RTX2060显卡 CUDA环境搭建_2060用什么cuda好-程序员宅基地
写在前面
我还以为不会有人看呢, 得认知整理一下, 写的有问题的话可以提出交流。
RTX 2060 显卡支持
RTX 2060 是一款NVIDIA推出的显卡,其支持 CUDA 加速技术,下面将详细介绍其支持的情况和使用方法。
CUDA 是一种针对NVIDIA GPU的并行计算平台和编程模型,通过 CUDA 编写程序可以利用GPU的并行处理能力加速计算。对于 RTX 2060 来说,其采用了 Turing 架构,支持 CUDA 10.1 和以上版本,可以充分发挥GPU的计算能力。
window环境搭建
参考网站
CUDA学习:Windows下的CUDA环境配置_cuda环境变量-程序员宅基地
1. 略述
主要干两件事:
(1) 安装两个API,CUDA提供两层API接口,CUDA驱动(driver)API 和 CUDA运行时(runtime)API。所以要安装两个API,一个是显卡驱动(drivers),一个是cuda运行时工具包(toolkit)。它们的关系如图所示。

(2)Visual Studio 开发环境配置。
2.下载显卡驱动和CUDA Toolkit工具包
(1) 查看显卡信息
要使用nvidia-smi指令,必须先安装NUIDIA的CUDA驱动,一般会自带驱动,只是版本不是最新的。
打开终端,输入nvidia-smi,本机显卡的显卡驱动版本为:551.86(driver) CUDA支持版本为:12.4(toolkit)(这个是我安装好之后的)。

在查看完电脑的显卡信息后,需要对显卡驱动版本和CUDA版本对应的CUDA Toolkit工具包进行确认.
或者使用“DirectX诊断工具”查看显卡信息:
按下“Win+R”组合键打开“运行”,输入“dxdiag”。
点击“确定”后,在“DirectX诊断工具”中可以看到显卡型号、显存容量等详细信息。

(2) 下载显卡驱动
地址:Official Drivers | NVIDIA

search之后直接点击下载

(3) 下载CUDA Toolkit工具箱
地址:CUDA Toolkit Archive | NVIDIA Developer

安装完毕后也可以通过nvidia-smi指令查看安装的对不对。
3. VS2019配置
(1) 添加环境变量
查看环境变量

安装完成后,系统环境变量中自动被添加上了如下所示的两个环境变量(版本号对应用户所下载的版本号)。
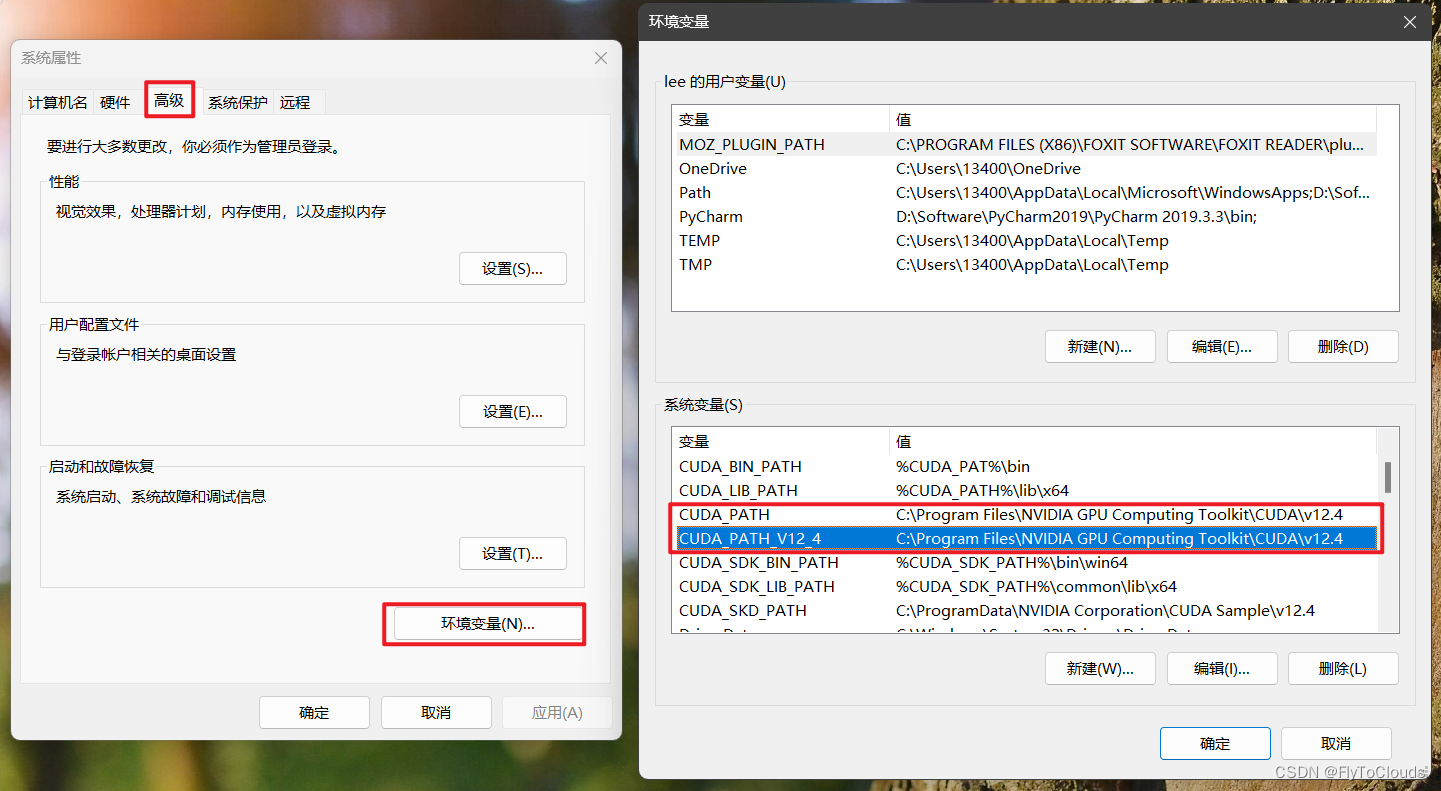
添加环境变量:
用户需要手动添加以下的环境变量:
CUDA_BIN_PATH=%CUDA_PAT%\bin
CUDA_LIB_PATH=%CUDA_PATH%\lib\x64
CUDA_SDK_BIN_PATH=%CUDA_SDK_PATH%\bin\win64
CUDA_SDK_LIB_PATH=%CUDA_SDK_PATH%\common\lib\x64
CUDA_SKD_PATH=C:\ProgramData\NVIDIA Corporation\CUDA Sample\v12.4

添加上述环境变量后,在系统环境变量Path中添加下列路径:
%CUDA_BIN_PATH%
%CUDA_LIB_PATH%
%CUDA_SDK_BIN_PATH%
%CUDA_SDK_LIB_path%

(2) 查看CUDA是否安装成功
在命令行中输入:nvcc --version查看nvcc编译器版本,如下图所示

(3) 查看设置的环境变量情况
在命令行中输入:set cuda,查看设置的环境变量情况.如下所示:

(4) 验证CUDA是否安装成功
进入目录:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite
终端执行deviceQuery.exe 结果如下 ,运行结果为result=PASS则说明CUDA安装成功。
deviceQuery.exe Starting...
CUDA Device Query (Runtime API) version (CUDART static linking)
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA GeForce RTX 2060"
CUDA Driver Version / Runtime Version 12.4 / 12.4
CUDA Capability Major/Minor version number: 7.5
Total amount of global memory: 6144 MBytes (6442123264 bytes)
(30) Multiprocessors, ( 64) CUDA Cores/MP: 1920 CUDA Cores
GPU Max Clock rate: 1350 MHz (1.35 GHz)
Memory Clock rate: 5501 Mhz
Memory Bus Width: 192-bit
L2 Cache Size: 3145728 bytes
Maximum Texture Dimension Size (x,y,z) 1D=(131072), 2D=(131072, 65536), 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: zu bytes
Total amount of shared memory per block: zu bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1024
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Maximum memory pitch: zu bytes
Texture alignment: zu bytes
Concurrent copy and kernel execution: Yes with 2 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: No
Support host page-locked memory mapping: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
CUDA Device Driver Mode (TCC or WDDM): WDDM (Windows Display Driver Model)
Device supports Unified Addressing (UVA): Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: No
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
deviceQuery, CUDA Driver = CUDART, CUDA Driver Version = 12.4, CUDA Runtime Version = 12.4, NumDevs = 1, Device0 = NVIDIA GeForce RTX 2060
**Result = PASS**
终端执行bandwidthTest.exe 结果如下 ,运行结果为result=PASS则说明CUDA安装成功。
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\extras\demo_suite>bandwidthTest.exe
[CUDA Bandwidth Test] - Starting...
Running on...
Device 0: NVIDIA GeForce RTX 2060
Quick Mode
Host to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 6497.3
Device to Host Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 6425.2
Device to Device Bandwidth, 1 Device(s)
PINNED Memory Transfers
Transfer Size (Bytes) Bandwidth(MB/s)
33554432 144153.3
Result = PASS
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.
(5) 在VS2019下配置CUDA调试环境
打开VS2019,新建空项目,右键项目,选择“生成依赖项”,选择“生成自定义”,在"生成自定义"中勾选"CUDA",如下所示:
在空项目中新建后缀为.cu的源文件.右键该文件,选择"属性"->“常规”->“项类型”.将"项类型设置为:CUDA C/C++.如下所示:

完成上述步骤后进行项目配置.右键项目,选择属性.配置选所有配置(即debug和Realise配置一致).
然后分平台(x64和win32)分别进行配置
x64平台下的配置
- 包含目录配置
项目->“属性”->“配置属性”->“VC++目录”->"包含目录
添加包含目录:$(CUDA_PATH)\include
- 库目录配置
“VC++目录”->“库目录”
添加库目录:$(CUDA_PATH)\lib\x64
- 依赖项
“配置属性”->“链接器”->“输入”->“附加依赖项”
添加库文件(库文件数量较多,默认存储路径为C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.3\lib\x64,可在该路径下自己添加依赖项):
cublas.lib;cuda.lib;cudadevrt.lib;cudart.lib;cudart_static.lib;OpenCL.lib
Win32平台下的配置
- 包含目录与x64相同
- 库目录配置
添加库目录:$(CUDA_PATH)\lib\Win32
- 依赖项
添加库文件(Win32平台与x64平台的库文件不相同):
cuda.lib;cudadevrt.lib;cudart.lib;cudart_static.lib;OpenCL.lib
(6) 配置VS2019下的NsightGPU代码编译器
在VS2019的"扩展"->“管理扩展"中联机搜索"nsight”,下载"NVIDIA Nsight Intergration"的扩展组件,用于在VS中调试GPU代码.如下所示.

拓展下载完成后,可以使用该扩展对GPU代码进行编程.
在GPU的核函数中添加断点,点击"Start CUDA Debugging(Next-Gen)“便可进入GPU代码的调试,调试过程与VS调试CPU代码相同
使用"CUDA Debugging"只能对GPU部分的代码进行调试,即只能对核函数进行调试,不能对CPU代码进行调试
使用VS2019中的"本地Windows调试器”**只能对CPU部分的代码进行调试,无法调试GPU部分的代码

使用下面给出的测试程序进行测试,查看能否正常运行.
(7) 测试代码
test1代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<iostream>
#include <stdio.h>
using namespace std;
constexpr size_t MAXSIZE = 20;
__global__ void addKernel(int* const c, const int* const b, const int* const a)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
constexpr size_t length = 6;
int host_a[length] = {
1,2,3,4,5,6 };
int host_b[length] = {
10,20,30,40,50,60 };
int host_c[length];
//为三个向量在GPU上分配显存
int* dev_a, *dev_b, *dev_c;
cudaMalloc((void**)&dev_c, length * sizeof(int));
cudaMalloc((void**)&dev_a, length * sizeof(int));
cudaMalloc((void**)&dev_b, length * sizeof(int));
//将主机端的数据拷贝到设备端
cudaMemcpy(dev_a, host_a, length * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, host_b, length * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_c, host_c, length * sizeof(int), cudaMemcpyHostToDevice);
//在GPU上运行核函数,每个线程进行一个元素的计算
addKernel << <1, length >> > (dev_c, dev_b, dev_a);
//将设备端的运算结果拷贝回主机端
cudaMemcpy(host_c, dev_c, length * sizeof(int), cudaMemcpyDeviceToHost);
//释放显存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
for (int i = 0; i < length; ++i)
cout << host_c[i] << " ";
cout << endl;
getchar();
system("pause");
return 0;
}
结果: 11 22 33 44 55 66
test2代码
#include <stdio.h>
#include <cuda_runtime.h>
#define N 10000
__global__ void add(int *a, int *b, int *c)
{
int tid = blockIdx.x * blockDim.x + threadIdx.x; // 计算线程ID
if(tid < N)
c[tid] = a[tid] + b[tid]; // 计算向量元素和
}
int main()
{
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
cudaMalloc((void**)&dev_a, N * sizeof(int));
cudaMalloc((void**)&dev_b, N * sizeof(int));
cudaMalloc((void**)&dev_c, N * sizeof(int));
for(int i = 0; i < N; i++)
{
a[i] = i;
b[i] = i;
}
cudaMemcpy(dev_a, a, N * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N * sizeof(int), cudaMemcpyHostToDevice);
add<<<(N + 255) / 256, 256>>>(dev_a, dev_b, dev_c); // 启动CUDA核函数
cudaMemcpy(c, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
int sum = 0;
for(int i = 0; i < N; i++)
sum += c[i];
printf("The sum is %d\n", sum); // 输出向量和
return 0;
}
结果:The sum is 99990000
test3代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include<iostream>
int main()
{
int dev = 0;
cudaDeviceProp devProp;
cudaGetDeviceProperties(&devProp, dev);
std::cout << "使用GPU device " << dev << ": " << devProp.name << std::endl;
std::cout << "SM的数量:" << devProp.multiProcessorCount << std::endl;
std::cout << "每个线程块的共享内存大小:" << devProp.sharedMemPerBlock / 1024.0 << " KB" << std::endl;
std::cout << "每个线程块的最大线程数:" << devProp.maxThreadsPerBlock << std::endl;
std::cout << "每个SM的最大线程数:" << devProp.maxThreadsPerMultiProcessor << std::endl;
std::cout << "每个SM的最大线程束数:" << devProp.maxThreadsPerMultiProcessor / 32 <<std::endl;
return 0;
}
结果:
使用GPU device 0: NVIDIA GeForce RTX 2060
SM的数量:30
每个线程块的共享内存大小:48 KB
每个线程块的最大线程数:1024
每个SM的最大线程数:1024
每个SM的最大线程束数:32
Linux 的 Windows 子系统搭建(没成功 待完善)
可能原因:
使用win中Linux 的 Windows 子系统 (WSL)
错误:下载CUDA Toolkit版本太低了
子系统运行错误
Installing, this may take a few minutes...
WslRegisterDistribution failed with error: 0x8007019e
Error: 0x8007019e ??????? Linux ? Windows ????
处理:
这个错误信息 WslRegisterDistribution failed with error: 0x8007019e 是在安装适用于 Linux 的 Windows 子系统 (WSL) 时遇到的。错误代码 0x8007019e 通常表示 ERROR_INVALID_FUNCTION,意味着你尝试调用的函数或操作在当前的上下文或配置中是不允许的。
WSL 未启用:确保你已经启用了 WSL 功能。你可以通过打开“控制面板” > “程序” > “程序和功能” > “启用或关闭 Windows 功能”,然后勾选“适用于 Linux 的 Windows 子系统”和“虚拟机平台”(如果需要运行 WSL 2)来启用它。
安装参考网址:
【AI】搭建Windows Linux子系统(WSL2)CUDA环境_wsl安装cuda toolkit-程序员宅基地
WSL安装CUDA Toolkit 问题
[INFO]: Executing NVIDIA-Linux-x86_64-418.87.00.run --ui=none --no-questions --accept-license --disable-nouveau --no-cc-version-check --install-libglvnd 2>&1
[INFO]: Finished with code: 256
[ERROR]: Install of driver component failed.
[ERROR]: Install of 418.87.00 failed, quitting
解释
在Windows Subsystem for Linux (WSL) 中安装CUDA Toolkit时遇到的问题提示表明驱动组件安装失败,这通常是因为WSL不支持直接安装NVIDIA显卡驱动。WSL主要用于在Windows环境中运行Linux二进制文件,它并不支持GPU加速,因此不能安装CUDA驱动。
CUDA Toolkit中的驱动组件是针对直接运行在物理硬件上的Linux系统设计的,用于与NVIDIA GPU进行通信。然而,WSL并不直接访问物理GPU硬件,因此不能安装和使用这些驱动。
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象