python爬虫技术实例详解及数据可视化库_爬虫入门 可视化图分析总结-程序员宅基地
技术标签: python 可视化 数据分析 python爬虫 大数据 初学笔记
前言
在当前数据爆发的时代,数据分析行业势头强劲,越来越多的人涉足数据分析领域。面对大量数据,人工获取信息的成本高、耗时长、效率低,那么是否能用代码去完成大量复杂的工作,从而从网络上获取到目标信息?由此,网络爬虫技术应运而生。
本文目录,你将会看到
- 网络爬虫简介
- 实例分析
- 示例背景
- 问题总括
- 示例全代码
- 数据处理与可视化之Altair
- 后言-python爬虫相关库
网络爬虫简介
网络爬虫(webcrawler,又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种用来自动浏览万维网的程序或者脚本。爬虫可以验证超链接和HTML代码,用于网络抓取(Webscraping)。传统爬虫从一个或若干初始网页URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。爬虫访问网站的过程会消耗目标系统资源,因此在访问大量页面时,爬虫需要考虑到规划、负载等问题。
实例分析
示例背景
- 利物浦足球俱乐部(Liverpool F.C.),简称利物浦,球队位于英格兰西北默西赛德郡港口城市利物浦,于1892年成立,是英格兰足球超级联赛的球队之一。2018/19赛季,利物浦2比0战胜热刺,历史上第六次捧起欧洲冠军联赛冠军奖杯。
- 目标网站:T足球(http://tzuqiu.cc/)
问题总括
- 为研究利物浦球队在欧冠中的整体表现,现需从T足球网站中获取利物浦在18/19赛季欧冠中的所有比赛的比赛报告,其中包括:数据类型分析、总计、球队进攻分布、球队数据以及TOP球员数据,并将其结果存储为本地文件,以便后续数据分析工作。
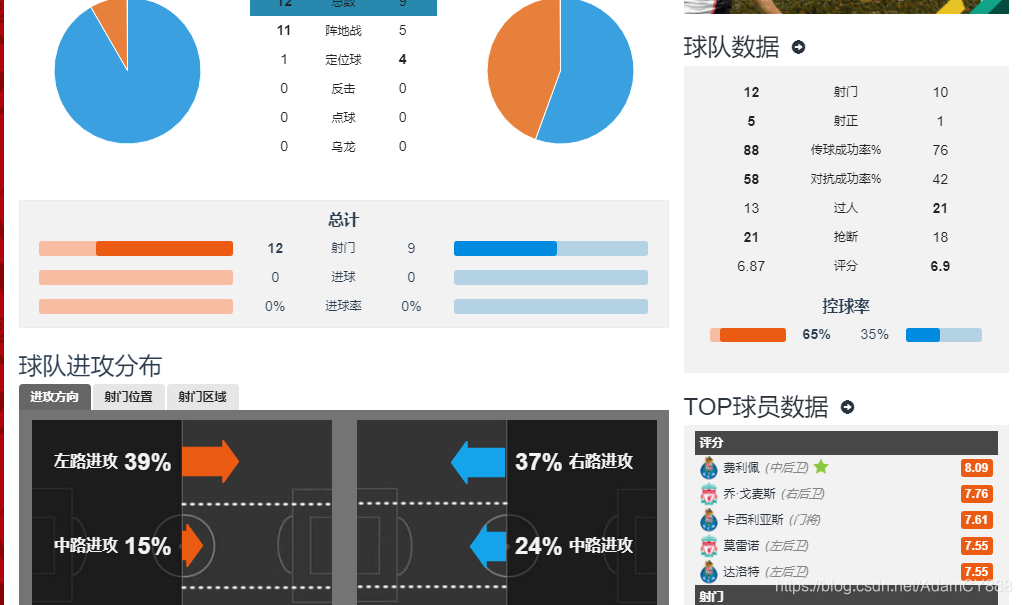
- 操作思路:首先查看该网站的robohttp://tzuqiu.cc/matches/56141/report.dots协议(Robots Exclusion Protocol),获取目标网址、请求访问、获取源码文本、选择目标信息、存储文件。
- 问题分析:该网站上没有18/19赛季比赛的专栏,提前通过度娘,检索到共有13场比赛(6场积分赛、7场淘汰赛)比赛时间,获取网址需要自行选择比赛时间后才能查看到当场比赛网址。其中C组积分赛事情况见下表。
| 时间 | 赛况 | 网址 |
|---|---|---|
| 2018年9月18日 | 利物浦 3:2 巴黎圣日耳曼 | http://tzuqiu.cc/matches/56141/report.do |
| 2018年10月3日 | 那不勒斯 1:0 利物浦 | http://tzuqiu.cc/matches/56138/report.do |
| 2018年10月24日 | 利物浦 4:0 贝尔格莱德红星 | http://tzuqiu.cc/matches/56139/report.do |
| 2018年11月6日 | 贝尔格莱德红星 2:0 利物浦 | http://tzuqiu.cc/matches/56147/report.do |
| 2018年11月28日 | 巴黎圣日耳曼 2:1 利物浦 | http://tzuqiu.cc/matches/56144/report.do |
| 2018年12月11日 | 利物浦 1:0 那不勒斯 | http://tzuqiu.cc/matches/56146/report.do |
- 在目标网址中仅有“数字码”不一致,猜测剩下7场比赛网址(url)结构一致。同理,获取到剩下7场淘汰赛的“数字码”,将13个“数字码“放在一个列表中,并构造链接”
urls = [56141,56138,56139,56147,56144,56146,56933,56931,57970,57967,58344,58341,58471]
for url_0 in urls:
url = "http://tzuqiu.cc/matches/" + str(url_0) + "/report.do"
print(url)
- 接下来需要先请求访问网站,获取源码文本数据,首先利用requests库进行请求,再获取文本。python的第三方库requests库安装方法:本地搜索:cmd (命令提示符),键入代码后等待下载安装(Tip:对于python中大多数第三方库都可以通过程序命令符pip程序进行下载、安装、删除等)。
pip install requests
- 由于爬虫代码是在短时间内多次访问目标网站,会对目标网站造成资源浪费,网站可能会建立有反爬虫机制,在请求访问网站时,目标网站会对申请访问对象进行身份识别。因此,需要先将爬虫代码伪装为一个浏览器,构造“请求头”,即:
heads = {
'Connection': 'keep-alive',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Accept': 'text/html,application/xhtml+xml,application/xml;\
q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',}
- 申请访问后,若目标网站回应“Response [200]”则表示成功,若为Response [404]或者其他则可以粗略理解为失败。
import requests
url = "http://tzuqiu.cc/matches/56141/report.do"
response = requests.get(url, headers = heads)
print(response)
#返回结果:Response [200]
- 成功访问后,获取源码,以便分析,可以打印浏览,也可以忽略打印,在网页中直接分析
content = response.text
- 打开目标网站-鼠标右键-检查/查看网页源代码,观察目标信息位置以及规律特征
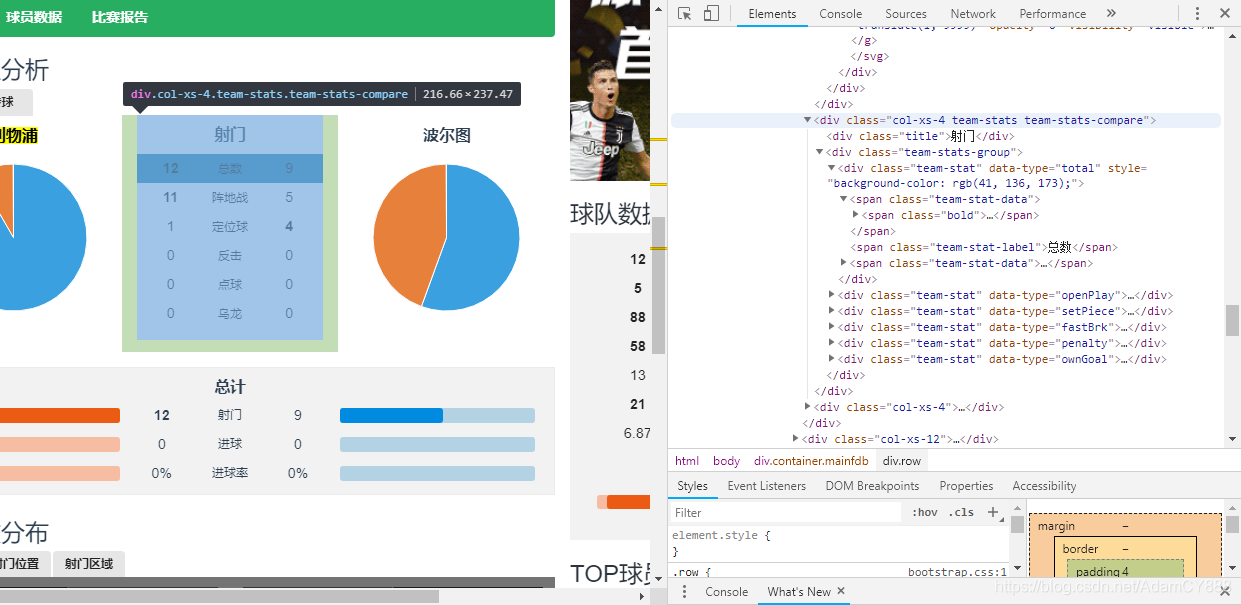
- 发现“数据类型分析”的“射门”与“传球”信息都存储在一个“div”标签 属性满足唯一字典,标签下的文本无其他干扰信息,同理可发现另外三个板块的字典信息。
| 类型 | div标签下特征字典 |
|---|---|
| 数据类型分析 | {“class”:“tabbable smallTab”} |
| 总计 | {“class”:“team-stats team-stats-table”} |
| 球队进攻分布 | {“class”:“col-xs-4 team-stats team-stats-compare”} |
| 球队数据、TOP球员数据 | {“class”:“col-xs-4 side-bar”} |
- 可利用BeautifulSoup库中find_all()函数查找目标信息,由于观察到该网页一个的特殊字典唯一,所以也可以用find()方法,查找到目标信息后,提取div标签下的所有文本信息。(BeautifulSoup库的安装-在cmd环境下键入:pip install bs4)
string = ["tabbable smallTab","team-stats team-stats-table",
"col-xs-4 team-stats team-stats-compare","col-xs-4 side-bar"]
s_sum = []
for reast in string:
tagss = soup.find_all('div',attrs = {
"class":reast})
for tags in tagss:
print(tags.text)
- 对数据进行格式清洗,去掉所有的空格、转行,并以逗号分隔添加到列表
for tags in tagss:
s_old = re.sub(r"\s+",",",tags.text)
s_new = s_old.strip(",''")
s_sum.append(s_new)
s_sum_new = str(s_sum).replace("'","")
- 到此已经爬取完网页上的所有目标信息,接下来将数据存储为txt文本
f = open(r"存储路径\py_txt文本_sum.txt",'w')
f.writelines([s_sum_new,'\n'])
f.close()
- txt文本以逗号为制表符转换成excel文件。也可以直接将爬取的数据以excel文件存储【Python实现的HTML/XML处理库,仅需少量代码,效率相对较低】但不清楚爬取的数据内部结构,可能会导致excel表格式杂乱无章,故用txt文本更为简便。
import xlwt
import os
import sys
def txt_xls(filename,xlsname):
try:
f = open(filename)
xls = xlwt.Workbook()
sheet = xls.add_sheet('sheet',cell_overwrite_ok=True)
x = 0
while True:
line = f.readline()
if not line:
break
for i in range(len(line.split(','))):
item = line.split(',')[i]
sheet.write(x,i,item)
x += 1
f.close()
xls.save(xlsname)
except:
raise
if __name__ == '__main__':
filename = 'txt文本存储本地路径.txt'
xlsname = 'excel存储地址.xlsx'
txt_xls(filename,xlsname)
- excel表格转换成csv文件,虽然csv打开方式与xlsx一样,但文件属性各异。
import xlwt
import pandas as pd
file = '文件路径/py_excel表格_sum.xlsx'
outfile = '文件路径/py_csv文件_sum.csv'
def xlsx_to_csv_pd():
data_xls = pd.read_excel(file, index_col=0)
data_xls.to_csv(outfile, encoding='utf-8')
if __name__ == '__main__':
xlsx_to_csv_pd()
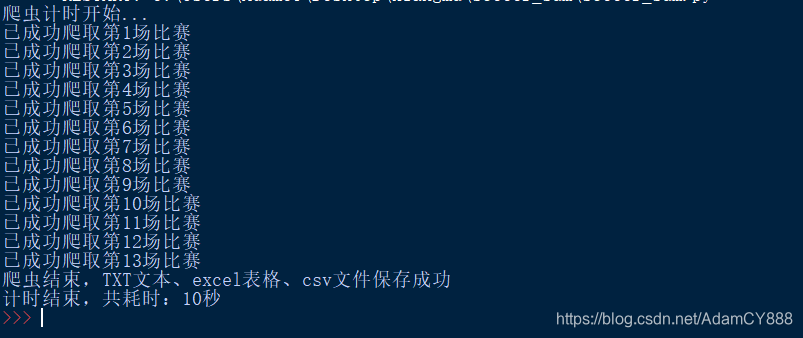
- 优化爬虫:在爬取过程中,经常会遇到“无限循环”“爬取结果为空”等情况,并不知道爬虫进展如何,则可以通过简单的语言实现爬虫进度。例如:
for i in range(len(urls)):
print("正在爬取第%d个网站"%i)
- 利用time库的时间戳,记录程序运行耗时
import time
star_time = time.time()
##爬虫代码
end_time = time.time()
spend_time = end_time - star_time
print(spend_time)
- 则整个爬虫过程进度可视化
示例全代码
import requests
import re
from bs4 import BeautifulSoup
import time
import xlwt
import os
import sys
import pandas as pd
print("爬虫计时开始...")
star_time = time.time()
heads = {
'Connection': 'keep-alive',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Accept': 'text/html,application/xhtml+xml,application/xml;\
q=0.9,image/webp,image/apng,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36\
(KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36',}
urls = [56141,56138,56139,56147,56144,56146,56933,56931,57970,57967,58344,58341,58471]
f = open(r"D:\Users\py_txt文本_sum.txt",'w')
m = 1
for url_0 in urls:
print("已成功爬取第%d场比赛"%m)
m += 1
url = "http://tzuqiu.cc/matches/" + str(url_0) + "/report.do"
response = requests.get(url, headers = heads)
content = response.text
soup = BeautifulSoup(content,"lxml")
string = ["tabbable smallTab","team-stats team-stats-table",
"col-xs-4 team-stats team-stats-compare","col-xs-4 side-bar"]
for reast in string:
s_sum = []
tagss = soup.find_all('div',attrs = {
"class":reast})
for tags in tagss:
s_old = re.sub(r"\s+",",",tags.text)
s_new = s_old.strip(",''")
s_sum.append(s_new)
s_sum_new = str(s_sum).replace("'","")
f.writelines([s_sum_new,'\n'])
f.close()
def txt_xls(filename,xlsname):
try:
f = open(filename)
xls = xlwt.Workbook()
sheet = xls.add_sheet('sheet',cell_overwrite_ok=True)
x = 0
while True:
line = f.readline()
if not line:
break
for i in range(len(line.split(','))):
item = line.split(',')[i]
sheet.write(x,i,item)
x += 1
f.close()
xls.save(xlsname)
except:
raise
if __name__ == '__main__':
filename = 'D:/Users/soccer_sum/py_txt文本_sum.txt'
xlsname = 'D:/Users/py_excel表格_sum.xlsx'
txt_xls(filename,xlsname)
file = 'D:/Users/py_excel表格_sum.xlsx'
outfile = 'D:/Users/py_csv文件_sum.csv'
def xlsx_to_csv_pd():
data_xls = pd.read_excel(file, index_col=0)
data_xls.to_csv(outfile, encoding='utf-8')
if __name__ == '__main__':
xlsx_to_csv_pd()
end_time = time.time()
time = end_time - star_time
print("爬虫结束,TXT文本、excel表格、csv文件保存成功")
print("计时结束,共耗时:%d秒"%time)
- 最终爬取结果
数据处理与可视化之Altair
Altair是一个专为Python编写的可视化软件包,它能让数据科学家更多地关注数据本身和其内在的联系。
- 绘制图表
chart = alt.Chart(cars)
- Chart有三个基本方法:数据(data)、标记(mark)和编码(encode)
alt.Chart(data).mark_point().encode(
encoding_1='column_1',
encoding_2='column_2',
# etc.
)
- 进一步了解编码具体内容
| 变量 | 名称 |
|---|---|
| x | x轴数值 |
| y | y轴数值 |
| color | 标记点颜色 |
| size | 标记点的大小 |
| opacity | 标记点的透明度 |
| row | 按行分列图片 |
| column | 按列分列图片 |
绘制二维图
alt.Chart(cars).mark_line().encode(
x='Miles_per_Gallon',
y='Horsepower'
)
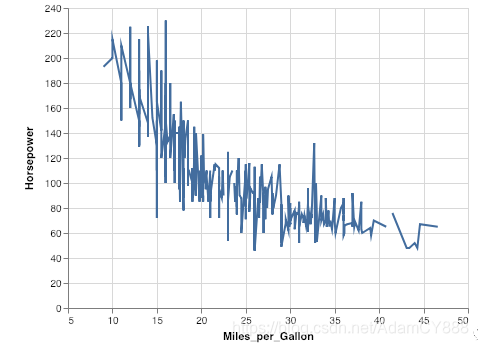
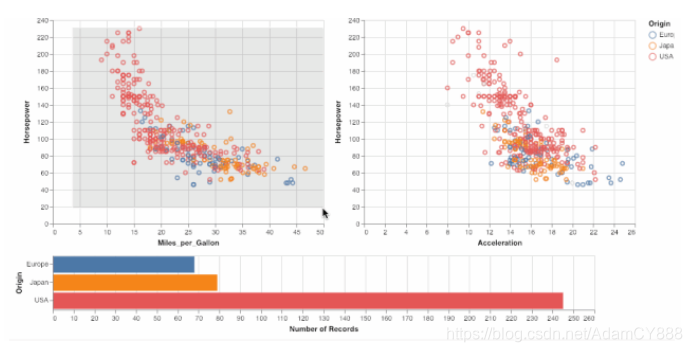
- 交互图形,在选择功能上,我们能做出一些更酷炫的高级功能,例如对选中的数据点进行统计,生成实时的直方图。
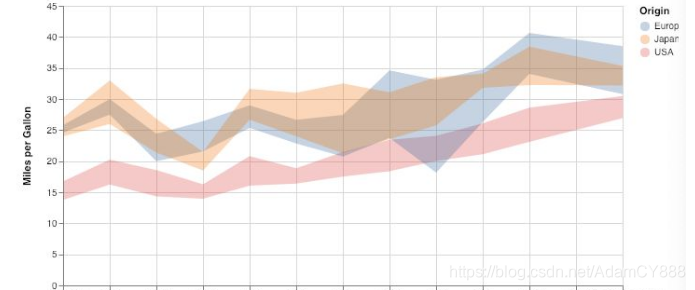
- 在统计学上,我们还能定义平均值的置信区间,为了让图表更好看,可以分别列出三个不同的平均值置信区间
alt.Chart(cars).mark_area(opacity=0.3).encode(
x=alt.X(‘Year’, timeUnit=’year’),
y=alt.Y(‘ci0(Miles_per_Gallon)’, axis=alt.Axis(title=’Miles per Gallon’)),
y2=’ci1(Miles_per_Gallon)’,
color=’Origin’
).properties(
width=600
)
后言-python爬虫相关库
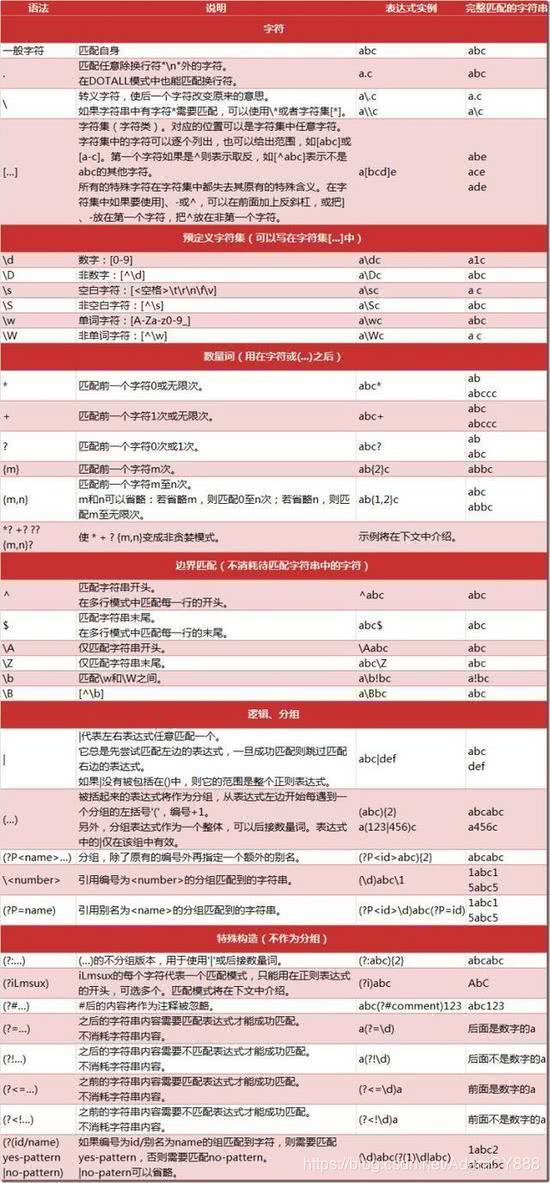
- python网络爬虫技术相关库
| 库名 | 简介 |
|---|---|
| urllib | Python内置的httpP请求库,提供一系列用于操作url的功能 |
| Requests | 基于urllib,采用Apache2 Licensed开源协议的HTTP库 |
| urllib | 提供多种python所没有的重要特性:线程安全,连接池,客户端SSL/TLS验证等 |
| scrapy | 一个为了爬取网站数据,提取结构性数据而编写的应用框架 |
| lxml | C语言编写高效HTML/XML处理库,支持XPath |
| BeautifulSoup | 纯Python实现的HTML/XML处理库,仅需少量代码,效率相对较低 |
END:创作不易,点个关注呗~
智能推荐
判断二叉树是否AVL树_如何判断一个二叉树是否为avl树-程序员宅基地
文章浏览阅读2.1k次。一、算法思想: 递归法判断一个二叉树是否平衡二叉树(AVL树),可以根据它的定义写出代码:(1)空树是一个AVL树;(2)只有一个根结点的树是一个AVL树;(2)左子树是一颗AVL树,且右子树是一个AVL树,且左子树的高度与右子树的高度差绝对值不超过1。二、代码:/*name:author:followStepdescription:date:2018/3/1..._如何判断一个二叉树是否为avl树
Ant design Pro 跨域问题解决方案(SpringBoot版本)_if an opaque response serves your needs, set the r-程序员宅基地
文章浏览阅读1.6k次。错误描述:Access to fetch at ‘http://localhost:9000/api/login/account’ from origin ‘http://localhost:8000’ has been blocked by CORS policy: Response to preflight request doesn’t pass access control check: No ‘Access-Control-Allow-Origin’ header is present on_if an opaque response serves your needs, set the request's mode to 'no-cors
压缩字符串 实现思路及练习题-程序员宅基地
文章浏览阅读413次,点赞15次,收藏4次。实现思路:遍历当前字符串,从第一个元素开始,遍历至倒数第二个元素,分别获取当前字符以及下一个字符然后对当前字符与下一个字符进行判断,如果相邻字符相等,表示连续相同,对其进行累加计数。否则相邻字符不相等,表示连续中断,将之前计数完成的字符+字符个数加到字符串末尾,并重新设置要比较的字符,且重新计数。题目:压缩字符串"AAAABBBCCDDDDEEEEEEFFF"使得其输出结果为A4B3C2D4E6F3。输入:AAAABBBCCDDDDEEEEEEFFF。输出:A4B3C2D4E6F3。
python字符串切片用法_Python字符串切片操作知识详解-程序员宅基地
文章浏览阅读541次。一:取字符串中第几个字符print "Hello"[0] 表示输出字符串中第一个字符print "Hello"[-1] 表示输出字符串中最后一个字符二:字符串分割print "Hello"[1:3]#第一个参数表示原来字符串中的下表#第二个阐述表示分割后剩下的字符串的第一个字符 在 原来字符串中的下标这句话说得有点啰嗦,直接看输出结果:el三:几种特殊情况(1)print "Hello"[:3] ...
120、仿真-51单片机温湿度光照强度C02 LCD1602 报警设计(Proteus仿真+程序+元器件清单等)-程序员宅基地
文章浏览阅读464次。(1)有优异的性能价格比。(2)集成度高、体积小、有很高的可靠性。单片机把各功能部件集成在一块芯片上,内部采用总线结构,减少了各芯片之间的连线,大大提高了单片机的可靠性和抗干扰能力。另外,其体积小,对于强磁场环境易于采取屏蔽措施,适合在恶劣环境下工作。(3)控制功能强。为了满足工业控制的要求,一般单片机的指令系统中均有极丰富的转移指令、I/O口的逻辑操作以及位处理功能。单片机的逻辑控制功能及运行速度均高于同一档次的微机。(4)低功耗、低电压,便于生产便携式产品。
国内几款常用热门音频功放芯片-低功耗、高保真_常用hifi芯片-程序员宅基地
文章浏览阅读2.8k次。工作电源电压范围:5V~28V;2、NTP8918;支持2 CH Stereo (15W x 2 BTL)该芯片RS DRC动态功率控制,有效防止破音,其内部设计有非常完善的过耗保护电路,它的音色非常甜美,音质醇厚,颇有电子管的韵味,适合播放比较柔和的音乐,2*16段可调PEQ,加入APEQ功能,真切改善音质,常应用于AI智能音箱上。目前,在手机终端上,音乐手机一般采用CODEC +PA的方式,CODEC要求极高的信噪比、丰富的编解码功能和接口,此外,为了支持16Ω的耳机,也需要较好品质的耳机功率放大器。_常用hifi芯片
随便推点
Anaconda安装_anaconda环境变量e:\anaconda3\library\usr\bin-程序员宅基地
文章浏览阅读7.1k次,点赞41次,收藏196次。文章目录1.Anaconda是什么2.Anaconda下载3.Anaconda安装4.Anaconda环境变量配置5.检验是否安装成功6.检验Anaconda Navifator是否安装成功7.修改Anaconda镜像修改为清华大学镜像移除清华大学镜像8.PyCharm配置Anaconda方式一(建立新的项目时)方式二(已经打开项目)9.总结1.Anaconda是什么Anaconda指的是一个开源的Python发行版本,其包含了conda、Python等180多个科学包及其依赖项。Anaconda也是P_anaconda环境变量e:\anaconda3\library\usr\bin
70个常用电脑快捷键,帮你工作效率提升100倍!职场新人必备!_快捷键可以帮助自己-程序员宅基地
文章浏览阅读2k次,点赞11次,收藏44次。电脑快捷键不仅可以帮助我们熟练的操作电脑,还可以帮助我们快速提升自己的工作效率,从此跟加班说拜拜!但由于电脑快捷键过于繁多不方便我们记忆!那么今天小编为大家整理的70个Wordows、Ctrl、Alt、Shift组合快捷键,运用好的话能够帮你工作效率提升100倍!希望能为大家派上用途!下面以图片&文字的形式展现给大家!文字可以直接复制!图片也可以直接拿去收藏!..._快捷键可以帮助自己
用HTML语言制作一个非常浪漫的生日祝福网,手把手教你制作炫酷生日祝福网页_用html做一个生日快乐网页-程序员宅基地
文章浏览阅读2.2w次,点赞317次,收藏636次。明天就是女朋友的生日了, 是时候展现专属于程序员的浪漫了!你打算怎么给心爱的人表达爱意?鲜花礼物?代码表白?还是创意DIY?或者…无论那种形式,快来秀我们一脸吧!_用html做一个生日快乐网页
idea快捷键配置和常用快捷键_idea自定义快捷键-程序员宅基地
文章浏览阅读1.1k次。idea快捷键配置和常用快捷键_idea自定义快捷键
y2.2隐藏英雄密码_从嗨到2y 10 tmnkr您的密码发生了什么-程序员宅基地
文章浏览阅读99次。y2.2隐藏英雄密码Say that I decide to sign up for an account an incredibly insecure password, ‘hi’. How does this become something stored in the database like this: 假设我决定为一个帐户注册一个非常不安全的密码“ hi ”。 它如何变成这样存储在数据..._$2y$10$y
从0到1搭建一套属于你自己的高精度实时结构光3D相机(1):硬件搭建-程序员宅基地
文章浏览阅读1.6k次,点赞42次,收藏11次。在这篇博客中,博主将主要介绍结构光3D相机的硬件如何搭建,主要涉及到相机与投影仪的选型与配置。在开头,博主先给大家摘出一段语录:能从硬件层面解决的问题,就别死磕算法了。是的,能从硬件层面解决的问题,死磕算法是没有意义的。例如,当你评估自己的3D相机精度却发现始终达不到理想水平时,不要在那两三句代码上死磕,回头想想,是不是自己的硬件搭建的不好,选型选的不对。就博主经验而言,大部分做结构光3D相机没几年的小萌新们,都对相机与投影仪的硬件特性毫无理解。