大数据实验总结(六)--搭建Mapreduce(YARN)环境,运行Wordcount示例_hdfs dfs -rm -r /output-程序员宅基地
搭建Mapreduce(YARN)环境,运行Wordcount示例
搭建Mapreduce(YARN)环境
- 修改yarn-site.xml文件:
cd /usr/local/hadoop/etc/hadoop/
vim yarn-site.xml
如图:

具体内容:
<!-- Site specific YARN configuration properties -->
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class </name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
其中名称yarn.resourcemanager.hostname指的是ResourceManager机器所在的节点位置;名称yarn.nodemanager.aux-services在hadoop2.2.0版本中是mapreduce_shuffle.
测试YARN环境
- 启动hdfs
start-dfs.sh - 启动hdfs
Start-yarn.sh
使用浏览器打开页面:
http://master:8088/
或http://192.168.50.100:8088/
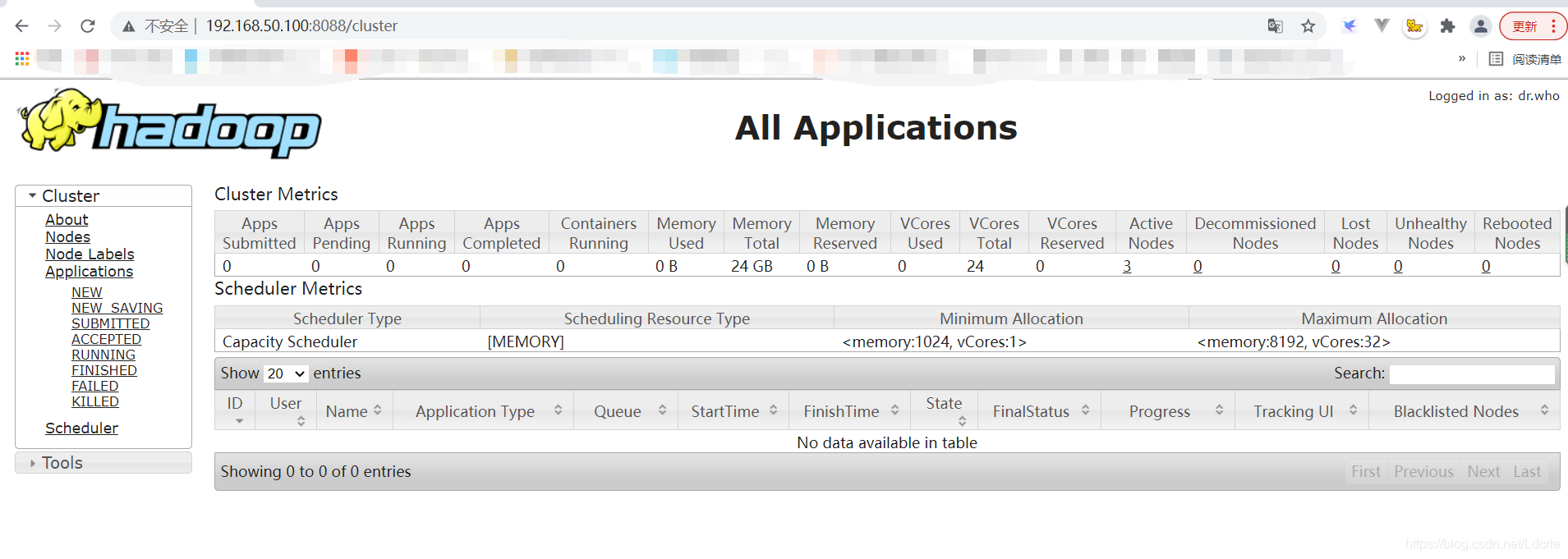
测试Mapreduce环境(运行Wordcount示例)
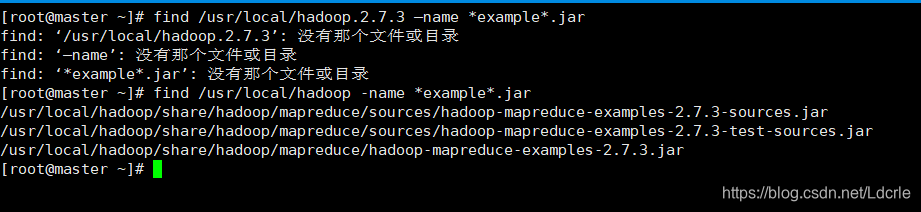
find /usr/local/hadoop -name *example*.jar
//查找示例程序,目录名需根据自己环境适当调整。

- 在HDFS上创建input目录
hdfs dfs -mkdir input - 在HDFS上创建output目录
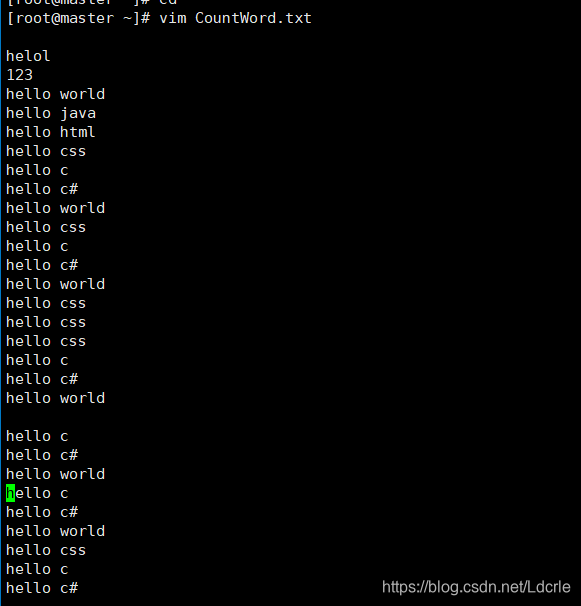
hdfs dfs -mkdir output - 创建运行示例文档CountWord.txt并进行编写:
例:
helol
123
hello world
hello java
hello html
hello css
hello c
hello c#
hello world
hello css
hello c
hello c#
hello world
hello css
hello css
hello css
hello c
hello c#
hello world
hello c
hello c#
hello world
hello c
hello c#
hello world
hello css
hello c
hello c#
hello world
hello css
hello c
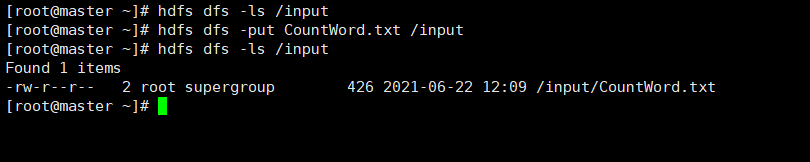
- 将CountWord.txt上传到HDFS中input目录下:
hdfs dfs -put CountWord.txt /input
- 查看:
hdfs dfs -ls /input
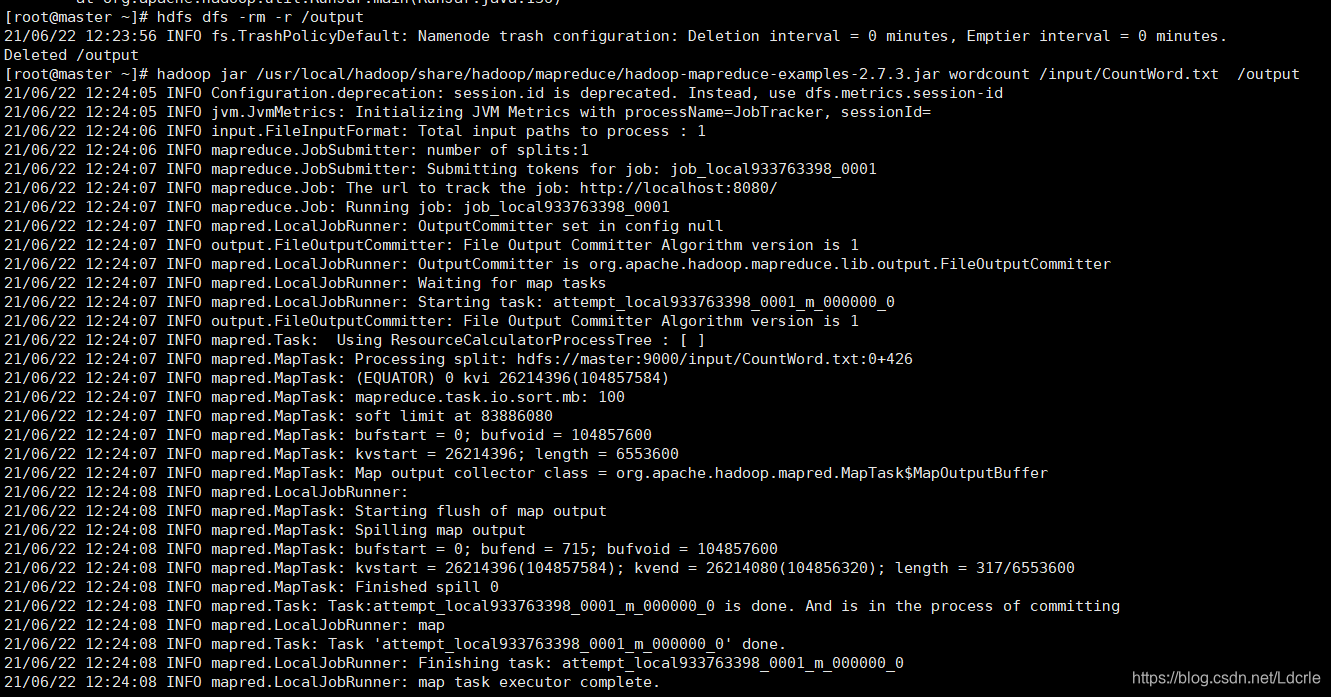
- 运行Wordcount示例程序:
输入为:/input/CountWord.txt ,运行结果输出目录为: /output
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/CountWord.txt /output
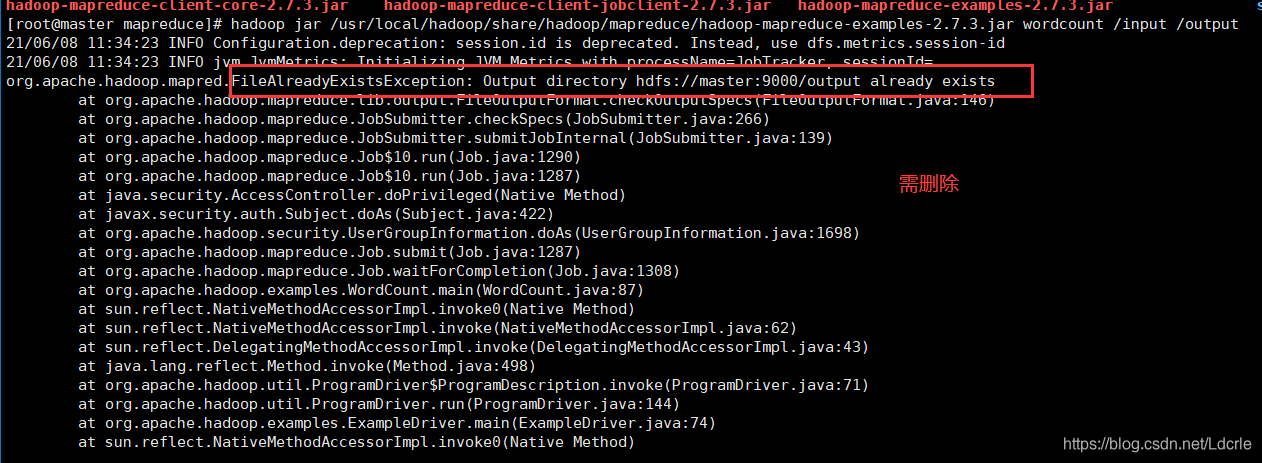
出现错误(FileAlreadyExistsException: Output directory hdfs://master:9000/output already exists):

原因:
上次运行的输出目录也是output,没有进行删除。(好像每次运行的输出目录不能存在,运行过程中自动创建,若存在则运行失败,也有可能是我重复执行同一个文件的原因)
解决方法:
将/output目录删除:
hdfs dfs -rm -r /output
-
再次运行,成功:
-
-
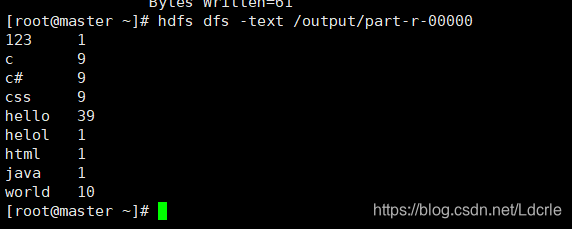
查看运行结果:
hdfs dfs -text /output/part-r-00000
注意事项:
每次运行前,请确保运行结果的输出目录不存在
[root@master mapreduce]# hdfs dfs -rm -r /output
执行的txt文件是需要自己上传到HDFS后才能运行的。
[root@master ~]# hdfs dfs -put CountWord.txt /input
运行成功详细信息:
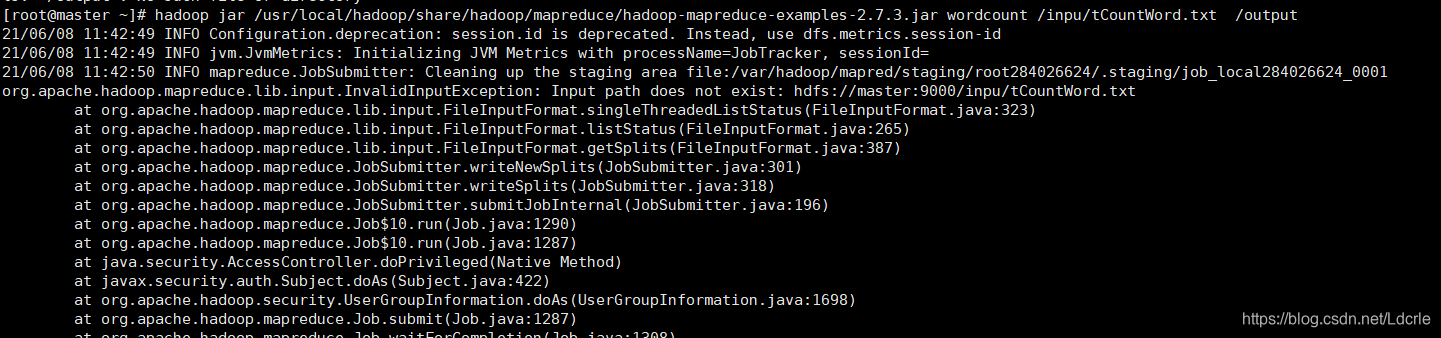
[root@master ~]# hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /inpu/tCountWord.txt /output
21/06/08 11:42:49 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
21/06/08 11:42:49 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
21/06/08 11:42:50 INFO mapreduce.JobSubmitter: Cleaning up the staging area file:/var/hadoop/mapred/staging/root284026624/.staging/job_local284026624_0001
org.apache.hadoop.mapreduce.lib.input.InvalidInputException: Input path does not exist: hdfs://master:9000/inpu/tCountWord.txt
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:323)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.listStatus(FileInputFormat.java:265)
at org.apache.hadoop.mapreduce.lib.input.FileInputFormat.getSplits(FileInputFormat.java:387)
at org.apache.hadoop.mapreduce.JobSubmitter.writeNewSplits(JobSubmitter.java:301)
at org.apache.hadoop.mapreduce.JobSubmitter.writeSplits(JobSubmitter.java:318)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:196)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1290)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1287)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1698)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1287)
at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1308)
at org.apache.hadoop.examples.WordCount.main(WordCount.java:87)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.ProgramDriver$ProgramDescription.invoke(ProgramDriver.java:71)
at org.apache.hadoop.util.ProgramDriver.run(ProgramDriver.java:144)
at org.apache.hadoop.examples.ExampleDriver.main(ExampleDriver.java:74)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
[root@master ~]# hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /input/CountWord.txt /output
21/06/08 11:43:35 INFO Configuration.deprecation: session.id is deprecated. Instead, use dfs.metrics.session-id
21/06/08 11:43:35 INFO jvm.JvmMetrics: Initializing JVM Metrics with processName=JobTracker, sessionId=
21/06/08 11:43:36 INFO input.FileInputFormat: Total input paths to process : 1
21/06/08 11:43:36 INFO mapreduce.JobSubmitter: number of splits:1
21/06/08 11:43:36 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_local764084505_0001
21/06/08 11:43:36 INFO mapreduce.Job: The url to track the job: http://localhost:8080/
21/06/08 11:43:36 INFO mapreduce.Job: Running job: job_local764084505_0001
21/06/08 11:43:36 INFO mapred.LocalJobRunner: OutputCommitter set in config null
21/06/08 11:43:36 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/06/08 11:43:36 INFO mapred.LocalJobRunner: OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
21/06/08 11:43:36 INFO mapred.LocalJobRunner: Waiting for map tasks
21/06/08 11:43:36 INFO mapred.LocalJobRunner: Starting task: attempt_local764084505_0001_m_000000_0
21/06/08 11:43:37 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/06/08 11:43:37 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
21/06/08 11:43:37 INFO mapred.MapTask: Processing split: hdfs://master:9000/input/CountWord.txt:0+426
21/06/08 11:43:37 INFO mapreduce.Job: Job job_local764084505_0001 running in uber mode : false
21/06/08 11:43:37 INFO mapred.MapTask: (EQUATOR) 0 kvi 26214396(104857584)
21/06/08 11:43:37 INFO mapred.MapTask: mapreduce.task.io.sort.mb: 100
21/06/08 11:43:37 INFO mapred.MapTask: soft limit at 83886080
21/06/08 11:43:37 INFO mapred.MapTask: bufstart = 0; bufvoid = 104857600
21/06/08 11:43:37 INFO mapred.MapTask: kvstart = 26214396; length = 6553600
21/06/08 11:43:37 INFO mapreduce.Job: map 0% reduce 0%
21/06/08 11:43:37 INFO mapred.MapTask: Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
21/06/08 11:43:38 INFO mapred.LocalJobRunner:
21/06/08 11:43:38 INFO mapred.MapTask: Starting flush of map output
21/06/08 11:43:38 INFO mapred.MapTask: Spilling map output
21/06/08 11:43:38 INFO mapred.MapTask: bufstart = 0; bufend = 715; bufvoid = 104857600
21/06/08 11:43:38 INFO mapred.MapTask: kvstart = 26214396(104857584); kvend = 26214080(104856320); length = 317/6553600
21/06/08 11:43:38 INFO mapred.MapTask: Finished spill 0
21/06/08 11:43:38 INFO mapred.Task: Task:attempt_local764084505_0001_m_000000_0 is done. And is in the process of committing
21/06/08 11:43:38 INFO mapred.LocalJobRunner: map
21/06/08 11:43:38 INFO mapred.Task: Task 'attempt_local764084505_0001_m_000000_0' done.
21/06/08 11:43:38 INFO mapred.LocalJobRunner: Finishing task: attempt_local764084505_0001_m_000000_0
21/06/08 11:43:38 INFO mapred.LocalJobRunner: map task executor complete.
21/06/08 11:43:38 INFO mapred.LocalJobRunner: Waiting for reduce tasks
21/06/08 11:43:38 INFO mapred.LocalJobRunner: Starting task: attempt_local764084505_0001_r_000000_0
21/06/08 11:43:38 INFO output.FileOutputCommitter: File Output Committer Algorithm version is 1
21/06/08 11:43:38 INFO mapred.Task: Using ResourceCalculatorProcessTree : [ ]
21/06/08 11:43:38 INFO mapred.ReduceTask: Using ShuffleConsumerPlugin: org.apache.hadoop.mapreduce.task.reduce.Shuffle@5eb258cc
21/06/08 11:43:38 INFO reduce.MergeManagerImpl: MergerManager: memoryLimit=363285696, maxSingleShuffleLimit=90821424, mergeThreshold=239768576, ioSortFactor=10, memToMemMergeOutputsThreshold=10
21/06/08 11:43:38 INFO reduce.EventFetcher: attempt_local764084505_0001_r_000000_0 Thread started: EventFetcher for fetching Map Completion Events
21/06/08 11:43:39 INFO mapreduce.Job: map 100% reduce 0%
21/06/08 11:43:39 INFO reduce.LocalFetcher: localfetcher#1 about to shuffle output of map attempt_local764084505_0001_m_000000_0 decomp: 97 len: 101 to MEMORY
21/06/08 11:43:39 INFO reduce.InMemoryMapOutput: Read 97 bytes from map-output for attempt_local764084505_0001_m_000000_0
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: closeInMemoryFile -> map-output of size: 97, inMemoryMapOutputs.size() -> 1, commitMemory -> 0, usedMemory ->97
21/06/08 11:43:39 WARN io.ReadaheadPool: Failed readahead on ifile
EBADF: Bad file descriptor
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posix_fadvise(Native Method)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX.posixFadviseIfPossible(NativeIO.java:267)
at org.apache.hadoop.io.nativeio.NativeIO$POSIX$CacheManipulator.posixFadviseIfPossible(NativeIO.java:146)
at org.apache.hadoop.io.ReadaheadPool$ReadaheadRequestImpl.run(ReadaheadPool.java:206)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
21/06/08 11:43:39 INFO reduce.EventFetcher: EventFetcher is interrupted.. Returning
21/06/08 11:43:39 INFO mapred.LocalJobRunner: 1 / 1 copied.
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: finalMerge called with 1 in-memory map-outputs and 0 on-disk map-outputs
21/06/08 11:43:39 INFO mapred.Merger: Merging 1 sorted segments
21/06/08 11:43:39 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 91 bytes
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: Merged 1 segments, 97 bytes to disk to satisfy reduce memory limit
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: Merging 1 files, 101 bytes from disk
21/06/08 11:43:39 INFO reduce.MergeManagerImpl: Merging 0 segments, 0 bytes from memory into reduce
21/06/08 11:43:39 INFO mapred.Merger: Merging 1 sorted segments
21/06/08 11:43:39 INFO mapred.Merger: Down to the last merge-pass, with 1 segments left of total size: 91 bytes
21/06/08 11:43:39 INFO mapred.LocalJobRunner: 1 / 1 copied.
21/06/08 11:43:39 INFO Configuration.deprecation: mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
21/06/08 11:43:39 INFO mapred.Task: Task:attempt_local764084505_0001_r_000000_0 is done. And is in the process of committing
21/06/08 11:43:39 INFO mapred.LocalJobRunner: 1 / 1 copied.
21/06/08 11:43:39 INFO mapred.Task: Task attempt_local764084505_0001_r_000000_0 is allowed to commit now
21/06/08 11:43:39 INFO output.FileOutputCommitter: Saved output of task 'attempt_local764084505_0001_r_000000_0' to hdfs://master:9000/output/_temporary/0/task_local764084505_0001_r_000000
21/06/08 11:43:39 INFO mapred.LocalJobRunner: reduce > reduce
21/06/08 11:43:39 INFO mapred.Task: Task 'attempt_local764084505_0001_r_000000_0' done.
21/06/08 11:43:39 INFO mapred.LocalJobRunner: Finishing task: attempt_local764084505_0001_r_000000_0
21/06/08 11:43:39 INFO mapred.LocalJobRunner: reduce task executor complete.
21/06/08 11:43:40 INFO mapreduce.Job: map 100% reduce 100%
21/06/08 11:43:40 INFO mapreduce.Job: Job job_local764084505_0001 completed successfully
21/06/08 11:43:40 INFO mapreduce.Job: Counters: 35
File System Counters
FILE: Number of bytes read=592184
FILE: Number of bytes written=1149995
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=852
HDFS: Number of bytes written=61
HDFS: Number of read operations=13
HDFS: Number of large read operations=0
HDFS: Number of write operations=4
Map-Reduce Framework
Map input records=44
Map output records=80
Map output bytes=715
Map output materialized bytes=101
Input split bytes=103
Combine input records=80
Combine output records=9
Reduce input groups=9
Reduce shuffle bytes=101
Reduce input records=9
Reduce output records=9
Spilled Records=18
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=46
Total committed heap usage (bytes)=242360320
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=426
File Output Format Counters
Bytes Written=61
[root@master ~]# hdfs dfs -text /output/part-r-00000
123 1
c 9
c# 9
css 9
hello 39
helol 1
html 1
java 1
world 10
智能推荐
一文掌握大模型提示词技巧:从战略到战术-程序员宅基地
文章浏览阅读5.2k次,点赞76次,收藏106次。本文从战略(宏观)和战术(微观)两个层次讲解提示词技巧。希望大家能够掌握常见的提示词技巧,能够在 AI 早期积极主动学习,占领先机。_大模型提示词
Description Resource Path Location Type The superclass "javax.servlet.http.HttpServlet" was not foun_"descriptionresourcepathlocationtype the superclas-程序员宅基地
文章浏览阅读2.4k次,点赞3次,收藏3次。建了一个简单web项目,但是项目出了一个Description Resource Path Location TypeDescription Resource Path Location TypeThe superclass “javax.servlet.http.HttpServlet” was not found on the Java Build Path index.jsp /s..._"descriptionresourcepathlocationtype the superclass \"javax.servlet.http.h"
Install Sun JDK on Fedora/Redhat[收藏]_fedora install jdk-程序员宅基地
文章浏览阅读1.8k次。1. Download Sun Java JDK or JRE Download Sun Java JDK or JRE from here (current version is JDK 6 Update 20)http://java.sun.com/javase/downloads/index.jsp.Note: you can Skip login step.Download rpm.bin package (example jdk-6u20-linux-i586-rpm.bin).2. Change_fedora install jdk
android 调用拍照 程序崩溃-程序员宅基地
文章浏览阅读108次。_andori拍照返回app 崩溃
STM32 IAP应用开发——自制BootLoader_stm32 bootloader-程序员宅基地
文章浏览阅读1.1w次,点赞48次,收藏317次。在嵌入式操作系统中,BootLoader是在操作系统内核运行之前运行。可以初始化硬件设备、建立内存空间映射图,从而将系统的软硬件环境带到一个合适状态,以便为最终调用操作系统内核准备好正确的环境。在嵌入式系统中,通常并没有像BIOS那样的固件程序(注,有的嵌入式CPU也会内嵌一段短小的启动程序),因此整个系统的加载启动任务就完全由BootLoader来完成。_stm32 bootloader
pic秒表c语言程序,PIC单片机C语言编程实例三-第7章秒表.doc-程序员宅基地
文章浏览阅读91次。PIC单片机C语言编程实例三-第7章秒表.docPAGEPAGE 133第7章 秒 表7.2.2 程序清单该源程序已在实验板上调试通过,读者可直接引用,并可利用软件编程的灵活性,加以拓展,实现更为复杂的功能。#include#include //此程序实现计时秒表功能,时钟显示范围00.00~99.99秒,分辨度:0.01秒unsigned chars0,s1,s2,s3;//定义0.0..._pic跑表启动条件
随便推点
3的倍数(暴力搜索)_3的倍数csdn-程序员宅基地
文章浏览阅读168次。牛客小白月赛20D 3的倍数题目链接算法分析n最大为15,范围比较小,所以直接来采用爆搜就行算法实现#include<iostream>#include<cstdio>#include<string>#include<cstring>#include<math.h>using namespace std;int ch[20][30];//ch[i][j]记录第i个字符串中j的个数,j为字符转换后的数字int dp[30];/_3的倍数csdn
【腾讯优测干货分享】如何降低App的待机内存(二)——规范测试流程及常见问题...-程序员宅基地
文章浏览阅读71次。本文来自于腾讯优测公众号(wxutest),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/806TiugiSJvFI7fH6eVA5w作者:腾讯TMQ专项测试团队导语最近小优听说,隔壁的腾讯TMQ团队出了一本新书——《移动App性能评测与优化》,便借阅了一本,读完感觉写得确实很赞。这本书体系化地介绍了移动应用性能评测与优化的方方面面,如内存,电量..._如何降低app的待机内存
Texlive2020+Texstudio2.12.22资源,附安装教程和书-程序员宅基地
文章浏览阅读1.6k次,点赞21次,收藏6次。Texlive2020+Texstudio2.12.22资源,附安装教程和刘海洋latex入门使用说明书百度云地址文件截图![\[\]](https://img-blog.csdnimg.cn/20201031105628261.png#pic_center)总结百度云地址链接:https://pan.baidu.com/s/1w4ZdEHvgMBF2uURQmnAxXw提取码:6jga复制这段内容后打开百度网盘手机App,操作更方便哦–来自百度网盘超级会员V1的分享文件截图总结如果链接..
Hamburgers 二分答案_hamburger题解-程序员宅基地
文章浏览阅读5.2k次。题目大意:有一种汉堡,用B、S、C三种原料做成,现在告诉你当前有的B、S、C的个数,到商店买的B、S、C的单价(商店无限供应这三种原料),还有你拥有的钱。问最多能做多少个汉堡。刚开始我还以为是模拟,先把能用的用完,再去买。但是写了半天写不下去了,找了一下题解才发现是二分答案板子题。发现自己对二分还是不是很敏感。AC代码://https://blog.csdn.net/hesorche..._hamburger题解
ubuntu下安装uhd+gnuradio_无法定位软件包 libuhd003-程序员宅基地
文章浏览阅读1.9k次。提示:安装uhd+gnuradio实际上并不难,只是实际安装的时候,作为新手经常会因为缺乏相关知识而踩不少坑,以下是我踩坑安装的一些记录。gnuradio+uhd安装过程ubuntu下安装uhd+gnuradioExample: For UHD 3.9.5:Example: For UHD 3.14.0.0win10下安装ubuntu双系统使用usrpb210ubuntu18.04安装方法有两种,一种是使用已经编译好的二进制码,缺点是版本通常比较旧,但学习usrp也不需要太新的版本,另外,这种_无法定位软件包 libuhd003
Awk命令详解_在linux系统中,awk允许进行多种测试。作为样式匹配,还提供了模式匹配表达式,以下-程序员宅基地
文章浏览阅读3.1k次,点赞4次,收藏45次。awk文本和数据进行处理的编程语言awk 是一种编程语言,用于在linux/unix下对文本和数据进行处理。数据可以来自标准输入(stdin)、一个或多个文件,或其它命令的输出。它支持用户自定义函数和动态正则表达式等先进功能,是linux/unix下的一个强大编程工具。它在命令行中使用,但更多是作为脚本来使用。awk有很多内建的功能,比如数组、函数等,这是它和C语言的相同之处,灵活性是awk最大的优势。awk命令格式和选项语法形式awk [options] ‘script’ va_在linux系统中,awk允许进行多种测试。作为样式匹配,还提供了模式匹配表达式,以下