Python+selinume+mysql爬取考拉商品信息_考拉商品图片python爬虫-程序员宅基地
环境:pycharm 2019
有点偷懒,缺少了一些相应的检测
第一步 获目标网页的信息
- url =
https://www.kaola.com/
from selenium import webdriver
url = 'http://www.kaola.com/'
#不打开浏览器
# chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument('--headless')
# driver = webdriver.Chrome(chrome_options=chrome_options)
driver = webdriver.Chrome() #打开浏览器,需要配置selinume
driver.implicitly_wait(10)#隐式等待十秒,推荐使用显示等待,自行查找资料
#大致就是 等待某些页面元素加载出来再执行下一步
driver.get(url)
html = driver.page_source #返回网站文本信息
print(html)
这样就可以获取目标网站页面的全部信息,或者在网页中通过开发者工具直接观察
输入框和搜索按钮,找到网页中的输入框以及搜索按钮所在点,之后可以通过ID或者CSS选择器或者Xpath路经将所需要搜索的物品发送进去以及点击,之后都是用Xpath路径


selinume 有个find_element_by_xpath()函数可以通过xpath路径找到所需要的属性,文本等
driver.find_element_by_xpath('//*[@id="topSearchInput"]').send_keys(name)
#关于xpath的路径 这里就不多说 不了解自己查资料吧
#send_keys()向搜索框输入需要查找的物品
driver.find_element_by_xpath('//*[@id="topSearchBtn"]').click()
#点击
执行到这里之后页面应该会跳转到你搜索的物品的商品界面,那么之后就要分析商品的页面了,因为有些网站是动态的商品的信息不会一下就显示在网页内容里
需要下拉页面
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
那么我们可以观察到页面已经将所有商品信息都包含在网页中了,因此不需要下拉网页

第二步,获取商品的信息
可以直接使用 find_element_by_xpath()找到所需要的信心,但是我上面为了查看当前页面的源码所以之后我再转换为HTML,HTML文本进行初始化,成功构造XPath解析对象,同时可以自动修正HMTL文本

Chrom有个很好用的开发着工具,Xpath可以查看你的预览xpath路径所查询到的东西。

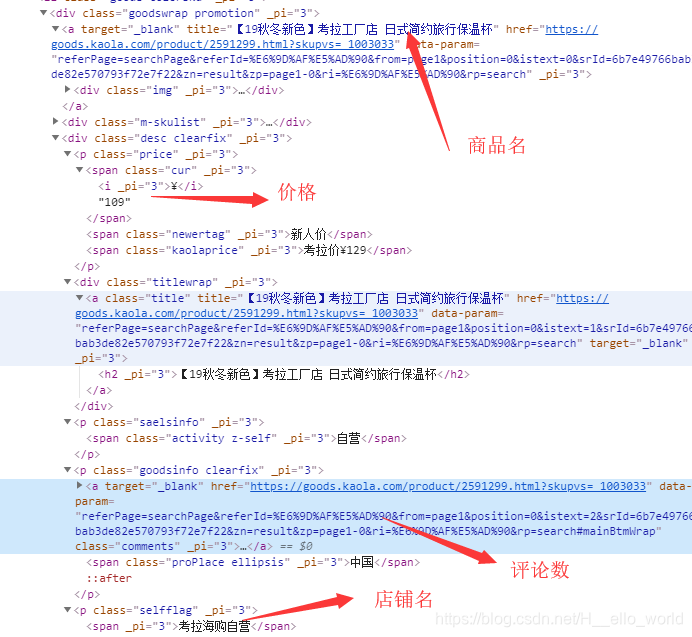
name = result.xpath('//div[@class="img"]/img/@alt')
price =result.xpath('//div[@class="desc clearfix"]/p[1]/span[1]/text()')
title = '¥'
for i in range(len(price)):
price[i] = title + price[i]
comments =result.xpath('//div[@class="desc clearfix"]/p[3]//text()')
comments = ' '.join(comments)
comments = re.findall(r'\d+',comments)
storename = result.xpath('//div[@class="desc clearfix"]/p[4]//text()')
storename_list = []
for item in storename:
if item != '' and item != ' ' and item != ' ' and item != ' ':
storename_list.append(item)
date = zip(name,price,comments,storename_list)#
return date
#获得商品信息后,会发现各种问题,比如列表里有很多空格,或者多了很多莫名的符号,那么要么就是xpath路径有问题,要么就需要自己筛选结果,比如正则表达式等
换页,找到下一页click()点击,按道理应该等到页码显示高亮再执行爬取的操作,但我找没找高亮的位置
driver.find_element_by_xpath('//*[@class="nextPage"]').click()
第三步,保存结果
这里只列举比较特殊的csv以及Mysql的保存方式
pycharm可以直接连接Mysql
CSV格式有挺多坑,比如中文乱码等问题
with open('2.csv', 'a', encoding='utf-8-sig', newline='') as f:
# 保存csv时编码格式 utf-o-sig不然会乱码
writer = csv.writer(f)
list = ['商品:','价格','评论','店铺']
writer.writerow(list)
for item in data:
writer.writerow(item)
数据库操作
conn = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='helloworld',
db='python',
charset='utf8'
)
table_name = input('the name of sheme')
cursor = conn.cursor()
sql = 'CREATE TABLE %s ( number INT PRIMARY KEY AUTO_INCREMENT,name varchar(100) ,price varchar(10) not null,comment int(10) not null,store varchar(40)not null);' % table_name
try:
cursor.execute(sql)
conn.commit()
except:
conn.rollback()
sql = 'alter table %s AUTO_INCREMENT = 1;'%table_name
try:
cursor.execute(sql)
conn.commit()
except:
conn.rollback()
将信息插入数据库
for item in data:
sql = 'INSERT INTO {name} values (number,%s,%s,%s,%s);'.format(name = table_name)
try:
cursor.execute(sql, item)
conn.commit()
except:
conn.rollback()
结果
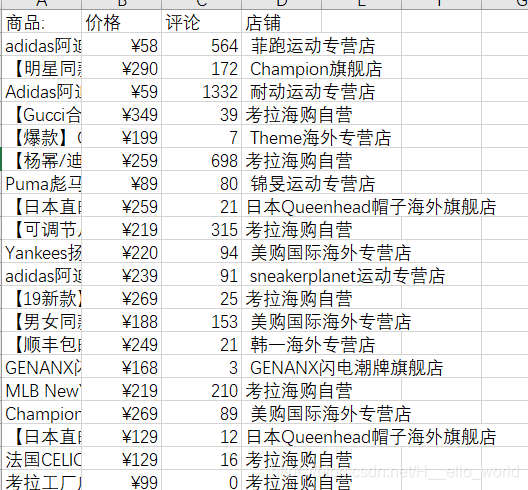
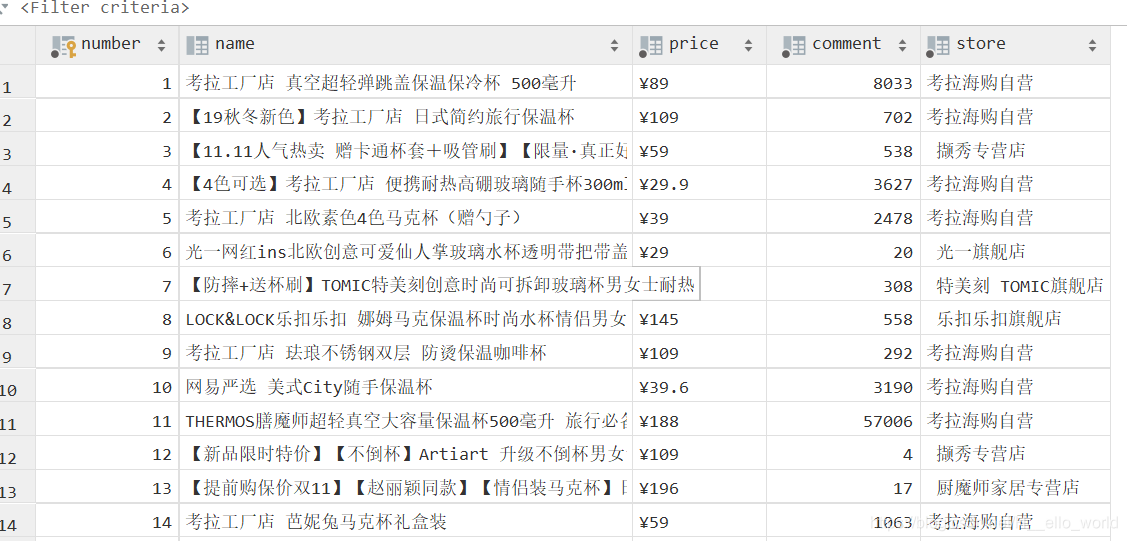
git-hub源码地址
#import urllib.parse
from selenium import webdriver
# from selenium.webdriver.common.by import By
# from selenium.webdriver.support import expected_conditions as EC
from lxml import etree
import pymysql
import time
import csv
import re
def crow(page,name,type):
# url = 'http://www.baidu.com'
url = 'http://www.kaola.com/'
#不打开浏览器
# chrome_options = webdriver.ChromeOptions()
# chrome_options.add_argument('--headless')
# driver = webdriver.Chrome(chrome_options=chrome_options)
driver = webdriver.Chrome()
driver.implicitly_wait(10)
driver.get(url)
driver.find_element_by_xpath('//*[@id="topSearchInput"]').send_keys(name)
# input = driver.find_element_by_id()
time.sleep(1)
driver.find_element_by_xpath('//*[@id="topSearchBtn"]').click()
for i in range(page):
print('你正在爬第%d页\n'%(i+1))
html = driver.page_source
data = get_product(html)
time.sleep(1)
if type == 1:
downland(i,data,name)
elif type == 2:
table_name = input('the name of sheme')
conn, cursor = connect_mysql(table_name)
insert_into(data,table_name,conn,cursor)
cursor.close()
conn.close()
else:
show(data)
time.sleep(1)
if i < page and driver.find_element_by_xpath('//*[@class="nextPage"]'):
driver.find_element_by_xpath('//*[@class="nextPage"]').click()
else:
i = page
def show(data):
for item in data:
print('商品名:'+item[0])
print('价格'+item[1])
print('评论:' + item[2])
print('店铺' + item[3])
def get_product(html):
result = etree.HTML(html)
name = result.xpath('//div[@class="img"]/img/@alt')
price =result.xpath('//div[@class="desc clearfix"]/p[1]/span[1]/text()')
title = '¥'
for i in range(len(price)):
price[i] = title + price[i]
comments =result.xpath('//div[@class="desc clearfix"]/p[3]//text()')
comments = ' '.join(comments)
comments = re.findall(r'\d+',comments)
storename = result.xpath('//div[@class="desc clearfix"]/p[4]//text()')
storename_list = []
for item in storename:
if item != '' and item != ' ' and item != ' ' and item != ' ':
storename_list.append(item)
date = zip(name,price,comments,storename_list)
return date
def downland(i,data,name):
with open('%s.csv'%name, 'a', encoding='utf-8-sig', newline='') as f: # 保存csv时编码格式 utf-o-sig不然会乱码
writer = csv.writer(f)
if i == 0:
list = ['商品:','价格','评论','店铺']
writer.writerow(list)
for item in data:
writer.writerow(item)
def insert_into(data,table_name,conn,cursor):
for item in data:
sql = 'INSERT INTO {name} values (number,%s,%s,%s,%s);'.format(name = table_name)
try:
cursor.execute(sql, item)
conn.commit()
except:
conn.rollback()
# for item in data
def connect_mysql(table_name):
conn = pymysql.Connect(
host='localhost',
port=3306,
user='root',
passwd='helloworld',
db='python',
charset='utf8'
)
cursor = conn.cursor()
sql = 'CREATE TABLE %s ( number INT PRIMARY KEY AUTO_INCREMENT,' \
'name varchar(100) ,price varchar(10) not null,' \
'comment int(10) not null,' \
'store varchar(40)not null);' % table_name
try:
cursor.execute(sql)
conn.commit()
except:
conn.rollback()
sql = 'alter table %s AUTO_INCREMENT = 1;' % table_name
try:
cursor.execute(sql)
conn.commit()
except:
conn.rollback()
return conn,cursor
if __name__=='__main__':
name = input('please enter the name of the goods')
page = int(input('please enter the page'))
type = int(input('what type do you want to download? 1 csv 2 mysql 3 I just want to look'))
crow(page, name, type)
print('thanks for you try')
智能推荐
字符,字节和编码-程序员宅基地
文章浏览阅读39次。级别:中级摘要:本文介绍了字符与编码的发展过程,相关概念的正确理解。举例说明了一些实际应用中,编码的实现方法。然后,本文讲述了通常对字符与编码的几种误解,由于这些误解而导致乱码产生的原因,以及消除乱码的办法。本文的内容涵盖了“中文问题”,“乱码问题”。掌握编码问题的关键是正确地理解相关概念,编码所涉及的技术其实是很简单的。因此,阅读本文时需要慢读多想,多思考。引言“字符与编码”...
Linux 修改 ELF 解决 glibc 兼容性问题_glibc_private-程序员宅基地
文章浏览阅读1.1k次。Linux glibc 问题相信有不少 Linux 用户都碰到过运行第三方(非系统自带软件源)发布的程序时的 glibc 兼容性问题,这一般是由于当前 Linux 系统上的 GNU C 库(glibc)版本比较老导致的,例如我在 CentOS 6 64 位系统上运行某第三方闭源软件时会报:[root@centos6-dev ~]# ldd tester./tester: /lib64/libc.so.6: version `GLIBC_2.17' not found (required by._glibc_private
wxWidgets:常用表达式_wxwidget 正则表达式 非数字字符-程序员宅基地
文章浏览阅读282次。wxWidgets:常用表达式wxWidgets:常用表达式不同风味的正则表达式转义Escapes元语法匹配限制和兼容性基本正则表达式正则表达式字符名称wxWidgets:常用表达式一个正则表达式描述字符的字符串。这是一种匹配某些字符串但不匹配其他字符串的模式。不同风味的正则表达式POSIX 定义的正则表达式 (RE) 有两种形式:扩展正则表达式(ERE) 和基本正则表达式(BRE)。ERE 大致是传统egrep 的那些,而 BRE 大致是传统ed 的那些。这个实现增加了第三种风格:高级正则表达式_wxwidget 正则表达式 非数字字符
Java中普通for循环和增强for循环的对比_for循环10万数据需要时间-程序员宅基地
文章浏览阅读3.4k次,点赞5次,收藏11次。Java中普通for循环和增强for循环的对比_for循环10万数据需要时间
学习PCB设计前的知识扫盲_pcb端子设计基础知识-程序员宅基地
文章浏览阅读2.7k次,点赞13次,收藏97次。0.工厂制作PCB线路板流程1.PCB的结构铜层阻焊丝印本质(PCB画电路板到底在画什么)基础工艺指标2.PCB图中的元素元素布局布线叠层设计3.PCB的设计依据原理图原理图元件库4.PCB的设计流程——总结_pcb端子设计基础知识
Python读取Excel内容;将读取的数据转换为list类型便于切片处理;列表的操作方法;pandas处理DataFrame类型数据;pandas操作;Python几种取整的方法_pandas excel list-程序员宅基地
文章浏览阅读4.5k次,点赞5次,收藏19次。Python读取Excel内容;将读取的数据转换为list类型便于切片处理;列表的操作方法;pandas处理DataFrame类型数据_pandas excel list
随便推点
Linux 开发环境工具[zt]-程序员宅基地
文章浏览阅读120次。软件集成开发环境(代码编辑、浏览、编译、调试)Emacs http://www.gnu.org/software/emacs/Source-Navigator 5.2b2 http://sourceforge.net/projects/sourcenavAnjuta http://anjuta.sourceforge...._linux上安装flawfinder
java小易——Spring_spring的beanfactory是hashmap吗-程序员宅基地
文章浏览阅读109次。SpringIoC DI AOPspring底层用的是ConcurrentHashMap解耦合:工厂模式:需要一个模板控制反转 IoC将原来有动作发起者(Main)控制创建对象的行为改成由中间的工厂来创建对象的行为的过程叫做IoC一个类与工厂之间如果Ioc以后,这个时候,动作发起者(Main)已经不能明确的知道自己获得到的对象,是不是自己想要的对象了,因为这个对象的创建的权利与交给我这个对象的权利全部转移到了工厂上了所用包:DOM4j解析XML文件lazy-init = _spring的beanfactory是hashmap吗
温故而知新:部分常见的图像数学运算处理算法的用途_图像处理算啊-程序员宅基地
文章浏览阅读1.3k次,点赞29次,收藏24次。本文将图像处理中常用的数学运算算法及其对图像的作用做了个汇总介绍,有助于图像处理时针对对应场景快速选择合适的数学算法。_图像处理算啊
EM Agent Fatal agent error: State Manager failed at Startup_check agent status retcode=1-程序员宅基地
文章浏览阅读1.1k次。EM 不定期异常宕机,问题重复出现,之前几次因为忙于其它事,无力兼顾,等回头处理时,发现EM已恢复正常。这次问题又重现,准备彻底解决,过程如下:1. 重新启动EM失败,报错:/u01/oracle/agent/core/12.1.0.5.0/bin/emctl status agentOracle Enterprise Manager Cloud Control 12c Relea_check agent status retcode=1
JVM常用调优参数 ——JVM篇_jvm调优-程序员宅基地
文章浏览阅读1.9w次,点赞50次,收藏366次。JVM常用性能调优参数详解 在学习完整个JVM内容后,其实目标不仅是学习了解整个JVM的基础知识,而是为了进行JVM性能调优做准备,所以以下的内容就是来说说JVM性能调优的知识。一、性能调优 性能调优包含多个层次,比如:架构调优、代码调优、JVM调优、数据库调优、操作系统调优等等。 架构调优和代码调优是JVM调优的基础,其中架构调优是对系统影响最大的。性能调优基本上按照以下步骤进行:明确优化目标发现性能瓶颈性能调优通过监控及数据统计工具获得数据确认是否达到目标二、何时进_jvm调优
三级嵌入式准备(二)_八个gpio引脚最多构成几个按键-程序员宅基地
文章浏览阅读435次,点赞3次,收藏7次。转载来源为https://blog.csdn.net/ReCclay/article/details/79439686 1、嵌入式系统的CPU主要使用的有DSP、ARM以及FPGA。2、DSP适用于数字信号处理的微处理器支持单指令多数据(DIMD)并行处理的指令显著提高音频、视频等数字信号的数据处理效率3、片上系统SOC已成为嵌入式处理器芯片的主流发展趋势它是..._八个gpio引脚最多构成几个按键