非支配排序遗传算法(NSGA,NSGA-II )-程序员宅基地
技术标签: 算法
非支配排序遗传算法(NSGA,NSGA-II )
一、非支配排序遗传算法(NSGA)
1995年,Srinivas和Deb提出了非支配排序遗传算法(Non-dominated Sorting Genetic Algorithms,NSGA)。这是一种基于Pareto最优概念的遗传算法。
1、基本原理
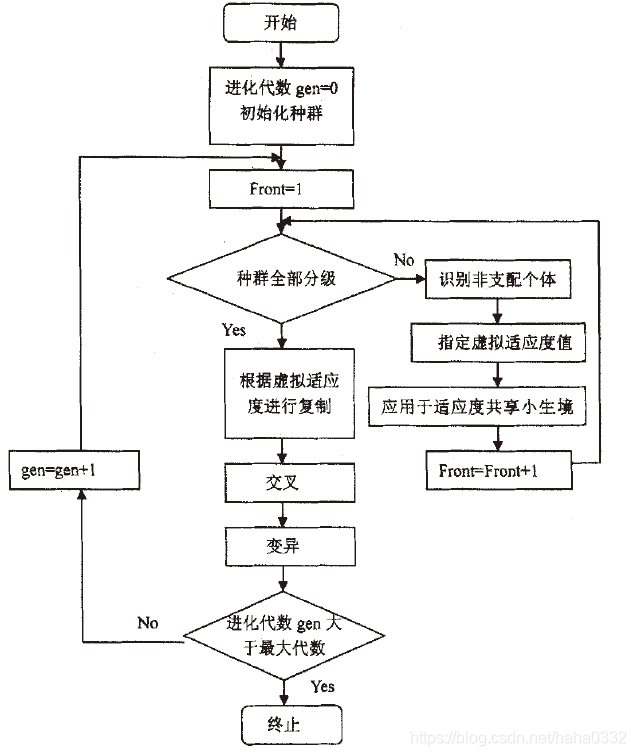
NSGA与简单的遗传算法的主要区别在于:该算法在选择算子执行之前根据个体之间的支配关系进行了分层。其选择算子、交叉算子和变异算子与简单遗传算法没有区别。
在选择操作执行之前,种群根据个体之间的支配与非支配关系进行排序:
首先,找出该种群中的所有非支配个体,并赋予他们一个共享的虚拟适应度值。得到第一个非支配最优层;
然后,忽略这组己分层的个体,对种群中的其它个体继续按照支配与非支配关系进行分层,并赋予它们一个新的虚拟适应度值,该值要小于上一层的值,对剩下的个体继续上述操作,直到种群中的所有个体都被分层。
算法根据适应度共享对虚拟适应值重新指定:
比如指定第一层个体的虚拟适应值为1,第二层个体的虚拟适应值应该相应减少,可取为0.9,依此类推。这样,可使虚拟适应值规范化。保持优良个体适应度的优势,以获得更多的复制机会,同时也维持了种群的多样性。
2、算法流程
NSGA采用的非支配分层方法,可以使好的个体有更大的机会遗传到下一代;适应度共享策略则使得准Pamto面上的个体均匀分布,保持了群体多样性,克服了超级个体的过度繁殖,防止了早熟收敛。算法流程如图所示:
3、算法缺陷
非支配排序遗传算法(NSGA)在许多问题上得到了应用。但NSGA仍存在一些问题:
-
计算复杂度较高,为
(m为目标函数个数,N为种群大小),所以当种群较大时,计算相当耗时。
-
没有精英策略;精英策略可以加速算法的执行速度,而且也能在一定程度上确保已经找到的满意解不被丢失。
-
需要指定共享半径
。
二、带精英策略的非支配排序的遗传算法(NSGA-II)
2000年,Deb又提出NSGA的改进算法一带精英策略的非支配排序遗传算法(NSGA-II),针对以上的缺陷通过以下三个方面进行了改进:
-
提出了快速非支配排序法,降低了算法的计算复杂度。由原来的
,其中,m为目标函数个数,N为种群大小。
-
提出了拥挤度和拥挤度比较算子,代替了需要指定共享半径的适应度共享策略,并在快速排序后的同级比较中作为胜出标准,使准Pareto域中的个体能扩展到整个Pareto域,并均匀分布,保持了种群的多样性。
-
引入精英策略,扩大采样空间。将父代种群与其产生的子代种群组合,共同竞争产生下一代种群,有利于保持父代中的优良个体进入下一代,并通过对种群中所有个体的分层存放,使得最佳个体不会丢失,迅速提高种群水平。
1、基本原理
1.1 快速支配排序法
NSGA-II对第一代算法中非支配排序方法进行了改进:对于每个个体 i 都设有以下两个参数 n(i) 和 S(i),
n(i) 为在种群中支配个体 i 的解个体的数量。(别的解支配个体 i 的数量)
S(i) 为被个体 i 所支配的解个体的集合。(个体 i 支配别的解的集合)
-
首先,找到种群中所有 n(i)=0 的个体(种群中所有不被其他个体至配的个体 i),将它们存入当前集合F(1);(找到种群中所有未被其他解支配的个体)
-
然后对于当前集合 F(1) 中的每个个体 j,考察它所支配的个体集 S(j),将集合 S(j) 中的每个个体 k 的 n(k) 减去1,即支配个体 k 的解个体数减1(因为支配个体 k 的个体 j 已经存入当前集 F(1) );(对其他解除去被第一层支配的数量,即减一)
-
如 n(k)-1=0则将个体 k 存入另一个集H。最后,将 F(1) 作为第一级非支配个体集合,并赋予该集合内个体一个相同的非支配序 i(rank),然后继续对 H 作上述分级操作并赋予相应的非支配序,直到所有的个体都被分级。其计算复杂度为
1.2确定拥挤度
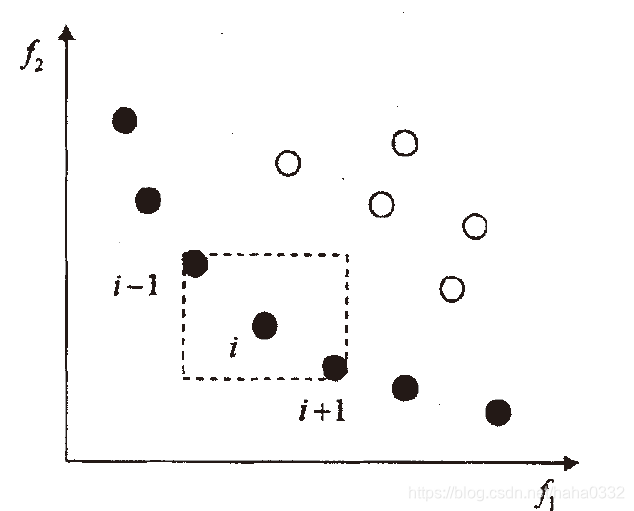
在原来的NSGA中,我们采用共享函数以确保种群的多样性,但这需要由决策者指定共享半径的值。为了解决这个问题,我们提出了拥挤度概念:在种群中的给定点的周围个体的密度,用 表示,它指出了在个体 i 周围包含个体 i 本身但不包含其他个体的长方形(以同一支配层的最近邻点作为顶点的长方形)
如图所示:
拥挤度比较算子:
从图中我们可以看出值较小时表示该个体周围比较拥挤。为了维持种群的多样性,我们需要一个比较拥挤度的算予以确保算法能够收敛到一个均匀分布的Pareto面上。
由于经过了排序和拥挤度的计算,群体中每个个体 i 都得到两个属性:非支配序 i(rank) 和拥挤度 ,则定义偏序关系:当满足条件 i(rank) <
,或满足 i(rank) =
且
>
时,定义
,也就是说:如果两个个体的非支配排序不同,取排序号较小的个体(分层排序时,先被分离出来的个体);如果两个个体在同一级,取周围较不拥挤的个体。
2、算法流程
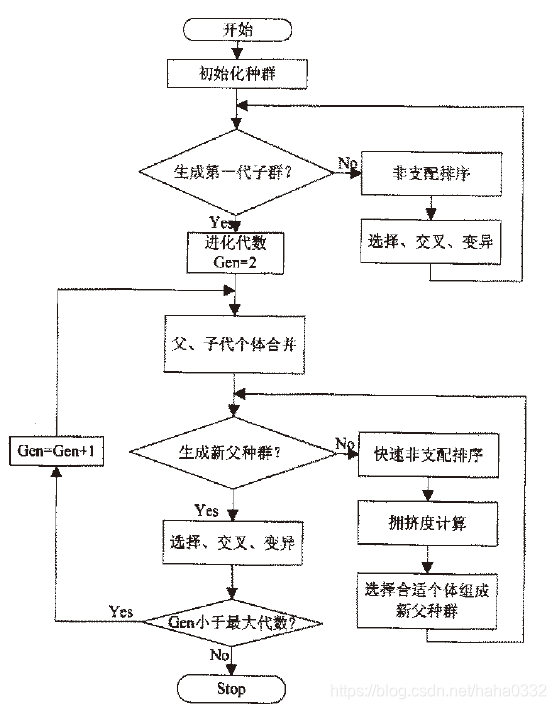
首先,随机初始化一个父代种群P(0),并将所有个体按非支配关系排序且指定一个适应度值,如:可以指定适应度值等于其非支配序 i(rank),则1是最佳适应度值。然后,采用选择、交叉、变异算子产生下一代种群Q(0),大小为N。
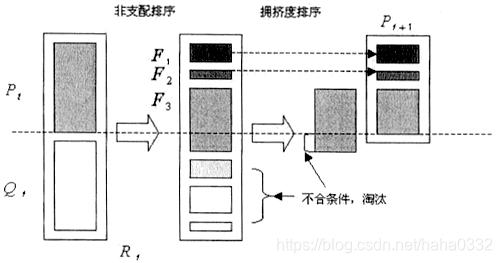
如图,首先将第 t 代产生的新种群Q(t)与父代P(t)合并组成R(t),种群大小为2N。然后R(t)。进行非支配排序,产生一系列非支配集 F(t) 并计算拥挤度。由于子代和父代个体都包含在 R(t) 中,则经过非支配排序以后的非支配集 F(1) 中包含的个体是 R(t) 中最好的,所以先将 F(1) 放入新的父代种群 P(t+1) 中。如果 F(1) 的大小小于N,则继续向 P(t+1) 中填充下一级非支配集 F(2),直到添加 F(3) 时,种群的大小超出N,对 F(3) 中的个体进行拥挤度排序(sort(F(3),)),取前个个体,使 P(t+1) 个体数量达到N。然后通过遗传算子(选择、交叉、变异)产生新的子代种群 Q(t+1)。
算法的整体复杂性为,由算法的非支配排序部分决定。
3、代码举例
import geatpy as ea
import numpy as np
class MyProblem(ea.Problem): # 继承Problem父类
def __init__(self):
name = 'NSGA2算法' # 初始化name(函数名称,可以随意设置)
M = 2 # 优化目标个数(两个x)
maxormins = [1] * M # 初始化maxormins(目标最小最大化标记列表,1:最小化该目标;-1:最大化该目标)
Dim = 1 # 初始化Dim(决策变量维数)
varTypes = [0] # 初始化varTypes(决策变量的类型,0:实数;1:整数)
lb = [-10] # 决策变量下界(自定义个上下界搜索)
ub = [10] # 决策变量上界
lbin = [1] # 决策变量下边界(0表示不包含该变量的下边界,1表示包含)
ubin = [1] # 决策变量上边界(0表示不包含该变量的上边界,1表示包含)
# 调用父类构造方法完成实例化
ea.Problem.__init__(self, name, M, maxormins, Dim, varTypes, lb, ub, lbin, ubin)
def evalVars(self, Vars): # 目标函数
f1 = Vars ** 2 # 第一个目标函数
f2 = (Vars - 2) ** 2 # 第二个目标函数
ObjV = np.hstack([f1, f2]) # 计算目标函数值矩阵
CV = -Vars ** 2 + 2.5 * Vars - 1.5 # 构建违反约束程度矩阵(需要转换为小于,反转一下)
return ObjV, CV
# 实例化问题对象
problem = MyProblem()
# 构建算法
algorithm = ea.moea_NSGA2_templet(problem,
# RI编码,种群个体50
ea.Population(Encoding='RI', NIND=50),
MAXGEN=200, # 最大进化代数
logTras=1) # 表示每隔多少代记录一次日志信息,0表示不记录。
# 求解
res = ea.optimize(algorithm, seed=1, verbose=False, drawing=1, outputMsg=True, drawLog=False, saveFlag=False, dirName='result')
4、帕累托最优解
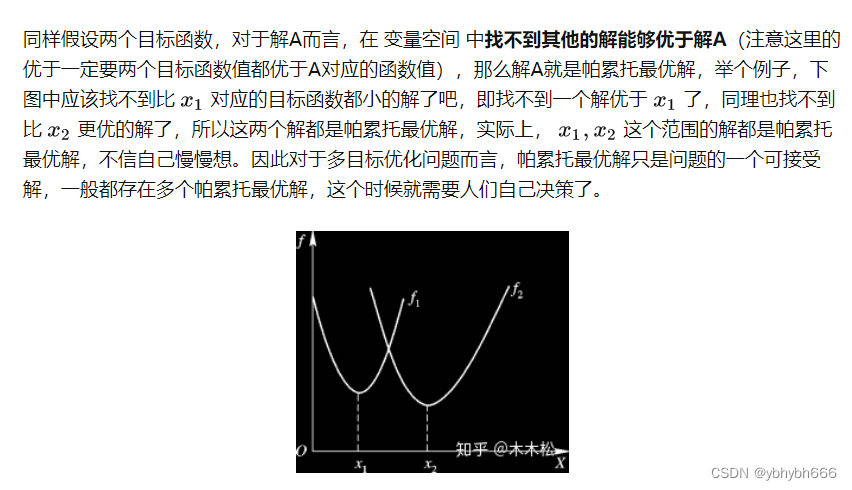
parero寻优类似于推荐系统,简单来说就是系统没有决定权,只有建议权。所以系统会推荐一系列在当前评价函数下性能相似的解。这个时候就需要决策者使用决定权从这些解中选择一个。如果是理论问题的话,最简单的就是随机选一个,反正都一样。但是到了实际问题,那就得具体问题具体分析了。比如,一次期末考试,考数学,语文和英语(三个评价函数),那么系统就会推荐你这三科分别的第一(parero 最优),然后让你从中间选一个最好的,你会怎么选?如果你是个普通老师,你会选总分最高的。但是如果你是一个数学竞赛的老师,你会选一个数学最高的那个。归根到底,还是那句话,具体问题具体分析。
————————————————
资料来源:CSDN博主「蓝色蛋黄包」的原创文章
原文链接:https://blog.csdn.net/haha0332/article/details/88672634
智能推荐
苹果https java_apple登录 后端java实现最终版-程序员宅基地
文章浏览阅读298次。import com.alibaba.fastjson.JSONArray;import com.alibaba.fastjson.JSONObject;import com.auth0.jwk.Jwk;import com.helijia.appuser.modules.user.vo.AppleCredential;import com.helijia.common.api.model.Api..._com.auth0.jwk.jwk
NLP学习记录(六)最大熵模型MaxEnt_顺序潜在最大熵强化学习(maxent rl)-程序员宅基地
文章浏览阅读4.7k次。原理在叧掌握关于未知分布的部分信息的情况下,符合已知知识的概率分布可能有夗个,但使熵值最大的概率分布最真实地反映了事件的的分布情况,因为熵定义了随机变量的不确定性,弼熵值最大时,随机变量最不确定,最难预测其行为。最大熵模型介绍我们通过一个简单的例子来介绍最大熵概念。假设我们模拟一个翻译专家的决策过程,关于英文单词in到法语单词的翻译。我们的翻译决策模型p给每一个单词或短语分配一..._顺序潜在最大熵强化学习(maxent rl)
计算机毕业设计ssm科研成果管理系统p57gs系统+程序+源码+lw+远程部署-程序员宅基地
文章浏览阅读107次。计算机毕业设计ssm科研成果管理系统p57gs系统+程序+源码+lw+远程部署。springboot基于springboot的影视资讯管理系统。ssm基于SSM高校教师个人主页网站的设计与实现。ssm基于JAVA的求职招聘网站的设计与实现。springboot校园头条新闻管理系统。ssm基于SSM框架的毕业生离校管理系统。ssm预装箱式净水站可视化信息管理系统。ssm基于SSM的网络饮品销售管理系统。
Caused by: org.xml.sax.SAXParseException; lineNumber: 38; columnNumber: 9; cvc-complex-type.2.3: 元素_saxparseexception; linenumber: 35; columnnumber: 9-程序员宅基地
文章浏览阅读1.6w次。不知道大家有没有遇到过与我类似的报错情况,今天发生了此错误后就黏贴复制了报错信息“Caused by: org.xml.sax.SAXParseException; lineNumber: 38; columnNumber: 9; cvc-complex-type.2.3: 元素 'beans' 必须不含字符 [子级], 因为该类型的内容类型为“仅元素”。”然后就是一顿的百度啊, 可一直都没有找到..._saxparseexception; linenumber: 35; columnnumber: 9; cvc-complex-type.2.3:
计算机科学与技术创新创业意见,计算机科学与技术学院大学生创新创业工作会议成功举行...-程序员宅基地
文章浏览阅读156次。(通讯员 粟坤萍 2018-04-19)4月19日,湖北师范大学计算机科学与技术学院于教育大楼学院会议室1110成功召开大学生创新创业工作会议。参与本次会议的人员有党总支副书记黄海军老师,创新创业学院吴杉老师,计算机科学与技术学院创新创业活动指导老师,15、16、17级各班班主任及学生代表。首先吴杉老师介绍了“互联网+”全国大学生创新创业大赛的相关工作进度,动员各级班主任充分做好“大学生创新创业大..._湖北师范 吴杉
【Android逆向】爬虫进阶实战应用必知必会-程序员宅基地
文章浏览阅读1.1w次,点赞69次,收藏76次。安卓逆向技术是一门深奥且充满挑战的领域。通过本文的介绍,我们了解了安卓逆向的基本概念、常用工具、进阶技术以及实战案例分析。然而,逆向工程的世界仍然在不断发展和变化,新的技术和方法不断涌现。展望未来,随着安卓系统的不断更新和加固,逆向工程将面临更大的挑战。同时,随着人工智能和机器学习技术的发展,我们也许能够看到更智能、更高效的逆向工具和方法的出现。由于篇幅限制,本文仅对安卓逆向技术进行了介绍和案例分析。
随便推点
Python数据可视化之环形饼图_数据可视化绘制饼图或圆环图-程序员宅基地
文章浏览阅读1.1k次。制作饼图还需要下载pyecharts库,Echarts 是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。随着学习python的热潮不断增加,Python数据可视化也不停的被使用,那我今天就介绍一下Python数据可视化中的饼图。在我们的生活和学习中,编程是一项非常有用的技能,能够丰富我们的视野,为各行各业的领域提供了新的角度。环形饼图的制作并不难,主要是在于数据的打包和分组这里会有点问题,属性的标签可以去 这个网站进行修改。图中的zip压缩函数,并分组打包。_数据可视化绘制饼图或圆环图
SpringMVC开发技术~5~基于注解的控制器_jsp/servlet到controller到基于注解的控制器-程序员宅基地
文章浏览阅读325次。1 Spring MVC注解类型Controller和RequestMapping注释类型是SpringMVC API最重要的两个注释类型。基于注解的控制器的几个优点:一个控制器类可以控制几个动作,而一个实现了Controller接口的控制器只能处理一个动作。这就允许将相关操作写在一个控制器类内,从而减少应用类的数量基于注解的控制器的请求映射不需要存储在配置文件中,而是使用RequestM..._jsp/servlet到controller到基于注解的控制器
利用波特图来满足动态控制行为的要求-程序员宅基地
文章浏览阅读260次,点赞3次,收藏4次。相位裕量可以从增益图中的交越频率处读取(参见图2)。使用的开关频率、选择的外部元件(例如电感和输出电容),以及各自的工作条件(例如输入电压、输出电压和负载电流)都会产生巨大影响。图2所示为波特图中控制环路的增益曲线,其中提供了两条重要信息。对于图2所示的控制环路,这个所谓的交越频率出现在约80 kHz处。通过使用波特图,您可以查看控制环路的速度,特别是其调节稳定性。图2. 显示控制环路增益的波特图(约80 kHz时,达到0 dB交越点)。图3. 控制环路的相位曲线,相位裕量为60°。
Glibc Error: `_obstack@GLIBC_2.2.5‘ can‘t be versioned to common symbol ‘_obstack_compat‘_`_obstack@glibc_2.2.5' can't be versioned to commo-程序员宅基地
文章浏览阅读1.8k次。Error: `_obstack@GLIBC_2.2.5’ can’t be versioned to common symbol '_obstack_compat’原因:https://www.lordaro.co.uk/posts/2018-08-26-compiling-glibc.htmlThis was another issue relating to the newer binutils install. Turns out that all was needed was to initi_`_obstack@glibc_2.2.5' can't be versioned to common symbol '_obstack_compat
基于javaweb+mysql的电影院售票购票电影票管理系统(前台、后台)_电影售票系统javaweb-程序员宅基地
文章浏览阅读3k次。基于javaweb+mysql的电影院售票购票电影票管理系统(前台、后台)运行环境Java≥8、MySQL≥5.7开发工具eclipse/idea/myeclipse/sts等均可配置运行适用课程设计,大作业,毕业设计,项目练习,学习演示等功能说明前台用户:查看电影列表、查看排版、选座购票、查看个人信息后台管理员:管理电影排版,活动,会员,退票,影院,统计等前台:后台:技术框架_电影售票系统javaweb
分分钟拯救监控知识体系-程序员宅基地
文章浏览阅读95次。分分钟拯救监控知识体系本文出自:http://liangweilinux.blog.51cto.com0 监控目标我们先来了解什么是监控,监控的重要性以及监控的目标,当然每个人所在的行业不同、公司不同、业务不同、岗位不同、对监控的理解也不同,但是我们需要注意,监控是需要站在公司的业务角度去考虑,而不是针对某个监控技术的使用。监控目标1.对系统不间断实时监控:实际上是对系统不间..._不属于监控目标范畴的是 实时反馈系统当前状态