吴恩达Coursera深度学习课程 DeepLearning.ai 提炼笔记(1-2)-- 神经网络基础-程序员宅基地
技术标签: 吴恩达《深度学习》课程笔记 吴恩达 deep-learning 神经网络和深度学习 吴恩达 深度学习 课程笔记 Coursera
作者: 大树先生
博客: http://blog.csdn.net/koala_tree
GitHub:https://github.com/KoalaTree
2017 年 09 月 20 日
以下为在Coursera上吴恩达老师的DeepLearning.ai课程项目中,第一部分《神经网络和深度学习》第二周课程部分关键点的笔记。笔记并不包含全部小视频课程的记录,如需学习笔记中舍弃的内容请至Coursera 或者 网易云课堂。同时在阅读以下笔记之前,强烈建议先学习吴恩达老师的视频课程。
同时我在知乎上开设了关于机器学习深度学习的专栏收录下面的笔记,方便在移动端的学习。欢迎关注我的知乎:大树先生。一起学习一起进步呀!^_^
神经网络和深度学习—神经网络基础
1. 二分类问题
对于二分类问题,大牛给出了一个小的Notation。
- 样本: (x,y) ,训练样本包含 m 个;
- 其中
x∈Rnx ,表示样本 x 包含nx 个特征; - y∈0,1 ,目标值属于0、1分类;
- 训练数据: { (x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))}
输入神经网络时样本数据的形状:
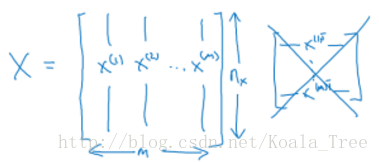
X.shape=(nx,m)
目标数据的形状:
Y=[y(1),y(2),⋯,y(m)]
Y.shape=(1,m)
2. logistic Regression
逻辑回归中,预测值:
其表示为1的概率,取值范围在 [0,1] 之间。
引入Sigmoid函数,预测值:
注意点:函数的一阶导数可以用其自身表示,
这里可以解释梯度消失的问题,当 z=0 时,导数最大,但是导数最大为 σ′(0)=σ(0)(1−σ(0))=0.5(1−0.5)=0.25 ,这里导数仅为原函数值的0.25倍。
参数梯度下降公式的不断更新, σ′(z) 会变得越来越小,每次迭代参数更新的步伐越来越小,最终接近于0,产生梯度消失的现象。
3. logistic回归 损失函数
Loss function
一般经验来说,使用平方错误(squared error)来衡量Loss Function:
但是,对于logistic regression 来说,一般不适用平方错误来作为Loss Function,这是因为上面的平方错误损失函数一般是非凸函数(non-convex),其在使用低度下降算法的时候,容易得到局部最优解,而不是全局最优解。因此要选择凸函数。
逻辑回归的Loss Function:
- 当 y=1 时, L(y^,y)=−logy^ 。如果 y^ 越接近1, L(y^,y)≈0 ,表示预测效果越好;如果 y^ 越接近0, L(y^,y)≈+∞ ,表示预测效果越差;
- 当 y=0 时, L(y^,y)=−log(1−y^) 。如果 y^ 越接近0, L(y^,y)≈0 ,表示预测效果越好;如果 y^ 越接近1, L(y^,y)≈+∞ ,表示预测效果越差;
- 我们的目标是最小化样本点的损失Loss Function,损失函数是针对单个样本点的。
Cost function
全部训练数据集的Loss function总和的平均值即为训练集的代价函数(Cost function)。
- Cost function是待求系数w和b的函数;
- 我们的目标就是迭代计算出最佳的w和b的值,最小化Cost function,让其尽可能地接近于0。
4. 梯度下降
用梯度下降法(Gradient Descent)算法来最小化Cost function,以计算出合适的w和b的值。
每次迭代更新的修正表达式:
在程序代码中,我们通常使用dw来表示 ∂J(w,b)∂w ,用db来表示 ∂J(w,b)∂b 。
5. 逻辑回归中的梯度下降法
对单个样本而言,逻辑回归Loss function表达式:
反向传播过程:
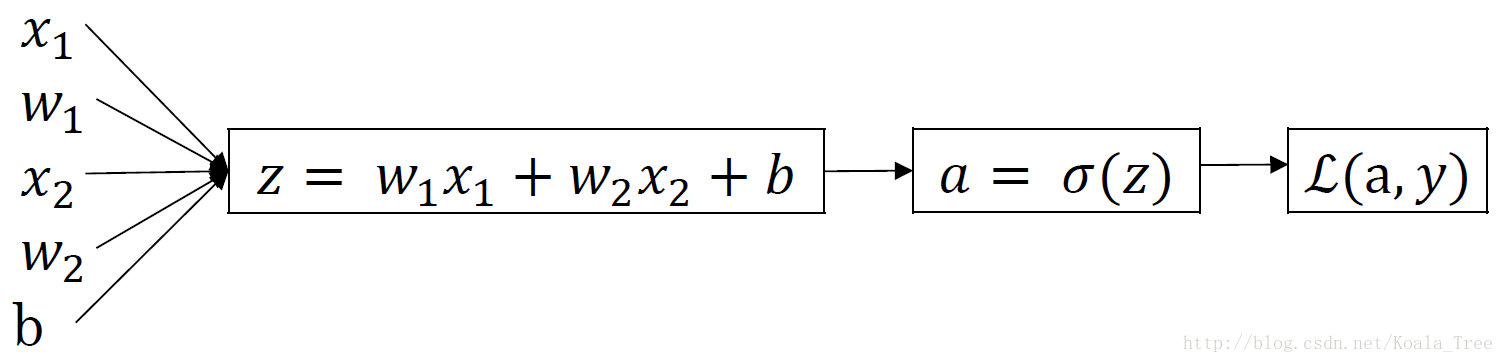
前面过程的da、dz求导:
再对 w1、w2 和b进行求导:
梯度下降法:
6. m个样本的梯度下降
对m个样本来说,其Cost function表达式如下:
Cost function 关于w和b的偏导数可以写成所有样本点偏导数和的平均形式:
7. 向量化(Vectorization)
在深度学习的算法中,我们通常拥有大量的数据,在程序的编写过程中,应该尽最大可能的少使用loop循环语句,利用python可以实现矩阵运算,进而来提高程序的运行速度,避免for循环的使用。
逻辑回归向量化
- 输入矩阵X: (nx,m)
- 权重矩阵w: (nx,1)
- 偏置b:为一个常数
- 输出矩阵Y: (1,m)
所有m个样本的线性输出Z可以用矩阵表示:
python代码:
Z = np.dot(w.T,X) + b
A = sigmoid(Z)逻辑回归梯度下降输出向量化
dZ对于m个样本,维度为 (1,m) ,表示为:
dZ=A−Ydb可以表示为:
db=1m∑i=1mdz(i)
python代码:
db = 1/m*np.sum(dZ)- dw可表示为:
dw=1mX⋅dZT
python代码:
dw = 1/m*np.dot(X,dZ.T)单次迭代梯度下降算法流程
Z = np.dot(w.T,X) + b
A = sigmoid(Z)
dZ = A-Y
dw = 1/m*np.dot(X,dZ.T)
db = 1/m*np.sum(dZ)
w = w - alpha*dw
b = b - alpha*db8. python的notation
虽然在Python有广播的机制,但是在Python程序中,为了保证矩阵运算的正确性,可以使用reshape()函数来对矩阵设定所需要进行计算的维度,这是个好的习惯;
如果用下列语句来定义一个向量,则这条语句生成的a的维度为(5,),既不是行向量也不是列向量,称为秩(rank)为1的array,如果对a进行转置,则会得到a本身,这在计算中会给我们带来一些问题。
a = np.random.randn(5)- 如果需要定义(5,1)或者(1,5)向量,要使用下面标准的语句:
a = np.random.randn(5,1)
b = np.random.randn(1,5)- 可以使用assert语句对向量或数组的维度进行判断。assert会对内嵌语句进行判断,即判断a的维度是不是(5,1),如果不是,则程序在此处停止。使用assert语句也是一种很好的习惯,能够帮助我们及时检查、发现语句是否正确。
assert(a.shape == (5,1))- 可以使用reshape函数对数组设定所需的维度
a.reshape((5,1))8. logistic regression代价函数的解释
Cost function的由来:
预测输出 y^ 的表达式:
其中,
y^ 可以看作预测输出为正类(+1)的概率:
当 y=1 时, P(y|x)=y^ ;当 y=0 时, P(y|x)=1−y^ 。
将两种情况整合到一个式子中,可得:
对上式进行log处理(这里是因为log函数是单调函数,不会改变原函数的单调性):
概率 P(y|x) 越大越好,即判断正确的概率越大越好。这里对上式加上负号,则转化成了单个样本的Loss function,我们期望其值越小越好:
对于m个训练样本来说,假设样本之间是独立同分布的,我们总是希望训练样本判断正确的概率越大越好,则有:
同样引入log函数,加负号,则可以得到Cost function:
本周(Week2)的课后编程题请参见:
智能推荐
正点原子bootloader代码(STM32F103ZET6)粗略解读_正点原子f103 bootloader模式-程序员宅基地
文章浏览阅读943次,点赞19次,收藏18次。关于正点原子IAP程序解读_正点原子f103 bootloader模式
多目标麻雀搜索优化算法及其MATLAB实现_多目标麻雀优化-程序员宅基地
文章浏览阅读186次。麻雀搜索优化算法(Sparrow Search Optimization,简称SSO)是一种基于麻雀行为的启发式优化算法,用于解决多目标优化问题。该算法模拟了麻雀在觅食和寻找栖息地过程中的行为,通过群体合作和信息共享来寻找最优解。本文将介绍多目标麻雀搜索优化算法的原理,并提供MATLAB实现的源代码。本文介绍了多目标麻雀搜索优化算法的原理,并提供了MATLAB实现的源代码。通过模拟麻雀的觅食和寻找栖息地行为,该算法在解决多目标优化问题上具有一定的效果。使用时,可以根据具体的多目标优化问题,实现。_多目标麻雀优化
newFixedThreadPool、newSingleThreadPool、newCachedThreadPool线程池创建线程的方式_executors.newfixedthreadpool(5)如何创建多线程-程序员宅基地
文章浏览阅读411次。newFixedThreadPool、newSingleThreadPool、newCachedThreadPool线程池创建线程的方式_executors.newfixedthreadpool(5)如何创建多线程
Java接口幂等性设计场景解决方案v1.0_java 面试场景题解决方案方案-程序员宅基地
文章浏览阅读145次,点赞2次,收藏2次。用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。举个简单的例子:那就是支付,用户购买商品后支付,支付扣款成功,但是返回结果的时候网络异常了,此时钱已经扣了,用户再次点击按钮,此时会进行第二次扣款,返回结果成功,用户查询余额发现多扣钱了,流水记录也变成了两条。在以前的单应用系统中,我们只需要对数据操作加入事务即可,发生错误的时候立即回滚,但是再响应客户端的时候也有可能网络中断或者异常等等情况。_java 面试场景题解决方案方案
A USB HID Component for C#-程序员宅基地
文章浏览阅读5.5k次。 Download source - 262.48 KB IntroductionThis article is about a USB HID component which enables you to communicate with HID devices over USB. There is no default component available for USB_a usb hid component for c#
SpringCloudOAuth2中访问/oauth/token报server_error_spring cloud oauth2中访问 /oauth/token 跳转不到具体方法-程序员宅基地
文章浏览阅读2k次。问题分析在新建的Spring Cloud OAuth2项目中使用grant_type为password方式访问时报server_error。在postman中如下图:{ "error": "server_error", "error_description": "Internal Server Error"}java后台报错如下:endpoint.TokenEndpoint : Handling error: NestedServletException, Handler d_spring cloud oauth2中访问 /oauth/token 跳转不到具体方法
随便推点
java http 请求网页保存导入写入 本地 文件_java http接口获取数据,结果写入文件-程序员宅基地
文章浏览阅读828次。目录依赖调用获取网页写入本地import依赖<dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpmime</artifactId> <version>4.5.2</version..._java http接口获取数据,结果写入文件
lists这个类无法使用maven打包_lists maven-程序员宅基地
文章浏览阅读1.6k次。org.assertj assertj-core_lists maven
关于微信小程序打包文件vendor.js超过500k的压缩方案_发行时压缩vendor文件-程序员宅基地
文章浏览阅读5.4k次。关于微信小程序打包文件vendor.js超过500k的压缩方案因为是开发环境,所以没进行UglifyJs压缩,所以解决的方法来了,引入UglifyJs插件修改build目录下 的webpack.dev.conf.js配置文件,前面添加插件的引入,var UglifyJsPlugin = require('uglifyjs-webpack-plugin') // 在插件列表加上一句话,就可将..._发行时压缩vendor文件
C语言--指针详解(下)--字符指针、数组指针、指针数组、函数指针、函数指针数组(转移表)-程序员宅基地
文章浏览阅读1k次,点赞33次,收藏30次。字符指针、数组指针、指针数组、函数指针、函数指针数组涵盖了在指针学习中有关指针的绝大多数的情况,熟练掌握它们,将对学习指针有巨大的帮助。同时,指针部分是C语言学习中重要的部分之一,熟练掌握指针对于C语言学习来说很重要。
心理韧性与青少年的大脑结构、功能和连接-程序员宅基地
文章浏览阅读31次。尽管早期的逆境经历与日后精神病理学风险增加有关,但一些经历过童年期逆境的个体表现出心理韧性。目前对心理韧性的神经相关知之甚少,特别是在青少年群体中。为了填补这一空白,我们对青少年心理韧性的神经影像学研究进行了系统综述。我们检索了PubMed、Web of Science、Scopus和PsycINFO数据库,共确定了5,482项研究。通过筛选标题/摘要,并通读剩余文章,纳入了基于19个独特数据集的22项研究。我们发现初步证据表明,通过结构和功能MRI以及弥散张量成像方法评估,心理韧性与青少年的大脑结构、功能
前端uni-app自定义精美全端复制文本插件,支持全端文本复制插件 可设置复制按钮颜色_uni-app 文本复制-程序员宅基地
文章浏览阅读1.4k次。标题:前端组件化开发之自定义全端复制文本插件一、引言随着前端技术的发展,组件化开发模式越来越受到重视。组件化开发可以将复杂的系统拆分为一系列可重复使用的组件,实现单独开发、单独维护,并可以随意组合,从而提高开发效率和降低维护成本。本文将介绍一款自定义全端复制文本插件,并阐述其在实际应用中的技术细节和优势。二、全端复制文本插件的功能和特点全端复制文本插件是一款可以自定义样式和复制文本内容的插件,支持设置复制按钮的颜色以及自定义复制文本字符。_uni-app 文本复制