataset.cifar.train10(),
buf_size=BATCH_SIZE * 100),
batch_size=BATCH_SIZE)
#用于测试的数据提供器
test_reader = paddle.batch(
paddle.dataset.cifar.test10(),
batch_size=BATCH_SIZE)
Step2.网络配置
(1)网络搭建
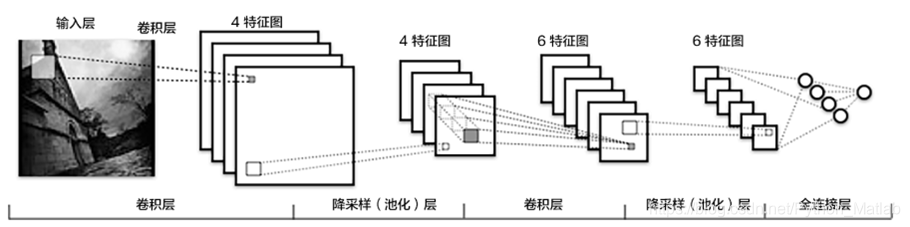
在CNN模型中,卷积神经网络能够更好的利用图像的结构信息。下面定义了一个较简单的卷积神经网络。显示了其结构:输入的二维图像,先经过两次卷积层到池化层,再经过全连接层,最后使用softmax分类作为输出层。
池化是非线性下采样的一种形式,主要作用是通过减少网络的参数来减小计算量,并且能够在一定程度上控制过拟合。通常在卷积层的后面会加上一个池化层。paddlepaddle池化默认为最大池化。是用不重叠的矩形框将输入层分成不同的区域,对于每个矩形框的数取最大值作为输出
def convolutional_neural_network(img):
# 第一个卷积-池化层
conv_pool_1 = fluid.nets.simple_img_conv_pool(
input=img, # 输入图像
filter_size=5, # 滤波器的大小
num_filters=20, # filter 的数量。它与输出的通道相同
pool_size=2, # 池化核大小2*2
pool_stride=2, # 池化步长
act="relu") # 激活类型
# 第二个卷积-池化层
conv_pool_2 = fluid.nets.simple_img_conv_pool(
input=conv_pool_1,
filter_size=5,
num_filters=50,
pool_size=2,
pool_stride=2,
act="relu")
# 以softmax为激活函数的全连接输出层,10类数据输出10个数字
prediction = fluid.layers.fc(input=conv_pool_2, size=10, act='softmax')
return prediction
(2)定义数据
#定义输入数据
data_shape = [3, 32, 32]
images = fluid.layers.data(name='images', shape=data_shape, dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
(3)获取分类器
# 获取分类器,用cnn进行分类
predict = convolutional_neural_network(images
(4)定义损失函数和准确率
这次使用的是交叉熵损失函数,该函数在分类任务上比较常用。
定义了一个损失函数之后,还有对它求平均值,因为定义的是一个Batch的损失值。
同时我们还可以定义一个准确率函数,这个可以在我们训练的时候输出分类的准确率。
# 获取损失函数和准确率
cost = fluid.layers.cross_entropy(input=predict, label=label) # 交叉熵
avg_cost = fluid.layers.mean(cost) # 计算cost中所有元素的平均值
acc = fluid.layers.accuracy(input=predict, label=label) #使用输入和标签计算准确率
(5)定义优化方法
这次我们使用的是Adam优化方法,同时指定学习率为0.001
# 定义优化方法
optimizer =fluid.optimizer.Adam(learning_rate=0.001)
optimizer.minimize(avg_cost)
print("完成")
在上述模型配置完毕后,得到两个fluid.Program:fluid.default_startup_program() 与fluid.default_main_program() 配置完毕了。
参数初始化操作会被写入fluid.default_startup_program()
fluid.default_main_program()用于获取默认或全局main program(主程序)。该主程序用于训练和测试模型。fluid.layers 中的所有layer函数可以向 default_main_program 中添加算子和变量。default_main_program 是fluid的许多编程接口(API)的Program参数的缺省值。例如,当用户program没有传入的时候, Executor.run() 会默认执行 default_main_program 。
Step3.模型训练 and Step4.模型评估
(1)创建Executor
首先定义运算场所 fluid.CPUPlace()和 fluid.CUDAPlace(0)分别表示运算场所为CPU和GPU
Executor:接收传入的program,通过run()方法运行program。
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
(2)定义数据映射器
DataFeeder 负责将reader(读取器)返回的数据转成一种特殊的数据结构,使它们可以输入到 Executor
feeder = fluid.DataFeeder( feed_list=[images, label],place=place)
(3)定义绘制训练过程的损失值和准确率变化趋势的方法draw_train_process
iter=0
iters=[]
train_costs=[]
train_accs=[]
def draw_train_process(iters, train_costs, train_accs):
title="training costs/training accs"
plt.title(title, fontsize=24)
plt.xlabel("iter", fontsize=14)
plt.ylabel("cost/acc", fontsize=14)
plt.plot(iters, train_costs, color='red', label='training costs')
plt.plot(iters, train_accs, color='green', label='training accs')
plt.legend()
plt.grid()
plt.show()
(3)训练并保存模型
Executor接收传入的program,并根据feed map(输入映射表)和fetch_list(结果获取表) 向program中添加feed operators(数据输入算子)和fetch operators(结果获取算子)。 feed map为该program提供输入数据。fetch_list提供program训练结束后用户预期的变量。
每一个Pass训练结束之后,再使用验证集进行验证,并打印出相应的损失值cost和准确率acc。
EPOCH_NUM = 3
model_save_dir = "/home/aistudio/data/catdog.inference.model"
for pass_id in range(EPOCH_NUM):
# 开始训练
train_cost = 0
for batch_id, data in enumerate(train_reader()): #遍历train_reader的迭代器,并为数据加上索引batch_id
train_cost,train_acc = exe.run(program=fluid.default_main_program(),#运行主程序
feed=feeder.feed(data), #喂入一个batch的数据
fetch_list=[avg_cost, acc]) #fetch均方误差和准确率
if batch_id % 100 == 0: #每100次batch打印一次训练、进行一次测试
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
iter=iter+BATCH_SIZE
iters.append(iter)
train_costs.append(train_cost[0])
train_accs.append(train_acc[0])
# 开始测试
test_costs = [] #测试的损失值
test_accs = [] #测试的准确率
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=fluid.default_main_program(), #运行测试程序
feed=feeder.feed(data), #喂入一个batch的数据
fetch_list=[avg_cost, acc]) #fetch均方误差、准确率
test_costs.append(test_cost[0]) #记录每个batch的误差
test_accs.append(test_acc[0]) #记录每个batch的准确率
test_cost = (sum(test_costs) / len(test_costs)) #计算误差平均值(误差和/误差的个数)
test_acc = (sum(test_accs) / len(test_accs)) #计算准确率平均值( 准确率的和/准确率的个数)
print('Test:%d, Cost:%0.5f, ACC:%0.5f' % (pass_id, test_cost, test_acc))
#保存模型
if not os.path.exists(model_save_dir):
os.makedirs(model_save_dir)
fluid.io.save_inference_model(model_save_dir,
['images'],
[predict],
exe)
print('训练模型保存完成!')
draw_train_process(iters, train_costs,train_accs)
Step5.模型预测
(1)创建预测用的Executor
infer_exe = fluid.Executor(place)
inference_scope = fluid.core.Scope()
(2)图片预处理
在预测之前,要对图像进行预处理。
首先将图片大小调整为32*32,接着将图像转换成一维向量,最后再对一维向量进行归一化处理。
def load_image(file):
#打开图片
im = Image.open(file)
im = im.convert('RGB')
#将图片调整为跟训练数据一样的大小 32*32, 设定ANTIALIAS,即抗锯齿.resize是缩放
im = im.resize((32, 32), Image.ANTIALIAS)
#建立图片矩阵 类型为float32
im = np.array(im).astype(np.float32)
#矩阵转置
im = im.transpose((2, 0, 1))
#将像素值从【0-255】转换为【0-1】
im = im / 255.0
#print(im)
im = np.expand_dims(im, axis=0)
# 保持和之前输入image维度一致
print('im_shape的维度:',im.shape)
return im
(3)开始预测
通过fluid.io.load_inference_model,预测器会从params_dirname中读取已经训练好的模型,来对从未遇见过的数据进行预测。
with fluid.scope_guard(inference_scope):
#从指定目录中加载 推理model(inference model)
[inference_program, # 预测用的program
feed_target_names, # 是一个str列表,它包含需要在推理 Program 中提供数据的变量的名称。
fetch_targets] = fluid.io.load_inference_model(model_save_dir,#fetch_targets:是一个 Variable 列表,从中我们可以得到推断结果。
infer_exe) #infer_exe: 运行 inference model的 executor
infer_path='/home/aistudio/data/dog.png'
img = Image.open(infer_path)
plt.imshow(img)
plt.show()
img = load_image(infer_path)
results = infer_exe.run(inference_program, #运行预测程序
feed={
feed_target_names[0]: img}, #喂入要预测的img
fetch_list=fetch_targets) #得到推测结果
print('results',results)
label_list = [
"airplane", "automobile", "bird", "cat", "deer", "dog", "frog", "horse",
"ship", "truck"
]
print("infer results: %s" % label_list[np.argmax(results[0])])
智能推荐
Docker 快速上手学习入门教程_docker菜鸟教程-程序员宅基地
文章浏览阅读2.5w次,点赞6次,收藏50次。官方解释是,docker 容器是机器上的沙盒进程,它与主机上的所有其他进程隔离。所以容器只是操作系统中被隔离开来的一个进程,所谓的容器化,其实也只是对操作系统进行欺骗的一种语法糖。_docker菜鸟教程
电脑技巧:Windows系统原版纯净软件必备的两个网站_msdn我告诉你-程序员宅基地
文章浏览阅读5.7k次,点赞3次,收藏14次。该如何避免的,今天小编给大家推荐两个下载Windows系统官方软件的资源网站,可以杜绝软件捆绑等行为。该站提供了丰富的Windows官方技术资源,比较重要的有MSDN技术资源文档库、官方工具和资源、应用程序、开发人员工具(Visual Studio 、SQLServer等等)、系统镜像、设计人员工具等。总的来说,这两个都是非常优秀的Windows系统镜像资源站,提供了丰富的Windows系统镜像资源,并且保证了资源的纯净和安全性,有需要的朋友可以去了解一下。这个非常实用的资源网站的创建者是国内的一个网友。_msdn我告诉你
vue2封装对话框el-dialog组件_<el-dialog 封装成组件 vue2-程序员宅基地
文章浏览阅读1.2k次。vue2封装对话框el-dialog组件_
MFC 文本框换行_c++ mfc同一框内输入二行怎么换行-程序员宅基地
文章浏览阅读4.7k次,点赞5次,收藏6次。MFC 文本框换行 标签: it mfc 文本框1.将Multiline属性设置为True2.换行是使用"\r\n" (宽字符串为L"\r\n")3.如果需要编辑并且按Enter键换行,还要将 Want Return 设置为 True4.如果需要垂直滚动条的话将Vertical Scroll属性设置为True,需要水平滚动条的话将Horizontal Scroll属性设_c++ mfc同一框内输入二行怎么换行
redis-desktop-manager无法连接redis-server的解决方法_redis-server doesn't support auth command or ismis-程序员宅基地
文章浏览阅读832次。检查Linux是否是否开启所需端口,默认为6379,若未打开,将其开启:以root用户执行iptables -I INPUT -p tcp --dport 6379 -j ACCEPT如果还是未能解决,修改redis.conf,修改主机地址:bind 192.168.85.**;然后使用该配置文件,重新启动Redis服务./redis-server redis.conf..._redis-server doesn't support auth command or ismisconfigured. try
实验四 数据选择器及其应用-程序员宅基地
文章浏览阅读4.9k次。济大数电实验报告_数据选择器及其应用
随便推点
灰色预测模型matlab_MATLAB实战|基于灰色预测河南省社会消费品零售总额预测-程序员宅基地
文章浏览阅读236次。1研究内容消费在生产中占据十分重要的地位,是生产的最终目的和动力,是保持省内经济稳定快速发展的核心要素。预测河南省社会消费品零售总额,是进行宏观经济调控和消费体制改变创新的基础,是河南省内人民对美好的全面和谐社会的追求的要求,保持河南省经济稳定和可持续发展具有重要意义。本文建立灰色预测模型,利用MATLAB软件,预测出2019年~2023年河南省社会消费品零售总额预测值分别为21881...._灰色预测模型用什么软件
log4qt-程序员宅基地
文章浏览阅读1.2k次。12.4-在Qt中使用Log4Qt输出Log文件,看这一篇就足够了一、为啥要使用第三方Log库,而不用平台自带的Log库二、Log4j系列库的功能介绍与基本概念三、Log4Qt库的基本介绍四、将Log4qt组装成为一个单独模块五、使用配置文件的方式配置Log4Qt六、使用代码的方式配置Log4Qt七、在Qt工程中引入Log4Qt库模块的方法八、获取示例中的源代码一、为啥要使用第三方Log库,而不用平台自带的Log库首先要说明的是,在平时开发和调试中开发平台自带的“打印输出”已经足够了。但_log4qt
100种思维模型之全局观思维模型-67_计算机中对于全局观的-程序员宅基地
文章浏览阅读786次。全局观思维模型,一个教我们由点到线,由线到面,再由面到体,不断的放大格局去思考问题的思维模型。_计算机中对于全局观的
线程间控制之CountDownLatch和CyclicBarrier使用介绍_countdownluach于cyclicbarrier的用法-程序员宅基地
文章浏览阅读330次。一、CountDownLatch介绍CountDownLatch采用减法计算;是一个同步辅助工具类和CyclicBarrier类功能类似,允许一个或多个线程等待,直到在其他线程中执行的一组操作完成。二、CountDownLatch俩种应用场景: 场景一:所有线程在等待开始信号(startSignal.await()),主流程发出开始信号通知,既执行startSignal.countDown()方法后;所有线程才开始执行;每个线程执行完发出做完信号,既执行do..._countdownluach于cyclicbarrier的用法
自动化监控系统Prometheus&Grafana_-自动化监控系统prometheus&grafana实战-程序员宅基地
文章浏览阅读508次。Prometheus 算是一个全能型选手,原生支持容器监控,当然监控传统应用也不是吃干饭的,所以就是容器和非容器他都支持,所有的监控系统都具备这个流程,_-自动化监控系统prometheus&grafana实战
React 组件封装之 Search 搜索_react search-程序员宅基地
文章浏览阅读4.7k次。输入关键字,可以通过键盘的搜索按钮完成搜索功能。_react search