oracle数据库基本知识和操作-程序员宅基地
FROM EMPLOYEES;
–从倒数第N位截取指定长度的字符串
SELECT SUBSTR(LAST_NAME,-3,2)
FROM EMPLOYEES;
- -INSTR():在第一个参数中查找第二个参数首次出现的位置,没找到返回0.
SELECT LAST_NAME,INSTR(LAST_NAME,‘a’)
FROM EMPLOYEES;
SELECT LAST_NAME
FROM EMPLOYEES
WHERE INSTR(LOWER(LAST_NAME),‘a’)>0;
–LPAD()/RPAD():显示第一个参数的值,并使用第二个参数指定第一个参数显示的长度,如果第一个参数长度不够,则使用第三个参数在第一个参数的左/右面补齐长度。
SELECT LPAD(EMPLOYEE_ID,6,0),LAST_NAME
FROM EMPLOYEES;
SELECT TRIM( ’ ABC ABC ') AS A–去掉字符串两端的空格
FROM DUAL;
SELECT TRIM(‘A’ FROM ‘AAABACAAA’)–去掉字符串两端指定的字符
FROM DUAL;
–查询employees表中所有员工的last_name,要求显示的last_name首字母为小写,其它均为大写。
SELECT LOWER(SUBSTR(LAST_NAME,1,1))||UPPER(SUBSTR(LAST_NAME,2))
FROM EMPLOYEES;
–数字单行函数
– ROUND():四舍五入
SELECT ROUND(2563.987),ROUND(2563.987,2),ROUND(2563.987,0),ROUND(2563.987,-1)
FROM DUAL;
- -TRUNC():截断数字
SELECT TRUNC(2563.987),TRUNC(2563.987,2),TRUNC(2563.987,0),TRUNC(2563.987,-1)
FROM DUAL;
- -MOD():取余数
SELECT MOD(15,2)
FROM DUAL;
–ABS():绝对值
SELECT ABS(-100)
FROM DUAL;
–日期单行函数
- -SYSDATE:获得数据库当前日期+时间
SELECT SYSDATE-100
FROM DUAL;
/*
1.日期+天数=日期
2.日期-天数=日期
3.日期-日期=天数
4.日期不能加日期
*/
–查询employees表中所有员工的last_name,hire_date,月数
SELECT LAST_NAME,HIRE_DATE,TRUNC((SYSDATE-HIRE_DATE)/30) AS 月数
FROM EMPLOYEES;
– MONTHS_BETWEEN():获得两个日期相差的月数
SELECT LAST_NAME,HIRE_DATE,TRUNC(MONTHS_BETWEEN(SYSDATE,HIRE_DATE)) AS 月数
FROM EMPLOYEES;
- -ADD_MONTHS():在指定的日期上加上指定的月数
SELECT ADD_MONTHS(SYSDATE,100)
FROM DUAL;
–NEXT_DAY():获得下一个星期N的日期 。
SELECT NEXT_DAY(SYSDATE,4)
FROM DUAL;
SELECT NEXT_DAY(SYSDATE,‘星期三’)
FROM DUAL;
–类型转换单行函数
–自动转换
SELECT LAST_NAME,SALARY
FROM EMPLOYEES
WHERE SALARY>‘10000’;
- -手动转换:TO_CHAR(),TO_DATE(),TO_NUMBER()
/*
1.字符串与日期可以相互转换
2.字符串与数字可以相互转换
3.日期与数字不能相互转换
*/
–TO_CHAR(N,F):将日期类型N根据模板F转换为字符串类型的值 。
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘YYYY-MM-DD’)
FROM EMPLOYEES;
SELECT TO_CHAR(SYSDATE,‘YYYY-MM-DD HH24:MI:SS DAY DY’)
FROM DUAL;
SELECT TO_CHAR(SYSDATE,‘D DD DDD’)
FROM DUAL;
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘FMYYYY"年"MM"月"DD"日"’)
FROM EMPLOYEES;
–查询employees表中所有星期一入职员工的last_name,hire_date(格式如:1999-1-1 星期一)
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘FMYYYY-MM-DD DAY’)
FROM EMPLOYEES
WHERE TO_CHAR(HIRE_DATE,‘DAY’)=‘星期一’;
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘FMYYYY-MM-DD DAY’)
FROM EMPLOYEES
WHERE TO_CHAR(HIRE_DATE,‘D’)=‘2’;
–TO_CHAR(N,F):将数据类型N根据模板F转换为字符串类型的值。
SELECT
TO_CHAR(256987.9654,‘FM$99,999,999.00’) AS A,
TO_CHAR(256987.9654,‘FML99,999,999.00’) AS A
FROM DUAL;
– RR:可自动补齐年的前2位
–T O_DATE(C,F):根据模板F将字符类型C转换为日期类型的值
SELECT TO_DATE(‘2017-1-27’,‘YYYY-MM-DD’)-SYSDATE
FROM DUAL;
SELECT TO_DATE(‘2017-1-27’,‘YYYY-MM-DD’)
FROM DUAL;
- -TO_NUMBER(C,F):根据模板F将字符类型C转换为数字类型的值。
SELECT TO_NUMBER(‘¥50,000.00’,‘L99,999.00’)
FROM DUAL;
–通用单行函数
–NVL():当第一个参数不为NULL,返回第一个参数。当第一个参数为NULL,返回第二个参数。两个参数的类型必须一致 。
SELECT LAST_NAME,NVL(TO_CHAR(COMMISSION_PCT,‘FM0.999’),‘没有佣金’)
FROM EMPLOYEES;
–关系数据库中,算术运算中出现NULL时,结果一定为NULL。
–查询employees表中所有员工的last_name,salary,commission_pct,年薪,年收入(年薪+年薪*佣金)
SELECT LAST_NAME,SALARY,COMMISSION_PCT,SALARY*12 AS 年薪,(SALARY*12)+(SALARY*12*NVL(COMMISSION_PCT,0)) AS 年收入
FROM EMPLOYEES;
–SQL Server中IFNULL()的功能与Oracle中的NVL()功能一致。
– 分支选择:case表达式,decode()
–CASE表达式:结果的类型必须保持一致 。
–查询employees表中所有员工的last_name,job_id,salary,新工资。如果job_id为it_prog时,工资增加10%。如果job_id为st_clerk时,工资增加15%。如果job_id为sa_rep时,工资增加20%,其它职位工资不变。
SELECT LAST_NAME,JOB_ID,SALARY,
CASE
WHEN JOB_ID=‘IT_PROG’ THEN TO_CHAR(SALARY*1.1,‘FM$999,999.00’)
WHEN JOB_ID=‘ST_CLERK’ THEN TO_CHAR(SALARY*1.15,‘FM$999,999.00’)
WHEN JOB_ID=‘SA_REP’ THEN TO_CHAR(SALARY*1.2,‘FM$999,999.00’)
ELSE ‘不在此次活动范围内’
END AS 新工资
FROM EMPLOYEES;
–只能判断是否相等
SELECT LAST_NAME,JOB_ID,SALARY,
CASE JOB_ID
WHEN ‘IT_PROG’ THEN TO_CHAR(SALARY*1.1,‘FM$999,999.00’)
WHEN ‘ST_CLERK’ THEN TO_CHAR(SALARY*1.15,‘FM$999,999.00’)
WHEN ‘SA_REP’ THEN TO_CHAR(SALARY*1.2,‘FM$999,999.00’)
ELSE ‘不在此次活动范围内’
END AS 新工资
FROM EMPLOYEES;
- -DECODE()函数:只能判断是否相等
SELECT LAST_NAME,JOB_ID,SALARY,
DECODE(
JOB_ID,
‘IT_PROG’,SALARY*1.1,
‘ST_CLERK’,SALARY*1.15,
‘SA_REP’,SALARY*1.2,
SALARY
)AS 新工资
FROM EMPLOYEES;
–2016-11-15
–查询employees表中所有5月入职的员工的last_name,hire_date(格式如:1999-5-1)
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘FMYYYY-MM-DD’)
FROM EMPLOYEES
WHERE TO_CHAR(HIRE_DATE,‘MM’)=‘05’;
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘FMYYYY-MM-DD’)
FROM EMPLOYEES
WHERE TO_CHAR(HIRE_DATE,‘MON’)='5月 ';
–表
/*
CREATE TABLE 表名(
列名 数据类型[(长度)] [约束],
列名 数据类型[(长度)] [约束],
……
列名 数据类型[(长度)] [约束]
);
*/
–常用的数据类型
/*
一、数字类型:NUMBER
1.整数:NUMBER(5),长度可以省略,省略时默认为38位的数字。
2.浮点数:NUMBER(8,2),长度不能省略,整个数字为8位,其中有两位小数。
二、字符类型:不能省略长度。默认单位为字节。
1.CHAR:保存固定长度的字符串,如果内容的长度不足,使用空格在内容的后面补齐长度。
2.VARCHAR2:保存可变长度的字符串(不能超过上限),不会使用空格补齐长度。
三、日期类型:不能指定长度。
DATE:日期+时间
*/
CREATE TABLE TEST(
T_ID NUMBER(5),
T_NAME VARCHAR2(20 CHAR),
T_SEX CHAR(1 CHAR),
T_BIRTHDAY DATE
);
–查看表结构:DESC 表名/视图名
–数据操作
/*
一、添加数据:INSERT INTO语句;
1.向表中添加一行新数据,并向新行中所有的列赋值。
格式:INSERT INTO 表名 VALUES(值,值,……);
例:
INSERT INTO TEST VALUES(1,‘AA’,‘男’,TO_DATE(‘1989-10-20’,‘YYYY-MM-DD’));
2.向表中添加一行新数据,并向新行中指定的列赋值。
格式:INSERT INTO 表名(列名,列名,……) VALUES(值,值,……);
例:
INSERT INTO TEST(T_ID,T_NAME) VALUES(2,‘BB’);
3.将其它表中的数据复制到指定的表中。
格式:INSERT INTO 表名[(列名,列名,……)] SELECT语句;
例:
INSERT INTO TEST(T_ID,T_NAME,T_BIRTHDAY) SELECT EMPLOYEE_ID,LAST_NAME,HIRE_DATE FROM EMPLOYEES;
二、修改数据:UPDATE语句;
格式:UPDATE 表名 SET 列名=值[,列名=值,……] [WHERE 条件];
例:
UPDATE TEST SET T_BIRTHDAY=SYSDATE WHERE T_BIRTHDAY IS NULL;
UPDATE TEST SET T_NAME=‘张三’,T_SEX=‘女’ WHERE T_ID=1;
三、删除数据:DELETE语句;
格式:DELETE [FROM] 表名 [WHERE 条件];
例:
DELETE FROM TEST WHERE T_ID>=200;
–删除TEST表T_NAME列中所有的数据。
UPDATE TEST SET T_NAME=NULL;
*/
– 事务:单位时间内的一系列操作,这些操作要么全部成功,要么全部失败。
–提交事务:COMMIT。将对表中数据的操作保存到表中。
–回退事务:ROLLBACK。将数据还原为最初或最后一次提交的状态。
/*
SQL语句的分类:
DML(数据操作语句):SELECT,INSERT,UPDATE,DELETE
DDL(数据定义语句):CREATE,DROP,ALTER等
DCL(数据控制语句):COMMIT,ROLLBACK,SAVEPOINT等
*/
/*
1.当出现一个DDL语句时,数据库会自动提交事务。
2.当正常退出Oracle时,Oracle会自动提交事务。
3.当异常退出Oracle时,Oracle会自动回退事务。
*/
–约束:
1 .主键约束:PRIMARY KEY,不能为NULL,不能重复。 通过主键可以在表中查询出唯一的一行数据。
2.非空约束:NOT NULL,不能为空。
3.检查约束:CHECK,添加或修改列中的数据时,检查数据是否合法。
4.默认值:DEFAULT,当没有向列中添加数据时,Oracle自动为列添加的数据。
5.唯一约束:UNIQUE,可以为NULL,不能重复。
6.外键约束:FOREIGN KEY。
- -删除表:DROP TABLE 表名;删除表同时删除表中所有的数据,删除的数据不能回退 。
DROP TABLE STUDENTS;
CREATE TABLE STUDENTS(
STU_ID NUMBER(5) PRIMARY KEY,
STU_NAME VARCHAR2(10 CHAR) NOT NULL,
STU_SEX CHAR(1 CHAR) CHECK(STU_SEX IN(‘男’,‘女’)),
STU_DATE DATE DEFAULT SYSDATE
);
INSERT INTO STUDENTS VALUES(1,‘AA’,‘女’,NULL);
INSERT INTO STUDENTS(STU_ID,STU_NAME,STU_SEX) VALUES(2,‘BB’,‘男’);
–数据库中不能存在同名的对象
CREATE TABLE S(
S_ID NUMBER(6) PRIMARY KEY,
S_NAME VARCHAR2(20 CHAR)
);
CREATE TABLE C(
C_ID NUMBER(3) PRIMARY KEY,
C_NAME VARCHAR2(100 CHAR)
);
CREATE TABLE SC(
SC_ID NUMBER(8) PRIMARY KEY,
SC_S_ID NUMBER(6) NOT NULL,
SC_C_ID NUMBER(3) NOT NULL,
CONSTRAINT SC_SID_FK FOREIGN KEY(SC_S_ID) REFERENCES S(S_ID),
CONSTRAINT SC_CID_FK FOREIGN KEY(SC_C_ID) REFERENCES C(C_ID)
);
– 添加数据:先添加主表数据,再添加子表数据。
–删除数据:先删除子表数据,再删除主表数据。
–视图
/*
CREATE [OR REPLACE] VIEW 视图名
AS
SELECT语句;
CREATE OR REPLACE VIEW V1
AS
SELECT LAST_NAME,JOB_ID,SALARY,
CASE
WHEN JOB_ID=‘IT_PROG’ THEN TO_CHAR(SALARY*1.1,‘FM$999,999.00’)
WHEN JOB_ID=‘ST_CLERK’ THEN TO_CHAR(SALARY*1.15,‘FM$999,999.00’)
WHEN JOB_ID=‘SA_REP’ THEN TO_CHAR(SALARY*1.2,‘FM$999,999.00’)
ELSE ‘不在此次活动范围内’
END AS 新工资
FROM EMPLOYEES;
SELECT *
FROM V1;
视图的作用:
1.简化查询。
2.提高数据库的安全性。
–视图中没有数据,视图的数据来自于表。
*/
–截断表:TRUNCATE TABLE 表名;删除表中所有的数据,但不删除表结构。删除的数据不能ROLLBACK。
–序列:产生一个数字。通常用于自动生成主键。
/*
创建序列的格式:
CREATE SEQUENCE 序列名
[INCREMENT BY n] --每次序列的值时,序列的值加N/减N,默认为1
[START WITH n] --起始值,默认为0
[{MAXVALUE n | NOMAXVALUE}] --最大值为N/没有最大值(默认)
[{MINVALUE n | NOMINVALUE}] --最小值为N/没有最小值
[{CYCLE | NOCYCLE}] --循环/不循环(默认)
[{CACHE n | NOCACHE}] --当数据库启动时将序列的后N个值存入缓存中(默认)/当数据库启动时不将序列的值存入缓存中;
*/
CREATE SEQUENCE TEST_ID_SEQ;
–序列的值不能ROLLBACK;
– 序列属性:
1.NEXTVAL:获得序列的下一个值。每次调用此属性一定改变序列的值。
2.CURRVAL:获得序列当前的值。调用此属性不会改变序列的值。
INSERT INTO TEST(T_ID,T_NAME) VALUES(TEST_ID_SEQ.NEXTVAL,‘AA’);
SELECT TEST_ID_SEQ.CURRVAL
FROM DUAL;
–2016-11-16
–查询出employees表中所有员工的last_name,hire_date(格式:YYYY-MM-DD),salary(格式:FM$99,999.00),工龄(只保留整数),奖金。奖金的计算方式如下:工龄大于15年,奖金为5倍工资。工龄大于20年,奖金为10倍工资,工龄大于25年,奖金为20倍工资。如果工龄没超过15年,则显示“没有奖金”,查询结果根据工龄降序排序。
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘YYYY-MM-DD’) AS 入职时间,TO_CHAR(SALARY,‘FM$99,999.00’) AS 工资,TRUNC(MONTHS_BETWEEN(SYSDATE,HIRE_DATE)/12) AS 工龄,
CASE
WHEN MONTHS_BETWEEN(SYSDATE,HIRE_DATE)/12 > 25 THEN TO_CHAR(SALARY*20,‘FM$99,999,999.00’)
WHEN MONTHS_BETWEEN(SYSDATE,HIRE_DATE)/12 > 20 THEN TO_CHAR(SALARY*10,‘FM$99,999,999.00’)
WHEN MONTHS_BETWEEN(SYSDATE,HIRE_DATE)/12 > 15 THEN TO_CHAR(SALARY*5,‘FM$99,999,999.00’)
ELSE ‘没有奖金’
END AS 奖金
FROM EMPLOYEES;
–查询employees表中所有员工的last_name,hire_date(格式:YYYY-MM-DD),入职时间的星期
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘YYYY-MM-DD’) AS 入职时间,TO_CHAR(HIRE_DATE,‘DAY’) AS 星期
FROM EMPLOYEES
ORDER BY TO_CHAR(HIRE_DATE-1,‘D’) ASC;
–多表连接
–笛卡尔积
–原因:没有连接条件或连接条件不正确。
–行数:多张表行数据的乘积。
–多表连接时,建议在每个列的前面都添加表名的前缀,可以提高查询的效率。
–等值连接(内连接):只能查询出满足连接条件的数据。
–查询员工的last_name,department_id,department_name
SELECT E.LAST_NAME,E.DEPARTMENT_ID,D.DEPARTMENT_NAME
FROM EMPLOYEES E,DEPARTMENTS D
WHERE E.DEPARTMENT_ID=D.DEPARTMENT_ID;
–查询员工的last_name,job_id,job_title(在JOBS表中)
SELECT E.LAST_NAME,E.JOB_ID,J.JOB_TITLE
FROM EMPLOYEES E,JOBS J
WHERE E.JOB_ID=J.JOB_ID;
–通常情况下,连接条件的个数是表为个数减一。
–查询员工的last_name,department_name,city
SELECT E.LAST_NAME,D.DEPARTMENT_NAME,L.CITY
FROM EMPLOYEES E,DEPARTMENTS D,LOCATIONS L
WHERE E.DEPARTMENT_ID=D.DEPARTMENT_ID
AND D.LOCATION_ID=L.LOCATION_ID;
–查询在城市’Toronto’工作的员工的last_name,department_id,department_name,job_title
SELECT E.LAST_NAME,E.DEPARTMENT_ID,D.DEPARTMENT_NAME,J.JOB_TITLE
FROM EMPLOYEES E,DEPARTMENTS D,JOBS J,LOCATIONS L
WHERE E.DEPARTMENT_ID=D.DEPARTMENT_ID
AND E.JOB_ID=J.JOB_ID
AND D.LOCATION_ID=L.LOCATION_ID
AND L.CITY=‘Toronto’;
–非等值连接
–查询员工的last_name,salary,grade_level
SELECT E.LAST_NAME,E.SALARY,J.GRADE_LEVEL
FROM EMPLOYEES E,JOB_GRADES J
WHERE E.SALARY BETWEEN J.LOWEST_SAL AND J.HIGHEST_SAL;
–SQL:99
–查询员工的last_name,department_name
SELECT E.LAST_NAME,E.DEPARTMENT_ID,D.DEPARTMENT_NAME
FROM EMPLOYEES E INNER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID=D.DEPARTMENT_ID;
–查询员工的last_name,department_name,job_title,city
SELECT E.LAST_NAME,D.DEPARTMENT_NAME,J.JOB_TITLE,L.CITY
FROM EMPLOYEES E JOIN DEPARTMENTS D ON E.DEPARTMENT_ID=D.DEPARTMENT_ID
JOIN LOCATIONS L ON L.LOCATION_ID=D.LOCATION_ID
JOIN JOBS J ON J.JOB_ID=E.JOB_ID;
- -外连接:可以查询出满足连接条件与不满足连接条件的数据
–左外连接
SELECT E.LAST_NAME,D.DEPARTMENT_NAME
FROM EMPLOYEES E LEFT OUTER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID=D.DEPARTMENT_ID;
–右外连接
SELECT E.LAST_NAME,D.DEPARTMENT_NAME
FROM EMPLOYEES E RIGHT OUTER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID=D.DEPARTMENT_ID;
–全外连接
SELECT E.LAST_NAME,D.DEPARTMENT_NAME
FROM EMPLOYEES E FULL OUTER JOIN DEPARTMENTS D
ON E.DEPARTMENT_ID=D.DEPARTMENT_ID;
–Oracle中特有的外连接语法:(+)
–左外连接
SELECT E.LAST_NAME,D.DEPARTMENT_NAME
FROM EMPLOYEES E,DEPARTMENTS D
WHERE E.DEPARTMENT_ID=D.DEPARTMENT_ID(+);
–右外连接
SELECT E.LAST_NAME,D.DEPARTMENT_NAME
FROM EMPLOYEES E,DEPARTMENTS D
WHERE E.DEPARTMENT_ID(+)=D.DEPARTMENT_ID;
–SQL Server中特有的外连接语法:*
–左外连接
SELECT E.LAST_NAME,D.DEPARTMENT_NAME
FROM EMPLOYEES E,DEPARTMENTS D
WHERE E.DEPARTMENT_ID*=D.DEPARTMENT_ID;
–右外连接
SELECT E.LAST_NAME,D.DEPARTMENT_NAME
FROM EMPLOYEES E,DEPARTMENTS D
WHERE E.DEPARTMENT_ID=*D.DEPARTMENT_ID;
- -组函数(聚合函数 )
–常用的组函数
–SUM():求总和
SELECT SUM(SALARY)
FROM EMPLOYEES;
–AVG():求平均值
SELECT AVG(SALARY)
FROM EMPLOYEES;
–MAX()/MIN():最大/最小值
SELECT MAX(SALARY),MIN(SALARY)
FROM EMPLOYEES
SELECT MAX(HIRE_DATE),MIN(HIRE_DATE)
FROM EMPLOYEES;
SELECT MAX(LAST_NAME),MIN(LAST_NAME)
FROM EMPLOYEES;
–COUNT()
SELECT COUNT(COMMISSION_PCT)–查询指定列中不为NULL的值
FROM EMPLOYEES;
SELECT COUNT(*)–获得查询结果的行数
FROM EMPLOYEES;
–查询50号部门的人数
SELECT COUNT(*)
FROM EMPLOYEES
WHERE DEPARTMENT_ID=50;
–组函数与DISTINCT
SELECT COUNT(JOB_ID),COUNT(DISTINCT JOB_ID),COUNT(DISTINCT DEPARTMENT_ID)
FROM EMPLOYEES;
–组函数与NULL:所有的组函数在运算时会自动忽略NULL.
SELECT AVG(NVL(COMMISSION_PCT,0))
FROM EMPLOYEES;
–2016-11-17
–GROUP BY子句:分组,统计,报表
SELECT 4
FROM 1
[WHERE] 2
[GROUP BY] 3
[ORDER BY] 5
–统计每个部门的人数,显示:department_id,人数,结果根据部门编号升序排序。
SELECT DEPARTMENT_ID,COUNT(*)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
ORDER BY DEPARTMENT_ID ASC;
–统计每个职位的平均工资,显示:job_id,平均工资
SELECT JOB_ID,AVG(SALARY)
FROM EMPLOYEES
GROUP BY JOB_ID;
– 当使用GROUP BY子句时,SELECT子句中出现的非组函数的列必须出现在GROUP BY子句中参加分组。
–统计每个部门的最高工资与最低工资,显示:department_name,最高工资,最低工资,人数,结果根据department_name升序排序。
SELECT D.DEPARTMENT_NAME,MAX(NVL(E.SALARY,0)),NVL(MIN(E.SALARY),0),COUNT(E.EMPLOYEE_ID)
FROM EMPLOYEES E RIGHT JOIN DEPARTMENTS D ON E.DEPARTMENT_ID=D.DEPARTMENT_ID
GROUP BY D.DEPARTMENT_NAME
ORDER BY D.DEPARTMENT_NAME ASC;
– GROUP BY子句中分组的列,可以不在SELECT子句中出现 。
SELECT DEPARTMENT_ID
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID;
–查询每个部门中每个职位的平均工资与人数,显示:department_name,job_title,平均工资,人数
SELECT D.DEPARTMENT_NAME,J.JOB_TITLE,AVG(E.SALARY),COUNT(*)
FROM EMPLOYEES E JOIN DEPARTMENTS D ON E.DEPARTMENT_ID=D.DEPARTMENT_ID
JOIN JOBS J ON E.JOB_ID=J.JOB_ID
GROUP BY D.DEPARTMENT_NAME,J.JOB_TITLE
ORDER BY 1 ASC;
– HAVING子句:过滤分组的结果,使用HAVING子句时必须使用GROUP BY子句。
SELECT 5
FROM 1
[WHERE] 2
[GROUP BY] 3
[HAVING] 4
[ORDER BY] 6
– WHERE子句中不能使用组函数作为过滤的条件
–HAVING子句中可以使用组函数作为过滤条件
–查询平均工资大于10000的职位与平均工资,显示:job_id,平均工资
SELECT JOB_ID,AVG(SALARY)
FROM EMPLOYEES
GROUP BY JOB_ID
HAVING AVG(SALARY)>10000
ORDER BY AVG(SALARY) DESC;
SELECT DISTINCT LAST_NAME
FROM EMPLOYEES
ORDER BY SALARY DESC;
– 当使用DISTINCT与GROUP BY子句时,ORDER BY子句中排序的列必须在SELECT子句中出现。
–查询人数在3人或3人以上的部门与人数,显示:department_id与人数,结果根据人数降序排序。
SELECT DEPARTMENT_ID,COUNT(*)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING COUNT(*)>=3
ORDER BY COUNT(*) DESC;
- -尽量将过滤条件放在WHERE子句中,可以提高查询效率。
–查询最低工资大于6000,并且job_id不包含’REP’的job_id与最低工资。
SELECT JOB_ID,MIN(SALARY)
FROM EMPLOYEES
WHERE JOB_ID NOT LIKE ‘%REP%’
GROUP BY JOB_ID
HAVING MIN(SALARY)>6000;
–组函数嵌套
–查询平均工资最高的部门的平均工资
SELECT MAX(AVG(SALARY)),MIN(AVG(SALARY)),COUNT(*)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID;
/*
1.组函数嵌套时必须使用GROUP BY子句。
2.组函数嵌套时,SELECT子句中只能出现组函数嵌套的列(COUNT()除外)
3.组函数嵌套只能直接出现在SELECT子句中。
*/
–统计出每年入职的人数,显示:年,人数,结果根据年升序排序。
SELECT TO_CHAR(HIRE_DATE,‘YYYY’) AS 年,COUNT(*)
FROM EMPLOYEES
GROUP BY TO_CHAR(HIRE_DATE,‘YYYY’)
ORDER BY 年 ASC;
–子查询(嵌套查询)
–查询employees表中收入比176号员工高的员工的employee_id,last_name,salary
SELECT EMPLOYEE_ID,LAST_NAME,SALARY
FROM EMPLOYEES
WHERE SALARY>(SELECT SALARY
FROM EMPLOYEES
WHERE EMPLOYEE_ID=176);
/*
1.从Oracle8开始,除了GROUP BY子句外,其它子句都可以使用子查询。
2.无论子查询出现在哪个子句中, 子查询必须放在一对小括号内 。
3.如果子查询作为条件,建议将子查询放在运算符的右面,可以提高查询的效率。
4.如果子查询作为条件,子查询中列的个数与 类型 必须与主查询中条件列的个数与类型保持 一致 。
5.除非作TOP N的操作,否则 不能在子查询中作用ORDER BY子句 (仅限于Oracle)。
*/
– 普通子查询:先执行子查询,再执行主查询。
–查询employees表中在Fay员工之后入职的员工,显示:last_name,hire_date(格式为:YYYY-MM-DD)
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘YYYY-MM-DD’)
FROM EMPLOYEES
WHERE HIRE_DATE>(SELECT HIRE_DATE
FROM EMPLOYEES
WHERE LAST_NAME=‘Fay’);
–子查询与组函数
–查询哪些员工的工资大于公司的平均工资,显示:last_name,salary
SELECT LAST_NAME,SALARY
FROM EMPLOYEES
WHERE SALARY>(SELECT AVG(SALARY)
FROM EMPLOYEES);
–查询公司最早入职的员工的last_name,hire_date
SELECT LAST_NAME,HIRE_DATE
FROM EMPLOYEES
WHERE HIRE_DATE = (SELECT MIN(HIRE_DATE)
FROM EMPLOYEES);
–查询与入职最早的员工在同一部门工作的员工,显示:last_name,job_id,department_id
SELECT LAST_NAME,JOB_ID,DEPARTMENT_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID IN (SELECT DEPARTMENT_ID
FROM EMPLOYEES
WHERE HIRE_DATE=(SELECT MIN(HIRE_DATE)
FROM EMPLOYEES));
–HAVING子句与子查询
–查询哪些部门的平均工资大于公司的平均工资,显示:department_id,平均工资,结果根据department_id升序排序
SELECT DEPARTMENT_ID,AVG(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING AVG(SALARY)>(SELECT AVG(SALARY)
FROM EMPLOYEES)
ORDER BY 1 ASC;
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

总结:绘上一张Kakfa架构思维大纲脑图(xmind)
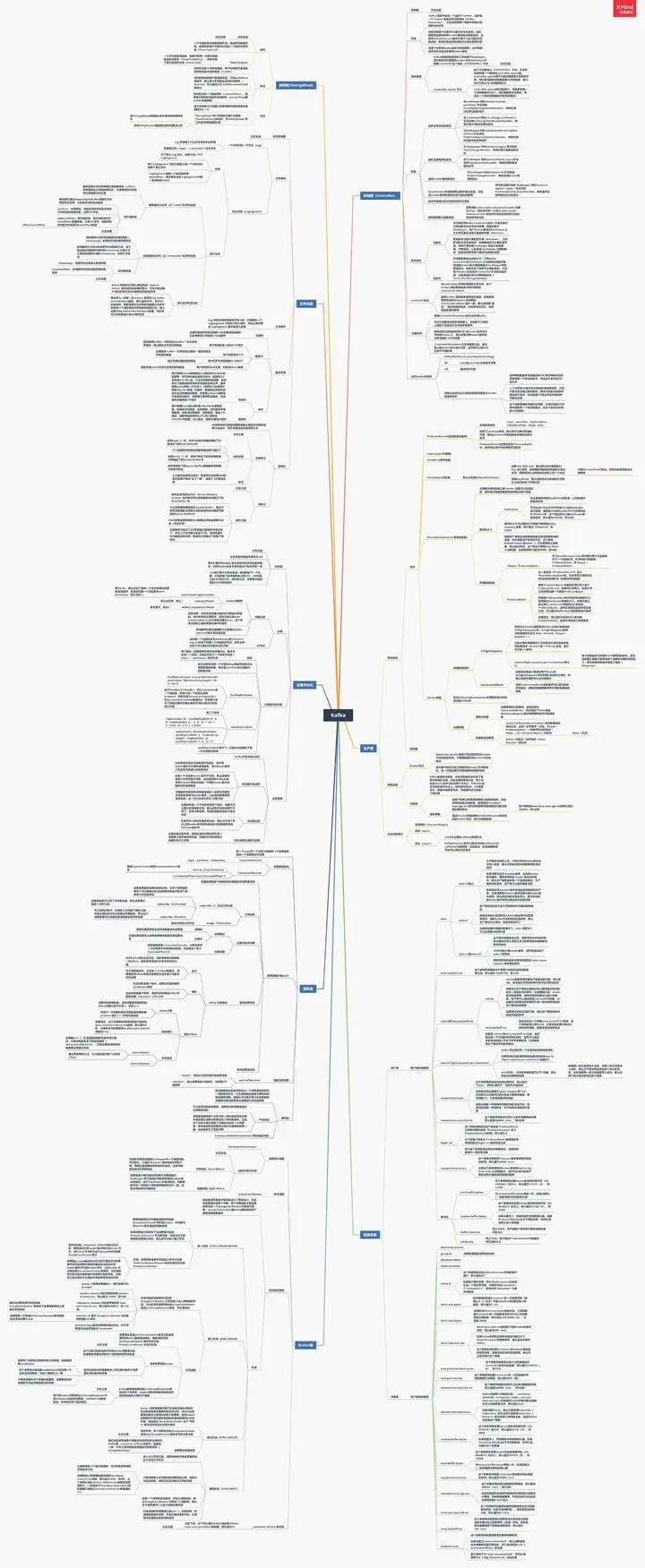
其实关于Kafka,能问的问题实在是太多了,扒了几天,最终筛选出44问:基础篇17问、进阶篇15问、高级篇12问,个个直戳痛点,不知道如果你不着急看答案,又能答出几个呢?
若是对Kafka的知识还回忆不起来,不妨先看我手绘的知识总结脑图(xmind不能上传,文章里用的是图片版)进行整体架构的梳理
梳理了知识,刷完了面试,如若你还想进一步的深入学习解读kafka以及源码,那么接下来的这份《手写“kafka”》将会是个不错的选择。
-
Kafka入门
-
为什么选择Kafka
-
Kafka的安装、管理和配置
-
Kafka的集群
-
第一个Kafka程序
-
Kafka的生产者
-
Kafka的消费者
-
深入理解Kafka
-
可靠的数据传递
-
Spring和Kafka的整合
-
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
行主查询。
–查询employees表中在Fay员工之后入职的员工,显示:last_name,hire_date(格式为:YYYY-MM-DD)
SELECT LAST_NAME,TO_CHAR(HIRE_DATE,‘YYYY-MM-DD’)
FROM EMPLOYEES
WHERE HIRE_DATE>(SELECT HIRE_DATE
FROM EMPLOYEES
WHERE LAST_NAME=‘Fay’);
–子查询与组函数
–查询哪些员工的工资大于公司的平均工资,显示:last_name,salary
SELECT LAST_NAME,SALARY
FROM EMPLOYEES
WHERE SALARY>(SELECT AVG(SALARY)
FROM EMPLOYEES);
–查询公司最早入职的员工的last_name,hire_date
SELECT LAST_NAME,HIRE_DATE
FROM EMPLOYEES
WHERE HIRE_DATE = (SELECT MIN(HIRE_DATE)
FROM EMPLOYEES);
–查询与入职最早的员工在同一部门工作的员工,显示:last_name,job_id,department_id
SELECT LAST_NAME,JOB_ID,DEPARTMENT_ID
FROM EMPLOYEES
WHERE DEPARTMENT_ID IN (SELECT DEPARTMENT_ID
FROM EMPLOYEES
WHERE HIRE_DATE=(SELECT MIN(HIRE_DATE)
FROM EMPLOYEES));
–HAVING子句与子查询
–查询哪些部门的平均工资大于公司的平均工资,显示:department_id,平均工资,结果根据department_id升序排序
SELECT DEPARTMENT_ID,AVG(SALARY)
FROM EMPLOYEES
GROUP BY DEPARTMENT_ID
HAVING AVG(SALARY)>(SELECT AVG(SALARY)
FROM EMPLOYEES)
ORDER BY 1 ASC;
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。[外链图片转存中…(img-KLxl9vbB-1713347395992)]
[外链图片转存中…(img-pmUsjXXW-1713347395993)]
[外链图片转存中…(img-fgPZoFIc-1713347395993)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
总结:绘上一张Kakfa架构思维大纲脑图(xmind)
[外链图片转存中…(img-7kHdz8mS-1713347395993)]
其实关于Kafka,能问的问题实在是太多了,扒了几天,最终筛选出44问:基础篇17问、进阶篇15问、高级篇12问,个个直戳痛点,不知道如果你不着急看答案,又能答出几个呢?
若是对Kafka的知识还回忆不起来,不妨先看我手绘的知识总结脑图(xmind不能上传,文章里用的是图片版)进行整体架构的梳理
梳理了知识,刷完了面试,如若你还想进一步的深入学习解读kafka以及源码,那么接下来的这份《手写“kafka”》将会是个不错的选择。
-
Kafka入门
-
为什么选择Kafka
-
Kafka的安装、管理和配置
-
Kafka的集群
-
第一个Kafka程序
-
Kafka的生产者
-
Kafka的消费者
-
深入理解Kafka
-
可靠的数据传递
-
Spring和Kafka的整合
-
SpringBoot和Kafka的整合
-
Kafka实战之削峰填谷
-
数据管道和流式处理(了解即可)
[外链图片转存中…(img-gjC7TIHg-1713347395994)]
[外链图片转存中…(img-7pPyQ8vy-1713347395994)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
智能推荐
vue引入原生高德地图_前端引入原生地图-程序员宅基地
文章浏览阅读556次,点赞2次,收藏3次。由于工作上的需要,今天捣鼓了半天高德地图。如果定制化开发需求不太高的话,可以用vue-amap,这个我就不多说了,详细就看官网 https://elemefe.github.io/vue-amap/#/zh-cn/introduction/install然而我们公司需要英文版的高德,我看vue-amap中好像没有这方面的配置,而且还有一些其他的定制化开发需求,然后就只用原生的高德。其实原生的引入也不复杂,但是有几个坑要填一下。1. index.html注意,引入的高德js一定要放在头部而_前端引入原生地图
ViewGroup重写大法 (一)-程序员宅基地
文章浏览阅读104次。本文介绍ViewGroup重写,我们所熟知的LinearLayout,RelativeLayout,FrameLayout等等,所有的容器类都是ViewGroup的子类,ViewGroup又继承View。我们在熟练应用这些现成的系统布局的时候可能有时候就不能满足我们自己的需求了,这是我们就要自己重写一个容器来实现效果。ViewGroup重写可以达到各种效果,下面写一个简单的重写一个Vi..._viewgroup 重写
Stm32学习笔记,3万字超详细_stm32笔记-程序员宅基地
文章浏览阅读1.8w次,点赞279次,收藏1.5k次。本文章主要记录本人在学习stm32过程中的笔记,也插入了不少的例程代码,方便到时候CV。绝大多数内容为本人手写,小部分来自stm32官方的中文参考手册以及网上其他文章;代码部分大多来自江科大和正点原子的例程,注释是我自己添加;配图来自江科大/正点原子/中文参考手册。笔记内容都是平时自己一点点添加,不知不觉都已经这么长了。其实每一个标题其实都可以发一篇,但是这样搞太琐碎了,所以还是就这样吧。_stm32笔记
CTS(13)---CTS 测试之Media相关测试failed 小结(一)_mediacodec框架 cts-程序员宅基地
文章浏览阅读1.8k次。Android o CTS 测试之Media相关测试failed 小结(一)CTSCTS 即兼容性测试套件,CTS 在桌面设备上运行,并直接在连接的设备或模拟器上执行测试用例。CTS 是一套单元测试,旨在集成到工程师构建设备的日常工作流程(例如通过连续构建系统)中。其目的是尽早发现不兼容性,并确保软件在整个开发过程中保持兼容性。CTS 是一个自动化测试工具,其中包括两个主要软件组件:CTS tra..._mediacodec框架 cts
chosen.js插件使用,回显,动态添加选项-程序员宅基地
文章浏览阅读4.5k次。官网:https://harvesthq.github.io/chosen/实例化$(".chosen-select").chosen({disable_search_threshold: 10});赋值var optValue = $(".chosen-select").val();回显1.设置回显的值$(".chosen-select").val(“opt1”);2.触发cho..._chosen.js
C++ uint8_t数据串如何按位写入_unit8_t 集合 赋值 c++-程序员宅基地
文章浏览阅读1.9k次。撸码不易,网上找不到,索性自己写,且撸且珍惜!void bitsWrite(uint8_t* buff, int pos, int size, uint32_t value){ uint32_t index[] = { 0x80000000, 0x40000000, 0x20000000, 0x10000000, 0x8000000, 0x4000000, 0x2000000, 0x1000000, 0x800000, 0x400000, 0_unit8_t 集合 赋值 c++
随便推点
Javaweb框架 思维导图_javaweb框架图-程序员宅基地
文章浏览阅读748次。javaweb知识点_javaweb框架图
adb的升级与版本更新_adb iptabls怎么升级-程序员宅基地
文章浏览阅读1.1w次,点赞3次,收藏16次。adb是没有自动升级的命令的,如果想要更新adb的版本,我们可以在网上找到自己想要的版本进行更新给大家提供几个版本https://pan.baidu.com/s/1yd0dsmWn5CK08MlyuubR7g&shfl=shareset 提取码: 94z81、下载解压后我们可以找到下面几个文件,并复制2、找到adb安装的文件夹下的platform-tools文件夹,我这里是..._adb iptabls怎么升级
微信苹果版删除所有的聊天记录的图文教程_mac微信怎么删除聊天列表-程序员宅基地
文章浏览阅读3.8k次。很多用户可能都知道怎么在Windows系统上删除微信的聊天记录,那么苹果电脑上的微信软件怎么删除所有的聊天记录呢?下面小编就专门来给大家讲下微信mac版删除所有的聊天记录的图文教程。点击后会弹出提示窗口,点击这里的确认按钮就可以将其清理掉了。在这里选择要清理的数据,然后点击下方右边的清理按钮就行了。在mac上打开微信后,点击左下角的横线图标。然后再点击这里的管理微信聊天数据按钮。打开了设置窗口,点击上方的“通用”。在这里点击下方的前往清理按钮。点击弹出菜单里的“设置”。_mac微信怎么删除聊天列表
【报错笔记】数据类型转换时报错:Request processing failed;nested exception is java.lang.NumberFormatException:..._request processing failed; nested exception is jav-程序员宅基地
文章浏览阅读7.7k次。数据类型转换时报错:Request processing failed;nested exception is java.lang.NumberFormatException:For input String “20151512345”报错原因:数字格式异常,接着后面有 For input string: “201515612343” 提示,这就告诉我们你当前想把 “201515612343” 转换成数字类型时出错了。解决方案:使用2015151612343这个数字太大了,所以直接使用string_request processing failed; nested exception is java.lang.numberformatexcepti
qml 自定义消息框_Qt qml 自定义消息提示框-程序员宅基地
文章浏览阅读387次。版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。本文链接:https://blog.csdn.net/a844651990/article/details/78376767Qt qml 自定义消息提示框QtQuick有提供比较传统的信息提示框MessageDialog,但是实际开发过程并不太能满足我们的需求。下面是根据controls2模块中..._qml 自定义 messagedialog
Redis.conf 默认出厂内容_默认出厂的原始redis.conf文件全部内容-程序员宅基地
文章浏览阅读599次。# Redis configuration file example.## Note that in order to read the configuration file, Redis must be# started with the file path as first argument:## ./redis-server /path/to/redis.conf # Note on units: when memory size is needed, it is pos._默认出厂的原始redis.conf文件全部内容