快乐学Python,数据分析之使用爬虫获取网页内容_python获取鼠标下网页内容-程序员宅基地
在上一篇文章中,我们了解了爬虫的原理以及要实现爬虫的三个主要步骤:下载网页-分析网页-保存数据。
下面,我们就来看一下:如何使用Python下载网页。
1、网页是什么?
浏览器画网页的流程,是浏览器将用户输入的网址告诉网站的服务器,然后网站的服务器将网址对应的网页返回给浏览器,由浏览器将网页画出来。
这里所说的网页,一般都是一个后缀名为 html 的文件。
网页文件和我们平时打交道的文件没什么不同,平时我们知道 Word 文件,后缀名为 .doc, 通过 Word 可以打开。图片文件后缀名为 .jpg,通过 Photoshop 可以打开;而网页则是后缀名为 .html,通过浏览器可以打开的文件。
网页文件本质也是一种文本文件,为了能够让文字和图片呈现各种各样不同的样式,网页文件通过一种叫作 HTML 语法的标记规则对原始文本进行了标记。
(1)手动下载网页
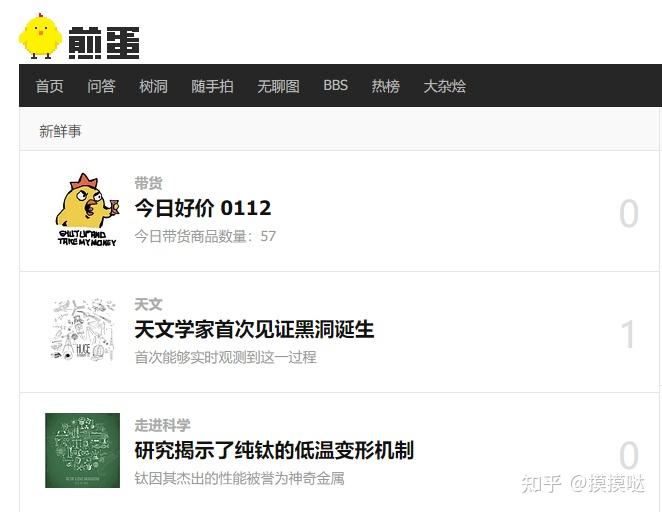
我们以煎蛋网为例体会一下网页的实质,使用浏览器打开这个链接http://jandan.net/可以看到如下界面。可以看到,第一条新闻的标题前缀是:今日好价。网页内容可能会随时间变化,这里你只需要注意第一条新闻的前几个字(暗号)即可,下同。
在空白区域点击右键,另存为,并在保存类型中选择:仅 HTML。
接下来回到桌面,可以看到网页已经被保存到桌面了,后缀名是 html,这个就是我们所说的网页文件。
(2)网页内容初探
我们右键刚下载的文件,选择用 VS Code 打开,打开后的文件内容如下图所示。
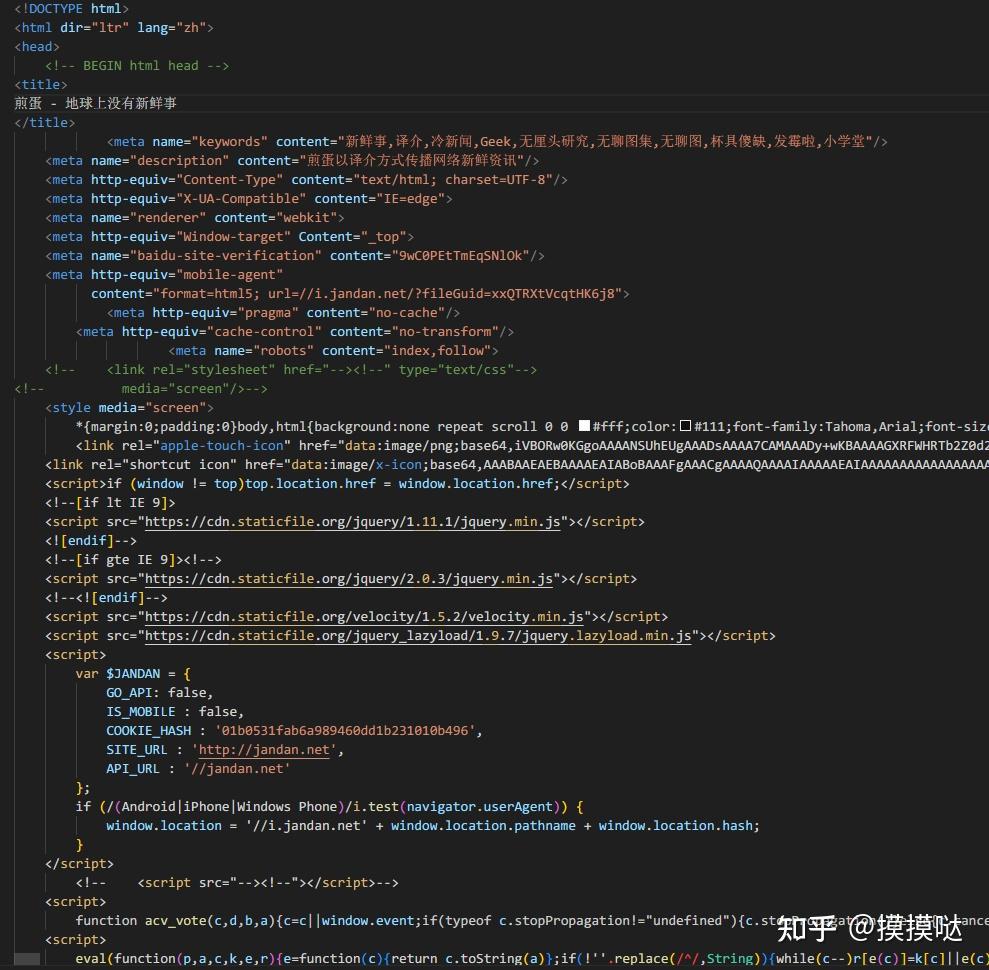
这就是网页文件的实际内容(未被浏览器画出来之前)。现在先不用管看不懂的代码,还记得我们看到的第一条新闻吗?“今日好价………………”。(你的暗号)
我们在 VS Code 中通过 CTRL + F 调出搜索面板,搜索“今日好价”(暗号)。可以看到成功找到了这条新闻,虽然被很多不认识的代码包围,但这也可以确定,我们看到的煎蛋网的主页确实就是这个 html 文件。

2、如何实现下载普通网页?
Python 以系统类的形式提供了下载网页的功能,放在 urllib3 这个模块中。这里面有比较多的类,我们并不需要逐一都用一遍,只需要记住主要的用法即可。
(1)获取网页内容
还是以煎蛋网为例。在我们打开这个网页的时候,排在第一的新闻是:“天文学家首次见证黑洞诞生”。
煎蛋又更新了新的新闻,你记住你当时的第一条新闻题目即可。我们待会儿会在我们下载的网页中搜索这个标题来验证我们下载的正确性。
下面开始,打开vscode,输入如下代码:
# 导入 urllib3 模块的所有类与对象
import urllib3
# 将要下载的网址保存在 url 变量中,英文一般用 url 表示网址的意思
url = "http://jandan.net/p/date/2021/03/23"
# 创建一个 PoolManager 对象,命名为 http
http = urllib3.PoolManager()
# 调用 http 对象的 request 方法,第一个参数传一个字符串 "GET"
# 第二个参数则是要下载的网址,也就是我们的 url 变量
# request 方法会返回一个 HTTPResponse 类的对象,我们命名为 response
response = http.request("GET", url)
# 获取 response 对象的 data 属性,存储在变量 response_data 中
response_data = response.data
# 调用 response_data 对象的 decode 方法,获得网页的内容,存储在 html_content
# 变量中
html_content = response_data.decode()
# 打印 html_content
print(html_content)
上述代码就完成了一个完成的网页下载的功能。其中有几个额外要注意的点:
- 我们创建 PoolManager的时候,写的是 urllib3.PoolManager,这里是因为我们导入了 urllib3 的所有类与函数。所以在调用这个模块的所有函数和类的前面都需要加模块名,并用点符号连接。
- response 对象的 data 属性也是一个对象,是一个 bytes 类型的对象。通过调用 decode 方法,可以转化成我们熟悉的字符串。
执行上述代码,可以看到打印出了非常多的内容,而且很像我们第一部分手动保存的网页,这说明目前 html_content 变量中保存的就是我们要下载的网页内容。
(2)将网页保存到文件
现在 html_content 已经是我们想要的网页内容,对于完成下载只差最后一步,就是将其保存成文件。其实这一步已经和保存网页无关的,而是我们如何把一个字符串保存成一个文件。
Python 中,读取文件和保存文件都是通过文件对象来完成的。接下来,我们通过实际的例子来了解这个技术。
新建 Cell,输入以下代码:
# 调用 open 函数,三个参数都是字符串类型,第一个参数为要操作的文件名
# 第二个参数代表模式,w 表示写入文件,r 表示读取文件
# 第三个参数表示编码格式,一般有中文的认准 utf-8 就好
# open 函数返回一个文件对象,我们存储在 fo 变量中
fo = open("jiandan.html","w", encoding="utf-8")
# 调用文件对象的 write 方法,将我们上面存储着网页内容的字符春变量,html_content
# 作为参数
fo.write(html_content)
# 关闭文件对象
fo.close()
执行完上述代码后,可以在 VS Code 的左侧边栏中看到,文件夹下多了一个 jiandan.html 的文件,这个就是我们用刚才 Python 代码保存的文件。
打开就可以看到熟悉的网页内容了。
(3)让我们的代码更加通用
刚才我们在两个 cell 中分别实现了将网页保存成一个字符串,以及将字符串保存为一个文件。如果我们要抓取新的网页,要么直接修改之前的代码,要么就需要拷贝一份代码出来。
这两种方式都不是很好,基于我们之前了解的内容,对于有一定通用度的代码我们可以将其改写为函数,来方便后续使用。
改写之后的代码如下:
# 第一个函数,用来下载网页,返回网页内容
# 参数 url 代表所要下载的网页网址。
# 整体代码和之前类似
def download_content(url):
http = urllib3.PoolManager()
response = http.request("GET", url)
response_data = response.data
html_content = response_data.decode()
return html_content
# 第二个函数,将字符串内容保存到文件中
# 第一个参数为所要保存的文件名,第二个参数为要保存的字符串内容的变量
def save_to_file(filename, content):
fo = open(filename,"w", encoding="utf-8")
fo.write(content)
fo.close()
url = "http://jandan.net/"
# 调用 download_content 函数,传入 url,并将返回值存储在html_content
# 变量中
html_content = download_content(url)
# 调用 save_to_file 函数,文件名指定为 jiandan.html, 然后将上一步获得的
# html_content 变量作为第二个参数传入
save_to_file("jiandan.html", html_content)
这样改写之后,我们在抓取新的网页的时候就可以使用 download_content 函数和 save_to_file 函数快速完成了,不再需要去写里面复杂的实现。
3、如何实现动态网页下载?
urllib3 很强大,但是却不能一劳永逸地解决网页下载问题。对于煎蛋这类普通网页,urllib3 可以表现更好,但是有一种类型的网页,它的数据是动态加载的,就是先出现网页,然后延迟加载的数据,那 urllib3 可能就有点力不从心了。
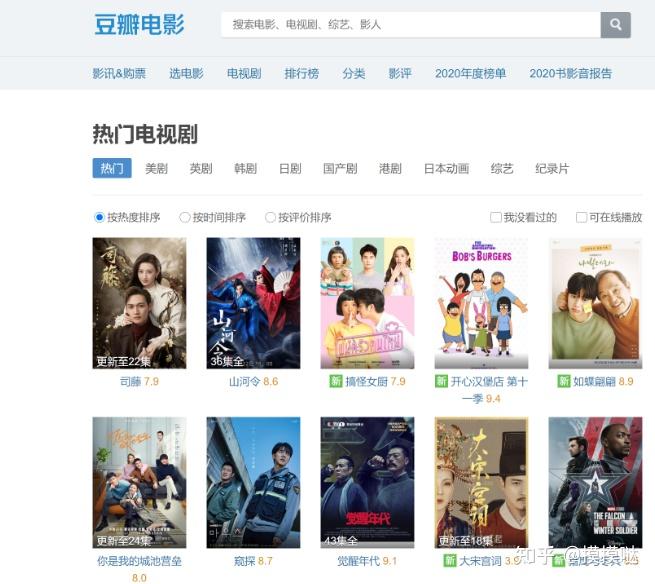
我们以豆瓣的电视剧网页为例:
现在,我们来使用刚才定义的两个函数来下载一下这个网页。
url = "https://movie.douban.com/tv"
html_content = download_content(url)
save_to_file("douban_tv.html", html_content)
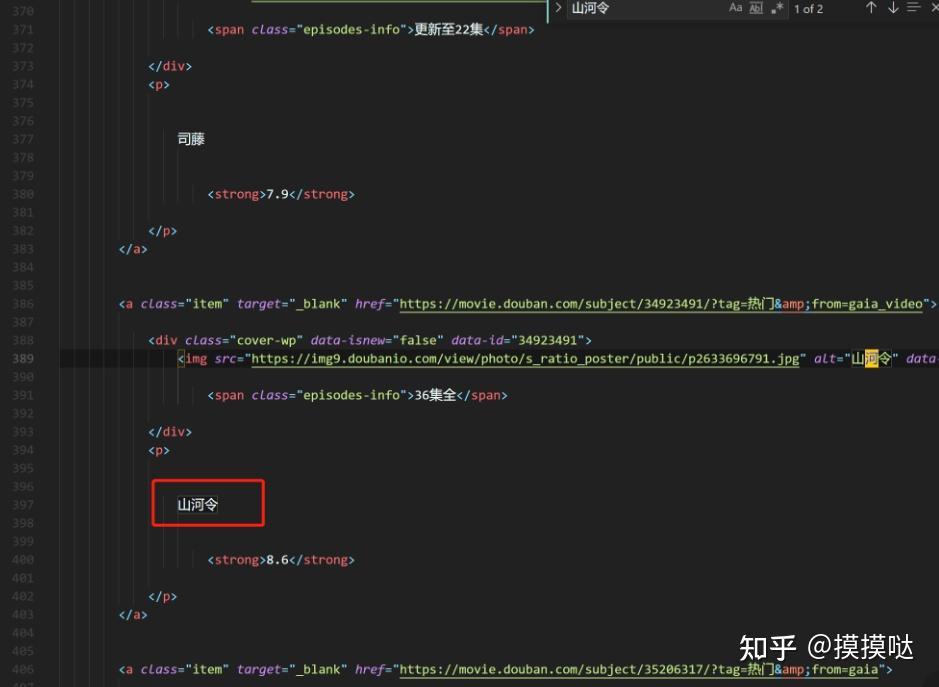
代码很简单,就是把豆瓣电视剧的网页下载到 douban_tv.html 这个文件中。执行代码,可以在 VS Code 左边的文件夹视图中看到成功生成了douban_tv.html 这个文件,这说明网页已经下载成功。
现在我们在 VS Code 中打开这个网页,搜索上图中出现的电视剧:“山河令”。这次却神奇的搜不到了,事实上,你会发现我们在网页看到的电视剧名字都搜不到。
为什么我们明明下载到了网页但是却搜不到电视剧呢?造成这个现象的原因是豆瓣电视剧网页中的电视剧列表的部分是动态加载的,所以我们用 urllib3 去直接下载,只能下载到一个壳网页,没有里面的列表内容。这种网页内部的数据是动态加载的网页,我们统一称之为动态网页。
动态网页应该怎么抓取呢?回过头去想,一个网页不管再怎么动态,最终都是要展示给用户看的,所以浏览器应该是最知道网页内容是什么的角色。如果我们可以使用代码控制浏览器来帮我们下载网页,应该就可以解决动态网页的抓取问题。
接下来我们就介绍使用 Python 来控制浏览器的利器:selenium。
(1)安装selenium
selenium 不属于 Python 的系统库,所以要使用这个库需要先进行安装。
我们安装 Python 的库一般通过 Anaconda 的命令行。既然是模拟浏览器,我们的电脑首先要先有浏览器。这里我们以 Chrome 为例。所以在一切开始之前,你需要确保你电脑上安装了 Chrome。
在准备环节,我们已经安装了 Anaconda 套件,现在我们去开始菜单(或者在桌面状态下按 Win 键)找到 Anaconda 3 文件夹,并点击文件夹中的 Anaconda Prompt 程序。Mac 用终端即可。
打开后会出现一个命令行窗口,在这个命令行,我们可以输入 conda install xxx 来安装 Python 的扩展库。
比如在这个例子中,我们输入 conda install selenium,回车。界面会变得如下所示,询问我们是否要确认安装,输入 y 继续回车就可以。
安装完毕后命令行窗口会回到待输入命令的状态,此时就可以关闭了。
回到 VS Code,新建 Cell,输入以下的测试代码:
# 从 selenium 库中导入 webdriver 类
from selenium import webdriver
# 创建一个 Chrome 浏览器的对象
brow = webdriver.Chrome()
# 使用 Chrome 对象打开 url(就是刚才豆瓣电视剧的 url)
brow.get(url)
运行代码,会自动打开一个 Chrome 浏览器的窗口,并展示 url 对应的网页。同时还会有一个提示,说明这个浏览器窗口是在被程序控制的,如下图所示。

如果代码运行出错,提示找不到 chromedriver。那说明你安装的 selenium 版本缺少 chromedriver, 可以按如下方式操作:
- 重新按照刚才的方法打开 Anaconda Prompt,输入 pip install --upgrade --force-reinstall chromedriver-binary-auto 回车执行安装。
- 在上面的代码增加一行 import chromedriver_binary 添加完毕后如下所示。
# 从 selenium 库中导入 webdriver 类
from selenium import webdriver
# 导入 chromedriver
import chromedriver_binary
# 创建一个 Chrome 浏览器的对象
brow = webdriver.Chrome()
# 使用 Chrome 对象打开 url(就是刚才豆瓣电视剧的 url)
brow.get(url)
(2)使用selenium下载动态网页
如果刚才的代码已经运行成功并打开了 Chrome 的界面的话,那我们离最后的下载动态网页已经不远了。在我们通过 Chrome 对象打开了一个网页之后,只需要访问 Chrome 对象的 page_source 属性即可拿到网页的内容。
代码如下:
# 从 selenium 库中导入 webdriver 类
from selenium import webdriver
# 创建一个 Chrome 浏览器的对象
brow = webdriver.Chrome()
# 使用 Chrome 对象打开 url(就是刚才豆瓣电视剧的 url)
brow.get(url)
# 访问 Chrome 对象的 page_source 属性,并存储在 html_content 变量中
html_content = brow.page_source
# 调用我们之前定义的 save_to_file 函数,这次我们保存为 double_tv1.html
# 要保存的内容就是 html_content
save_to_file("douban_tv1.html", html_content)
运行代码,可以看到 Chrome 被打开并加载网页,等电视剧列表都加载完之后,在 VS Code 中可以看到 double_tv1.html 也被成功创建。
这个时候我们去这个文件搜索山河令,发现已经有结果了,在这个 html 文件中已经有了所有电视剧的信息。
至此,我们也实现了对于动态内容网页的下载功能。
以上就是“快乐学Python,数据分析之使用爬虫获取网页内容”的全部内容,希望对你有所帮助。
关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

五、Python练习题
检查学习结果。

六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后祝大家天天进步!!
上面这份完整版的Python全套学习资料已经上传至CSDN官方,朋友如果需要可以直接微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。

智能推荐
c# 调用c++ lib静态库_c#调用lib-程序员宅基地
文章浏览阅读2w次,点赞7次,收藏51次。四个步骤1.创建C++ Win32项目动态库dll 2.在Win32项目动态库中添加 外部依赖项 lib头文件和lib库3.导出C接口4.c#调用c++动态库开始你的表演...①创建一个空白的解决方案,在解决方案中添加 Visual C++ , Win32 项目空白解决方案的创建:添加Visual C++ , Win32 项目这......_c#调用lib
deepin/ubuntu安装苹方字体-程序员宅基地
文章浏览阅读4.6k次。苹方字体是苹果系统上的黑体,挺好看的。注重颜值的网站都会使用,例如知乎:font-family: -apple-system, BlinkMacSystemFont, Helvetica Neue, PingFang SC, Microsoft YaHei, Source Han Sans SC, Noto Sans CJK SC, W..._ubuntu pingfang
html表单常见操作汇总_html表单的处理程序有那些-程序员宅基地
文章浏览阅读159次。表单表单概述表单标签表单域按钮控件demo表单标签表单标签基本语法结构<form action="处理数据程序的url地址“ method=”get|post“ name="表单名称”></form><!--action,当提交表单时,向何处发送表单中的数据,地址可以是相对地址也可以是绝对地址--><!--method将表单中的数据传送给服务器处理,get方式直接显示在url地址中,数据可以被缓存,且长度有限制;而post方式数据隐藏传输,_html表单的处理程序有那些
PHP设置谷歌验证器(Google Authenticator)实现操作二步验证_php otp 验证器-程序员宅基地
文章浏览阅读1.2k次。使用说明:开启Google的登陆二步验证(即Google Authenticator服务)后用户登陆时需要输入额外由手机客户端生成的一次性密码。实现Google Authenticator功能需要服务器端和客户端的支持。服务器端负责密钥的生成、验证一次性密码是否正确。客户端记录密钥后生成一次性密码。下载谷歌验证类库文件放到项目合适位置(我这边放在项目Vender下面)https://github.com/PHPGangsta/GoogleAuthenticatorPHP代码示例://引入谷_php otp 验证器
【Python】matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距-程序员宅基地
文章浏览阅读4.3k次,点赞5次,收藏11次。matplotlib.plot画图横坐标混乱及间隔处理_matplotlib更改横轴间距
docker — 容器存储_docker 保存容器-程序员宅基地
文章浏览阅读2.2k次。①Storage driver 处理各镜像层及容器层的处理细节,实现了多层数据的堆叠,为用户 提供了多层数据合并后的统一视图②所有 Storage driver 都使用可堆叠图像层和写时复制(CoW)策略③docker info 命令可查看当系统上的 storage driver主要用于测试目的,不建议用于生成环境。_docker 保存容器
随便推点
网络拓扑结构_网络拓扑csdn-程序员宅基地
文章浏览阅读834次,点赞27次,收藏13次。网络拓扑结构是指计算机网络中各组件(如计算机、服务器、打印机、路由器、交换机等设备)及其连接线路在物理布局或逻辑构型上的排列形式。这种布局不仅描述了设备间的实际物理连接方式,也决定了数据在网络中流动的路径和方式。不同的网络拓扑结构影响着网络的性能、可靠性、可扩展性及管理维护的难易程度。_网络拓扑csdn
JS重写Date函数,兼容IOS系统_date.prototype 将所有 ios-程序员宅基地
文章浏览阅读1.8k次,点赞5次,收藏8次。IOS系统Date的坑要创建一个指定时间的new Date对象时,通常的做法是:new Date("2020-09-21 11:11:00")这行代码在 PC 端和安卓端都是正常的,而在 iOS 端则会提示 Invalid Date 无效日期。在IOS年月日中间的横岗许换成斜杠,也就是new Date("2020/09/21 11:11:00")通常为了兼容IOS的这个坑,需要做一些额外的特殊处理,笔者在开发的时候经常会忘了兼容IOS系统。所以就想试着重写Date函数,一劳永逸,避免每次ne_date.prototype 将所有 ios
如何将EXCEL表导入plsql数据库中-程序员宅基地
文章浏览阅读5.3k次。方法一:用PLSQL Developer工具。 1 在PLSQL Developer的sql window里输入select * from test for update; 2 按F8执行 3 打开锁, 再按一下加号. 鼠标点到第一列的列头,使全列成选中状态,然后粘贴,最后commit提交即可。(前提..._excel导入pl/sql
Git常用命令速查手册-程序员宅基地
文章浏览阅读83次。Git常用命令速查手册1、初始化仓库git init2、将文件添加到仓库git add 文件名 # 将工作区的某个文件添加到暂存区 git add -u # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,不处理untracked的文件git add -A # 添加所有被tracked文件中被修改或删除的文件信息到暂存区,包括untracked的文件...
分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120-程序员宅基地
文章浏览阅读202次。分享119个ASP.NET源码总有一个是你想要的_千博二手车源码v2023 build 1120
【C++缺省函数】 空类默认产生的6个类成员函数_空类默认产生哪些类成员函数-程序员宅基地
文章浏览阅读1.8k次。版权声明:转载请注明出处 http://blog.csdn.net/irean_lau。目录(?)[+]1、缺省构造函数。2、缺省拷贝构造函数。3、 缺省析构函数。4、缺省赋值运算符。5、缺省取址运算符。6、 缺省取址运算符 const。[cpp] view plain copy_空类默认产生哪些类成员函数