大数据处理流程-程序员宅基地
大数据处理流程
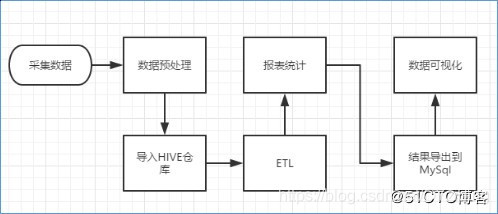
1. 数据处理流程
网站流量日志数据分析是一个纯粹的数据分析项目,其整体流程基本上就是依据数据的处理流程进行。有以下几个大的步骤:
1.1 数据采集
数据采集概念,目前行业会有两种解释:一是数据从无到有的过程(web服务器打印的日志、自定义采集的日志等)叫做数据采集;另一方面也有把通过使用Flume等工具把数据采集到指定位置的这个过程叫做数据采集。
关于具体含义要结合语境具体分析,明白语境中具体含义即可。
1.2 数据预处理
通过mapreduce程序对采集到的原始日志数据进行预处理,比如清洗,格式整理,滤除脏数据等,并且梳理成点击流模型数据。
1.3 数据入库
将预处理之后的数据导入到HIVE仓库中相应的库和表中。
1.4 数据分析
项目的核心内容,即根据需求开发ETL分析语句,得出各种统计结果。
1.5 数据展现
将分析所得数据进行数据可视化,一般通过图表进行展示。
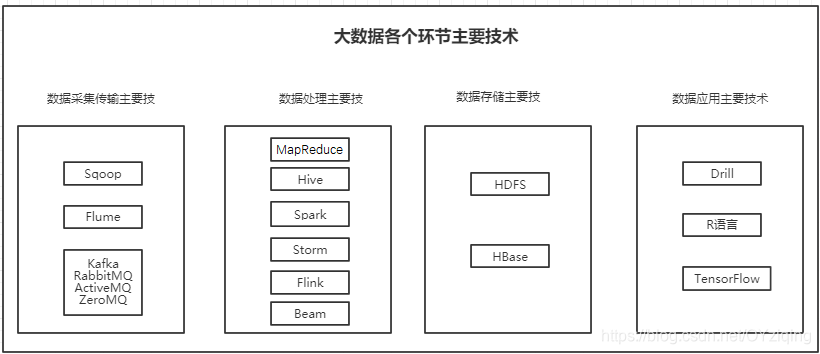
扩展:
1、数据处理主要技术
Sqoop:作为一款开源的离线数据传输工具,主要用于Hadoop(Hive) 与传统数据库(MySql,PostgreSQL)间的数据传递。它可以将一个关系数据库中数据导入Hadoop的HDFS中,也可以将HDFS中的数据导入关系型数据库中。
Flume:实时数据采集的一个开源框架,它是Cloudera提供的一个高可用用的、高可靠、分布式的海量日志采集、聚合和传输的系统。目前已经是Apache的顶级子项目。使用Flume可以收集诸如日志、时间等数据并将这些数据集中存储起来供下游使用(尤其是数据流框架,例如Storm)。和Flume类似的另一个框架是Scribe(FaceBook开源的日志收集系统,它为日志的分布式收集、统一处理提供一个可扩展的、高容错的简单方案)
Kafka:通常来说Flume采集数据的速度和下游处理的速度通常不同步,因此实时平台架构都会用一个消息中间件来缓冲,而这方面最为流行和应用最为广泛的无疑是Kafka。它是由LinkedIn开发的一个分布式消息系统,以其可以水平扩展和高吞吐率而被广泛使用。目前主流的开源分布式处理系统(如Storm和Spark等)都支持与Kafka 集成。Kafka是一个基于分布式的消息发布-订阅系统,特点是速度快、可扩展且持久。与其他消息发布-订阅系统类似,Kafka可在主题中保存消息的信息。生产者向主题写入数据,消费者从主题中读取数据。作为一个分布式的、分区的、低延迟的、冗余的日志提交服务。和Kafka类似消息中间件开源产品还包括RabbiMQ、ActiveMQ、ZeroMQ等。
MapReduce是Google公司的核心计算模型,它将运行于大规模集群上的复杂并行计算过程高度抽象为两个函数:map和reduce。MapReduce最伟大之处在于其将处理大数据的能力赋予了普通开发人员,以至于普通开发人员即使不会任何的分布式编程知识,也能将自己的程序运行在分布式系统上处理海量数据。
Hive:MapReduce将处理大数据的能力赋予了普通开发人员,而Hive进一步将处理和分析大数据的能力赋予了实际的数据使用人员(数据开发工程师、数据分析师、算法工程师、和业务分析人员)。Hive是由Facebook开发并贡献给Hadoop开源社区的,是一个建立在Hadoop体系结构上的一层SQL抽象。Hive提供了一些对Hadoop文件中数据集进行处理、查询、分析的工具。它支持类似于传统RDBMS的SQL语言的查询语言,一帮助那些熟悉SQL的用户处理和查询Hodoop在的数据,该查询语言称为Hive SQL。Hive SQL实际上先被SQL解析器解析,然后被Hive框架解析成一个MapReduce可执行计划,并按照该计划生产MapReduce任务后交给Hadoop集群处理。
Spark:尽管MapReduce和Hive能完成海量数据的大多数批处理工作,并且在打数据时代称为企业大数据处理的首选技术,但是其数据查询的延迟一直被诟病,而且也非常不适合迭代计算和DAG(有限无环图)计算。由于Spark具有可伸缩、基于内存计算能特点,且可以直接读写Hadoop上任何格式的数据,较好地满足了数据即时查询和迭代分析的需求,因此变得越来越流行。Spark是UC Berkeley AMP Lab(加州大学伯克利分校的 AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,它拥有Hadoop MapReduce所具有的优点,但不同MapReduce的是,Job中间输出结果可以保存在内存中,从而不需要再读写HDFS ,因此能更好适用于数据挖掘和机器学习等需要迭代的MapReduce算法。Spark也提供类Live的SQL接口,即Spark SQL,来方便数据人员处理和分析数据。Spark还有用于处理实时数据的流计算框架Spark Streaming,其基本原理是将实时流数据分成小的时间片段(秒或几百毫秒),以类似Spark离线批处理的方式来处理这小部分数据。
Storm:MapReduce、Hive和Spark是离线和准实时数据处理的主要工具,而Storm是实时处理数据的。Storm是Twitter开源的一个类似于Hadoop的实时数据处理框架。Storm对于实时计算的意义相当于Hadoop对于批处理的意义。Hadoop提供了Map和Reduce原语,使对数据进行批处理变得非常简单和优美。同样,Storm也对数据的实时计算提供了简单的Spout和Bolt原语。Storm集群表面上和Hadoop集群非常像,但是在Hadoop上面运行的是MapReduce的Job,而在Storm上面运行的是Topology(拓扑)。Storm拓扑任务和Hadoop MapReduce任务一个非常关键的区别在于:1个MapReduce Job最终会结束,而1一个Topology永远运行(除非显示的杀掉它,),所以实际上Storm等实时任务的资源使用相比离线MapReduce任务等要大很多,因为离线任务运行完就释放掉所使用的计算、内存等资源,而Storm等实时任务必须一直占有直到被显式的杀掉。Storm具有低延迟、分布式、可扩展、高容错等特性,可以保证消息不丢失,目前Storm, 类Storm或基于Storm抽象的框架技术是实时处理、流处理领域主要采用的技术。
Flink:在数据处理领域,批处理任务和实时流计算任务一般被认为是两种不同的任务,一个数据项目一般会被设计为只能处理其中一种任务,例如Storm只支持流处理任务,而MapReduce, Hive只支持批处理任务。Apache Flink是一个同时面向分布式实时流处理和批量数据处理的开源数据平台,它能基于同一个Flink运行时(Flink Runtime),提供支持流处理和批处理两种类型应用的功能。Flink在实现流处理和批处理时,与传统的一些方案完全不同,它从另一个视角看待流处理和批处理,将二者统一起来。Flink完全支持流处理,批处理被作为一种特殊的流处理,只是它的数据流被定义为有界的而已。基于同一个Flink运行时,Flink分别提供了流处理和批处理API,而这两种API也是实现上层面向流处理、批处理类型应用框架的基础。
2、数据存储主要技术
HDFS:Hadoop Distributed File System,简称FDFS,是一个分布式文件系统。它有一定高度的容错性和高吞吐量的数据访问,非常适合大规模数据集上的应用。HDFS提供了一个高容错性和高吞吐量的海量数据存储解决方案。在Hadoop的整个架构中,HDFS在MapReduce任务处理过程在中提供了对文件操作的和存储的的支持,MapReduce在HDFS基础上实现了任务的分发、跟踪和执行等工作,并收集结果,两者相互作用,共同完成了Hadoop分布式集群的主要任务。
HBase:HBase是一种构建在HDFS之上的分布式、面向列族的存储系统。在需要实时读写并随机访问超大规模数据集等场景下,HBase目前是市场上主流的技术选择。
HBase技术来源于Google论文《Bigtable :一个结构化数据的分布式存储系统》。如同Bigtable利用了Google File System提供的分布式数据存储方式一样,HBase在HDFS之上提供了类似于Bigtable的能力。
HBase解决了传递数据库的单点性能极限。实际上,传统的数据库解决方案,尤其是关系型数据库也可以通过复制和分区的方法来提高单点性能极限,但这些都是后知后觉的,安装和维护都非常复杂。
而HBase从另一个角度处理伸缩性的问题,即通过线性方式从下到上增加节点来进行扩展。
HBase 不是关系型数据库,也不支持SQL,它的特性如下:
1、大:一个表可以有上亿上,上百万列。
2、面向列:面向列表(簇)的存储和权限控制,列(簇)独立检索。
3、稀疏:为空(null)的列不占用存储空间,因此表可以设计的非常稀疏。
4、无模式::每一行都有一个可以排序的主键和任意多的列。列可以根据需求动态增加,同一张表中不同的行可以有截然不同的列。
5、数据多版本:每个单元的数据可以有多个版本,默认情况下,版本号字段分开,它是单元格插入时的时间戳。
6、数据类型单一:HBase中数据都是字符串,没有类型。
智能推荐
利用Python实现多元伯努利事件的朴素贝叶斯分类器_python手写实现伯努利贝叶斯分类器-程序员宅基地
文章浏览阅读2.2k次。前言本篇博客所写的算法对应于吴恩达教授的机器学习教程里的多元伯努利事件模型的朴素贝叶斯。多元伯努利事件模型的Python代码#!/usr/bin/env python# -*- coding: utf-8 -*-# @Time : 2018/9/415:55# @Author : DaiPuWei# E-Mail : [email protected]#..._python手写实现伯努利贝叶斯分类器
ipmitool常用命令详解_ipmitool命令详解-程序员宅基地
文章浏览阅读3.2w次,点赞18次,收藏219次。ipmitool命令ipmitool –I [open|lan|lanplus] commandOpenIPMI接口,command有以下项: raw:发送一个原始的IPMI请求,并且打印回复信息。 Lan:配置网络(lan)信道(channel) chassis :查看底盘的状态和设置电源 event:向BMC发送一个已经定义的事件(event),可用于测试配置的SNMP是否成功 mc:查看MC(..._ipmitool命令详解
java求数组中元素最大值最小值及其下标等相关问题_java、 编写两个方法,分别求出数组中最大和最小元素的下标。如果这样的元素个数大-程序员宅基地
文章浏览阅读9.6k次,点赞9次,收藏39次。功能需求:遍历数组,并求出数组中元素的最大元素,最小元素,及其相应的索引等问题,要求用方法完成. 思路:分别创建不同的方法,然后再调用方法.代码展示:public class Array{ public static void main(String[] args){ int[] arr={13,45,7,3,9,468,4589,76,4}; //声明数组并赋值..._java、 编写两个方法,分别求出数组中最大和最小元素的下标。如果这样的元素个数大
Linux(Ubuntu)中对音频批量转换格式MP3转WAV/PCM转WAV_ubuntu批量mp3转wav命令-程序员宅基地
文章浏览阅读2.2k次。1、批量将MP3格式音频转换成WAV格式利用ffmpeg工具,统一处理成16bit ,小端编码,单通道,16KHZ采样率的wav音频格式。首先新建Mp3ToWav.sh 文件以路径/home/XXX下音频处理为例,编辑如下代码段:#!/bin/bashfolder=/home/XXXfor file in $(find "$folder" -type f -iname "*.mp3..._ubuntu批量mp3转wav命令
用python+graphviz/networkx画目录结构树状图_networkx画树状图-程序员宅基地
文章浏览阅读1.3w次,点赞2次,收藏22次。想着用python绘制某目录的树状图,一开始想到了用grapgviz,因为去年离职的时候整理文档,用graphviz画过代码调用结构图。graphviz有一门自己的语言DOT,dot很简单,加点加边设置属性就这点东西,而且有python接口。我在ubuntu下,先要安装graphviz软件,官网有deb包,然后python安装pygraphviz模块。目标功能是输入一个路径,输出该路径下的_networkx画树状图
【绿色求索T1设备资产通1.5单机版】适用于资产密集型企业管理_求索t1设备资产通系统(单机版)注册码-程序员宅基地
文章浏览阅读899次。绿色求索T1设备资产通 1.5 单机版 [企业管理高价值设备资产的使用情况]下载软件大小:5.56MB软件语言:简体中文软件类别:软件授权:免费软件更新时间:2013-08-03 07:44:00应用平台:Win2K,WinXP,Win2003,Vista,Win7绿色软件下么官方地址:系统之家官网求索T1设备资产通 1.5 单机版 _求索t1设备资产通系统(单机版)注册码
随便推点
【C++ 项目设计】深入JSON处理与项目实践:C++中的高效设计与应用-程序员宅基地
文章浏览阅读220次。在`JSONHandler`中,我们定义了几个核心组件:- **JSON Parser (JSON 解析器)**:负责读取和解析JSON数据。- **JSON Writer (JSON 写入器)**:负责将JSON数据写入文件或其他输出流。- **JSON Manipulator (JSON 操作器)**:提供了一系列方法来修改、查询和操作JSON数据。这三个组件是`JSONHandler`的基石,它们确保了数据的正确读取、写入和操作。
Algorithm Gossip (20) 阿姆斯壮数_actan算法 c++-程序员宅基地
文章浏览阅读543次。Algorithm Gossip: 阿姆斯壮数_actan算法 c++
php中大量数据如何优化,如何对PHP导出的海量数据进行优化-程序员宅基地
文章浏览阅读429次。本篇文章的主要主要讲述的是对PHP导出的海量数据进行优化,具有一定的参考价值,有需要的朋友可以看看。导出数据量很大的情况下,生成excel的内存需求非常庞大,服务器吃不消,这个时候考虑生成csv来解决问题,cvs读写性能比excel高。测试表student 数据(大家可以脚本插入300多万测数据。这里只给个简单的示例了)SET NAMES utf8mb4;SET FOREIGN_KEY_CHECK..._php大数据优化
有道云笔记怎么保存html,有道云笔记如何保存网页 有道笔记保存页面教程-程序员宅基地
文章浏览阅读905次。有道云笔记如何保存网页 有道笔记保存页面教程网页剪报功能支持哪些浏览器?IE,360安全,Firefox,Chrome,搜狗,遨游等主流浏览器。不能收藏网页,原因是没有安装浏览器剪报插件:②点击如下图部门网页剪报”立即体验“。③在弹出”有道云笔记网页剪报“网页对话框,点击如下图”添加到浏览器“。④然后在弹出”确认新增扩展程序“网页对话框中,点击”添加“即可。⑤现在,在浏览器右上角多了一个标记,只需..._有道云笔记装扩展
EasyUI 取得选中行数据-程序员宅基地
文章浏览阅读63次。转自:http://www.jeasyui.net/tutorial/23.html本实例演示如何取得选中行数据。数据网格(datagrid)组件包含两种方法来检索选中行数据:getSelected:取得第一个选中行数据,如果没有选中行,则返回 null,否则返回记录。getSelections:取得所有选中行数据,返回元素记录的数组数据。创建数据网格(DataGrid)<..._easyui 获取table选中的一行的值
云上武功秘籍(三)华为云上部署金蝶EAS Cloud_云上部署含带宽-程序员宅基地
文章浏览阅读1k次。每天琐事缠身,查错、维护、开接口?——不,你可以更加富有创造力!假期千里迢迢飞回公司机房处理一个小故障?——不,你可以更加自由高效!如果这就是你的写照,那为什么不选择上云呢?如果要上云,那为什么不选择华为云呢?云上秘籍第三弹——超详细、超全面的金蝶EAS Cloud部署教程来啦!负载均衡?WEB安全?一篇文章全部搞定!最后,请大家相信我们华为云生态 ISV团队的诚意和实力,谢谢!_云上部署含带宽