Python中的数据类型及其操作(str、list、tuple、set、dict)_python set(str+str)-程序员宅基地
技术标签: tuple python string dict list
文章目录
- 1.字符串(Str)
-
- 1.1字符串的定义
- 字符串的特性:
- 1.1 字符串的索引(index)
- 1.2 字符串的切片(slice)
- 1.3 字符串的重复(repeat)
- 1.4 字符串的连接(link)
- 1.5 字符串的成员操作符(in / not in )
- 1.6 字符串中数字/字母的判断(isdigit)
- 1.7 字符串中对于开头/结尾的处理(endwith / startwith)
- 1.8 去除字符串中的空格(strip)
- 1.9 字符串的搜索
- 1.10 字符串的替换(replace)
- 1.11 字符串的对齐
- 1.12 字符串的统计(count)
- 1.13 字符串的长度(len)
- 1.14 字符串的分隔(split)
- 1.15 字符串的连接(join)
- 1.16 字符串的练习
- 2.列表(list)
- 3.Python 中的内置函数
- 4 元组(tuple)
- 5. 集合(set)
- 6.字典(dict)
1.字符串(Str)
1.1字符串的定义
In [1]: a='hello'
In [2]: print(a)
hello
In [3]: b='test'
In [4]: print(b)
test
In [5]: c='what\'s up'
In [6]: print(c)
what's up
In [7]: d=""" ###多行字符串
...: 语文
...: 数学
...: 英语
...: """
In [8]: print(d)
语文
数学
英语
In [9]: print(type(d))
<class 'str'>
字符串的特性:
1.1 字符串的索引(index)
s = 'hello'
print(s[0]) ##打印字符串中第一个元素
print(s[1]) ##打印字符串中第二个元素
print(s[-1]) ##打印字符串中倒数第一个元素
print(s[-2]) ##打印字符串中倒数第二个元素

1.2 字符串的切片(slice)
s = 'python'
print(s[0:3]) ##打印第1个到第三个元素
print(s[0:4:2]) ##打印第一个到第四个元素(间隔为2)
print(s[:]) ##打印全部元素
print(s[1:]) ##打印除第一个之外的元素
print(s[:3]) ##打印前三个字符
print(s[::-1]) ##打印倒序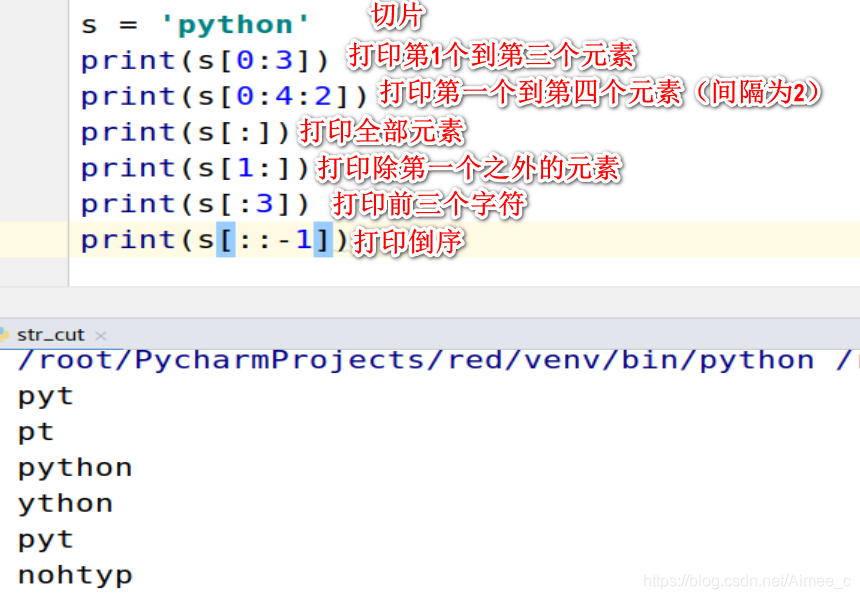
1.3 字符串的重复(repeat)
s = 'test'
print(s*2)##重复打印2遍
print(s*3)##重复打印3遍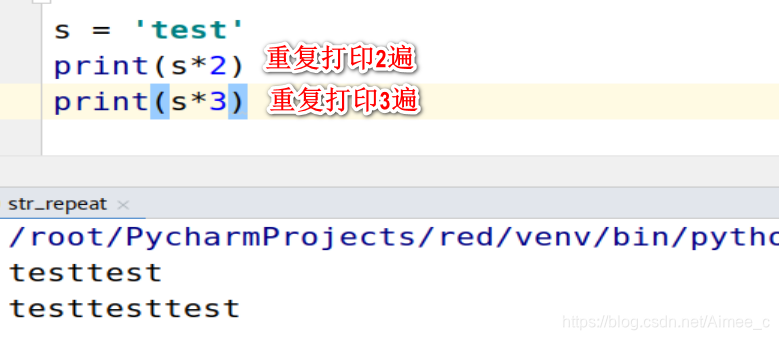
1.4 字符串的连接(link)
print('good' + 'bye')
print('hello' + ' world')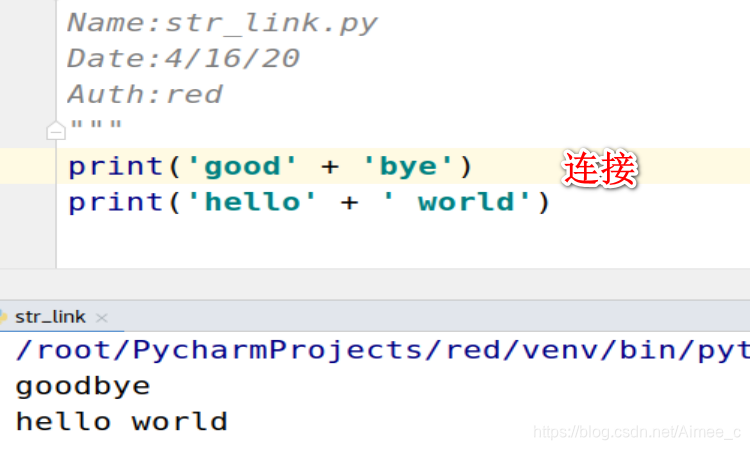
1.5 字符串的成员操作符(in / not in )
s = 'practice'
print('h' in s)##检测字符‘h’是否在字符串中
print('a' in s)##检测字符‘a’是否在字符串中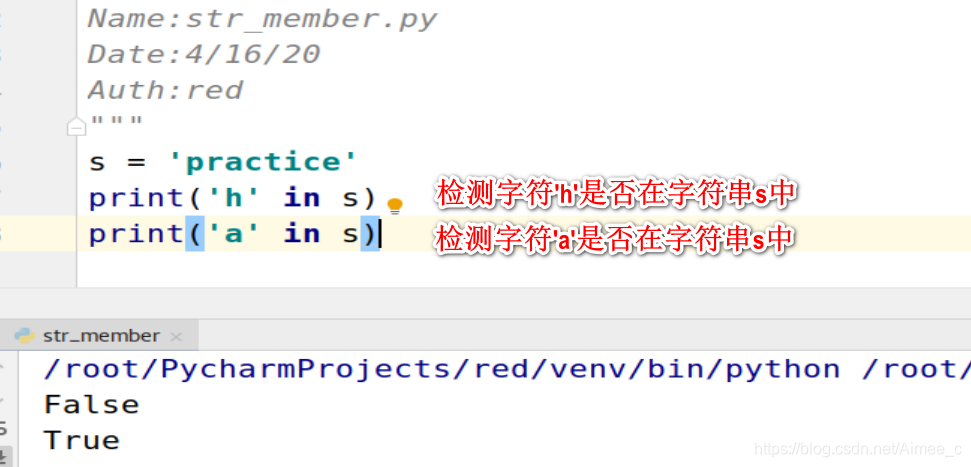
1.6 字符串中数字/字母的判断(isdigit)
In [1]: print('123'.isdigit()) ##判断字符串是否为数字
True
In [2]: print('HeLLo'.istitle())##判断字符串是否为标题
False
In [3]: print('Hello'.istitle())##标题首字母大写,其他字母小写
True
In [4]: print('linux'.islower())##判断字符串是否为小写
True
In [5]: print('LINUX'.isupper())##判断字符串是否为大写
True
In [6]: print('linux'.upper())##把字符串输出为大写
LINUX
In [7]: print('LINUX'.lower())##把字符串输出为小写
linux
In [8]: print('hello123'.isalnum()) ##判断字符串是否为数字或字母
True
In [10]: print('ttt'.isalpha())##判断字符串是否为字母
True
1.7 字符串中对于开头/结尾的处理(endwith / startwith)
常用于对文件的处理
| endswith | 以…结尾 |
|---|---|
| startswith | 以…开头 |
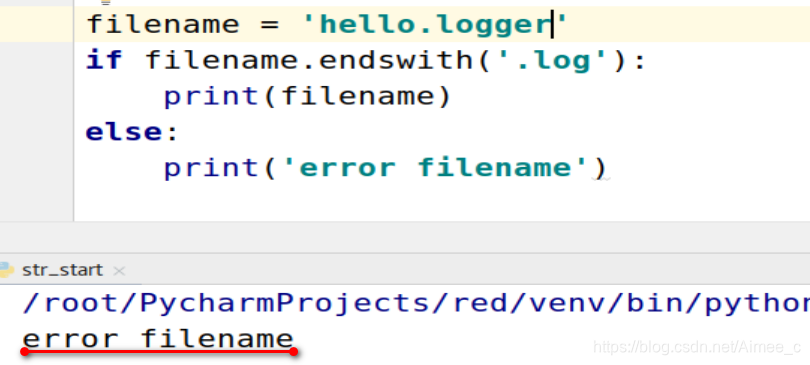
filename = 'hello.logger'
if filename.endswith('.log'):###以.....结尾
print(filename)
else:
print('error filename')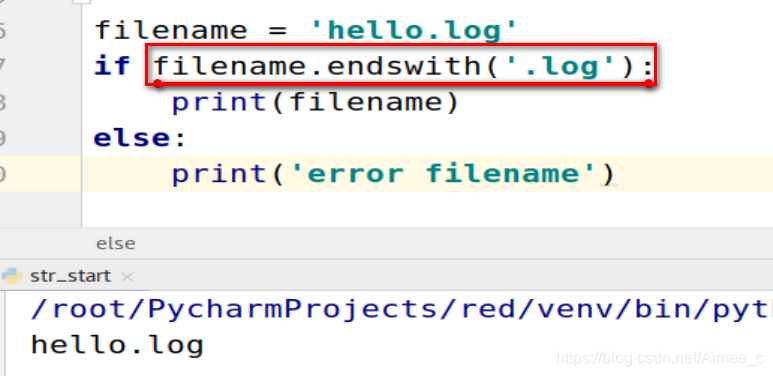
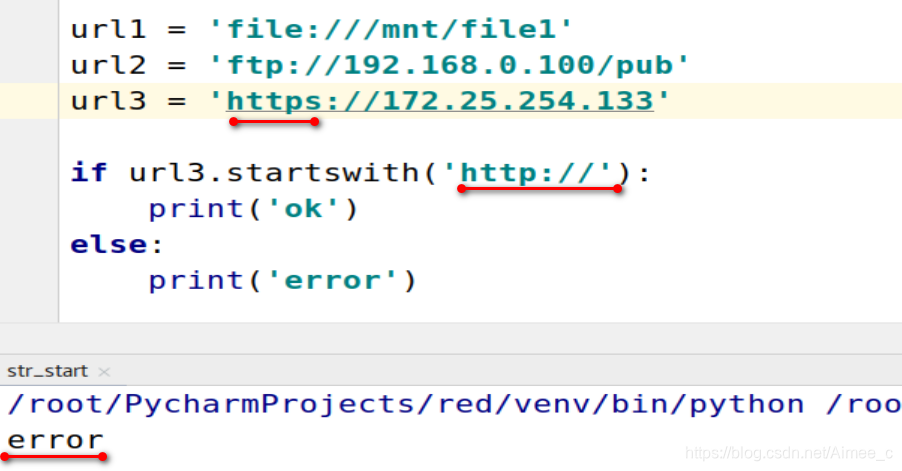
url1 = 'file:///mnt/file1'
url2 = 'ftp://192.168.0.100/pub'
url3 = 'http://172.25.254.133'
if url3.startswith('http://'):###以......开头
print('ok')
else:
print('error')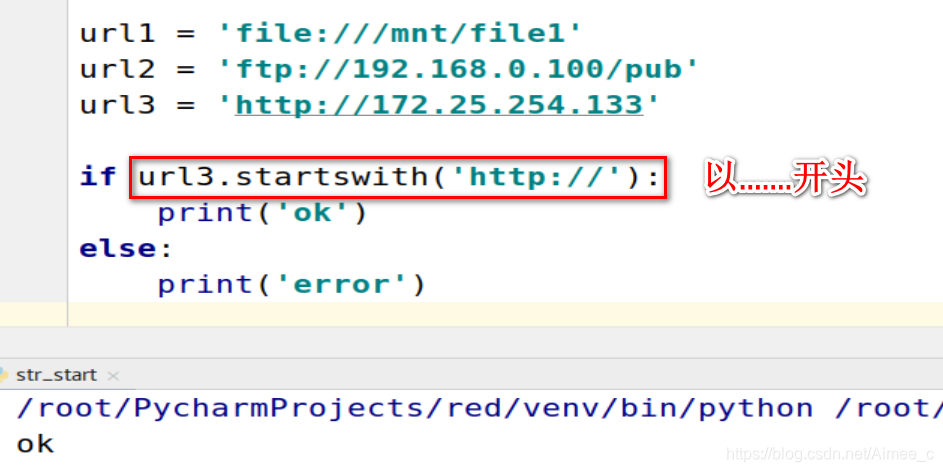
1.8 去除字符串中的空格(strip)
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。
In [1]: s = ' hello '
In [2]: s
Out[2]: ' hello '
In [3]: s.strip() ####去除所有的空格
Out[3]: 'hello'
In [3]: t = '\nhello\t\t'####注意:这里是广义上的空格
In [2]: t.strip()
Out[2]: 'hello'
In [4]: s.lstrip() ####去除左边的空格
Out[4]: 'hello '
In [5]: s.rstrip() ####去除右边的空格
Out[5]: ' hello'
In [6]: v = 'world'####去除字符串两边的字符
In [6]: v.strip('wo')
Out[6]: 'rld'
In [7]: u = 'helleh' ####去除字符串两边的字符
In [7]: u.strip('h')
Out[7]: 'elle'1.9 字符串的搜索
1.返回字符串中字符最小的索引(find)
s = 'Today is a sunny day'
print(s.find('day'))
print(s.find('sunny'))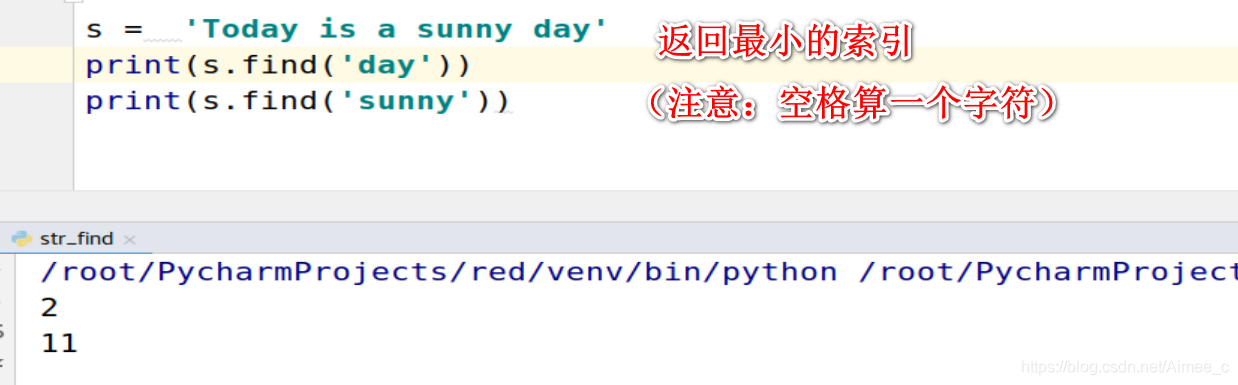
2.返回字符串中字符最大的索引(rfind)
s = 'Today is a sunny day'
print(s.rfind('day'))
print(s.rfind('sunny'))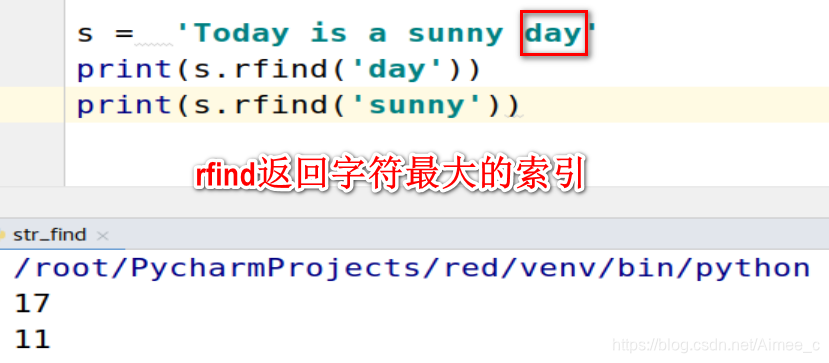
1.10 字符串的替换(replace)
s = 'Today is a sunny day'
print(s.replace('sunny','windy'))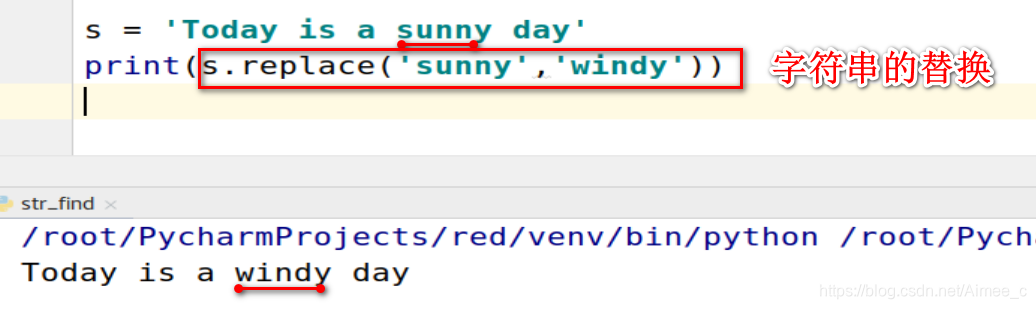
1.11 字符串的对齐
1.字符串的居中对齐(center)
s = 'hello world'
print(s.center(50))
print(s.center(50,'*'))
print(s.center(50,'-'))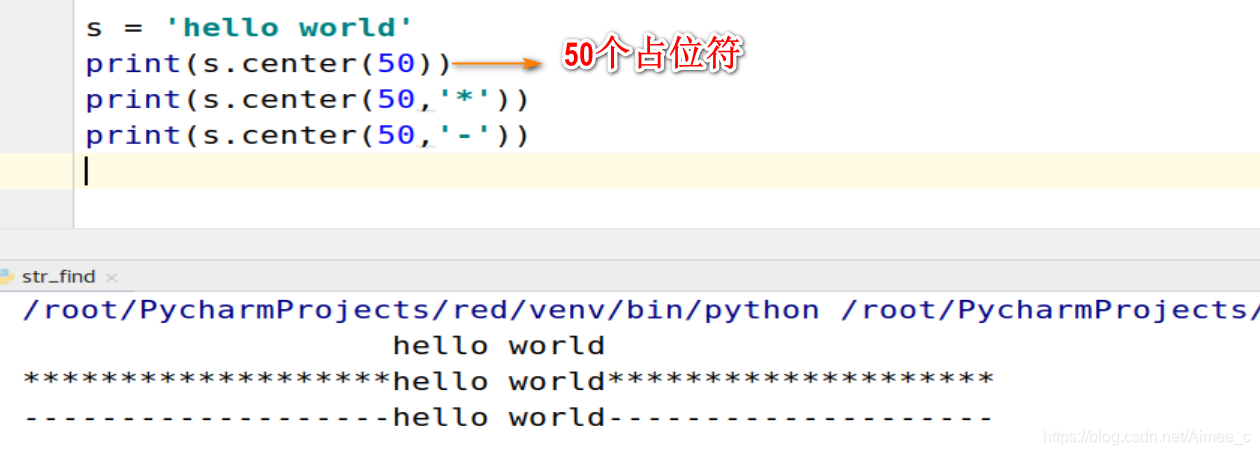
2.字符串的左对齐(ljust)
s = 'hello world'
print(s.ljust(50,'*'))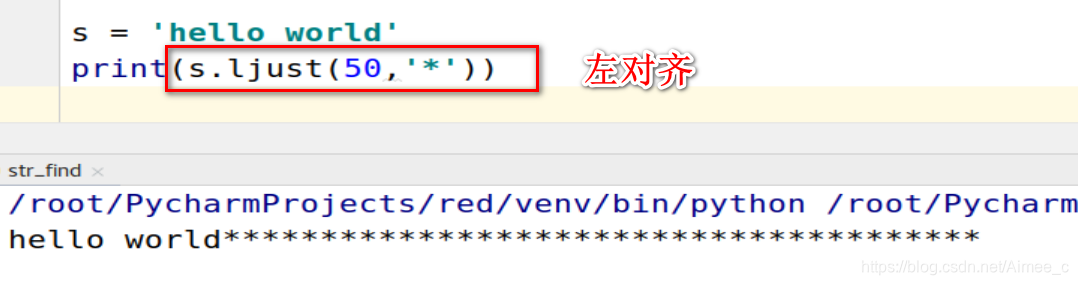
3.字符串的右对齐(rjust)
s = 'hello world'
print(s.rjust(50,'*'))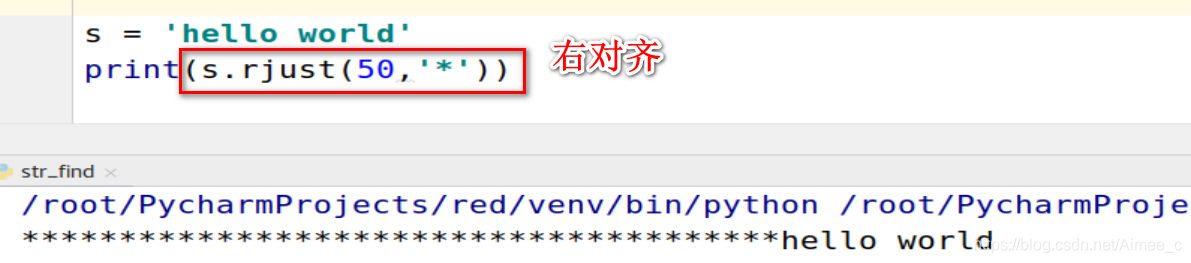
1.12 字符串的统计(count)
s = 'hello world'
print(s.count('l'))
print(s.count('ll'))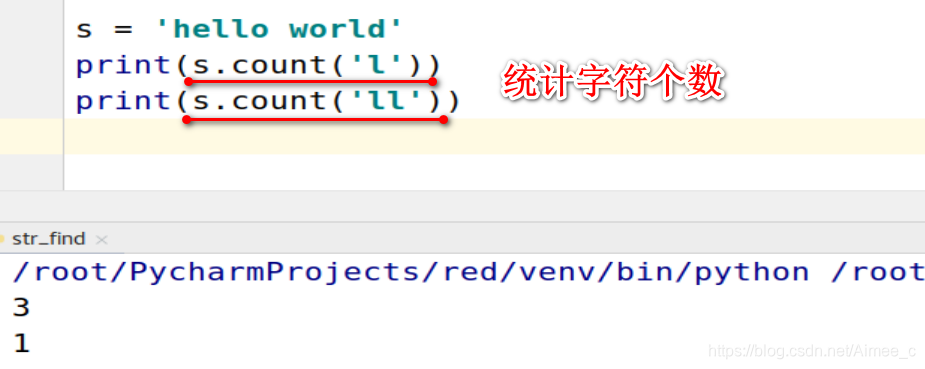
1.13 字符串的长度(len)
s1 = 'hello python'
print(len('python'))
print(len(s1))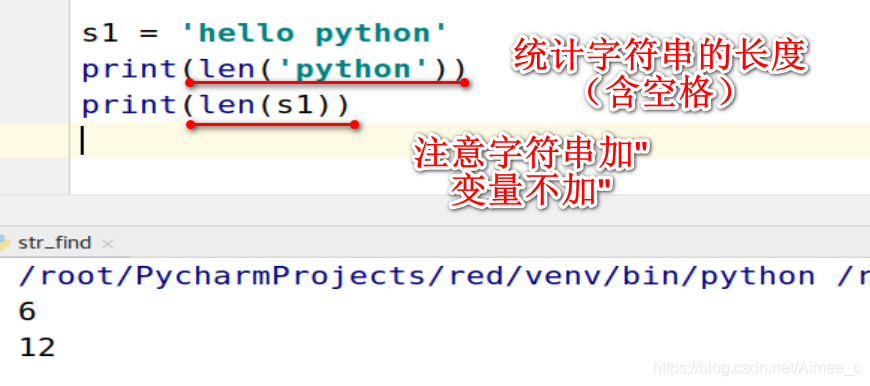
1.14 字符串的分隔(split)
s = '172.25.254.165'
print(s.split('.'))
print(s.split('.')[::-1])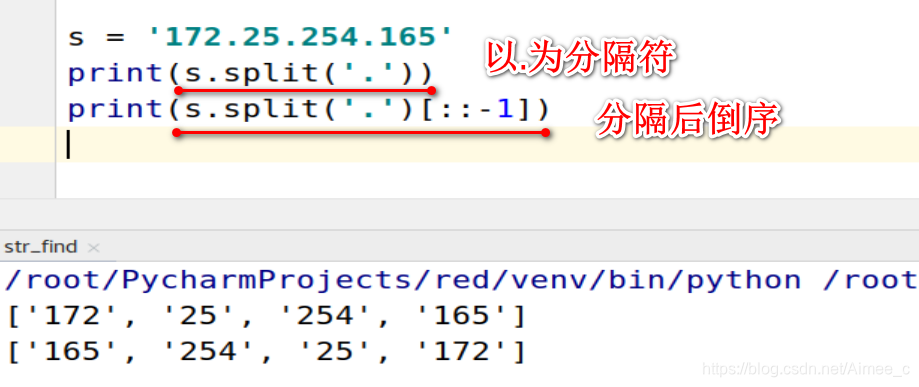
1.15 字符串的连接(join)
date = '2020-04-16'
print(''.join(date.split('-')))
print('/'.join(date.split('-')))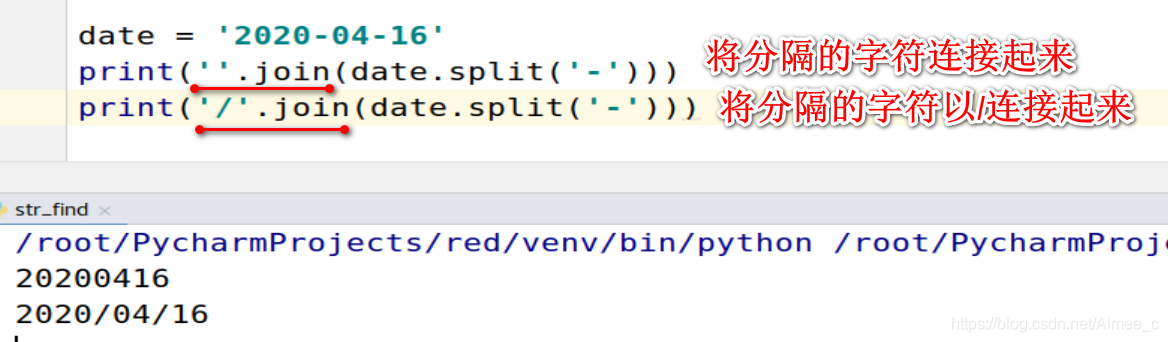
1.16 字符串的练习
练习:检测是否为回文数字
示例 1:
输入: 121
输出: true
示例 2:
输入: -121
输出: false
解释: 从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不
是一个回文数。
示例 3:
输入: 10
输出: false
解释: 从右向左读, 为 01 。因此它不是一个回文数。
num = input('Number:')
if num == num[::-1]:
print ('True')
else:
print ('False')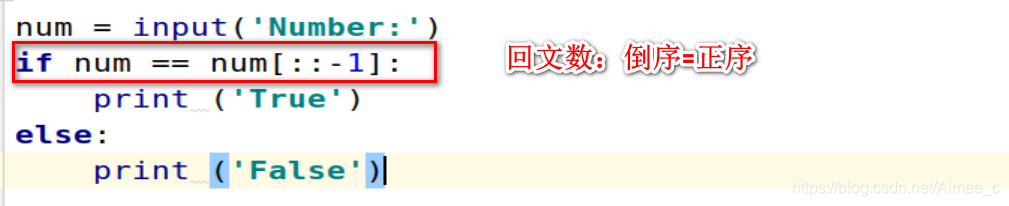

练习:变量名是否合法
1.变量名可以由字母,数字或者下划线组成
2.变量名只能以字母或者下划线开头 s = ‘hello@’
1.判断变量名的第一个元素是否为字母或者下划线 s[0]
2.如果第一个元素符合条件,判断除了第一个元素之外的其他元素s[1:]
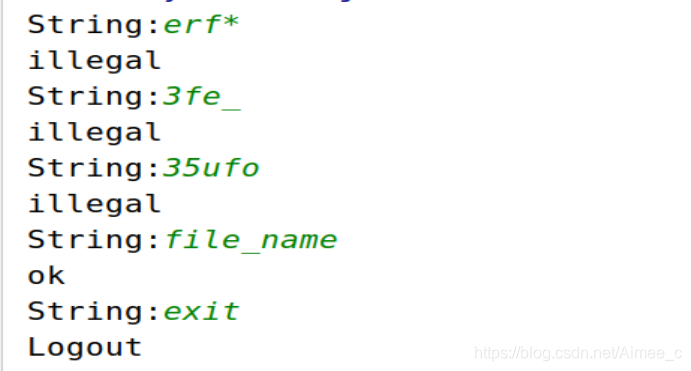
while True:
s = input('String:')
if s == 'exit':
print('Logout')
break
elif s[0].isalpha() or s[0] == '_':
for i in s[1::]:
if not(i.isalnum() or i == '_'):
print('illegal')
break
else:
print('ok')
else: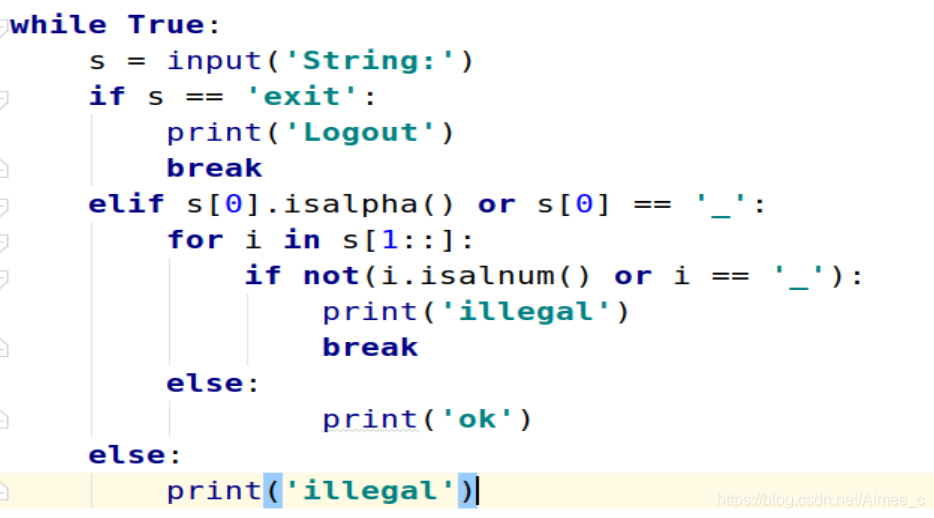
练习:根据这个学生的出勤纪录判断他是否会被奖赏
给定一个字符串来代表一个学生的出勤纪录,这个纪录仅包含以下三个字符:
‘A’ : Absent,缺勤
‘L’ : Late,迟到
‘P’ : Present,到场
如果一个学生的出勤纪录中不超过一个’A’(缺勤)并且不超过两个连续的’L’(迟到),那么这个学生会被奖赏。你需要根据这个学生的出勤纪录判断他是否会被奖赏。
示例 1:
输入: “PPALLP”
输出: True
示例 2:
输入: “PPALLL”
输出: False
在这里插入代码片方法一
s = input()
if s.count('A') <= 1 and s.count('LLL') == 0:
print('True')
else:
print('False')

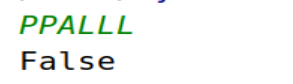
方法二
s = input()
print(s.count('A') <= 1 and s.count('LLL') == 0)
练习:将句子中的单词位置反转
题目描述:给定一个句子(只包含字母和空格), 将句子中的单词位置反转,单词用空格分割, 单词之间只有一个空格,前后没有空格。
输入描述:输入数据有多组,每组占一行,包含一个句子(句子长度小于1000个字符)
输出描述:对于每个测试示例,要求输出句子中单词反转后形成的句子
- 示例1:
- 输入:hello xiao mi
- 输出:mi xiao hello
s = input()
print(' '.join(s.split(' ')[::-1]))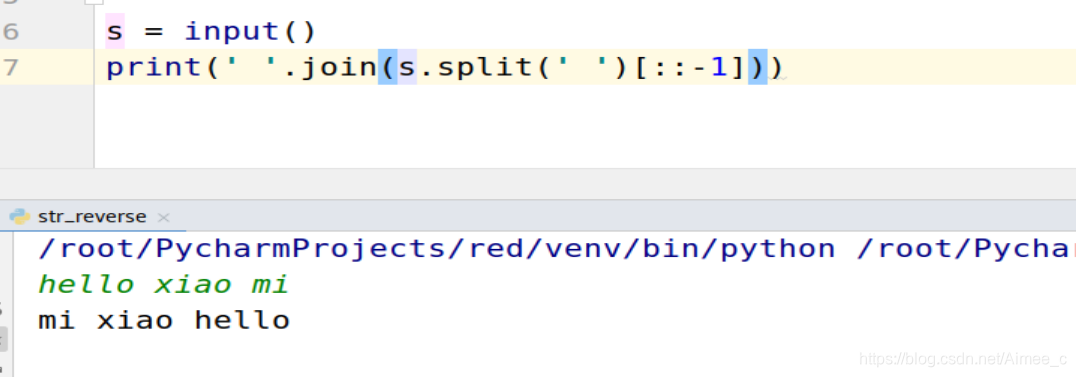
方法二:
print(' '.join(input().split(' ')[::-1]))
练习:从第一字符串中删除第二个字符串中所有的字符
题目描述:输入两个字符串,从第一字符串中删除第二个字符串中所有的字符。
输入描述:每个测试输入包含2个字符串
输出描述:输出删除后的字符串
- 示例1:
输入:They are students和aeiou
输出:Thy r stdnts.
s1 = input('String1:')
s2 = input('String2:')
for i in s1:
if i in s2:
s1 = s1.replace(i,'')
print(s1)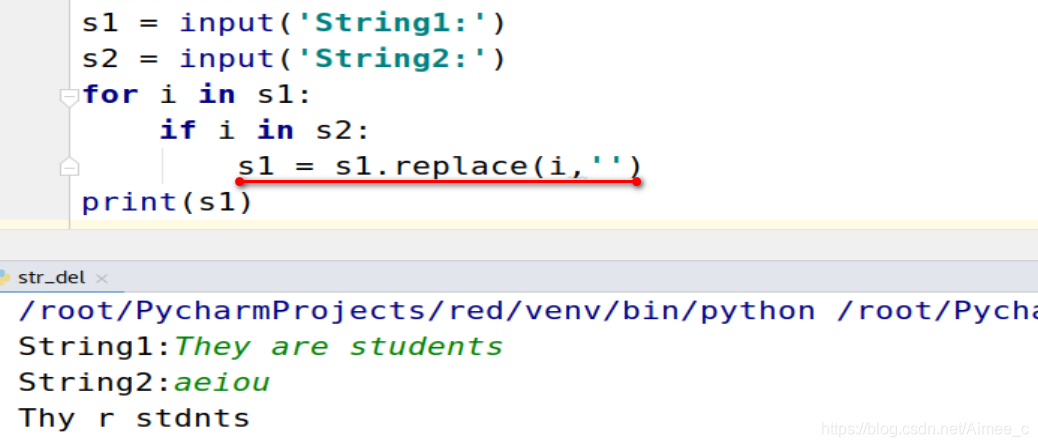
练习:10以内的加法
设计一个程序,帮助小学生练习10以内的加法
详情:
- 随机生成加法题目;
- 学生查看题目并输入答案;
- 判别学生答题是否正确?
- 退出时, 统计学生答题总数,正确数量及正确率(保留两>位小数点);
import random ##导入随机数
count = 0 ##定义计数器(统计总题数)
right = 0 ##定义计数器(统计正确的题数)
while True:
a = random.randint(0, 9)
b = random.randint(0, 9)
res = a + b
ans = input('请输入你的答案:(q离开)\n %d+%d=' % (a, b)) ##条件放循环内部
if ans == 'q':
print('logout')
break
elif ans == str(res):
print('right')
right += 1
count += 1
else:
print('error')
count += 1
percent = right / count
print('测试结束:共回答%d道题,正确%d道题,正确率为%.2f%%' %(count,right,percent*100))


练习:生成验证码/内推码
方法一
import random
import string
code_str = string.ascii_letters+string.digits
def gen_code(len=4):
code = ''
for i in range(len):
new_s = random.choice(code_str)
code += new_s
print(code)
gen_code()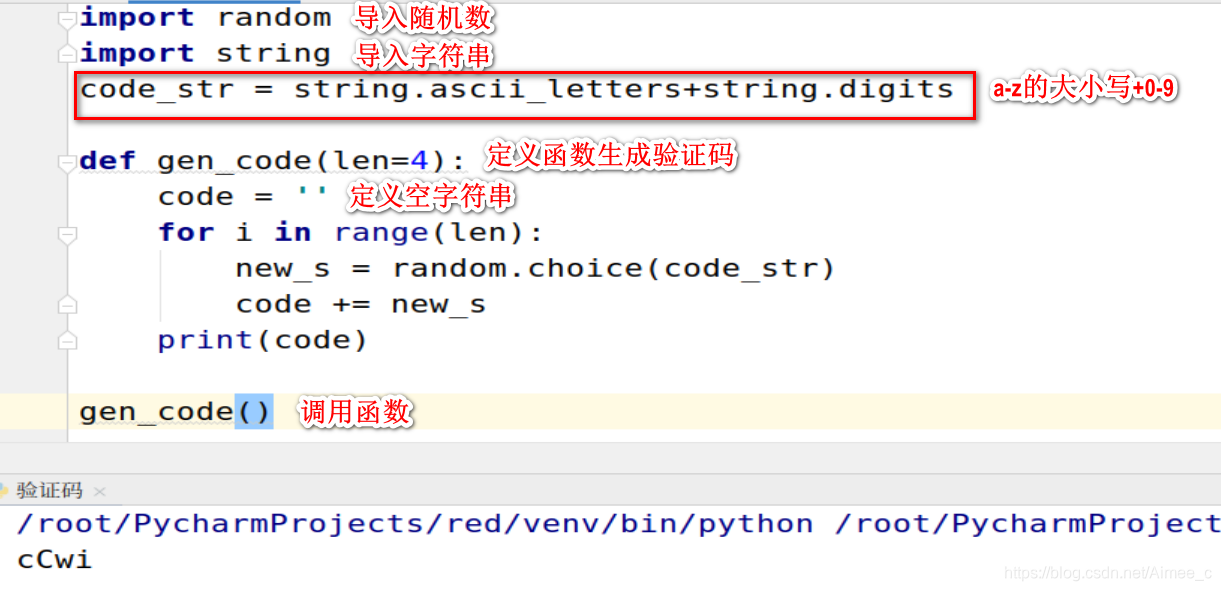
方法二
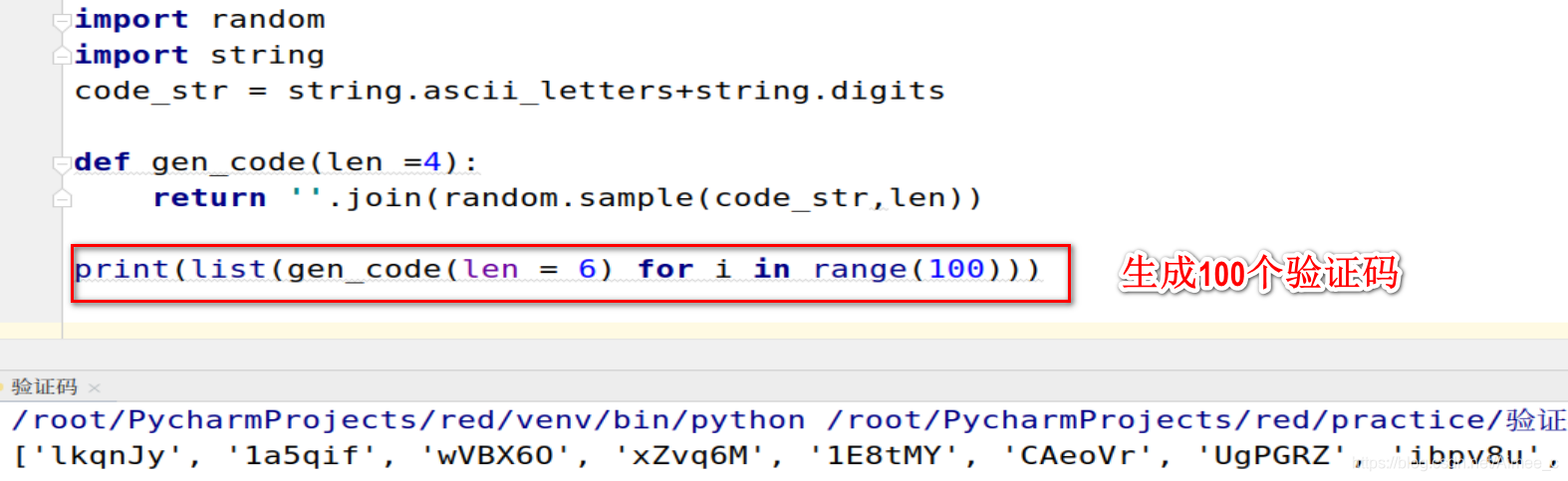
import random
import string
code_str = string.ascii_letters+string.digits
def gen_code(len =4):
return ''.join(random.sample(code_str,len))
a = gen_code()
print(a)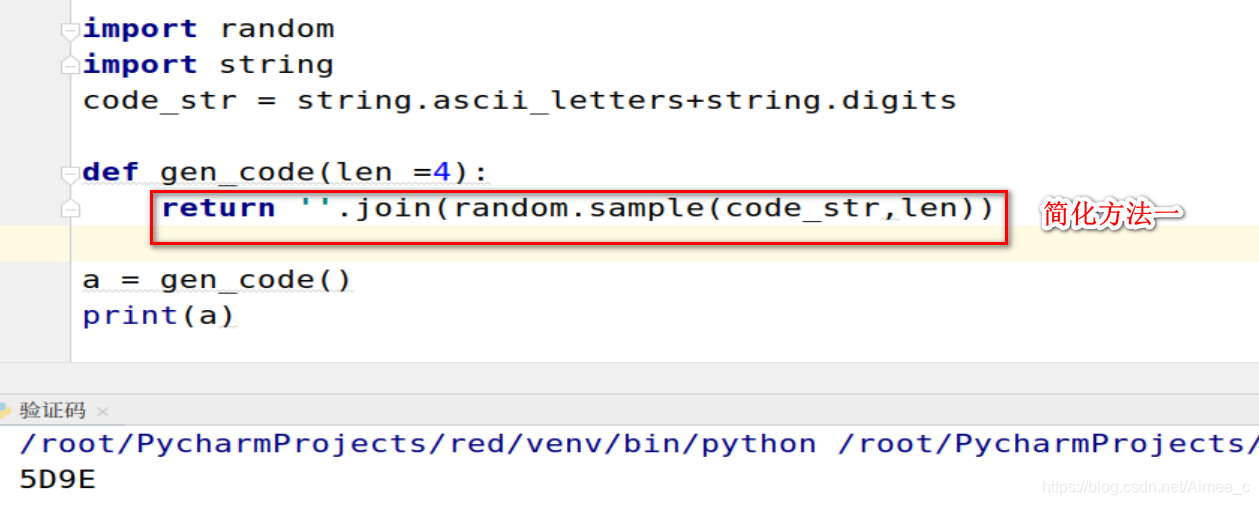
2.列表(list)
2.1 列表的定义
1.列表:一个变量存储多个信息
In [1]: name = ['tom','coco','bob','lily']
In [2]: name
Out[2]: ['tom', 'coco', 'bob', 'lily']
In [3]: type(name)
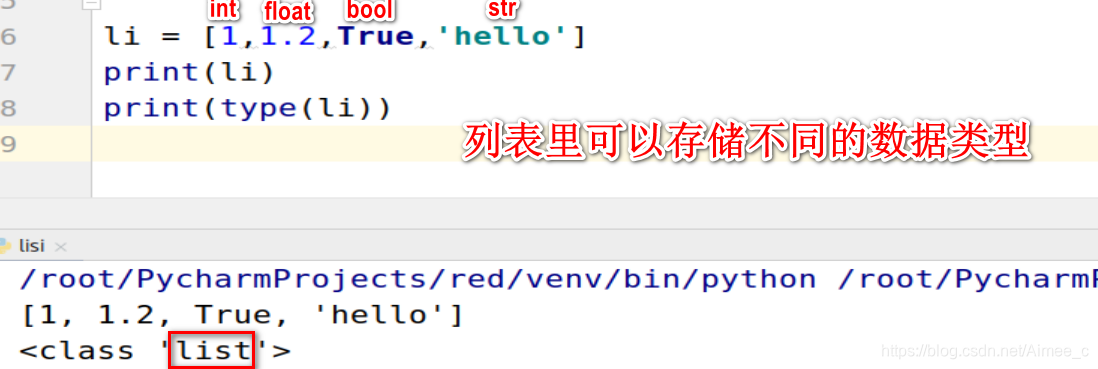
Out[3]: list2.列表里可以存储不同的数据类型
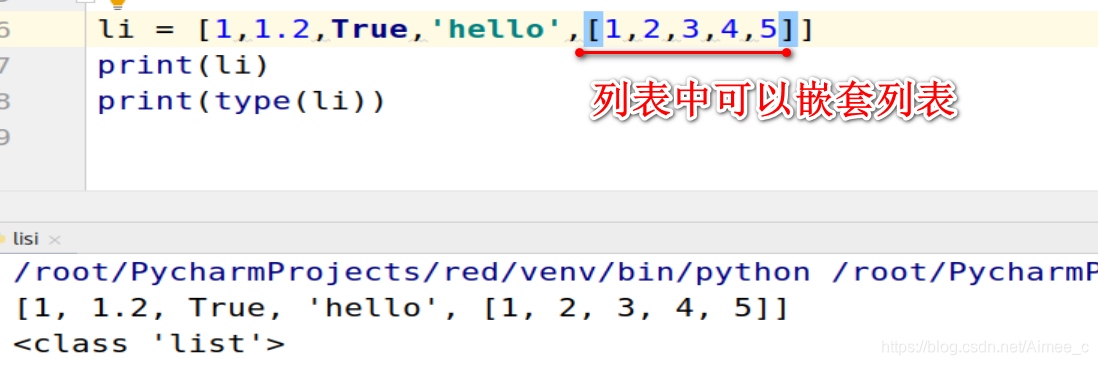
3.列表里嵌套列表
列表的特性:
2.2 列表的索引(index)
service = ['http','ssh','ftp','samba']
print(service[0])
print(service[1])
print(service[-1])
2.3 列表的切片(slice)
service = ['http','ssh','ftp','samba']
print(service[::-1])
print(service[2:])
print(service[:-1])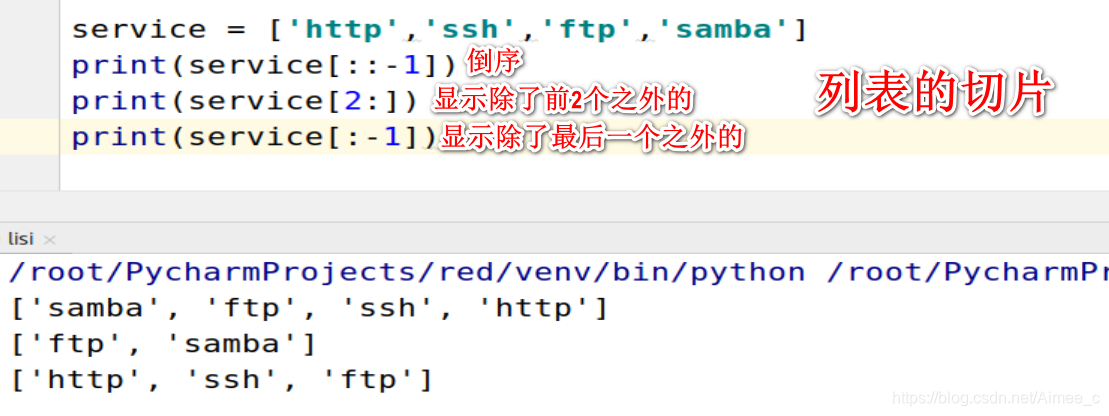
2.4 列表的重复(repeat)
service = ['http','ssh','ftp','samba']
print(service*2)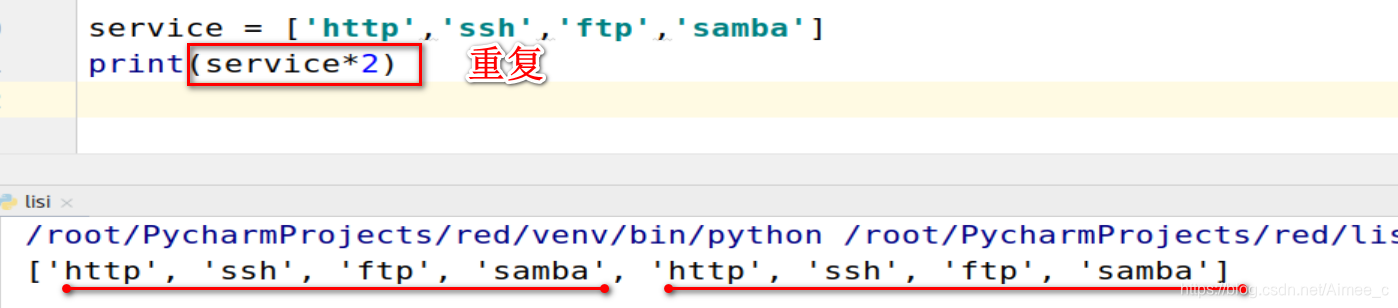
2.5 列表的拼接(link / join)
service1 = ['http','ssh','ftp']
service2 = ['samba','firewalld']
print(service1 + service2)
service = ['http','80']
print(':'.join(service))
2.6 列表的成员操作符(in / not in)
service = ['http','ssh','ftp','samba']
print('samba' in service)
print('ftp' not in service)
print('firewalld' in service)
2.7 列表的迭代(for)
service = ['http','ssh','ftp','samba']
for i in service:
print(i)
2.8 列表中嵌套列表
1.嵌套列表的索引
service = [['http','80'],['ssh','22'],['ftp','21']]
print(service[0][0])
print(service[0][1])
print(service[-1][1])
2.嵌套列表的切片
service = [['http','80'],['ssh','22'],['ftp','21']]
print(service[1:])
print(service[1:][0])
print(service[:-1])
print(service[:-1][0])
print(service[::-1])
2.9 列表的添加
append适用于添加一个元素,extend适用于添加多个元素,insert适用于添加元素到指定位置。
1.列表的添加(+)
service = ['http','ssh','ftp']
print(service+['firewalld'])
2.列表的追加(append)
注意:append只能添加一个元素
service = ['http','ssh','ftp']
service.append('samba')
print(service)
3.列表的拉伸(extend)
注意:extend可以追加多个元素到列表中
service = ['http','ssh','ftp']
service.extend(['samba','firewalld'])
print(service)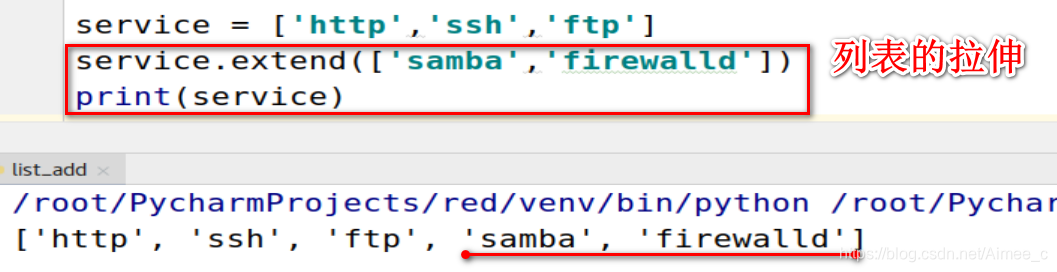
4.列表的插入(insert)
注意:insert在指定位置添加
service = ['http','ssh','ftp']
service.insert(1,'mysql')
print(service)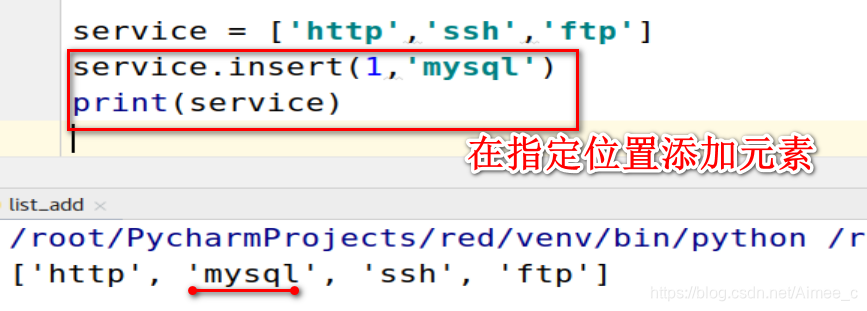
2.10 列表的删除
pop适用于索引,remove适用于指定元素。
1.列表元素的弹出(pop)
pop() 函数用于移除列表中的一个元素(默认最后一个元素),并且返回该元素的值。
注意:pop弹出列表中不会再存在这个元素,不能使用这个元素,但是内存中存在;如果需要使用需要给弹出的元素一个变量

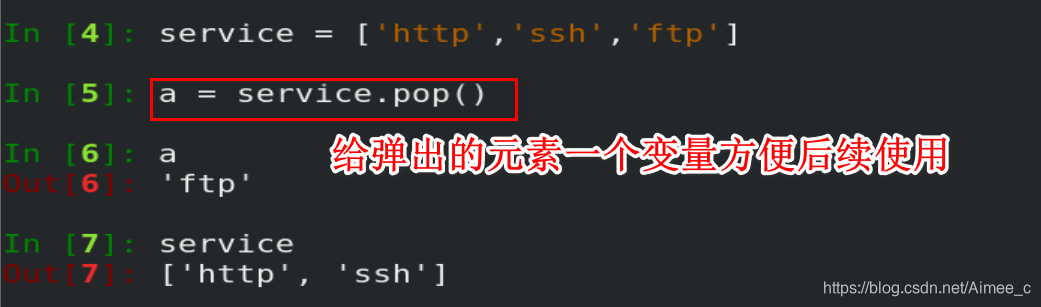
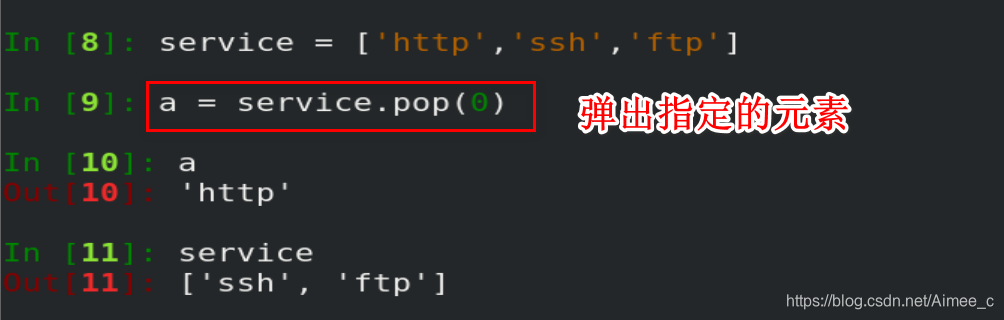
注意:如果为空列表不能弹出,会报错
2.删除列表中指定元素(remove)
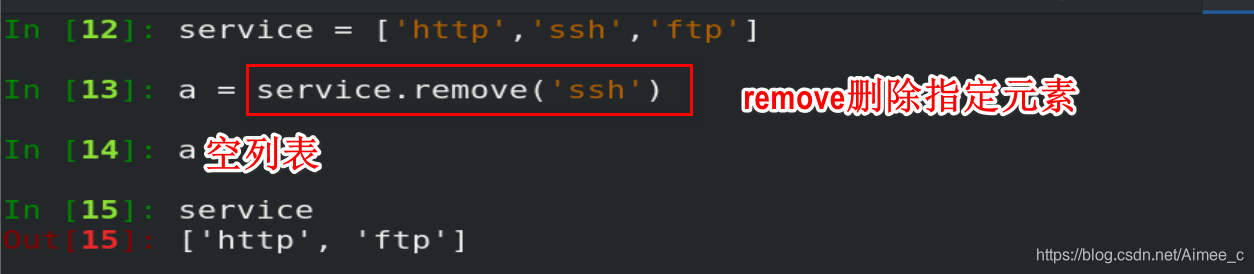
2.从内存中删除(del)
注意:del是将元素从内存中删除
service = ['http','ssh','ftp']
print(service)
del service
print(service)
2.11 列表的改写
1.通过索引修改
service = ['http','ssh','ftp']
service[0] = 'samba'
print(service)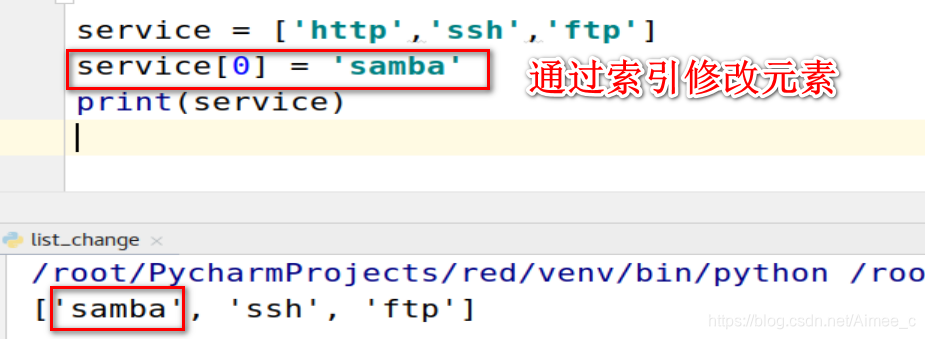
2.通过切片修改
service = ['http','ssh','ftp']
service[:2]=['samba','nfs','firewalld']
print(service)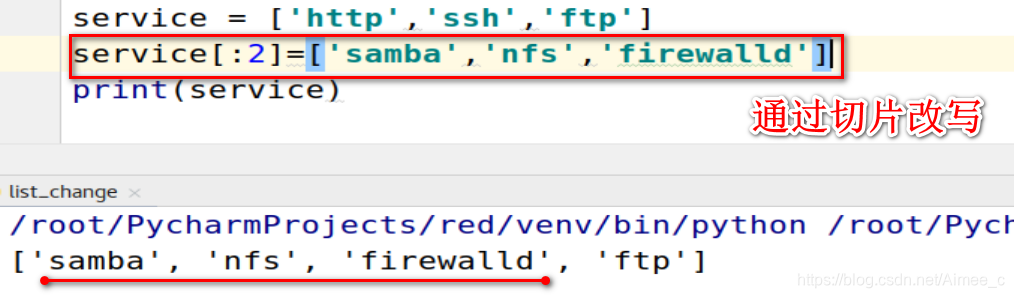
2.12 列表的查看
count适用于查看元素出现的次数,index适用于查看元素的索引值。
1.查看元素出现的次数(count)
service = ['http','ssh','ftp','ssh']
print(service.count('ssh'))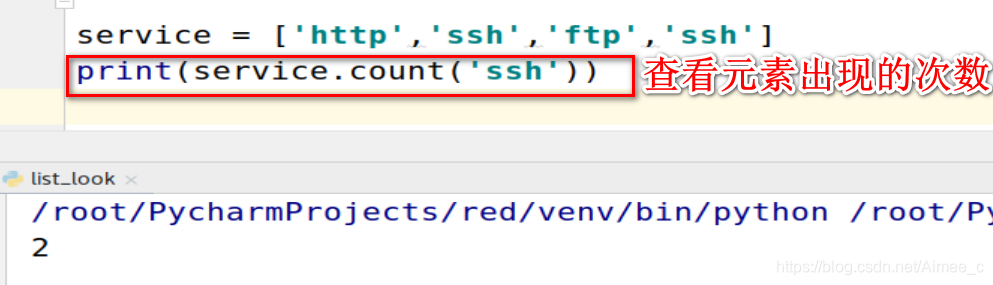
2.查看指定元素的索引值(index)
service = ['http','ssh','ftp','ssh']
print(service.index('ftp'))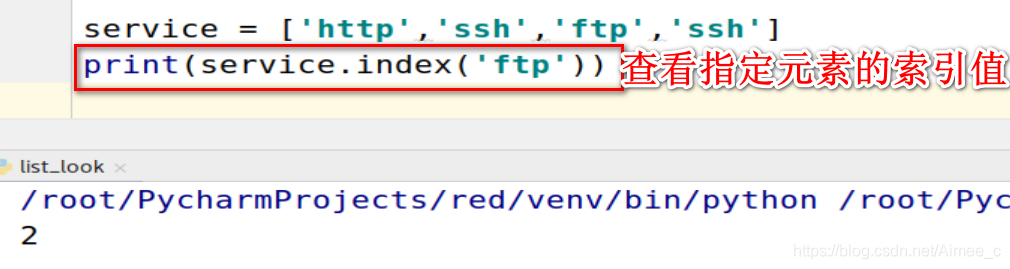
service = ['http','ssh','ftp','ssh']
print(service.index('ssh',0,2))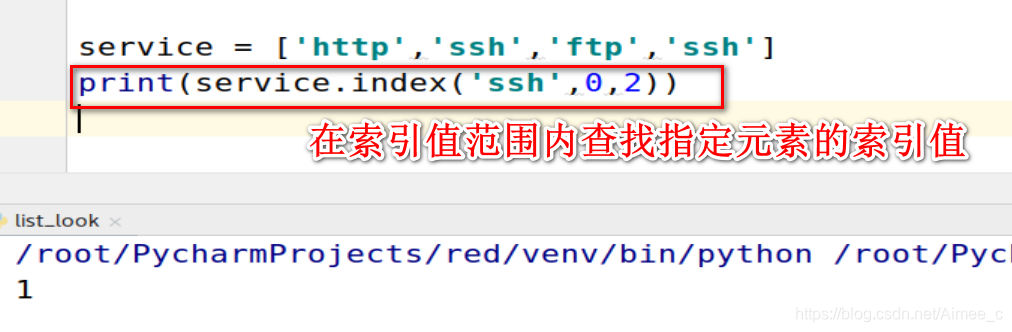
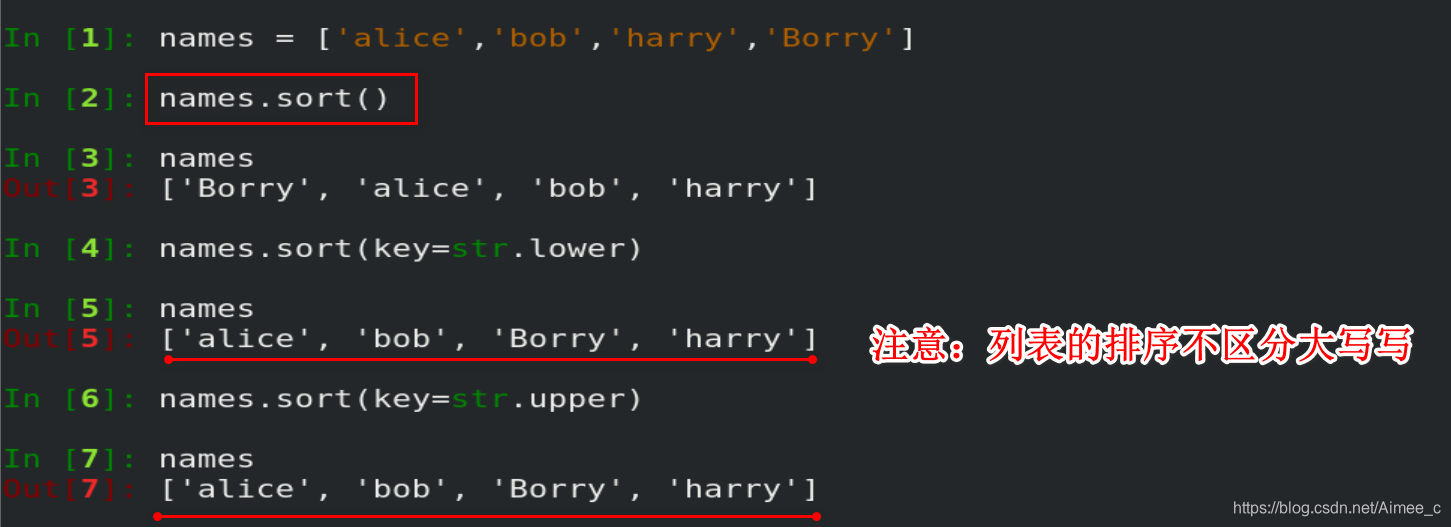
2.13 列表的排序
service = ['http','ssh','ftp','samba']
service.sort()
print(service)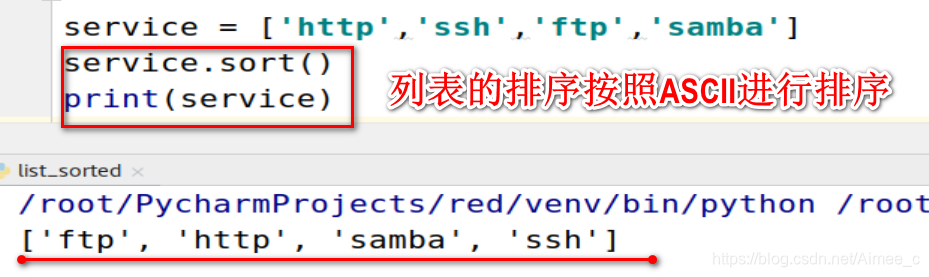
2.14 列表的打乱(random.shuffle)
print(range(10))
import random
li = list(range(10))
print(li)
random.shuffle(li)
print(li)
2.15 列表的练习
练习:列表中的元素输出为句子
假定有下面这样的列表:
names = [ ‘mango’, ‘pear’,‘peach’, ‘apple’]
输出结果为:‘I have mango,pear, peach and apple.’
names = [ 'mango', 'pear','peach', 'apple']
print('I have '+ ','.join(names[:-1])+' and '+names[-1])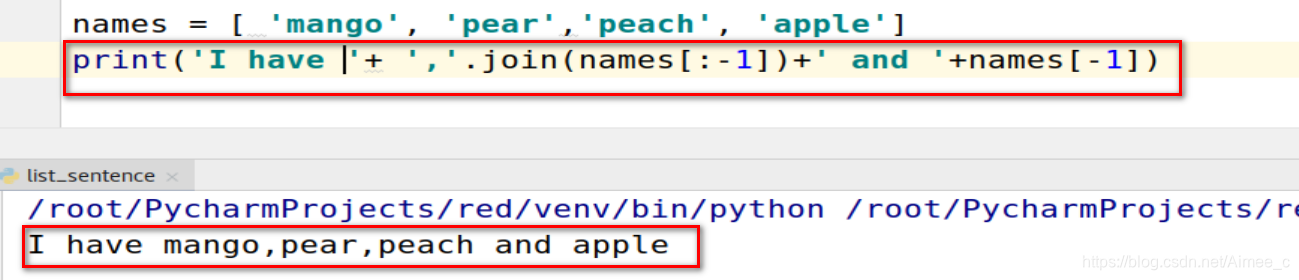
练习:用户登录检测
1.系统里面有多个用户,用户的信息目前保存在列表里面
users = [‘root’,‘westos’]
passwd = [‘123’,‘456’]
2.用户登陆(判断用户登陆是否成功
1).判断用户是否存在
2).如果存在
1).判断用户密码是否正确
如果正确,登陆成功,推出循环
如果密码不正确,重新登陆,总共有三次机会登陆
3).如果用户不存在
重新登陆,总共有三次机会
users = ['root', 'westos']
passwds = ['123', '456']
trycount = 0
while trycount < 3:
inuser = input('Username:')
inpasswd = input('Password:')
trycount += 1 ###输完用户名密码后统计次数
if inuser in users:
index = users.index(inuser)###获取用户所对应的索引值
passwd = passwds[index]###获取上一布索引值对应的密码
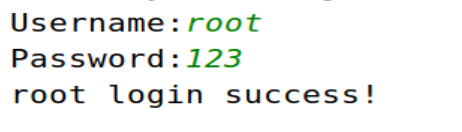
if inpasswd == passwd:
print('%s login success!' %inuser)
break
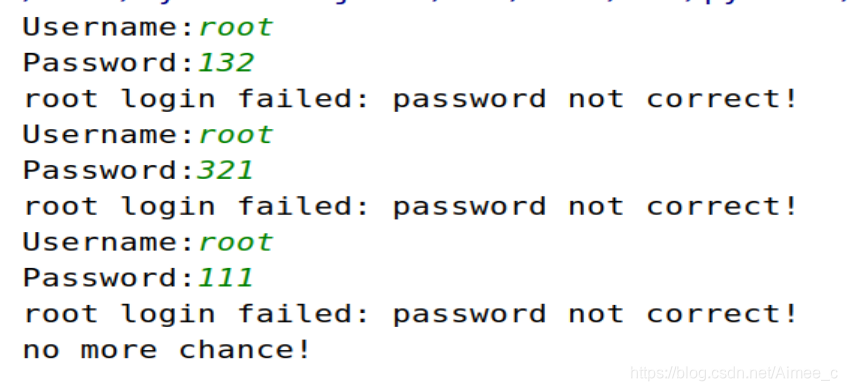
else:
print('%s login failed: password is not correct!' %inuser)
else:
print('User %s not exist!' %inuser)
else:
print('no more chance!')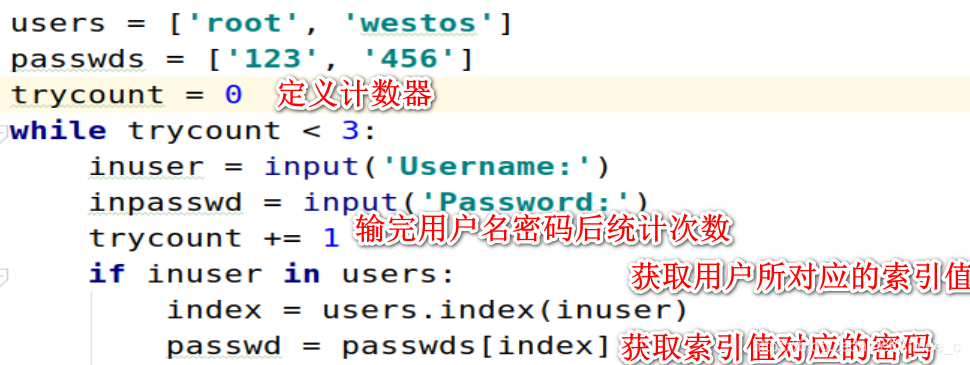

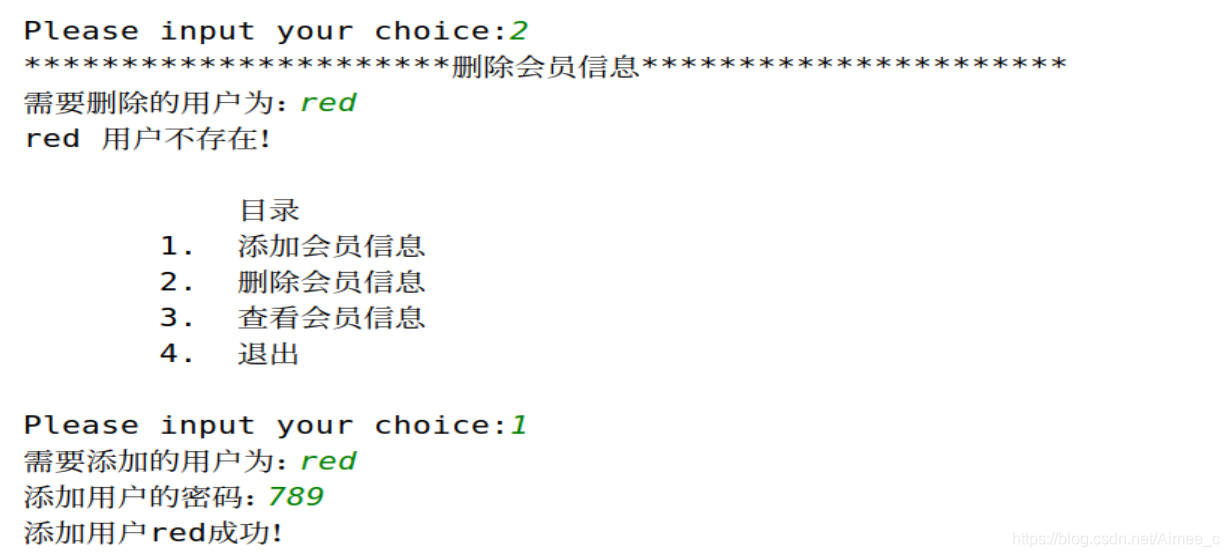
练习:管理后台用户
- 后台管理员只有一个用户: admin, 密码: admin
- 当管理员登陆成功后, 可以管理前台会员信息.
- 会员信息管理包含:
添加会员信息
删除会员信息
查看会员信息
退出
print('管理员登陆'.center(50,'*'))
inuser = input('Username:')
inpasswd = input('Password:')
users = ['root', 'westos']
passwds = ['123', '456']
if inuser == 'admin' and inpasswd == 'admin':
print('管理员登陆成功!')
print('会员信息管理'.center(50,'*'))
while True:
print("""
目录
1. 添加会员信息
2. 删除会员信息
3. 查看会员信息
4. 退出
""")
choice = input('Please input your choice:')
if choice == '1':
adduser = input('需要添加的用户为:')
if adduser in users:
print('%s用户已经存在!' %adduser)
else:
addpasswd = input('添加用户的密码:')
users.append(adduser)
passwds.append(addpasswd)
print('添加用户%s成功!' %adduser)
elif choice == '2':
print('删除会员信息'.center(50,'*'))
deluser = input('需要删除的用户为:')
if deluser not in users:
print('%s用户不存在!' %deluser)
else:
delindex = users.index(deluser)
users.remove(deluser)###删除指定元素用remove
passwds.pop(delindex)###删除索引元素用pop
print('删除用户%s成功!' %deluser)
elif choice == '3':
print('查看会员信息'.center(50,'*'))
print('\t用户名\t密码' )
usercount = len(users)###列表的长度即列表中元素个数
for i in range(usercount):
print('\t%s\t%s' %(users[i],passwds[i]))
elif choice == '4':
exit()
else:
print('Please check your input!')
else:
print('管理员登陆失败!')



练习:栈的工作原理
入栈 append
出栈 pop
栈顶元素
栈的长度 len
栈是否为空 len == 0
stack = []
print('栈的工作原理'.center(50,'*'))
while True:
print("""
目录
1. 入栈
2. 出栈
3. 栈顶元素
4. 栈的长度
5. 栈是否为空
6. 离开
""")
choice = input('Please input your choice:')
if choice == '1':
additem = input('入栈的元素为:')
stack.append(additem)
print('元素%s入栈成功!' %additem)
elif choice == '2':
delitem = input('出栈的元素为:')
if not stack:
print('元素%s不存在,不能出栈!' %delitem)
else:
stack.pop(delitem)
print('元素%s出栈成功!' % delitem)
elif choice == '3':
if len(stack) == 0:
print('栈为空')
else:
print('栈顶元素为:%s' %(stack[-1]))
elif choice == '4':
print('栈的长度为:%s' %len(stack))
elif choice == '5':
if len(stack) == 0:
print('栈为空')
else:
print('栈不为空')
elif choice == '6':
exit()
else:
print('Please check your input')
3.Python 中的内置函数
3.1 求最小值(min)
n [1]: min(3,4)
Out[1]: 3
3.2 求最大值(max)
In [2]: max(6,10)
Out[2]: 103.3 求和(sum)
In [3]: sum(range(1,101))###求1-100的和
Out[3]: 5050
In [4]: sum(range(1,101,2))###求1-100所有奇数的和
Out[4]: 2500
In [5]: sum(range(2,101,2))###求1-100所有偶数的和
Out[5]: 25503.4 枚举(enumerate)
枚举:
for i,v in enumerate('hello'):
print(i,v)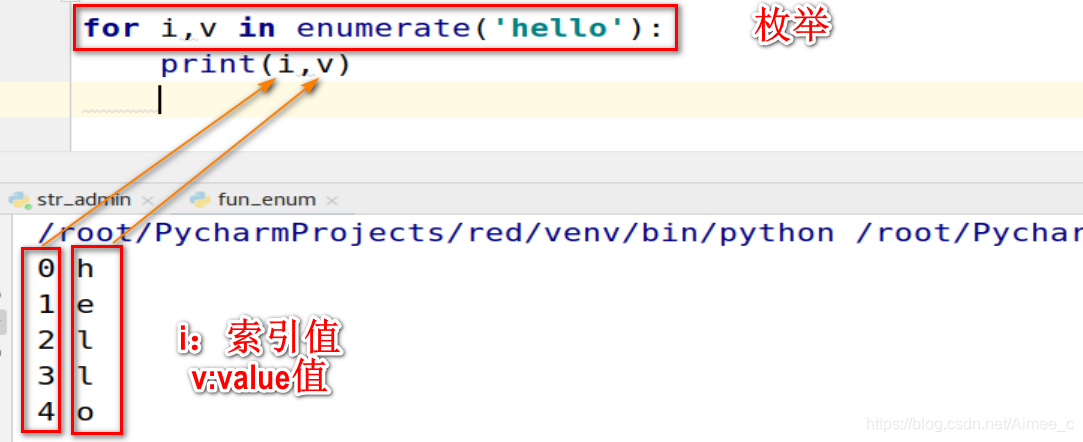
3.5 压缩(zip)
将两个字符串压缩为一个字符串
s1 = 'abc'
s2 = '123'
for i in zip(s1,s2):
print(i)
for i in zip(s1,s2):
print(''.join(i))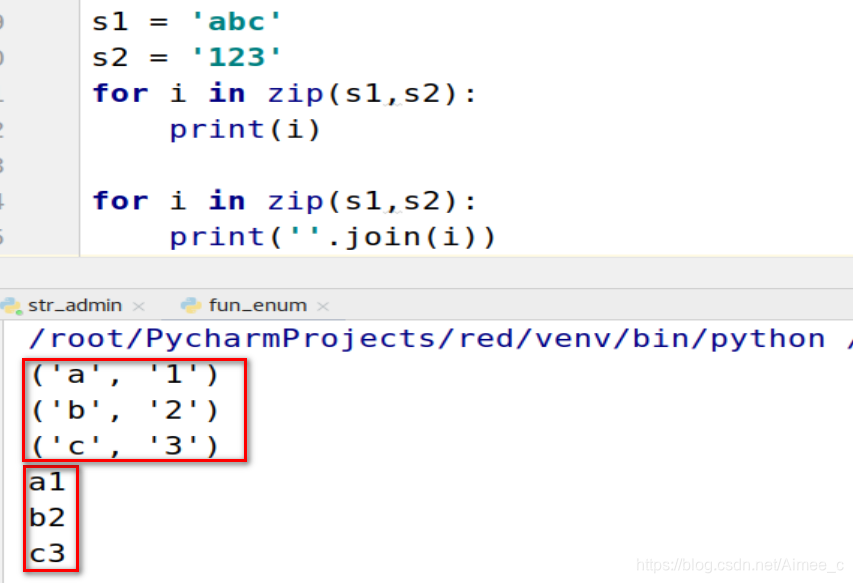
4 元组(tuple)
4.1 元组的定义
1.元组本身是一个不可变的数据类型,没有增删改查,但是元组内可以存储任意变量。
t = (1,2.3,True,'westos')
print(type(t))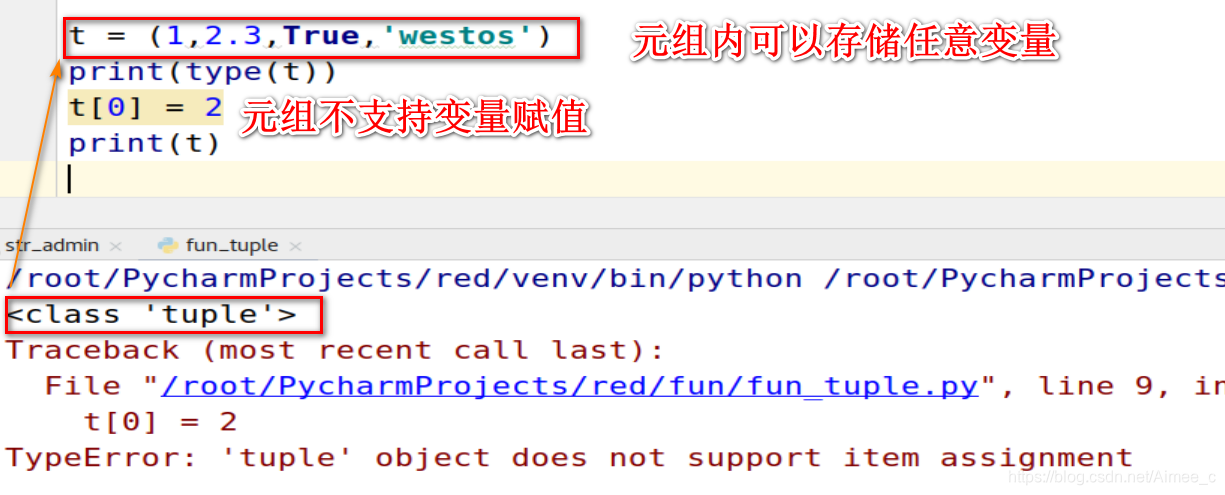
2.元组中的列表是可变数据类型,可以通过修改列表简介修改元组
t1 = ([1,2,3,4],4)
t1[0].append(5)
print(t1)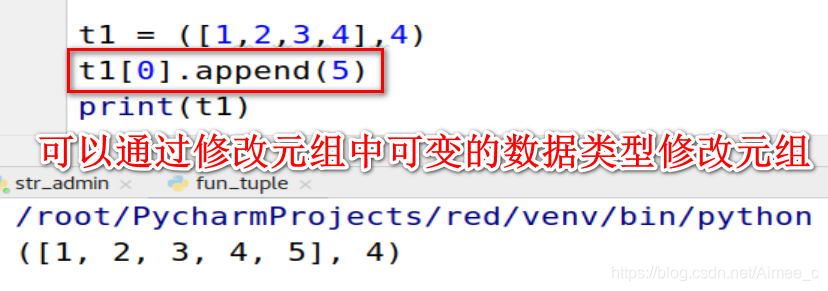
3.如果元组中只有一个元素,需要加,(逗号)

元组的特性:
4.2 元组的索引(index)
services = ('http','ssh','ftp')
print(services[0])
print(services[-1])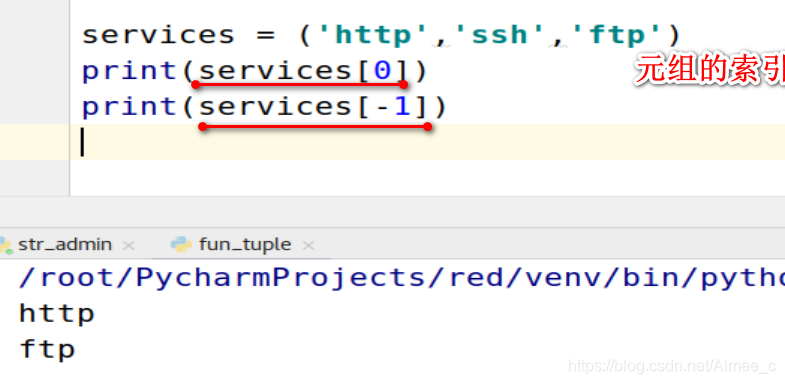
4.3 元组的切片(slice)
services = ('http','ssh','ftp')
print(services[::-1])
print(services[1:])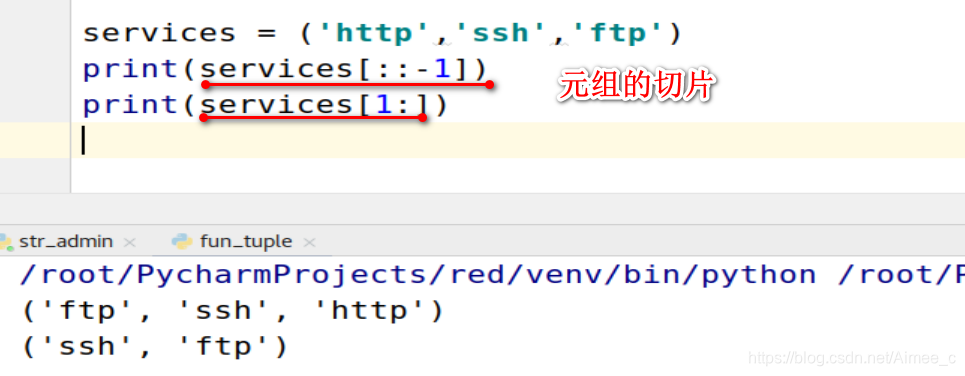
4.4 元组的重复(repeat)
services = ('http','ssh','ftp')
print(services*2)
4.5 元组的连接(link)
services = ('http','ssh','ftp')
print(services + ('samba','nfs'))
4.6 元组的成员操作符(in / not in)
services = ('http','ssh','ftp')
print('ftp' in services)
print('ftp' not in services)
4.7 元组的迭代(for)
services = ('http','ssh','ftp')
port = (80,22,21)
for index,service in enumerate(services):
print(index,service)
services = ('http','ssh','ftp')
ports = (80,22,21)
for service,port in zip(services,ports):
print(service,':',port)
4.8 元组的查看
查看元组中元素出现的次数(count)
t = (1,2.3,True,'red',2.3)
print(t.count('red'))
print(t.count(2.3))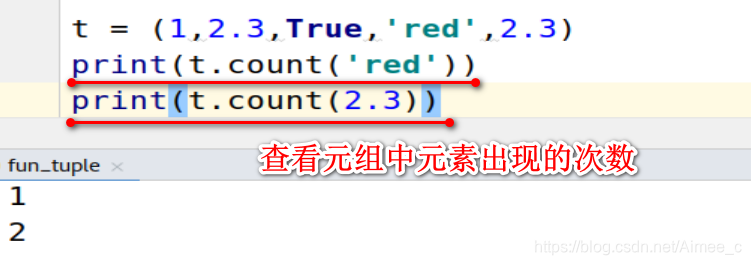
查看元组中指定元素的索引值(index)
t = (1,2.3,True,'red',2.3)
print(t.index(1))
print(t.index('red'))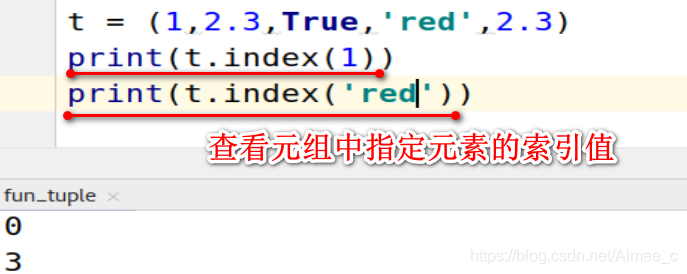
4.9 元组的赋值
t = ('red',11,100)
name,age,score = t
print(name,age,score)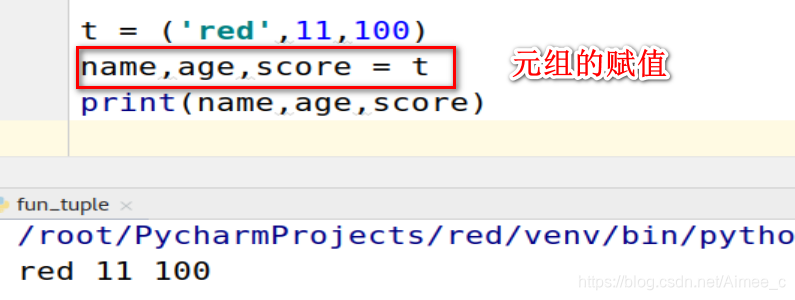
4.10 元组的排序(sort)
scores = (100,89,45,78,65)
scoreli = list(scores)##把元组转换为列表
scoreli.sort()##列表进行排序
t = tuple(scoreli)##把列表再转换为元组
print(t)
4.11 元组的练习
求平均成绩(去掉最高最低分)
scores = (100,89,45,78,65)
scoreli = list(scores)
scoreli.sort()
t = tuple(scoreli)
minscore,*middlescore,maxscore = t
print(minscore)
print(middlescore)
print(maxscore)
print(sum(middlescore)/len(middlescore))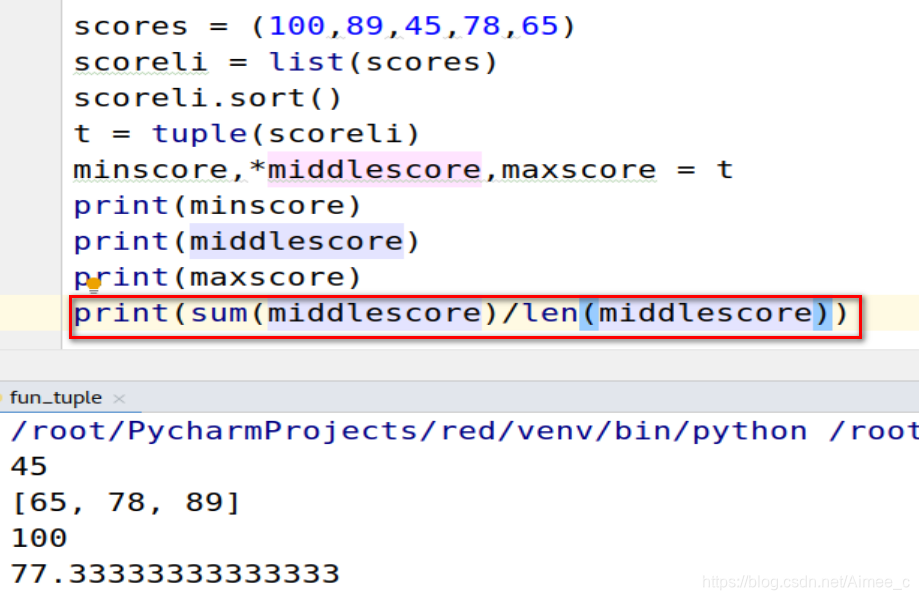
5. 集合(set)
5.1 集合的定义
集合中的元素不可重复
s = {
1,2,3,1,2,3,4,5}
print(s)
print(type(s))
s1 = {
1}
print(s1)
print(type(s1))
定义空集合
s2 = {
}
print(type(s2))
s3 = set([])
print(type(s3))
5.2 集合的去重
li = [1,2,3,1,2,3]
print(list(set(li)))
5.3 集合支持成员操作符
s = {
1,2,3,4,5}
print(2 in s)
5.4 集合支持迭代(for)
s = {
1,2,3,4,5}
for i in s:
print(i,end='|')
5.4 集合支持枚举
s = {
1,2,3,4,5}
for i,v in enumerate(s):
print(i,v)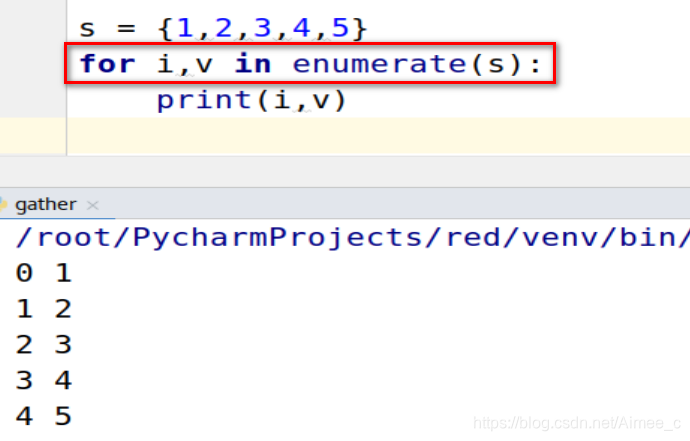
5.5 集合的增加
增加一个元素(add)
s = {
6,7,8,9}
s.add(1)
print(s)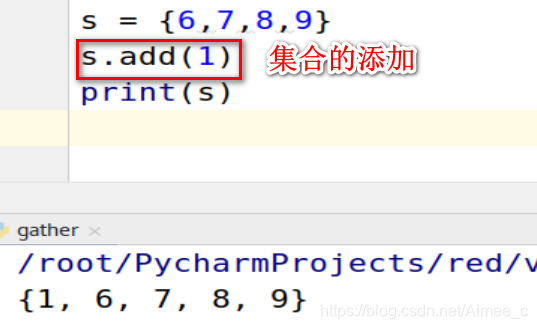
增加多个元素(update)
s = {
6,7,8,9}
s.update({
5,3,2})
print(s)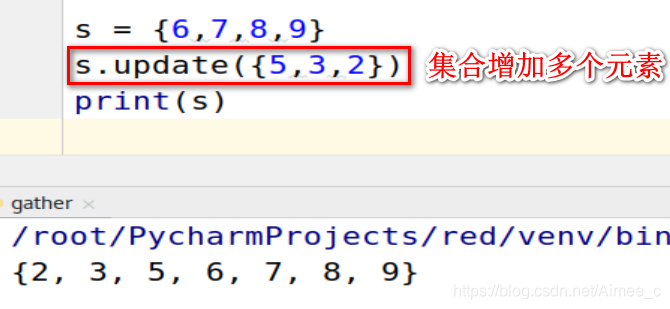
5.6 集合的删除
pop(随机删除)
s = {
6,7,8,9}
s.pop()
print(s)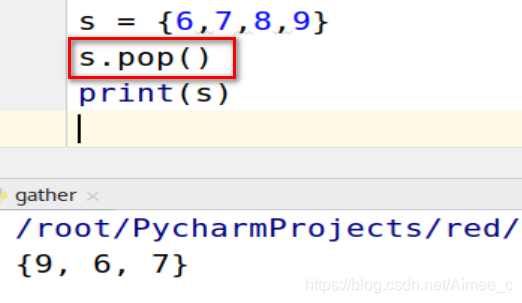
remove(指定删除)
s = {
6,7,8,9}
s.remove(6)
print(s)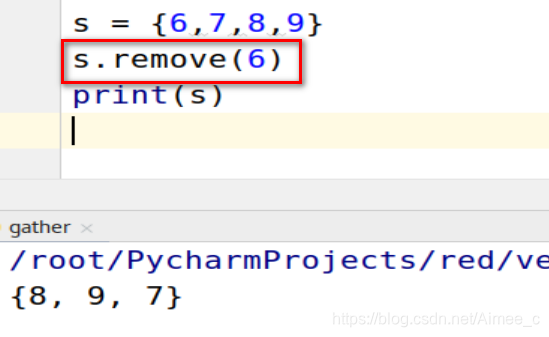
5.7 集合的交集(intersection/&)
s1 = {
1,2,3}
s2 = {
2,3,4}
print('交集:',s1.intersection(s2))
print('交集:',s1 & s2)
5.8 集合的并集(union / |)
s1 = {
1,2,3}
s2 = {
2,3,4}
print('并集:',s1.union(s2))
print('并集:',s1 | s2)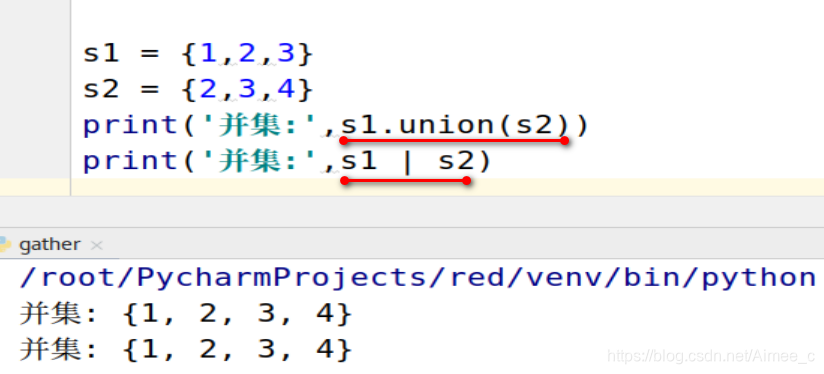
5.9 集合的差集(difference)
s1 = {
1,2,3}
s2 = {
2,3,4}
print('差集:',s1.difference(s2)) # s1-(s1&s2)
print('差集:',s2.difference(s1)) # s2-(s1&s2)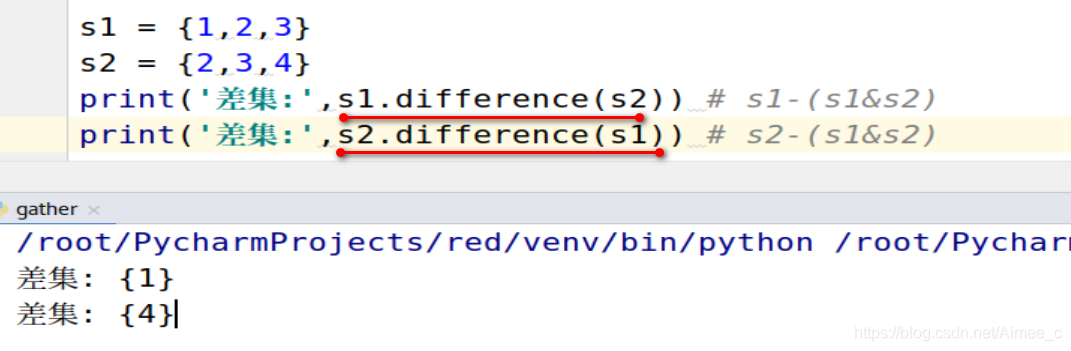
5.10 集合的对等差分:并集-差集(symmetric_difference/^)
s1 = {
1,2,3}
s2 = {
2,3,4}
print('对等差分:',s1.symmetric_difference(s2))
print('对等差分:',s1^s2)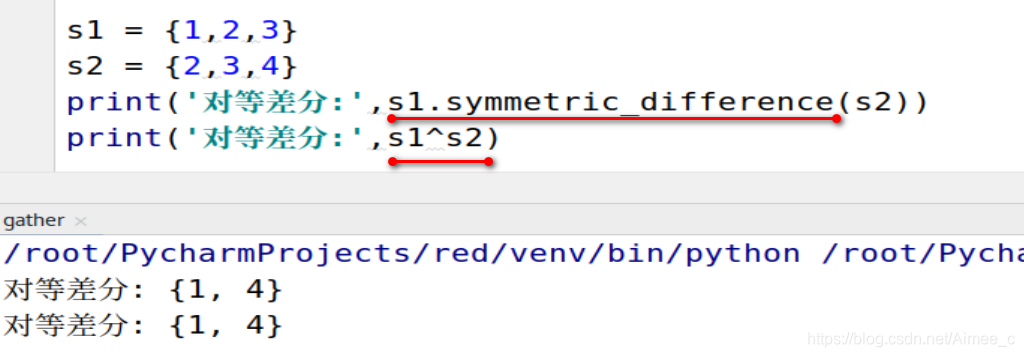
5.11 集合的超集
s1 = {
1,2}
s2 = {
1,2,3}
print(s2.issuperset(s1))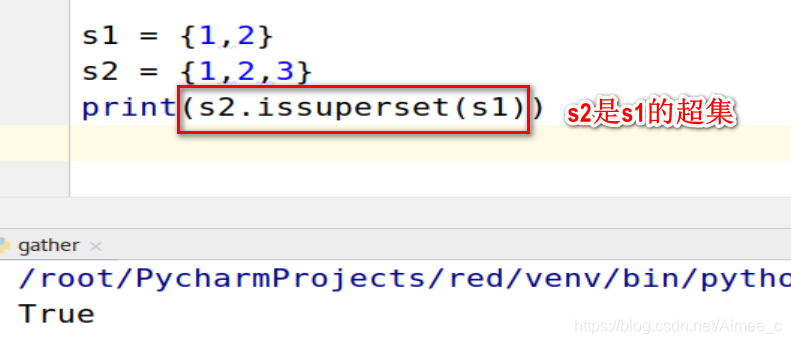
5.12 集合的子集
s1 = {
1,2}
s2 = {
1,2,3}
print(s1.issubset(s2))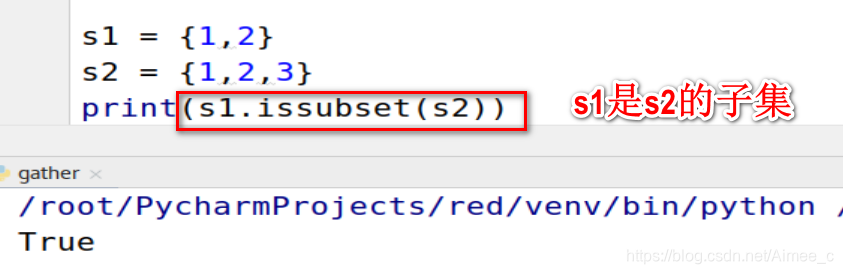
5.13 集合的不相交
s1 = {
1,2}
s2 = {
1,2,3}
print(s1.isdisjoint(s2))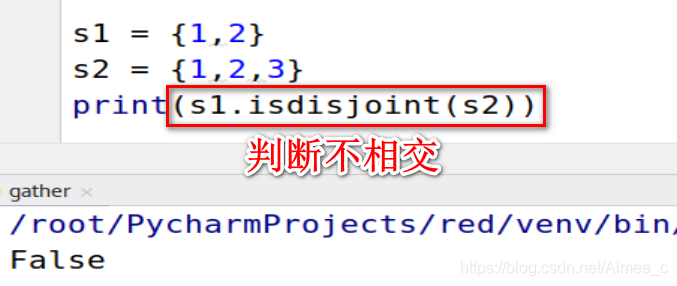
5.14 集合的练习
对数字进行去重排序
明明想在学校中请一些同学一起做一项问卷调查,为了实验的客观性
他先用计算机生成了N个1~1000之间的随机整数(N<=1000),N是用户输入的,对于其中重复的数字,只保留一个,把其余相同的数字去掉,不同的数对应着不>同的学生的学号,然后再把这些数从小到大排序,按照排好的顺序去找同学做调查,请你协助明明完成“去重”与排序工作
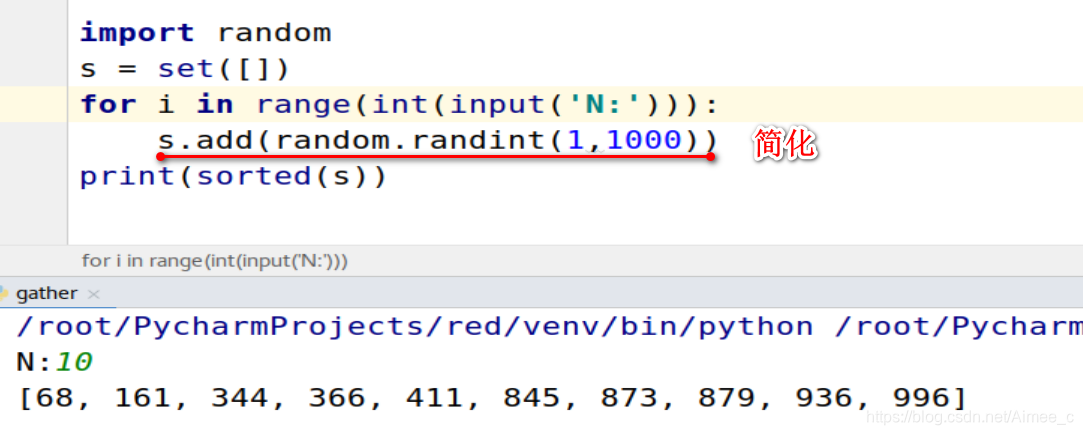
import random
s = set([])##定义空列表去重
for i in range(int(input('N:'))):
num = random.randint(1,1000)
s.add(num)
print(sorted(s))##排序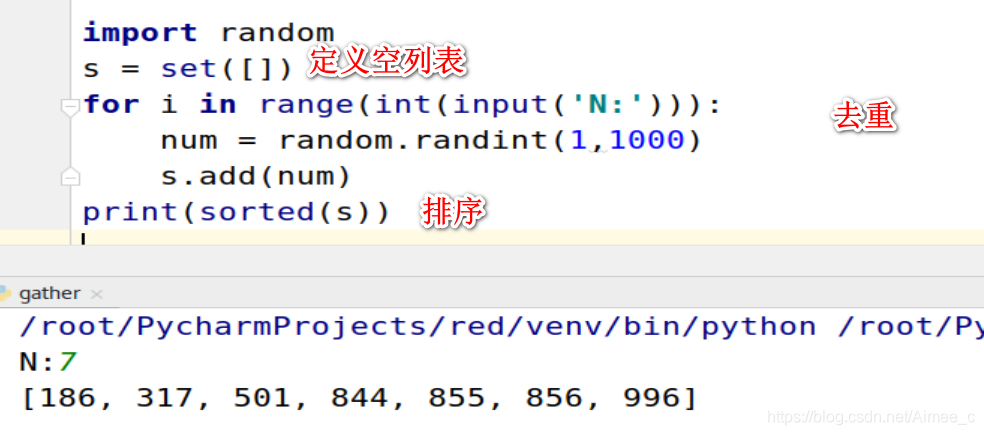
6.字典(dict)
6.1 字典的定义
字典是无序的数据集合,使用字典的输出顺序与定义的顺序不同。
users = ['user1','user2']
passwds = ['123','456']
print(zip(users,passwds))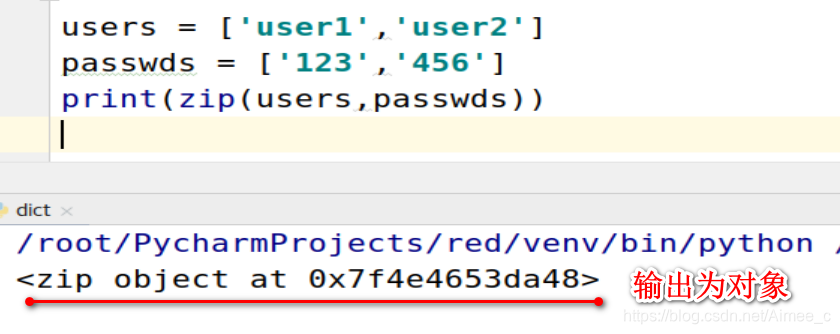
users = ['user1','user2']
passwds = ['123','456']
print(list(zip(users,passwds)))
users = ['user1','user2']
passwds = ['123','456']
print(dict(zip(users,passwds)))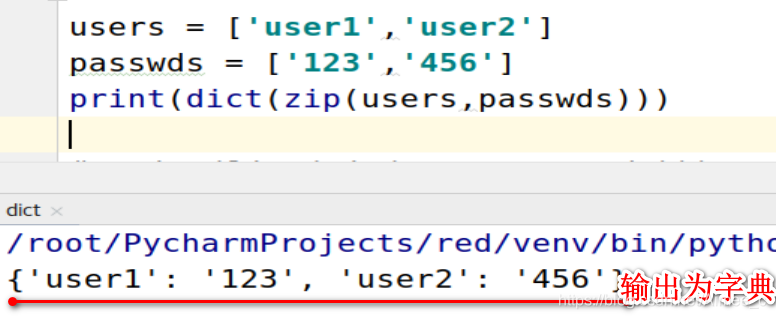
空字典
s = {
}
print(type(s))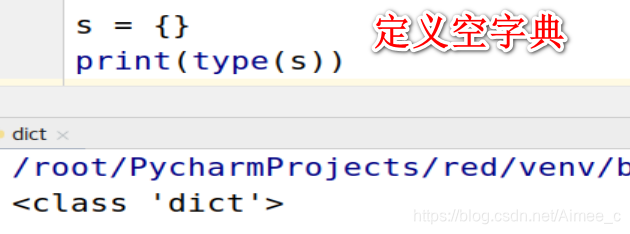
工厂函数
d = dict()
print(d)
print(type(d))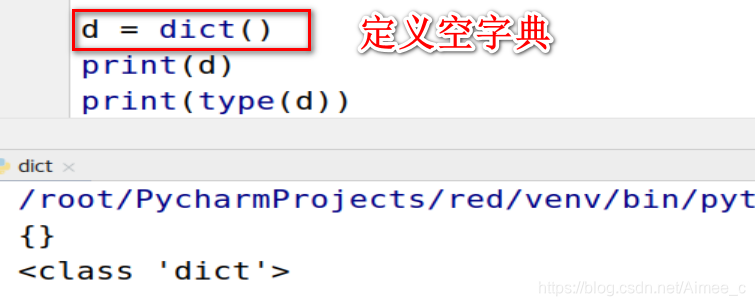
字典是键值对
key是唯一的,value可以对应任意变量值。
s = {
'user1':[100,99,88],
'user2':[190,543,345]
}
print(s)
print(type(s))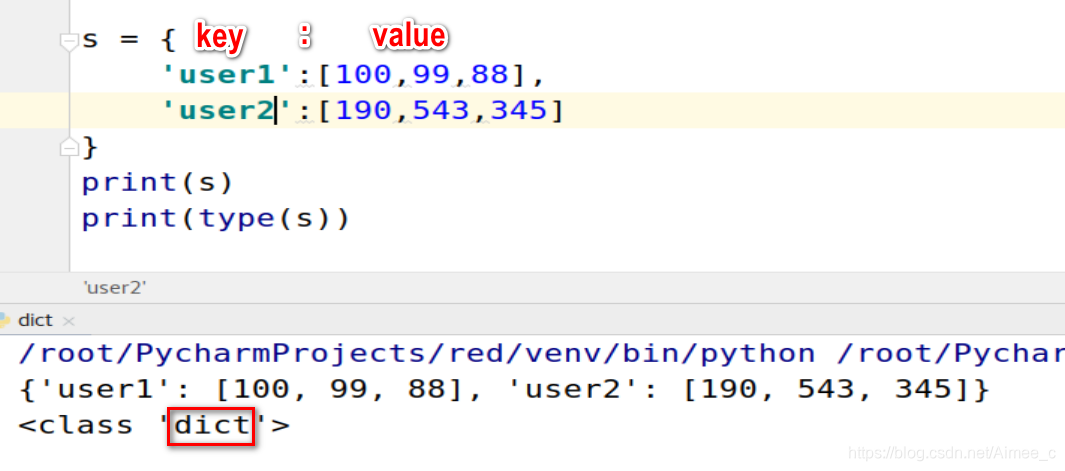
6.2 字典的嵌套
students = {
'coco':{
'id':'03113009',
'age':18,
'score':90
},
'lily':{
'id':'03113010',
'age':20,
'score':100
}
}
print(students['lily']['id'])##获取对应值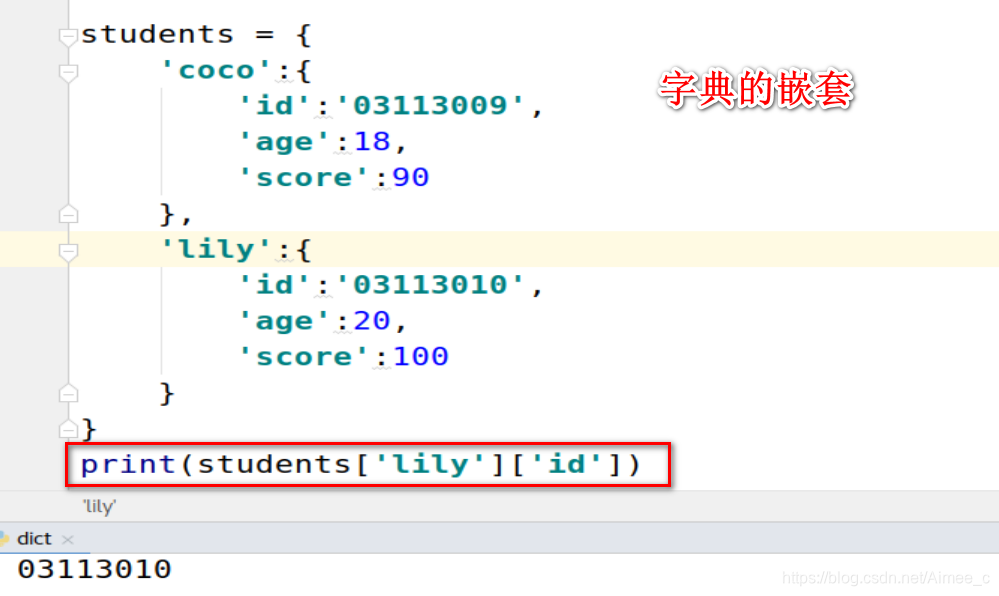
注意:通过key获取value值
6.3 字典的统一value值
print({
}.fromkeys({
'1','2'},'000000'))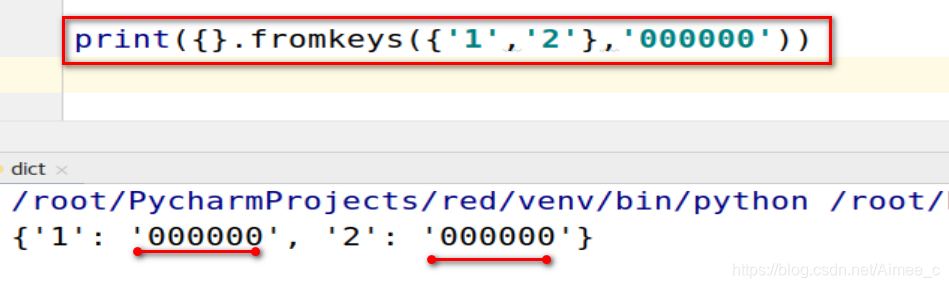
字典的特性
字典不支持索引、切片
6.4 字典的成员操作符(in / not in)
d = {
'1':'a',
'2':'b'
}
print('1' in d)
print('1' not in d)
**
6.4 字典的迭代
d = {
'1':'a',
'2':'b'
}
for key in d:
print(key)
d = {
'1':'a',
'2':'b'
}
for key in d:
print(key,d[key])
注意:在遍历字典时,默认遍历的是key值
6.5 字典的增加
字典的增加
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services)
services['mysql'] = 3306
print(services)
字典的更新
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services)
services['http'] = 443
print(services)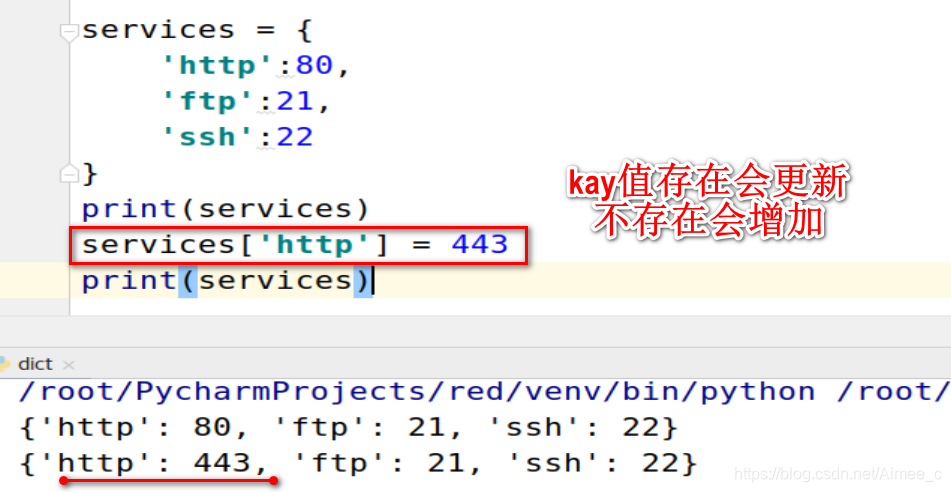
字典更新多个值(update)
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services)
services_backup = {
'https':443,
'tomcat':8080,
'http':8080
}
services.update(services_backup)
print(services)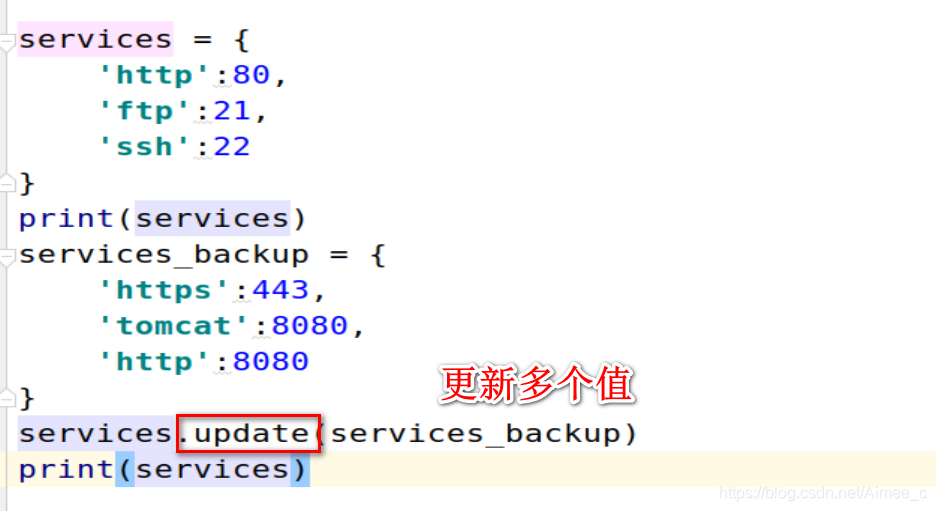

services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services)
services.update(flask=9000,http=8000)
print(services)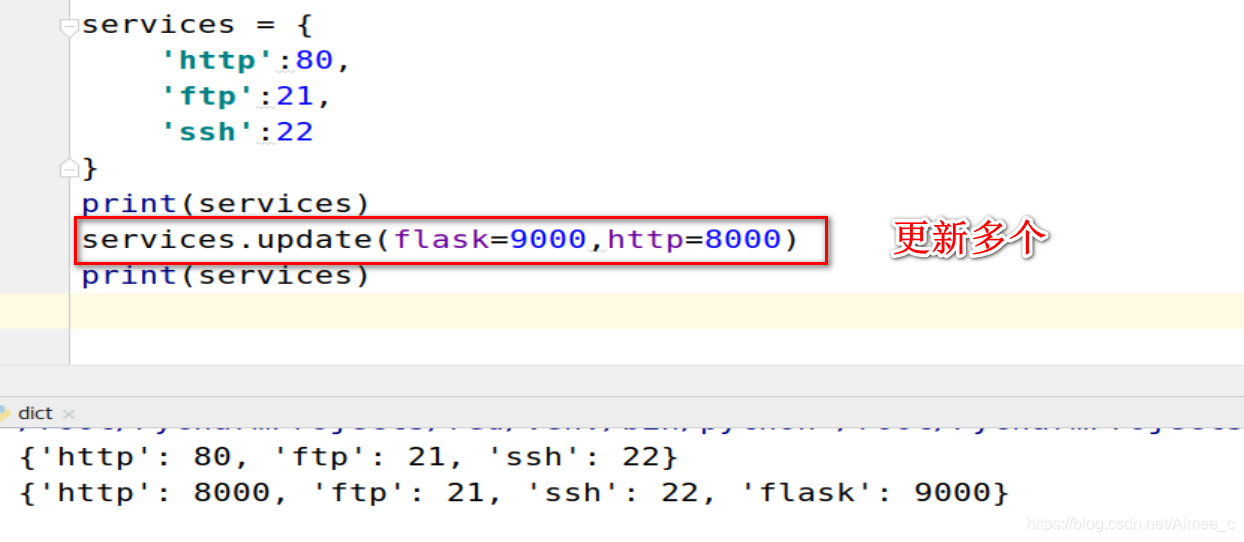
字典添加key值(setdefault)
key值存在不做修改,key值不存在添加
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services)
services.setdefault('http',9090)
print(services)
services.setdefault('oracle',44575)
print(services)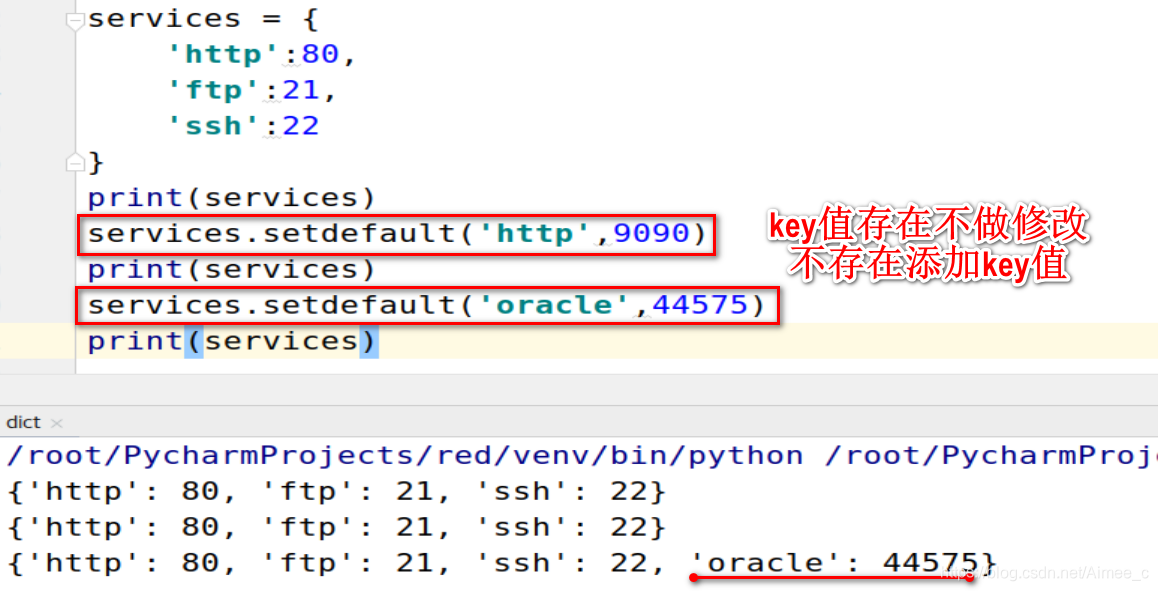
6.6 字典的删除
键值对的删除(del)
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services)
del services['http']
print(services)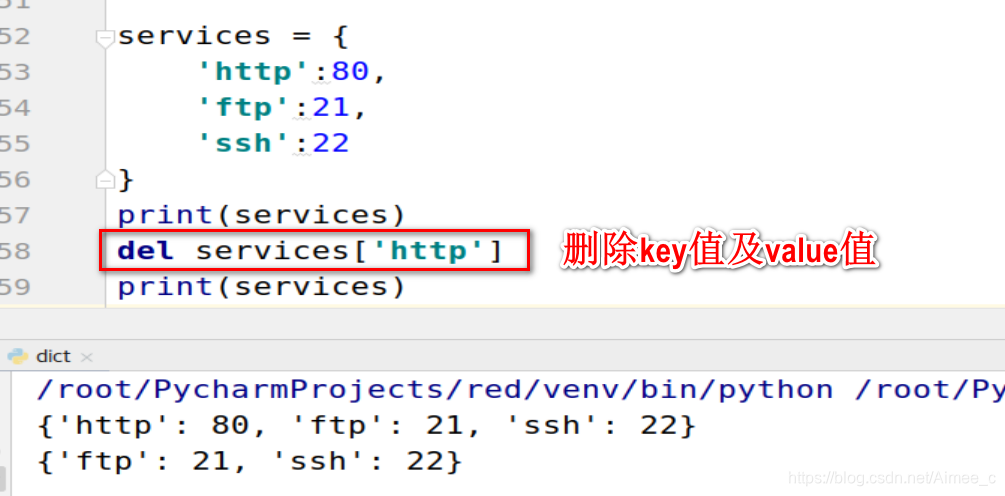
删除并返回对应值(pop)
注意:key值不存在会报错,key值存在会删除key值及对应值,并且返回删除key所对应的value值
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services)
item = services.pop('http')
print(item)
print(services)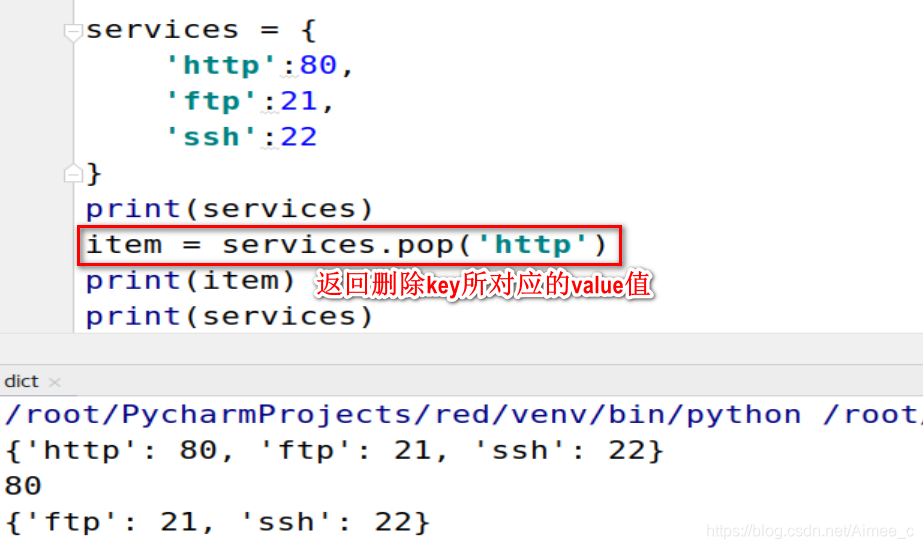

删除最后一个key/value值(popitem)
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services)
item = services.popitem()
print('The last key-value is:',item)
print(services)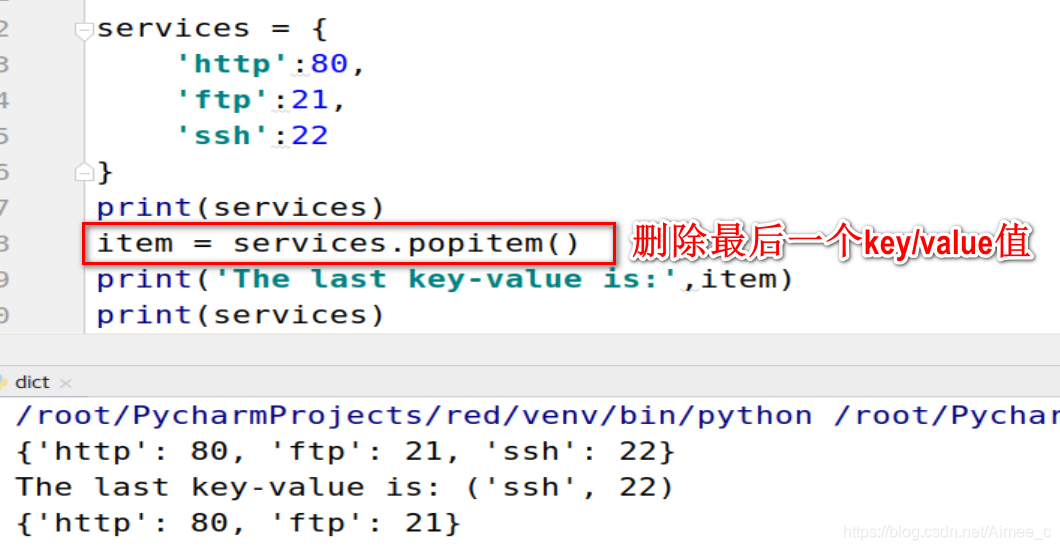
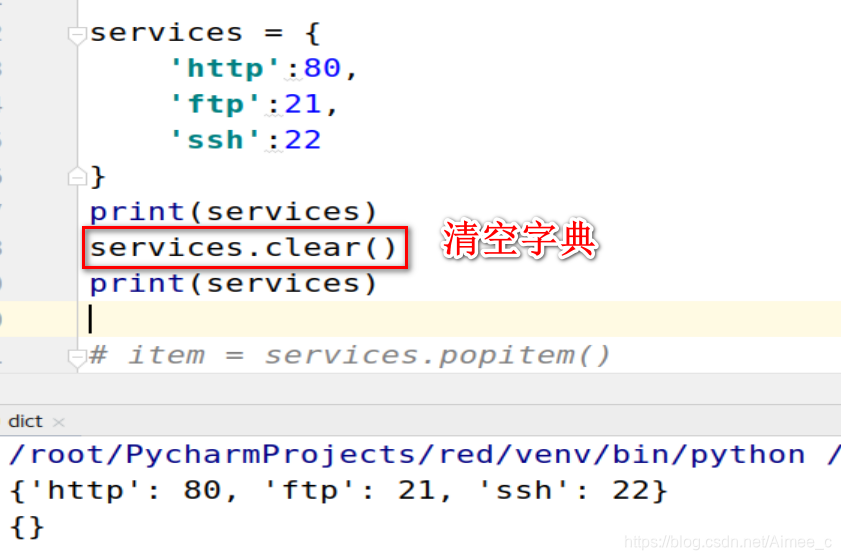
清空字典
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services)
services.clear()
print(services)
6.7 字典的查看
查看key值
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services.keys())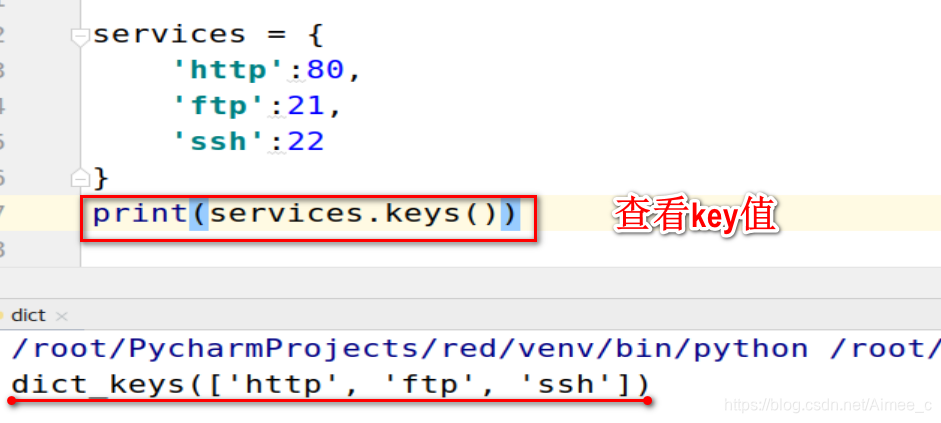
查看value值
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services.values())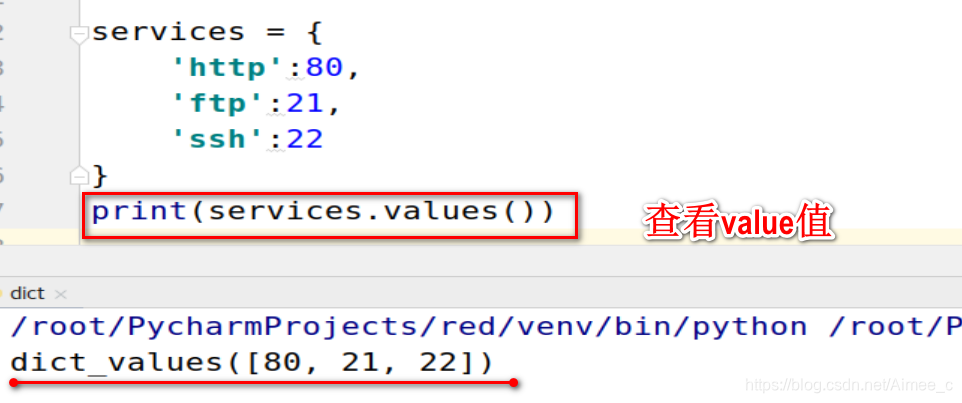
查看对应关系
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services.items())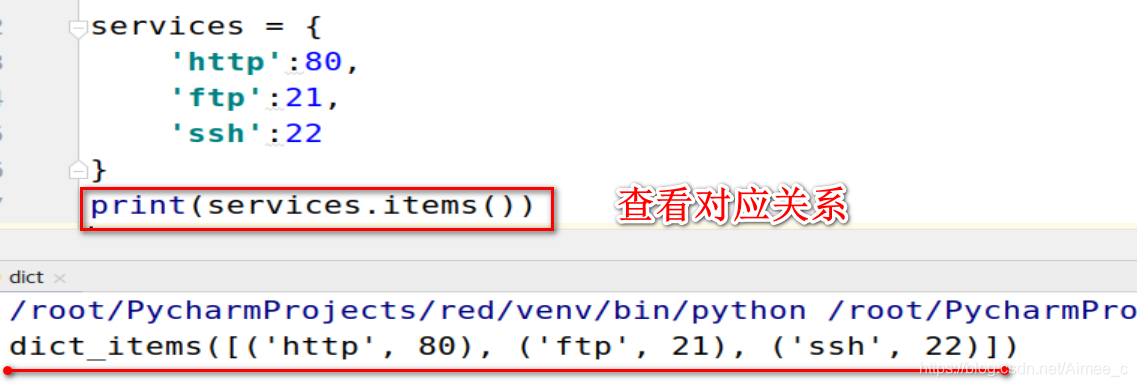
查看对应key的value值
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services['http'])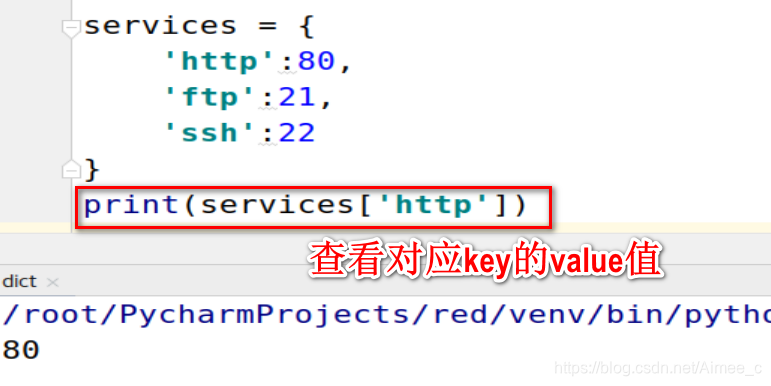

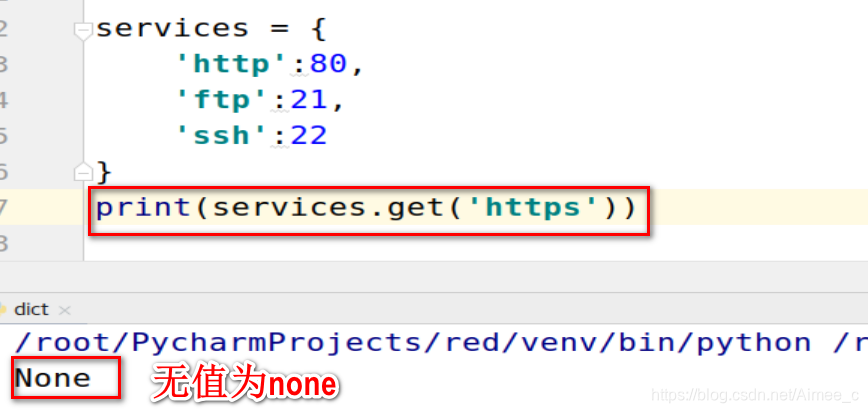
查看key的value值(get)
services = {
'http':80,
'ftp':21,
'ssh':22
}
print(services.get('https','key not exist'))
循环遍历字典的键值对(for(k))
services = {
'http':80,
'ftp':21,
'ssh':22
}
for k in services:
print('key:',k,'value:',services[k])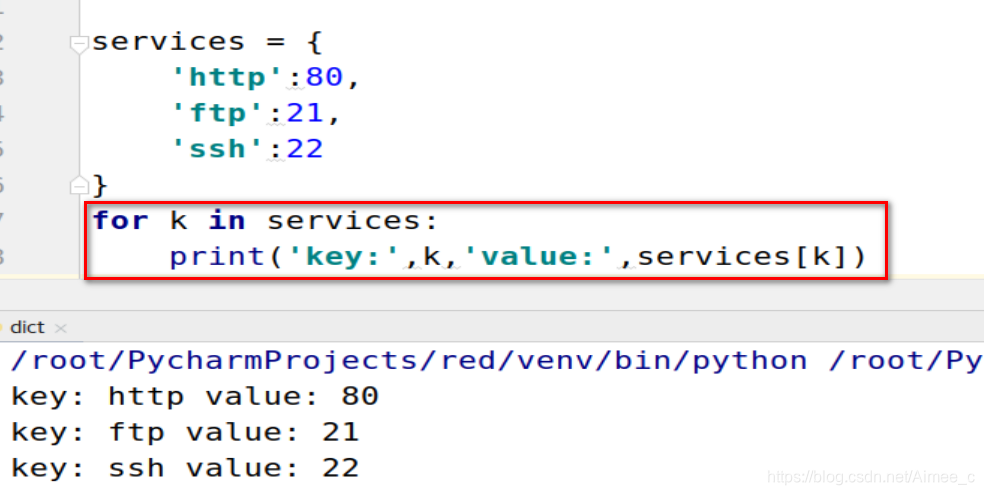
6.8 字典的练习
练习:数字重复统计
1). 随机生成1000个整数;
2). 数字的范围[20, 100],
3). 升序输出所有不同的数字及其每个数字重复的次数;
import random
all_nums = []
for item in range(1000):
all_nums.append(random.randint(20,100))
sorted_nums = sorted(all_nums)
num_dict = {
}
for num in sorted_nums:
if num in num_dict:
num_dict[num] += 1
else:
num_dict[num] = 1
print(num_dict)
练习:打印单词重复的次数
重复的单词: 此处认为单词之间以空格为分隔符, 并且不包含,和.;
# 1. 用户输入一句英文句子;
# 2. 打印出每个单词及其重复的次数;
“hello java hello python”
依次循环遍历列表:
如果列表元素不在字典的key中,将元素作为key 1作为value值
如果列表元素在字典的key中,直接更新元素value值,在原有的基础上加1
hello 2
java 1
python 1
方法一
item = input('请输入一句英文:')
listitem = item.split(' ')
words = {
} ###定义空字典 iu
for i in listitem:
if i == ',' or i == '.':
continue
count = listitem.count(i)
words[i] = count
print(words)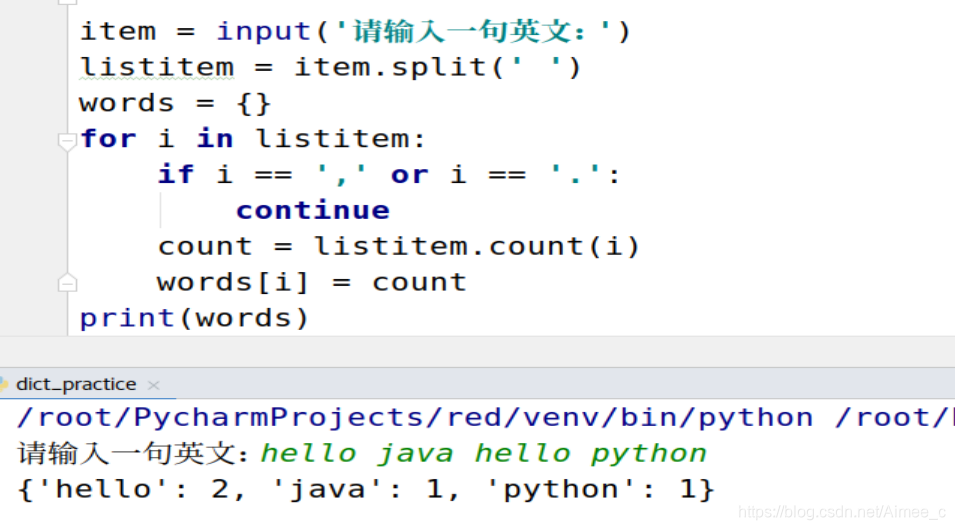
方法二:
s = input('请输入一句英文:')
listitem = s.split(' ')
words = {
}
for item in listitem:
if item not in words:
words[item] = 1 ##如果第一次出现为1
else:
words[item] += 1 ##第二次出现+1
print(words)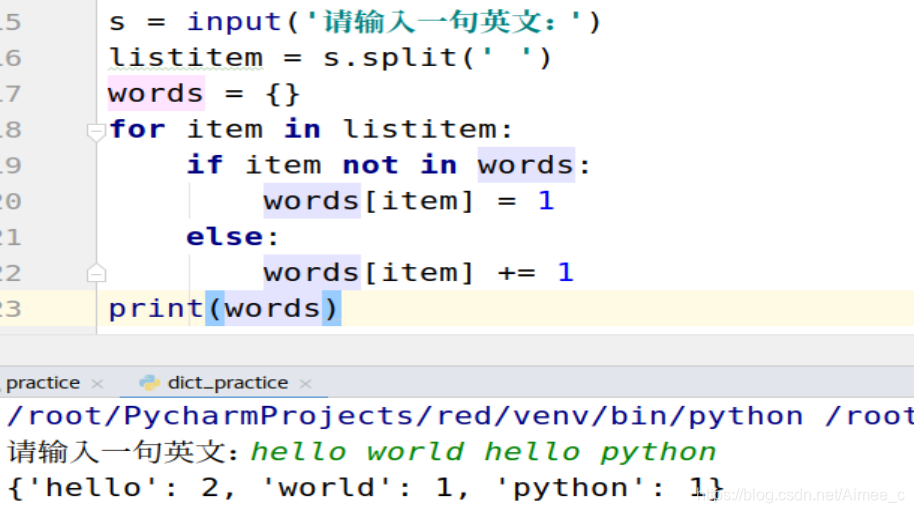
练习:生成银行卡号及密码
1.随机生成100个卡号:卡号以6102009开头, 后面3位依次是 (001, 002, 003, 100),
2. 生成关于银行卡号的字典, 默认每个卡号的初始密码为"redhat";
3. 输出卡号和密码信息, 格式如下:
| 卡号 | 密码 |
|---|---|
| 6102009001 | 000000 |
import random
bank_account = [] ##定义空列表
for i in range(100): ##生成卡号(列表)
bank_account.append('6102009%.3d' %(i+1))
account_info = {
}.fromkeys(bank_account,'redhat')##生成密码(字典)
print('卡号\t\t\t\t密码')##输出
for k,v in account_info.items():
print(k,'\t\t',v)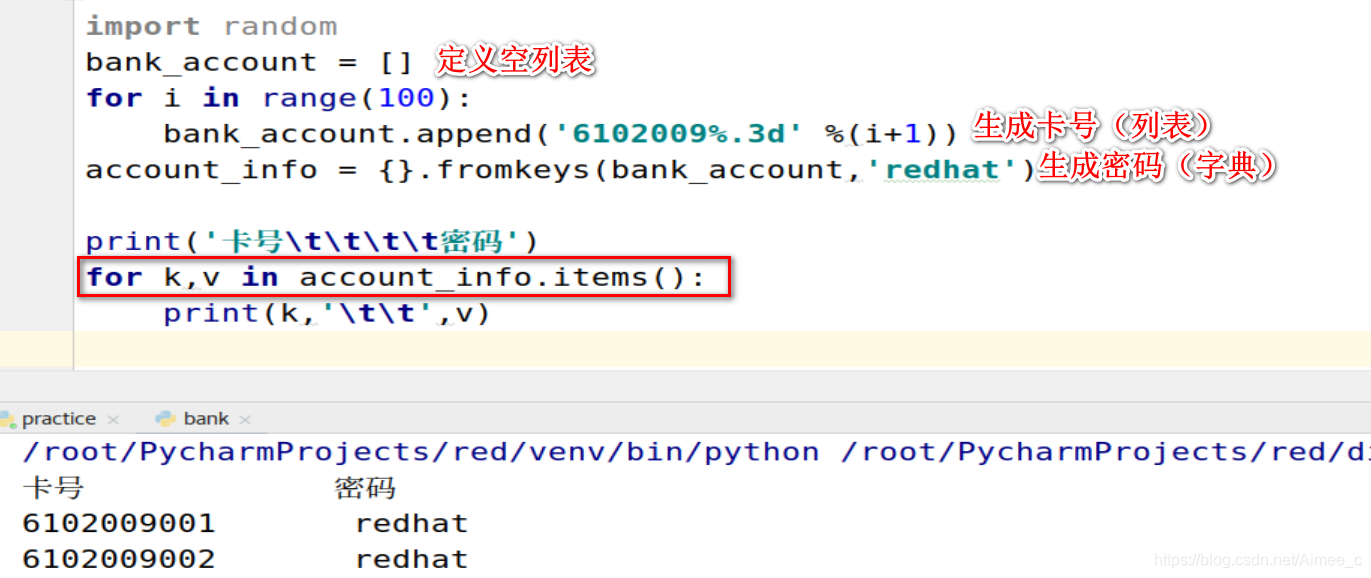
智能推荐
lufylegend.js的简单使用-程序员宅基地
文章浏览阅读826次。js 引入<script type="text/javascript" src="js/lufylegend/lufylegend-1.10.1.min.js"></script>html<div id="legend"></div><img src="" alt="" class="photo_img">..._lufylegend.js
MongoDB入门级保姆教程_mongodb保姆间教程-程序员宅基地
文章浏览阅读687次,点赞3次,收藏4次。MongoDB是文档数据库,旨在简化开发和扩展,本文主要介绍关键概念和基础语句并提供操作和管理上的注意事项。_mongodb保姆间教程
输入若干个正整数,判断每个数从高位到低位各位数字是否按值从小到大排列_输入一批正整数(以零或负数为结束标志),判断每个数从高位到低位的各位数字是否按-程序员宅基地
文章浏览阅读1.1w次,点赞7次,收藏16次。4-2输入若干个正整数,判断每个数从高位到低位各位数字是否按值从小到大排列,请根据题意,将程序补充完整。#include <stdio.h>int fun1(int m);int main(void){ int n; scanf("%d", &n); while (n > 0) { if(fun1(..._输入一批正整数(以零或负数为结束标志),判断每个数从高位到低位的各位数字是否按
IDEA用户登入简易版_idea中的个人博客网址的登录网址是那个去那里找-程序员宅基地
文章浏览阅读281次。<!DOCTYPE html><html lang="en"><head> <style> form{ border: 10px solid cornflowerblue;border-radius: 10px } </style> <meta charset="UTF-8"> <title>用户注册</title>..._idea中的个人博客网址的登录网址是那个去那里找
使用 Python 数据写入 Excel 工作表_python把数据写表格-程序员宅基地
文章浏览阅读2.4k次,点赞40次,收藏39次。本文所使用的 API 中,使用 Workbook 类来代表一个 Excel 工作簿。在操作 Excel 工作簿时,可以使用该类下的 LoadFromFile() 方法从文件读取 Excel 工作簿进行操作或直接通过创建 Workbook 的对象从而创建工作簿进行操作。需要注意的是,新建的 Excel 工作簿默认有三个工作表。同时,该 API 还提供 Worksheet 类和一系列方法、属性来对工作表及其中的单元格数据、格式等内容进行操作。_python把数据写表格
关于No converter found for return value of type: class java.util.ArrayList出现的几个问题-程序员宅基地
文章浏览阅读6.4k次,点赞5次,收藏4次。当我使用spring,springmvc,mybatis整合开发项目的时候,在controller层的方法使用@responsebody想要返回一个list集合对象的转换为json格式在页面输出。出现了异常:No converter found for return value of type: class java.util.ArrayList,是说明没有可以转换对象成json的转换..._no converter found for return value of type: c
随便推点
浙大 | PTA 习题7-7 字符串替换 (15分)_例题3-7 统计英文字母和数字字符[2] 分数 15 作者 颜晖 单位 浙大城市学院 本题要-程序员宅基地
文章浏览阅读2.3k次。本题要求编写程序,将给定字符串中的大写英文字母按以下对应规则替换:原字母 对应字母 A Z B Y C X D W … … X C Y B Z A输入格式:输入在一行中给出一个不超过80个字符、并以回车结束的字符串。输出格式:输出在一行中给出替换完成后的字符串。输入样例:Only the 11 CAPItaL LeTtERS are replaced.输出样例:..._例题3-7 统计英文字母和数字字符[2] 分数 15 作者 颜晖 单位 浙大城市学院 本题要
Bioinformatics | 预测药物-药物相互作用的多模态深度学习框架_ddimdl-程序员宅基地
文章浏览阅读4.1k次,点赞4次,收藏38次。作者 | 朱玉磊审稿 | 李芬今天给大家介绍来自华中农业大学信息学院章文教授课题组在Bioinformatics上发表的一篇关于预测药物与药物相互作用事件的文章。作者提出了一个多模态深度..._ddimdl
制作一个有趣的QQ机器人_qrspeed官网-程序员宅基地
文章浏览阅读7.7k次,点赞19次,收藏72次。如何制作一个有趣的QQ机器人制作一个好玩的QQ机器人(只能手机进行操作哦)题记:这个机器人用来整蛊兄弟或者是在朋友面前装逼都是不错的选择QQ机器人简介机器人效果图机器人制作方法机器人必下软件如何制作机器人词库的编写编写词库的软件词库的编写规则给大家找了一个QR下载的官网(不想加群的兄弟姐妹看这个)结尾题记:这个机器人用来整蛊兄弟或者是在朋友面前装逼都是不错的选择)QQ机器人简介QQ机器人,根据字面意思,就是利用特定的代码,使一个QQ账号成功具备自我反应并作出应答,而这也是我今天想要教你们做的一款最_qrspeed官网
「离散数学」是一门什么样的学科_离散数学学什么-程序员宅基地
文章浏览阅读2.4k次,点赞6次,收藏13次。写这篇文章的动机是想探讨从离散数学开始入门数理逻辑的路径以及离散数学与数理逻辑之间的关系。以学习数理逻辑为目的学习离散数学,而一般的以学习计算机为目的的学习还是有相当的不同,最大的不同就是:以数理逻辑为目的的学习,应当以「证明」 — — 形式证明为目的,这其中包括了关于形式证明的理论 — — 一阶理论的句法和语义,以及关于形式证明的实践 — — 证明框架和策略。学习的中心内容有两个:「语言」 — — 「 一阶语言」;「结构」 — — 数学中关于「结构」的思想、概念、种类、实例以及「结构」和「语言」的关系。_离散数学学什么
使用 vue-cli 遇到的坑1 - 打包后显示空白_vue cli 组件导出为null-程序员宅基地
文章浏览阅读248次。输入 npm run build 打包后显示空白解决方法1. 打开 config 文件夹里的 index.js 文件。找到 build 下面的 assetsPublicPath,将原来的assetsPublicPath: '/'修改为assetsPublicPath: './'2.打开 build 文件夹里的 utils.js,在下图位置添加 publicPath: '../../'..._vue cli 组件导出为null
嵌入式Linux(二十二)Linux内核分析及移植_嵌入式内核移植qspi-程序员宅基地
嵌入式Linux内核分析及移植的文章介绍了编译Linux内核的过程,并提供了一个编译脚本。作者使用NXP提供的内核进行移植,并在自己的开发板上进行测试。在启动Linux后,可以使用ifconfig命令查看网络接口,并使用ifconfig eth0 up命令启动ENET2接口。