五分钟了解机器学习的基本概念-程序员宅基地
技术标签: 基于matlab的机器学习 机器学习 人工智能
目录
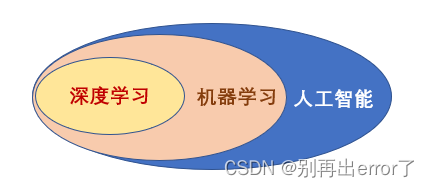
1、人工智能、机器学习、深度学习之间的关系
总的来说,深度学习时机器学习的一个子类,而机器学习又是人工智能的一个子类。
人工智能是一个非常宽泛的概念,它可以代指任何形式的蕴含某些智能特性的技术,并非特指某一特定技术领域。而机器学习则指一个特定领域,用于指代人工智能的一个特定类别。而进一步的,机器学习也包含很多技术,深度学习就是其中之一。
2、什么是机器学习?
简单地说,机器学习其实就是一种对数据的建模技术,(就我个人看来也像是一种数据处理的算法模型),是一种从数据抽象出模型的技术。数据可以是各种信息,如文档、图像等等,模型就是机器学习的产物。
//就我个人的理解来看,机器学习就是通过海量的数据集合,来对你所建立的模型进行训练,使其达到一个预期的效果,最终生成一个可靠的模型。
 在完成一个模型的建模之后,可以完成推理。(即根据新的数据输入,通过模型后得到一个输出)。而训练数据和输入数据之间存在的差异是机器学习面临的结构下挑战,也是一切问题的根源。
在完成一个模型的建模之后,可以完成推理。(即根据新的数据输入,通过模型后得到一个输出)。而训练数据和输入数据之间存在的差异是机器学习面临的结构下挑战,也是一切问题的根源。
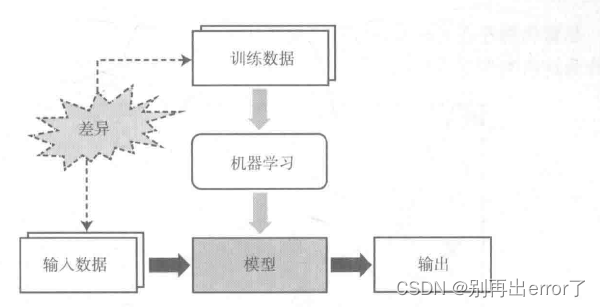
机器学习无法基于错误的训练数据来实现预期目标,就像给新生的婴儿几个苹果,一会儿告诉你是苹果,一会儿告诉你是梨子,一会儿又说是西瓜,他永远不会知道到底什么是苹果。所以,获取能够充分反应实际领域据特征的无偏训练数据至关重要。
这里需要提到一个概念,泛化(generalization):确保模型对于训练数据与输入数据能够获得一致性能的处理过程。机器学习能否成功很大程度上取决于泛化的有效程度。
3、机器学习的常见问题之 过拟合
泛化过程失效的主要诱因之一就是 过拟合。这是一个训练模型时十分常见的问题。下面举一个例子进行简单的描述。
例如,我们需要利用机器学习对两类数据点进行分类。我们以两类数据的特征坐标画出一幅散点图:
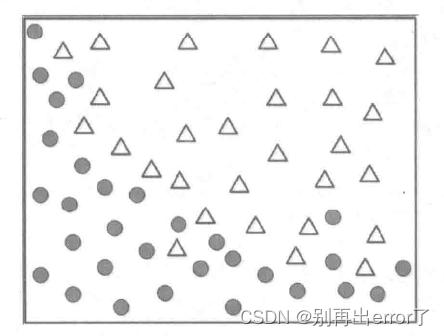
此时我们需要建立一个模型对两者进行分类,实际上也就是得到一条区分两者的边界
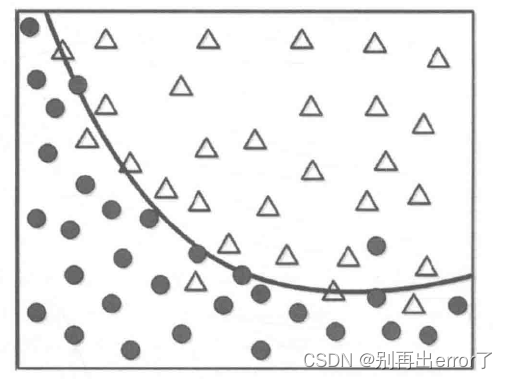
如图所示,虽然存在一定的数据点偏离,但曲线似乎是一条比较合理的边界。
如果我们要以完美的边界对所有数据点进行划分呢?能否正确地反映普适的行为特征呢?
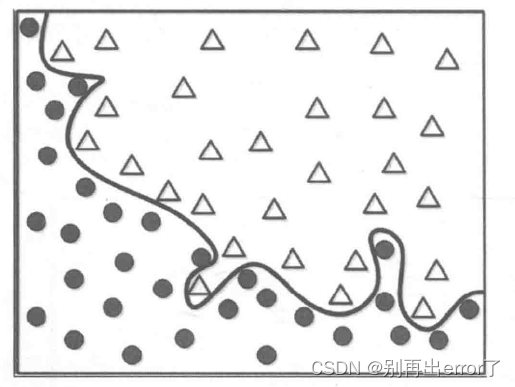
完美的边界如上图所示,针对这样的模型,如果有一个新的数据(正方形)输入,能否得到一个准确的划分呢?
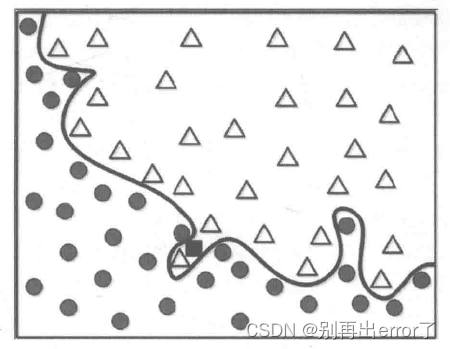
这个完美的边界模型将黑色方形划分为△,但实际上它应该属于黑色圆更加合理,为什么对训练数据的100%准确率匹配会产生问题呢?
其实,在大量的训练数据中,存在的大量的噪声,就比如上述的一些偏离了的数据点。但机器学习无法区分噪声,如果过分要求区分所有训练集数据,他将会生成一个不合理的模型,而对后续所需要判定的实际数据的判定产生误差。
如果认为训练数据中的每一个元素都是准确的,并且精准匹配模型,这将会得到一个普适性较低的模型,这就是过拟合。就比如,你拿出三个苹果,十分强硬地和婴儿宝宝说这就是苹果,其他的就算很像也不是苹果,只有这三个才是苹果。这样,如果再拿来一个新的没有见过的苹果,婴儿宝宝也会觉得这个东西不是刚见过的苹果,所以判断失误,这其实就是过拟合的概念。
4、如何克服过拟合?
这里介绍两种克服过拟合问题的典型方法:正则化和验证。
(1)正则化:是一种力求构建极简模型的数值方法。精简后的模型能以较小的性能代价,避免过拟合的影响。类似于前文讨论的例子,复杂的曲线更倾向于过拟合。而简单的曲线虽然未能正确划分部分数据点,但能更加好的反映总体特征。
(2)验证:验证是指预留一部分训练数据,并利用其监控模型性能的过程。验证数据集不参与训练过程。如果训练过程所生成的模型对预留输入数据的处理效果不佳,则认为存在过拟合。
验证的方法十分常见,也拿之前说的认识苹果来说,相当于你在教婴儿“这2个是苹果”之后,再拿出另一个苹果出来,如果婴儿宝宝能认出来也是苹果,说明教的效果好,反之如果不认识,那就是过拟合的意思了。
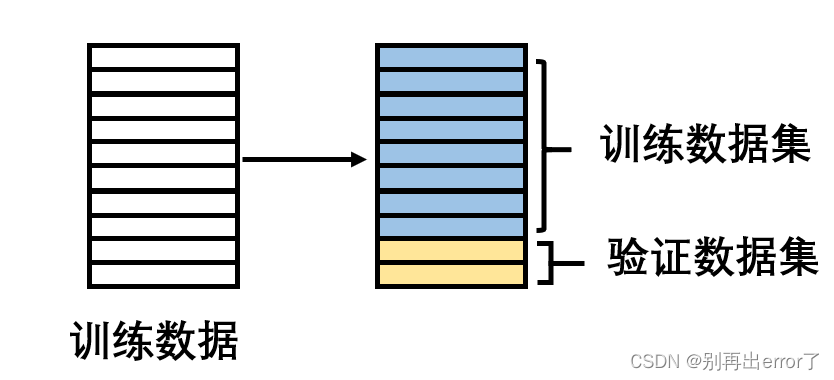
在利用验证技术的机器学习过程包括以下几步:
(1)将训练数据分为两组:一组用于训练,另一组用于验证。根据经验规律,训练数据与验证数据的比例为8:2;
(2)使用训练数据对模型进行训练;
(3)利用验证数据评估模型效果。如果效果满意。结束训练;如果效果不显著,修改模型重新进行训练。
这里再介绍一种验证方法——交叉验证
简单的说,交叉验证就是不保留数据的原始划分,而是重复划分数据。比例一定,但数据划分范围不同,是从训练过程中随机选出的。
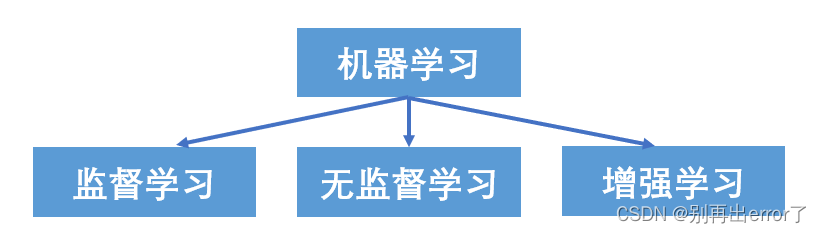
5、机器学习的类型
主要分以下三个大类:
监督学习的应用最为广泛。在监督学习中,每个训练数据集均由输入与标准输出构成的数据对构成。标准输出是模型对该输入应生成的预期结果。
{ input , correct output }
类似于之前的教婴儿认识苹果,苹果这个物体就是数据,它包含苹果的各种特征,比如颜色、大小、触感等等,对用的输出结果就是苹果,婴儿需要学会通过大脑收集到的信息对其进行判断。这就是监督学习。
而在无监督学习中,训练数据仅包含输入,而不包含标准输出。
{ input }
无监督学习通常用于分析数据的特征,并对数据进行预处理。再类比于教婴儿学习苹果,无监督学习相当于没有人告诉宝宝啥是苹果和梨子,而是把一堆水果塞给宝宝,让他自己根据特征分出两个种类,这个过程就相当于提取物体的关键特征。
增强学习利用输入、某些输出以及评分组成的数据集作为训练数据。它通常用在需要优化折中的情况,例如控制和博弈问题。
{ input,some output, grade for this output }
6、分类和回归
监督学习最常见的两类应用就是分类(classification)和回归(regression)。
分类可以说是最主流的应用了,它所关注的就是寻找数据所属的类别。比如数字识别、面部识别等等。类似的,分类问题的训练数据如下
{ input , class} //class 种类即对应这数据的标准输出。
回归不判定类别,而是预测数值。针对对以后数据的学习,得到一个模型,可对新输入的数据进行值的预测。比如天气预测、股票预测等等。
总之,分类是分析研究利用模型来判别输入数据属于哪一种类别;回归是分析利用模型来估计数据的趋势。
DONEDONEDONE!!!

智能推荐
自己动手编写 Windows 防止锁屏脚本程序_防锁屏脚本-程序员宅基地
文章浏览阅读1.4w次,点赞25次,收藏108次。背景介绍有些公司处于安全和保密工作考虑,会通过 Windows 组策略强制所有办公电脑在无操作的情况下 5 分钟或者 10 分钟自动锁屏,避免无关人士看到不该看的内容。作为程序员,十分反感这种一刀切的方案,一来很容易打断思路,比如正在写代码或者向别人展示时,突然锁屏了就挺恶心的;二来每次锁屏后都要输入密码,这简直就是浪费生命,不能忍!为了解决这个问题,我们可以编写一个简单的 vbs 脚本,在锁屏周期内模拟按键操作,从而避免 Windows 桌面被锁屏。之所以使用 vbs 脚本,而不是 Python、Ja_防锁屏脚本
MFC总结_mfc报告总结-程序员宅基地
文章浏览阅读559次。一、MFC类库概述MFC(Microsoft Foundation class)微软基本类(库),有时候也有人叫做微软基本类库,因为它确实是一个类库(物理上讲),而且非常庞大;它也是一个面向对象的应用程序架构(逻辑上),程序员利用它可以很方便搭建应用程序框架。MFC结合了面向对象的编程技术和WINDOWS消息驱动的编程技术,并封装了WIN32API,其设计好处:消除了WIN32API的复杂性,封装了WIN32API,统一了程序的概念,而且可扩展。MFC由AFX项目小组进化而来,还有一些AFX代码,如Af_mfc报告总结
Python机器学习笔记——随机森林算法-程序员宅基地
文章浏览阅读2.1k次。随机森林算法的理论知识 随机森林是一种有监督学习算法,是以决策树为基学习器的集成学习算法。随机森林非常简单,易于实现,计算开销也很小,但是它在分类和回归上表现出非常惊人的性能,因此,随机森林被誉为“代表集成学习技术水平的方法”。一,随机森林的随机性体现在哪几个方面?1,数据集的随机选取 从原始的数据集中采取有放回的抽样(bagging),构造子数据集,子数据集的数据量是和原始数..._python随机森林算法
linux端口详解大全-程序员宅基地
文章浏览阅读189次。2019独角兽企业重金招聘Python工程师标准>>> ..._linux7879端口干嘛的
光伏“领跑者”基础在制造业 组件户外可靠性仍存疑-程序员宅基地
文章浏览阅读92次。自2015年国家能源局下发关于发挥市场作用促进光伏技术进步和产业升级的意见开启光伏“领跑者”计划,到“630”前首个“领跑者”基地山西大同采煤沉陷区光伏电站如期并网,再到2016年18.1GW光伏建设规模中新晋8个“领跑者”基地,光伏产业的主旋律逐渐被“领跑者”接手。回归光伏“领跑者”计划始源,顶层设计旨在细分市场刺激企业加快技术和应用创新,引导国内光..._光伏组件耐用性和可靠性测试的重要性
一文了解Kubernetes的前世今生 -程序员宅基地
文章浏览阅读405次。近十几年来,IT领域新技术、新概念层出不穷,例如DevOps、微服务(Microservice)、容器(Container)、云计算(Cloud Computing)和区块链(Blockchain)等,直有“乱花渐欲迷人眼”之势。另外,出于业务的需要,IT应用模型也在不断地变革,例如,开发模式从瀑布式(Waterfall)到敏捷(Agile)再到精益(L..._devops 演变过程 瀑布式 物理机 敏捷 虚拟机
随便推点
深度缓存算法-程序员宅基地
文章浏览阅读3.5k次,点赞2次,收藏4次。通常用z轴来计算各对象的距观察平面的距离。处理每一面时,将其到观察平面的深度与前面已经处理表面进行比较。如果一个表面比任一已处理表面都近,则计算其表面颜色并和深度一起存储。场景的可见面由一组在所有表面处理完后存储的表面来表示。该算法需要两个缓存器,一个用来存放颜色的颜色缓存器,一个用来存放深度的深度缓存器。利用深度缓存器进行可见性的判断,消除隐藏对象。其具体做法是首先对深度缓存器和颜色缓存器进行初..._深度缓存算法
正弦交流电电压电流峰值与有效值关系的推导-程序员宅基地
文章浏览阅读8k次,点赞2次,收藏3次。类似的,设有效电流为I_电流有限值推导
MVC ViewModel_mvc viewmodel name id-程序员宅基地
文章浏览阅读1.4k次。项目图我们来看看自动生成的T_UserInfo.cs类下面我们创建一个T_UserInfoValidate.cs类 作为与T_UserInfo对应的实体类using System;using System.Collections.Generic;using System.ComponentModel;using System.ComponentModel._mvc viewmodel name id
使用ZooKeeper实现队列_zookeeper中要实现优先队列-程序员宅基地
文章浏览阅读6.1k次。实现原理先进先出队列是最常用的队列,使用Zookeeper实现先进先出队列就是在特定的目录下创建PERSISTENT_SEQUENTIAL节点,创建成功时通知等待的队列,队列消费序列号最小的节点。此场景下Zookeeper的znode用于消息存储,znode存储的数据就是消息队列中的消息内容,SEQUENTIAL序列号就是消息的编号,按序取出即可。由于创建的节点是持久化的,所以不必_zookeeper中要实现优先队列
Python爬虫——爬取淘宝商品做数据挖掘分析实战篇 教程_python爬虫淘宝图片-程序员宅基地
文章浏览阅读4k次,点赞14次,收藏93次。项目内容本案例选择>> 商品类目:沙发;数量:共100页 4400个商品;筛选条件:天猫、销量从高到低、价格500元以上。项目目的1. 对商品标题进行文本分析 词云可视化2. 不同关键词word对应的sales的统计分析3. 商品的价格分布情况分析4. 商品的销量分布情况分析5. 不同价格区间的商品的平均销量分布6. 商品价格对销量的影响分析7. 商品价格对销售额的影响分析8. 不同省份或城市的商品数量分布9.不同省份的商品平均销量分..._python爬虫淘宝图片
python tornado异步_Tornado异步原理详析-程序员宅基地
文章浏览阅读344次。原创文章出自公众号:「码农富哥」,如需转载请请注明出处!文章如果对你有收获,可以收藏转发,这会给我一个大大鼓励哟!另外可以关注我公众号「码农富哥」 (搜索id:coder2025),我会持续输出Python,算法,计算机基础的 原创 文章Tornado是什么?Tornado是一个用Python编写的异步HTTP服务器,同时也是一个web开发框架。Tornado 优秀的大并发处理能力得益于它的 we..._tornado.ioloop.ioloop.current().call_later